密度聚类 即"基于密度的聚类"(density-based clustering),++此类算法通过样本分布的紧密程度确定聚类结构。通常情况下,密度聚类算法从样本密度的角度考察样本之间的可聚类性,并基于样本之间的可聚类性不断扩展聚类簇获得最终的聚类结果++。
23.1 密度聚类 : DBSCAN算法
DBSCAN是著名的密度聚类算法之一,它基于"邻域"(neighborhood)参数(ε, MinPts)刻画样本分布的紧密程度。给定数据集D={x1, x2, ..., xm},定义以下几个概念:
ε-邻域:对于xj∈D,其ε-邻域包含数据集D中与xj的距离不大于ε的样本;即Nε(xj)={xi∈D|dist(xi,xj)≤ε};
核心对象(core object):若xj的ε-邻域至少包含MinPts个样本,则xj是一个核心对象;
密度直达(directly density-reachable):若xi位于xj的ε-邻域中,xj是核心对象,则称xi对xj密度直达;
密度可达 (density-reachable):对于xi与xj,若存在样本序列x1, x2, ..., xn,其中x1=xi, xn=xj且xk+1对xk密度直达(k=1,2,...,n-1),则称xj对xi密度可达;<注意:密度可达描述的是单向传递关系,用于构建簇的扩展路径。>
密度相连 (density-connected):对于xi与xj,若存在xk使得xi与xj均对xk密度可达,则称xi与xj密度相连。<注意:密度相连描述的是双向对称关系,用于确保簇内点的最大连接性。>
如图是上述概念的直观显示:
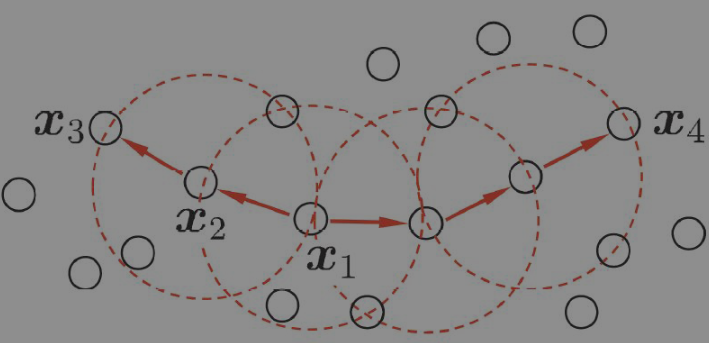
虚线圆环代表ε-邻域,MinPts=3,x1是核心对象,x2对x1密度直达,x3对x1密度可达,x3与x4密度相连。
基于这些概念,++DBSCAN将"簇"定义为:由密度可达关系导出的最大的密度相连的样本集合++。
<也就是说,一个簇内,从核心样本出发,簇内的样本均可在ε半径之内直达或可达,即簇内的样本均在ε半径之内环环相连。>
D中不属于任何簇的样本被认为是噪声(noise)或异常(anomaly)样本。
如何从数据集中生成 DBSCAN 聚类簇?DBSCAN算法如下所示:

23.1.1 算法解读
DBSCAN算法解读如下:
令Ω为核心对象集合
for j=1,2, ..., m do
确定样本 xj 的ε-邻域 Nε(xj) <dji=||xj-xi||2 ≤ ε, xi∈D, i≠j>
if |Nε(xj)| ≥ MinPts : 将 xj 加入核心对象集合Ω
end for
初始化聚类簇个数 k=0
初始化当前未访问的样本集合 ∅=D
while Ω ≠ None do
∅0=∅ <记录当前未访问过的样本集合>
从Ω中随机选取一个核心对象o,初始化队列Q=<o>,∅=∅\o <一个新簇开始划分>
while Q ≠ None do
从队列Q中取出一个样本x (Q=Q\x)
<"10. while"循环最初是从核心对象o出发,先将其ε-邻域内的样本加入队列;依次执行,则每下一个从队列Q中取出的样本x即ε-邻域中的一个样本,...>
确定样本x的ε-邻域 Nε(x)
if |Nε(x)| ≥ MinPts :
将Nε(x)中的样本加入队列Q
<如果(ε-邻域中的)这个样本x也是核心对象,则将这个样本的ε-邻域也加入队列即加入当前的簇,这样环环相扣,可不断寻找样本密度达到要求的 (|Nε(x)|≥MinPts) 可扩展的最大路径,体现了此算法从样本密度的角度考察样本之间的可聚类性并不断扩展聚类簇。>
∅=∅\Nε(x)
<此ε-邻域已加入队列Q即加入当前的簇,则应从∅中去除此ε-邻域内的样本,即当前未访问过的样本集合已更新>
end if
<然后从++"10. while"开始新的子循环:从Q中取出下一个样本x开始连接一个新的ε-邻域++>
- end while
<当Q=None,本次"10. while"循环结束,即当前簇的扩展过程结束。>
- 生成聚类簇 : k=k+1, Ck=∅0\∅
<从"10. while"循环之初记录的∅0去除"当前未访问的样本集合"∅,即本次"10. while"循环划分到当前簇Ck里的样本子集>
- Ω=Ω\Ck
<然后从++"7. while"开始新的子循环:从Ω中随机选取下一个核心对象o开始划分一个新簇++>
- end
<当Ω = None,"7. while"总循环结束,核心对象集合Ω全部遍历完成,数据集D全部簇划分完成。>
输出:簇划分C={C1, C2, ..., Ck}
DBSCAN算法从一个核心对象出发,基于样本密度 (|Nε(x)|≥MinPts) 逐一扩展新的聚类簇,直观过程如上图所示。
23.2 层次聚类 : AGNES算法
层次聚类(hierarchical clustering)通过按照不同的层次对数据集进行划分,形成树形的聚类结构。可采用"自底向上"的聚合策略,也可采用"自顶向下"的分拆策略。
++AGNES是一种采用自底向上聚合策略的层次聚类算法。它先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,此过程不断重复,直至达到预设的聚类簇个数。++
++关键是如何计算聚类簇之间的距离++。实际上,每个簇是一个样本集合,因此,采用能够代表集合的某种距离即可:簇之间的最小距离 dmin 由两个簇最近的样本距离决定;簇之间的最大距离 dmax 由两个簇最远的样本距离决定;簇之间的平均距离 davg 由两个簇全部样本之间的距离求和再平均决定。当聚类簇之间的距离由dmin,dmax或davg计算时,AGNES算法被相应地称为"单链接"(single-linkage)、"全链接"(complete-linkage)或"均链接"(average-linkage)算法。
AGNES算法如下所示:

23.2.1 算法解读
AGNES算法解读如下:
样本集D={x1, x2, ..., xm}
距离矩阵 M
聚类簇之间距离度量函数 d
聚类簇最终个数为k
for j=1,2, ..., m do
Cj = {xj}
end for
<将每个样本作为一个初始聚类簇>
for i=1,2, ..., m do
for j=i+1, i+2, ..., m do
M(i, j) = d(Ci, Cj)
M(j, i) = M(i, j)
end for
end for
<计算每个样本与其它全部样本之间的距离 (即初始聚类簇之间的距离),构建成一个对称的距离矩阵 M>
设置当前聚类簇个数:q = m
while q>k do
从距离矩阵M中找出距离最近的两个簇 Ci 和 Cj <即M中的最小值对应的i与j>
将 Cj 合并到 Ci : Ci* = Ci ∪ Cj
for j* = j+1, j+2, ..., q do <注意这里最末位是q(当前聚类簇个数),不能是m>
Cj*-1 = Cj*
<Cj = Cj+1, Cj+1 = Cj+2, ..., Cq-1 = Cq
即 Cj 合并到 Ci 之后,相当于 j 位为空,则从 Cj+1 开始到 Cq (最后一个聚类簇),每个C向前移一位>
end for
q=q-1
<簇划分的一次更新包括两个步骤:簇合并,簇移位。
之后,需要相应地更新距离矩阵M :>
- 删除距离矩阵M的第 j 行和第 j 列
<原Cj 已不存在,应将原Cj与其它全部聚类簇之间的距离全部删除>
for l = 1, 2, ..., q do
M(i, l) = d(Ci*, Cl)
M(l, i) = M(i, l)
end for
<更新 合并之后的新簇 Ci* 与其它簇之间的距离,距离矩阵M更新完成。
然后,开始下一个子循环 ...>
end while
<每次子循环将当前距离最近的两个簇进行合并,直到簇的个数合并到设定的k,循环结束,样本集D的簇划分完成。>
输出:簇划分C={C1, C2, ..., Ck}
AGNES算法生成的"树状图" :
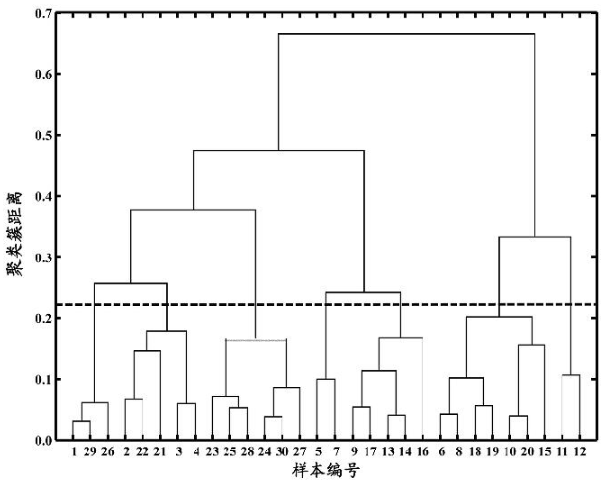
采用将 dmax 低于一个阈值的两个簇进行合并 (提高合并速度)。横轴对应样本编号,++纵轴对应聚类簇合并时彼此之间的距离dmax++。
<此树状图一个有趣的特点:画一条水平虚线对树状图进行分割,水平虚线在树状图上的分割点即当前合并出来的簇。将水平虚线逐步提升,则聚类簇逐步合并逐步减少。>