
1、什么是常量 什么是变量 整形常量的写法 (八进制 进制 十进制分别怎么表示) 浮点数常量的写法。
-
常量 :在程序运行过程中,其值不能被改变的量。例如:
5、3.14、'a'都是常量。 -
变量 :在程序运行过程中,其值可以改变的量。变量必须有一个名字(标识符)和数据类型,用来存储数据。例如:
int a = 10;中的a就是变量。
整型常量的写法
整型常量可以用三种进制表示:
-
十进制 :普通数字,如
123、-456。 -
八进制 :以
0开头,如0123(相当于十进制83)。 -
十六进制 :以
0x或0X开头,如0x1A(相当于十进制26)。
|---------|--------------------------------|------------------------|
| 二进制 | 以 0b 或 0B 开头,后面跟二进制数字(0和1) | 0b1010(=10) -0B111 |
注意 :二进制表示并非所有编程语言都支持。在C语言中,它是某些编译器的扩展(如GCC);在C++14及以后的标准中,
0b前缀已成为官方语法。







题目
-
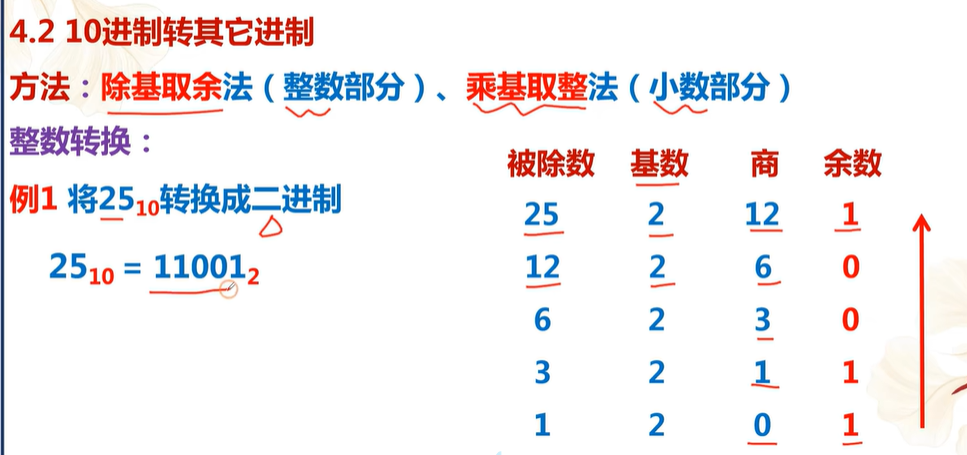
二进制转十进制 :将二进制数
101101转换为十进制。 -
十进制转二进制 :将十进制数
89转换为二进制。 -
八进制转十进制 :将八进制数
237转换为十进制。 -
十进制转八进制 :将十进制数
156转换为八进制。 -
十六进制转十进制 :将十六进制数
3F2转换为十进制。 -
十进制转十六进制 :将十进制数
255转换为十六进制。 -
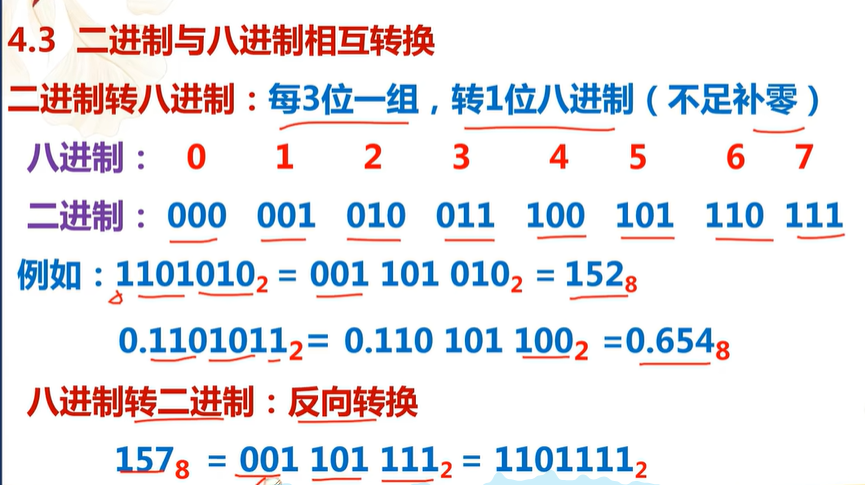
二进制转八进制 :将二进制数
1101101转换为八进制。 -
八进制转二进制 :将八进制数
543转换为二进制。 -
二进制转十六进制 :将二进制数
101011转换为十六进制。 -
十六进制转二进制 :将十六进制数
A7B转换为二进制。
答案
-
101101₂ = 45₁₀
(计算:1×2⁵ + 0×2⁴ + 1×2³ + 1×2² + 0×2¹ + 1×2⁰ = 32 + 0 + 8 + 4 + 0 + 1 = 45)
-
89₁₀ = 1011001₂
(89 ÷ 2 取余:89→44余1, 44→22余0, 22→11余0, 11→5余1, 5→2余1, 2→1余0, 1→0余1,倒序得 1011001)
-
237₈ = 159₁₀
(2×8² + 3×8¹ + 7×8⁰ = 128 + 24 + 7 = 159)
-
156₁₀ = 234₈
(156 ÷ 8:156÷8=19余4, 19÷8=2余3, 2÷8=0余2,倒序得 234)
-
3F2₁₆ = 1010₁₀
(3×16² + 15×16¹ + 2×16⁰ = 768 + 240 + 2 = 1010)
-
255₁₀ = FF₁₆
(255 ÷ 16:255÷16=15余15(F), 15÷16=0余15(F),得 FF)
-
1101101₂ = 155₈
(从右向左每3位一组:001 101 101,即 1 5 5,得 155₈)
-
543₈ = 101100011₂
(每位转3位二进制:5→101, 4→100, 3→011,连起来得 101100011)
-
101011₂ = 2B₁₆
(从右向左每4位一组:0010 1011,即 2 和 B,得 2B₁₆)
-
A7B₁₆ = 101001111011₂
(每位转4位二进制:A→1010, 7→0111, B→1011,连起来得 101001111011)
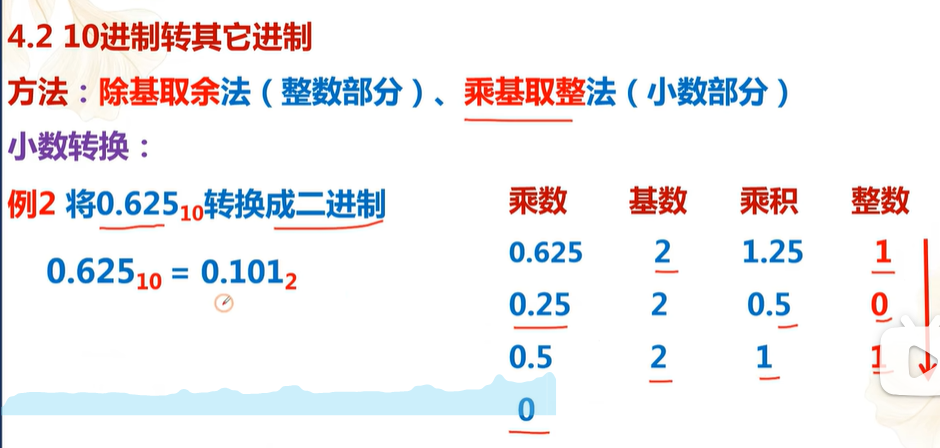
浮点数常量的写法
浮点数常量有两种形式:
-
小数形式 :如
3.14、0.5、.25、-2.0。 -
指数形式 :用
e或E表示10的幂次,如1.2e3(1200)、4.5E-2(0.045)。
2、数据类型有哪些 分别长度是多少 分别在内存中是怎么表示的 表示范围应该怎么计算
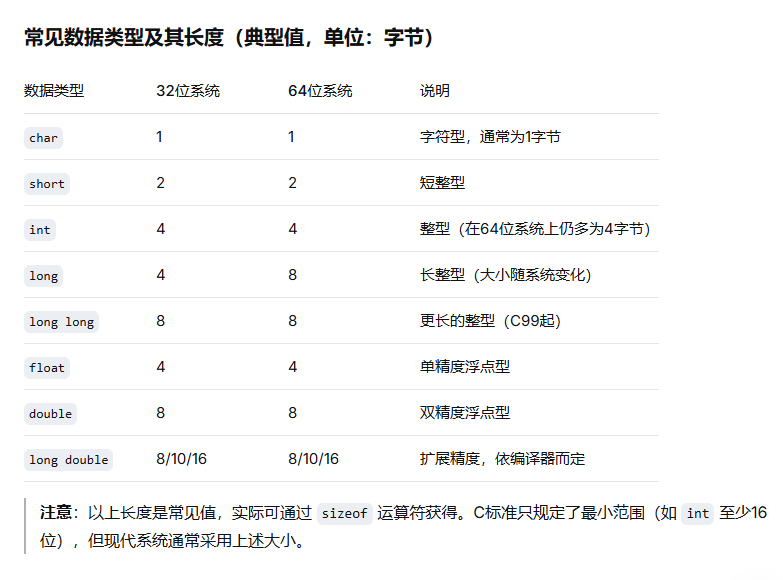
内存中的表示方式
1. 整型(Integers)
-
无符号整型 :直接以二进制原码存储。例如
unsigned int占4字节(32位),数值范围 0 ~ 2³²-1。 -
有符号整型 :以补码 形式存储。最高位为符号位(0正1负),正数的补码等于原码,负数的补码为其绝对值的原码取反加1。例如
int占4字节,范围 -2³¹ ~ 2³¹-1。
2. 字符型(char)
- 本质上是小整型,通常以ASCII码存储。
char可能是有符号 (-128~127)或无符号 (0~255),由编译器决定。
3. 浮点型(Floating-point)
-
遵循 IEEE 754 标准:
-
float(32位):1位符号位,8位指数位,23位尾数位。表示范围约 ±1.2×10⁻³⁸ ~ ±3.4×10³⁸,精度约6~7位十进制。
-
double(64位):1位符号位,11位指数位,52位尾数位。范围约 ±2.2×10⁻³⁰⁸ ~ ±1.8×10³⁰⁸,精度约15~16位十进制。
-
-
内存中按符号、指数、尾数顺序排列(注意字节序可能因平台而异)。
表示范围的计算方法
整型范围
设数据类型总位数为 n(即 sizeof(type) * 8):
-
无符号整型:最小值 0,最大值 = 2ⁿ - 1。
-
有符号整型(补码):最小值 = -2ⁿ⁻¹,最大值 = 2ⁿ⁻¹ - 1。
例如:
-
unsigned int(32位):0 ~ 2³²-1 = 0 ~ 4294967295 -
int(32位):-2³¹ ~ 2³¹-1 = -2147483648 ~ 2147483647
浮点型范围
浮点数的范围由指数位数决定,但受规格化表示限制。以 float 为例:
-
指数部分8位,可表示指数范围 -126 ~ 127(偏移127),尾数23位隐含1位整数部分(1.m)。
-
最大正数 ≈ (2 - 2⁻²³) × 2¹²⁷ ≈ 3.4×10³⁸
-
最小正规格化数 ≈ 2⁻¹²⁶ ≈ 1.2×10⁻³⁸
-
实际范围包括正负零、无穷大、NaN等。
计算时通常直接参考标准值,无需手动推导。
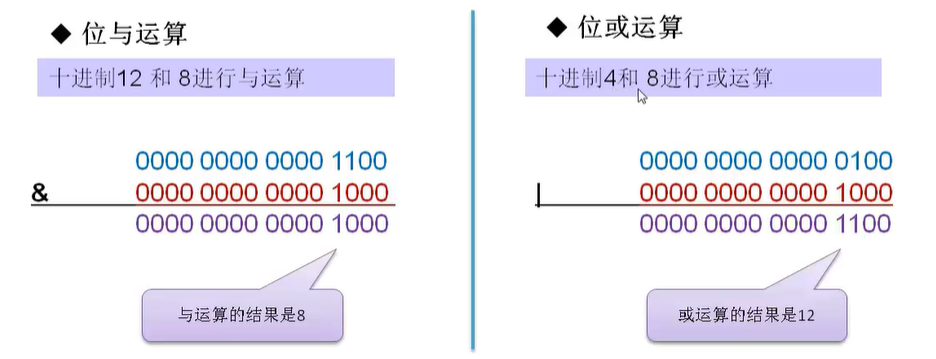
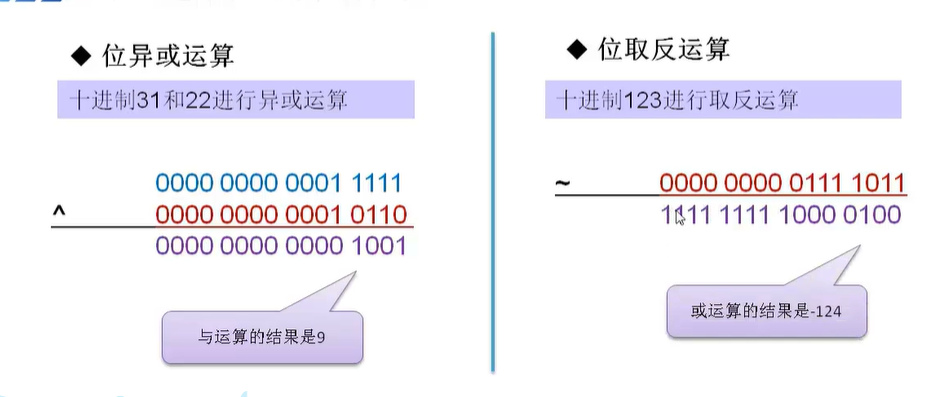
3、位运算 (左移 右移 与 或 非 异或) 理解怎么将一个int 拆分按位成三个整数
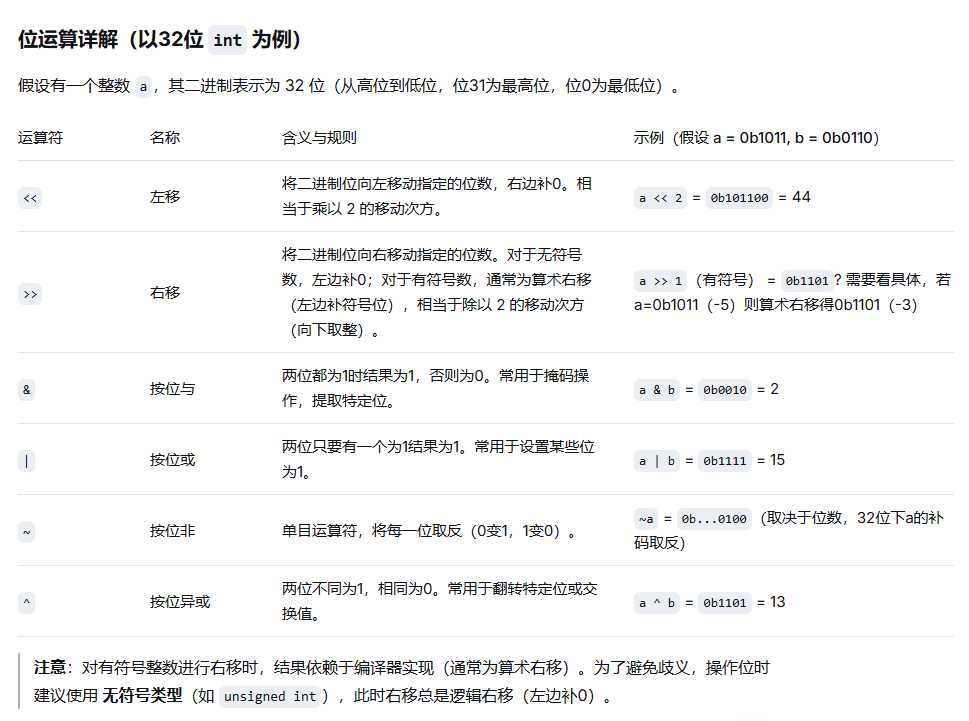
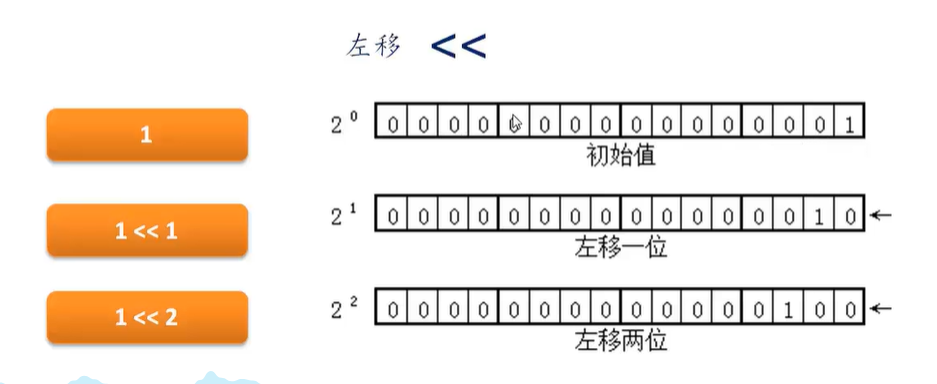
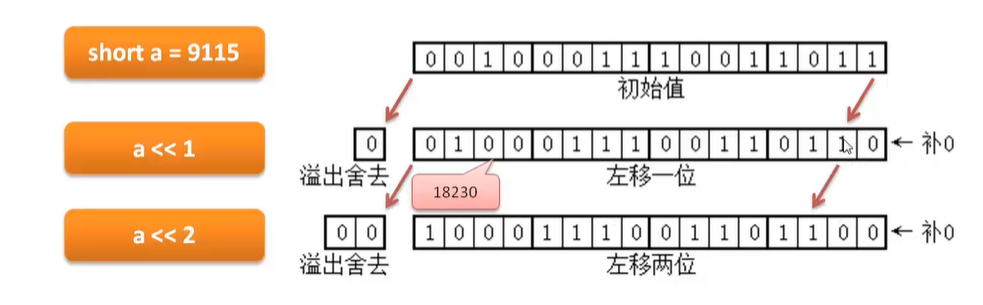
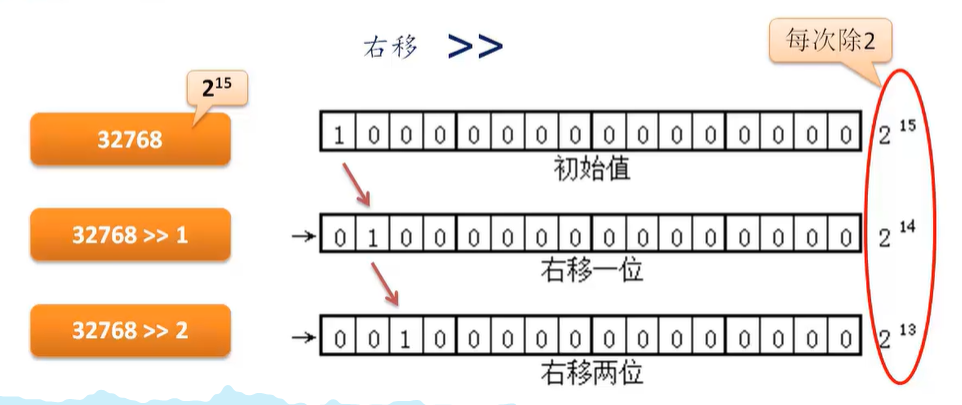
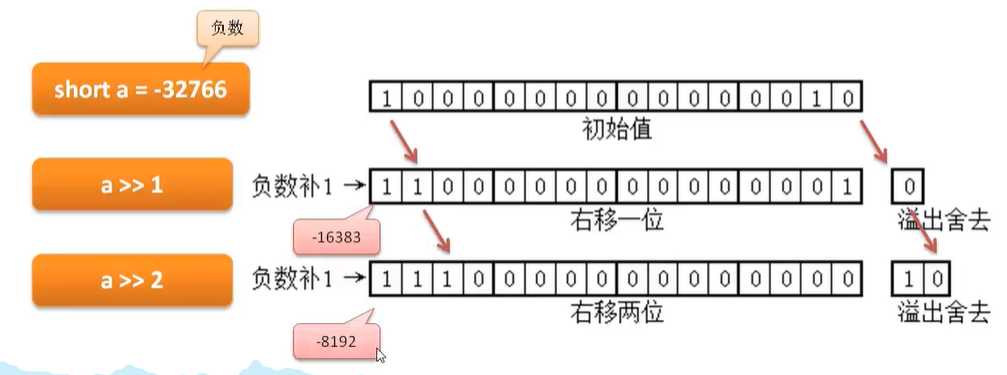
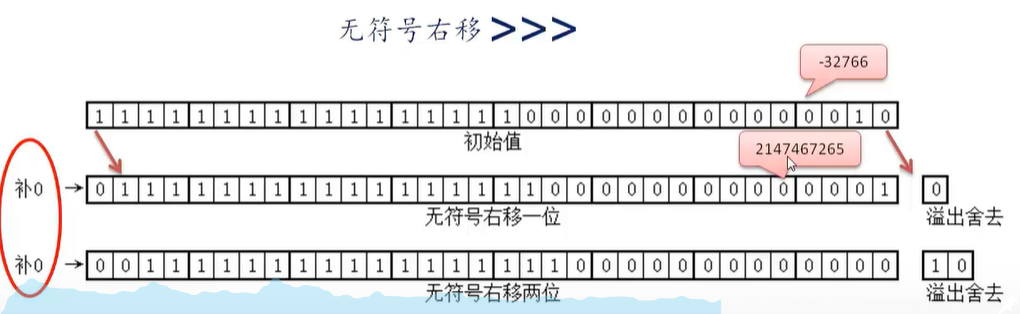
如何将一个 int 拆分成三个整数
拆分整数通常指将一个整数的二进制位分割成几个部分,每个部分存储到另一个整数中。例如,将一个 32 位整数拆成三个字段:
-
高16位(位31~16)
-
中间8位(位15~8)
-
低8位(位7~0)
通过掩码和移位操作可以轻松提取每个字段。掩码是一个二进制数,需要提取的位为1,其余为0,通过与运算保留这些位,再通过移位调整到最低位。
unsigned int 是 C/C++ 中的一种基本数据类型,表示无符号整数 。这里的"无符号"意味着它不能存储负数 ,只能存储 0 和正整数。
#include <stdio.h>
int main() {
unsigned int value = 0x12345678; // 32位十六进制数
// 拆分成三个部分
unsigned int high = (value >> 16) & 0xFFFF; // 高16位:0x1234
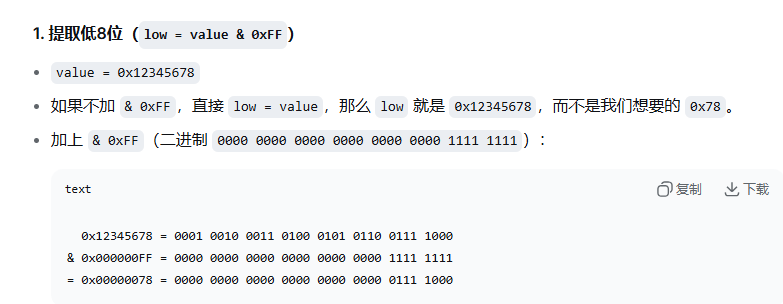
unsigned int mid = (value >> 8) & 0xFF; // 中间8位:0x56
unsigned int low = value & 0xFF; // 低8位:0x78
printf("原始值: 0x%X\n", value);
printf("高16位: 0x%X\n", high);
printf("中间8位: 0x%X\n", mid);
printf("低8位: 0x%X\n", low);
return 0;
}
通用方法
要提取从第 start 位开始、长度为 len 的位段(start 为最低位索引,从0开始),可以使用:
c
unsigned int field = (value >> start) & ((1u << len) - 1);例如,提取位15~8(长度8,起始位8):(value >> 8) & 0xFF。
反向操作:合并三个整数为一个
如果需要将这三个部分重新合并成原始整数,可以使用左移和按位或:
c
unsigned int restored = (high << 16) | (mid << 8) | low;4、运算符(重点理解 整除 取模 ++ -- )的含义
1. 整除(整数除法)
-
定义:当两个整数相除时,结果只保留整数部分,小数部分被截断。这不同于数学中的实数除法。
-
示例(以C语言为例):
c
int a = 7, b = 3; int result = a / b; // result 值为 2(截断小数部分) -
截断方向 :C99标准规定整数除法的结果是向零取整(即舍弃小数部分)。对于正数,截断就是向下取整;对于负数,截断是向零的方向取整。
c
int x = -7 / 3; // 结果是 -2,因为 -7/3 ≈ -2.33,向零取整得 -2 int y = 7 / -3; // 也是 -2 -
注意:如果除数为0,会导致运行时错误(除零异常)。
2. 取模(求余数)
-
定义 :取模运算符
%返回整数除法后的余数。满足关系:(a / b) * b + a % b == a。 -
示例:
c
int a = 7, b = 3; int mod = a % b; // mod 值为 1(因为 7 ÷ 3 = 2 余 1) -
负数的取模 :C99规定,取模的结果符号与被除数
a相同(即结果的正负取决于a)。例如:c
-7 % 3 // 结果是 -1(因为 -7 = (-2)*3 + (-1)) 7 % -3 // 结果是 1 -7 % -3 // 结果是 -1 -
注意 :取模运算中,除数
b不能为0。
3. 自增 ++ 和自减 -- 运算符
这两个运算符用于将变量的值增加1或减少1。它们有两种形式:前置 (++i)和后置 (i++),区别在于表达式的求值顺序。
3.1 前置版本(如 ++i)
-
先将变量
i的值加1,然后返回增加后的值。c
int i = 5; int a = ++i; // i 先变成 6,然后 a 赋值为 6
3.2 后置版本(如 i++)
-
先返回变量
i的原值 ,然后再将i加1。c
int i = 5; int b = i++; // b 赋值为 5,然后 i 变成 6
3.3 示例对比
c
int x = 3, y = 3;
printf("%d\n", ++x); // 输出 4(x 变为 4)
printf("%d\n", y++); // 输出 3(y 原为3,然后变为4)
printf("%d\n", x); // 输出 4
printf("%d\n", y); // 输出 43.4 注意事项
-
自增/自减运算符只能作用于变量 ,不能用于常量或表达式(如
(x+y)++非法)。 -
在同一个表达式中多次修改同一个变量,行为是未定义的(如
i = i++ + ++i;),应避免这样使用。 -
这些运算符常用于循环、数组索引等场景。
5、逻辑运算符 需要知道逻辑运算符执行的顺序 举例 表达式1&&表达式2 先判定表达式1 如果表达式1为假那么直接返回false 如果表达式1为真才会判定表达式2
逻辑运算符用于组合或取反条件表达式,其求值顺序具有短路特性,即根据左操作数的结果决定是否计算右操作数。这在编程中非常重要,可以避免不必要的计算或防止潜在错误(如空指针访问)。
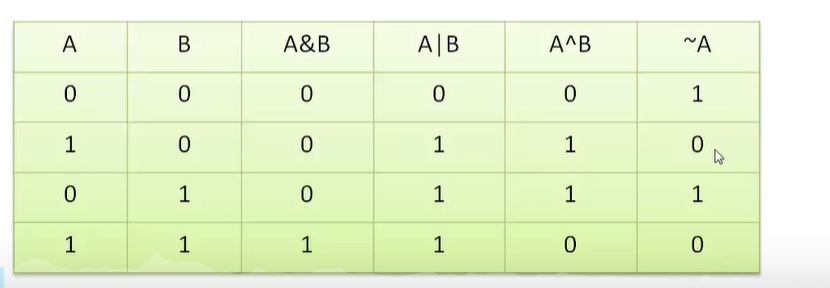
1. 逻辑运算符
-
逻辑与
&&:当且仅当两个操作数都为真时,结果为真;否则为假。 -
逻辑或
||:当且仅当两个操作数都为假时,结果为假;否则为真。 -
逻辑非
!:单目运算符,将真变为假,假变为真。
2. 短路求值规则
C语言(以及大多数语言)保证逻辑运算符的求值顺序从左到右,并且:
-
对于
表达式1 && 表达式2:-
首先计算
表达式1。 -
如果
表达式1为假(0),则整个表达式结果为假,不再计算表达式2。 -
如果
表达式1为真(非0),则继续计算表达式2,其结果作为整个表达式的值。
-
-
对于
表达式1 || 表达式2:-
首先计算
表达式1。 -
如果
表达式1为真(非0),则整个表达式结果为真,不再计算表达式2。 -
如果
表达式1为假(0),则继续计算表达式2,其结果作为整个表达式的值。
-
这种短路行为可以用于安全地编写条件,例如:
c
if (p != NULL && p->value > 10) { ... }这里如果 p 是空指针,p->value 不会被访问,避免了空指针解引用错误。
3. 示例
c
#include <stdio.h>
int main() {
int a = 0, b = 5;
// 逻辑与短路
if (a && (b = 10)) { // a为假,右边b=10不执行
// 不进入
}
printf("b = %d\n", b); // 输出 b = 5,b未被修改
// 逻辑或短路
int c = 1, d = 5;
if (c || (d = 20)) { // c为真,右边d=20不执行
// 进入
}
printf("d = %d\n", d); // 输出 d = 5,d未被修改
// 逻辑非没有短路,因为它是单目运算
return 0;
}4. 注意事项
-
短路求值意味着依赖副作用的表达式(如赋值、自增)可能不会执行,因此要避免在逻辑表达式中写入有副作用的代码,除非你明确知道短路行为。
-
逻辑运算符的优先级:
!最高,其次是&&,最后是||。但短路顺序始终从左到右,不受优先级影响(优先级只决定结合,但求值顺序仍从左到右,且短路规则优先)。
理解短路求值有助于编写高效且安全的条件判断。
6、条件分支语句 特别是switch case的运行逻辑
1. if 语句
语法:
c
if (表达式) {
// 表达式为真(非0)时执行的语句块
}示例:
c
int score = 85;
if (score >= 60) {
printf("及格\n");
}2. if-else 语句
语法:
c
if (表达式) {
// 真时执行
} else {
// 假时执行
}示例:
c
if (score >= 60) {
printf("及格\n");
} else {
printf("不及格\n");
}3. else if 链
用于多条件判断,依次检查每个条件。
语法:
c
if (表达式1) {
// 表达式1为真
} else if (表达式2) {
// 表达式1为假且表达式2为真
} else if (表达式3) {
// 前面均为假且表达式3为真
} else {
// 所有条件都为假
}示例:
c
if (score >= 90) {
printf("优秀\n");
} else if (score >= 80) {
printf("良好\n");
} else if (score >= 60) {
printf("及格\n");
} else {
printf("不及格\n");
}4. switch 语句
适用于根据单个整型表达式的值进行多分支选择。
语法:
c
switch (表达式) {
case 常量1:
语句序列1
break; // 可选,但通常需要
case 常量2:
语句序列2
break;
// 更多 case
default: // 可选
语句序列n
}switch-case 语句的运行逻辑
switch 语句是一种多分支选择结构,适用于根据一个整型表达式的值跳转到多个不同代码块之一。其基本语法如下:
c
switch (表达式) {
case 常量表达式1:
语句序列1
break; // 可选
case 常量表达式2:
语句序列2
break; // 可选
// 更多 case ...
default: // 可选
语句序列n
}执行流程
-
计算控制表达式 :首先计算
switch后括号内表达式的值,得到一个整数值(类型为整型、字符型或枚举型)。 -
匹配 case 标签 :将表达式的值与每个
case后的常量表达式进行比较,寻找第一个相等的case标签。-
如果找到匹配的
case,程序跳转到该标签处开始顺序执行其后的语句。 -
如果没有找到匹配的
case,且存在default标签,则跳转到default处执行。 -
如果没有匹配且无
default,则整个switch语句体不执行,直接跳出。
-
-
执行与穿透(fall-through) :从匹配的
case开始,程序会顺序执行 所有后续语句,直到遇到break语句或到达switch语句的末尾。这意味着如果一个case块末尾没有break,执行会"穿透"到下一个case块继续执行,而不管其标签是否匹配。这就是所谓的 case 穿透。 -
break 的作用 :
break语句用于立即跳出整个switch结构,将控制权转移到switch后的下一条语句。通常每个case块结尾都应有break,除非特意利用穿透特性。
示例说明
c
#include <stdio.h>
int main() {
int num = 2;
switch (num) {
case 1:
printf("One\n");
break;
case 2:
printf("Two\n");
// 没有 break,会继续执行下一个 case
case 3:
printf("Three\n");
break;
default:
printf("Other\n");
}
return 0;
}输出:
text
Two
Three解释:num 值为 2,匹配 case 2,先打印 "Two",由于没有 break,继续向下执行 case 3 的代码,打印 "Three",然后遇到 break 退出。
default 子句
-
default是可选的,位置可以放在任意处(但通常放在最后)。 -
当没有任何
case匹配时,执行default块。如果default不在末尾且没有break,也会发生穿透。
重要规则与注意事项
-
case 标签必须是常量表达式:在编译时就能确定的值,如整数常量、字符常量、枚举常量,不能是变量。
-
表达式类型限制 :
switch后的表达式必须返回整数类型(包括char、enum),不能是浮点型或字符串。 -
case 值唯一 :同一个
switch中不能出现两个相同的case值。 -
穿透的利用 :有时故意省略
break让多个case共享一段代码,例如处理多个相同逻辑的情况:c
switch (grade) { case 'A': case 'B': case 'C': printf("Pass\n"); break; case 'D': case 'F': printf("Fail\n"); break; } -
与 if-else 的对比 :
switch更适合对单个变量的多个离散值进行分支选择,代码更清晰;而if-else可以处理复杂条件(如范围、逻辑组合)。编译时switch通常会被优化为跳转表,效率可能更高。
理解 switch 的运行逻辑,尤其是穿透行为,可以帮助你写出正确且高效的多分支代码。
循环用于重复执行一段代码,直到满足特定条件。理解循环的执行顺序对编写正确程序至关重要。C语言主要有三种循环结构:while、do-while 和 for。它们的执行顺序各不相同。
7、循环 理解循环的执行顺序
1. while 循环
语法:
c
while (条件表达式) {
// 循环体语句
}执行顺序:
-
判断条件:首先计算条件表达式的值。
-
条件为真(非0):执行循环体一次。
-
条件为假(0):跳出循环,执行循环后的代码。
-
执行完循环体后,自动回到步骤1,再次判断条件。
流程图:
text
┌─────────┐
│ 条件判断 │<─────┐
└────┬────┘ │
│ 真 │
▼ │
┌─────────┐ │
│ 循环体 │──────┘
└─────────┘
│ 假
▼
循环结束注意:如果一开始条件为假,循环体一次也不执行。
示例:
c
int i = 0;
while (i < 3) {
printf("%d ", i);
i++;
}
// 输出:0 1 2执行步骤:
-
i=0,条件 0<3 真,打印0,i=1
-
i=1,条件 1<3 真,打印1,i=2
-
i=2,条件 2<3 真,打印2,i=3
-
i=3,条件 3<3 假,退出。
2. do-while 循环
语法:
c
do {
// 循环体语句
} while (条件表达式);执行顺序:
-
执行循环体:先无条件执行一次循环体。
-
判断条件:执行完循环体后,计算条件表达式。
-
条件为真:返回步骤1,再次执行循环体。
-
条件为假:退出循环。
流程图:
text
┌─────────┐
│ 循环体 │
└────┬────┘
▼
┌─────────┐
│ 条件判断 │
└────┬────┘
│ 真
└──────┐
│
假 │
▼ │
循环结束 │
│
└──────┘特点:循环体至少执行一次。
示例:
c
int i = 0;
do {
printf("%d ", i);
i++;
} while (i < 3);
// 输出:0 1 2执行步骤:
-
第一次执行循环体,打印0,i=1,判断条件 1<3 真,继续。
-
第二次执行循环体,打印1,i=2,判断 2<3 真,继续。
-
第三次执行循环体,打印2,i=3,判断 3<3 假,退出。
即使初始 i=3,循环体也会执行一次:
c
int i = 3;
do {
printf("%d ", i); // 输出 3
i++;
} while (i < 3);3. for 循环
语法:
c
for (初始化表达式; 条件表达式; 迭代表达式) {
// 循环体语句
}执行顺序(分步):
-
初始化:先执行一次初始化表达式(通常用于设置循环变量)。
-
条件判断:计算条件表达式。
-
如果为真(非0),执行循环体。
-
如果为假(0),跳出循环。
-
-
执行循环体:执行花括号内的语句。
-
迭代:执行迭代表达式(通常用于更新循环变量)。
-
返回步骤2:再次判断条件,重复直到条件为假。
流程图:
text
┌─────────┐
│ 初始化 │
└────┬────┘
▼
┌─────────┐
│ 条件判断 │<─────┐
└────┬────┘ │
│ 真 │
▼ │
┌─────────┐ │
│ 循环体 │ │
└────┬────┘ │
▼ │
┌─────────┐ │
│ 迭代 │──────┘
└─────────┘
│ 假
▼
循环结束示例:
c
for (int i = 0; i < 3; i++) {
printf("%d ", i);
}
// 输出:0 1 2执行步骤:
-
初始化 i=0
-
判断 i<3 真 → 进入循环体,打印0
-
迭代 i++ → i=1
-
判断 i<3 真 → 打印1
-
迭代 i++ → i=2
-
判断 i<3 真 → 打印2
-
迭代 i++ → i=3
-
判断 i<3 假 → 退出
注意:初始化表达式只执行一次;条件表达式在每次循环开始前判断;迭代表达式在每次循环体结束后执行。
4. break 和 continue 对循环顺序的影响
-
break:立即跳出当前循环(不再执行循环体内剩余语句,也不再进行迭代和条件判断)。
-
continue:跳过循环体中剩余的语句,直接进入下一次循环的迭代部分(for 循环会执行迭代表达式,然后判断条件;while/do-while 会直接判断条件)。
示例:
c
for (int i = 0; i < 5; i++) {
if (i == 2) continue; // 跳过打印 i=2
if (i == 4) break; // i=4 时跳出循环
printf("%d ", i);
}
// 输出:0 1 3执行顺序:
-
i=0:打印0,迭代i=1
-
i=1:打印1,迭代i=2
-
i=2:条件 i==2 真,执行 continue,跳过打印,直接进入迭代 i=3
-
i=3:打印3,迭代i=4
-
i=4:条件 i==4 真,执行 break,退出循环。
5. 无限循环
如果条件永远为真,则形成无限循环。常见形式:
c
while (1) { ... }
for (;;) { ... }需要使用 break 或 return 退出。
总结
-
while:先判断,后执行,可能一次都不执行。
-
do-while:先执行一次,后判断,至少执行一次。
-
for:将初始化、条件、迭代集中在一起,顺序清晰。
理解执行顺序有助于避免逻辑错误,如死循环或循环次数错误。
8、数组 数组的声明和定义的几种写法
1. 一维数组
基本声明(定义)
c
类型 数组名[常量表达式];例如:int a[10]; 定义一个包含10个int元素的数组,元素未初始化(若在函数内则为随机值)。
声明时初始化
-
完全初始化:提供所有元素的初值。
c
int a[5] = {1, 2, 3, 4, 5}; -
部分初始化:只提供前几个值,其余元素自动初始化为0。
c
int a[5] = {1, 2}; // a[0]=1, a[1]=2, a[2]=0, a[3]=0, a[4]=0 -
省略大小:由初始化列表长度决定数组大小。
c
int a[] = {1, 2, 3, 4, 5}; // 数组大小为5 -
指定初始化器(C99起):可指定特定索引的元素值,其余为0。
c
int a[5] = {[1]=10, [3]=30}; // a[1]=10, a[3]=30, 其余为0
字符数组的特殊写法
-
字符串常量初始化 :自动添加结尾的
'\0'。c
char str[] = "hello"; // 大小为6,包含 'h','e','l','l','o','\0' -
字符列表初始化 :需手动添加
'\0'(若需要字符串结束标志)。c
char str[] = {'h','e','l','l','o','\0'}; // 等同于上例
2. 多维数组
二维数组声明
c
类型 数组名[行数][列数];例如:int matrix[3][4]; 定义3行4列的int数组。
初始化
-
按行嵌套初始化:
c
int matrix[2][3] = {{1,2,3}, {4,5,6}}; -
扁平初始化(按行顺序填充):
c
int matrix[2][3] = {1,2,3,4,5,6}; // 等价于上例 -
部分初始化:未指定的元素自动为0。
c
int matrix[2][3] = {{1,2}, {4}}; // 第一行:1,2,0;第二行:4,0,0 -
省略第一维大小:必须指定第二维,编译器根据初始化列表自动推断第一维。
c
int matrix[][3] = {{1,2,3}, {4,5,6}, {7,8,9}}; // 第一维为3 -
指定初始化器(C99):
c
int matrix[2][3] = {[0][1]=10, [1][2]=20}; // 其他为0
3. 使用 typedef 定义数组类型
通过 typedef 可以创建数组类型的别名,然后使用该别名声明变量。
c
typedef int IntArray10[10]; // IntArray10 代表含有10个int的数组类型
IntArray10 arr; // 等价于 int arr[10];4. 外部数组声明(extern)
如果数组定义在另一个文件中,或希望声明但不定义,使用 extern:
c
extern int arr[]; // 声明外部数组,大小未知
extern int arr[10]; // 也可指定大小,但非必需5. 变长数组(C99 特性)
数组大小可以在运行时确定,但不能在定义时进行初始化(C99/C11 不支持变长数组初始化,但C23可能支持)。
c
int n = 5;
int arr[n]; // 变长数组,大小由变量 n 决定
// 之后通过循环赋值
for (int i = 0; i < n; i++) arr[i] = i;6. 静态(static)和全局数组
-
全局数组:定义在所有函数之外,具有静态存储期,默认初始化为0。
c
int global_arr[10]; // 全局,元素初值为0 -
静态局部数组 :在函数内使用
static修饰,生命周期为整个程序,默认初始化为0。c
void func() { static int arr[5]; // 只初始化一次,后续调用保留上次的值 }
9、字符串 字符串的含义 什么是编码 字符串的数值怎么和数值转换
一、字符串的含义
在C语言中,字符串 是由字符组成的序列,并以空字符 '\0' 结尾。空字符标志着字符串的结束,它不是可显示字符,只作为终止符。例如,字符串 "hello" 在内存中实际存储为 'h','e','l','l','o','\0' 共6个字符。
字符串通常用字符数组或字符指针来操作:
c
char str1[] = "hello"; // 字符数组,自动添加 '\0'
char *str2 = "world"; // 指向字符串字面量的指针(只读)注意:字符串字面量(如 "hello")是只读的,不能修改;而字符数组可以修改其内容。
二、什么是编码?
编码 是将字符映射为计算机内部二进制数值的一套规则。计算机只能存储二进制数,因此每个字符都需要对应一个唯一的数值(码点)。常见的字符编码有:
-
ASCII :使用7位或8位二进制,共128或256个字符,包括英文字母、数字、标点等。例如,字符
'A'的ASCII码是65(十进制),'0'是48。 -
扩展ASCII:使用8位,增加了一些符号。
-
Unicode :统一字符集,包含几乎所有语言的字符。其常见实现有 UTF-8 (变长编码,兼容ASCII)、UTF-16 、UTF-32 等。
在C语言中,char 类型通常采用ASCII(或兼容的UTF-8)编码,一个 char 变量存储一个字符的码值。
三、字符串的数值与数值的转换
编程中经常需要将字符串(如 "123")转换为整数或浮点数,或者将数值(如 123)转换为字符串。C语言提供了多种方法。
1. 字符串 → 数值
常用库函数(定义在 <stdlib.h> 中)
-
int atoi(const char *str);// 字符串转 int -
long atol(const char *str);// 字符串转 long -
long long atoll(const char *str);// C99,转 long long -
double atof(const char *str);// 字符串转 double
这些函数忽略前导空白字符,直到遇到数字或正负号,然后转换直到非数字字符。如果字符串不能转换为数值,返回0(但无法区分错误)。
c
#include <stdio.h>
#include <stdlib.h>
int main() {
char s1[] = "123";
char s2[] = " -45.67";
int a = atoi(s1); // a = 123
double b = atof(s2); // b = -45.67
printf("%d %.2f\n", a, b);
return 0;
}更安全的函数(能检测错误):
-
long strtol(const char *str, char **endptr, int base);// 可指定进制,并返回未转换部分的指针 -
unsigned long strtoul(...) -
double strtod(const char *str, char **endptr);
c
char *end;
long val = strtol("123abc", &end, 10); // val=123,end指向 "abc"手动转换(整数)
可以通过遍历字符,利用字符与数字的ASCII差值进行累加:
c
int my_atoi(const char *str) {
int result = 0;
int sign = 1;
if (*str == '-') { sign = -1; str++; }
while (*str >= '0' && *str <= '9') {
result = result * 10 + (*str - '0');
str++;
}
return sign * result;
}2. 数值 → 字符串
常用库函数(<stdio.h>)
-
int sprintf(char *str, const char *format, ...);// 将格式化的数据写入字符串 -
int snprintf(char *str, size_t size, const char *format, ...);// 更安全,指定缓冲区大小
c
char buffer[50];
int num = 123;
sprintf(buffer, "%d", num); // buffer 内容为 "123"
double pi = 3.14159;
snprintf(buffer, sizeof(buffer), "%.2f", pi); // buffer="3.14"其他函数(非标准但常见)
-
char *itoa(int value, char *str, int base);// 非标准,部分编译器提供 -
可以使用
sprintf替代。
手动转换(整数)
将整数逐位取出,转换为字符:
c
void my_itoa(int n, char *str) {
int i = 0;
int sign = n;
if (n < 0) n = -n;
do {
str[i++] = n % 10 + '0';
n /= 10;
} while (n > 0);
if (sign < 0) str[i++] = '-';
str[i] = '\0';
// 反转字符串
for (int j = 0; j < i/2; j++) {
char t = str[j];
str[j] = str[i-1-j];
str[i-1-j] = t;
}
}课外
原码、反码和补码是计算机科学中用来表示有符号整数(即正数和负数)的三种编码方式。
理解它们的核心在于:计算机内部只有加法器,没有专门的减法器。为了用加法来计算减法(例如 1 - 1 变成 1 + (-1)),我们需要一种方式来表示负数,使得正数和负数的加法运算结果依然正确。补码就是为了解决这个问题而诞生的。
以下是这三种编码方式的详细解释:
1. 原码
原码是最直观的表示法,直接对应人类日常的二进制书写习惯。
-
表示方法:
-
用最高位(最左边的一位)作为符号位:0 代表正数,1 代表负数。
-
其余位表示数值的绝对值(即数的大小)。
-
-
例子(假设用 8 位二进制表示):
-
+5的原码:0000 0101 -
-5的原码:1000 0101(最高位的 1 代表负号,后面的
0000101代表数字 5)
-
-
缺点:
-
0 的表示不唯一 :会出现
+0(0000 0000)和-0(1000 0000),这对计算机来说会造成浪费和不便。 -
无法直接进行加法运算 :如果直接用原码计算
1 + (-1),结果是0000 0001 + 1000 0001 = 1000 0010,这等于-2,显然是错误的。因此原码不适合直接用于计算机的运算。
-
2. 反码
反码通常作为原码到补码的中间过渡,现在很少直接使用。
-
表示方法:
-
正数 :反码与原码相同。
-
负数 :在原码的基础上,符号位保持不变 ,其余位(数值位)按位取反(0 变成 1,1 变成 0)。
-
-
例子(8 位二进制):
-
+5的反码:0000 0101(与原码相同) -
-5的反码:1111 1010(原码
1000 0101,符号位 1 不动,数值位0000101取反变成1111010)
-
-
缺点:
-
0 的表示依然不唯一 :
+0是0000 0000,-0是1111 1111。 -
运算循环进位问题:用反码计算加法虽然比原码好,但在计算涉及 0 的时候,会出现需要把最高位的进位加回最低位的情况(即循环进位),增加了电路设计的复杂度。
-
3. 补码(计算机实际使用)
补码是现代计算机实际存储和运算所使用的编码方式。它完美解决了原码和反码的缺点。
-
表示方法:
-
正数 :补码与原码相同。
-
负数 :在反码的基础上加 1(或者说:原码除符号位外取反,再加 1)。
-
-
例子(8 位二进制,求 -5 的补码):
-
先求原码:
1000 0101 -
除符号位取反得反码:
1111 1010 -
末位加 1:
1111 1010 + 1 = 1111 1011所以,
-5在计算机中存储为1111 1011。
-
-
核心优点:
-
0 的表示唯一 :
0000 0000代表 0,1000 0000不再表示 -0,而是用来表示-128。这使得 8 位二进制能表示的范围从原码的 -127 到 +127,扩大为 -128 到 +127。 -
化减为加 :
1 - 1 = 1 + (-1) = 0可以直接用补码计算:-
1的补码:0000 0001 -
-1的补码:1111 1111 -
相加:
0000 0001 + 1111 1111 = 1 0000 0000 -
结果产生了 9 位,最高位的 1 会被丢弃(因为寄存器是 8 位的),剩下
0000 0000,即 0。计算正确!
-
-
总结表格与速算
以一个字节(8 位二进制)为例,假设数字是 5 和 -5:
| 数值 | 原码 | 反码 | 补码 (计算机实际存储) |
|---|---|---|---|
| +5 | 0000 0101 | 0000 0101 | 0000 0101 |
| -5 | 1000 0101 | 1111 1010 | 1111 1011 |
速记口诀:
-
正数:三码合一(原码 = 反码 = 补码)。
-
负数:
-
原码符号位不变,其他位取反得到反码。
-
反码加 1 得到补码。
-
如何从补码转回原码?
对补码再求一次补码(即取反加一),就得到原码(符号位依然不变,数值位取反加一)。


例子,-1的补码怎么求?
- 第一步:先求负数的「原码」
原码是最直观的二进制表示,规则:
符号位:1(负数)
数值位:该负数绝对值的二进制表示
示例(以 8 位二进制表示 - 5):
5 的二进制:00000101
-5 的原码:10000101(最高位改 1,数值位不变)
- 第二步:由原码求「反码」
负数反码的计算规则:
符号位:保持 1 不变(仅数值位取反)
数值位:每一位按位取反(0 变 1,1 变 0)
示例(-5 的反码):
-5 的原码:10000101
符号位:1(不变)
数值位取反:00000101 → 11111010
-5 的反码:11111010(拼接符号位 + 取反后的数值位)
- 第三步:由反码求「补码」
负数补码的计算规则:
补码 = 反码 + 1(二进制加法,逢 2 进 1)
示例(-5 的补码):
-5 的反码:11111010
加 1 计算:11111010 + 1 = 11111011
-5 的补码:11111011(这就是计算机实际存储的 - 5)
扩展:32 位 int 的 - 5 补码
32 位 int 的最高位是第 31 位(从 0 开始计数),计算逻辑和 8 位一致,只是数值位补满 31 位:
-5 的 32 位原码:10000000 00000000 00000000 00000101
-5 的 32 位反码:11111111 11111111 11111111 11111010
-5 的 32 位补码:11111111 11111111 11111111 11111011