目录
[1 NoSQL](#1 NoSQL)
[2 Redis](#2 Redis)
[2.1 Redis 特征](#2.1 Redis 特征)
[2.2 Redis安装](#2.2 Redis安装)
[2.3 Redis客户端](#2.3 Redis客户端)
[2.3.1 Redis命令行客户端](#2.3.1 Redis命令行客户端)
[2.3.2 图形化桌面客户端](#2.3.2 图形化桌面客户端)
[3 Redis数据结构及通用命令](#3 Redis数据结构及通用命令)
[3.1 通用命令](#3.1 通用命令)
[3.2 String](#3.2 String)
[3.3 Hash(键值对)](#3.3 Hash(键值对))
[3.4 List(有序、可重复)](#3.4 List(有序、可重复))
[3.5 Set(无序、不可重复)](#3.5 Set(无序、不可重复))
[3.6 SortedSet(有序、不重复)](#3.6 SortedSet(有序、不重复))
[4 Redis的Java客户端](#4 Redis的Java客户端)
[4.1 Jedis](#4.1 Jedis)
[4.2 Spring Data Redis](#4.2 Spring Data Redis)
[4.3 RedisTemplate 的两种序列化实践方案](#4.3 RedisTemplate 的两种序列化实践方案)
1 NoSQL
| 比较维度 | SQL(关系型数据库) | NoSQL(非关系型数据库) |
|---|---|---|
| 全称 | Structured Query Language 结构化查询语言 | Not Only SQL |
| 数据结构 | 结构化:表结构数据库,像 Excel 表格。有行、列、字段类型严格固定。 | 非结构化 / 半结构化(如 Redis 键值类型) |
| 数据关系 | 表与表有关系,强关联 | 无关联 |
| 操作语言 | 用统一的 SQL 语句操作 | 非 SQL |
| 事务 | ACID(强事务 / 无事务) | BASE(弱事务 / 无事务) |
| 存储位置 | 硬盘(磁盘)为主,持久化存储 | 内存(快) + 硬盘(如 Redis 常用内存,MongoDB 用硬盘) |
| 核心优势 | 安全、准确、支持复杂查询 | 快、高并发、结构灵活 |
| 适合场景 | 银行、订单、用户账户、必须保证数据 100% 准确 | 高并发、大数据量、缓存、日志、用户行为、聊天记录 |
| 选择口诀 | 要安全、要准确、要关联 → 选 SQL | 要快、要高并发、要灵活 → 选 NoSQL |
2 Redis
Redis = REmote DIctionary Server
远程字典服务器
基于内存 的 NoSQL 键值(Key-Value)数据库
2.1 Redis 特征
- 纯内存操作 → 速度极快
- Key-Value 型数据库(value支持多种数据结构)
- 单线程 + IO 多路复用 → 高并发、无锁竞争
- 支持数据持久化(定期写入磁盘、安全)
- 非关系型、无表结构、无关联
2.2 Redis安装
Redis安装在Linux虚拟机上,此处用的CentOS7,流程如下:
-
打开 VMware(虚拟机软件) → 启动虚拟电脑
-
虚拟电脑里跑着 CentOS (Linux操作系统)
-
打开 FinalShell(SSH 工具,用于远程连接、管理Linux) → 连接 CentOS → 开始操作 Linux
//Redis是基于C语言编写的,因此首先需要安装Redis所需要的gcc依赖
yum install -y gcc tcl//Redis安装包上传到虚拟机的/usr/local/src 目录,解压缩
cd /usr/local/src
tar -xzf redis-6.2.6.tar.gz//进入redis目录
cd redis-6.2.6//运行编译、安装命令
make && make install//默认的安装路径是在 /usr/local/bin目录下,可以进入目录查看一下
cd /usr/local/bin
ll
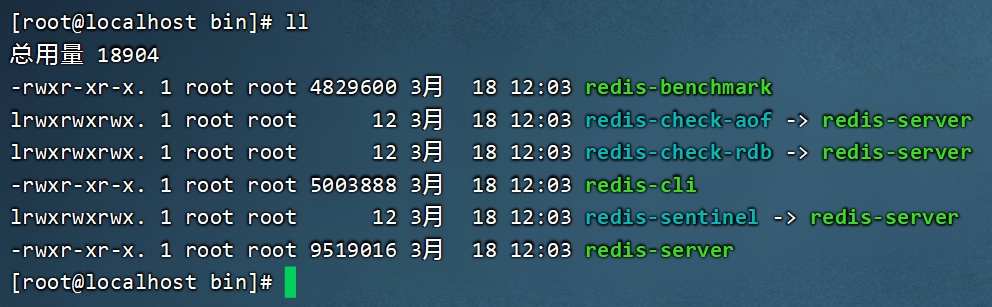
安装完成后,在任意目录输入redis-server命令即可启动Redis(第一种启动方式),但前台启动会阻塞整个会话窗口:
redis-server指定配置启动(第二种启动方式):修改Redis配置文件,就在我们之前解压的redis安装包下,名字叫redis.conf,可修改为后台启动,同时可以配置更多信息,比如log等等。
开机自启(第三种启动方式):
vi /etc/systemd/system/redis.service
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.6/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis执行下面的命令,可以让redis开机自启:
systemctl enable redis2.3 Redis客户端
2.3.1 Redis命令行客户端
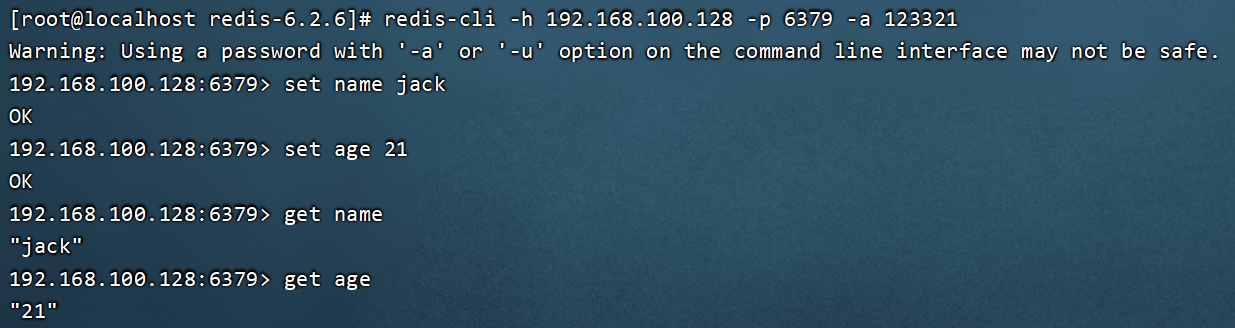
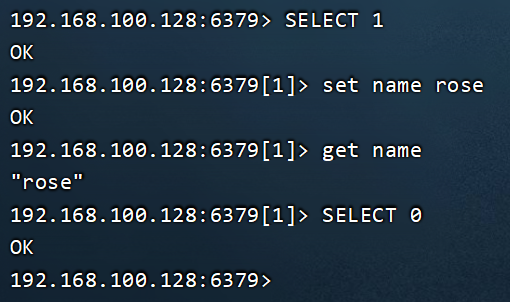
redis-cli [options] [commonds]- h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1
- p 6379:指定要连接的redis节点的端口,默认是6379
- a 123321:指定redis的访问密码
ping:与redis服务端做心跳测试,服务端正常会返回pong.

2.3.2 图形化桌面客户端
Redis的图形化桌面客户端,地址:https://github.com/uglide/RedisDesktopManager
在下面这个仓库可以找到安装包:https://github.com/lework/RedisDesktopManager-Windows/releases
若连接不成功,注意开放6379端口。
# 开放 6379 端口
firewall-cmd --permanent --add-port=6379/tcp
# 重新加载防火墙规则
firewall-cmd --reload
# 验证端口是否开放
firewall-cmd --list-ports
3 Redis数据结构及通用命令
| 数据结构 | 示例数据 | 典型应用场景 |
|---|---|---|
| String | hello world | 缓存、计数器、分布式锁、Session 存储 |
| Hash | {name: "Jack", age: 21} | 用户信息、商品详情、配置项 |
| List | A -\> B -\> C -\> C | 消息队列、评论列表、栈 / 队列 |
| Set | {A, B, C} | 去重、点赞 / 收藏、共同好友、抽奖 |
| SortedSet(ZSet) | {A: 1, B: 2, C: 3} | 排行榜、热搜榜、优先级队列 |
| GEO | {A: (120.3, 30.5)} | 附近的人、地址检索、路线规划 |
| BitMap | 0110110101110101011 | 签到统计、用户活跃状态、布隆过滤器 |
| HyperLogLog | 0110110101110101011 | UV 统计、独立访客数、海量数据去重计数 |
String、Hash、List、Set、SortedSet 是 Redis 最核心、最常用的 5 种数据结构,后三种只适合特殊场景。
3.1 通用命令
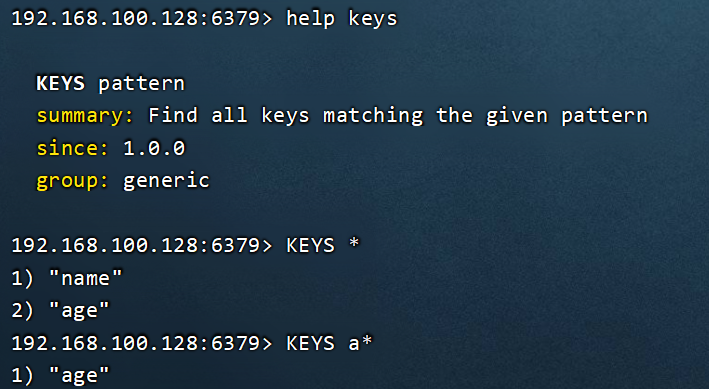
命令写法查看:https://redis.io/docs/latest/commands/
命令行查看:help command,比如:help keys
| 命令 | 功能描述 | 重要说明 / 示例 |
|---|---|---|
| KEYS | 查看所有符合给定模式的 key | ⚠️不建议在生产环境使用,会阻塞 Redis 主线程(因为单线程)遍历所有键,性能极差。 示例:KEYS user* |
| DEL | 删除一个或多个指定的 key | 成功删除返回删除数量,key 不存在返回 0。 示例:DEL name age |
| EXISTS | 判断一个或多个 key 是否存在 | 存在返回 1,不存在返回 0;多个 key 时返回存在的数量。 示例:EXISTS name |
| EXPIRE | 为指定 key 设置过期时间(秒),到期后自动删除 | 成功设置返回 1,key 不存在或设置失败返回 0。 示例:EXPIRE name 60(60 秒后过期) |
| TTL | 查看指定 key 的剩余存活时间(秒) | 返回值:正数 = 剩余秒数;-1= 永不过期;-2=key 不存在 / 已过期。 示例:TTL name |
3.2 String
string、int、float
| 命令 | 功能描述 | 示例 |
|---|---|---|
| SET | 添加或修改一个 String 类型的键值对 | SET name "Jack" |
| GET | 根据 key 获取对应的 String 类型 value | GET name → 返回 "Jack" |
| MSET | 批量添加多个 String 类型的键值对 | MSET age 21 city "Beijing" gender "male" |
| MGET | 根据多个 key 批量获取对应的 value | MGET name age city → 返回 "Jack", "21", "Beijing" |
| INCR | 让一个整型 key 的值自增 1 | INCR count → 若 count 为 5,执行后变为 6 |
| INCRBY | 让一个整型 key 的值按指定步长自增 | INCRBY num 2 → 若 num 为 3,执行后变为 5 |
| INCRBYFLOAT | 让一个浮点类型 key 的值按指定步长自增,浮点型自增必须设置步长 | INCRBYFLOAT price 0.5 → 若 price 为 10.0,执行后变为 10.5 |
| SETNX | SET Not Exist 仅当 key 不存在时,添加一个 String 类型键值对(不存在才设置) | SETNX lock "true" → 若 lock 不存在则设置成功,返回 1;若已存在则返回 0 |
| SETEX | SET EXpire 添加一个 String 类型键值对,并指定过期时间(秒) | SETEX token 300 "abc123" → token 会在 300 秒后自动过期删除 |
KEY的层级结构 :用户模块用 id:1,商品模块也用 id:1,此时会产生冲突。因此用 冒号 : 分隔,模拟目录层级,让 Key 分类清晰、易管理、不冲突。
192.168.100.128:6379> SET heima:user:1 '{"id":1, "name":"Jack", "age": 21}'
OK
192.168.100.128:6379> SET heima:user:2 '{"id":2, "name":"Rose", "age": 18}'
OK
192.168.100.128:6379> SET heima:product:1 '{"id":1, "name":"小米11", "price": 4999}'
OK
192.168.100.128:6379> SET heima:product:2 '{"id":2, "name":"荣耀6", "price": 2999}'
OK
192.168.100.128:6379> KEYS heima:*
1) "heima:product:2"
2) "heima:user:1"
3) "heima:user:2"
4) "heima:product:1"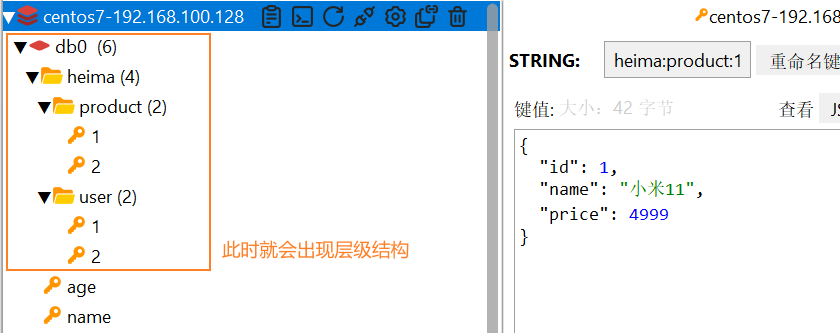
3.3 Hash(键值对)
String 存储对象的痛点
将对象序列化为 JSON 字符串存入 String 类型时:heima:user:1 → {name:"Jack", age:21}
修改单个字段极不方便!!!需要先取出整个 JSON、反序列化、修改、再序列化存回。
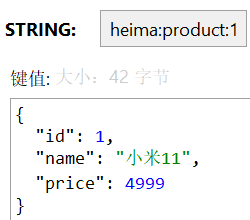
Hash 结构将对象的每个字段独立存储为 field-value:

优势:可以针对单个字段做 CRUD,无需操作整个对象,更高效、更灵活。
| 命令 | 功能描述 | 示例 |
|---|---|---|
| HSET | 添加或者修改 hash 类型 key 的 field 的值 | HSET heima:user:1 name Jack |
| HGET | 获取一个 hash 类型 key 的 field 的值 | HGET heima:user:1 name |
| HMSET | 批量添加多个 hash 类型 key 的 field 的值 | HMSET heima:user:1 name Jack age 21 |
| HMGET | 批量获取多个 hash 类型 key 的 field 的值 | HMGET heima:user:1 name age |
| HGETALL | 获取一个 hash 类型的 key 中的所有的 field 和 value | HGETALL heima:user:1 |
| HKEYS | 获取一个 hash 类型的 key 中的所有的 field | HKEYS heima:user:1 |
| HVALS | 获取一个 hash 类型的 key 中的所有的 value | HVALS heima:user:1 |
| HINCRBY | 让一个 hash 类型 key 的字段值自增并指定步长 | HINCRBY heima:user:1 age 1 |
| HSETNX | 添加一个 hash 类型的 key 的 field 值,前提是这个 field 不存在,否则不执行 | HSETNX heima:user:1 gender male |
192.168.100.128:6379> HMSET heima:user:3 name Lilei age 21
OK
192.168.100.128:6379> HMGET heima:user:3 name age
1) "Lilei"
2) "21"
192.168.100.128:6379> HGETALL heima:user:3
1) "name"
2) "Lilei"
3) "age"
4) "21"
192.168.100.128:6379> HKEYS heima:user:3
1) "name"
2) "age"
192.168.100.128:6379> HVALS heima:user:3
1) "Lilei"
2) "21"
192.168.100.128:6379> HSET heima:user:3 age 24
(integer) 0
192.168.100.128:6379> HVALS heima:user:3
1) "Lilei"
2) "24"3.4 List(有序、可重复)
List 双向链表,支持正向 / 反向检索。
核心特征:有序、可重复、插入 / 删除极快、查询速度一般(遍历链表)。
| 命令 | 功能描述 | 示例 |
|---|---|---|
| LPUSH key element | 向列表左侧插入一个或多个元素 | LPUSH users 1 2 3 |
| LPOP key | 移除并返回列表左侧的第一个元素,没有则返回 nil | LPOP users |
| RPUSH key element | 向列表右侧插入一个或多个元素 | RPUSH users 4 5 6 |
| RPOP key | 移除并返回列表右侧的第一个元素 | RPOP users |
| LRANGE key start stop | 返回一段角标范围内的所有元素 | LRANGE users 0 5 |
| BLPOP key timeout | 与 LPOP 类似,在没有元素时等待指定时间,而非直接返回 nil | BLPOP users 5 |
| BRPOP key timeout | 与 RPOP 类似,在没有元素时等待指定时间,而非直接返回 nil | BRPOP users 5 |
192.168.100.128:6379> LPUSH users 1 2 3
(integer) 3
192.168.100.128:6379> RPUSH users 4 5 6
(integer) 6
192.168.100.128:6379> LRANGE users 0 5
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
6) "6"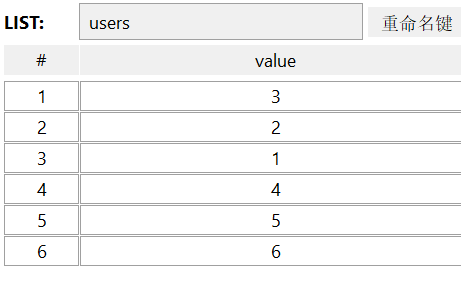
3.5 Set(无序、不可重复)
特征: 无序、不可重复、查找速度快、支持集合运算。
| 命令 | 功能描述 | 示例 |
|---|---|---|
| SADD key member1 member2 ... | 向 set 中添加一个或多个元素 | SADD s1 a b c |
| SMEMBERS key | 获取 set 中的所有元素 | SMEMBERS s1 |
| SISMEMBER key member | 判断一个元素是否存在于 set 中 | SISMEMBER s1 a |
| SCARD key | 返回 set 中元素的个数 | SCARD s1 |
| SREM key member1 member2 ... | 移除 set 中的指定元素 | SREM s1 a |
| SINTER key1 key2 | 求多个 set 的交集 | SINTER s1 s2 |
| SUNIONkey1 key2 | 求多个 set 的并集 | SUNION s1 s2 |
| SDIFF key1 key2 | 求多个 set 的差集,在第一个不在第二个 | SDIFF s1 s2 |
192.168.100.128:6379> SADD s1 a b c
(integer) 3
192.168.100.128:6379> SMEMBERS s1
1) "a"
2) "c"
3) "b"
192.168.100.128:6379> SADD zhangsan lisi wangwu zhaoliu
(integer) 3
192.168.100.128:6379> SADD lisi wangwu mazi ergou
(integer) 3
192.168.100.128:6379> SCARD zhangsan
(integer) 3
192.168.100.128:6379> SINTER zhangsan lisi
1) "wangwu"
192.168.100.128:6379> SDIFF zhangsan lisi
1) "zhaoliu"
2) "lisi"
192.168.100.128:6379> SUNION zhangsan lisi
1) "ergou"
2) "lisi"
3) "wangwu"
4) "zhaoliu"
5) "mazi"
3.6 SortedSet(有序、不重复)
特征:可排序、不重复、查询速度快、常使用在排行榜、优先级队列等需要排序的业务场景。
| 命令 | 功能描述 | 示例 |
|---|---|---|
| ZADD key score member | 添加一个或多个元素到 sorted set,若元素已存在则更新其 score 值 | ZADD stus 85 Jack 89 Lucy |
| ZREM key member | 删除 sorted set 中的一个指定元素 | ZREM stus Tom |
| ZSCORE key member | 获取 sorted set 中指定元素的 score 值 | ZSCORE stus Amy |
| ZRANK key member | 获取 sorted set 中指定元素的排名(从小到大,从 0 开始) | ZREVRANK stus Rose 获取分数排名时要从大到小,加上REV |
| ZCARD key | 获取 sorted set 中的元素个数 | ZCARD stus |
| ZCOUNT key min max | 统计 score 值在给定范围内的所有元素的个数 | ZCOUNT stus 80 100 |
| ZINCRBY key increasement member | 让 sorted set 中的指定元素自增,步长为指定的 increment 值 | ZINCRBY stus 5 Jack |
| ZRANGE key min max | 按照 score 排序后,获取指定排名范围内的元素(默认升序) | ZREVRANGE stus 0 2 获取前几名时要从大到小,加上REV |
| ZRANGEBYSCORE key min max | 按照 score 排序后,获取指定 score 范围内的元素 | ZRANGEBYSCORE stus 90 100 |
| ZDIFF numkeys key1 key2 | 求多个 sorted set 的差集 | ZDIFF 2 stus stus2 |
| ZINTER numkeys key1 key2 | 求多个 sorted set 的交集 | ZINTER 2 stus stus2 |
| ZUNION numkeys key1 key2 | 求多个 sorted set 的并集 | ZUNION 2 stus stus2 |
默认从小到大,Z 变成 ZREV 就是 倒序、从大到小 的意思。
192.168.100.128:6379> ZADD stus 85 Jack 89 Lucy 82 Rose 95 Tom 78 Jerry 92 Amy 76 Miles
(integer) 7
192.168.100.128:6379> ZREM stus Tom
(integer) 1
192.168.100.128:6379> ZSCORE stus Amy
"92"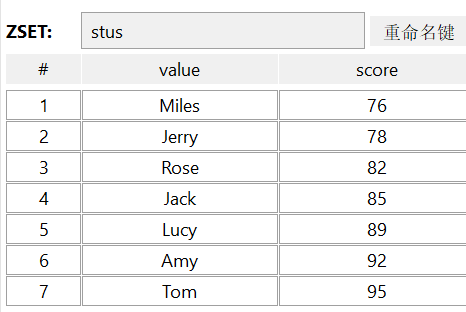
4 Redis的Java客户端
工具 核心特点 线程安全 定位 Jedis 轻量、命令和 Redis 一致、学习简单 否 基础 Redis 客户端 Lettuce 基于 Netty、异步非阻塞、高并发稳定 是 高级 Redis 客户端 Spring Data Redis 封装 Jedis/Lettuce、提供统一 API、集成 Spring ❤ 是 Spring 生态 Redis 操作模板 Redisson 基于 Redis 实现分布式 Java 数据结构、提供分布式锁 / 队列等高级功能 是 分布式场景专用工具 (侧重分布式服务) Jedis 和 Lettuce 是底层客户端,Spring Data Redis 是上层封装,SpringBoot 默认用 Lettuce。
4.1 Jedis
官网快速入门:https://github.com/redis/jedis
Jedis 缺点:
(1)Jedis 实例本身是线程不安全的,多线程环境下直接使用会引发并发问题。
(2)频繁创建 / 销毁 Jedis 连接会产生性能损耗,影响系统效率。
==>推荐使用 Jedis 连接池 替代直连方式。
Jedis 使用基本步骤:
- 引入依赖:在项目中引入 Jedis 的 Maven 依赖。
XML
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>7.1.0</version>
</dependency>- 创建 Jedis 对象,建立连接:通过 new Jedis(host, port) 实例化对象并连接 Redis,可补充认证、选择数据库等操作。
java
@BeforeEach
void setUP() {
jedis = new Jedis("192.168.100.128", 6379);
jedis.auth("123321");
jedis.select(0);
}- 使用 Jedis:调用与 Redis 命令同名的方法(如 set()/get() 对应 SET/GET 命令)操作数据。
java
@Test
void testString() {
String result = jedis.set("name", "虎哥");
System.out.println("result = " + result);
String name = jedis.get("name");
System.out.println("name = " + name);
}- 释放资源:调用 close() 方法关闭连接,释放底层资源,避免连接泄漏。
java
@AfterEach
void tearDown() {
//必须先判断不为空再关闭,防止jedis创建失败是null,直接close()会空指针崩溃
if (jedis != null) {
jedis.close();
}
}测试通过!
Jedis连接池:
- 不直接 new Jedis() ,而是使用 JedisPool 连接池 统一管理连接。
- 连接池在类加载时初始化一次,全局复用,避免频繁创建 / 销毁连接。
- 用完连接不真正关闭 ,而是归还到连接池,供其他线程使用。
连接池工具类:提供统一获取 Jedis 连接的方法,内部维护一个静态、不可变的连接池对象:private static final JedisPool jedisPool。
java
package com.heima.jedis.util;
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
//static { } 就是:类一加载就自动运行,且只运行一次的代码块。
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(8);
jedisPoolConfig.setMaxIdle(8);
jedisPoolConfig.setMinIdle(0);
jedisPoolConfig.setMaxWait(Duration.ofMillis(1000));
jedisPool = new JedisPool(jedisPoolConfig, "192.168.100.128", 6379, 1000, "123321");
}
public static Jedis getJedis() {
return jedisPool.getResource();
}
}使用连接池获取一个 Jedis
java
package com.heima.test;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUP() {
jedis = JedisConnectionFactory.getJedis(); //不再new一个jedis,而是从池子里拿一个
jedis.auth("123321");
jedis.select(0);
}
@Test
void testString() {
String result = jedis.set("name", "虎哥");
System.out.println("result = " + result);
String name = jedis.get("name");
System.out.println("name = " + name);
}
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close(); //归还给池子
}
}
}4.2 Spring Data Redis
Spring Data 模块下的 Redis 集成组件,是 Spring 生态中操作 Redis 的统一方案。
官网:https://spring.io/projects/spring-data-redis
- 整合 Lettuce、Jedis 等多种 Redis 客户端,底层切换灵活。
- 提供RedisTemplate统一 API,简化 Redis 操作。
- 支持 Redis 发布订阅、哨兵、集群等高级模式。
- 支持基于 Lettuce 的响应式编程。
- 提供多种数据序列化方案(JDK、JSON、字符串、Spring 对象等)。
- 实现了基于 Redis 的 JDK Collection 接口,可以像操作 Java 集合 (List/Map/Set 等)一样操作 Redis。
RedisTemplate快速入门:
① 引入依赖
XML
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>② 配置文件application.yml
XML
spring:
data:
redis:
host: 192.168.100.128
port: 6379
password: 123321
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 1000ms③ 注入RedisTemplate并使用
java
@SpringBootTest
class RedisDemoApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
redisTemplate.opsForValue().set("name", "虎哥");
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}4.3 RedisTemplate 的两种序列化实践方案
RedisTemplate:默认 JDK 序列化(乱码、体积大,不推荐)
StringRedisTemplate:RedisTemplate 的子类,key/value 都默认 String 序列化(推荐)
(1)方案1:自定义 RedisTemplate + JSON 自动序列化
适用场景:快速开发,不想手动处理 JSON,让 RedisTemplate 自动序列化成可读 JSON。但是会存全类名,体积大。
- 自定义 RedisTemplate
- 修改 RedisTemplate 的序列化器为 GenericJackson2JsonRedisSerializer
(2)方案二:StringRedisTemplate + 手动 JSON 转换 ❤
适用场景:企业生产最常用,可控性强、无冗余数据、跨语言兼容。
- 使用 StringRedisTemplate
- 写入 Redis 时,手动把对象序列化为 JSON
- 读取 Redis 时,手动把读取到的 JSON 反序列化为对象
java
@SpringBootTest
class RedisStringTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
// 普通字符串存、取 Redis
@Test
void testString() {
stringRedisTemplate.opsForValue().set("name", "虎哥");
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
/**
* 定义Jackson的ObjectMapper工具对象
* 用于实现Java对象和JSON字符串的相互转换(序列化/反序列化)
* 声明为static final,全局复用,提升性能
*/
private static final ObjectMapper mapper = new ObjectMapper();
// 对象 → JSON → 存 Redis,读 Redis → JSON → 对象
@Test
void testSaveUser() throws JsonProcessingException {
//创建对象
User user = new User("虎哥", 21);
//手动序列化
String json = mapper.writeValueAsString(user);
//写入redis
stringRedisTemplate.opsForValue().set("user:100", json);
//读取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:100");
//手动反序列化
User user1 = mapper.readValue(jsonUser, User.class);
//输出结果
System.out.println("user1:" + user1);
}
}