首先,让我们先创建一张表,如以下sql语句:
sql
-- 创建用户表(user 是关键字,建议用 user_info 避免冲突)
CREATE TABLE IF NOT EXISTS user_info (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
username VARCHAR(50) NOT NULL COMMENT '用户名(唯一)',
age TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄(0-255)',
email VARCHAR(100) DEFAULT NULL COMMENT '邮箱',
-- 主键约束
PRIMARY KEY (id),
-- 联合索引:(username, age) 满足你的需求
INDEX idx_username_age (username, age)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT = '用户信息表';
INSERT INTO user_info (username, age, email)
VALUES
('zhangsan', 25, 'zhangsan@example.com'),
('lisi', 30, 'lisi@example.com'),
('wangwu', 28, 'wangwu@example.com');如果想要复合索引不失效的话,就要遵循**最左前缀匹配原则,**复合索引(username,age)的底层是按username先排序,username相同再按照age排序的结构
下面就来介绍复合索引失效的场景
1.跳过最左列,只讲age作为查询条件
sql
-- 索引失效(只用到 age,跳过了最左的 username)
SELECT * FROM user_info WHERE age = 25;
-- 执行计划验证(能看到 type=ALL 表示全表扫描)
EXPLAIN SELECT * FROM user_info WHERE age = 25;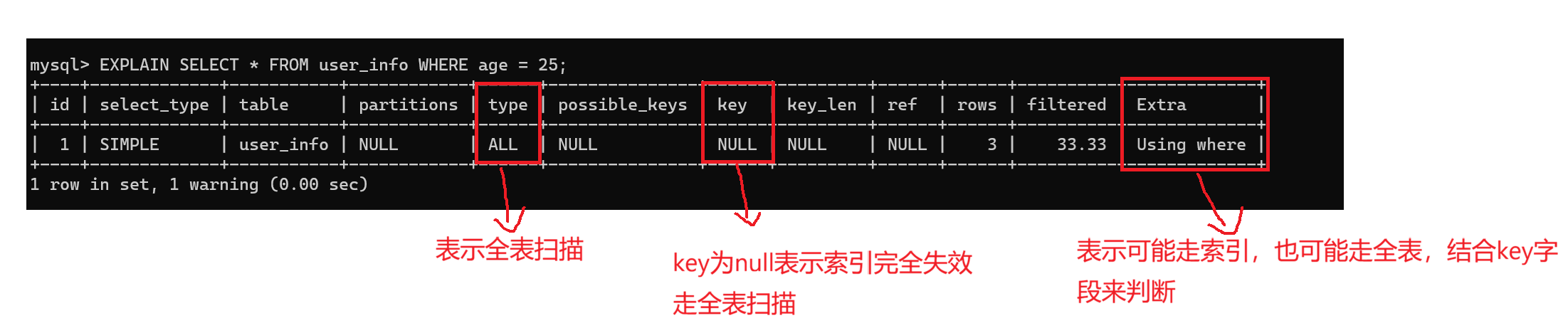
失效原因:联合索引的结构是先按照username进行排序,在按age排序,没有username的筛选条件,MySQL无法定位到age的有效范围,此时就只能全表扫描了
2.最左字段使用了函数/最左字段进行了运算操作/最左字段发生了类型转换
如果对username(最左字段)使用函数、算术运算、类型转换等,就会导致索引失效,因为索引存储的是原始值,函数处理后的值无法匹配到索引。
sql
-- 索引失效场景:
-- 1. 对 username 用函数
SELECT * FROM user_info WHERE UPPER(username) = 'ZHANGSAN' AND age = 25;
-- 2. 对 username 做拼接运算
SELECT * FROM user_info WHERE CONCAT(username, '123') = 'zhangsan123' AND age = 25;
-- 3. 隐式类型转换(比如 username 是字符串,却用数字匹配)
SELECT * FROM user_info WHERE username = 123 AND age = 25;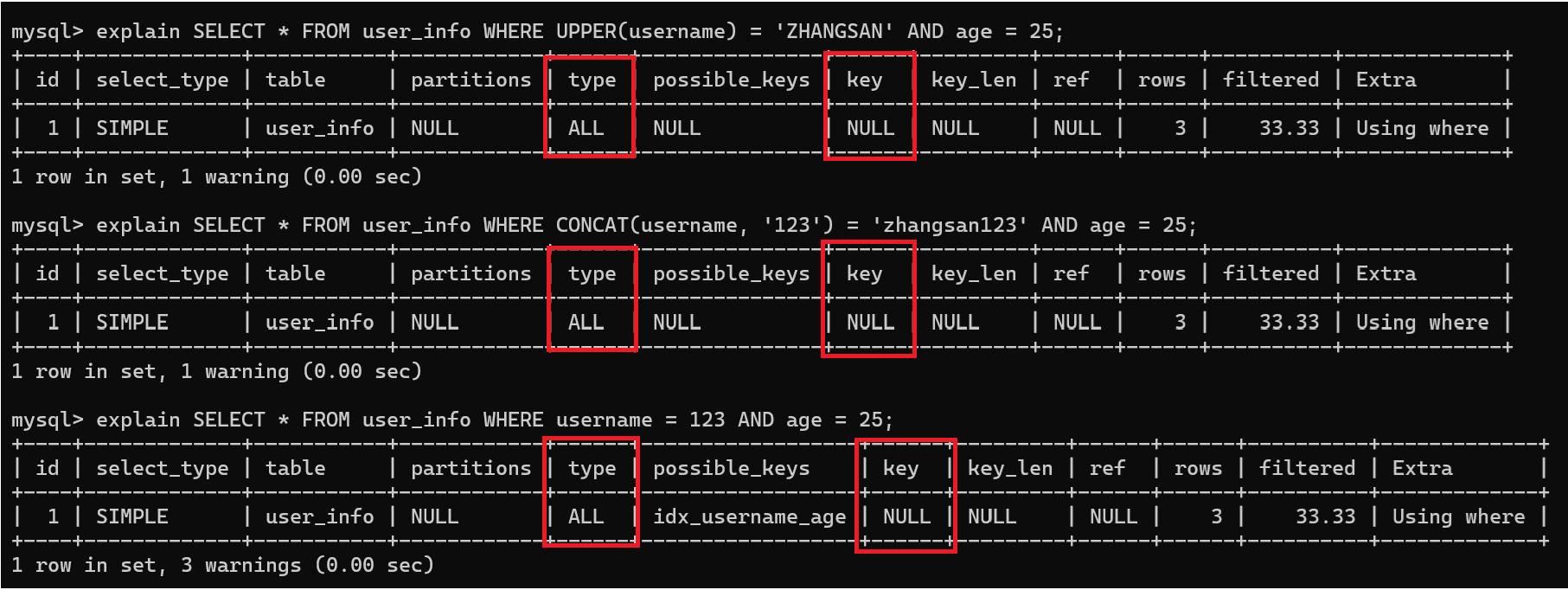
3.最左字段用了不等号,导致右侧字段索引失效
写sql时,如果对复合索引中的最左字段使用了!=来进行运算,此时就会导致右侧索引失效。
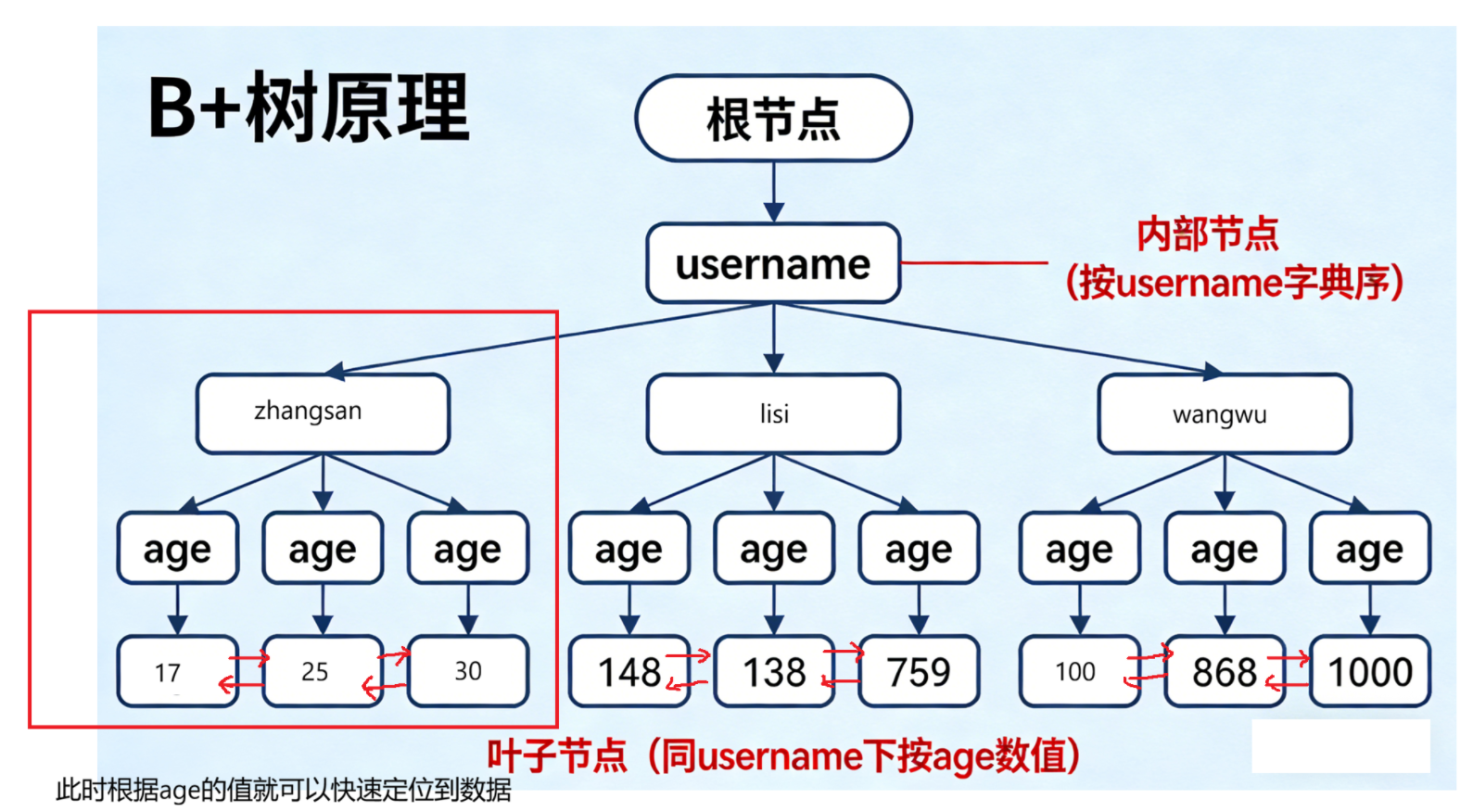
原因分析:首先联合索引(username,age),它是先根据username按照字典序进行排序,然后再在同一个username下面按照age的数值来进行排序,如下面的sql:
sql
SELECT * FROM user_info WHERE username = 'zhangsan' AND age = 25;此时上面这条sql中,age索引是生效的,对应到B+树中,在叶子节点的一条数据双向链表中,根据age的有序性,快速定位到数据,如下图
此时如果写的是下面这条sql
sql
SELECT * FROM user_info WHERE username != 'zhangsan' AND age = 25;此时因为username!=zhangsan等价于username>zhangsan和username<zhangsan,此时就会将索引拆分成两个区间,分别是最小,zhangsan)和(zhangsan,最大,此时由于在这两段区间中,username的取值存在跳跃的情况,此时就会导致age不是有序的,此时就会导致要在B+树的叶子节点的每一段区间的所有记录逐个对比age,此时的效率也就会大打折扣。

3.1索引下堆
索引下堆就是一个在索引里进行一个数据筛选的过程,尽量减少进行回表查询在筛选的操作,提前在索引中完成筛选,尽量减少回表的次数。
以下面的sql为例子:
sql
SELECT * FROM user_info WHERE username != 'zhangsan' AND age = 25;没有索引下堆的传统流程是:
首先在索引中找到username!='zhangsan'的数据行,然后将从索引中获得的每一条数据行都进行一遍回表,最终在得到的结果集中去筛选age=25的数据行
然后再MySQL5.6版本后,有了索引下堆之后:
此时的流程就会优化为:
首先在联合索引中定位到所有username!=zhangsan的数据行,此时直接在索引直接筛选出age=25的数据行,不满足的直接跳过,这些跳过的数据行就会直接被过滤,这些被过滤的数据行就不需要回表查询了,这样就需要对从索引中成功筛选出来的数据行记录进行回表查询,那些被过滤掉的数据行就不需要回表查询了,此时就可以减少IO操作,提高效率。
4.最左字段用了like '%xxx'(以%开头)
sql
-- 失效:username 以 % 开头,无法利用索引排序
SELECT * FROM user WHERE username LIKE '%san' AND age = 20;
-- 生效:username 前缀固定,能匹配索引有序性
SELECT * FROM user WHERE username LIKE 'zhang%' AND age = 20;首先,之所以使用 like 'zhang%' 时,索引会生效,因为我们的复合索引是(username,age),对应到B+树中,它是先根据username先进行排序,在username排好序的基础上,再根据age来排序。而此时由于使用的是 zhang% ,由于zhang是确定的,此时MySQL就可以直接通过索引中username的有序性,zhang开头的记录在索引中是一段连续的区间,此时MySQL就可以根据username的有序性,快速定位到以zhang开头的第一条记录,根据username的有序性,就可以顺序扫描到以zhang开头的最后一条记录,此时就不需要进行全表扫描了

然后就是为什么 like '%san' ,索引会失效?
%san的意思是匹配所有以san结尾的字符串,前面可以是任意字符
由于索引是按照username的前缀进行排序的,也就是按照username的值的字典序进行排序,由于是%san,就导致san前面的字符串的值是不确定的,就会导致以san结尾的字符串在索引里面可能是完全分散的,比如lisan,zhangsan,wangsan这三个字符串就会分布在索引中的不同区间。
由于那些以san结尾的字符串在索引中是分散的,MySQL就无法通过索引的有序性直接定位到这些分散的记录,此时就只能遍历整个索引树,将索引树中的每条记录都拿出来去判断一下该记录是否是以san结尾,此时就跟全表扫描差不多了,此时索引也就失去了加速的意义
所以这种情况下,MySQL会直接放弃索引,进行全表扫秒(在MySQL 5.6版本后,会出现索引下推的情况)

4.1 %在中间的情况
比如:username LIKE 'zhang%san',此时的索引可以理解为部分生效的,因为以zhang开头,依旧可以根据username的有序性去定位到想要查询数据的连续区间,但是因为 %san 这部分,MySQL是无法利用索引的有序性来进行过滤的,在这段连续区间的记录中,zhang后面的字符串是无法确定的(比如zhang123,zhangkl,zhangsk等等都在这个区间里面)。
所以MySQL只能定位到zhang开头的区间后,逐条遍历这段区间中的所有记录,然后再去判断是否以san结尾
4.2 如何让 %xxx 也用到索引
4.2.1 使用索引覆盖
假设我们的sql是:
sql
SELECT username, age FROM user WHERE username LIKE '%san' AND age = 20;此时复合索引(username,age)就覆盖了所有查询的字段,此时MySQL回去扫描整个索引树,此时的效率还是要比回表查询的效率要好很多的
4.2.2 使用全文索引---FULLTEXT
如果是大量模糊匹配的业务场景,可以用FULLTEXT索引来提到LIKE查询,专门处理这种前后都带通配符的场景
5.对最左字段用 NOT IN 、!= 、NOT EXISTS
当当复合索引中的最左字段使用了否定类查询(NOT IN 、!= 、NOT EXISTS),此时的原因还是索引的有序性,导致索引失效
sql
-- 失效:username 用 NOT IN
SELECT * FROM user WHERE username NOT IN ('zhangsan', 'lisi') AND age = 20;
-- 反例(生效):age 用 NOT IN,username 等值查询,索引生效
SELECT * FROM user WHERE username = 'zhangsan' AND age != 20;

6.使用了关键字OR
6.1 场景1:OR包含了非索引列
sql
SELECT * FROM user WHERE username = 'zhangsan' OR address = 'Beijing';因为使用的是OR关键字,这条sql的意思就是要将所有username='zhangsan'或者address='Beijing'的记录找出来,因为在username是索引列,此时找username='zhangsan'的所有记录是可以走索引的,但是由于address不是索引列,但是我们是要找出所有address='Beijing'的记录的,所以此时只能去回表进行全表查询了,既然都发生了全表查询了,此时就username='zhangsan'没必要走索引了,直接全表扫描更省事一点了
6.2 场景2:OR的一侧无索引列,逻辑上跳过了最左列
sql
SELECT * FROM user WHERE username = 'zhangsan' OR age = 20;由于我们定义的索引是(username,age),此时username='zhangsan'由于是复合索引中的第一列,此时是可以走索引的,但是问题就出现在age=20,由于age在索引中是第二列,此时就会导致age=20是无法走索引的,因为索引中所有age=20的记录是分散的,此时如果想找出所有age=20的记录,只能去全表查询,既然都进行了全表查询,那么此时username='zhangsan'也就顺便全表查询了,省事点
补充,下面这种情况索引是生效的:
sql
SELECT * FROM user WHERE username = 'zhangsan' OR username = 'lisi';6.3 解决方案---使用union关键字
sql
-- 第一段:走 username 索引
SELECT * FROM USER WHERE username = 'zhangsan'
UNION -- 合并结果(自动去重)
-- 第二段:给 age 单独建索引!就能走索引了
SELECT * FROM USER WHERE age = 20;