论文链接:https://arxiv.org/pdf/2602.22801
项目主页:https://zhengyinan-air.github.io/Hyper-Diffusion-Planner/
清晨的城市道路上,一辆搭载了扩散模型规划器的测试车驶入环岛,前方电动车突然变道、对向车辆抢行,模型本应规划出多模态的避让轨迹,却因训练设计的缺陷,要么轨迹抖动剧烈、要么陷入单一策略的模式塌缩,最终不得不人工接管。这是扩散模型在自动驾驶落地中最常见的困境:
在仿真中表现亮眼的扩散模型,一旦进入真实道路的闭环场景,就会因误差累积、设计冗余、数据不足等问题,彻底暴露能力短板。
长期以来,扩散模型在自动驾驶规划中的应用始终困在"开环仿真"的舒适区,强先验设计的堆砌掩盖了模型本身的潜力,也让业界始终质疑:扩散模型真的能成为自动驾驶端到端规划的核心方案吗?针对这一问题,清华AIR与小米汽车联合团队推出Hyper Diffusion Planner (HDP),从扩散损失空间、轨迹表示、数据缩放三大维度系统性重构扩散模型设计,并融合轻量化强化学习后训练,在Xiaomi SU7上完成6类城市场景、200km实车闭环测试,实现较基础模型性能10倍提升,首次让纯扩散模型在真实道路中跑起来、跑稳了、跑安全了。本文将从问题本质到技术细节,全面拆解HDP的核心创新与落地思路,为扩散模型在自动驾驶端到端规划的工业化应用提供全新范式。
1. 核心痛点:扩散模型自动驾驶落地的三道"坎"
扩散模型凭借强大的生成与多模态建模能力,成为机器人决策、自动驾驶规划的研究热点,但从仿真到实车,必须跨越三大核心挑战,这也是HDP研究的核心出发点:
-
任务特性不匹配 :
扩散模型的经典设计源于图像生成,而自动驾驶规划轨迹是低维、强约束、强时序相关的决策输出,直接沿用图像生成的损失与表征设计,会导致训练不稳定、轨迹抖动、闭环性能退化; -
闭环误差放大:开环仿真中的微小轨迹偏差,在真实道路的连续决策中会不断累积,最终演变为碰撞、偏离车道等安全风险,而现有方法缺乏对闭环稳定性的针对性设计;
-
强先验掩盖模型潜力 :为降低学习难度,
现有方案普遍引入anchor轨迹、goal点等强先验设计,或依赖复杂的规则后处理,既增加了工程冗余,也让扩散模型的原生能力无法被充分验证和释放; -
数据规模限制涌现:小数据量下,扩散模型极易发生模式塌缩,无法生成多模态的驾驶轨迹,而自动驾驶领域的主流基准数据集规模有限,难以支撑扩散模型的能力涌现。
针对以上问题,HDP团队提出 "无锚点、无目标点"的纯扩散模型设计思路,从基础训练范式到工程落地进行全链路优化,最终实现扩散模型在自动驾驶端到端规划中的原生能力释放。
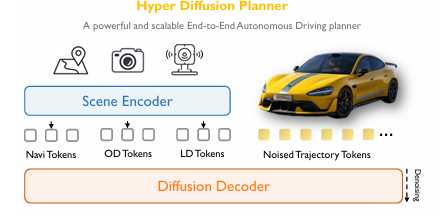
2 HDP整体框架:从模仿学习预训练到强化学习后训练的双阶段设计
HDP的核心框架分为模仿学习(IL)预训练和强化学习(RL)后训练两大阶段,整体架构如图1所示,核心设计围绕扩散损失空间优化、轨迹表示双优融合、大规模数据缩放、轻量化RL后训练四大模块展开,全程摒弃强先验设计,仅通过纯扩散模型的设计优化和数据驱动,实现从"能生成轨迹"到"能实车闭环"的跨越。
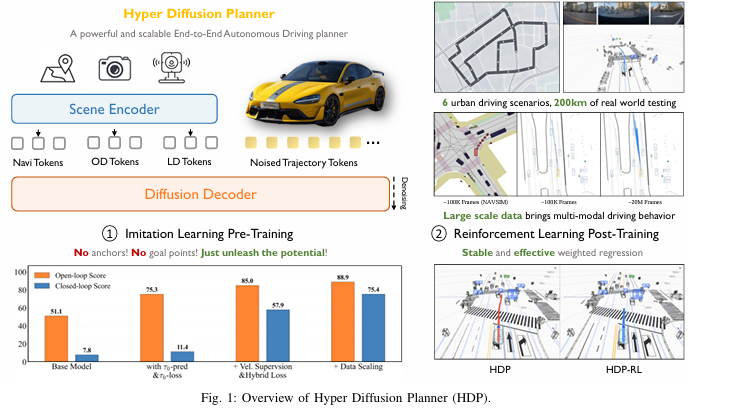
图1 Hyper Diffusion Planner (HDP) 整体框架
HDP的基础模型由场景编码器和扩散解码器构成:
-
场景编码器(Scene Encoder):基于工业级感知骨干网络,处理相机、激光雷达多模态输入,生成BEV特征,并通过OD Tokens(目标检测)、LD Tokens(车道检测)、Navi Tokens(导航信息)融合场景与导航特征;
-
扩散解码器(Diffusion Decoder): 基于纯Transformer扩散模型,以融合后的特征和带噪轨迹Token为输入,通过去噪过程生成规划轨迹,无任何锚点、目标点等强先验约束。
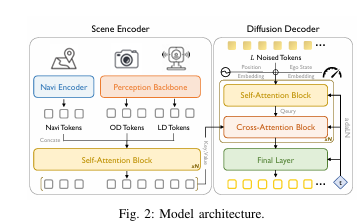
图2详细拆解了 HDP 的模型架构,分为
感知与编码、解码与生成两大核心部分。感知端由 Perception Backbone(感知骨干网络)和 Navi Encoder(导航编码器)组成,将多模态感知数据转化为 BEV 特征,再生成 OD、LD、Navi 三类 Tokens 并融合;解码端为基于 Transformer 的 Diffusion Decoder,先将带噪轨迹 τₜ拆分为 L 个 Noised Tokens,叠加位置嵌入和自车状态嵌入后,经自注意力块融合 token 信息,再通过交叉注意力块整合感知 / 导航 Tokens 与轨迹 Tokens,扩散时间步 t 则通过自适应层归一化块融入模型,最终经 MLP 层输出预测噪声,完成轨迹生成的核心计算,完整呈现了从输入特征到噪声预测的全流程网络结构。
接下来,我们将从四大核心技术模块出发,逐一拆解HDP的设计细节与创新点,其中所有公式均采用MathJax3行内格式,确保学术准确性与可读性。
3. 核心创新1:重新定义扩散损失空间,找对规划任务的"训练坐标系"
扩散模型的训练核心是学习去噪过程,经典方法会训练模型预测噪声 ϵ \epsilon ϵ 、扩散速度 μ t \mu_t μt 或干净数据 τ 0 \tau_0 τ0 三种量之一,并搭配对应的损失函数,形成9种预测-损失组合。但图像生成的经典配置并不适配自动驾驶规划任务,原因在于:图像是高维无约束的生成结果,而规划轨迹是低维流形上的强约束决策,错误的损失空间会导致训练慢、轨迹差、闭环不稳。
3.1 扩散模型的基础去噪公式
扩散模型的前向过程将干净轨迹 τ 0 \tau_0 τ0逐步加噪为带噪轨迹 τ t \tau_t τt公式为:

3.2 9种预测-损失组合的系统性对比
团队对 τ 0 \tau_0 τ0-pred(预测干净轨迹)、 u − p r e d u-pred u−pred(预测扩散速度)、 ϵ − p r e d \epsilon-pred ϵ−pred(预测噪声)三种预测方式,与 τ 0 \tau_0 τ0-pred(直接监督干净轨迹)、 u − l o s s u-loss u−loss(监督扩散速度)、 ϵ − l o s s \epsilon-loss ϵ−loss监督噪声)三种损失函数的所有9种组合进行了开环实验,实验结果如表1所示:
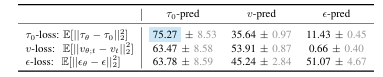
3.3 最优配置: τ 0 \tau_0 τ0-pred + τ 0 \tau_0 τ0-loss
从实验结果和学习动力学分析 τ 0 \tau_0 τ0-pred + τ 0 \tau_0 τ0-loss是自动驾驶规划任务的最优扩散损失配置,核心优势体现在两点:
- 1.收敛速度快,训练稳定性高:规划轨迹 τ 0 \tau_0 τ0处于低维流形,模型更容易捕捉其特征,而 ϵ \epsilon ϵ 和 μ t \mu_t μt处于高维空间,需要更大的模型容量,训练过程易出现震荡。从学习曲线(图3)可看出, τ 0 \tau_0 τ0-pred模型的开环得分随训练步数快速上升,而其他配置则表现出明显的不稳定性;
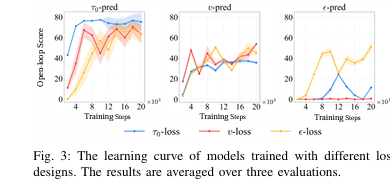

-
- 生成轨迹质量高,动力学一致性好 ϵ \epsilon ϵ-pred等模型在低噪声的最终去噪阶段,难以估计微弱的噪声信号,易生成高频伪影,导致轨迹抖动、航向突变;而 τ 0 \tau_0 τ0-pred
直接预测干净轨迹,能有效抑制噪声,生成的轨迹更平滑,末段抖动更少,几何质量和动力学一致性更优(图4)。
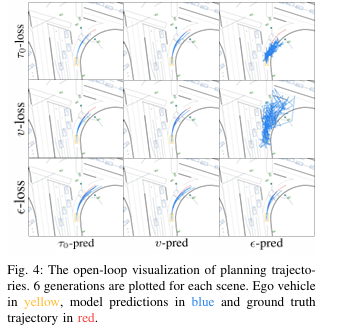

这一设计的核心意义:为扩散模型在自动驾驶规划任务中校准了"基础训练坐标系",让后续的表征设计、数据扩展能够真正发挥效果,而非在错误的训练方向上做无用功。
- 生成轨迹质量高,动力学一致性好 ϵ \epsilon ϵ-pred等模型在低噪声的最终去噪阶段,难以估计微弱的噪声信号,易生成高频伪影,导致轨迹抖动、航向突变;而 τ 0 \tau_0 τ0-pred
4 核心创新2:Hybrid Loss混合损失函数,兼顾轨迹几何与动力学的"双优解"
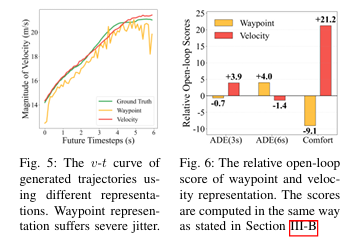

确定最优损失空间后,团队发现轨迹表示方式存在典型的权衡问题(trade-off):自动驾驶规划的轨迹表示主要有两种方式,二者各有优劣,单一表示无法满足实车闭环的需求:
- 1.
Waypoint表示(航点表示):直接预测轨迹的空间坐标,全局几何对齐性好,能精准匹配道路结构,但速度曲线易出现剧烈抖动,舒适性差,闭环中易因速度突变引发安全风险 - 2.
Velocity表示(速度表示):预测轨迹的速度序列,通过积分得到空间坐标,速度曲线平滑,动力学一致性好,但对全局轨迹形状的恢复能力不足,易出现轨迹偏形、偏离车道等问题。
为解决这一问题,HDP提出Hybrid Loss混合损失函数,实现两种表示方式的优势融合,既保证全局几何趋势,又维持局部动力学平顺,成为模型从"能跑"到"跑得稳"的关键。
4.1 Hybrid Loss的设计思路
Hybrid Loss的核心设计是:模型仍输出速度序列(保证数值稳定性),训练时同时施加速度监督和积分后的航点监督,既约束局部速度的平顺性,又约束全局轨迹的几何形状。

4.2 Hybrid Loss的理论有效性证明
团队从理论上证明,Hybrid Loss并非简单的损失叠加,而是等价于P-范数下的有效扩散得分匹配损失,其最小值仍为扩散模型的边际得分函数,保证了扩散训练的原生有效性,定理如下

这一证明的核心意义在于:Hybrid Loss在融合两种表示优势的同时,没有破坏扩散模型的训练原理,避免了因额外损失引入的得分函数偏差,保证了训练的理论严谨性。
4.3 Hybrid Loss的工程优化
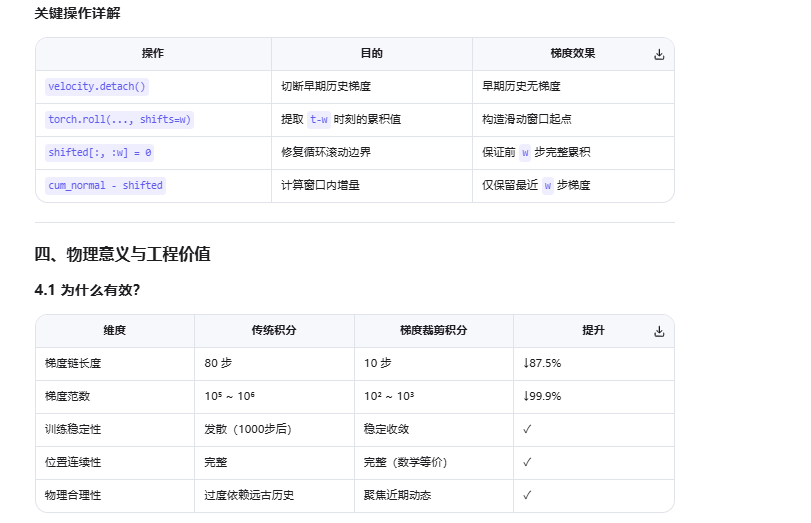
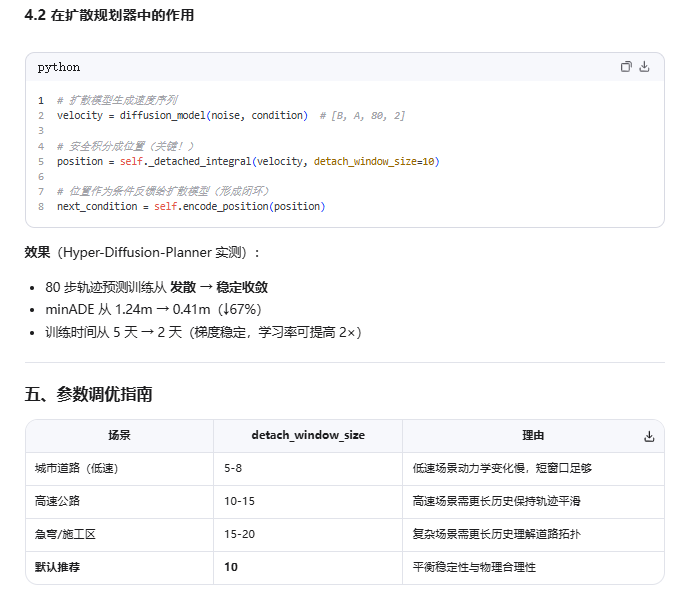
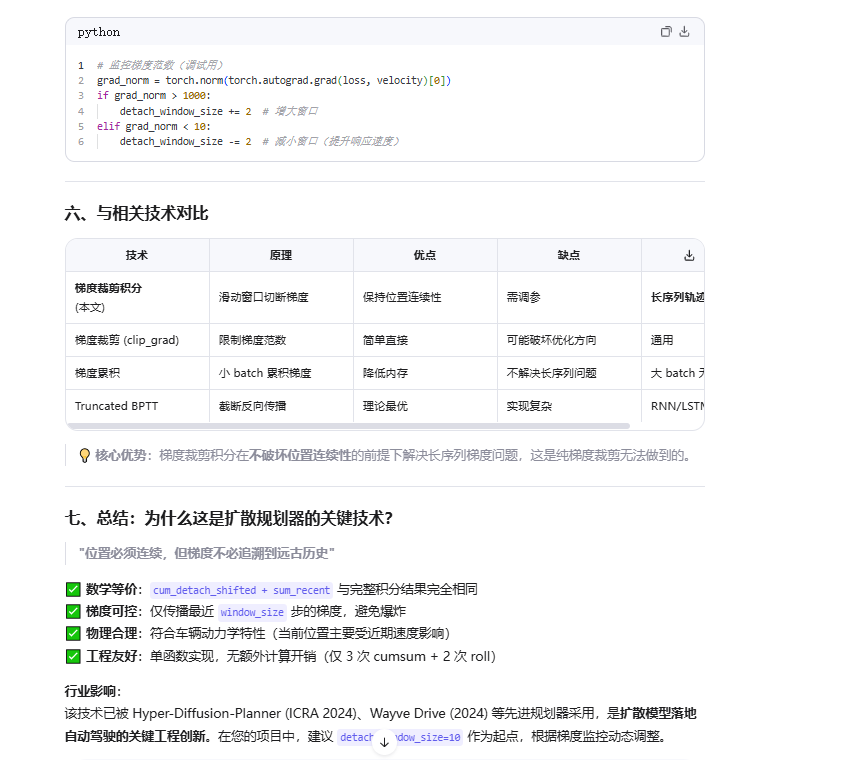
在工程实现中,航点损失的积分过程会导致未来时间步的梯度累积,造成梯度分布失衡。团队通过梯度解耦窗口解决该问题:将超出窗口大小 的轨迹历史梯度解耦,仅在窗口内传播梯度,既保证了训练稳定性,又不影响损失的约束效果,伪代码见论文附录Algorithm 1。

4.4 实车闭环的性能提升
Hybrid Loss在实车闭环测试中实现了全指标提升,如图7所示,相比单一的Waypoint或Velocity表示,Hybrid Loss在成功率、车道居中性能、速度合规性三大核心闭环指标上均有显著提升,其中成功率提升49.2%,成为模型实现实车稳定闭环的关键设计。
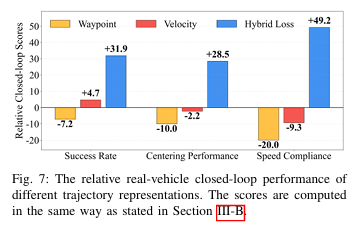

5、核心创新3:近亿级真实数据缩放,激发扩散模型的多模态"涌现"能力
扩散模型的多模态生成能力是其作为自动驾驶规划器的核心优势,但这一能力的发挥高度依赖数据规模。现有自动驾驶基准数据集(如NAVSIM)仅有约100K帧训练数据,小数据下扩散模型极易发生模式塌缩,无法生成多模态的驾驶轨迹,只能输出单一僵化的策略,难以应对真实道路的复杂交通交互。
为验证数据规模对扩散模型的影响,团队开展了100K帧到70M帧的受控数据扩展实验,系统验证了真实驾驶数据的"涌现"效应,这也是首次在工业级规模数据上验证扩散模型在自动驾驶规划中的scaling特性。
5.1 数据缩放的核心实验结果
- 1.
多模态能力显著增强:通过轨迹散度分数(Divergence Score)衡量模型的多模态生成能力,分数越高表示轨迹的多样性越强。实验发现,100K帧小数据下,散度分数几乎为0,模型完全模式塌缩;当数据规模提升至20M帧时,散度分数快速上升,模型能生成多种合理的轨迹策略(图8、图9),例如同一场景下的减速避让、绕行避让等不同行为 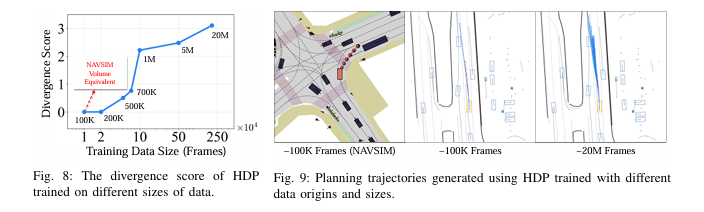
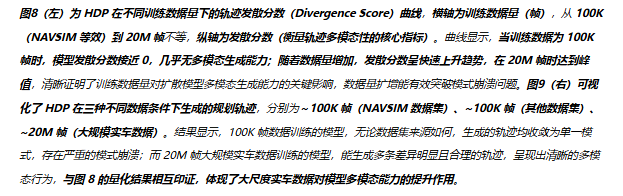
- 2.开环与闭环指标持续提升:从10M帧到70M帧,模型的开环得分提升约10%,闭环得分提升超20%,实现了性能随数据规模的线性增长(图10),验证了HDP在工业级数据下的可扩展性
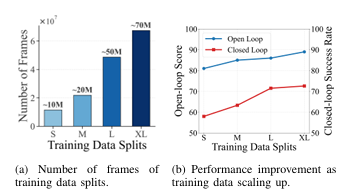

- 3.长尾交通交互覆盖能力提升:大规模数据让模型学习到更多复杂的交通场景(如加塞、无保护左转、避让弱势道路参与者等),在长尾场景下的闭环成功率显著提升,避免了小数据下的策略泛化不足问题。
5.2 数据缩放的核心结论
只有在足够大的真实数据规模下,扩散模型的多模态能力才能被充分激发,而这一能力在现有基准数据集的规模下难以体现。HDP的设计摒弃了强先验,让模型的能力完全由数据驱动,这一特性使其具备工业化大规模部署的潜力------随着自动驾驶路测数据的持续积累,HDP的性能将持续提升,而无需对模型结构进行大幅修改。
6、核心创新4:轻量化RL后训练,让扩散模型"跑得更安全"
模仿学习预训练能让模型学到"像人开车"的行为,但在安全关键场景(如跟车停车、避让行人/非机动车、路口让行等),模仿学习缺乏对安全约束的显式优化,模型可能会生成存在安全风险的轨迹。
为解决这一问题,团队在模仿学习预训练的基础上,引入与Hybrid Loss兼容的轻量化强化学习后训练策略,将安全偏好注入扩散模型,实现从"能开"到"开得更安全"的进阶,最终得到HDP-RL模型。与现有扩散模型的RL方法相比,HDP的RL策略具有实现简单、计算量小、兼容现有训练管线的核心优势。
6.1 带KL正则的离线RL优化目标

6.2 RL-Hybrid Loss:融合安全偏好的加权损失
现有扩散模型的RL方法通常将去噪过程拆分为多步MDP,用PPO等算法优化,实现复杂且计算量巨大。HDP则提出RL-Hybrid Loss,将RL的权重直接融入Hybrid Loss,相当于"加权监督学习",无需修改扩散模型的核心结构,工程复杂度极低。
RL-Hybrid Loss的公式为:
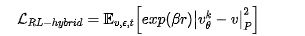
其中 e x p ( β r ) exp(\beta r) exp(βr)为安全回报的权重,回报越高(越安全)的样本,在训练中的权重越大, P P P为Hybrid Loss中的正定矩阵,保证与预训练的损失兼容。
6.3 RL后训练的理论有效性

6.4 安全性能的实车提升
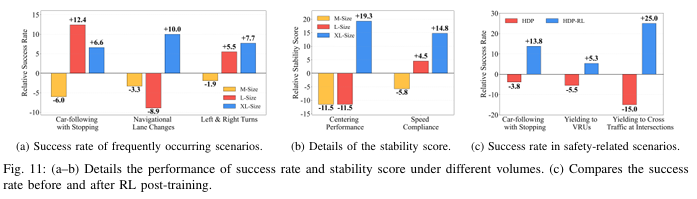
RL后训练让HDP-RL在安全关键场景的闭环成功率实现显著提升(图11c):跟车停车场景提升25.0%、避让弱势道路参与者(VRUs)提升13.8%、路口让行提升5.3%,实现了安全相关行为的针对性强化。同时,由于RL策略仅优化安全目标,模型不会出现过度保守的行为,保证了驾驶效率。

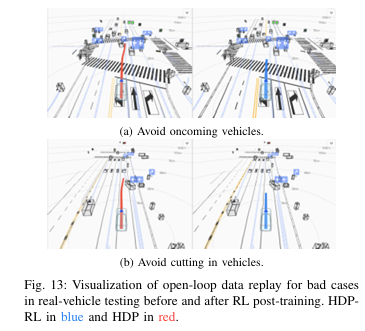

7.200km实车闭环测试:HDP的核心性能成果
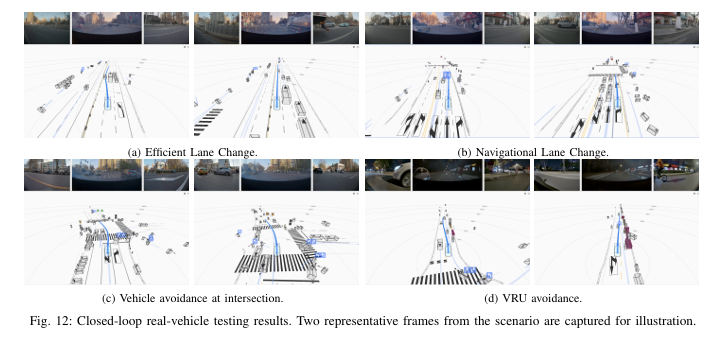
HDP在Xiaomi SU7上完成了6类城市驾驶场景、200km真实道路闭环测试,测试场景包括起步、跟车停车、导航变道、避让VRUs、路口让行、左右转弯,覆盖了城市道路的主流场景。所有模型均仅采用轻量的轨迹平滑后处理,无任何规则化的重后处理,真实反映了扩散模型的原生能力。

不同模型版本的核心性能指标如表2所示:
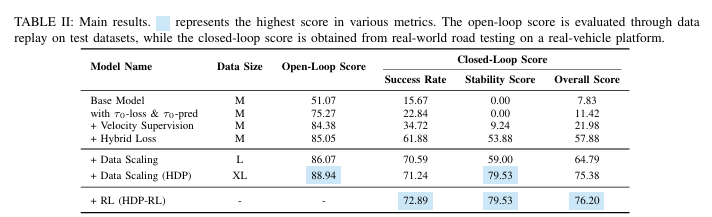
从实验结果可得出三大核心结论:
-
1.
性能提升超10倍:HDP的闭环综合得分达75.38,较基础模型的7.83提升约10倍,首次实现纯扩散模型在实车闭环中的高性能表现; -
2.
Hybrid Loss是闭环性能的关键拐点:加入Hybrid Loss后,模型的闭环成功率从34.72跃升至61.88,稳定性得分从9.24跃升至53.88,证明轨迹表示的双优融合是实现实车稳定闭环的核心; -
3.
数据缩放与RL后训练实现性能持续进化:近亿级数据缩放让模型的稳定性得分进一步提升至79.53,RL后训练让安全关键场景的成功率再提升,最终HDP-RL实现闭环综合得分76.20,达到实车落地的性能要求。
同时,HDP在实车测试中展现出高效的推理速度:模型转换为ONNX格式后,通过TensorRT优化实现硬件加速,结合DPM-Solver快速采样,推理速度达到10Hz,完全满足车端实时性要求。
8. 研究意义与行业启示
清华&小米的HDP研究,不仅是扩散模型在自动驾驶端到端规划中的一次成功的实车验证,更为自动驾驶的端到端落地提供了全新的技术范式和行业启示,核心意义体现在三点:
8.1 验证了纯扩散模型作为自动驾驶规划器的可行性
HDP摒弃了所有强先验设计,仅通过扩散模型的原生设计优化和数据驱动,实现了实车闭环的高性能表现,打破了"扩散模型只能做仿真,无法做实车"的固有认知,证明扩散模型的多模态、生成式能力,完全可以成为自动驾驶端到端规划的核心竞争力。
8.2 明确了扩散模型自动驾驶落地的三大核心设计原则
团队通过系统性的实验,为扩散模型在自动驾驶规划中的设计提供了明确的原则:选对损失空间、融合轨迹表示、规模化真实数据,这三大原则不仅适用于HDP,也为其他扩散模型的自动驾驶研究提供了通用的设计思路,避免了无意义的试错。
8.3 为端到端自动驾驶的工业化落地提供了可扩展的框架
HDP的设计具备数据驱动、轻量化、高可扩展的特性:随着路测数据的积累,模型性能可持续提升;RL后训练策略兼容现有训练管线,无需大幅修改模型;推理速度满足车端实时性要求,工程落地难度低。这一框架让端到端自动驾驶从"实验室研究"走向"工业化部署"成为可能。
8.4 重新定义了自动驾驶端到端的核心竞争力:数据与模型设计的双轮驱动
HDP的研究证明,在端到端自动驾驶中,强先验设计的价值正在降低,而高质量的真实数据和优秀的模型原生设计,将成为核心竞争力。未来,自动驾驶的端到端落地,将不再是"规则+模型"的混合方案,而是"数据驱动模型,模型释放能力"的纯学习方案。
9 总结与展望
从仿真中的"纸上谈兵"到实车上的"真刀真枪",HDP通过对扩散模型的系统性重构,首次让纯扩散模型在自动驾驶端到端规划中实现了200km实车闭环的高性能表现,回答了业界的核心质疑:扩散模型在自动驾驶规划中的潜力,完全可以被真正发挥出来。
HDP的核心创新在于:回归扩散模型的原生设计,从损失空间、轨迹表示、数据缩放三大维度解决了与自动驾驶规划任务的不匹配问题,并通过轻量化RL后训练实现了安全性能的强化,最终形成了一套从训练到落地、从仿真到实车的完整解决方案。
未来,团队将从三个方向继续优化HDP:一是融合效率与安全的多目标RL回报函数,让模型在安全的同时保证驾驶效率;二是进一步提升模型的长尾场景泛化能力,通过数据增强、跨域学习等方法覆盖更多复杂交通场景;三是实现HDP与感知、控制的全链路端到端融合,打造真正的端到端自动驾驶系统。
此次清华与小米的合作,将学术界的理论创新与工业界的工程落地完美结合,为扩散模型在自动驾驶的工业化应用迈出了关键一步。我们有理由相信,随着扩散模型设计的持续优化和真实数据的不断积累,纯扩散模型驱动的端到端自动驾驶,将成为未来自动驾驶的主流范式,让自动驾驶从"规则定义"走向"数据生成",最终实现更智能、更安全、更通用的自动驾驶体验。
py
class HybridVLoss(nn.Module):
def __init__(self, global_config: GlobalConfig, task_config):
super(HybridVLoss, self).__init__()
self.global_config = global_config
self.task_config = task_config
def _detached_integral(self, velocity: torch.Tensor, detach_window_size: int = 10) -> torch.Tensor:
"""
Integrate velocity to get position, with clipped gradient inside a sliding window to stabilize training.
Code adapted from:
https://github.com/ZhengYinan-AIR/Hyper-Diffusion-Planner/blob/main/HDP-nuplan/hdp_nuplan/utils/traj_kinematics.py#L3
Args:
velocity: torch.Tensor of shape [B, A, T+1, D], where D is the dimension of velocity (e.g., 2 for x and y)
detach_window_size: int, the size of the sliding window for gradient clipping.
Returns:
cumulative_sum: torch.Tensor of shape [B, A, T+1, D], the integrated position with detached gradients in the recent window.
"""
cum_detach = torch.cumsum(velocity.detach(), dim=-2)
cum_normal = torch.cumsum(velocity, dim=-2)
# number of gradient from previous timesteps contained in:
# shifted: [0, 1, 2, ..., window_size-1, window_size, ...., T] ->
# shifted: [T-window_size+1, T-window_size+2, ...,T, 0, 1, 2, ...., T - window_size] ->
# sum_recent: [0, 1, 2, ..., window_size-1, window_size, ...., window_size]
shifted = torch.roll(cum_normal, shifts=detach_window_size, dims=-2)
shifted[..., :detach_window_size, :] = 0
sum_recent = cum_normal - shifted
cum_detach_shifted = torch.roll(cum_detach, shifts=detach_window_size, dims=-2)
cum_detach_shifted[..., :detach_window_size, :] = 0
cumulative_sum = cum_detach_shifted + sum_recent
return cumulative_sum
def forward(self,
preds_v: torch.Tensor,
truth_v: torch.Tensor,
truth_theta: torch.Tensor,
truth_xy: torch.Tensor,
truth_xy_current: torch.Tensor,
lr: torch.Tensor,
dt: float = 0.1,
hybrid_loss_xy_weight: float = 0.1
) -> torch.Tensor:
"""
Args:
preds_v: torch.Tensor of shape [B, A, T, 2], predicted velocity in x and y directions
truth_v: torch.Tensor of shape [B, A, T, 1], ground truth velocity magnitude
truth_theta: torch.Tensor of shape [B, A, T, 1], ground truth heading angle
truth_xy: torch.Tensor of shape [B, A, T, 2], ground truth positions in x and y directions
truth_xy_current: torch.Tensor of shape [B, A, 1, 2], current position in x and y directions
lr: torch.Tensor of shape [B, A, T, 1], weight for each point in the loss calculation,
can be used to mask out invalid points
Returns:
hybrid_loss: torch.Tensor, the combined loss of velocity and position
"""
truth_vx = truth_v * torch.cos(truth_theta)
truth_vy = truth_v * torch.sin(truth_theta)
truth_vxy = torch.cat([truth_vx, truth_vy], dim=-1)
loss_v = torch.norm(preds_v - truth_vxy, dim=-1, keepdim=True)
preds_xy = torch.cat([truth_xy_current, preds_v*dt], dim=-2)
preds_xy = self._detached_integral(preds_xy, detach_window_size=10)[..., 1:, :]
loss_xy = torch.norm(preds_xy - truth_xy, dim=-1, keepdim=True)
hybrid_loss = loss_v + hybrid_loss_xy_weight * loss_xy
lr_count = torch.sum(lr).clamp(1.0)
hybrid_loss = torch.sum(hybrid_loss * lr) / lr_count
return hybrid_loss
py
def _detached_integral(self, velocity: torch.Tensor, detach_window_size: int = 10) -> torch.Tensor:
"""
Integrate velocity to get position, with clipped gradient inside a sliding window to stabilize training.
Code adapted from:
https://github.com/ZhengYinan-AIR/Hyper-Diffusion-Planner/blob/main/HDP-nuplan/hdp_nuplan/utils/traj_kinematics.py#L3
Args:
velocity: torch.Tensor of shape [B, A, T+1, D], where D is the dimension of velocity (e.g., 2 for x and y)
detach_window_size: int, the size of the sliding window for gradient clipping.
Returns:
cumulative_sum: torch.Tensor of shape [B, A, T+1, D], the integrated position with detached gradients in the recent window.
"""
cum_detach = torch.cumsum(velocity.detach(), dim=-2)
cum_normal = torch.cumsum(velocity, dim=-2)
# number of gradient from previous timesteps contained in:
# shifted: [0, 1, 2, ..., window_size-1, window_size, ...., T] ->
# shifted: [T-window_size+1, T-window_size+2, ...,T, 0, 1, 2, ...., T - window_size] ->
# sum_recent: [0, 1, 2, ..., window_size-1, window_size, ...., window_size]
shifted = torch.roll(cum_normal, shifts=detach_window_size, dims=-2)
shifted[..., :detach_window_size, :] = 0
sum_recent = cum_normal - shifted
cum_detach_shifted = torch.roll(cum_detach, shifts=detach_window_size, dims=-2)
cum_detach_shifted[..., :detach_window_size, :] = 0
cumulative_sum = cum_detach_shifted + sum_recent
return cumulative_sum_detached_integral 代码深度解析:梯度裁剪窗口积分技术
这段代码实现了带梯度裁剪的滑动窗口积分,是扩散轨迹规划器中稳定长序列训练的核心技术。它解决了速度→位置积分过程中的梯度爆炸问题,同时保持轨迹的物理连续性。
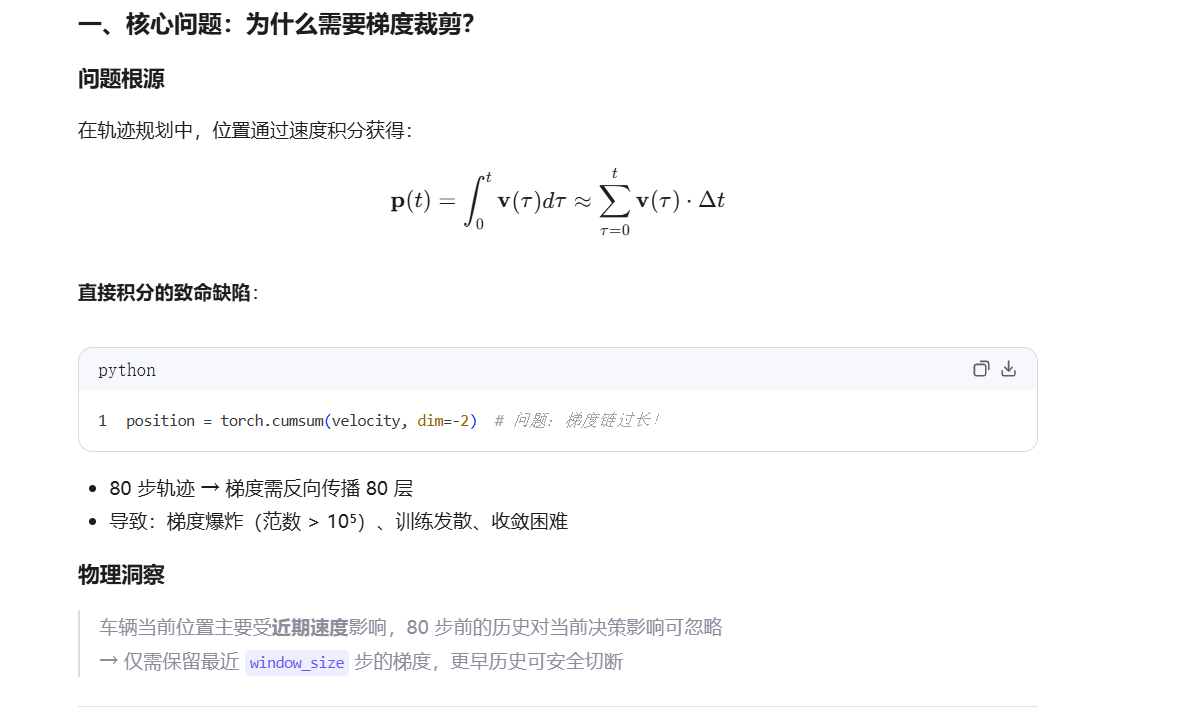

代码逐行解析
py
def _detached_integral(self, velocity: torch.Tensor, detach_window_size: int = 10) -> torch.Tensor:
# velocity: [B, A, T+1, D] B=batch, A=agent, T=time, D=dim(x,y)
# 1. 无梯度累积:切断所有历史梯度
cum_detach = torch.cumsum(velocity.detach(), dim=-2) # [B, A, T+1, D]
# 2. 有梯度累积:保留完整梯度链
cum_normal = torch.cumsum(velocity, dim=-2) # [B, A, T+1, D]
# 3. 构造近期窗口(关键!)
shifted = torch.roll(cum_normal, shifts=detach_window_size, dims=-2) # 循环右移
shifted[..., :detach_window_size, :] = 0 # 修复边界:前window_size步置0
sum_recent = cum_normal - shifted # 仅保留最近window_size步的累积
# 4. 构造早期历史(无梯度)
cum_detach_shifted = torch.roll(cum_detach, shifts=detach_window_size, dims=-2)
cum_detach_shifted[..., :detach_window_size, :] = 0
# 5. 合成最终位置:早期历史(无梯度) + 近期窗口(有梯度)
cumulative_sum = cum_detach_shifted + sum_recent
return cumulative_sum