大模型在生成内容时经常出现与给定上下文不一致、不相关的 "忠诚度幻觉",给检索增强生成、摘要等实际应用带来风险。现有检测方法要么依赖大型高级模型导致部署低效,要么像黑盒一样只给结果不给解释,还存在跨任务泛化差、训练数据质量低的问题。清华大学、复旦大学等机构联合提出了 FaithLens 模型,既能高效检测幻觉,又能给出清晰解释,完美平衡了可信度、效率和效果。
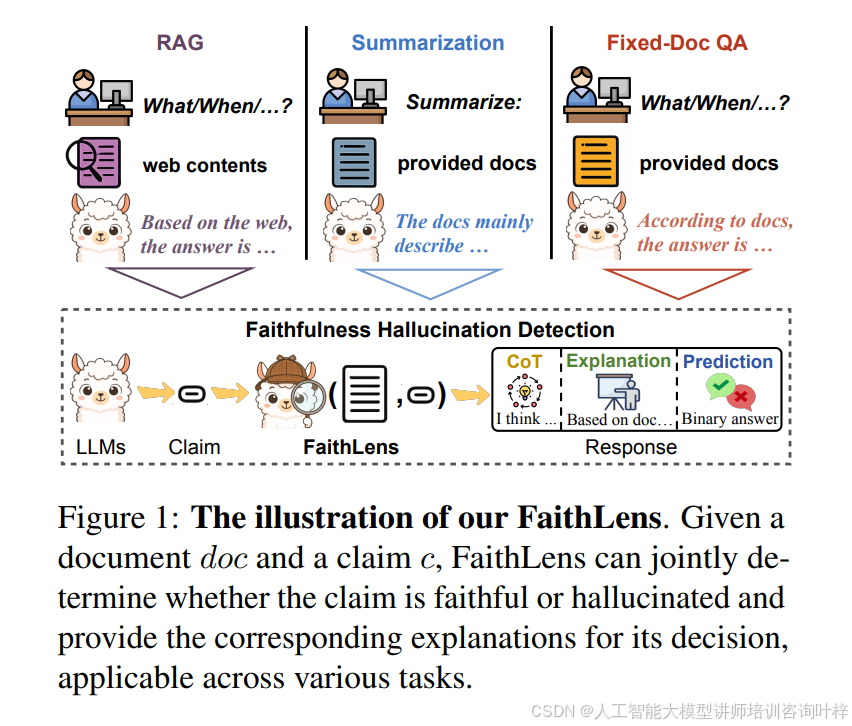
FaithLens 的核心逻辑很明确:先通过高质量数据训练打好基础,再用强化学习优化性能和解释质量。图 1展示了它的工作流程 ------ 给定文档和大模型生成的主张,模型不仅能给出 "忠实" 或 "幻觉" 的二分类结果,还能附上详细解释,适配摘要、RAG、固定文档问答等多种任务。
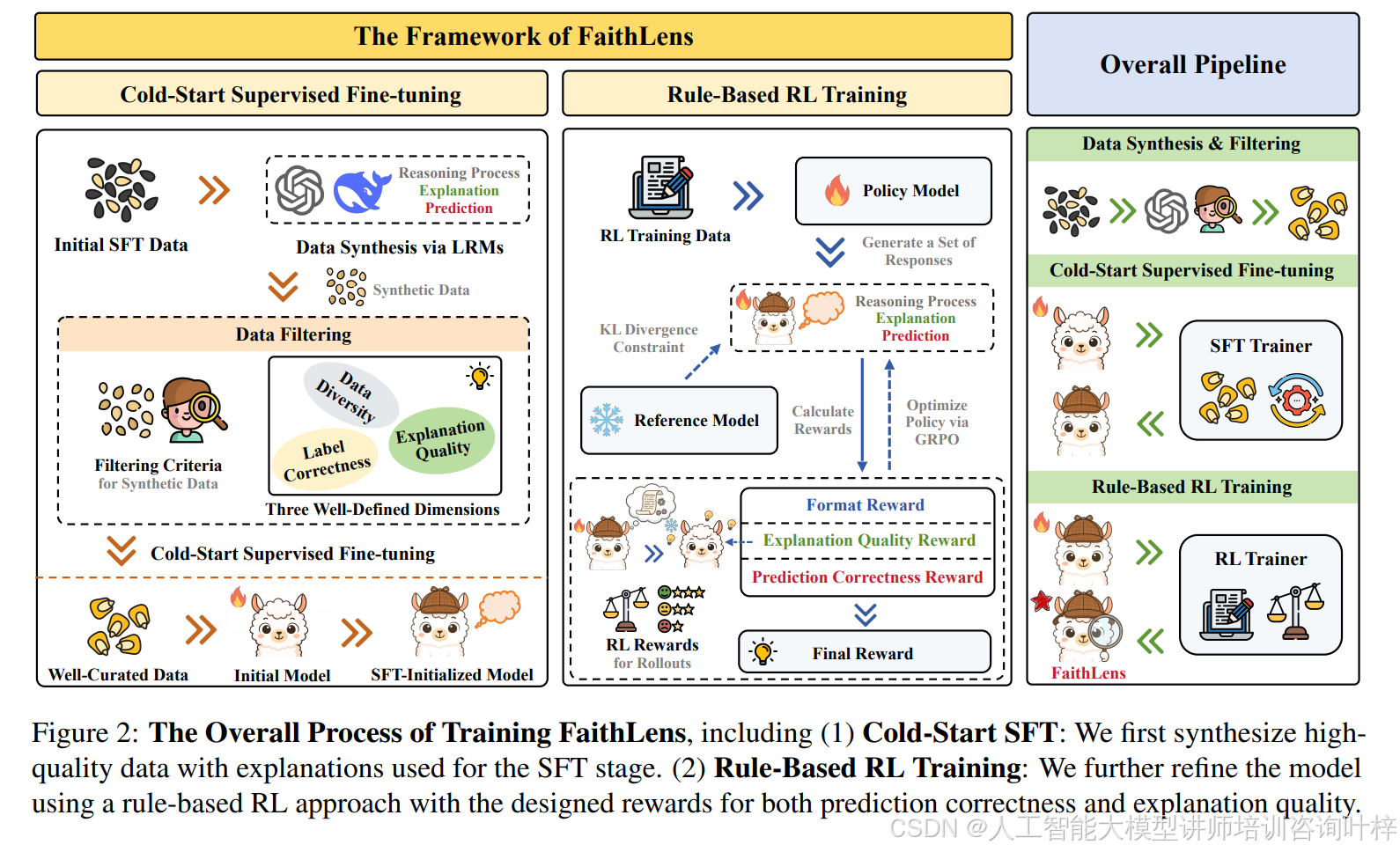
训练过程分为两大关键阶段,图 2:第一阶段是冷启动监督微调,先用 DeepSeek-V3.2-Think 这类高级推理模型,从开源数据集合成带解释的训练样本,每个样本都包含思维链、解释和预测标签。但合成数据难免有噪声,所以设计了三重过滤机制:先确保标签正确,剔除模型预测与真实标签不一致的样本;再验证解释质量,只有能降低训练模型对正确标签困惑度的解释才会保留;最后通过 K-Medoids 聚类保证数据多样性,避免模型只擅长简单场景。经过筛选的优质数据,能让模型快速掌握幻觉检测和解释生成能力。
第二阶段是基于规则的强化学习优化,采用 GRPO 算法不用额外训练奖励模型。设计了三重奖励机制:预测正确性奖励直接关联检测结果是否准确,解释质量奖励要看生成的解释能否帮助新手模型(如 Llama-3.1-8B-Inst)做出正确判断,格式奖励则确保输出符合规范。三重奖励共同作用,让模型在提升检测性能的同时,保持解释的连贯性和信息量。
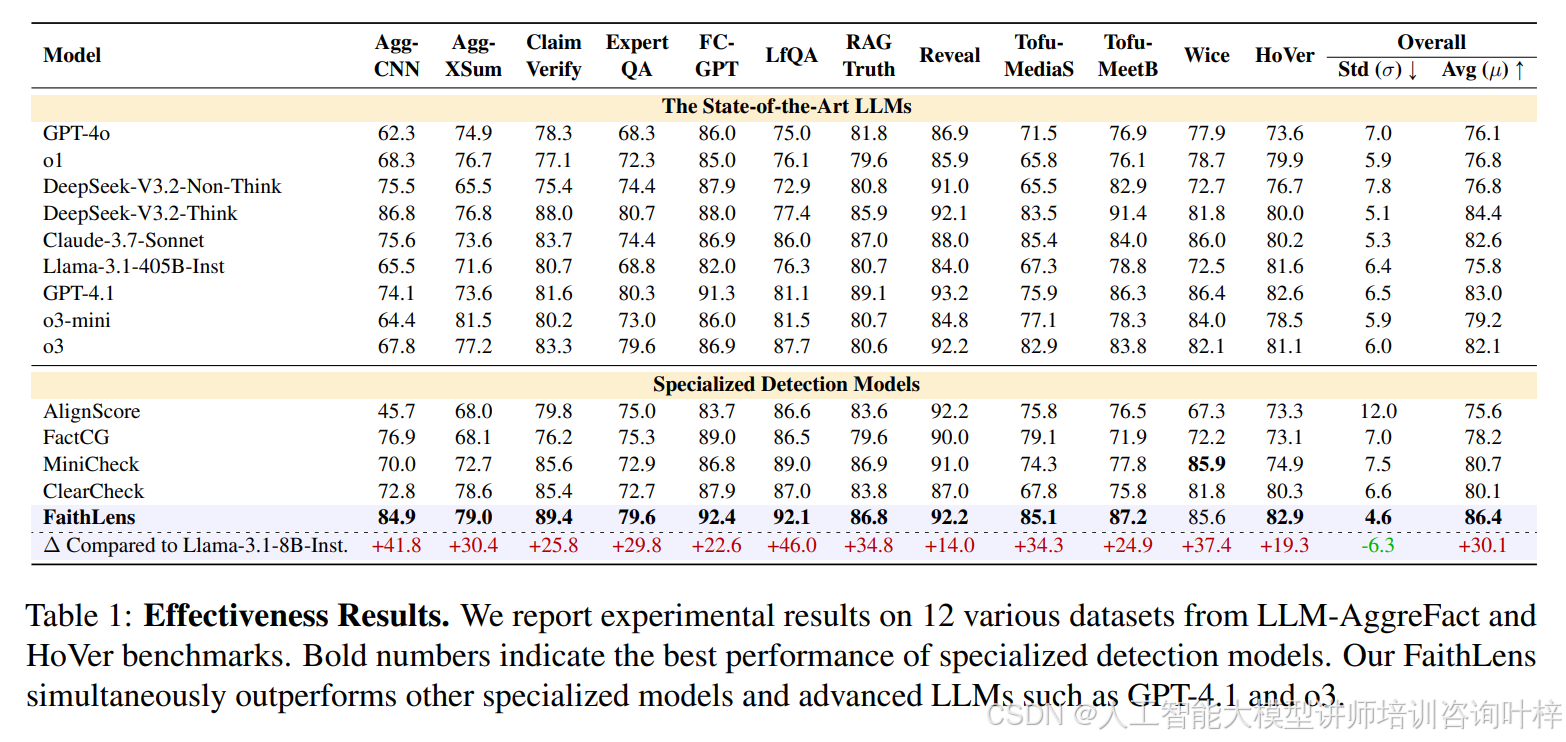
实验结果让人眼前一亮,表 1显示,8B 参数的 FaithLens 在 LLM-AggreFact 的 11 个跨任务场景和 HoVer 的多跳推理任务中,整体表现超越了 GPT-4.1、o3 等高级大模型,而且标准差最低,跨任务性能最稳定。在解释质量上,表 2用可读性、帮助性、信息量三个维度评估,FaithLens 平均得分 90.4,远超 ClearCheck 等专用检测模型,甚至能和 GPT-4o 等顶尖模型掰手腕。
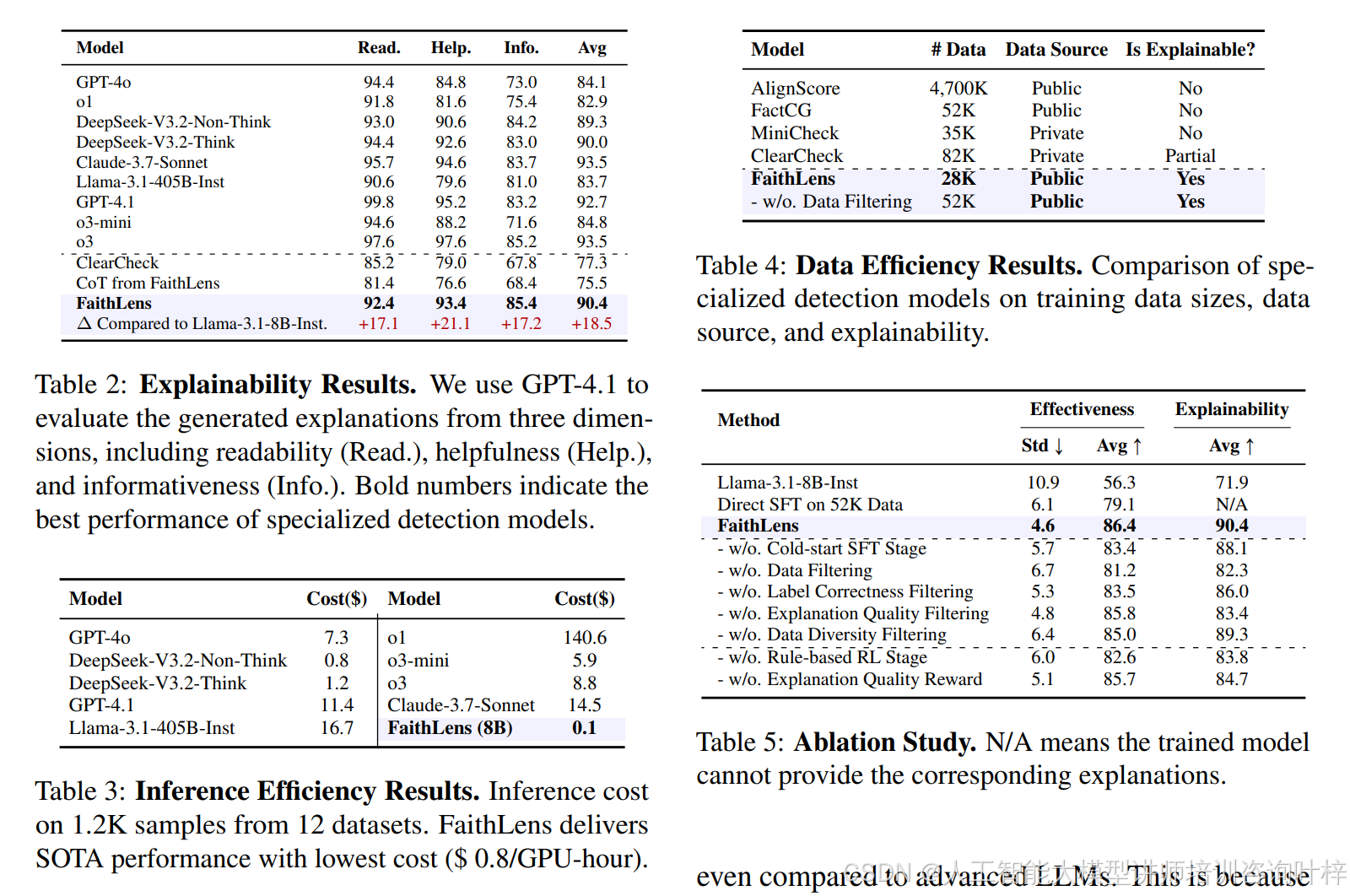
效率方面更是 FaithLens 的强项,表 3显示它处理 1.2K 样本的推理成本仅 0.1 美元,远低于 GPT-4o 的 7.3 美元和 GPT-4.1 的 11.4 美元,表 4还证明它只用 28K 公开数据,就能实现比依赖私有数据的模型更优的效果,数据利用率极高。消融实验(表 5)进一步验证了各组件的必要性:去掉数据过滤会让效果下降 5.2 个百分点,缺少强化学习阶段则会损失 3.8 个百分点,解释质量奖励对提升解释可读性和帮助性至关重要。
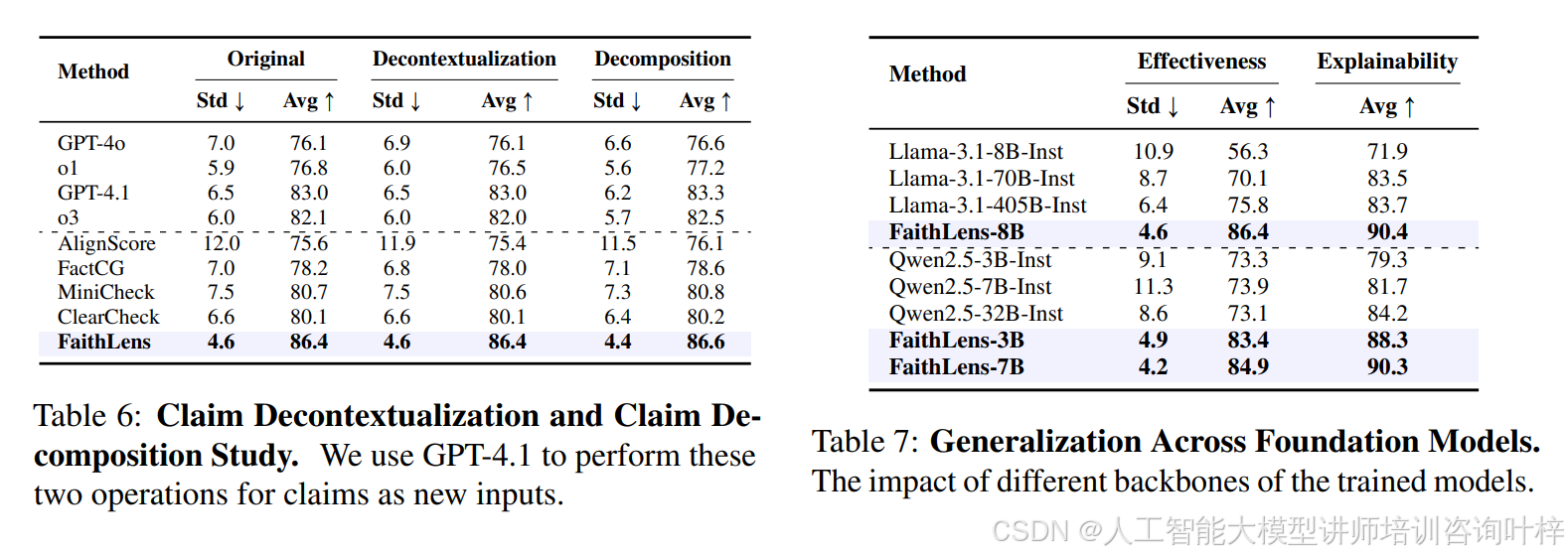
值得一提的是,FaithLens 的泛化能力极强,表 7显示无论是基于 Llama-3.1 还是 Qwen2.5 系列模型作为基座,经过它的训练流程后,性能都能显著提升。而且不需要对主张进行去语境化处理(表 6),模型自身就能捕捉上下文依赖关系,若配合主张分解将复杂主张拆分为原子事实,还能进一步提升检测精度。
实际案例更能体现解释优势:在涉及《联邦兰哈姆法案》和《联邦贸易委员会法案》的幻觉检测中,FaithLens 不仅指出《兰哈姆法案》未被文档提及,还列举了文档中提到的其他相关法案作为佐证;在判断《猫和老鼠:胡桃夹子的传说》相关主张时,会明确区分 "影片属于动画" 这一正确信息和 "1940 年上映" 这一幻觉点,解释逻辑远超 GPT-4o 和 o1 的简单判断。
当然 FaithLens 也有局限,目前只支持文本领域的幻觉检测,不涉及多模态场景,而且生成思维链、解释和标签的顺序流程,会比只输出标签的模型多一点推理开销。不过这些不影响它成为当前最实用的幻觉检测工具之一。