
文章速览:本文深度解读Transformer-XL核心架构,拆解段级递归与相对位置编码两大创新,彻底解决传统Transformer上下文碎片化、长依赖建模失效难题,兼顾性能与效率,是长文本AI的奠基性工作。
一、开篇痛点:长文本建模的"卡脖子"难题
在NLP领域,语言建模的核心目标,是让机器读懂文本里的长期依赖关系------跨越句子、段落甚至章节的语义关联,一直是模型能力的分水岭。
但传统模型始终绕不开两大致命缺陷:
-
RNN/LSTM系列:深陷梯度消失/爆炸困境,即便优化后的LSTM,实际仅能有效记忆200个左右词汇,长文本直接"断片";
-
标准Transformer:依赖固定长度上下文窗口,强行切割长文本,完全无视语义边界,引发上下文碎片化,序列开头缺乏前文支撑,预测偏差极大。
要么记不住,要么记不全,长文本建模陷入僵局。直到Transformer-XL的出现,用极简架构打破了这一困局。
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 论文核心信息 📄 标题:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context 👥 作者:Zihang Dai、Zhilin Yang 等(卡内基梅隆大学、Google Brain) 🔗 原文:https://arxiv.org/pdf/1901.02860 💻 源码:https://github.com/kimiyoung/transformer-xl |
二、核心贡献:两大创新,破局长依赖建模
Transformer-XL没有推翻Transformer架构,而是做了两项关键改进,既保留自注意力优势,又彻底突破长度限制,同时解决效率痛点。
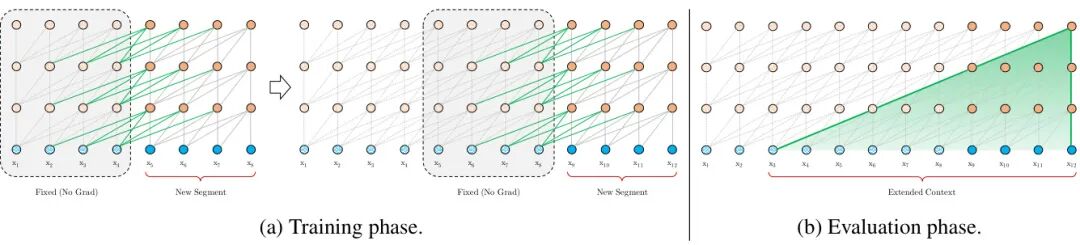
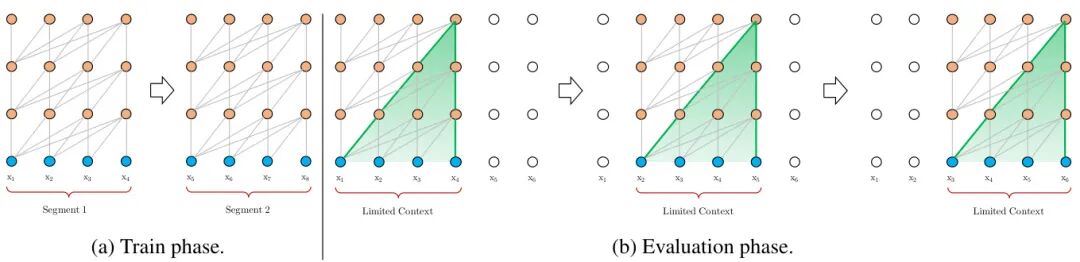
✅ 创新1:段级递归机制------让历史信息"流动"起来
这是Transformer-XL突破长度限制的核心设计。不同于传统Transformer逐段独立计算、丢弃历史信息,Transformer-XL引入段间递归:
处理新文本段时,复用前一段的隐藏状态作为额外上下文,将前序段落的信息缓存为"记忆",与当前段建立递归连接。
这种设计带来三大好处:
-
彻底摆脱固定长度束缚,上下文可无限延伸;
-
根治上下文碎片化,保留完整语义连贯性;
-
缓存状态复用,避免重复计算,大幅提升推理效率。
✅ 创新2:相对位置编码------杜绝时序混乱
复用历史状态会引发新问题:传统绝对位置编码会导致段间位置号重复、时序错乱。
Transformer-XL直接抛弃绝对位置,改用相对位置编码:只关注词汇间的相对距离,而非绝对位置,让跨段位置信息保持一致。
优势远超传统方案:
-
解决递归带来的位置混淆,保证时序连贯;
-
泛化能力更强,可适配远超训练长度的文本;
-
实证效果优于绝对位置编码,建模更精准。
|------------------------------------------------------------------|
| 架构一句话总结: Transformer-XL = 段级递归(突破长度)+ 相对位置编码(保证时序),二者协同实现超长依赖建模。 |
三、实验结果:性能+效率双碾压,数据说话
Transformer-XL在多大数据集上刷新SOTA,不仅效果拔尖,推理速度更是实现数量级突破。
📊 核心性能指标:全面领跑
-
WikiText-103数据集:困惑度从20.5降至18.3,刷新纪录,长文本建模能力大幅提升;
-
enwik8/text8字符级建模:拿下最优结果,12层模型仅用64层Transformer 17%的参数,实现同等性能;
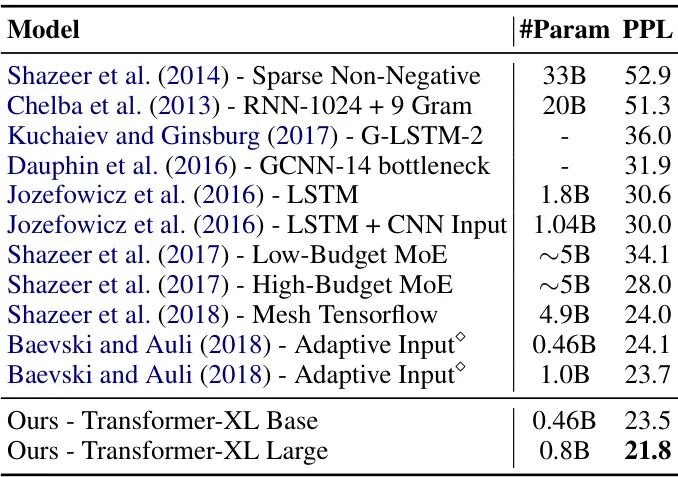
-
One Billion Word数据集:即便针对短依赖任务,仍将困惑度从23.7优化至21.8,通用性拉满;
-
RECL长依赖指标:有效上下文长度达900词,是标准Transformer的4.5倍、LSTM的1.8倍。

⚡ 效率突破:推理加速1800+倍
得益于状态缓存复用机制,长文本评估时效率暴增:
-
注意力长度3800时,速度提升1874倍;
-
单GPU即可轻松运行超长文本推理,落地门槛极低。

四、价值与应用:不止是论文,更是长文本AI基石
🔬 学术价值
Transformer-XL是首个在纯自注意力模型中,实现稳定长程依赖建模的架构,成为后续Longformer、GPT长上下文版本等模型的设计蓝本,重新定义了语言建模的上限。
💼 工业落地场景
-
长文本生成:小说、报告、论文、多轮对话续写;
-
文档理解:合同审核、财报分析、书籍精读;
-
代码建模:项目级超长代码理解、批量代码生成;
-
无监督特征学习:跨章节语义提取、长序列数据建模。
五、全文总结:抓住核心,一秒吃透
Transformer-XL用两项极简设计,解决了长文本建模的本质矛盾:
-
段级递归:打破固定长度枷锁,实现超长上下文记忆;
-
相对位置编码:保证时序连贯,杜绝位置信息混乱;
-
状态复用:推理效率暴增,兼顾性能与落地性;
-
连贯上下文:根治碎片化,真正读懂全文语义。
可以说,没有Transformer-XL,就没有如今主流大模型的长上下文能力,它是现代长文本AI不可或缺的奠基之作。
你在长文本建模、模型部署中遇到过哪些长度瓶颈?欢迎在评论区留言交流~
觉得干货满满,别忘了点赞+在看+转发,持续更新顶会论文精读!