原理
初版机制
我们先来看下,在网页搜索内容的过程是怎么样的。
首先,我们需要输入要搜索的查询词,比如,我们要搜索 "python 教程";然后,搜索引擎通过检索技术,搜索到以下标题的网页:【python 教程、python 项目、java 教程】,每个标题网页里,对应有标题相应的内容,分别是【python 语法...,python 贪吃蛇...,java 语法...】。
注意力机制和上述检索过程类似。在注意力机制中,有三个词:q,k,v;q 是我们要查询的词,对应上述在搜索引擎中输入的词:"python 教程",k 是搜索出来的网页标题;【python 教程、python 项目、java 教程】,v 是网页标题里的内容:【python 语法...,python 贪吃蛇...,java 语法...】。
我们会根据查询词和标题的相关性,分配不同的注意力分数,两者相关性越高,分配的注意力分数越高,qk.T 就是计算相关性;有了相关性之后,我们再根据相关性去读取网页里的内容,这个过程就是qk.T*v,可以理解和查询词相关性高的网页内容,我们要重点关注;和查询词相关性低的网页内容,我们要省略的浏览。
以上过程,就是一个粗略的注意力机制流程了。上面我们查询了一个词,如果我们要查询的词很多,就可以用向量 Q 来表示一组查询词。目前,我们得到的注意力机制公式是:
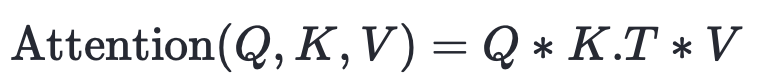
最终优化
但是,直接用上述公式会存在一些问题:
1、一个人的总注意力是固定的"1",但是 Q*K.T 计算出来的相关性权重和不一定是"1"
不止是权重和不一定是"1",根据Q*K.T 计算出来的权重数值差异,可能非常大,比如可能计算出来的有 1 和 1000,这种数值不稳定性,会影响训练过程的收敛;并且这种数值无法解释相关性权重分配,如查询词 "python 教程"和网页标题【python 教程、python 项目、java 教程】,计算出来的相关性权重为【1,0,0】,另一组查询词"吃饭"和网页标题【吃饭、睡觉、写代码】,计算出来的相关性权重为【100,0,0】,这两种情况,我们都应该是关注第 1 个标题的内容,但数值差异 100 倍,不合逻辑。
我们将QK.T 的值,通过 softmax 函数处理,就解决上述问题了,即 softmax(QK.T)。
2、如果上述向量维度 d_k 很大,Q*K.T 计算出来的差异会很大
我们假设 Q、K 中每个元素是独立随机变量,经过归一化或合理初始化后,均值为 0,方差为 1,向量维度为 d_k, 那么QK.T 中的元素,均值为 0,方差为 d_k。方差 d_k 越大,则元素差异也会越大。如有两组QK.T 的值,一组是 2.0,1.0,经过 softmax 处理后,输出 0.731,0.269;还有一组是 10.0,1.0,经过 softmax 处理后,输出 0.99988,0.00012。梯度接近 0,权重几乎不会再更新,停止学习。类比上述查询过程就是,针对权重接近为 0 的标题,我们几乎不会再去关注,也就停止学习过程了。
我们通过缩放,就可以解决这个问题了,将Q*K.T 的结果再除以根号 d_k。这样,我们就得到了最终的注意力机制公式:
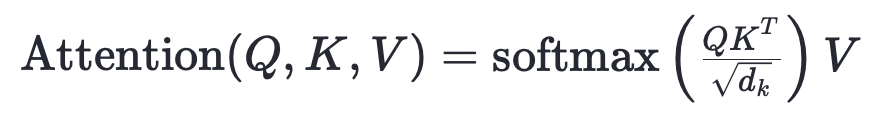
代码实现
python
import torch
import torch.nn.functional as F
import math
# 注意力机制的实现
def attention(q, k, v, dropout=None):
"""
q: query, shape (batch_size, seq_len, d_k)
k: key, shape (batch_size, seq_len, d_k)
v: value, shape (batch_size, seq_len, d_v)
dropout: nn.Dropout
"""
# 计算注意力分数
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(q.size(-1))
# 计算注意力权重
p_attn = F.softmax(scores, dim=-1)
# 应用dropout(如果有)
if dropout is not None:
p_attn = dropout(p_attn)
# 返回注意力输出
return torch.matmul(p_attn, v)
# 测试代码
if __name__ == "__main__":
print("=== 测试注意力机制 ===")
# 设置参数
batch_size = 2
seq_len = 10
d_k = 8
d_v = 8
# 创建dropout层
dropout = torch.nn.Dropout(0.1)
# 创建测试数据
q = torch.randn(batch_size, seq_len, d_k)
k = torch.randn(batch_size, seq_len, d_k)
v = torch.randn(batch_size, seq_len, d_v)
print(f"Q形状: {q.shape}")
print(f"K形状: {k.shape}")
print(f"V形状: {v.shape}")
# 调用attention函数
output = attention(q, k, v, dropout=dropout)
print(f"输出形状: {output.shape}")
print("测试完成!")