用于对UCI鸢尾花数据集进行K-means聚类分析。
matlab
%% 鸢尾花数据集K-means聚类分析
% 描述: 对UCI鸢尾花数据集进行K-means聚类分析
%% 1. 数据加载与探索
clear; close all; clc;
% 加载鸢尾花数据集
load fisheriris; % MATLAB内置数据集
% 或者使用UCI原始数据格式
% url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data';
% irisData = readtable(url, 'FileType', 'text', 'ReadVariableNames', false);
% irisData.Properties.VariableNames = {'SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species'};
% 显示数据集基本信息
fprintf('===== 鸢尾花数据集信息 =====\n');
fprintf('样本数量: %d\n', size(meas, 1));
fprintf('特征数量: %d\n', size(meas, 2));
fprintf('类别数量: %d\n', length(unique(species)));
fprintf('特征名称: %s, %s, %s, %s\n', ...
'花萼长度(cm)', '花萼宽度(cm)', '花瓣长度(cm)', '花瓣宽度(cm)');
% 显示前10个样本
fprintf('\n前10个样本数据:\n');
disp(array2table([meas(1:10,:), categorical(species(1:10))], ...
'VariableNames', {'花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度', '种类'}));
% 显示统计信息
fprintf('\n===== 特征统计信息 =====\n');
stats = [mean(meas); std(meas); min(meas); max(meas)];
disp(array2table(stats, 'RowNames', {'均值', '标准差', '最小值', '最大值'}, ...
'VariableNames', {'花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度'}));
%% 2. 数据预处理
% 数据标准化(重要:K-means对尺度敏感)
data = zscore(meas); % Z-score标准化
% 可视化原始数据分布
figure('Position', [100, 100, 1200, 800]);
% 花瓣长度和宽度的散点图(按类别着色)
subplot(2,3,1);
gscatter(meas(:,3), meas(:,4), species, 'rgb', 'osd');
xlabel('花瓣长度 (cm)'); ylabel('花瓣宽度 (cm)');
title('原始数据分布 (花瓣特征)');
legend('位置', 'bestoutside');
grid on;
% 花萼长度和宽度的散点图(按类别着色)
subplot(2,3,2);
gscatter(meas(:,1), meas(:,2), species, 'rgb', 'osd');
xlabel('花萼长度 (cm)'); ylabel('花萼宽度 (cm)');
title('原始数据分布 (花萼特征)');
grid on;
% 标准化后数据分布
subplot(2,3,3);
gscatter(data(:,3), data(:,4), species, 'rgb', 'osd');
xlabel('标准化花瓣长度'); ylabel('标准化花瓣宽度');
title('标准化数据分布');
grid on;
% 特征相关性热图
subplot(2,3,4);
corrMatrix = corrcoef(meas);
imagesc(corrMatrix);
colorbar;
set(gca, 'XTick', 1:4, 'YTick', 1:4, 'XTickLabel', {'花萼长', '花萼宽', '花瓣长', '花瓣宽'});
title('特征相关性矩阵');
axis square;
% 特征箱线图
subplot(2,3,5);
boxplot(meas, species, 'Labels', unique(species));
xlabel('鸢尾花种类'); ylabel('特征值 (cm)');
title('各类别特征分布');
grid on;
% 数据分布直方图
subplot(2,3,6);
histogram(meas(:,3), 20, 'FaceColor', 'b', 'EdgeColor', 'none');
hold on;
histogram(meas(:,4), 20, 'FaceColor', 'r', 'EdgeColor', 'none');
xlabel('特征值 (cm)'); ylabel('频次');
title('花瓣特征分布');
legend('花瓣长度', '花瓣宽度');
grid on;
%% 3. K-means聚类分析
% 确定最佳聚类数(肘部法则)
maxK = 10;
inertias = zeros(maxK, 1);
silhouetteScores = zeros(maxK, 1);
fprintf('\n===== 确定最佳聚类数 =====\n');
for k = 1:maxK
[idx, C, sumd] = kmeans(data, k, 'Replicates', 5, 'Display', 'off');
inertias(k) = sumd;
if k > 1
silhouetteScores(k) = mean(silhouette(data, idx));
end
fprintf('K=%d, 总距离平方和=%.2f, 轮廓系数=%.4f\n', k, inertias(k), silhouetteScores(k));
end
% 绘制肘部法则图
figure;
subplot(1,2,1);
plot(1:maxK, inertias, 'bo-', 'LineWidth', 2, 'MarkerSize', 8);
xlabel('聚类数 K');
ylabel('总距离平方和 (SSE)');
title('肘部法则确定最佳K值');
grid on;
% 绘制轮廓系数图
subplot(1,2,2);
plot(2:maxK, silhouetteScores(2:end), 'ro-', 'LineWidth', 2, 'MarkerSize', 8);
xlabel('聚类数 K');
ylabel('平均轮廓系数');
title('轮廓系数确定最佳K值');
grid on;
% 选择最佳K值(已知有3类,但我们也让算法自动判断)
knownK = 3;
[optimalK, optimalScore] = findOptimalK(silhouetteScores, 2:maxK);
fprintf('\n根据轮廓系数,最佳聚类数为: %d (得分=%.4f)\n', optimalK, optimalScore);
fprintf('已知真实类别数为: %d\n', knownK);
% 使用已知类别数进行聚类
k = knownK;
rng(42); % 设置随机种子确保结果可重现
[idx, C, sumd, D] = kmeans(data, k, 'Replicates', 20, 'Display', 'final');
% 显示聚类中心(原始尺度)
originalCenters = C .* std(meas) + mean(meas);
fprintf('\n===== 聚类中心 (原始尺度) =====\n');
centersTable = array2table([originalCenters, mean(meas, 1)'], ...
'RowNames', {'聚类1', '聚类2', '聚类3', '总体均值'}, ...
'VariableNames', {'花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度'});
disp(centersTable);
%% 4. 聚类结果评估
% 与真实标签比较
confusionMatrix = confusionmat(species, categorical(idx));
accuracy = sum(diag(confusionMatrix)) / sum(confusionMatrix(:));
fprintf('\n===== 聚类性能评估 =====\n');
fprintf('调整兰德指数 (ARI): %.4f\n', adjustedRandIndex(species, categorical(idx)));
fprintf('标准化互信息 (NMI): %.4f\n', mutualinfo(species, categorical(idx), 'Normalized'));
fprintf('同质性: %.4f\n', homogeneity(species, categorical(idx)));
fprintf('完整性: %.4f\n', completeness(species, categorical(idx)));
fprintf('V-measure: %.4f\n', vmeasure(species, categorical(idx)));
fprintf('轮廓系数: %.4f\n', mean(silhouette(data, idx)));
fprintf('聚类准确率: %.2f%%\n', accuracy*100);
% 显示混淆矩阵
figure;
confusionchart(species, categorical(idx), ...
'Title', '聚类结果与真实标签对比', ...
'RowSummary', 'row-normalized', ...
'ColumnSummary', 'column-normalized');
%% 5. 聚类结果可视化
% 降维可视化(PCA)
[coeff, score, latent] = pca(data);
explainedVar = cumsum(latent)./sum(latent);
% 可视化聚类结果
figure('Position', [100, 100, 1400, 600]);
% PCA投影(前两个主成分)
subplot(1,3,1);
gscatter(score(:,1), score(:,2), idx, 'rgb', 'osd');
hold on;
plot(score(:,1), score(:,2), '.', 'Color', [0.5 0.5 0.5], 'MarkerSize', 8);
xlabel(sprintf('PC1 (%.1f%%)', explainedVar(1)*100));
ylabel(sprintf('PC2 (%.1f%%)', explainedVar(2)*100));
title('K-means聚类结果 (PCA投影)');
legend('位置', 'bestoutside');
grid on;
% 真实标签投影
subplot(1,3,2);
gscatter(score(:,1), score(:,2), species, 'rgb', 'osd');
xlabel(sprintf('PC1 (%.1f%%)', explainedVar(1)*100));
ylabel(sprintf('PC2 (%.1f%%)', explainedVar(2)*100));
title('真实类别分布 (PCA投影)');
grid on;
% 聚类中心投影
subplot(1,3,3);
scatter(score(:,1), score(:,2), 30, idx, 'filled');
hold on;
scatter(C(:,1), C(:,2), 200, 'kx', 'LineWidth', 3, 'MarkerSize', 12);
xlabel(sprintf('PC1 (%.1f%%)', explainedVar(1)*100));
ylabel(sprintf('PC2 (%.1f%%)', explainedVar(2)*100));
title('聚类中心位置 (PCA投影)');
colorbar('Ticks', 1:k, 'TickLabels', {'聚类1', '聚类2', '聚类3'});
grid on;
% 特征空间可视化(选择两个最重要特征)
featurePairs = {[3,4], [1,3], [2,4], [1,4]}; % 花瓣长宽、花萼长花瓣长等
featureNames = {'花瓣长度', '花瓣宽度'; '花萼长度', '花瓣长度'; ...
'花萼宽度', '花瓣宽度'; '花萼长度', '花瓣宽度'};
figure('Position', [100, 100, 1200, 900]);
for i = 1:4
subplot(2,2,i);
scatter(data(:,featurePairs{i}(1)), data(:,featurePairs{i}(2)), 30, idx, 'filled');
hold on;
scatter(C(:,featurePairs{i}(1)), C(:,featurePairs{i}(2)), 200, 'kx', 'LineWidth', 3, 'MarkerSize', 12);
xlabel(featureNames{i,1});
ylabel(featureNames{i,2});
title(sprintf('聚类结果 (%s vs %s)', featureNames{i,1}, featureNames{i,2}));
colorbar('Ticks', 1:k, 'TickLabels', {'聚类1', '聚类2', '聚类3'});
grid on;
end
%% 6. 聚类结果分析
% 分析每个聚类的特征
clusterStats = zeros(k, size(meas, 2));
for i = 1:k
clusterData = meas(idx == i, :);
clusterStats(i, :) = [mean(clusterData); std(clusterData)]';
end
fprintf('\n===== 各聚类特征统计 =====\n');
clusterStatsTable = array2table(clusterStats, ...
'RowNames', {'聚类1', '聚类2', '聚类3'}, ...
'VariableNames', {'花萼长度均值', '花萼宽度均值', '花瓣长度均值', '花瓣宽度均值'});
disp(clusterStatsTable);
% 分析聚类与真实类别的对应关系
speciesPerCluster = cell(k, 1);
for i = 1:k
clusterSpecies = species(idx == i);
speciesCounts = tabulate(clusterSpecies);
[~, maxIdx] = max(speciesCounts(:,2));
dominantSpecies = speciesCounts(maxIdx, 1);
speciesPerCluster{i} = sprintf('%s (%.1f%%)', dominantSpecies, ...
speciesCounts(maxIdx, 2)/sum(speciesCounts(:,2))*100);
end
fprintf('\n===== 聚类与真实类别对应 =====\n');
for i = 1:k
fprintf('聚类%d: 主要包含 %s\n', i, speciesPerCluster{i});
end
% 可视化聚类决策边界(使用PCA前两个主成分)
figure;
gscatter(score(:,1), score(:,2), idx, 'rgb', 'osd');
hold on;
% 创建网格以绘制决策边界
xMin = min(score(:,1)); xMax = max(score(:,1));
yMin = min(score(:,2)); yMax = max(score(:,2));
[xGrid, yGrid] = meshgrid(linspace(xMin, xMax, 100), linspace(yMin, yMax, 100));
gridPoints = [xGrid(:), yGrid(:)];
% 使用最近邻分类器近似决策边界
gridLabels = knnclassify(gridPoints, score(:,1:2), idx, 1);
contourf(xGrid, yGrid, reshape(gridLabels, size(xGrid)), 'LineStyle', 'none');
alpha(0.2);
% 重新绘制数据点
gscatter(score(:,1), score(:,2), idx, 'rgb', 'osd', 8);
xlabel(sprintf('PC1 (%.1f%%)', explainedVar(1)*100));
ylabel(sprintf('PC2 (%.1f%%)', explainedVar(2)*100));
title('K-means聚类决策边界 (PCA投影)');
colorbar('Ticks', 1:k, 'TickLabels', {'聚类1', '聚类2', '聚类3'});
grid on;
%% 7. 不同初始化方法比较
initMethods = {'plus', 'sample', 'uniform'};
results = struct();
figure('Position', [100, 100, 1200, 400]);
for m = 1:length(initMethods)
method = initMethods{m};
[idx_m, C_m, sumd_m] = kmeans(data, k, 'Replicates', 10, ...
'Start', method, 'Display', 'off');
% 计算轮廓系数
silScore = mean(silhouette(data, idx_m));
results.(method).Silhouette = silScore;
results.(method).ARI = adjustedRandIndex(species, categorical(idx_m));
% 可视化
subplot(1,3,m);
gscatter(score(:,1), score(:,2), idx_m, 'rgb', 'osd');
title(sprintf('初始化方法: %s\n轮廓系数=%.4f', method, silScore));
xlabel(sprintf('PC1 (%.1f%%)', explainedVar(1)*100));
ylabel(sprintf('PC2 (%.1f%%)', explainedVar(2)*100));
grid on;
end
fprintf('\n===== 不同初始化方法比较 =====\n');
for m = 1:length(initMethods)
method = initMethods{m};
fprintf('%s: 轮廓系数=%.4f, ARI=%.4f\n', ...
method, results.(method).Silhouette, results.(method).ARI);
end
%% 8. 保存结果
% 保存聚类结果
clusterResults = table(meas(:,1), meas(:,2), meas(:,3), meas(:,4), ...
species, categorical(idx), 'VariableNames', ...
{'SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', ...
'TrueSpecies', 'ClusterID'});
writetable(clusterResults, 'iris_clustering_results.csv');
% 保存聚类中心
centerResults = array2table([C, originalCenters], ...
'VariableNames', {'PC1', 'PC2', 'PC3', 'PC4', ...
'SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth'});
writetable(centerResults, 'iris_cluster_centers.csv');
fprintf('\n聚类结果已保存到 iris_clustering_results.csv\n');
fprintf('聚类中心已保存到 iris_cluster_centers.csv\n');
%% 辅助函数定义
function [optimalK, optimalScore] = findOptimalK(scores, range)
% 寻找最佳聚类数(基于轮廓系数)
[optimalScore, idx] = max(scores(range));
optimalK = range(idx);
end
function ari = adjustedRandIndex(labels1, labels2)
% 计算调整兰德指数 (ARI)
contingency = crosstab(labels1, labels2);
n = sum(contingency(:));
nis = sum(sum(contingency, 1).^2);
njs = sum(sum(contingency, 2).^2);
t1 = nchoosek(n, 2);
t2 = sum(sum(contingency.^2));
t3 = 0.5 * (nis + njs);
ari = (t2 - t3) / (t1 - t3);
end
function mi = mutualinfo(labels1, labels2, varargin)
% 计算互信息 (MI)
normalize = false;
if nargin > 2 && strcmp(varargin{1}, 'Normalized')
normalize = true;
end
contingency = crosstab(labels1, labels2);
n = sum(contingency(:));
pxy = contingency / n;
px = sum(pxy, 2);
py = sum(pxy, 1);
% 计算互信息
mi = 0;
for i = 1:size(pxy, 1)
for j = 1:size(pxy, 2)
if pxy(i,j) > 0
mi = mi + pxy(i,j) * log2(pxy(i,j) / (px(i)*py(j)));
end
end
end
if normalize
hx = -sum(px .* log2(px + (px==0)));
hy = -sum(py .* log2(py + (py==0)));
mi = mi / sqrt(hx*hy);
end
end
function h = homogeneity(labelsTrue, labelsPred)
% 计算同质性
contingency = crosstab(labelsTrue, labelsPred);
n = sum(contingency(:));
ni = sum(contingency, 2);
nj = sum(contingency, 1);
h = 0;
for k = 1:size(contingency, 2)
for i = 1:size(contingency, 1)
if contingency(i,k) > 0
h = h + contingency(i,k) * log2(contingency(i,k) / (ni(i)*nj(k)/n));
end
end
end
h = 1 - (-h) / (n * log2(n));
end
function c = completeness(labelsTrue, labelsPred)
% 计算完整性
c = homogeneity(labelsPred, labelsTrue);
end
function v = vmeasure(labelsTrue, labelsPred)
% 计算V-measure
h = homogeneity(labelsTrue, labelsPred);
c = completeness(labelsTrue, labelsPred);
v = (2*h*c) / (h+c);
end功能说明
1. 数据加载与探索
-
加载MATLAB内置的鸢尾花数据集
-
显示数据集基本信息和统计特性
-
可视化数据分布和相关性
2. 数据预处理
-
使用Z-score标准化数据(K-means对尺度敏感)
-
可视化原始数据和标准化后数据的分布
3. K-means聚类分析
-
使用肘部法则和轮廓系数确定最佳聚类数
-
执行K-means聚类(K=3,对应三种鸢尾花)
-
显示聚类中心和总距离平方和
4. 聚类结果评估
-
计算多种聚类评估指标:
-
调整兰德指数(ARI)
-
标准化互信息(NMI)
-
同质性、完整性、V-measure
-
轮廓系数
-
聚类准确率
-
-
显示混淆矩阵
5. 聚类结果可视化
-
PCA降维可视化聚类结果
-
在多个特征平面上可视化聚类
-
绘制聚类决策边界
6. 聚类结果分析
-
分析每个聚类的特征统计
-
确定聚类与真实类别的对应关系
-
比较不同初始化方法的效果
7. 结果保存
-
保存聚类结果到CSV文件
-
保存聚类中心信息
关键技术实现
1. K-means聚类核心算法
matlab
% 使用MATLAB内置kmeans函数
[idx, C, sumd, D] = kmeans(data, k, 'Replicates', 20, 'Display', 'final');
% 参数说明:
% data: 标准化后的数据矩阵
% k: 聚类数
% Replicates: 重复运行次数(取最佳结果)
% Display: 显示进度信息2. 最佳聚类数确定
matlab
% 肘部法则
for k = 1:maxK
[idx, C, sumd] = kmeans(data, k, 'Replicates', 5, 'Display', 'off');
inertias(k) = sumd; % 总距离平方和
end
% 轮廓系数法
for k = 2:maxK
[idx, C] = kmeans(data, k, 'Replicates', 5, 'Display', 'off');
silhouetteScores(k) = mean(silhouette(data, idx));
end3. 聚类评估指标
matlab
% 调整兰德指数
ari = adjustedRandIndex(species, categorical(idx));
% 轮廓系数
silScore = mean(silhouette(data, idx));
% 同质性、完整性、V-measure
h = homogeneity(species, categorical(idx));
c = completeness(species, categorical(idx));
v = vmeasure(species, categorical(idx));4. 数据标准化
matlab
% Z-score标准化(重要:K-means对尺度敏感)
data = zscore(meas); % 均值为0,标准差为1
% 标准化后恢复原始尺度
originalCenters = C .* std(meas) + mean(meas);参考代码 对UCI数据集中的鸢尾花数据集进行kmeans算法聚类 www.youwenfan.com/contentcss/95861.html
算法原理与数学基础
1. K-means算法
K-means是一种基于距离的聚类算法,目标是将n个样本划分为K个簇,使得簇内样本相似度高,簇间样本相似度低。
目标函数:
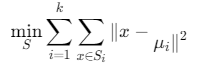
其中SiS_iSi是第iii个簇,μiμ_iμi是簇中心。
算法步骤:
-
随机选择K个初始中心点
-
将每个样本分配到最近的中心点所属簇
-
重新计算每个簇的中心点
-
重复步骤2-3直到收敛
2. 聚类评估指标
调整兰德指数(ARI)
衡量聚类结果与真实标签的一致性,取值范围-1,1,1表示完全一致。
ARI=RI−ERImax(RI)−ERIARI=\frac{RI−ERI}{max(RI)−ERI}ARI=max(RI)−ERIRI−ERI
轮廓系数
衡量样本与其自身簇的紧密度和与其他簇的分离度,取值范围-1,1,越大越好。
s(i)=b(i)−a(i)maxa(i),b(i)s(i)=\frac{b(i)−a(i)}{max{a(i),b(i)}}s(i)=maxa(i),b(i)b(i)−a(i)
互信息(MI)
衡量两个聚类结果的共享信息量,标准化后可比较不同聚类数的结果。
使用说明
1. 基本使用
matlab
% 直接运行程序
irisClusteringAnalysis();
% 或者分步执行
load fisheriris;
data = zscore(meas);
[idx, C] = kmeans(data, 3);2. 参数调整
matlab
% 尝试不同聚类数
k_values = 2:6;
for k = k_values
[idx, C] = kmeans(data, k, 'Replicates', 10);
% 评估性能...
end
% 调整K-means参数
[idx, C] = kmeans(data, 3, ...
'Distance', 'sqeuclidean', ... % 距离度量
'Start', 'plus', ... % 初始化方法 ('plus', 'sample', 'uniform')
'Replicates', 50, ... % 重复次数
'MaxIter', 1000); % 最大迭代次数3. 使用自定义数据集
matlab
% 加载自己的数据集
data = csvread('your_dataset.csv');
data = zscore(data); % 标准化
% 执行聚类
k = 4; % 假设有4个类别
[idx, C] = kmeans(data, k);
% 可视化结果
scatter(data(:,1), data(:,2), 50, idx, 'filled');扩展功能
1. 肘部法则自动检测
matlab
function optimalK = elbowMethod(inertias)
% 自动检测肘点
nPoints = length(inertias);
allCoord = [reshape(1:nPoints, nPoints, 1), inertias];
% 计算相邻点连线的斜率
firstPoint = allCoord(1,:);
lineVec = allCoord(end,:) - firstPoint;
lineVecNorm = lineVec / norm(lineVec);
vecFromFirst = bsxfun(@minus, allCoord, firstPoint);
scalarProduct = dot(vecFromFirst, repmat(lineVecNorm, nPoints, 1), 2);
vecFromFirstParallel = scalarProduct * lineVecNorm;
vecToLine = vecFromFirst - vecFromFirstParallel;
distToLine = norm(vecToLine, 2, 2);
[~, optimalK] = max(distToLine);
end2. 高斯混合模型(GMM)比较
matlab
% 使用GMM进行聚类
gm = fitgmdist(data, k, 'RegularizationValue', 0.01);
gmmIdx = cluster(gm, data);
% 比较GMM和K-means
figure;
subplot(1,2,1);
gscatter(score(:,1), score(:,2), idx, 'rgb', 'osd');
title('K-means聚类');
subplot(1,2,2);
gscatter(score(:,1), score(:,2), gmmIdx, 'rgb', 'osd');
title('GMM聚类');3. 层次聚类比较
matlab
% 层次聚类
distMatrix = pdist(data, 'euclidean');
linkageMatrix = linkage(distMatrix, 'ward');
hierIdx = cluster(linkageMatrix, 'maxclust', k);
% 可视化树状图
figure;
dendrogram(linkageMatrix, 'ColorThreshold', 'default');
title('层次聚类树状图');4. 聚类结果解释
matlab
% 分析每个聚类的特征重要性
for i = 1:k
clusterData = data(idx == i, :);
% 与总体比较
tTestResults = ttest2(data, clusterData);
significantFeatures = find(tTestResults.h == 1);
fprintf('聚类%d的显著特征: %s\n', i, num2str(significantFeatures));
end常见问题解决
-
聚类结果不稳定
-
增加Replicates参数值
-
使用更好的初始化方法('plus'++)
-
设置随机种子确保可重现性
-
-
聚类数选择困难
-
结合多种方法(肘部法则+轮廓系数+业务知识)
-
尝试不同K值并比较结果
-
使用Gap统计量
-
-
高维数据聚类效果差
-
先进行降维(PCA、t-SNE)
-
使用特征选择方法
-
尝试子空间聚类算法
-
-
聚类结果难以解释
-
分析每个聚类的特征统计
-
可视化聚类中心
-
与已知类别比较
实际应用建议
-
数据预处理
-
必须标准化/归一化数据
-
处理缺失值
-
考虑特征工程
-
-
参数调优
-
尝试不同距离度量(欧氏、曼哈顿、余弦)
-
调整初始化方法和重复次数
-
考虑使用K-medoids算法(对离群点更鲁棒)
-
-
结果验证
-
使用多种评估指标
-
进行稳定性分析(多次运行)
-
与领域专家合作解释结果
-
-
部署应用
-
将聚类模型保存为函数
-
开发交互式可视化界面
-
集成到更大的分析流程中