一、传统 Serverless 的痛点
在传统的 Serverless 架构中,运行时通常采用独立进程或容器化的部署方式。这种模式存在以下问题:
1. 架构复杂
2. 通信开销大
3. 运维门槛高
二、openYuanrong 的设计理念
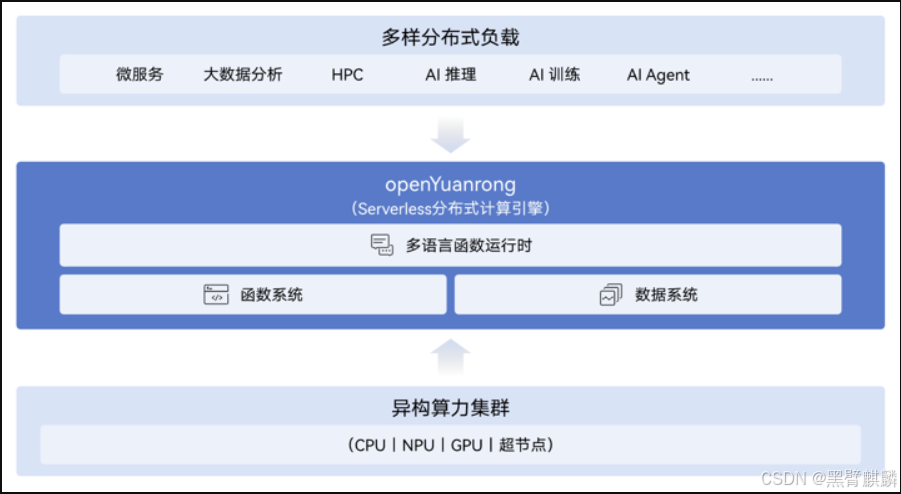
2. 核心优势
零通信开销:
- 函数调用直接在进程内完成
- 无需序列化/反序列化
- 无进程间通信(IPC)
简化运维:
- 无需管理独立的运行时进程
- SDK 随用户程序一起启动和停止
- 资源由用户进程统一管理
部署简单:
Python 部署步骤
我的系统是Ubuntu 24.04 的 Python 是系统管理的,安装了
py
# 1. 激活 conda 环境
source ~/miniconda/etc/profile.d/conda.sh
conda activate yr
查看 Python 版本
python
python3 --version
安装 openYuanrong
py
pip install https://openyuanrong.obs.cn-southwest-2.myhuaweicloud.com/release/0.7.0/linux/x86_64/openyuanrong-0.7.0-cp311-cp311-manylinux_2_34_x86_64.whl
py
验证 yr 命令
yr version
查看 Python SDK 路径
python -c "import yr; import os; print(os.path.dirname(yr.__file__))"
C++ 部署步骤
查看 C++ SDK 结构
bash
ls -la /home/test/miniconda/envs/yr/lib/python3.11/site-packages/yr/inner/runtime/sdk/cpp/
创建项目目录
bash
mkdir -p ~/cpp_demo
cd ~/cpp_demo
创建 CMakeLists.txt和创建 main.cpp
bash
cat > CMakeLists.txt << 'EOF'
cmake_minimum_required(VERSION 3.10)
project(cpp_demo)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# openYuanrong SDK 路径
set(YR_INSTALL_PATH "/home/test/miniconda/envs/yr/lib/python3.11/site-packages/yr/inner/runtime/sdk/cpp")
include_directories(${YR_INSTALL_PATH}/include)
link_directories(${YR_INSTALL_PATH}/lib)
set(CMAKE_INSTALL_RPATH "${YR_INSTALL_PATH}/lib")
set(CMAKE_BUILD_WITH_INSTALL_RPATH TRUE)
add_executable(demo main.cpp)
target_link_libraries(demo yr-api functionsdk datasystem litebus)
EOF
cat > main.cpp << 'EOF'
#include <iostream>
#include <yr/yr.h>
int main() {
std::cout << "openYuanrong C++ Demo" << std::endl;
YR::Config conf;
conf.mode = YR::Config::LOCAL_MODE;
YR::Init(conf);
std::cout << "openYuanrong initialized successfully!" << std::endl;
YR::Finalize();
std::cout << "Demo completed!" << std::endl;
return 0;
}
EOF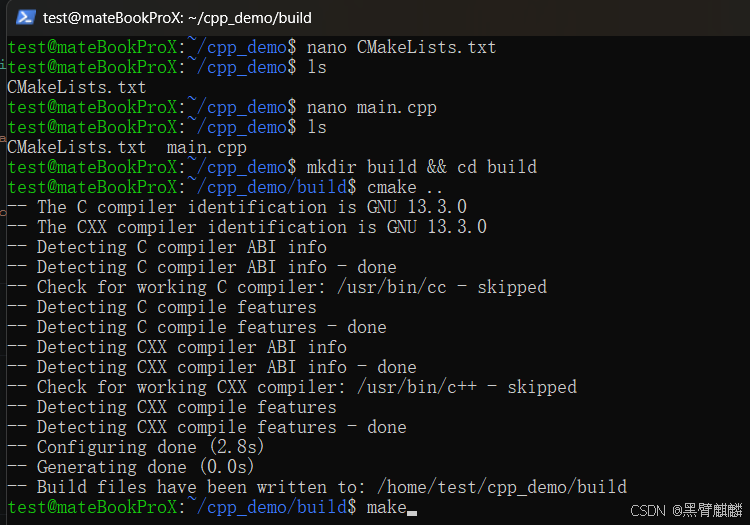
bash
# 编译
mkdir -p build && cd build
cmake ..
make
# 运行
export LD_LIBRARY_PATH=/home/test/miniconda/envs/yr/lib/python3.11/site-packages/yr/inner/runtime/sdk/cpp/lib:$LD_LIBRARY_PATH
./demo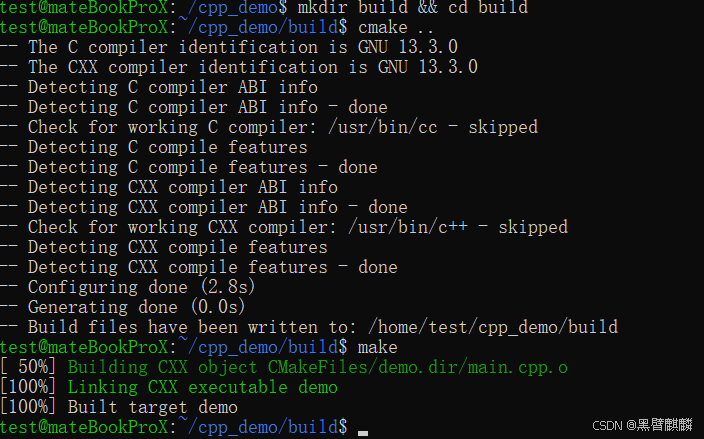
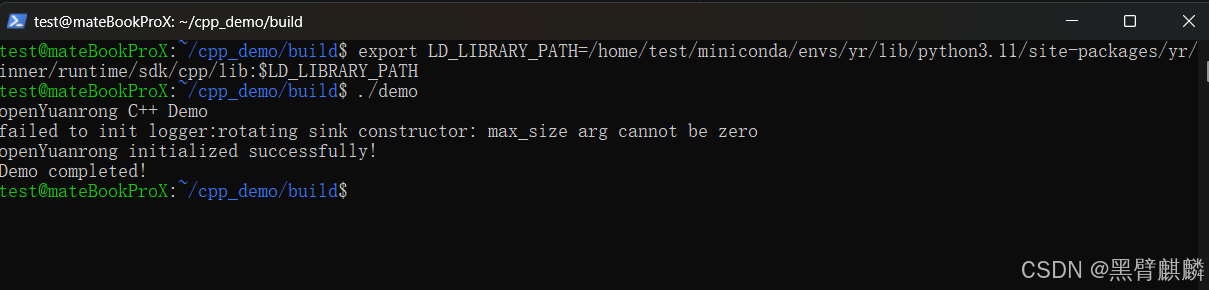
运行成功输出
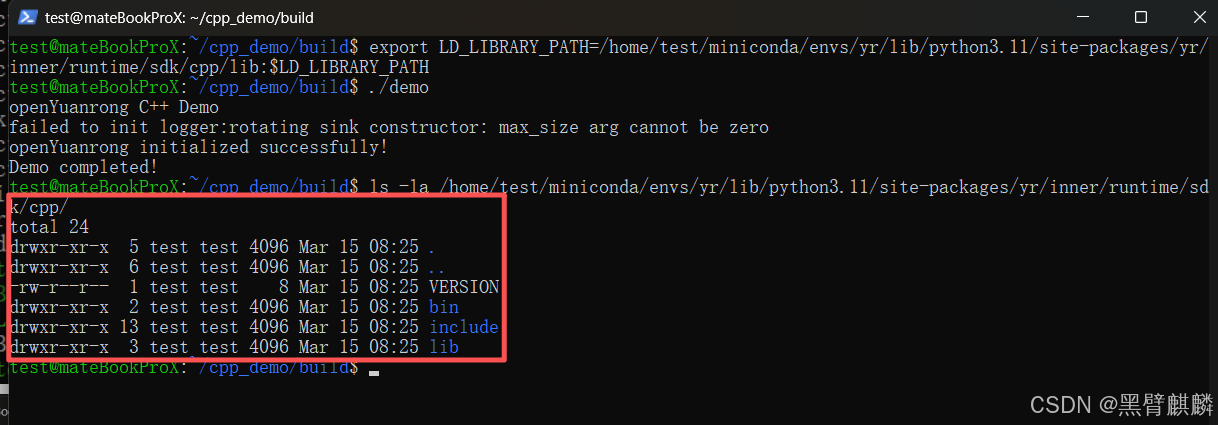
Java SDK 部署教程
bash
# 查看 Java SDK 文件
ls -la /home/test/miniconda/envs/yr/lib/python3.11/site-packages/yr/inner/runtime/sdk/java/
bash
# 创建 Java 项目
mkdir -p ~/java_demo
cd ~/java_demo
bash
# 创建 Java 源文件
mkdir -p src/main/java/demo
cat > src/main/java/demo/Demo.java << 'EOF'
package demo;
import org.yuanrong.YR;
import org.yuanrong.Config;
public class Demo {
public static void main(String[] args) {
System.out.println("openYuanrong Java Demo");
// 配置本地模式
Config config = new Config();
config.setMode(Config.Mode.LOCAL_MODE);
// 初始化
YR.init(config);
System.out.println("openYuanrong initialized successfully!");
// 清理
YR.finalize();
System.out.println("Demo completed!");
}
}
EOF我这里用的nano,你们用linux也可以
bash
# 设置 SDK 路径
SDK_PATH=/home/test/miniconda/envs/yr/lib/python3.11/site-packages/yr/inner/runtime/sdk/java
# 编译
javac -cp $SDK_PATH/yr-api-sdk-0.7.0.jar:$SDK_PATH/faas-function-sdk-0.7.0.jar \
src/main/java/demo/Demo.java
# 运行
java -cp $SDK_PATH/yr-api-sdk-0.7.0.jar:$SDK_PATH/faas-function-sdk-0.7.0.jar:src/main/java demo.Demo三种语言 SDK 对比
| 特性 | Python SDK | C++ SDK | Java SDK |
|---|---|---|---|
| 形式 | Python 模块 + .so 库 | 头文件 + 动态库 | JAR 包 |
| 大小 | 约 100MB | 97MB | 15MB |
| 安装方式 | pip install |
CMake 链接 | Maven 依赖 |
| 初始化 | yr.init() |
YR::Init() |
YR.init() |
openYuanrong 拓扑感知调度:提升函数运行时性能
一、什么是拓扑感知调度
1. NUMA 架构基础
现代多核服务器通常采用 NUMA(Non-Uniform Memory Access) 架构,即"非统一内存访问"架构。
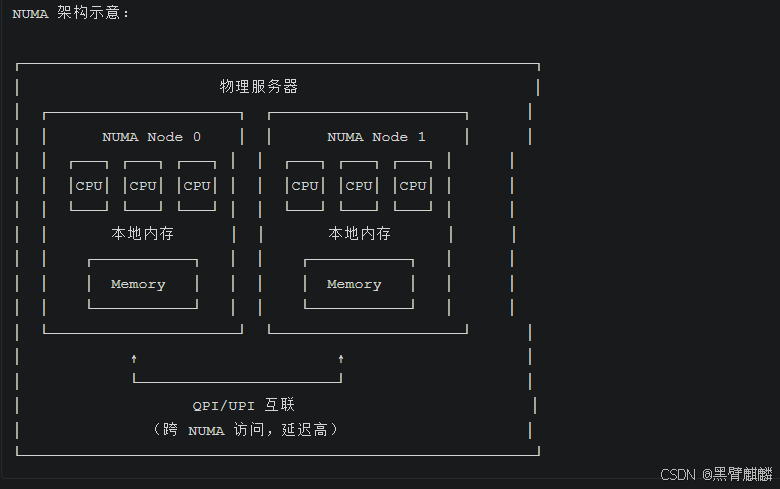
核心特点:
- 每个 NUMA 节点有自己的本地内存
- 访问本地内存速度快
- 跨 NUMA 访问内存速度慢(延迟高 2-3 倍)
2. 拓扑层级
openYuanrong 支持多级拓扑感知:
3. 为什么需要拓扑感知调度
问题场景:

二、openYuanrong 的拓扑感知调度
| 层级 | 说明 | 示例 |
|---|---|---|
| Node | NUMA 节点 | node0, node1 |
| Socket | CPU 插槽 | socket0, socket1 |
| Core | 物理核心 | core0 - core19 |
| L1/L2/L3 Cache | 缓存层级 | 共享或独立 |
1. 调度亲和性 API
openYuanrong 提供了丰富的调度亲和性 API:
bash
from yr.affinity import (
Affinity,
AffinityKind,
AffinityType,
AffinityScope,
LabelOperator,
OperatorType
)亲和性类型:
| 类型 | 说明 | 使用场景 |
|---|---|---|
| PREFERRED | 优先满足 | 尽量调度到指定节点 |
| REQUIRED | 必须满足 | 必须调度到指定节点 |
| PREFERRED_ANTI | 优先避开 | 尽量避开指定节点 |
| REQUIRED_ANTI | 必须避开 | 必须避开指定节点 |
亲和性作用域:
| 作用域 | 说明 |
|---|---|
| POD | POD 级别实例亲和 |
| NODE | NODE 级别实例亲和 |
2. 使用示例
示例 1:优先调度到特定 NUMA 节点
bash
import yr
from yr.affinity import (
Affinity, AffinityKind, AffinityType,
LabelOperator, OperatorType
)
# 初始化
yr.init()
# 创建拓扑亲和性
affinity = Affinity(
affinity_kind=AffinityKind.RESOURCE,
affinity_type=AffinityType.PREFERRED,
label_operators=[
LabelOperator(OperatorType.LABEL_IN, "numa_node", ["node0"])
]
)
# 定义分布式函数
@yr.invoke(affinities=[affinity])
def compute(data):
return data * 2
# 调用
result = compute.invoke(10)
value = yr.get(result)
print(f"Result: {value}")
# 清理
yr.finalize()
结果:

示例 2:必须调度到有 GPU 的节点
bash
import yr
from yr.affinity import (
Affinity, AffinityKind, AffinityType,
LabelOperator, OperatorType
)
yr.init()
# 标签存在:gpu
gpu_affinity = Affinity(
affinity_kind=AffinityKind.RESOURCE,
affinity_type=AffinityType.REQUIRED,
label_operators=[
LabelOperator(OperatorType.LABEL_EXISTS, "gpu", [])
]
)
@yr.invoke(affinities=[gpu_affinity])
def gpu_compute(data):
# GPU 计算任务
return process_on_gpu(data)运行结果:
示例 3:实例亲和(函数间通信优化)
bash
import yr
from yr.affinity import (
Affinity, AffinityKind, AffinityType,
LabelOperator, OperatorType, AffinityScope
)
yr.init()
# 让多个函数实例运行在同一节点,减少网络通信
instance_affinity = Affinity(
affinity_kind=AffinityKind.INSTANCE,
affinity_type=AffinityType.PREFERRED,
label_operators=[
LabelOperator(OperatorType.LABEL_EXISTS, "same_node", [])
],
affinity_scope=AffinityScope.NODE
)
@yr.invoke(affinities=[instance_affinity])
def process(data):
return data
这个是三个示例的全部结果。
python affinity_demo.py → Result: 20
python gpu_affinity_demo.py → Result: 20
python instance_affinity_demo.py → Result: 20总结
多语言运行时独立部署
openYuanrong 的多语言运行时独立部署方案,通过库集成的设计理念,有效解决了传统 Serverless 架构的痛点:
| 对比项 | 传统 Serverless | openYuanrong |
|---|---|---|
| 架构复杂度 | 多进程协作 | 单进程集成 |
| 通信开销 | IPC + 序列化 | 零开销 |
| 运维门槛 | 高(需管理运行时) | 低(SDK 随程序启动) |
| 冷启动延迟 | 毫秒~秒级 | 微秒级 |
| 部署方式 | 容器/VM | 库依赖 |
核心优势:
- 零通信开销 - 函数调用直接在进程内完成,无需序列化/反序列化
- 简化运维 - SDK 随用户程序一起启动和停止,无需管理独立进程
- 多语言支持 - Python、C++、Java 三种 SDK,满足不同开发需求
- 轻量部署 - Python 约 100MB、C++ 97MB、Java 仅 15MB
这种设计特别适合:
- 高性能计算(HPC):需要低延迟的函数调用
- 边缘计算:资源受限,需要轻量级部署
- 企业应用:希望简化运维复杂度的场景
拓扑感知调度
openYuanrong 的拓扑感知调度功能,通过感知底层硬件拓扑结构,智能地将函数调度到最优的计算节点:
| 优化点 | 效果 |
|---|---|
| 减少跨 NUMA 内存访问 | 降低内存延迟 |
| 提升缓存命中率 | 提高计算效率 |
| 减少网络通信 | 降低函数间调用延迟 |
核心特性:
- 多级拓扑感知 - 支持 Node、Socket、NUMA node 等层级
- 灵活的亲和性配置 - PREFERRED/REQUIRED/PREFERRED_ANTI/REQUIRED_ANTI 四种类型
- 多种作用域 - 支持 POD 级别和 NODE 级别实例亲和
- 多语言 API - Python 和 C++ 均提供完整的调度亲和性 API
适用场景:
| 场景 | 推荐配置 |
|---|---|
| HPC 高性能计算 | 绑定到特定 NUMA 节点(REQUIRED) |
| AI 推理 | 调度到有 GPU 的节点(REQUIRED + LABEL_EXISTS) |
| 大数据处理 | 函数和数据在同一节点(INSTANCE + NODE 作用域) |
| 微服务 | 服务间频繁通信,部署在同一节点(INSTANCE + PREFERRED) |
这对于 HPC 高性能计算、AI 推理、大数据处理 等场景尤为重要,可以显著提升函数运行时性能