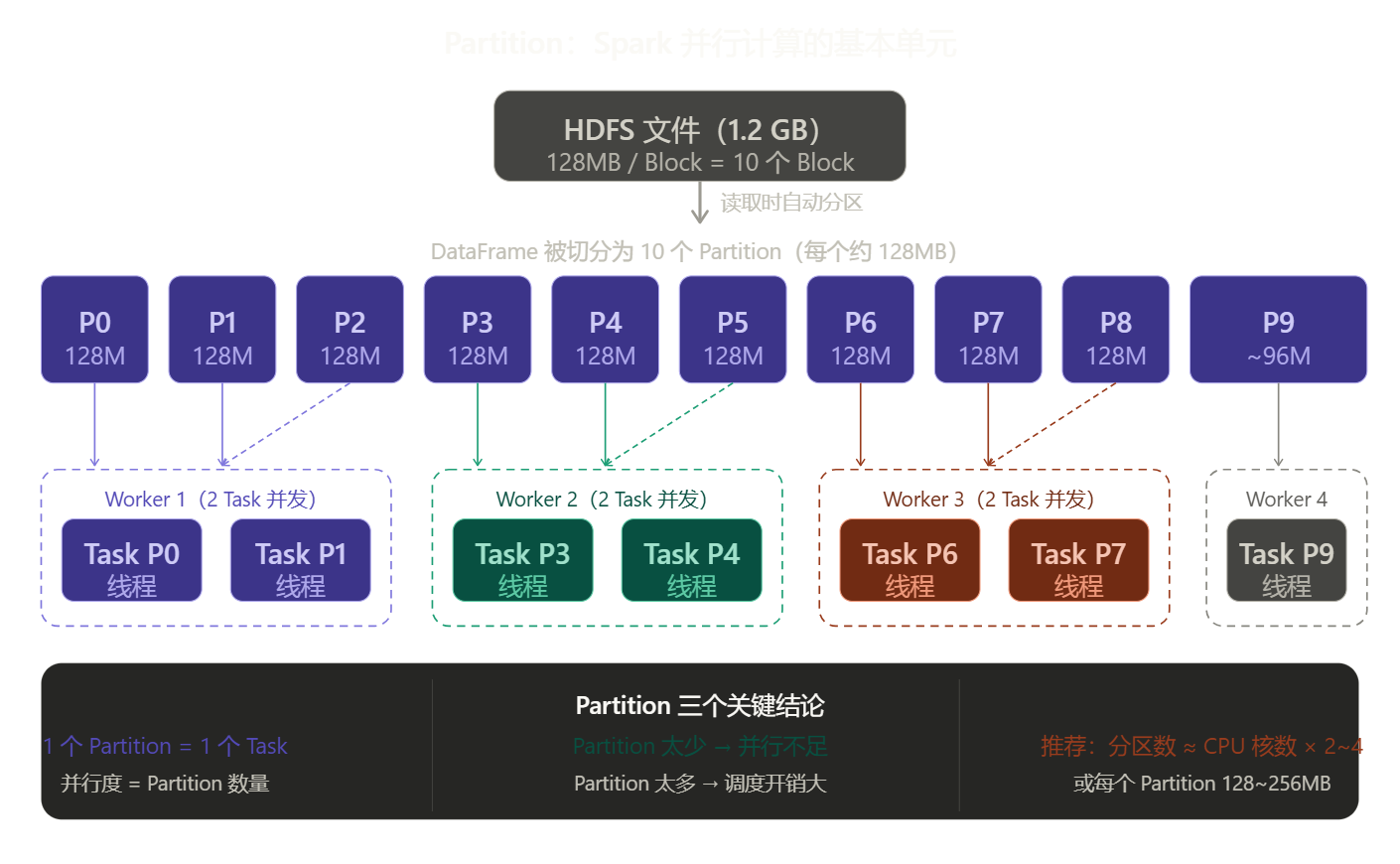
RDD 血统
RDD 血统 图--- 理解"懒执行"的关键:map、filter、reduceByKey 这些 Transformation 调用后 Spark 什么都没做,只是在内存里记下了一张"操作流程图"(血统图)。直到你调用 collect()、count()、save() 这类 Action,整条链才从头开始真正运行。好处是 Spark 能看到全貌再优化,坏处是调试时不容易发现哪步出错。
这张图揭示了 RDD 最核心的秘密:懒执行(Lazy Evaluation)。 前四步只是"记账",Spark 把每一步操作记录成一张血统图,直到 collect() 这个 Action 触发,整条链才真正开始计算。好处是 Spark 可以在执行前看到全貌,从而做整体优化。
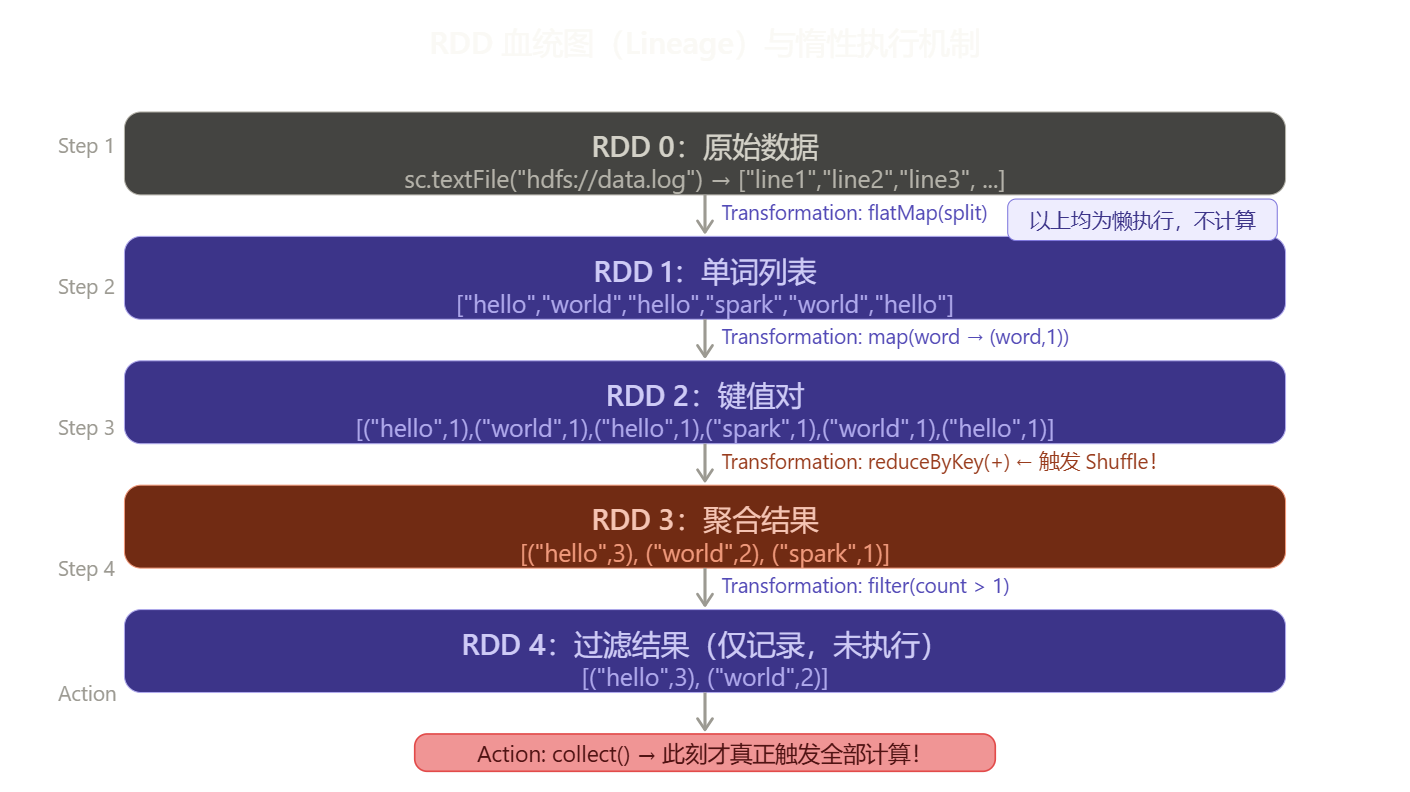
窄依赖 vs 宽依赖:Stage 划分的本质
窄依赖 vs 宽依赖(图二) --- 这是 Stage 划分的本质。map/filter 是窄依赖,一个父分区只对应一个子分区,不需要跨节点传数据,可以流水线执行,非常快。groupByKey/join 是宽依赖,每个子分区需要从所有父分区里拉数据,必须走网络 Shuffle,代价极高,也正是这里切出了 Stage 边界。写代码时尽量少用宽依赖算子,能用 reduceByKey 就不用 groupByKey,前者会在 Map 端先做一次预聚合,大幅减少 Shuffle 数据量。
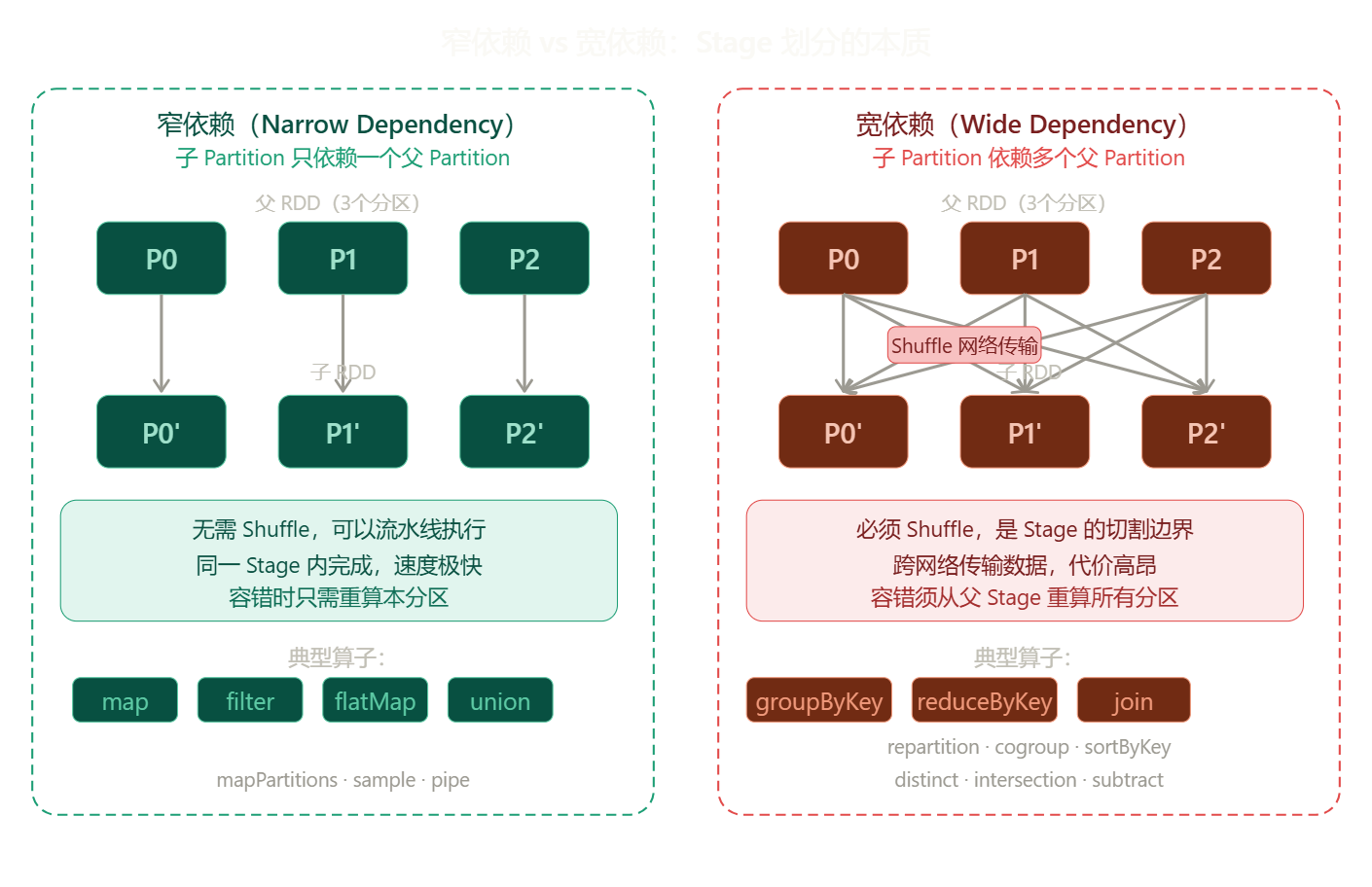
Dataset 三层抽象全景
三大抽象对比(图三) --- 对初学者最实用的结论是:直接用 DataFrame + Spark SQL,不要纠结 RDD。DataFrame 有 Schema、有 Catalyst 优化器、有 Tungsten 列式内存引擎,性能比手写 RDD 高很多,而且代码简洁十倍。RDD 只在处理非结构化数据(如图片字节流、自定义序列化对象)或需要精细控制执行行为时才有必要。Dataset 是 Scala/Java 专属,Python 用户完全不需要关心。
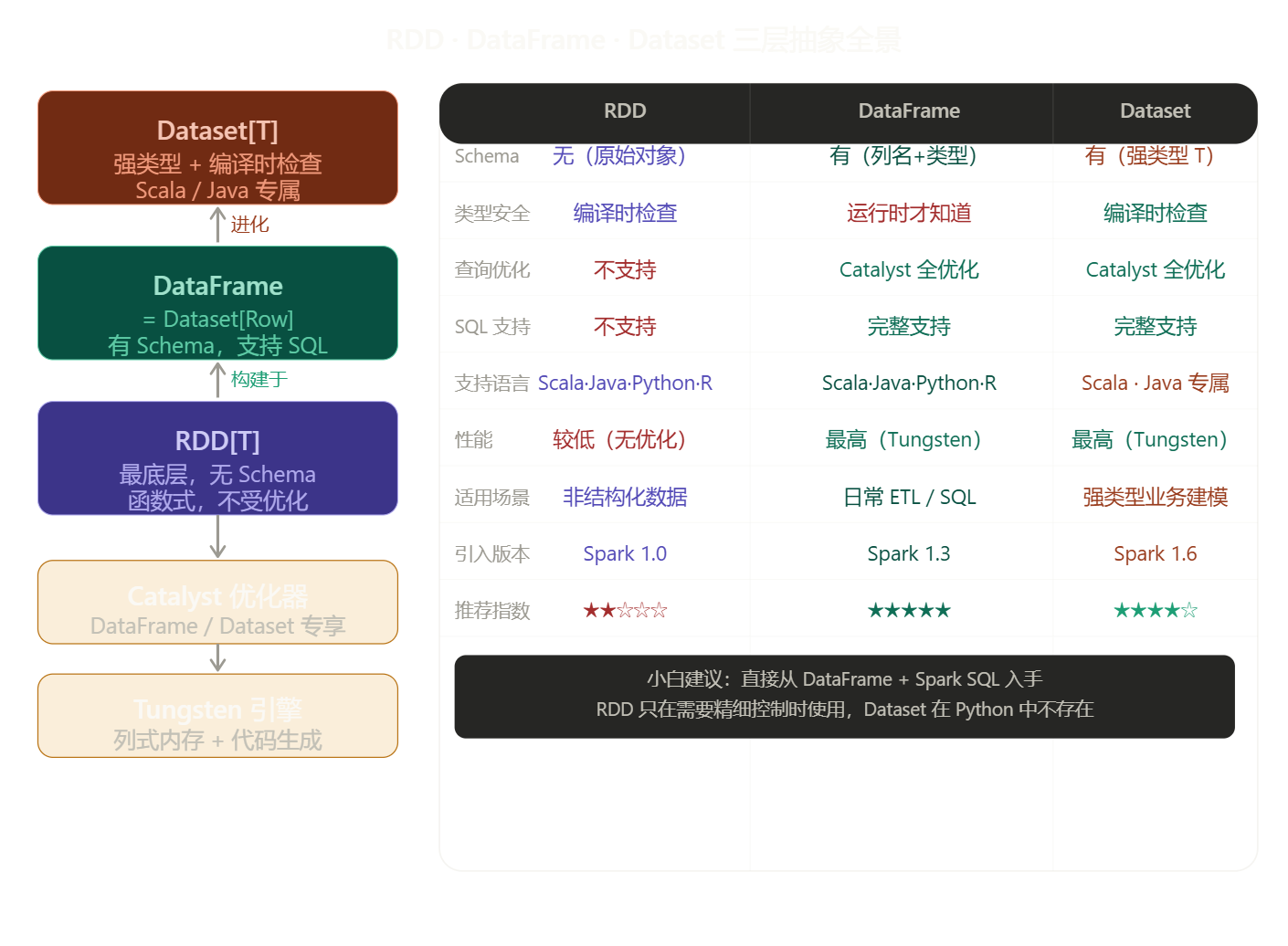
Partition:Spark 并行计算的基本单元
Partition 并行模型(图四) --- Partition 是 Spark 并行的最小单位,一个 Partition 对应一个 Task,一个 Task 跑在一个线程上。1.2GB 的文件默认被切成约 10 个 128MB 的分区,分发给各 Worker 上的 Executor 并行处理。分区数太少,机器核数用不满;分区数太多,Task 调度开销反而变大。实际经验是每个分区保持 128~256MB,分区总数约等于集群 CPU 总核数的 2 ~ 4 倍。