起因时这样的,我在根据视频生成音频的时候,发现生成的音频与视频的时间不对
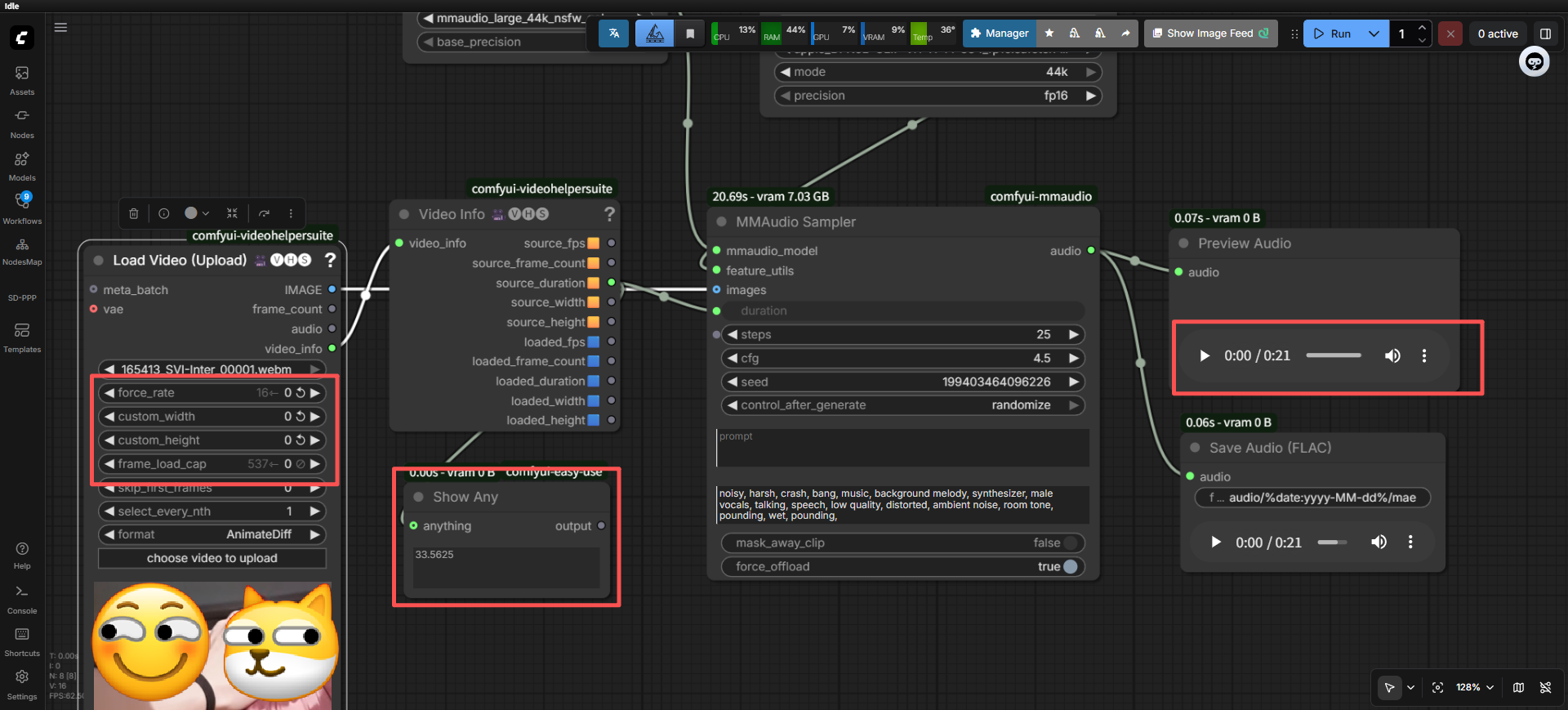
可以明显看到,视频的FPS=16,长度(图片数量)=537
理论时间也输出了 537/16 = 33.5625 秒,但是我们可以看到生成的音频时长是21秒,看一下后台什么情况
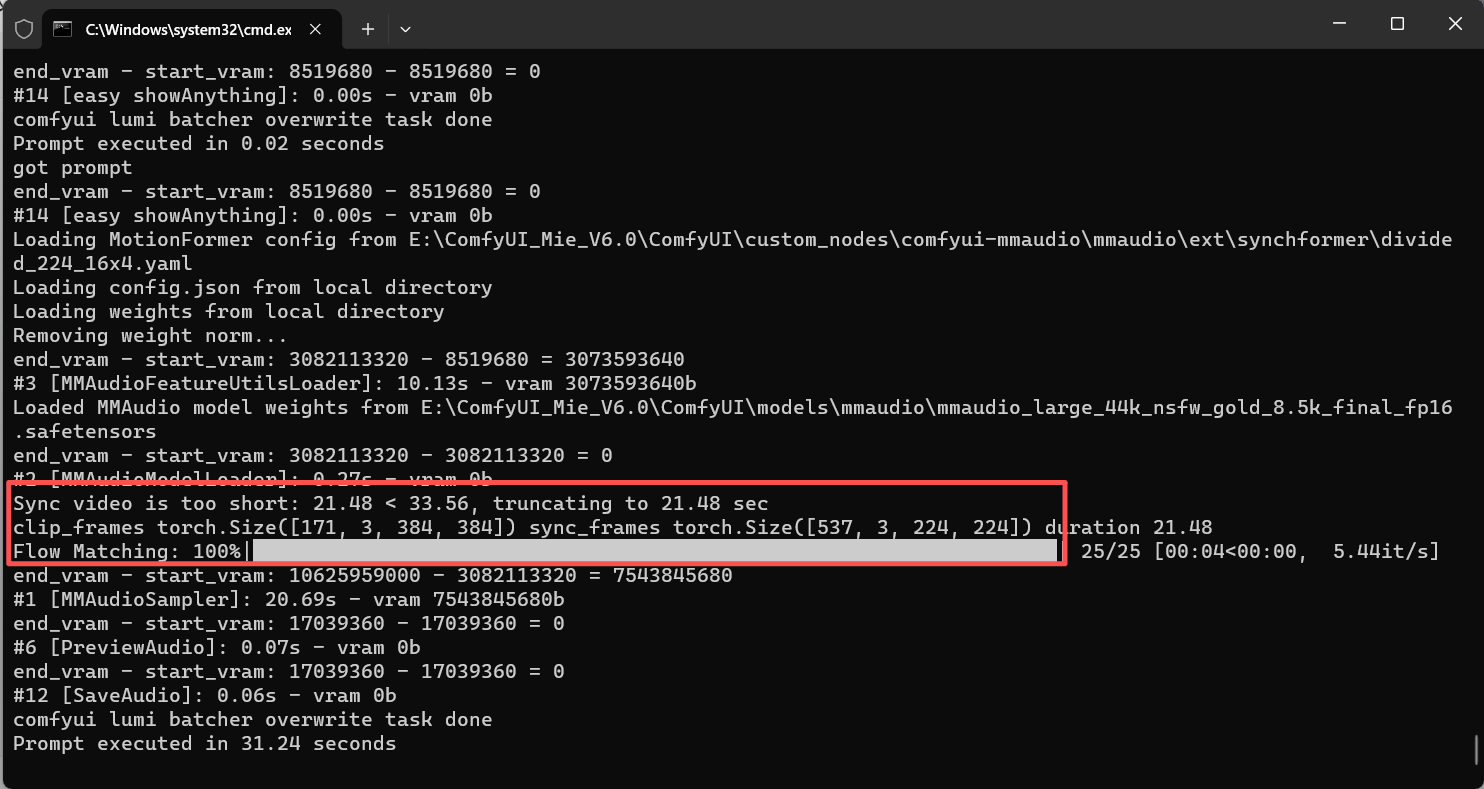
后台计算的视频长度是21.48秒,不对啊,于是我又尝试了一下别的视频,发现都不对劲,时间总是不对
我们倒推算一下,537张,时间21.48秒,那么帧率就是 537/21.48 = 25 FPS
于是我尝试了别的帧率的视频,发现这个mmaudio节点是默认所有视频25帧的,而且不给改,这就很操蛋了,我要是硬件够的话,我还用用16帧???
解决办法
-
所有视频都用25FPS
-
修改节点
修改节点准备
莫名的激动,之前只是改一改一些导入错误而已,第一次尝试修改,暂时就是准备给他加一个可以输入的参数,用来输入帧率,这样我们就可以调控视频的帧率了
要修改外观,然后代替里面的默认25帧的参数就行,很简单
代码查询
最难的一步,看一下kijia大佬写的插件,先弄懂大部分的代码就行
一步一步来,先了解一下comfyui的插件规定,怎么写才是对的
插件规定骨架
不管是音频节点、图像节点,ComfyUI 的节点都遵循一个固定模板,先记住这个骨架,下面的代码时资料的例子,瞎写的,不是哪个节点
python
# 1. 导入必要的库(比如处理音频的mmaudio、ComfyUI的基础类、数值处理的numpy等)
import torch
import mmaudio
from mmaudio.apis import inference_audio
from comfyui.nodes import NodeBase # 不同版本写法可能略不同,核心是继承基类
# 2. 定义一个节点类(比如"音频特征提取节点"),必须继承ComfyUI的节点基类
class MMAudioFeatureExtractor(NodeBase):
# 2.1 【关键】定义节点的输入参数(UI上能填的参数都在这)
@classmethod
def INPUT_TYPES(cls):
return {
"required": { # 必选参数(UI上标红,必须填)
"audio_path": ("STRING", {"default": "your_audio.wav", "multiline": False}), # 字符串类型(音频文件路径)
"feature_type": (["mfcc", "mel", "spectrogram"], {"default": "mfcc"}), # 下拉选择框(可选特征类型)
"sample_rate": ("INT", {"default": 16000, "min": 8000, "max": 48000}), # 整数类型(采样率)
},
"optional": { # 可选参数(不填也能运行)
"normalize": ("BOOLEAN", {"default": True}), # 布尔值(是否归一化)
}
}
# 2.2 【关键】定义节点的输出类型(节点能输出什么数据)
RETURN_TYPES = ("TENSOR", "STRING") # 输出:张量(特征数据)、字符串(特征类型说明)
RETURN_NAMES = ("feature_tensor", "feature_info") # 输出的名字(UI上显示的输出端口名)
# 2.3 【关键】定义节点执行的核心函数名(下面的process方法就是实际干活的)
FUNCTION = "extract_feature"
# 2.4 【关键】定义节点在UI上的分类(比如"Audio/MMAudio",方便找)
CATEGORY = "Audio/MMAudio"
# 2.5 【核心逻辑】节点的实际功能(输入参数 → 处理 → 输出结果)
def extract_feature(self, audio_path, feature_type, sample_rate, normalize=True):
# 步骤1:加载音频文件(调用mmaudio的方法)
audio_data, sr = mmaudio.load(audio_path, sr=sample_rate)
# 步骤2:根据选择的特征类型,提取音频特征
if feature_type == "mfcc":
feature = mmaudio.features.mfcc(audio_data, sr=sr, normalize=normalize)
elif feature_type == "mel":
feature = mmaudio.features.mel_spectrogram(audio_data, sr=sr)
else:
feature = mmaudio.features.spectrogram(audio_data, sr=sr)
# 步骤3:把特征转成ComfyUI能传递的张量(PyTorch Tensor)
feature_tensor = torch.from_numpy(feature)
# 步骤4:准备输出信息
feature_info = f"提取{feature_type}特征,采样率{sample_rate},形状{feature_tensor.shape}"
# 必须返回:和RETURN_TYPES数量、顺序完全一致的结果
return (feature_tensor, feature_info)
# 3. 把节点注册到ComfyUI(让UI能识别这个节点)
NODE_CLASS_MAPPINGS = {
"MMAudioFeatureExtractor": MMAudioFeatureExtractor # "UI上显示的节点名": 上面定义的类名
}
NODE_DISPLAY_NAME_MAPPINGS = {
"MMAudioFeatureExtractor": "MMAudio 音频特征提取" # 更友好的中文显示名
}上面这个是查的模板,大概就是这样的骨架(理解成必须用这种格式给节点comfyui才会识别到),也就是comfyui给你开放了一套模板,你必须按照这个模板来才可以被comfyui使用
骨架解析
1. 导入库(开头的 import)
import torch:ComfyUI 底层用 PyTorch,所有数据(比如音频特征)都要转成 Tensor(张量),所以必须导入;import mmaudio:核心!comfyui-mmaudio是基于 mmaudio 库做的,所有音频处理(加载、提取特征)都靠它;from comfyui.nodes import NodeBase:继承 ComfyUI 的节点基类,只有继承了,你写的类才是 "ComfyUI 能识别的节点"。
2. 节点类的核心部分(小白重点记)
① INPUT_TYPES(定义输入参数)
- 这是「UI 上能操作的参数」的定义处,比如你在节点上填 "音频路径"、选 "MFCC 特征"、改 "采样率",都在这定义;
- 格式说明:
"required":必选参数,不填节点跑不了(UI 上会标红);"optional":可选参数,不填也能跑;- 每个参数的格式:
参数名: (类型, 配置)- 类型:
"STRING"(字符串,比如文件路径)、"INT"(整数,比如采样率)、"BOOLEAN"(布尔值,True/False)、["选项1","选项2"](下拉选择框); - 配置:
{"default": 默认值, "min": 最小值, "max": 最大值, "multiline": 是否多行}。
- 类型:
② RETURN_TYPES / RETURN_NAMES(定义输出)
RETURN_TYPES:节点输出的数据类型,比如"TENSOR"(张量,ComfyUI 里传递数据的核心格式)、"STRING"(字符串)、"AUDIO"(音频,部分版本有专属类型);RETURN_NAMES:给输出端口起名字,方便你在 UI 上看 "这个输出是特征张量,那个是信息"。
③ FUNCTION(指定核心函数)
- 比如
FUNCTION = "extract_feature",意思是:当你点击 "运行" 时,节点会执行extract_feature这个方法(下面定义的 def 函数)。
④ CATEGORY(节点分类)
- 比如
CATEGORY = "Audio/MMAudio",意思是:这个节点会出现在 ComfyUI 的 "Audio" 分类下的 "MMAudio" 子分类里,方便你找。
⑤ 核心方法(比如 extract_feature)
- 这是节点「实际干活的地方」:接收输入参数 → 调用 mmaudio 做音频处理 → 生成输出;
- 小白重点看逻辑:
- 先加载音频:
mmaudio.load(audio_path, sr=sample_rate)→ 把音频文件读成 "音频数据 + 采样率"; - 再提取特征:根据选的
feature_type(比如 mfcc),调用 mmaudio 对应的函数提取特征; - 转格式:把 mmaudio 输出的 numpy 数组转成 PyTorch Tensor(因为 ComfyUI 只认 Tensor);
- 返回结果:必须和
RETURN_TYPES的数量、顺序完全一致!比如RETURN_TYPES = ("TENSOR", "STRING"),就必须返回(tensor, 字符串)。
- 先加载音频:
3. 节点注册(最后两行)
NODE_CLASS_MAPPINGS:把你定义的节点类 "注册" 到 ComfyUI,UI 才能显示这个节点;NODE_DISPLAY_NAME_MAPPINGS:给节点起一个 "友好的显示名"(比如中文),不然 UI 上显示的是类名(MMAudioFeatureExtractor),不直观。
上面的太过复杂,当然是一定得看的,我自己总结了一下,根据节点mmaudio的nodes.py为例子(其他节点的文件名字可能不一样,但是一般放在最外层),大概就是:
1. 导入库
这个就是最简单的你要用那些包,python的哪些依赖库,就pip安装的那些,还有自己写的那些文件(核心处理过程)
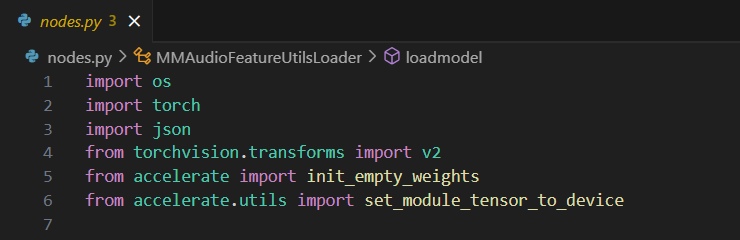
2.节点的类
你创建一个类MMAudioModelLoader,代表这个节点,然后按照规定定义一些东西就行
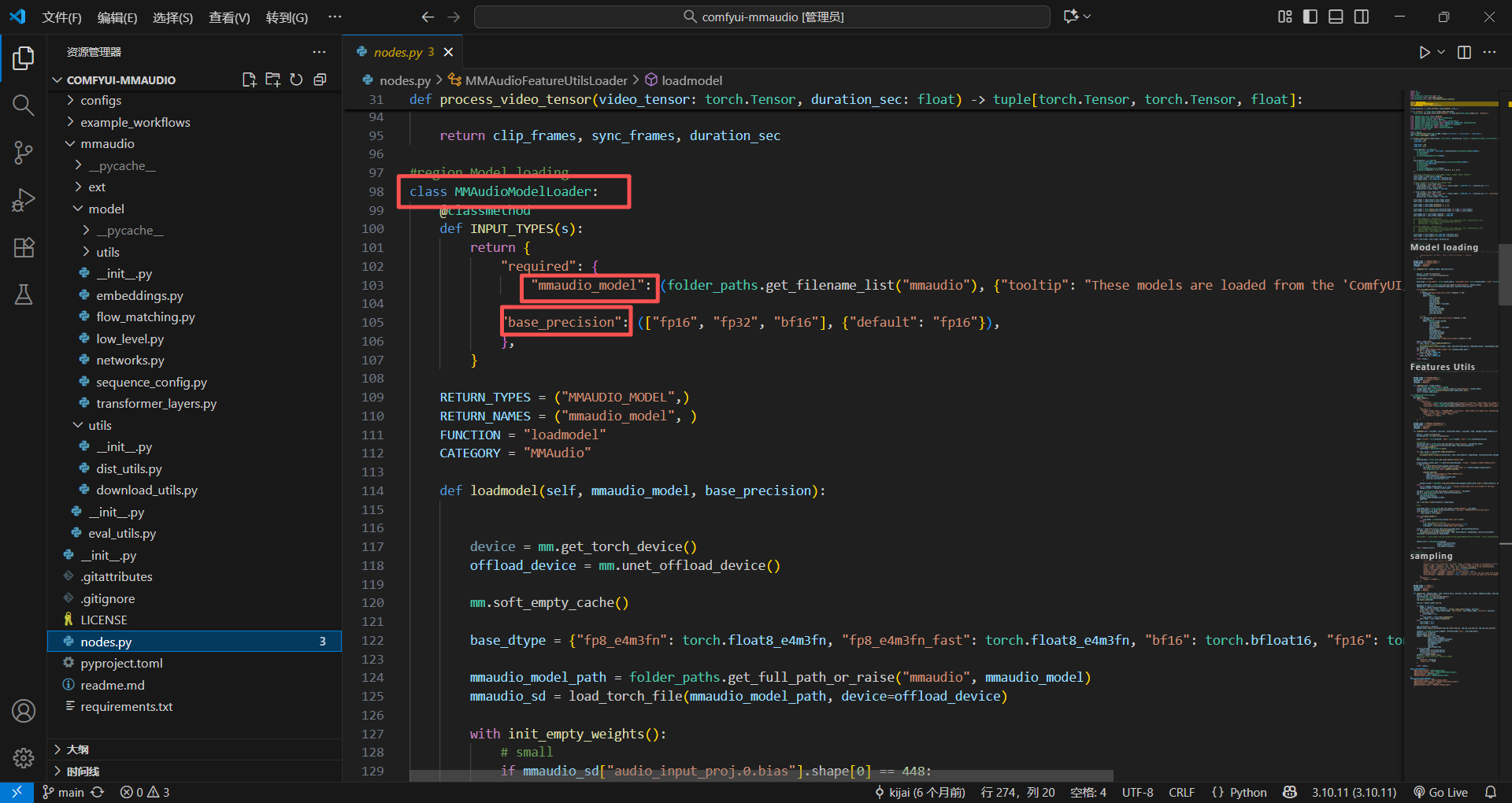
INPUT_TYPES看上面的输入类型,对应输入的东西
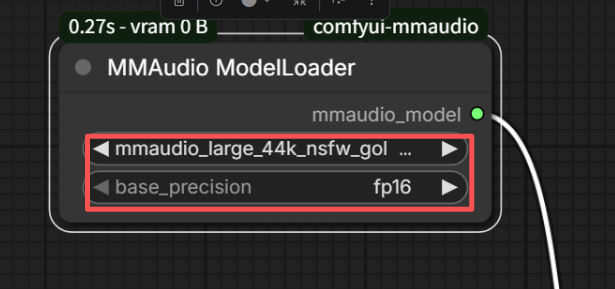
RETURN_TYPES代表输出的类型,其实就是一个暗号,告诉你我输出的是这个暗号,你要跟我的线连在一起,必须得是一样的暗号才行
这个暗号的名字随便你,只要你不去设置官方设置的一些变成其他类型的输入类型就行(例如INT就是数值类型的输入,就不是连线了)
我们可以直接看看这个节点连接的下一个节点的输入代码,暗号肯定是一样的,至于输出了啥给他,是不用管的,一个数字,一张图片,一个对象,啥都可以(只要符合python代码)
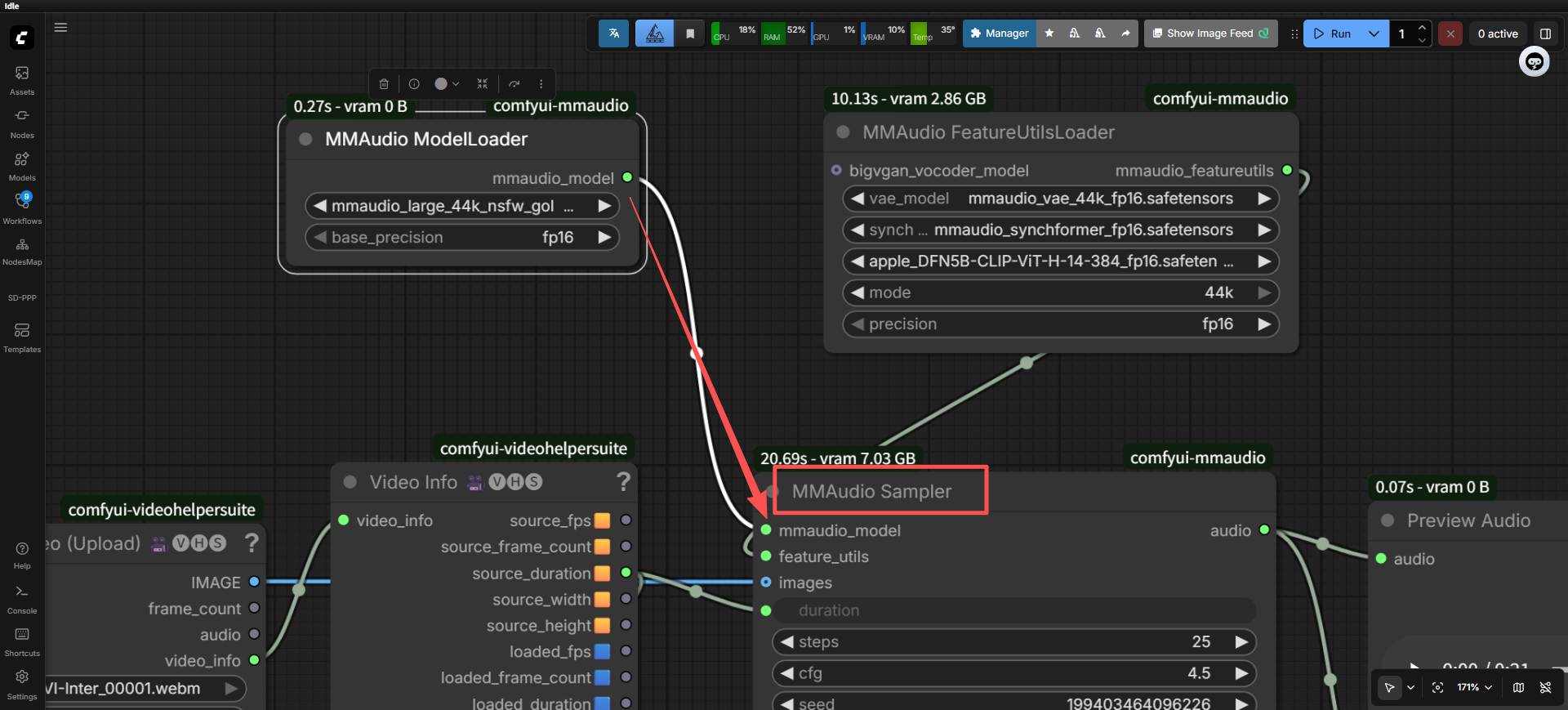
直接搜索这个文件里面的名字定义,肯定有,然后看他对应的类是哪个,马上找到,果真是一样的暗号,天王盖地虎,暗号不对你还连不上的
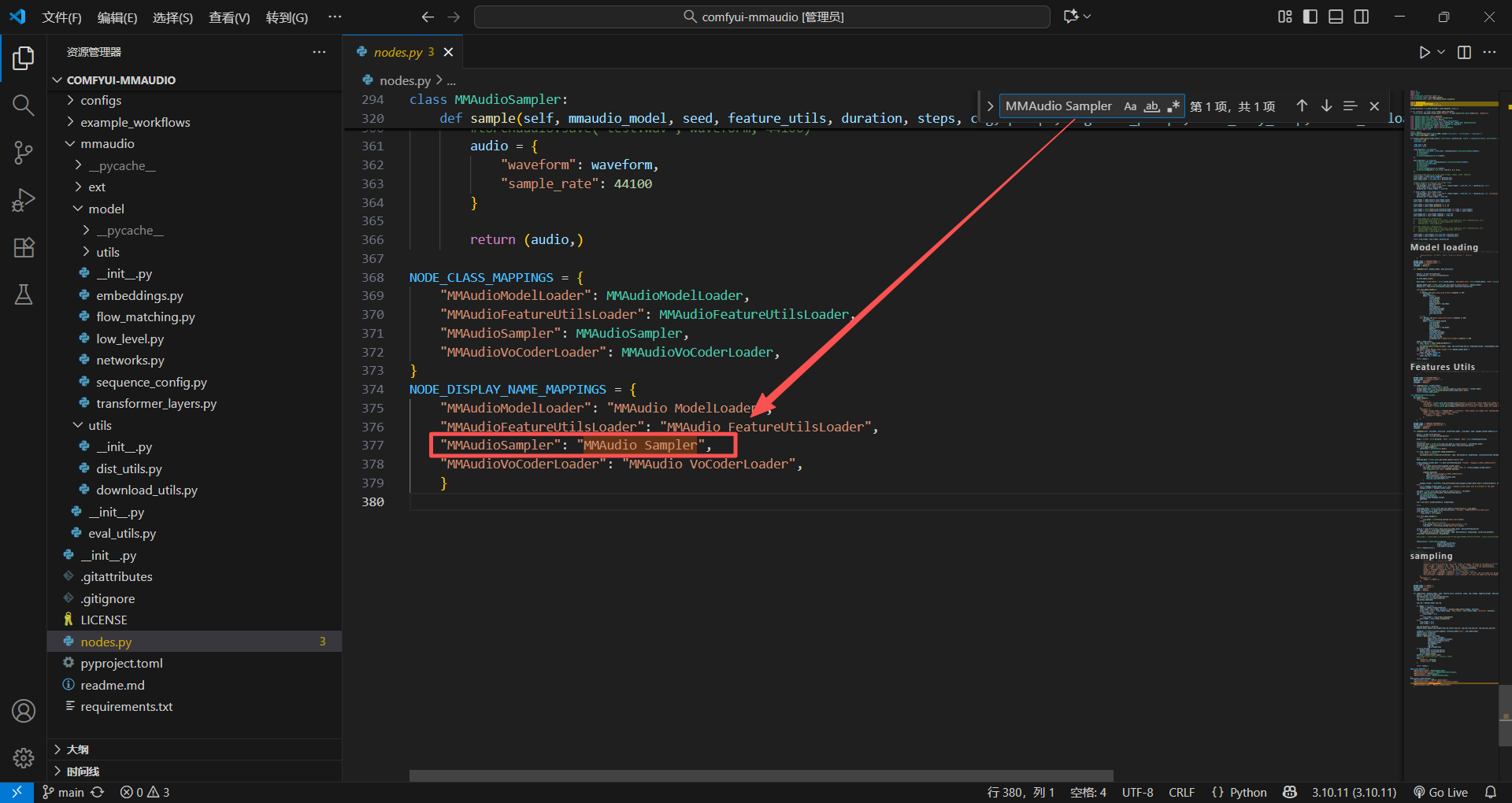
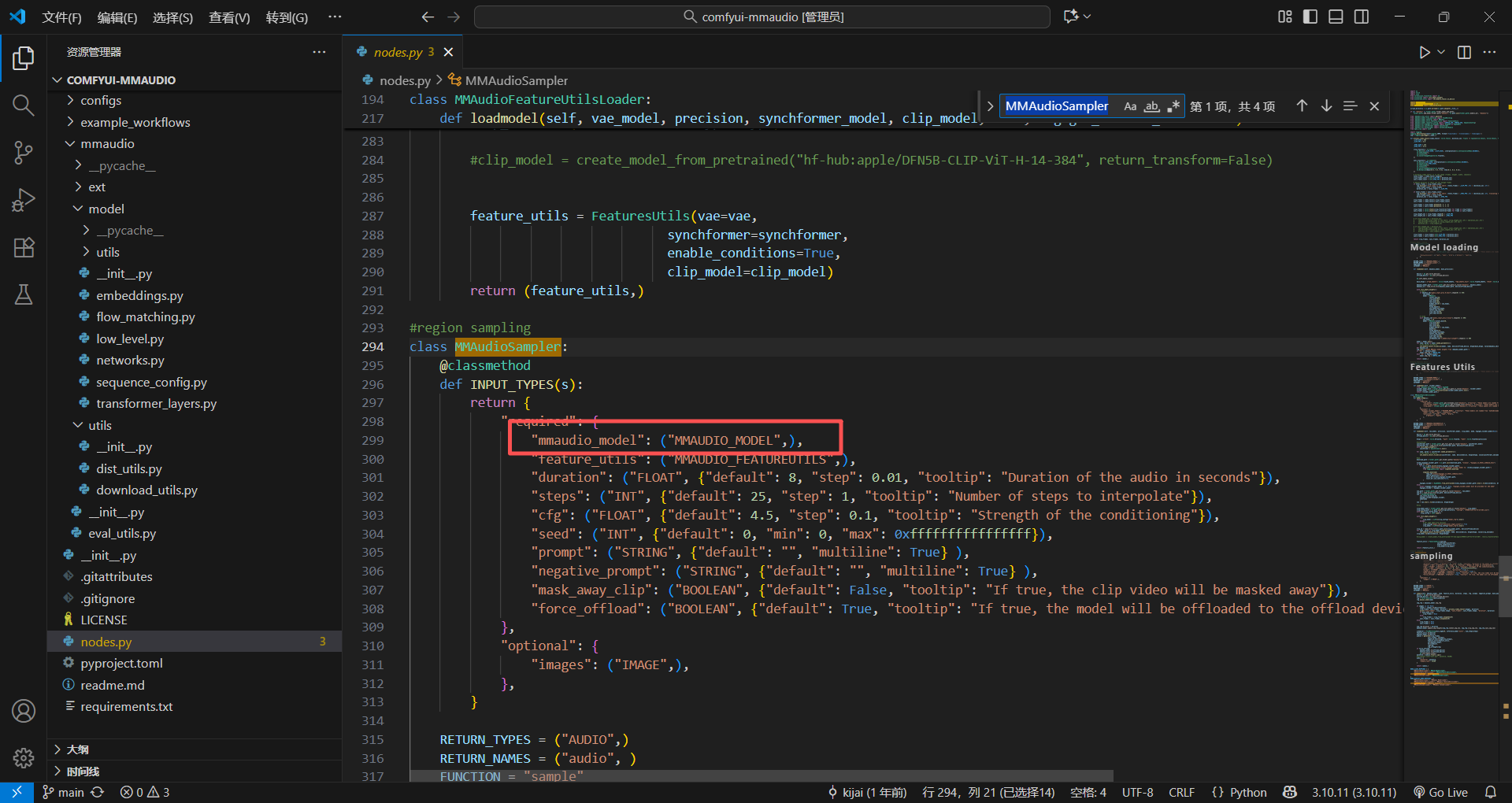
RETURN_NAMES代表输出的名字,你会发现可以连线出来的哪个名字就跟RETURN_NAMES一样,当然可以定义多个,在括号内继续写就行,用逗号隔开
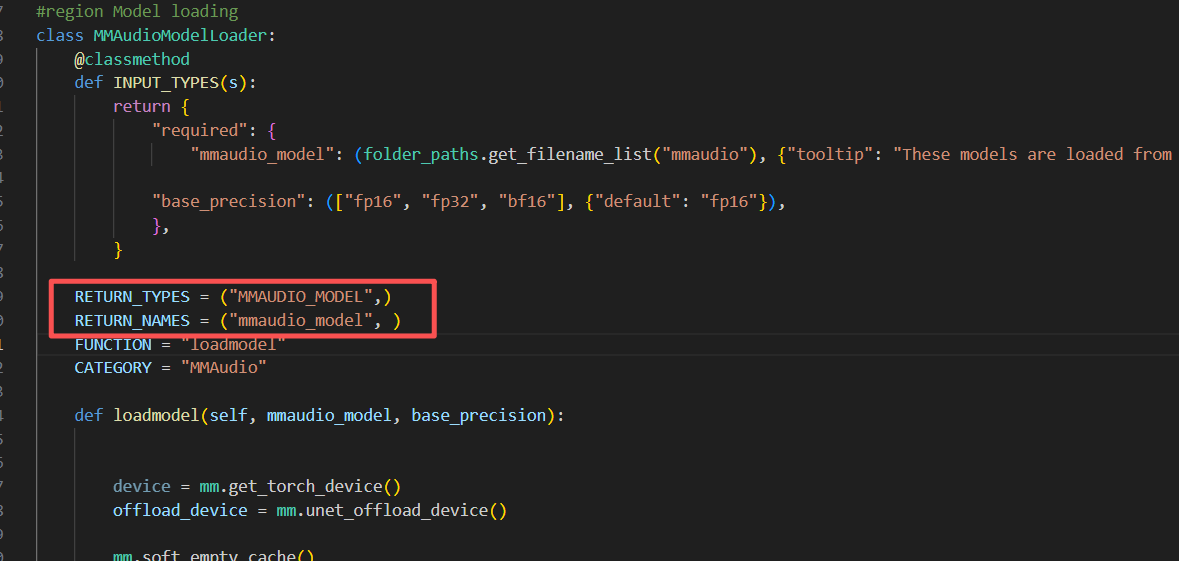
FUNCTION = "loadmodel"
说明这个类的处理过程就在这个loadmodel方法里面,这里就是怎么读取模型的过程,当然这个方法得写在这个类里面
CATEGORY = "MMAudio"
这个就是规定节点的存放位置,就是你搜索的位置,这里就是放在MMAudio下面,我们直接搜索就能看到了,之前我就纳闷过,有些插件位置跟存放的文件夹不一样,原来是这样,果真还是得直接看代码才行
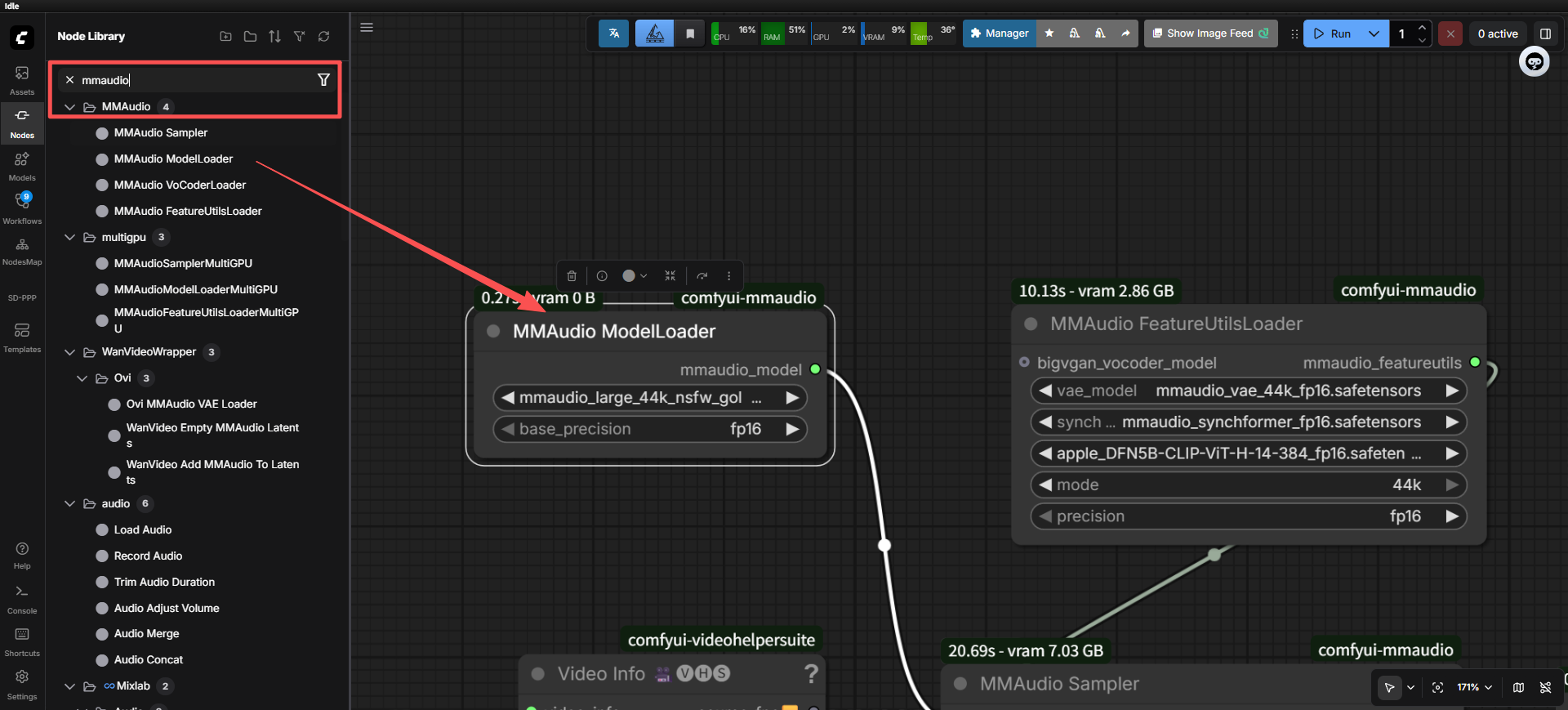
3.节点注册
简单说就是盖个章,让comfyui官方承认
NODE_CLASS_MAPPINGS 就是映射,里面的节点名字随便你设置,例如MMAudioModelLoader是这个节点的名字,他对应的是绿色的MMAudioModelLoader这个类
我们刚才又在这个类里面把那些什么输入输出啊,要干的事情(方法)全部设置好了,所以这个节点就算弄好了,又给官方承认了,那这个类就搞定了,可以直接在comfyui里面直接用
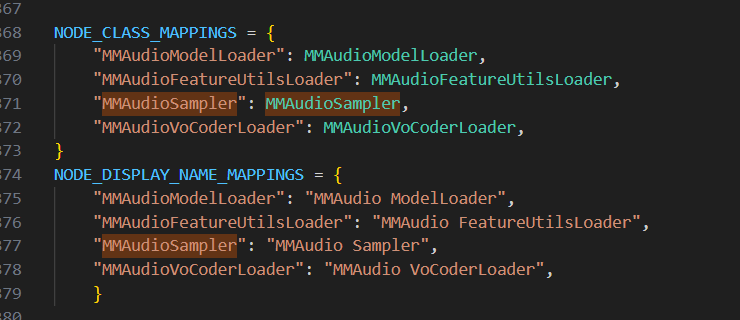
NODE_DISPLAY_NAME_MAPPINGS 这个就是给这个节点显示的名字,后面的是名字,你设置成"爸爸"都无所谓,只不过到时候会变成这样
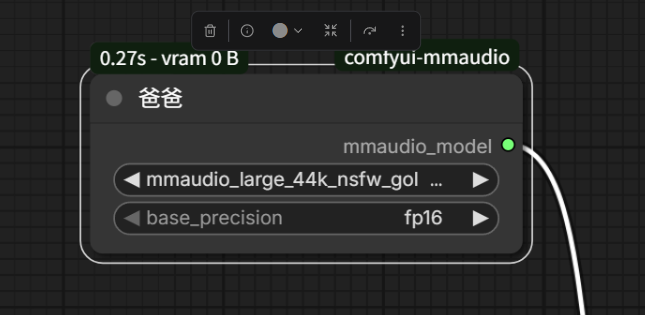
ps :NODE_CLASS_MAPPINGS 和 NODE_DISPLAY_NAME_MAPPINGS 这两个不能随便改,官方规定必须使用这两个名字,不然你一改他就不承认了
init.py
这个就是初始化文件了,对应上面的那几个映射,让comfyui能够找到这里
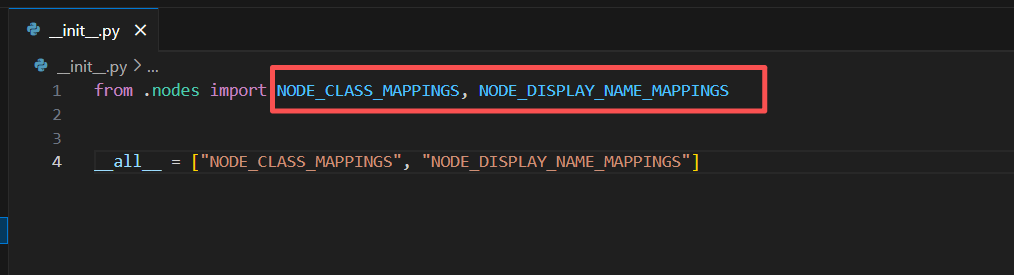
是不是很熟,就是我们刚才定义的那个,然后下面那个all直接一样就行,反正没必要去改,等下又各种问题
就是前面的导入根据你的节点文件名字改就行,这里的是nodes(看你前面的文件名字)
Pyproject TOML
Python 项目的官方配置文件:可以直接理解成这个项目的信息,"项目身份证" + "采购清单"
它的核心作用是:告诉 ComfyUI / Python 编译器 "这个插件是谁、叫什么、需要什么工具才能运行"。
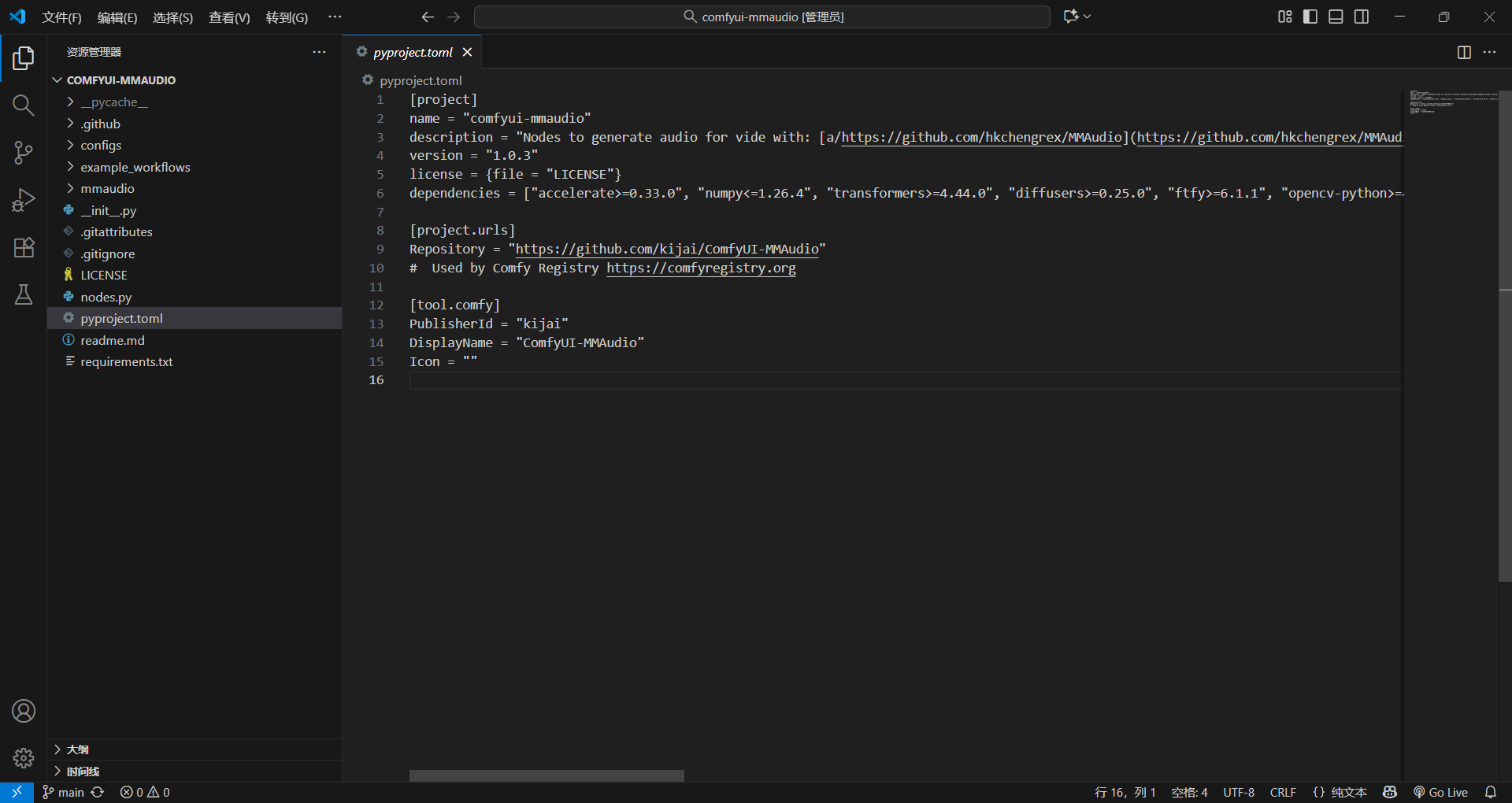
感觉像xml的配置文件啊,反正差不多
可以看到上面写了一些
节点名字(name)、节点描述说明(description)、版本号(version)、协议(license)、仓库的地址(Repository)、仓库发布者也就是作者(PublisherId)等等
最重要的就是这个dependencies------这个告诉我们需要什么依赖库才能使用这个节点,就跟那个requirement差不多
太长了,休息一下,下一篇继续