为什么需要undo log?
1.事务回滚需要历史记录
2.MVCC机制的底层BufferPool中的数据页和索引页什么区别?数据不也是以B+树索引的形式存储的么
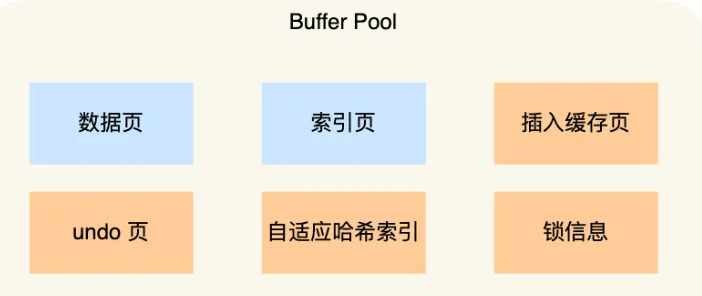
对于一级索引树:数据页是真实记录,也就是B+树的叶子节点,索引页存的是一级索引树的非叶子节点用于索引
对于二级索引树:二级索引树不存真实记录,因此所有节点都在索引页中
除了在BufferPool中,在InnoDB持久化硬盘中,物理结构也分数据页索引页
什么是BufferPool中的脏页
写入硬盘非常慢,因此写入的时候先在内存中写入脏页("脏"的意思是与硬盘有不一致),后续异步写入硬盘。BufferPool中的数据页和UNDO页都先作为脏页后续被刷盘。
什么是undo页
UNDOLOG本质就是一条条记录,一个实际记录对应多个历史记录(UNDOLOG),因此UNDOLOG也作为页存储,存储在UNDO页
什么是RedoLog
在写入BufferPool的脏页(包括数据页和UNDO页)前先向RedoLog备份要对该页的操作,作为保险单提供断电恢复功能。
同时为了能断电恢复,每次写RedoLog并commit后都要把内存中的RedoLog立马持久化到硬盘
RedoLog有什么用
断电恢复
RedoLog和脏页都存储了对数据库的操作,后续写入硬盘用的谁
RedoLog只作为备份使用,存储的不是完整信息,只存储变化信息,且在硬盘中,因此直接把脏页存入硬盘对应页
RedoLog和UndoLog啥区别
UndoLog存储每个操作前的历史记录,也就是插入更新修改前的状态,方便回滚
RedoLog存储每个操作后的记录,作为预写日志WAL,断电后只需要重跑一遍RedoLog就能恢复,方便断电恢复。同时操作Undo页时也要在Redolog记录。
插入修改删除一条记录并commit的实际流程
1. 准备阶段:加载与锁定
- 动作 :InnoDB 先看该记录所在的 数据页 和需要的 Undo 页 是否在 Buffer Pool 里。
- 细节 :如果不在,先从磁盘
.ibd文件和 Undo 空间里加载页到内存。同时对该行记录加锁。
2. 写入 Undo Log(后悔药):修改 Undo 页
- 动作 :在 Buffer Pool 的 Undo 页 中插入一条逻辑记录(如:刚才删了张三,这里记下张三的所有原数据)。
- 状态 :此时,Undo 页变成了脏页 。同时,这个修改 Undo 页的动作会产生一份 Redo Log(记录了 Undo 页的物理变化)。
3. 修改数据页(改正文):插入脏页
- 动作 :在 Buffer Pool 的 数据页 中执行真正的增删改。
- 状态 :此时,数据页变成了脏页 。同时,这个修改数据页的动作也会产生一份 Redo Log(记录了数据页的物理变化)。
- 注意:对数据页增删改,可能也要动索引页,索引页也可能成为脏页
4. 记录 Redo Log Buffer(预热)
- 动作 :将上述产生的两部分 Redo Log(针对 Undo 页的和针对数据页的)全部写入内存中的 Redo Log Buffer。
- 注意:此时所有操作都在内存,硬盘还没动。
5. 执行 Commit(生死关头:WAL 持久化)
- 动作 :当你点下
commit时,InnoDB 强制将 Redo Log Buffer 中的内容刷新到磁盘的 Redo Log 文件(ib_logfile) 中。 - 意义 :这就是 WAL(预写日志)。只要日志进了硬盘,哪怕下一秒停电,数据也丢不了。
6. 响应用户(成功反馈)
- 动作:Redo Log 刷盘完成后,MySQL 立刻给客户端返回"Query OK"或"事务提交成功"。
- 现状 :此时,磁盘里的
.ibd数据文件和 Undo 文件依然是旧的!最新的数据只存在于:内存脏页 + 磁盘 Redo Log。
7. 异步刷脏(落叶归根:Checkpoint)
- 动作 :由后台线程(Page Cleaner)根据系统的繁忙程度,异步地将 Buffer Pool 里的 数据脏页 和 Undo 脏页 真正写入磁盘的
.ibd文件和 Undo 空间。 - 清理:等到脏页安全落盘,Redo Log 里对应的位置就可以标记为"已失效",准备被后续的日志覆盖。
redolog什么时候刷盘
- MySQL 正常关闭时;
- 当 redo log buffer 中记录的写入量大于 redo log buffer 内存空间的一半时,会触发落盘;
- InnoDB 的后台线程每隔 1 秒,将 redo log buffer 持久化到磁盘。
- 每次事务提交时都将缓存在 redo log buffer 里的 redo log 直接持久化到磁盘。
binlog是什么
是在Server层实现的日志,记录了所有修改数据的逻辑sql。包含3种模式:STATEMENT,ROW,MIXED
binlog和canal什么联系
canal伪装从库监控binlog,之后将主库的记录修改信息发送给redis进行修改
binlog和redolog很像,什么区别
binlog存逻辑sql,redolog存物理变动;binlog在server层,redolog在innodb存储层;redolog循环写大小固定会覆盖,binlog追加写,写满一个开下一个永久保存;redolog主要用于崩溃恢复,binlog用于主从复制数据恢复
Mysql集群主从库功能划分
主库用来写;从库用来读
Mysql集群主库变动如何复制到从库
主库开启logdump线程,每次更新将binlog发给从库的IO线程,从库用来更新
Mysql集群从库是不是越多越好
不是。因为从库数量增加,从库连接上来的 I/O 线程也比较多,主库也要创建同样多的 log dump 线程来处理复制的请求,对主库资源消耗比较高,同时还受限于主库的网络带宽
binlog怎么刷盘
1.write:指把日志写入到文件系统的 page cache(操作系统的缓存),并没有真正落盘。这一步速度极快。
2.fsync:指将数据从 page cache 强制刷入 磁盘文件。这才叫真正的持久化。
二阶段提交
二阶段提交(Two-Phase Commit, 2PC) 是 MySQL 为了解决 Redo Log 和 Binlog 之间"内部一致性"问题而设计的。
简单来说,Redo Log 归 InnoDB 管,Binlog 归 Server 层管。如果不协调好,就会出现"主库有数据(Redo 有),从库没数据(Binlog 没)"或者反过来的灵异事件。
1. 为什么需要二阶段提交?
假设我们没有二阶段提交,而是简单地先写 A 日志再写 B 日志:
- 先写 Redo,再写 Binlog:Redo 写完瞬间断电,Binlog 没写成。重启后主库靠 Redo 恢复了,但从库因为没收到 Binlog,数据就丢了。
- 先写 Binlog,再写 Redo:Binlog 写完瞬间断电。重启后主库发现 Redo 没写,认为事务失败,不恢复;但从库收到 Binlog 并执行了。结果:从库多了数据。
为了让这两个日志同生共死,2PC 应运而生。
2. 二阶段提交的详细流程
当一个事务准备提交时,流程被拆分为两个阶段:
第一阶段:Prepare(准备阶段)
- 生成 Redo Log:InnoDB 将该事务的所有物理改动写入 Redo Log。
- 标记 Prepare :将这条 Redo Log 记录的状态设置为
PREPARE状态。 - 刷盘 :将这条
PREPARE状态的 Redo Log 真正刷入磁盘(受innodb_flush_log_at_trx_commit影响)。
- 此时,Binlog 还没动。
第二阶段:Commit(提交阶段)
- 写入 Binlog:事务提交后,Server 层将事务的逻辑操作(SQL 或行数据)写入 Binlog 文件。
- 刷盘 :将 Binlog 真正刷入磁盘(受
sync_binlog影响)。 - 写入 Commit 标记 :在 Redo Log 中追加一个
COMMIT标记,表示事务在引擎层也正式完成。
- 注意:这一步通常只需要 write 到系统缓存,不需要强制 fsync,因为即便这一步失败了,数据也能找回来。
3. 崩溃恢复(Crash Recovery)的逻辑
如果第二阶段失败了,磁盘中的redolog没有commit标记会怎么样
简单直接的结论是:不一定会回滚。MySQL 会根据 Binlog 的完整性来做最终裁决。
当 MySQL 崩溃恢复(Crash Recovery)发现一条 Redo Log 只有 PREPARE 标记而没有 COMMIT 标记时,它会进入一个逻辑判定流程:
核心判定逻辑:以 Binlog 为准
MySQL 会拿着这条处于 PREPARE 状态的 Redo Log 里的 XID (事务 ID),去 Binlog 文件里查找。
-
情况 A:Binlog 中找不到对应的 XID
- 判定:说明在第二阶段,Binlog 还没写完(或没刷盘)系统就崩了。
- 动作 :执行 回滚(Rollback)。
- 理由:既然 Binlog 没写,从库肯定没收到这条数据。为了保证主从一致,主库必须把之前的改动撤销。
-
情况 B:Binlog 中能找到对应的 XID
- 判定 :说明 Binlog 已经成功写入并落盘了,只是在最后往 Redo Log 补写
COMMIT标记时系统崩了。 - 动作 :执行 提交(Commit)。
- 理由:既然 Binlog 已经落盘,从库迟早会执行这个事务。如果主库因为没看到 commit 标记就回滚,会导致主从数据不一致(从库有,主库没)。
- 判定 :说明 Binlog 已经成功写入并落盘了,只是在最后往 Redo Log 补写
为什么这样做是安全的?
你可能会担心:Redo Log 里没记 commit,那内存里的数据页还是脏的吗?
- 恢复过程:在恢复时,MySQL 发现 Binlog 有记录,会再次触发引擎层的提交逻辑。
- 补写标记 :它会把这个事务在内存中重新变为"提交"状态,并补齐磁盘上 Redo Log 的
COMMIT标记。 - 最终一致:这样,主库的数据状态就和 Binlog 记录的逻辑状态完全对齐了。
redolog会定时持久化,binlog只在事务提交时才会持久化么
对
在一个事务中会不会存在多个redolog对应一个binlog的情况
会。持久化时机不一样,定时持久化的redolog可能会有多个但每个事务只有一个binlog
那binlog持久化后,是不是要对多个redolog打上commit标记
直观上确实容易这么想,但是实际上只需要一个标记。因为 Redo Log 是按照 LSN(日志序列号) 顺序排列的。MySQL 只需要在日志流里看到某个 XID 的 COMMIT 记录,就代表在这个 LSN 之前,该事务的所有 PREPARE 记录都已经安全躺在硬盘里了。
组提交
两阶段提交的问题
1.redolog和binlog每次事务提交都要至少两次刷盘
2.早期mysql为防止出现"事务A的redolog刷盘 + 事务B的binlog刷盘"的情况(主库只有事务A的记录,从库只有事务B的记录),将"redolog刷盘+binlog刷盘"加锁,限制了高并发。这被称为顺序一致性,顺序一致性的关键是"事务A的redolog先刷盘,那么事务A的binlog也应该先刷盘"。
组提交详细的联动流程
组提交的逻辑就是:与其让 100 个事务排队去撞 100 次磁盘,不如让它们在门口等一下,由一个"领头人"带着这 100 个事务的日志,一次性撞一次磁盘。
- Flush Stage (写入缓冲区) :
- 多个事务进入队列,Leader 把这组事务的 Binlog 写入 OS Cache。
- 此时 Redo Log 还在内存中,状态是 Prepare。
- Sync Stage (磁盘同步) :
- 核心动作 :Leader 发现有一组事务要提交,它会先触发 InnoDB 的 Redo Log 刷盘(把所有 LSN 小于当前最大值的日志全部 fsync)。
- 接着,Leader 再执行自己的
fsync(binlog)。 - 结果:这一组事务的 Redo 和 Binlog 都在这个阶段完成了物理落盘。
- Commit Stage (引擎提交) :
- 既然大家都落地了,Leader 告诉 InnoDB 可以批量把这些事务标记为
COMMIT了。
- 既然大家都落地了,Leader 告诉 InnoDB 可以批量把这些事务标记为
为什么要这么设计?(一箭三雕)
这种设计实现了三个目标:
- 保证一致性:顺序被队列锁死,落盘被 Leader 统一。
- 消灭全局锁 :不再需要
prepare_commit_mutex这种大锁,因为队列本身就是有序的。 - 减少 fsync 次数:Redo Log 也不再需要每个事务刷一次,而是跟着 Binlog 的节奏"组团"刷盘。