一、双向链表
链式存储结构的节点中只有一个指示直接后继的指针域,由此,从某个结点出发只能顺指针向后寻查其他节点。若要寻查结点的直接前驱、则必须从表头指针出发。换句话说,在单链表中,查找直接后继的执行时间为〇(1),而查找直接前驱的执行时间为 O(n)为克服单链表这种单向性的缺点,可利用双向链表(Double Linked List)。 在双向链表的节点中有两个指针域,一个指向直接后继,另一个指向直接前驱。
二、双向链表结构与初始化
cpp
#include <stdio.h>
#include <stdlib.h>
// 定义链表存储的数据类型为int
typedef int ElemType;
// 定义双向链表节点结构
typedef struct node {
ElemType data; // 数据域
struct node *next; // 后继指针,指向后一个节点
struct node *prev; // 前驱指针,指向前一个节点
} Node;
/**
* 初始化双向链表(带头节点)
* 返回值:指向头节点的指针
*/
Node* initList() {
// 动态分配头节点内存
Node *head = (Node*)malloc(sizeof(Node));
if (head == NULL) { // 内存分配失败判断
printf("内存分配失败!\n");
exit(1);
}
head->data = 0; // 头节点数据域可忽略,一般不存储有效数据
head->next = NULL; // 后继指针初始化为空
head->prev = NULL; // 前驱指针初始化为空
return head;
}三、头插法核心代码(重点)
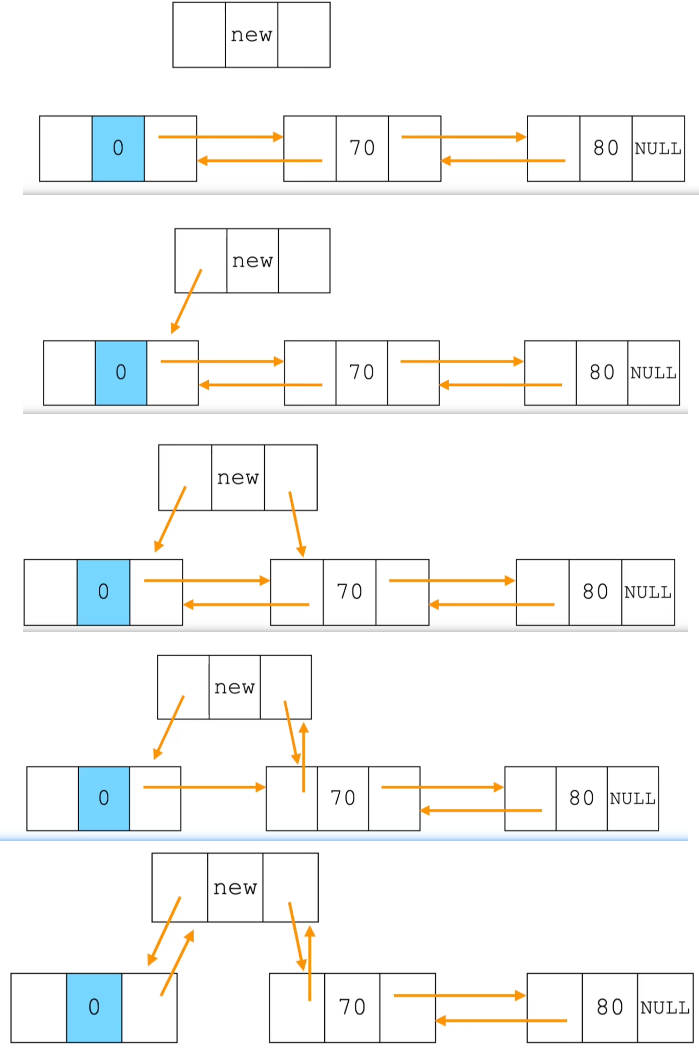
cpp
/**
* 双向链表头插法(在头节点后插入新节点)
* 参数 L:链表头节点指针
* 参数 e:待插入的数据
* 返回值:1表示插入成功
*/
int insertHead(Node* L, ElemType e) {
// 1. 为新节点分配内存
Node *p = (Node*)malloc(sizeof(Node));
if (p == NULL) {
printf("内存分配失败!\n");
exit(1);
}
// 2. 给新节点赋值
p->data = e; // 新节点数据域 = 待插入数据
p->prev = L; // 新节点的前驱 = 头节点
p->next = L->next; // 新节点的后继 = 原头节点的后继节点
// 3. 如果原链表不为空(头节点后有节点),需要修改原第一个节点的前驱指针
if (L->next != NULL) {
L->next->prev = p; // 原第一个节点的前驱 = 新节点
}
// 4. 头节点的后继指针指向新节点(完成插入)
L->next = p;
return 1; // 插入成功
}头插法核心思想:
-
新节点搭桥:先让新节点
p连接到链表结构中(p->prev指向头节点,p->next指向原第一个节点)。 -
旧节点修正:如果原链表不为空,要让原第一个节点的
prev指针指向新节点,保证双向链接完整。 -
头节点挂接:最后让头节点
L的next指针指向新节点,完成 "插入到最前面" 的操作。 -
顺序关键:必须先处理新节点的指针 ,再修改原有节点的指针 ,否则会丢失原链表的引用。
三、遍历链表代码
cpp
/**
* 遍历并打印双向链表(从第一个有效节点开始)
* 参数 L:链表头节点指针
*/
void listNode(Node* L) {
Node *p = L->next; // 从第一个有效节点开始遍历(跳过头节点)
while (p != NULL) { // 遍历到链表末尾
printf("%d ", p->data); // 打印当前节点数据
p = p->next; // 指针后移
}
printf("\n"); // 遍历结束后换行
}四、完整可运行代码(含主函数测试)
cpp
#include <stdio.h>
#include <stdlib.h>
typedef int ElemType;
typedef struct node {
ElemType data;
struct node *next;
struct node *prev;
} Node;
// 初始化链表
Node* initList() {
Node *head = (Node*)malloc(sizeof(Node));
if (head == NULL) {
printf("内存分配失败!\n");
exit(1);
}
head->data = 0;
head->next = NULL;
head->prev = NULL;
return head;
}
// 头插法插入节点
int insertHead(Node* L, ElemType e) {
Node *p = (Node*)malloc(sizeof(Node));
if (p == NULL) {
printf("内存分配失败!\n");
exit(1);
}
p->data = e;
p->prev = L;
p->next = L->next;
if (L->next != NULL) {
L->next->prev = p;
}
L->next = p;
return 1;
}
// 遍历链表
void listNode(Node* L) {
Node *p = L->next;
while (p != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}
// 主函数:测试双向链表头插法
int main() {
// 1. 初始化链表
Node *list = initList();
// 2. 头插法插入数据(注意:头插法会让数据逆序存储)
insertHead(list, 10);
insertHead(list, 20);
insertHead(list, 30);
// 3. 遍历打印链表
printf("链表元素:");
listNode(list); // 输出:30 20 10
return 0;
}五、运行结果说明
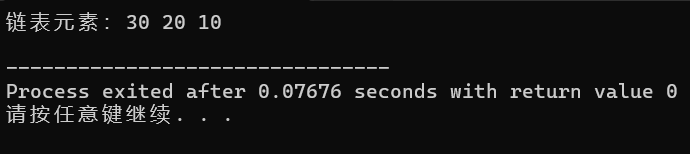
因为头插法是将新节点插入到链表最前面 ,所以先插入的 10 会被后插入的 20、30 依次挤到后面,最终遍历顺序是 30 → 20 → 10。
六、补充:双向循环链表改造
如果要改成双向循环链表,只需要在初始化和插入时做两处修改:
- 初始化时:
head->next = head; head->prev = head; - 头插法中:将
NULL判断改为!= head,并保证最后一个节点的next指向头节点、头节点的prev指向最后一个节点