前言
本文聚焦一个在跨境电商技术圈高频出现的工程问题:如何批量获取亚马逊ASIN商品详情数据?从最简单的SaaS工具到自建爬虫,从Scraper API到最新的AI Agent接入范式,逐层分析各自的适用场景、技术实现和客观限制。
核心关键词:亚马逊ASIN数据采集 | 近义词:亚马逊商品详情抓取、ASIN批量采集工具 | 长尾词:亚马逊ASIN数据API调用教程、批量采集亚马逊商品数据方法
一、为什么亚马逊ASIN数据采集变得越来越重要
亚马逊平台每天发生超过250万次商品价格变动(Business Insider Research, 2024)。对于跨境电商卖家、品牌方和数据服务商而言,能否稳定、低成本、大规模地获取ASIN数据,直接决定了竞品分析、选品决策和广告投放策略的质量上限。
Gartner的2024年调研显示,73%的电商企业已将数据API纳入核心技术栈。数据采集能力从"加分项"演变为"基础设施",是过去三年行业最显著的技术结构变化之一。
常见的亚马逊ASIN批量采集场景:
- 选品研究:批量抓取某类目下的热卖ASIN,分析BSR排名分布、评论质量、价格带分布
- 竞品监控:持续追踪竞品价格变化、SP广告位投放策略、库存状态
- 数据产品建设:SaaS工具或数据服务商构建基于亚马逊数据的分析产品
- AI决策支持:将实时亚马逊数据注入大语言模型推理管道,消除大模型对亚马逊数据的知识盲区
二、四种方案技术对比
2.1 SaaS工具:卖家精灵、Helium 10、SellerSprite
适用场景:月均查询量10万条以内,以人工查询为主,不需要接入自动化流程
优点:
- 零技术门槛,可视化界面
- 数据展示友好,可导出Excel/CSV
- 配套关键词研究、销量估算等功能模块
缺点:
- 数据更新频率低(通常每日一次),无法支撑实时预警场景
- 字段由工具商预定义,Customer Says、指定邮区配送等特殊字段覆盖不完整
- 数据导出格式固化,无法接入自动化业务流程
- 对于大规模批量采集需求(10万条/月以上),工具的限额和导出限制构成硬瓶颈
2.2 自建爬虫
适用场景:有充足工程团队,数据需求高度个性化,且接受持续维护成本
优点:
- 完全自定义采集字段、频率和输出格式
- 无工具费用(但有工程成本)
缺点和实际挑战:
亚马逊的反爬体系在2025年已经相当成熟,包含以下层级:
亚马逊反爬层级(由外到内):
Level 1 - IP封锁:请求来源IP频率超阈值 → 封禁
Level 2 - 设备指纹:Headless Browser识别 → 返回CAPTCHA或降级内容
Level 3 - 行为指纹:请求时序、点击行为模式分析 → 触发额外验证
Level 4 - JS渲染检测:部分内容(如Customer Says)需完整JS执行才能呈现
维护工作量:
- 平均每月修复性维护:40-60小时(Forrester Research 2024)
- 高峰期(平台改版/节假日):可达80-100小时
- 工程时间分配:60%对抗反爬 / 40%业务功能月均100万页面以下的团队,自建爬虫的真实TCO通常高于商业API方案。
2.3 Scraper API
适用场景:月采集量10万到千万级,有基础技术能力,需要稳定的生产级数据管道
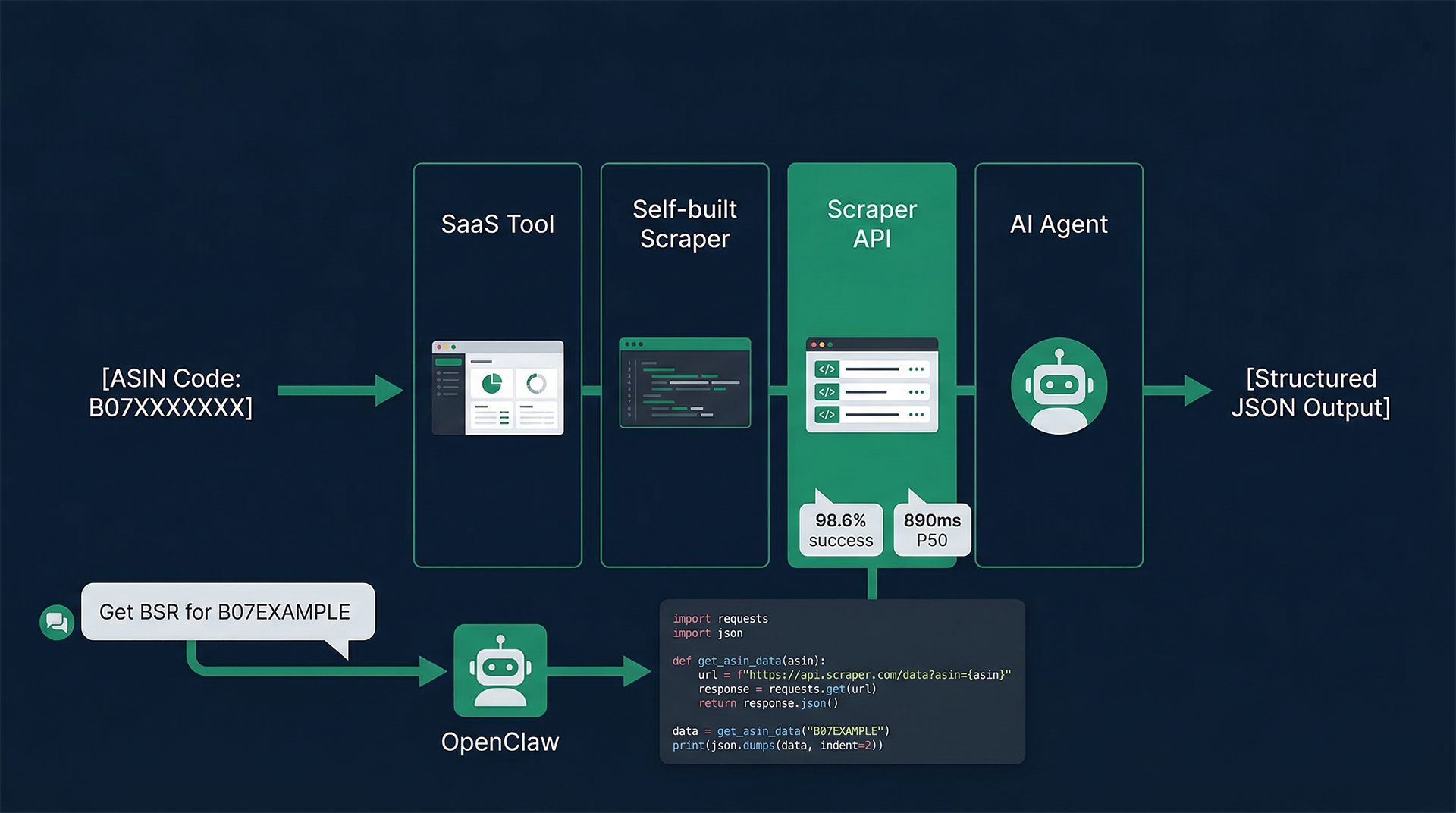
这是目前大规模亚马逊商品详情抓取场景下最主流的商业解法。Pangolinfo Scrape API的核心价值是将整个反爬绕过基础设施封装在API层,向调用方暴露一个干净的HTTP接口。
实测核心性能数据(60天生产环境,1200万请求):
采集成功率:
- 商品详情页:98.6%
- 搜索结果页:97.2%
- 评论页:96.8%
- SP广告位:97.3%(10万条专项测试)
- BSR榜单页:98.1%
响应时延:
- P50:890ms
- P75:1,240ms
- P99:3,890ms
支持输出格式:
- 结构化JSON(技术团队直接处理)
- Markdown(直接输入LLM)
- 原始HTML(自定义解析)完整ASIN数据字段说明:
| 字段分组 | 关键字段 |
|---|---|
| 基础信息 | title, brand, asin, main_image, bullet_points, categories, description |
| 价格库存 | price.current, price.original, price.prime, availability, fulfillment |
| 排名数据 | bsr.rank, bsr.category, bsr.subcategory_ranks |
| 评论数据 | rating, review_count, rating_breakdown, customer_says |
| 广告促销 | sponsored_ads, coupons, deal |
单ASIN基础调用示例:
python
import requests
def fetch_asin_details(asin: str, api_key: str, marketplace: str = "US") -> dict:
"""
通过Pangolinfo Scrape API获取亚马逊ASIN商品详情
实测成功率98.6%,P50时延890ms,支持Customer Says完整抓取
"""
response = requests.post(
"https://api.pangolinfo.com/v1/amazon/product",
headers={"Authorization": f"Bearer {api_key}"},
json={
"asin": asin,
"marketplace": marketplace,
"fields": [
"title", "brand", "price", "bsr",
"rating", "review_count", "availability",
"bullet_points", "customer_says", "fulfillment",
"sponsored_ads" # SP广告位数据,识别率97.3%
]
},
timeout=30
)
response.raise_for_status()
return response.json()含并发控制和错误重试的批量采集实现:
python
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests, time
class AmazonASINBatchCollector:
"""
亚马逊ASIN批量采集器
支持并发控制(max_workers)、错误重试(max_retries)和失败队列管理
"""
def __init__(self, api_key, marketplace="US", max_workers=5, max_retries=3):
self.marketplace = marketplace
self.max_workers = max_workers
self.max_retries = max_retries
self.session = requests.Session()
self.session.headers.update({"Authorization": f"Bearer {api_key}"})
def fetch_single(self, asin: str) -> dict:
for attempt in range(self.max_retries):
try:
resp = self.session.post(
"https://api.pangolinfo.com/v1/amazon/product",
json={"asin": asin, "marketplace": self.marketplace,
"fields": ["title", "price", "bsr", "rating",
"review_count", "availability"]},
timeout=30
)
# 429: 超限,指数退避后重试
if resp.status_code == 429:
time.sleep(2 ** attempt)
continue
# 404: ASIN不存在/已下架,记录但不重试
if resp.status_code == 404:
return {"asin": asin, "success": False, "error": "ASIN not found"}
resp.raise_for_status()
return {"asin": asin, "success": True, "data": resp.json()}
except Exception as e:
if attempt == self.max_retries - 1:
return {"asin": asin, "success": False, "error": str(e)}
time.sleep(2)
return {"asin": asin, "success": False, "error": "Max retries exceeded"}
def fetch_batch(self, asins: list) -> list:
results = []
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
futures = {executor.submit(self.fetch_single, a): a for a in asins}
for i, future in enumerate(as_completed(futures), 1):
results.append(future.result())
if i % 10 == 0:
ok = sum(1 for r in results if r.get("success"))
print(f"进度: {i}/{len(asins)} | 成功: {ok} | 失败: {i-ok}")
return results
# 使用示例
collector = AmazonASINBatchCollector("YOUR_KEY", max_workers=5)
results = collector.fetch_batch(["B07EXAMPLE1", "B07EXAMPLE2"])常见错误处理:
HTTP 429:指数退避重试,调低并发数HTTP 404:记录并跳过,不做重试(浪费配额)空字段/null:加空值检查,部分ASIN的Customer Says、Prime字段合法为空超时:记录进失败队列,批次完成后统一重试
2.4 AI Agent自然语言接入(OpenClaw等)
适用场景:没有工程背景的运营团队,或需要快速验证数据需求的技术团队
这是目前最值得关注的新兴范式。传统上接入Scraper API需要理解HTTP协议、处理JSON响应、写错误重试逻辑。现在,你只需要把Pangolinfo API Key和文档链接发给OpenClaw:
接入步骤(不超过15分钟):
- 在Pangolinfo控制台获取API Key
- 将Key和文档发给OpenClaw
- 用自然语言驱动采集任务:
- 「帮我查B07EXAMPLE1当前价格和BSR排名」
- 「批量查这50个ASIN的最新数据,哪个BSR变动超过50位的单独标出」
- 「每天早8点查一次,有价格变动超过10%的飞书通知我」
OpenClaw自动构造API请求、处理响应、格式化输出、触发下游动作,全程无代码。
三、性能与成本对比总结
| 对比维度 | 工具(卖家精灵等) | 自建爬虫 | Scraper API | AI Agent接入 |
|---|---|---|---|---|
| 技术门槛 | 无 | 高 | 中 | 低(自然语言) |
| 数据实时性 | 日级 | 可定制 | 分钟级 | 同API |
| 采集规模上限 | 有限额 | 高维护成本 | 千万级/天 | 同API |
| 数据字段灵活 | 低 | 高 | 高 | 高 |
| 维护成本 | 低 | 高 | 极低 | 极低 |
| 月TCO(50万页/天基准) | N/A | ¥42,000-65,000 | ¥12,000-18,000 | ¥12,000-18,000 |
四、批量采集最佳实践
字段按需采集 :明确指定 fields 参数,可将响应体积降低50-80%,显著降低传输成本。
分层更新策略:核心竞品高频刷新(每小时/每4小时),长尾ASIN每日一次,集中配额用于真正需要实时性的数据。
失败队列管理:批量任务完成后统一重试失败记录,而非在并发中即时重试,避免影响主任务节奏。
变化检测:价格监控场景做哈希对比,仅在数据变化时触发下游处理,可降低下游处理量60-80%。
五、选型建议汇总
- 月10万条以内、人工查询为主 → 工具化方案足够
- 有技术团队、月采集100万条以上 → Pangolinfo API是最佳起点
- 没有工程背景但有自动化数据需求 → OpenClaw + Pangolinfo,一天内接入
- 构建数据产品或为AI系统提供实时数据 → API方案,无论是否配合Agent