作者说明:本文是RAG系列文章的第三篇,着重解析Docx文档的智能问答。本系列前两篇已经将PPTX和PDF文档做了深入阐述。至此,企业级智能知识问答系统落地最常见的文档格式及其处理全部完成。
引言:为什么DOCX是RAG落地的"最后一公里"
在企业级AI应用蓬勃发展的今天,一个不争的事实摆在所有工程师面前:大量的企业知识沉淀在Office文档中。这些文档承载着产品规格说明、合同条款、技术规范、业务流程文档等核心企业资产。然而,与结构清晰的Markdown或纯文本不同,DOCX实际上是一个高度复杂的"压缩包"------它内部充斥着嵌套表格、不同年代的矢量图标准(VML与DrawingML)以及隐性的排版逻辑。
当我们谈论RAG(检索增强生成)技术时,PDF往往是最先被提及的文档格式,因为PDF的解析难度已经广为人知。但实际上,DOCX的复杂性有过之而无不及。传统的RAG方案直接将DOCX转换为文本,往往会导致表格变形、图片丢失、上下文断裂等问题,这些问题直接影响了检索的精度,使得最终的用户体验大打折扣。
本文将复盘一个生产级DOCX RAG系统的完整技术实现,从架构哲学到关键代码,从格式兼容到智能分块,深入拆解我们是如何通过"分层流水线"和"父子块结构"攻克这些难题的。希望通过这篇技术博文,为正在或即将踏上RAG开发之路的同行者提供有价值的参考和启发。
系统界面展示
表格内嵌图片复杂结构问答界面
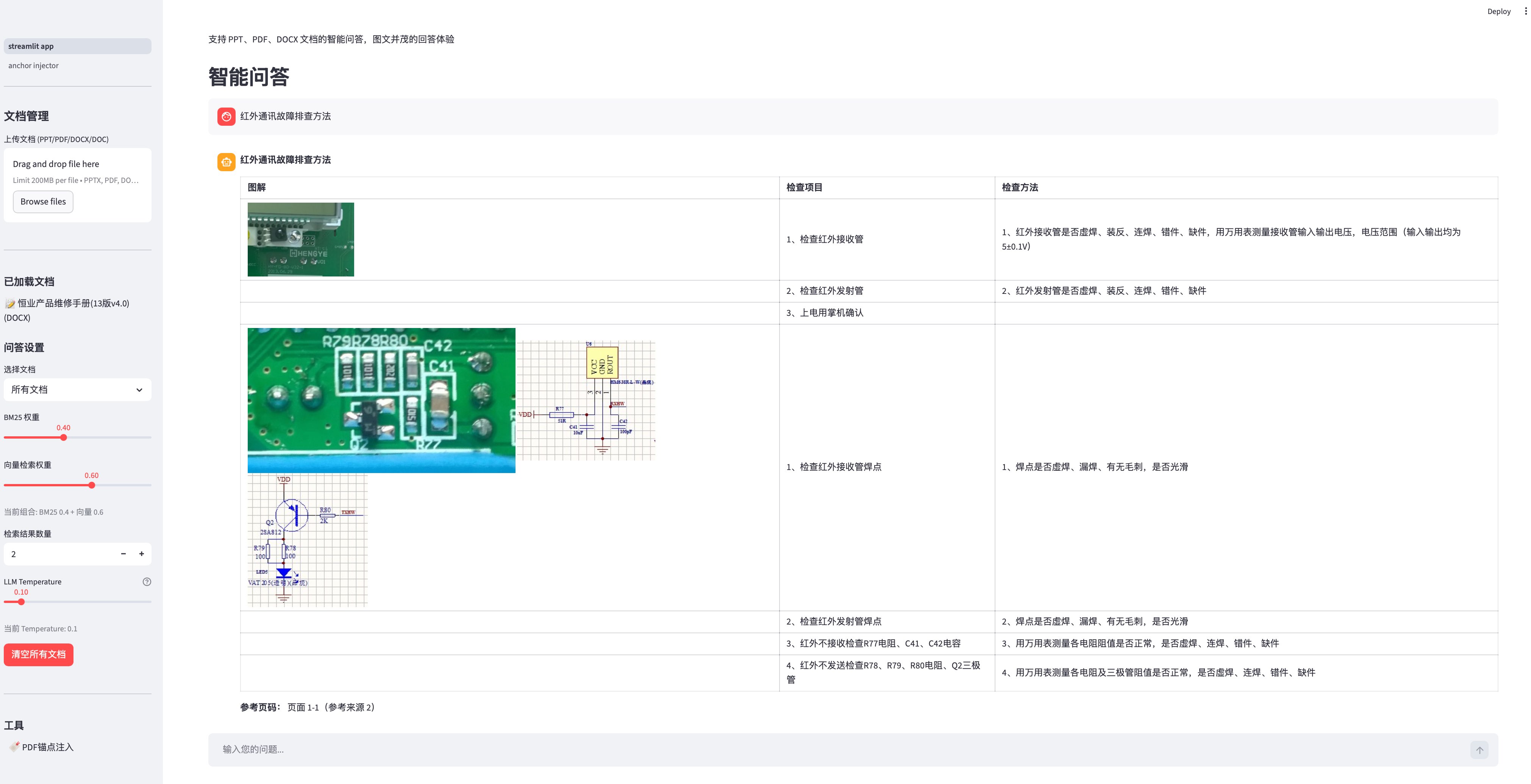
表格和图片同时显示问答界面
一、架构哲学:流水线式的"解耦"艺术
1.1 面对复杂性的最佳策略
面对DOCX的复杂性,最忌讳的是"一把梭"的处理方式。许多开发者在初次接触DOCX解析时,往往会尝试用简单的文本提取库(如python-docx)直接读取文档内容,然后草草地进行向量化存储。这种方式在面对简单文档时或许能够work,但一旦处理生产环境中真实存在的复杂文档,就会暴露出种种问题:表格结构丢失、图片无法提取、格式信息丢失、检索效果差等。
我们设计的架构遵循**职责分离(Separation of Concerns)**原则,将整个DOCX处理流程拆解为五个核心层级。每一个层级都有其明确的职责边界,通过定义清晰的输入输出接口实现层间通信。这种设计带来的好处是显而易见的:当需要支持新的文档格式时,只需在相应层次插入新的处理模块,而无需改动整体架构;当某个处理环节出现性能瓶颈时,可以针对性地进行优化,而不会影响其他部分的稳定性。
1.2 核心层级功能拆解
让我们详细审视每一个层级的功能和设计考量:
预处理层 负责解决"数字遗产"问题。在企业的文档资产中,不可避免地存在一些使用旧版Office创建的文档。这些文档可能采用过时的VML矢量图形格式,而现代解析工具往往无法正确处理。预处理层通过格式检测识别这些旧版文档,并调用Pandoc进行标准化转换,确保后续解析层能够获得统一格式的输入。这一层的核心价值在于前置化处理------将格式兼容性问题在最开始就解决掉,而不是让它们在后续环节中造成各种奇怪的错误。
解析层 利用Docling(IBM开源的高性能解析器)将二进制DOCX文档转化为结构化Markdown。为什么选择Docling而不是python-docx?这是一个关键的技术决策。python-docx虽然能够读取DOCX的DOM结构,但它无法理解文档的布局信息。而Docling具备布局感知能力,能够识别文档中的语义结构,这对于后续的分块处理很重要。此外,Docling在转换Markdown的同时,能够保留图片在文中的精确位置占位符,这是实现多模态RAG的基础。
分块层是RAG的"灵魂"。分块(Chunking)是将连续文本拆分成适合检索和生成的独立语义单元的过程。这一层通过"向上聚合"与"向下拆分"两种策略的组合,平衡语义粒度,既避免了过短的碎片化内容,也防止了过长的上下文稀释。分块策略的质量直接决定了检索的精度和生成的质量。
存储层构建FAISS向量库与DocStore原文库的映射关系。这里采用了父子块结构------子块存入FAISS向量库用于快速检索,父块存入DocStore用于提供完整上下文。这种双层存储设计是整个系统的技术核心,我们会在后续章节中详细展开讨论。
框架复用 :这种流水线设计最大的优势在于"热插拔"。如果未来出现更强的解析工具(如专门处理复杂表格的OCR),我们只需更换解析层,而无需重构整个检索逻辑。这也体现了良好架构设计的核心原则:变化的部分应该被封装,不变的部分应该被抽象。
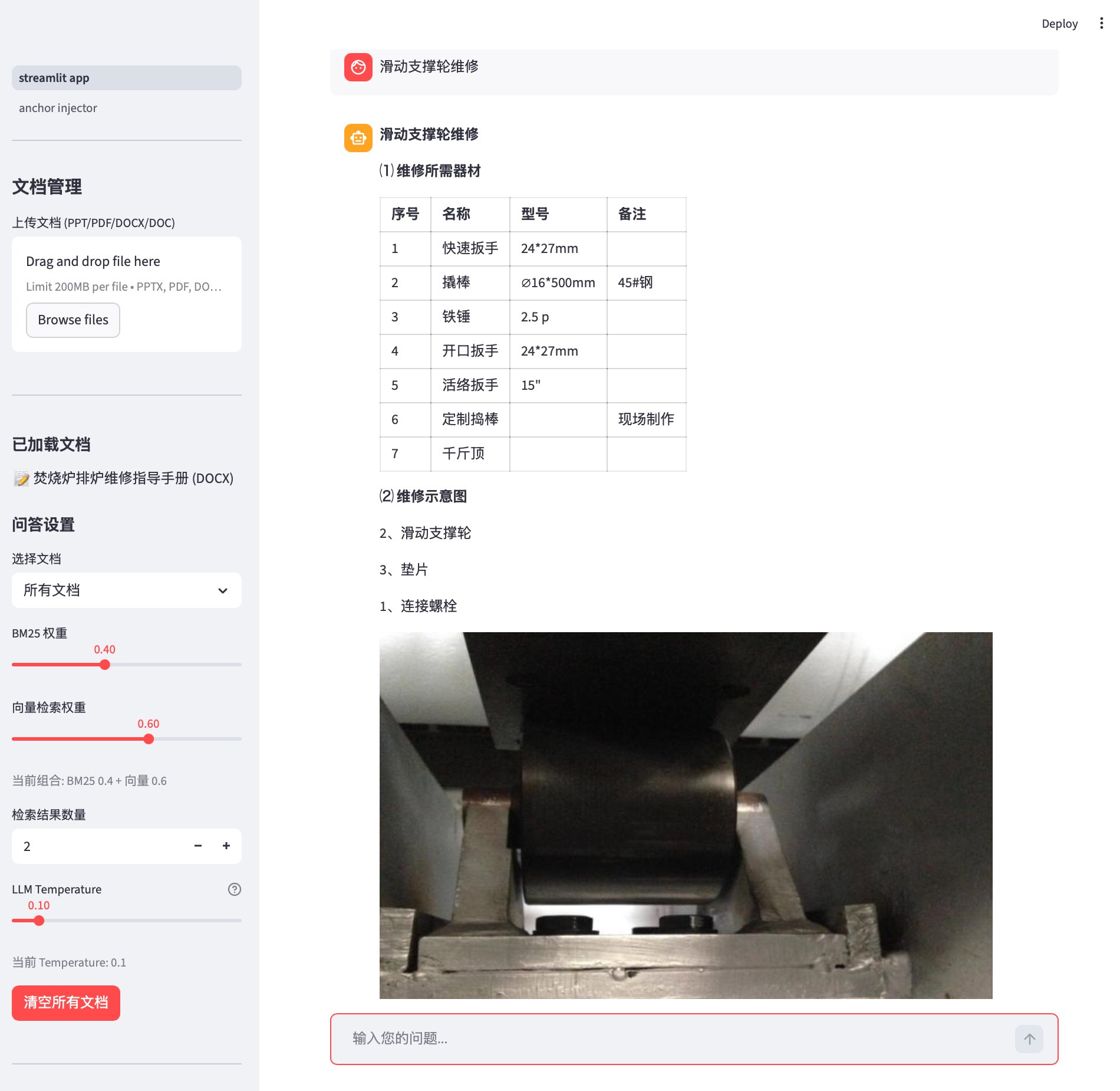
1.3 架构全景图
下图展示了整个DOCX RAG系统的数据流转过程:

从输入到存储,整个流水线形成了一个清晰的数据流转通道。每一层的输出都是下一层的输入,这种单向流动的设计使得系统的数据流易于理解和调试。
二、格式兼容:跨越二十年的技术鸿沟
2.1 DOCX格式的演进史与兼容性挑战
DOCX的进化史上存在着两个平行的世界:VML (Vector Markup Language)和DrawingML。这是理解DOCX格式兼容性的关键。
VML是早期Office版本(Word 2003及更早版本)使用的矢量图形描述语言。当你创建一个Word文档并插入一张图片时,在DOCX的内部XML结构中,这张图片是通过VML标签来描述的。随着Office 2007的发布,微软引入了新的图形格式------DrawingML。DrawingML不仅支持更丰富的图形效果,还提供了更好的性能和更大的灵活性。
问题在于:这两种格式是并存的。即使在最新的Office版本中创建的文档,如果通过某些特定的复制粘贴操作或者使用某些老旧的插件,仍然可能产生包含VML内容的文档。这意味着企业环境中的DOCX文档可能是十年前创建的,也可能是昨天生成的,RAG系统必须能够无缝处理这两种截然不同的内部表示。
2.2 智能检测:识别文档的"年龄"
我们的方案是在解析前插入一道检测关卡。这个检测模块通过解析DOCX内部的XML结构,识别文档中图片和形状的编码方式:
python
def detect_docx_format(docx_path: str) -> dict:
"""
检测DOCX文档的内部格式类型
通过分析word/document.xml中的命名空间和元素,
判断文档使用的图片格式是VML还是DrawingML
Returns:
dict: 包含格式类型和统计信息的字典
- format_type: 'legacy_vml' | 'modern_drawingml' | 'mixed' | 'unknown'
- vml_count: VML图片数量
- drawingml_count: DrawingML图片数量
"""
vml_count = 0
drawingml_count = 0
with zipfile.ZipFile(docx_path, 'r') as zf:
if 'word/document.xml' not in zf.namelist():
return {"format_type": "unknown", "vml_count": 0, "drawingml_count": 0}
xml_content = zf.read('word/document.xml').decode('utf-8')
# 检测VML图片
if 'v:imagedata' in xml_content or '<v:shape' in xml_content:
vml_matches = re.findall(r'<v:imagedata[^>]*>', xml_content)
vml_count = len(vml_matches)
# 检测DrawingML图片
if 'a:blip' in xml_content or 'w:drawing' in xml_content:
drawingml_matches = re.findall(r'<a:blip[^>]*>', xml_content)
drawingml_count = len(drawingml_matches)
# 确定格式类型
if vml_count > 0 and drawingml_count == 0:
format_type = "legacy_vml"
elif drawingml_count > 0 and vml_count == 0:
format_type = "modern_drawingml"
elif vml_count > 0 and drawingml_count > 0:
format_type = "mixed"
else:
format_type = "unknown"
return {
"format_type": format_type,
"vml_count": vml_count,
"drawingml_count": drawingml_count
}这个检测函数的原理其实非常直接:DOCX本质上是一个ZIP压缩包,内部包含多个XML文件。其中word/document.xml是文档的主体内容。我们通过正则表达式扫描这个XML文件,统计其中包含VML标签(<v:imagedata>、<v:shape>)和DrawingML标签(<a:blip>、<w:drawing>)的数量,从而判断文档的格式类型。
2.3 Pandoc桥接:格式的"瑞士军刀"
为什么这里要引入Pandoc? 这个问题值得深入探讨。Pandoc不仅仅是转换器,它更像是一个"格式洗涤器"。
当检测到旧版VML格式时,系统会自动触发pypandoc转换。这一步的本质是利用Pandoc的内部渲染引擎,强制将所有矢量图重写为标准的DrawingML。转换过程不仅仅是简单的格式重写,而是一次完整的"重新渲染"------Pandoc会解析原始文档的完整内容,然后用现代格式重新生成整个文档。在这个过程中,VML图形被转换为等效的DrawingML表示。
python
def convert_to_standard_docx(input_path: str, output_path: str) -> str:
"""
使用Pandoc将VML格式的DOCX转换为标准DrawingML格式
当检测到legacy_vml格式时,调用此函数进行转换。
转换后的文档使用现代DrawingML格式,可被Docling正确解析。
Args:
input_path: 原始DOCX文件路径
output_path: 转换后的DOCX文件路径
Returns:
str: 转换后的文件路径
Raises:
RuntimeError: 当Pandoc转换失败或pypandoc未安装时
"""
try:
import pypandoc
# 使用Pandoc转换DOCX到DOCX
# 这会重新生成使用现代DrawingML格式的DOCX
pypandoc.convert_file(input_path, 'docx', outputfile=output_path)
return output_path
except ImportError:
raise RuntimeError(
"pypandoc not installed. "
"Please install: pip install pypandoc"
)
except Exception as e:
raise RuntimeError(f"Pandoc conversion failed: {e}")这一步转换确保了后续Docling解析阶段能够正确提取文档中的图片和排版信息。虽然增加了一个转换步骤会带来一定的性能开销,但相比因为格式不兼容而导致的图片丢失,这个代价是值得的。从技术决策的角度来看,这是一个典型的以空间换时间、以时间换质量的选择。
三、智能解析:Docling驱动的多模态提取
3.1 为什么是Docling:技术选型的深度考量
在解析器选型上,我们放弃了传统的python-docx,选择了Docling。这个选择背后有着深思熟虑的技术考量。
python-docx的局限性 在于它只是一个文档结构读取器。它能够解析DOCX文件的XML DOM结构,提取段落、表格、图片等信息,但它无法理解文档的语义结构。它不知道一个段落是标题还是正文,也不知道表格的表头在哪里。这种语义理解的缺失会导致后续分块策略的失效------我们将无法根据文档的结构来智能地进行分块。
Docling的优势则体现在以下几个方面:
首先,布局感知是Docling的核心能力。它能够识别什么是标题、什么是页眉、什么是正文、什么是表格。这种布局信息的识别对于RAG场景下的分块至关重要------我们希望将同一章节的内容放在一起,而不是将标题和正文割裂。
其次,图片锚点功能让我们能够在转换Markdown的同时,保留图片在文中的精确位置占位符。在后续的检索阶段,LLM可以通过这个URL直接访问图片,极大增强了多模态生成的可能性。这意味着我们的RAG系统不仅能够处理文本,还能够处理图文结合的复杂内容。
3.2 Docling配置与图片提取
Docling转换流程的核心在于DocumentConverter的配置。系统使用专门针对DOCX格式优化的转换器,启用图片提取功能以确保文档中的视觉信息不会丢失:
python
def init_docling_converter_for_docx_with_images(converter_class=None):
"""
初始化Docling DocumentConverter用于DOCX图片提取
DOCX格式使用Docling的默认converter,但启用图片提取功能。
需要设置generate_picture_images=True才能提取文档中的图片。
Args:
converter_class: 可选的DocumentConverter类(用于测试mock)
Returns:
配置好的DocumentConverter实例
"""
from docling.document_converter import DocumentConverter, WordFormatOption
from docling.datamodel.pipeline_options import PdfPipelineOptions
from docling.datamodel.base_models import InputFormat
# 配置Pipeline选项 - 启用图片提取
pipeline_options = PdfPipelineOptions()
artifacts_path = get_docling_artifacts_path()
if artifacts_path and Path(artifacts_path).exists():
pipeline_options.artifacts_path = artifacts_path
# 禁用OCR(DOCX是结构化文档,不需要OCR)
pipeline_options.do_ocr = False
# 启用表格结构识别
pipeline_options.do_table_structure = True
# 关键:启用图片提取
pipeline_options.generate_page_images = False
pipeline_options.generate_picture_images = True # 启用图片提取
# 创建Word格式选项
word_format_option = WordFormatOption(pipeline_options=pipeline_options)
# 初始化文档转换器
if converter_class:
return converter_class(format_options={InputFormat.DOCX: word_format_option})
return DocumentConverter(format_options={InputFormat.DOCX: word_format_option})这里有几个关键的配置参数值得深入解释:
do_ocr = False:因为DOCX本身是结构化文档,其文本内容已经以明文形式存储在XML中,不需要通过OCR来识别。
generate_picture_images = True:这是实现多模态RAG的关键开关。开启后,Docling在解析DOCX时会将文档中的图片导出为独立的图像文件。这些图片随后会被保存到本地存储,并在Markdown内容中以的形式嵌入。
do_table_structure = True:启用表格结构识别,让Docling能够理解表格的表头、行列结构,而不仅仅是将表格视为一堆文本的组合。
3.3 闭环的图片处理逻辑
为了让RAG具备"看图说话"的能力,我们不仅要提取文字,还要构建完整的图片处理流程。整个流程可以分为以下几个步骤:
图片提取:Docling转换后的Markdown内容中,图片以特殊的占位符形式存在。系统需要遍历Docling解析结果中的所有图片元素,将二进制数据保存到以文件哈希命名的目录中:
python
def _extract_images_from_docling(self, docling_doc, file_hash: str, file_name: str) -> Dict[str, str]:
"""
从Docling解析结果中提取图片
Docling转换后的文档中包含图片引用,需要提取实际的图片数据
并保存到本地存储。支持两种图片引用格式:
- <!-- image --> HTML注释占位符
- <!-- IMAGE_PLACEHOLDER:xxx --> 带ID的占位符
"""
images_dir = Path(config.images_dir) / file_hash
images_dir.mkdir(parents=True, exist_ok=True)
image_map = {}
image_counter = 0
# 遍历Docling文档中的所有图片元素
for item in docling_doc._iterate_items():
if item._item_kind == DocItemKind.PICTURE:
image_counter += 1
# 生成图片文件名
ext = "png" # Docling默认输出PNG
image_filename = f"{file_name}_image_{image_counter:03d}.{ext}"
image_path = images_dir / image_filename
# 提取并保存图片数据
try:
image_data = item.get_image()
if image_data:
with open(image_path, 'wb') as f:
f.write(image_data)
# 记录映射关系
placeholder_id = f"image_{image_counter}"
image_map[placeholder_id] = str(image_path)
except Exception as e:
self.log.warning(f"Failed to extract image {image_counter}: {e}")
return image_map哈希去重:利用图片数据的MD5值命名,避免同一张Logo在数据库中重复存储上千次。这是一个简单但非常实用的优化------在企业文档中,同一张公司Logo可能会出现在成百上千份文档中,如果每次都重新存储,会造成极大的存储浪费。
占位符替换 :解析后的Markdown包含形式的图片引用。在检索阶段,LLM可以通过这个URL直接访问图片:
python
def _replace_image_placeholders(self, markdown: str, image_map: Dict[str, str],
image_server_url: str) -> str:
"""
替换Markdown中的图片占位符为实际URL
"""
result = markdown
placeholder_pattern = r'<!--\s*IMAGE_PLACEHOLDER:(\w+)\s*-->|<!--\s*image\s*-->'
def replace_match(match):
placeholder_id = match.group(1)
if placeholder_id and placeholder_id in image_map:
local_path = image_map[placeholder_id]
relative_path = Path(local_path).relative_to(config.images_dir)
image_url = f"{image_server_url}/{relative_path}"
return f''
if 'image' in match.group(0).lower():
for pid, path in image_map.items():
relative_path = Path(path).relative_to(config.images_dir)
image_url = f"{image_server_url}/{relative_path}"
return f''
return match.group(0)
result = re.sub(placeholder_pattern, replace_match, result)
return result图片处理流程图:
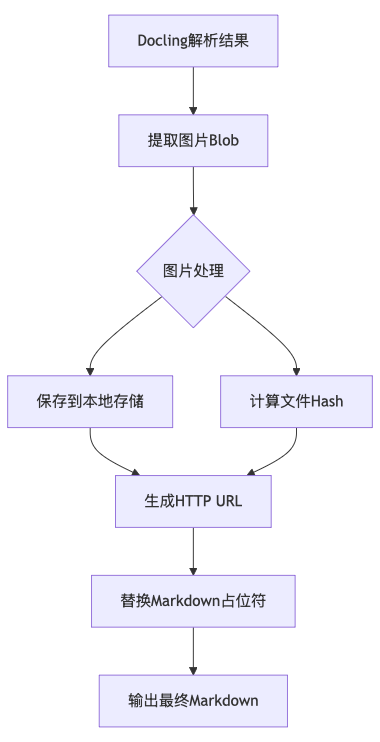
这种闭环的图片处理逻辑确保了RAG系统不仅能够处理纯文本,还能够处理图文结合的复杂内容。在实际应用中,这意味着当用户询问"报告中提到的那个流程图是什么意思"时,系统能够准确定位到相关的图片,并将其作为上下文提供给LLM。
四、分块策略:精度与深度的"双舞"
4.1 分块的重要性:被低估的RAG核心环节
分块(Chunking)是RAG系统中最容易被低估、也最影响效果的环节。许多开发者在构建RAG系统时,往往会将大量精力放在向量模型选择、检索算法优化等方面,而对分块策略不够重视。然而,在实际生产环境中,分块策略的选择直接影响着检索的精度和生成的质量。
为什么分块如此重要? 原因在于向量检索的基本原理。当我们将文本转换为向量时,较短的文本通常能够获得更精确的向量表示------因为向量是对整个文本内容的语义压缩,如果文本过长,语义信息会被"稀释",导致检索时匹配不到真正相关的内容。但另一方面,较短的文本可能缺乏足够的上下文信息,导致LLM无法生成完整、准确的回答。
传统的固定长度分块方式存在明显的局限性:它会强行在任意位置切断文本,可能将一个完整的句子拆分成两半,也可能将标题和其对应的内容分到不同的块中。这种"断章取义"的分块方式会严重影响检索效果。
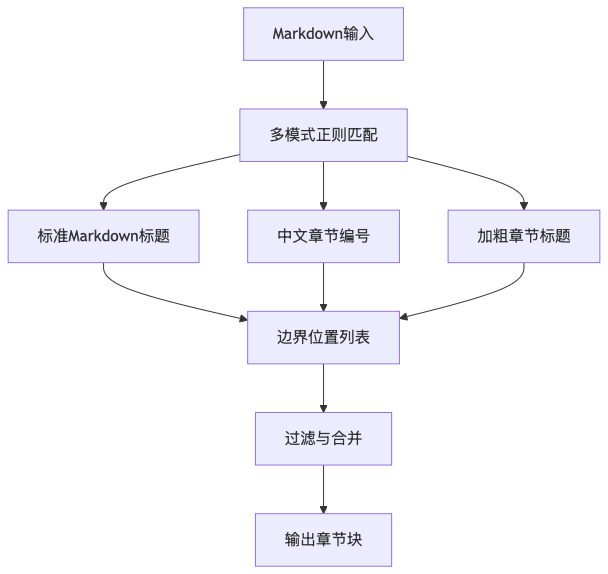
4.2 章节边界检测:打破"字数截断"的魔咒
针对固定长度分块的局限性,我们采用了基于正则的章节边界检测方法。系统内置了20多种模式,覆盖了"第一章"、"1.1.1"、"(一)"等中西合璧的编号格式:
python
section_patterns = [
# 标准Markdown标题
r'^#\s+.*', # 一级标题
r'\n#\s+.*',
r'^##\s+.*', # 二级标题
r'\n##\s+.*',
# 中文章节编号
r'^第[一二三四五六七八九十]+章.*', # 汉字数字章节
r'\n第[一二三四五六七八九十]+章.*',
r'^第\d+章.*', # 阿拉伯数字章节
# 加粗章节标题(黑体)
r'\*\*第[一二三四五六七八九十]+章\s*[^\*\n]{1,30}\*\*',
r'\*\*(?:[一二三四五六七八九十]十?[一二三四五六七八九]?|[1-9][0-9]*)[ 、\.]+[^\*]{1,30}\*\*',
# 列表编号
r'^[一二三四五六七八九十]、\s*[^\n]{1,30}', # 中式编号
]这些模式按照优先级组合成一个联合正则表达式,通过一次扫描即可识别出文档中所有的潜在章节边界。随后,系统会对检测到的边界进行过滤,剔除那些间距过近的冗余边界,确保最终保留的章节边界具有足够的语义区分度。
4.3 向上聚合与向下拆分:自适应算法
章节边界检测只是分块的第一步。真实世界的文档结构千差万别:有的文档章节划分过细,每个章节只有寥寥数语(如只有标题没有内容的空章节);有的文档则存在超长章节,包含数万字的连续内容(如详细设计说明)。为了应对这些复杂情况,系统设计了双向分块策略。
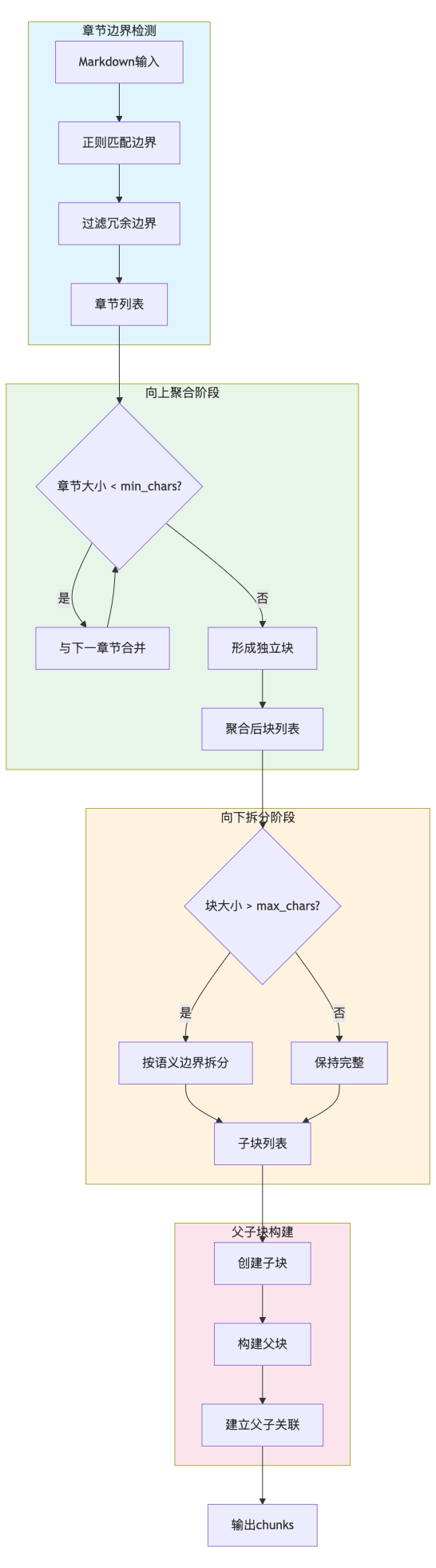
向上聚合(Bottom-up Aggregation):如果一个章节只有50个字,系统会自动将其与下一节合并,避免产生"语义碎片"。这个过程就像是把太小的石子聚合成更大的鹅卵石:
python
def _aggregate_sections(self, sections, min_chars, max_chars):
"""
向上聚合:合并小章节直到达到min_chars
算法:
1. 从空buffer开始
2. 逐个遍历章节:
- 如果buffer为空: 将当前章节加入buffer
- 如果buffer+当前章节 > max_chars: 先finalize buffer, 再开始新buffer
- 如果buffer < min_chars: 合并当前章节到buffer
- 如果buffer >= min_chars: finalize buffer, 开始新buffer
3. finalize剩余的buffer
"""
aggregated = []
buffer_content = ""
buffer_start_idx = 0
for section_idx, (header, content) in enumerate(sections):
section_text = f"{header}\n{content}".strip() if header else content.strip()
if not section_text:
continue
# Buffer为空 - 开始新buffer
if not buffer_content:
buffer_content = section_text
buffer_start_idx = section_idx
if len(buffer_content) >= min_chars:
aggregated.append((buffer_content, buffer_start_idx, section_idx))
buffer_content = ""
continue
# 计算合并后的长度
merged_size = len(buffer_content) + len("\n\n") + len(section_text)
# 超过max_chars - finalize当前, 开始新buffer
if merged_size > max_chars:
aggregated.append((buffer_content, buffer_start_idx, section_idx - 1))
buffer_content = section_text
buffer_start_idx = section_idx
if len(buffer_content) >= min_chars:
aggregated.append((buffer_content, buffer_start_idx, section_idx))
buffer_content = ""
continue
# Buffer < min_chars - 安全合并
if len(buffer_content) < min_chars:
buffer_content += "\n\n" + section_text
if len(buffer_content) >= min_chars:
aggregated.append((buffer_content, buffer_start_idx, section_idx))
buffer_content = ""
continue
# Buffer >= min_chars - finalize当前, 开始新buffer
aggregated.append((buffer_content, buffer_start_idx, section_idx - 1))
buffer_content = section_text
buffer_start_idx = section_idx
# 处理剩余的buffer
if buffer_content:
aggregated.append((buffer_content, buffer_start_idx, len(sections) - 1))
return aggregated向下拆分(Top-down Split) :如果一个详细设计章节有5000字,系统会调用RecursiveCharacterTextSplitter进行递归拆分,优先在段落处切分,其次是句子,最后才是空格:
python
def _split_oversized_parents(
self, parents: List[Tuple[str, int, int]], max_chars: int
) -> List[Tuple[str, int, int]]:
"""
向下拆分:使用文本分割器拆分超长的父块
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=max_chars,
chunk_overlap=config.parent_chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", " ", ""],
)
final_parents = []
for content, start_idx, end_idx in parents:
if len(content) > max_chars:
# 超长父块需要拆分
split_parts = splitter.split_text(content)
for part_content in split_parts:
final_parents.append((part_content, start_idx, end_idx))
else:
final_parents.append((content, start_idx, end_idx))
return final_parents这个分割器的智能之处在于它的"递归"特性:它会按优先级顺序尝试不同的分隔符。首先尝试段落分隔符(\n\n),如果分割后的片段仍然超过max_chars,则退而尝试换行符(\n);如果还是太长,则尝试句子结束符(。、!、?);最后才使用空格或强制切割。这种"由粗到细"的分割策略确保了文本的语义完整性得到最大程度的保护。
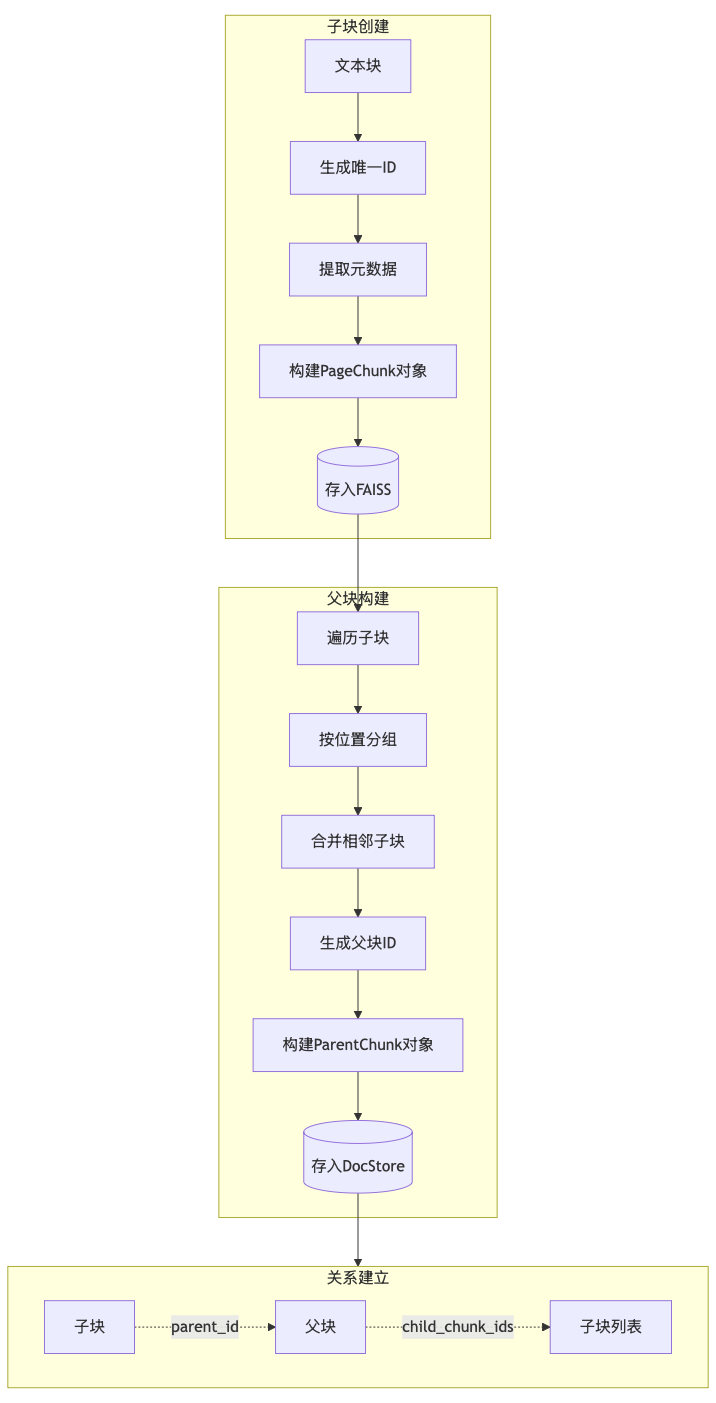
4.4 父子块结构:检索的杀手锏
这是本系统的技术核心。父子块结构的设计理念源于对RAG检索和LLM生成两个阶段的深度理解:
子块(Child Chunk) :短小精悍(约300-500 tokens),专用于向量匹配。这确保了检索的"准"。子块被存储在FAISS向量数据库中,支持基于语义相似度的快速检索。
父块(Parent Chunk) :逻辑完整(通常是整个段落或章节),存储在DocStore中。父块的内容长度可以达到数万字符,足以提供丰富的背景信息。
检索逻辑:
当用户提问时,系统检索到最匹配的子块 ,但并不直接传给LLM。相反,它通过parent_id找到对应的父块,将更有上下文深度的内容喂给LLM。
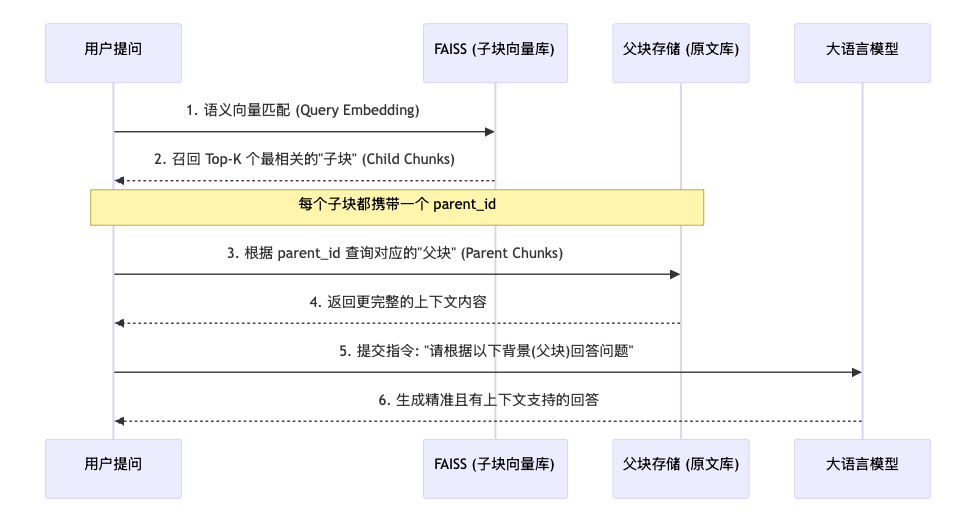
核心价值分析:
- 解决"断章取义":子块可能只有一句话,无法解释复杂的逻辑;父块能提供完整的段落甚至章节。
- 提升检索效率:向量库只存精简的子块,计算速度更快,且能避免长文本带来的向量均值化模糊。
这种机制本质上是在做"空间换质量"。子块负责在向量空间里"锚定"精确位置,父块负责在生成阶段提供"语义背景"。
五、关键技术与实践经验
5.1 为什么分层架构是DOCX RAG的最优解?
DOCX RAG系统的复杂性源于DOCX格式本身的多层次复杂性:格式版本兼容性、丰富的排版信息、图文混排结构。分层流水线架构通过职责分离,将这一复杂问题分解为多个可管理的子问题。
每一层专注于解决特定类型的复杂性,层与层之间通过定义清晰的接口交互,使得系统既易于理解,又便于扩展。当某个处理环节出现问题时,我们可以快速定位到问题所在的层级,而不是在整个系统中大海捞针。
这种设计也体现了软件工程的核心原则:高内聚、低耦合。每个层级都有明确的职责,层级内部高度内聚,层级之间通过接口松散耦合。这不仅使得代码易于维护,也为后续的功能扩展奠定了基础。
5.2 VML到DrawingML转换的必要性
VML(Vector Markup Language)是早期Office版本使用的矢量图形描述语言,而DrawingML是现代Office的默认格式。许多企业环境中仍存在大量使用旧版Office创建的DOCX文档,这些文档内部使用VML描述图片和形状。如果不进行格式转换,现代的文档解析工具(如Docling)可能无法正确识别和提取这些文档中的图片。
通过Pandoc进行VML到DrawingML的转换,确保了这些"数字遗产"能够在现代RAG系统中得到正确处理。这提醒我们,在企业级应用中,兼容性和向前兼容性是永恒的主题。我们不能假设所有输入都是"新鲜"的文档,必须考虑到历史遗留资产的长期价值。
5.3 父子块结构:RAG性能的倍增器
父子块结构的设计是对RAG系统"检索-生成"两阶段特性的深度洞察。传统单一层级的分块策略面临着两难困境:小块有利于检索精度但不利于生成质量(上下文不足),大块有利于生成质量但不利于检索精度(召回率低)。
父子块结构通过双层级存储巧妙地化解了这一矛盾:检索阶段使用小块确保高精度召回,生成阶段使用大块确保高质量生成。这种设计使得RAG系统能够同时达到高召回率和高生成质量,是实现生产级RAG应用的关键技术之一。
六、总结与实战建议
DOCX RAG的本质不是简单的文件解析,而是结构化信息的恢复与语义边界的重构。在开发此类系统时,建议关注以下三点:
-
重视预处理:不要信任任何原始文档的格式,Pandoc是你的好伙伴。在预处理阶段多花一点时间,可以避免后续环节中的大量麻烦。
-
优化分块粒度:父子块结构是目前解决"检索精度"与"生成质量"矛盾的最优解。根据实际业务需求调整子块和父块的大小,找到最适合你的场景的配置。
-
多模态预留:即使目前只做文本检索,也要在解析阶段把图片和表格位置保留下来。RAG技术发展迅速,多模态能力将成为标配,提前预留接口可以避免未来的重构成本。
项目源代码
完整的项目代码和更详细的实现,请访问我的知识星球( https://t.zsxq.com/CCi0k ),获取完整系统项目源代码。