一、原理
GAN(Generative Adversarial Networks,生成对抗网络) 是一种创新的深度学习框架,其核心思想是通过两个神经网络的对抗性训练,生成高质量、与真实数据相似的新数据。 这一系统由生成器(Generator)和判别(Discriminator)两大核心组件构成,二者在博弈中共同进化,最终实现生成逼真数据的目标。
1、核心组件
(1)生成器(Generator)
功能:接收随机噪声向量作为输入,通过多层神经网络架构将其转换为与真实数据分布相似的新样本(如图像、文本、音频等)。
目标:生成足够逼真的数据,以"欺骗"判别器,使其无法区分生成数据与真实数据。
优化方向:通过调整网络参数,最大化判别器对生成数据的误判概率(即最小化判别器正确识别的概率)。
(2)判别器(Discriminator)
功能:接收真实数据或生成器生成的假数据作为输入,输出一个概率值,表示输入数据为真实数据的概率。
目标:精准区分真实数据与生成数据,确保真实样本被判别为真(概率接近1),生成样本被判别为假(概率接近0)。
优化方向:通过调整网络参数,最大化对真实数据的正确分类概率,同时最小化对生成数据的错误分类概率。
2、对抗训练机制
GAN的训练过程是一种动态博弈,通过交替优化生成器和判别器实现:
(1)训练判别器
固定生成器参数,仅更新判别器参数。
输入真实数据和生成数据,计算判别器对两类数据的损失(如二元交叉熵损失)。
通过反向传播算法更新判别器参数,提升其区分能力。
(2)训练生成器
固定判别器参数,仅更新生成器参数。
输入随机噪声,生成假数据,计算生成器损失(通常基于判别器对生成数据的判断概率)。
通过反向传播算法更新生成器参数,提升其生成逼真数据的能力。
(3)迭代优化
重复上述步骤,交替训练生成器和判别器,直至达到纳什均衡状态。此时,生成器生成的数据分布与真实数据分布无法被判别器区分,系统达到稳定。
3、关键技术
(1)损失函数设计
判别器损失:包含两部分------最大化真实样本的判别概率,同时最小化生成样本的判别概率。
生成器损失:通过对抗损失(如最小化判别器对生成数据的判断概率)推动生成质量持续提升。
改进方案:如Wasserstein GAN采用Wasserstein距离构建损失函数,缓解模式坍塌问题;相对论GAN通过梯度惩罚提升训练稳定性。
(2)网络架构优化
生成器架构:通常采用全连接层、卷积层或Transformer等结构,逐步将低维噪声映射为高维数据。
判别器架构:与生成器对称设计,通过多层非线性变换提取数据特征,最终输出判别概率。
改进方案:如DCGAN(深度卷积生成对抗网络)引入卷积层提升图像生成质量;CycleGAN通过循环一致性损失实现无配对数据跨域转换。
(3)训练稳定性提升
挑战:生成器与判别器能力失衡易导致训练过程振荡或发散。
解决方案:采用梯度惩罚、谱归一化等技术约束判别器梯度;使用多尺度梯度、双时间尺度更新规则平衡训练速度;引入标签平滑、添加噪声等技巧缓解过拟合问题。
二、实践
1、生成器训练
(1)参考代码
python
import numpy as np
import matplotlib.pyplot as plt
# 定义目标图像(16x16 二值矩阵,1=白,0=黑)
target_image = np.array([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
# 可视化目标图像
plt.imshow(target_image, cmap="gray")
plt.title("Target Image (16x16)")
plt.axis("off")
plt.show()
# 将目标图像展平并归一化到[0,1]
target_data = target_image.reshape(1, -1).astype(np.float32)
# 参数设置
latent_dim = 10
hidden_dim = 32
input_dim = 16 * 16
lr = 0.001
epochs = 200
batch_size = 1 # 改为单样本训练(因为只有一个目标图像)
save_num = 50
num_images_to_show = int(epochs/save_num)
fig, axes = plt.subplots(1, num_images_to_show, figsize=(20, 5)) # 横向排列
fig.suptitle("Generated Images During Training", fontsize=16)
# 初始化权重
def init_weights(shape):
return np.random.randn(*shape) * 0.01
# VAE生成器(解码器部分)
class Decoder:
def __init__(self):
self.W1 = init_weights((latent_dim, hidden_dim))
self.b1 = np.zeros(hidden_dim)
self.W2 = init_weights((hidden_dim, input_dim))
self.b2 = np.zeros(input_dim)
def forward(self, z):
self.h1 = np.tanh(np.dot(z, self.W1) + self.b1)
self.logits = np.dot(self.h1, self.W2) + self.b2
self.prob = 1 / (1 + np.exp(-self.logits)) # Sigmoid
return self.prob.reshape(16, 16)
def backward(self, z, d_logits):
# 输出层梯度
d_W2 = np.dot(self.h1.T, d_logits)
d_b2 = np.sum(d_logits, axis=0)
# 隐藏层梯度
d_h1 = np.dot(d_logits, self.W2.T)
d_h1 = d_h1 * (1 - self.h1**2)
# 输入层梯度
d_W1 = np.dot(z.T, d_h1)
d_b1 = np.sum(d_h1, axis=0)
return {"W1": d_W1, "b1": d_b1, "W2": d_W2, "b2": d_b2}
# 训练函数(使用二元交叉熵损失)
def train_decoder(decoder, z, real_data, lr):
# 前向传播
fake_data = decoder.forward(z).reshape(1, -1)
# 二元交叉熵损失
loss = -np.mean(real_data * np.log(fake_data + 1e-8) +
(1 - real_data) * np.log(1 - fake_data + 1e-8))
# 计算梯度
d_logits = (fake_data - real_data) / (fake_data * (1 - fake_data) + 1e-8)
# 反向传播
grads = decoder.backward(z, d_logits)
# 参数更新
decoder.W1 -= lr * grads["W1"]
decoder.b1 -= lr * grads["b1"]
decoder.W2 -= lr * grads["W2"]
decoder.b2 -= lr * grads["b2"]
return loss
# 初始化解码器
decoder = Decoder()
# 训练循环
for epoch in range(epochs+1):
# 生成潜在噪声
z = np.random.randn(1, latent_dim) # batch_size=1
# 训练一步
loss = train_decoder(decoder, z, target_data, lr)
if epoch % save_num == 0:
print(f"Epoch {epoch}, Loss: {loss:.4f}")
generated_image = decoder.forward(z)
# 计算当前图片的索引
img_idx = int(epoch // save_num)
# 如果是单个子图,axes 会是 1D 数组,需要取第一个元素
if num_images_to_show == 1:
ax = axes
else:
ax = axes[img_idx-1]
# 显示图片
ax.imshow(generated_image, cmap="gray", vmin=0, vmax=1)
ax.set_title(f"Epoch {epoch}")
ax.axis("off")
# 调整子图间距
plt.tight_layout()
plt.show()(2)前向传播
1)网络结构
输入:潜在向量z∈R1×latent_dimz\in R^{1 \times latent\_dim}z∈R1×latent_dim
第一层:全连接 + Tanh 激活
权重 W1∈Rlatent_dim×hidden_dimW_1 \in R^{latent\_dim \times hidden\_dim}W1∈Rlatent_dim×hidden_dim
偏置b1∈R1×hidden_dimb_1 \in R^{1 \times hidden\_dim}b1∈R1×hidden_dim
输出:h1=tanh(zW1+b1)h_1 =tanh(zW_1+b_1)h1=tanh(zW1+b1)。
此处为zW1zW_1zW1,而非W1zW_1zW1z。这是因为zzz为1×latent_dim1 \times latent\_dim1×latent_dim,是行向量,所以要与xxx常为列向量做区分。
第二层:全连接 + Sigmoid 激活(输出像素概率)
权重W2∈Rhidden_dim×input_dimW_2 \in R^{hidden\_dim \times input\_dim}W2∈Rhidden_dim×input_dim。其中,input_dim=16∗16=256input\_dim=16*16=256input_dim=16∗16=256
偏置b2∈R1×input_dimb_2 \in R^{1 \times input\_dim}b2∈R1×input_dim
输出:logits=h1W2+b2logits =h_1W_2+b_2logits=h1W2+b2
最终概率:p=σ(logits)=11+e−logitsp=\sigma(logits)=\frac{1}{1+e^{-logits}}p=σ(logits)=1+e−logits1。
2)数学原理
h1=tanh(zW1+b1)h_1 = tanh(zW_1+b_1)h1=tanh(zW1+b1)
tanh(x)=ex+e−xex−e−x,tanh′(x)=1−tanh2(x)tanh(x)=\frac{e^x+e^{-x}}{e^x-e^{-x}},tanh'(x) =1-tanh^2(x)tanh(x)=ex−e−xex+e−x,tanh′(x)=1−tanh2(x)。
Sigmoid的导数
σ′(x)=σ(x)(1−σ(x))\sigma'(x)=\sigma(x)(1-\sigma(x))σ′(x)=σ(x)(1−σ(x))
反向传播优化损失函数
L=1N∑i=1N(yilog(pi)+(1−yi)log(1−pi))L=\frac{1}{N}\sum\limits_{i=1}^N(y_ilog(p_i)+(1-y_i)log(1-p_i))L=N1i=1∑N(yilog(pi)+(1−yi)log(1−pi))
其中,yiy_iyi是真实像素(0,1),pip_ipi是生成概率。
梯度计算:
∂L∂logits=yi−pi\frac{\partial L}{\partial logits}=y_i-p_i∂logits∂L=yi−pi
∂L∂W2=h1T⋅∂L∂logits\frac{\partial L}{\partial W_2}=h_1^T \cdot \frac{\partial L}{\partial logits}∂W2∂L=h1T⋅∂logits∂L
∂L∂b2=∑i=1input_dim∂L∂logits\frac{\partial L}{\partial b_2}=\sum\limits_{i=1}^{input\dim} \frac{\partial L}{\partial logits}∂b2∂L=i=1∑input_dim∂logits∂L
∂L∂h1=∂L∂logits⋅W2T\frac{\partial L}{\partial h_1}= \frac{\partial L}{\partial logits} \cdot W_2^T∂h1∂L=∂logits∂L⋅W2T
∂L∂(zW1+b1)=∂L∂h1⊙(1−h12),⊙表示逐元素相乘。\frac{\partial L}{\partial(zW_1+b_1)}=\frac{\partial L}{\partial h_1} \odot (1-h_1^2),\odot表示逐元素相乘。∂(zW1+b1)∂L=∂h1∂L⊙(1−h12),⊙表示逐元素相乘。
∂L∂W1=zT⋅∂L∂(zW1+b1)\frac{\partial L}{\partial W_1}=z^T \cdot \frac{\partial L}{\partial(zW_1+b_1)}∂W1∂L=zT⋅∂(zW1+b1)∂L
∂L∂b1=∑i=1hidden_dim∂L∂logits\frac{\partial L}{\partial b_1} =\sum\limits{i=1}^{hidden\_dim} \frac{\partial L}{\partial logits}∂b1∂L=i=1∑hidden_dim∂logits∂L
(3)结果分析
初始图像

迭代过程图

可以看出,由于采用全连接+梯度下降的方法,很快就能发现图像的局部特征,多次迭代不过只是增强了图像的整体信息。
2、判别器训练
原理与生成器基本相同,但判别器的训练必须要多个数据 。
(1)参考代码
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# ====================== 1. 定义基础参数与目标图像 ======================
# 目标0-1矩阵
target_image = np.array([
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,1,1,0,0,0,0,0,1,1,0,0,0,0],
[0,0,1,0,0,1,0,0,0,1,0,0,1,0,0,0],
[0,1,0,0,0,0,1,0,1,0,0,0,0,1,0,0],
[0,1,0,0,0,0,1,0,1,0,0,0,0,1,0,0],
[0,0,1,0,0,1,0,0,0,1,0,0,1,0,0,0],
[0,0,0,1,1,0,0,0,0,0,1,1,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],
[0,0,0,1,1,1,1,0,0,1,1,1,1,0,0,0],
[0,0,1,0,0,0,0,1,1,0,0,0,0,1,0,0],
[0,1,0,0,0,0,0,0,0,0,0,0,0,0,1,0],
[0,1,0,0,0,0,0,0,0,0,0,0,0,0,1,0],
[0,0,1,0,0,0,0,1,1,0,0,0,0,1,0,0],
[0,0,0,1,1,1,1,0,0,1,1,1,1,0,0,0],
[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
], dtype=np.float32)
# 基础参数
img_size = target_image.shape[0] # 16
input_dim = img_size * img_size # 256
n_pos_samples = 500 # 正样本数量(低噪声)
n_neg_samples = 500 # 负样本数量(高噪声)
noise_low_threshold = 0.2 # 噪声低阈值
noise_high_threshold = 0.5 # 噪声高阈值
# ====================== 2. 生成训练数据 ======================
def generate_dataset(target, n_pos, n_neg, noise_low_thresh,noise_high_thresh):
"""生成正负样本数据集"""
dataset = []
labels = []
# 生成正样本(噪声0~0.2)
for _ in range(n_pos):
noise = np.random.uniform(0, noise_low_thresh, target.shape)
pos_img = target + noise
pos_img = np.clip(pos_img, 0, 1) # 限制在0-1范围
dataset.append(pos_img.flatten())
labels.append(1) # 正样本标签=1
# 生成负样本(噪声>0.2)
for _ in range(n_neg):
noise = np.random.uniform(noise_high_thresh + 0.01, 1.0, target.shape)
neg_img = target + noise
neg_img = np.clip(neg_img, 0, 1)
dataset.append(neg_img.flatten())
labels.append(0) # 负样本标签=0
# 转换为数组并打乱
dataset = np.array(dataset, dtype=np.float32)
labels = np.array(labels, dtype=np.float32).reshape(-1, 1)
# 打乱数据
shuffle_idx = np.random.permutation(len(dataset))
dataset = dataset[shuffle_idx]
labels = labels[shuffle_idx]
return dataset, labels
# 生成数据集并划分训练/测试集
X, y = generate_dataset(target_image, n_pos_samples, n_neg_samples, noise_low_threshold,noise_high_threshold)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
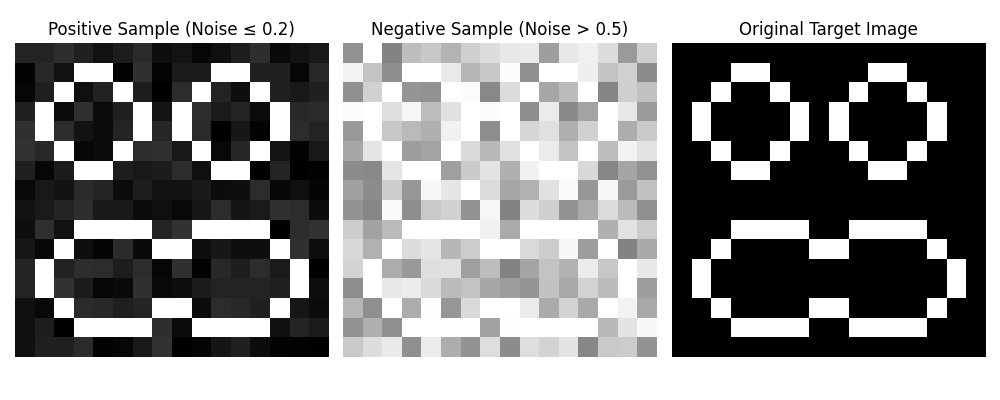
# 可视化样本示例
plt.figure(figsize=(10, 4))
# 正样本示例
pos_idx = np.where(y_train == 1)[0][0]
plt.subplot(1, 3, 1)
plt.imshow(X_train[pos_idx].reshape(img_size, img_size), cmap="gray", vmin=0, vmax=1)
plt.title(f"Positive Sample (Noise ≤ {noise_low_threshold})")
plt.axis("off")
# 负样本示例
neg_idx = np.where(y_train == 0)[0][0]
plt.subplot(1, 3, 2)
plt.imshow(X_train[neg_idx].reshape(img_size, img_size), cmap="gray", vmin=0, vmax=1)
plt.title(f"Negative Sample (Noise > {noise_high_threshold})")
plt.axis("off")
# 原始目标图像
plt.subplot(1, 3, 3)
plt.imshow(target_image, cmap="gray", vmin=0, vmax=1)
plt.title("Original Target Image")
plt.axis("off")
plt.tight_layout()
plt.show()
# ====================== 3. 定义判别器类 ======================
class NoiseDiscriminator:
def __init__(self, input_dim, hidden_dim=128):
# 初始化权重(He初始化)
self.W1 = np.random.randn(input_dim, hidden_dim) * np.sqrt(2. / input_dim)
self.b1 = np.zeros(hidden_dim)
self.W2 = np.random.randn(hidden_dim, hidden_dim) * np.sqrt(2. / hidden_dim)
self.b2 = np.zeros(hidden_dim)
self.W3 = np.random.randn(hidden_dim, 1) * np.sqrt(2. / hidden_dim)
self.b3 = np.zeros(1)
# 记录中间层输出(用于梯度计算)
self.h1, self.h2 = None, None
self.logits, self.out = None, None
def sigmoid(self, x):
"""sigmoid激活函数"""
return 1. / (1. + np.exp(-np.clip(x, -500, 500)))
def sigmoid_deriv(self, x):
"""sigmoid导数"""
s = self.sigmoid(x)
return s * (1 - s)
def relu(self, x):
"""ReLU激活函数"""
return np.maximum(0, x)
def relu_deriv(self, x):
"""ReLU导数"""
return (x > 0).astype(np.float32)
def forward(self, x):
"""前向传播"""
# x: (batch_size, input_dim)
self.h1 = self.relu(np.dot(x, self.W1) + self.b1)
self.h2 = self.relu(np.dot(self.h1, self.W2) + self.b2)
self.logits = np.dot(self.h2, self.W3) + self.b3
self.out = self.sigmoid(self.logits) # 输出概率(0~1)
return self.out
def compute_loss(self, y_pred, y_true):
"""计算交叉熵损失"""
eps = 1e-8 # 防止log(0)
loss = -np.mean(y_true * np.log(y_pred + eps) + (1 - y_true) * np.log(1 - y_pred + eps))
return loss
def backward(self, x, y_true):
"""反向传播计算梯度"""
batch_size = x.shape[0]
# 输出层梯度
d_logits = (self.out - y_true) / batch_size
dW3 = np.dot(self.h2.T, d_logits)
db3 = np.sum(d_logits, axis=0)
# 第二层梯度
dh2 = np.dot(d_logits, self.W3.T) * self.relu_deriv(self.h2)
dW2 = np.dot(self.h1.T, dh2)
db2 = np.sum(dh2, axis=0)
# 第一层梯度
dh1 = np.dot(dh2, self.W2.T) * self.relu_deriv(self.h1)
dW1 = np.dot(x.T, dh1)
db1 = np.sum(dh1, axis=0)
# 梯度裁剪(防止爆炸)
grads = {
"W1": dW1, "b1": db1,
"W2": dW2, "b2": db2,
"W3": dW3, "b3": db3
}
max_norm = 1.0
total_norm = np.sqrt(sum(np.sum(g**2) for g in grads.values()))
clip_coef = max_norm / (total_norm + 1e-8)
if clip_coef < 1:
for k in grads:
grads[k] *= clip_coef
return grads
def update(self, grads, lr):
"""更新权重"""
self.W1 -= lr * grads["W1"]
self.b1 -= lr * grads["b1"]
self.W2 -= lr * grads["W2"]
self.b2 -= lr * grads["b2"]
self.W3 -= lr * grads["W3"]
self.b3 -= lr * grads["b3"]
# ====================== 4. 判别器训练函数 ======================
def train_discriminator(
discriminator,
X_train, y_train,
X_test, y_test,
epochs=50,
batch_size=32,
lr=0.0001,
print_interval=10
):
"""
训练判别器的核心函数
参数:
- discriminator: 判别器实例
- X_train/y_train: 训练集数据/标签
- X_test/y_test: 测试集数据/标签
- epochs: 训练轮次
- batch_size: 批次大小
- lr: 学习率
- print_interval: 打印间隔
"""
train_losses = []
test_losses = []
train_accs = []
test_accs = []
n_batches = len(X_train) // batch_size
for epoch in range(epochs):
# 打乱训练集
shuffle_idx = np.random.permutation(len(X_train))
X_train_shuffled = X_train[shuffle_idx]
y_train_shuffled = y_train[shuffle_idx]
epoch_loss = 0.0
# 批次训练
for b in range(n_batches):
start = b * batch_size
end = start + batch_size
batch_X = X_train_shuffled[start:end]
batch_y = y_train_shuffled[start:end]
# 前向传播
y_pred = discriminator.forward(batch_X)
# 计算损失
loss = discriminator.compute_loss(y_pred, batch_y)
# 反向传播
grads = discriminator.backward(batch_X, batch_y)
# 更新权重
discriminator.update(grads, lr)
epoch_loss += loss
# 计算平均训练损失
avg_train_loss = epoch_loss / n_batches
train_losses.append(avg_train_loss)
# 计算训练集准确率
train_pred = discriminator.forward(X_train)
train_pred_label = (train_pred > 0.5).astype(np.float32)
train_acc = accuracy_score(y_train, train_pred_label)
train_accs.append(train_acc)
# 计算测试集损失和准确率
test_pred = discriminator.forward(X_test)
test_loss = discriminator.compute_loss(test_pred, y_test)
test_losses.append(test_loss)
test_pred_label = (test_pred > 0.5).astype(np.float32)
test_acc = accuracy_score(y_test, test_pred_label)
test_accs.append(test_acc)
# 打印训练进度
if (epoch + 1) % print_interval == 0:
print(f"Epoch {epoch+1}/{epochs} | "
f"Train Loss: {avg_train_loss:.4f} | Train Acc: {train_acc:.4f} | "
f"Test Loss: {test_loss:.4f} | Test Acc: {test_acc:.4f}")
return discriminator, train_losses, test_losses, train_accs, test_accs
# ====================== 5. 初始化并训练判别器 ======================
# 初始化判别器
discriminator = NoiseDiscriminator(input_dim, hidden_dim=128)
# 训练判别器
trained_disc, train_losses, test_losses, train_accs, test_accs = train_discriminator(
discriminator,
X_train, y_train,
X_test, y_test,
epochs=50,
batch_size=32,
lr=0.0001,
print_interval=5
)
# ====================== 6. 训练结果可视化 ======================
# 损失曲线
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label="Train Loss", color="blue")
plt.plot(test_losses, label="Test Loss", color="red")
plt.xlabel("Epoch")
plt.ylabel("Cross Entropy Loss")
plt.title("Discriminator Loss Curve")
plt.legend()
plt.grid(alpha=0.3)
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(train_accs, label="Train Accuracy", color="blue")
plt.plot(test_accs, label="Test Accuracy", color="red")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.title("Discriminator Accuracy Curve")
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
# ====================== 7. 测试判别器效果 ======================
# 随机生成测试样本
def test_discriminator_example(disc, target, noise_low_thresh,noise_high_thresh):
"""测试判别器对不同噪声样本的判断"""
# 生成低噪声样本(正确)
low_noise = np.random.uniform(0, noise_low_thresh, target.shape)
low_noise_img = target + low_noise
low_noise_img = np.clip(low_noise_img, 0, 1)
# 生成高噪声样本(错误)
high_noise = np.random.uniform(noise_high_thresh + 0.01, 1.0, target.shape)
high_noise_img = target + high_noise
high_noise_img = np.clip(high_noise_img, 0, 1)
# 判别器预测
low_noise_pred = disc.forward(low_noise_img.flatten().reshape(1, -1))[0][0]
high_noise_pred = disc.forward(high_noise_img.flatten().reshape(1, -1))[0][0]
# 可视化结果
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.imshow(low_noise_img, cmap="gray", vmin=0, vmax=1)
plt.title(f"Low Noise (≤{noise_low_thresh})\nPred: {low_noise_pred:.4f} (Correct={low_noise_pred>0.5})")
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(high_noise_img, cmap="gray", vmin=0, vmax=1)
plt.title(f"High Noise (> {noise_high_thresh})\nPred: {high_noise_pred:.4f} (Correct={high_noise_pred<0.5})")
plt.axis("off")
plt.tight_layout()
plt.show()
# 测试示例
test_discriminator_example(trained_disc, target_image, noise_low_threshold,noise_high_threshold)(2)结果分析
| 训练次数 | 训练集损失 | 训练集准确率 | 测试集损失 | 测试集准确率 |
|---|---|---|---|---|
| Epoch 5/50 | Train Loss: 0.6163 | Train Acc: 0.6438 | Test Loss: 0.5979 | Test Acc: 0.6850 |
| Epoch 10/50 | Train Loss: 0.5756 | Train Acc: 0.8287 | Test Loss: 0.5600 | Test Acc: 0.8650 |
| Epoch 15/50 | Train Loss: 0.5381 | Train Acc: 0.9413 | Test Loss: 0.5249 | Test Acc: 0.9700 |
| Epoch 20/50 | Train Loss: 0.5038 | Train Acc: 0.9950 | Test Loss: 0.4930 | Test Acc: 1.0000 |
| Epoch 25/50 | Train Loss: 0.4724 | Train Acc: 1.0000 | Test Loss: 0.4634 | Test Acc: 1.0000 |
| Epoch 30/50 | Train Loss: 0.4432 | Train Acc: 1.0000 | Test Loss: 0.4360 | Test Acc: 1.0000 |
| Epoch 35/50 | Train Loss: 0.4162 | Train Acc: 1.0000 | Test Loss: 0.4103 | Test Acc: 1.0000 |
| Epoch 40/50 | Train Loss: 0.3909 | Train Acc: 1.0000 | Test Loss: 0.3864 | Test Acc: 1.0000 |
| Epoch 45/50 | Train Loss: 0.3677 | Train Acc: 1.0000 | Test Loss: 0.3641 | Test Acc: 1.0000 |
| Epoch 50/50 | Train Loss: 0.3459 | Train Acc: 1.0000 | Test Loss: 0.3431 | Test Acc: 1.0000 |
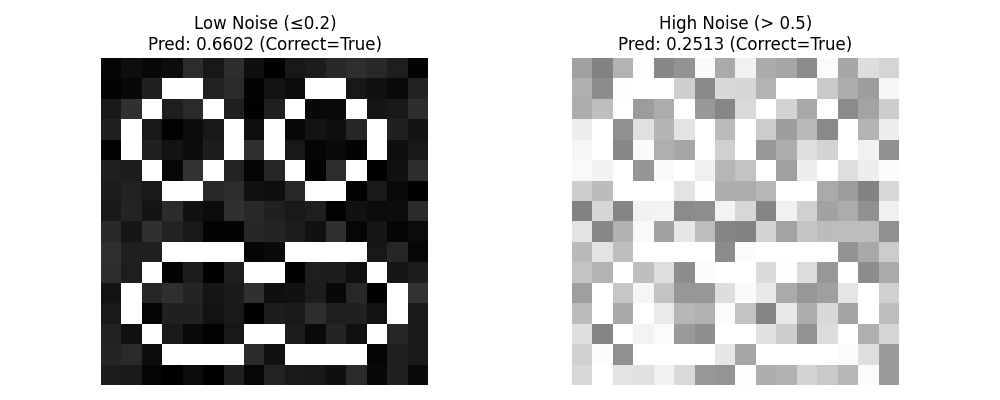
分类效果较好,数据集训练次数50次即可。
3、GAN训练
(1)参考代码
python
import numpy as np
import matplotlib.pyplot as plt
# ====================== 1. 定义目标图像与预处理 ======================
target_image = np.array([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
# 可视化目标图像
plt.figure(figsize=(4, 4))
plt.imshow(target_image, cmap="gray", vmin=0, vmax=1)
plt.title("Target Image (16x16)")
plt.axis("off")
plt.show()
# 展平为一维向量(作为真实样本)
real_data = target_image.reshape(1, -1).astype(np.float32)
# ====================== 2. GAN超参数设置 ======================
latent_dim = 10 # 生成器输入噪声维度
g_hidden_dim = 64 # 生成器隐藏层维度
d_hidden_dim = 32 # 判别器隐藏层维度(比生成器小,避免判别过强)
input_dim = 16 * 16 # 图像展平维度
g_lr = 0.0005 # 生成器学习率(略小,避免生成器过拟合)
d_lr = 0.001 # 判别器学习率
epochs = 50000 # GAN需要更多训练轮数
d_steps = 1 # 每轮训练判别器的次数
g_steps = 1 # 每轮训练生成器的次数
save_interval = 10000 # 每10000轮保存生成结果
batch_size = 1 # 单样本训练
# 可视化设置
num_images_to_show = (epochs // save_interval) + 1
fig, axes = plt.subplots(1, num_images_to_show, figsize=(4*num_images_to_show, 4))
fig.suptitle("GAN Generated Images During Training", fontsize=16)
# ====================== 3. 权重初始化与工具函数 ======================
def init_weights(shape):
"""Xavier初始化,保证梯度稳定"""
if type(shape)!=int and len(shape) == 2:
fan_in, fan_out = shape[0], shape[1]
std = np.sqrt(2 / (fan_in + fan_out))
return np.random.randn(*shape) * std
return np.zeros(shape) # 偏置初始化为0
def sigmoid(x):
"""Sigmoid激活函数(判别器输出)"""
return 1 / (1 + np.exp(-np.clip(x, -500, 500))) # 防止数值溢出
def sigmoid_derivative(x):
"""Sigmoid导数(用于判别器反向传播)"""
s = sigmoid(x)
return s * (1 - s)
def binary_cross_entropy_loss(y_pred, y_true):
"""二元交叉熵损失"""
epsilon = 1e-8
return -np.mean(y_true * np.log(y_pred + epsilon) + (1 - y_true) * np.log(1 - y_pred + epsilon))
# ====================== 4. 生成器定义(替代原VAE解码器) ======================
class Generator:
def __init__(self, latent_dim, hidden_dim, output_dim):
# 生成器网络参数
self.W1 = init_weights((latent_dim, hidden_dim))
self.b1 = init_weights(hidden_dim)
self.W2 = init_weights((hidden_dim, output_dim))
self.b2 = init_weights(output_dim)
# 记录前向传播中间值
self.h1 = None
self.logits = None
self.output = None
def forward(self, z):
"""前向传播:噪声→生成图像"""
# 隐藏层:ReLU激活(生成器常用)
self.h1 = np.maximum(0, np.dot(z, self.W1) + self.b1) # ReLU
# 输出层:Sigmoid归一化到[0,1](匹配图像像素值)
self.logits = np.dot(self.h1, self.W2) + self.b2
self.output = sigmoid(self.logits)
return self.output.reshape(16, 16) # 重塑为图像
def backward(self, z, d_out_grad):
"""反向传播:计算生成器梯度(基于判别器的反馈)"""
# 输出层梯度
d_logits = d_out_grad * sigmoid_derivative(self.logits)
d_W2 = np.dot(self.h1.T, d_logits)
d_b2 = np.sum(d_logits, axis=0)
# 隐藏层梯度(ReLU导数:大于0为1,否则为0)
d_h1 = np.dot(d_logits, self.W2.T) * (self.h1 > 0).astype(np.float32)
d_W1 = np.dot(z.T, d_h1)
d_b1 = np.sum(d_h1, axis=0)
return {"W1": d_W1, "b1": d_b1, "W2": d_W2, "b2": d_b2}
def update(self, grads, lr):
"""参数更新(梯度下降)"""
self.W1 -= lr * grads["W1"]
self.b1 -= lr * grads["b1"]
self.W2 -= lr * grads["W2"]
self.b2 -= lr * grads["b2"]
# ====================== 5. 判别器定义(修复Leaky ReLU) ======================
class Discriminator:
def __init__(self, input_dim, hidden_dim):
# 判别器网络参数(二分类:真实=1,生成=0)
self.W1 = init_weights((input_dim, hidden_dim))
self.b1 = init_weights(hidden_dim)
self.W2 = init_weights((hidden_dim, 1))
self.b2 = init_weights(1)
# 记录前向传播中间值
self.h1 = None
self.logits = None
self.output = None
def forward(self, x):
"""前向传播:图像→判别概率(0-1)"""
# 隐藏层:正确的Leaky ReLU实现
linear_out = np.dot(x, self.W1) + self.b1 # (1,32)
# Leaky ReLU:大于0保留原值,小于0乘以0.2
self.h1 = np.where(linear_out > 0, linear_out, linear_out * 0.2)
# 输出层:Sigmoid输出判别概率
self.logits = np.dot(self.h1, self.W2) + self.b2
self.output = sigmoid(self.logits)
return self.output
def backward(self, x, y_true):
"""反向传播:计算判别器梯度"""
# 输出层梯度(二元交叉熵损失的梯度)
d_logits = (self.output - y_true) / batch_size
d_W2 = np.dot(self.h1.T, d_logits)
d_b2 = np.sum(d_logits, axis=0)
# 隐藏层梯度(Leaky ReLU导数)
d_h1 = np.dot(d_logits, self.W2.T)
# Leaky ReLU导数:大于0为1,小于0为0.2
d_h1 = d_h1 * np.where(self.h1 > 0, 1, 0.2)
d_W1 = np.dot(x.T, d_h1)
d_b1 = np.sum(d_h1, axis=0)
return {"W1": d_W1, "b1": d_b1, "W2": d_W2, "b2": d_b2}
def update(self, grads, lr):
"""参数更新(梯度下降)"""
self.W1 -= lr * grads["W1"]
self.b1 -= lr * grads["b1"]
self.W2 -= lr * grads["W2"]
self.b2 -= lr * grads["b2"]
# ====================== 6. GAN核心训练函数 ======================
def train_gan(generator, discriminator, real_data, latent_dim, epochs, d_steps, g_steps, g_lr, d_lr, save_interval, axes):
"""
训练GAN网络:交替训练判别器和生成器
"""
img_idx = 0
for epoch in range(epochs + 1):
# --------------------------
# 1. 训练判别器(D)
# --------------------------
for _ in range(d_steps):
# 生成噪声
z = np.random.randn(batch_size, latent_dim)
# 步骤1:训练判别器识别真实样本(标签=1)
d_real_pred = discriminator.forward(real_data)
d_real_grads = discriminator.backward(real_data, np.ones_like(d_real_pred))
discriminator.update(d_real_grads, d_lr)
# 步骤2:训练判别器识别生成样本(标签=0)
generator.forward(z) # 生成假样本
d_fake_pred = discriminator.forward(generator.output) # 取生成器展平的输出
d_fake_grads = discriminator.backward(generator.output, np.zeros_like(d_fake_pred))
discriminator.update(d_fake_grads, d_lr)
# --------------------------
# 2. 训练生成器(G)
# --------------------------
for _ in range(g_steps):
# 生成噪声
z = np.random.randn(batch_size, latent_dim)
# 生成器生成样本
generator.forward(z)
# 欺骗判别器:让判别器认为生成样本是真实的(标签=1)
d_pred = discriminator.forward(generator.output)
# 生成器梯度:基于判别器的输出,目标是让d_pred→1
g_out_grad = - (1 - d_pred) * sigmoid_derivative(discriminator.logits) # 生成器损失梯度
g_grads = generator.backward(z, g_out_grad)
generator.update(g_grads, g_lr)
# --------------------------
# 3. 打印损失与保存可视化结果
# --------------------------
if epoch % 5000 == 0:
# 计算当前损失
z = np.random.randn(batch_size, latent_dim)
generator.forward(z)
d_real_loss = binary_cross_entropy_loss(discriminator.forward(real_data), np.ones((1,1)))
d_fake_loss = binary_cross_entropy_loss(discriminator.forward(generator.output), np.zeros((1,1)))
g_loss = binary_cross_entropy_loss(discriminator.forward(generator.output), np.ones((1,1)))
print(f"Epoch {epoch:4d} | D Loss: {d_real_loss + d_fake_loss:.4f} | G Loss: {g_loss:.4f}")
if epoch % save_interval == 0:
# 生成并保存当前图像
z = np.random.randn(batch_size, latent_dim)
generated_img = generator.forward(z)
ax = axes[img_idx] if num_images_to_show > 1 else axes
ax.imshow(generated_img, cmap="gray", vmin=0, vmax=1)
ax.set_title(f"Epoch {epoch}")
ax.axis("off")
img_idx += 1
# ====================== 7. 初始化GAN并训练 ======================
# 初始化生成器和判别器
generator = Generator(latent_dim, g_hidden_dim, input_dim)
discriminator = Discriminator(input_dim, d_hidden_dim)
# 开始训练
train_gan(generator, discriminator, real_data, latent_dim, epochs, d_steps, g_steps, g_lr, d_lr, save_interval, axes)
# 调整子图间距
plt.tight_layout()
plt.show()
# ====================== 8. 最终生成结果 ======================
# 生成最终图像
final_z = np.random.randn(batch_size, latent_dim)
final_img = generator.forward(final_z)
final_img_binary = (final_img > 0.5).astype(np.float32)
# 显示最终结果
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.imshow(final_img, cmap="gray", vmin=0, vmax=1)
plt.title("Final GAN Output (Raw)")
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(final_img_binary, cmap="gray", vmin=0, vmax=1)
plt.title("Final GAN Output (Binary)")
plt.axis("off")
plt.tight_layout()
plt.show()(2)结果分析
目标图片:

训练中生成器表现:

最终结果:

右图为左图锐化结果,并非优秀的输出。
损失函数:
| 训练节点 | 判别器损失 | 生成器损失 |
|---|---|---|
| Epoch 0 | D Loss: 1.1204 | G Loss: 0.7130 |
| Epoch 5000 | D Loss: 0.0045 | G Loss: 6.3255 |
| Epoch 10000 | D Loss: 0.0020 | G Loss: 7.1477 |
| Epoch 15000 | D Loss: 0.0013 | G Loss: 7.4985 |
| Epoch 20000 | D Loss: 0.0009 | G Loss: 7.9259 |
| Epoch 25000 | D Loss: 0.0007 | G Loss: 8.0534 |
| Epoch 30000 | D Loss: 0.0006 | G Loss: 8.4213 |
| Epoch 35000 | D Loss: 0.0005 | G Loss: 8.4327 |
| Epoch 40000 | D Loss: 0.0005 | G Loss: 8.3566 |
| Epoch 45000 | D Loss: 0.0004 | G Loss: 8.6743 |
| Epoch 50000 | D Loss: 0.0003 | G Loss: 9.0597 |
结合三者不难看出,模型训练出现了模式崩溃 。
(3)模式崩溃
GAN 的理想目标是:生成器能学习到真实数据的完整分布(比如能生成不同角度、不同细节的 "眼睛"),但模式崩溃时,生成器只会学习到真实分布的极小一部分(甚至完全偏离),表现为:
生成器要么只输出某一种固定样本,要么输出毫无意义的噪点,彻底无法生成符合预期的多样化结果。
完全崩溃:生成图全是噪点、全黑 / 全白、模糊一片,完全没有目标结构(比如眼睛轮廓)。
部分崩溃(常见) 所有生成图都是 "同一张脸 / 同一个眼睛",只是略有噪点差异,丧失多样性。
局部崩溃 生成图有大致结构,但关键部分(比如眼睛的瞳孔)永远缺失 / 变形。
模式崩溃的损失曲线有三大典型特征:
判别器损失(D Loss)持续趋近于 0: 判别器能 100% 区分真假样本,对生成器的输出 "一眼识破",完全碾压生成器;
生成器损失(G Loss)持续飙升 / 居高不下: 生成器尝试无数次都无法欺骗判别器,损失(-log (D (G (z))))越来越大,彻底学不到有效信息;
损失曲线无波动 / 单边走:健康 GAN 的 D Loss 和 G Loss 会在 0.69(ln2)左右波动,形成动态平衡;崩溃时曲线要么一路跌、要么一路涨,毫无平衡可言。
3、改进模式崩溃
(1)使用原始数据
python
import numpy as np
import matplotlib.pyplot as plt
# ====================== 1. 定义目标图像与预处理 ======================
target_image = np.array([
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
# 创建带噪声的样本
num_samples = 4
sample_data = np.stack([target_image] * num_samples, axis=0).astype(np.float32)
noise_scale = 0.5
noise = np.random.normal(loc=0.0, scale=noise_scale, size=sample_data.shape).astype(np.float32)
real_data = sample_data + noise
real_data = np.clip(real_data, 0.0, 1.0)
# 可视化带噪声的真实样本
plt.figure(figsize=(12, 4))
for i in range(num_samples):
plt.subplot(1, num_samples, i+1)
plt.imshow(real_data[i], cmap="gray", vmin=0, vmax=1)
plt.title(f"Noisy Real Sample {i+1}")
plt.axis("off")
plt.tight_layout()
plt.show()
# 展平为一维向量
real_data_flat = real_data.reshape(num_samples, -1)
# ====================== 2. 超参数 ======================
latent_dim = 40
g_hidden_dim = 128
d_hidden_dim = 16
input_dim = 16 * 16
g_lr = 0.0002
d_lr = 0.0001
epochs = 2000
d_steps = 2
g_steps = 1
save_interval = 400
batch_size = 2
num_batches = num_samples // batch_size
# 新增:MSE损失权重(平衡GAN损失和监督损失)
mse_weight = 0.9
# 可视化设置
num_images_to_show = (epochs // save_interval) + 1
fig, axes = plt.subplots(num_samples, num_images_to_show,
figsize=(4*num_images_to_show, 4*num_samples))
fig.suptitle("GAN Generated Images (With Supervised MSE Loss)", fontsize=16)
# ====================== 3. 工具函数 ======================
def init_weights(shape):
if type(shape)!=int and len(shape) == 2:
fan_in, fan_out = shape[0], shape[1]
std = np.sqrt(2 / (fan_in + fan_out))
return np.random.randn(*shape) * std
return np.zeros(shape)
def sigmoid(x):
return 1 / (1 + np.exp(-np.clip(x, -500, 500)))
def sigmoid_derivative(x):
s = sigmoid(x)
return s * (1 - s)
def binary_cross_entropy_loss(y_pred, y_true):
epsilon = 1e-8
return -np.mean(y_true * np.log(y_pred + epsilon) + (1 - y_true) * np.log(1 - y_pred + epsilon))
def mse_loss(y_pred, y_true):
"""新增:均方误差损失(监督学习)"""
return np.mean((y_pred - y_true) ** 2)
def clip_gradient(grads, max_norm=1.0):
total_norm = 0
for key in grads.keys():
total_norm += np.sum(grads[key] **2)
total_norm = np.sqrt(total_norm)
clip_coef = max_norm / (total_norm + 1e-6)
if clip_coef < 1:
for key in grads.keys():
grads[key] *= clip_coef
return grads
# ====================== 4. 生成器(新增MSE梯度计算) ======================
class Generator:
def __init__(self, latent_dim, hidden_dim, output_dim):
self.W1 = init_weights((latent_dim, hidden_dim))
self.b1 = init_weights(hidden_dim)
self.W2 = init_weights((hidden_dim, hidden_dim))
self.b2 = init_weights(hidden_dim)
self.W3 = init_weights((hidden_dim, output_dim))
self.b3 = init_weights(output_dim)
self.h1, self.h2 = None, None
self.logits, self.output = None, None
def forward(self, z):
self.h1 = np.maximum(0, np.dot(z, self.W1) + self.b1) # ReLU
self.h2 = np.maximum(0, np.dot(self.h1, self.W2) + self.b2) # ReLU
self.logits = np.dot(self.h2, self.W3) + self.b3
self.output = sigmoid(self.logits) # 输出0-1之间
return self.output.reshape(-1, 16, 16)
def backward_gan(self, z, d_pred):
"""GAN损失的反向传播(修正版)"""
# 正确的GAN梯度:-log(D(G(z))) 的导数
d_logits_grad = -1 / (d_pred + 1e-8) * sigmoid_derivative(self.logits)
d_logits = d_logits_grad
d_W3 = np.dot(self.h2.T, d_logits)
d_b3 = np.sum(d_logits, axis=0)
d_h2 = np.dot(d_logits, self.W3.T) * (self.h2 > 0).astype(np.float32)
d_W2 = np.dot(self.h1.T, d_h2)
d_b2 = np.sum(d_h2, axis=0)
d_h1 = np.dot(d_h2, self.W2.T) * (self.h1 > 0).astype(np.float32)
d_W1 = np.dot(z.T, d_h1)
d_b1 = np.sum(d_h1, axis=0)
return {"W1": d_W1, "b1": d_b1, "W2": d_W2, "b2": d_b2, "W3": d_W3, "b3": d_b3}
def backward_mse(self, z, real_target):
"""MSE监督损失的反向传播(新增)"""
# MSE损失:(G(z) - real)^2 / 2 的导数
mse_grad = (self.output - real_target) / batch_size
d_logits = mse_grad * sigmoid_derivative(self.logits)
d_W3 = np.dot(self.h2.T, d_logits)
d_b3 = np.sum(d_logits, axis=0)
d_h2 = np.dot(d_logits, self.W3.T) * (self.h2 > 0).astype(np.float32)
d_W2 = np.dot(self.h1.T, d_h2)
d_b2 = np.sum(d_h2, axis=0)
d_h1 = np.dot(d_h2, self.W2.T) * (self.h1 > 0).astype(np.float32)
d_W1 = np.dot(z.T, d_h1)
d_b1 = np.sum(d_h1, axis=0)
return {"W1": d_W1, "b1": d_b1, "W2": d_W2, "b2": d_b2, "W3": d_W3, "b3": d_b3}
def update(self, grads, lr):
self.W1 -= lr * grads["W1"]
self.b1 -= lr * grads["b1"]
self.W2 -= lr * grads["W2"]
self.b2 -= lr * grads["b2"]
self.W3 -= lr * grads["W3"]
self.b3 -= lr * grads["b3"]
# ====================== 5. 判别器(保持不变) ======================
class Discriminator:
def __init__(self, input_dim, hidden_dim):
self.W1 = init_weights((input_dim, hidden_dim))
self.b1 = init_weights(hidden_dim)
self.W2 = init_weights((hidden_dim, 1))
self.b2 = init_weights(1)
self.h1 = None
self.logits, self.output = None, None
def forward(self, x):
linear_out1 = np.dot(x, self.W1) + self.b1
self.h1 = np.where(linear_out1 > 0, linear_out1, linear_out1 * 0.2) # Leaky ReLU
self.logits = np.dot(self.h1, self.W2) + self.b2
self.output = sigmoid(self.logits)
return self.output
def backward(self, x, y_true):
d_logits = (self.output - y_true) / batch_size
d_W2 = np.dot(self.h1.T, d_logits)
d_b2 = np.sum(d_logits, axis=0)
d_h1 = np.dot(d_logits, self.W2.T)
d_h1 = d_h1 * np.where(self.h1 > 0, 1, 0.2)
d_W1 = np.dot(x.T, d_h1)
d_b1 = np.sum(d_h1, axis=0)
grads = {"W1": d_W1, "b1": d_b1, "W2": d_W2, "b2": d_b2}
grads = clip_gradient(grads, max_norm=0.5)
return grads
def update(self, grads, lr):
self.W1 -= lr * grads["W1"]
self.b1 -= lr * grads["b1"]
self.W2 -= lr * grads["W2"]
self.b2 -= lr * grads["b2"]
# ====================== 6. 训练函数(核心改进:加入MSE监督) ======================
def train_gan(generator, discriminator, real_data, latent_dim, epochs,
d_steps, g_steps, g_lr, d_lr, save_interval, axes, mse_weight):
d_loss_history, g_loss_history, mse_loss_history = [], [], []
img_idx = 0
for epoch in range(epochs + 1):
idx = np.random.permutation(num_samples)
real_data_shuffled = real_data[idx]
epoch_d_loss, epoch_g_loss, epoch_mse_loss = 0.0, 0.0, 0.0
for b in range(num_batches):
batch_real = real_data_shuffled[b*batch_size : (b+1)*batch_size]
batch_real_flat = batch_real.reshape(batch_size, -1)
# -------------------------- 训练判别器 --------------------------
for _ in range(d_steps):
z = np.random.randn(batch_size, latent_dim)
real_label = np.ones((batch_size, 1)) * 0.9
fake_label = np.zeros((batch_size, 1)) * 0.1
# 训练真实样本
d_real_pred = discriminator.forward(batch_real_flat)
d_real_grads = discriminator.backward(batch_real_flat, real_label)
discriminator.update(d_real_grads, d_lr)
# 训练生成样本
generator.forward(z)
batch_fake_flat = generator.output.reshape(batch_size, -1)
d_fake_pred = discriminator.forward(batch_fake_flat)
d_fake_grads = discriminator.backward(batch_fake_flat, fake_label)
discriminator.update(d_fake_grads, d_lr)
# 累计损失
d_real_loss = binary_cross_entropy_loss(d_real_pred, real_label)
d_fake_loss = binary_cross_entropy_loss(d_fake_pred, fake_label)
epoch_d_loss += (d_real_loss + d_fake_loss)
# -------------------------- 训练生成器(核心改进) --------------------------
for _ in range(g_steps):
z = np.random.randn(batch_size, latent_dim)
# 1. 前向传播生成样本
generator.forward(z)
batch_fake_flat = generator.output.reshape(batch_size, -1)
# 2. GAN损失:欺骗判别器
d_pred = discriminator.forward(batch_fake_flat)
g_gan_grads = generator.backward_gan(z, d_pred)
g_gan_loss = binary_cross_entropy_loss(d_pred, np.ones((batch_size,1)))
# 3. MSE监督损失:直接匹配真实数据(新增)
g_mse_grads = generator.backward_mse(z, batch_real_flat)
g_mse_loss = mse_loss(generator.output, batch_real_flat)
# 4. 混合梯度:GAN损失 + MSE监督损失
mixed_grads = {}
for key in g_gan_grads.keys():
mixed_grads[key] = (1 - mse_weight) * g_gan_grads[key] + mse_weight * g_mse_grads[key]
# 5. 更新生成器
generator.update(mixed_grads, g_lr)
# 累计损失
epoch_g_loss += g_gan_loss
epoch_mse_loss += g_mse_loss
# 计算平均损失
avg_d_loss = epoch_d_loss / (num_batches * d_steps)
avg_g_loss = epoch_g_loss / (num_batches * g_steps)
avg_mse_loss = epoch_mse_loss / (num_batches * g_steps)
d_loss_history.append(avg_d_loss)
g_loss_history.append(avg_g_loss)
mse_loss_history.append(avg_mse_loss)
# 打印与可视化
if epoch % save_interval == 0:
print(f"Epoch {epoch:4d} | D Loss: {avg_d_loss:.4f} | G Loss: {avg_g_loss:.4f} | MSE Loss: {avg_mse_loss:.4f}")
z = np.random.randn(num_samples, latent_dim)
generated_imgs = generator.forward(z)
for i in range(num_samples):
ax = axes[i, img_idx]
ax.imshow(generated_imgs[i], cmap="gray", vmin=0, vmax=1)
ax.set_title(f"Epoch {epoch}")
ax.axis("off")
img_idx += 1
# 绘制损失曲线
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.plot(d_loss_history, label="Discriminator Loss", color="blue")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Discriminator Loss")
plt.subplot(1, 3, 2)
plt.plot(g_loss_history, label="Generator GAN Loss", color="red")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Generator GAN Loss")
plt.subplot(1, 3, 3)
plt.plot(mse_loss_history, label="Generator MSE Loss", color="green")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Generator MSE Loss (Supervised)")
plt.suptitle("Loss Curve (GAN + MSE Supervision)")
plt.tight_layout()
plt.show()
# 最终对比
z = np.random.randn(num_samples, latent_dim)
generated_imgs = generator.forward(z)
plt.figure(figsize=(12, 8))
for i in range(num_samples):
plt.subplot(2, num_samples, i+1)
plt.imshow(real_data[i], cmap="gray", vmin=0, vmax=1)
plt.title(f"Real {i+1}")
plt.axis("off")
plt.subplot(2, num_samples, i+1+num_samples)
plt.imshow(generated_imgs[i], cmap="gray", vmin=0, vmax=1)
plt.title(f"Gen {i+1}")
plt.axis("off")
plt.tight_layout()
plt.show()
# ====================== 7. 初始化并训练 ======================
generator = Generator(latent_dim, g_hidden_dim, input_dim)
discriminator = Discriminator(input_dim, d_hidden_dim)
train_gan(generator, discriminator, real_data, latent_dim, epochs,
d_steps, g_steps, g_lr, d_lr, save_interval, axes, mse_weight)即通过使用原始数据得到均方误差(Mean Square Error,MSE)来辅助更新生成器。
结果如下:
增加噪声的原始图片:

判别器和生成器的GAN误差和MSE误差曲线图。
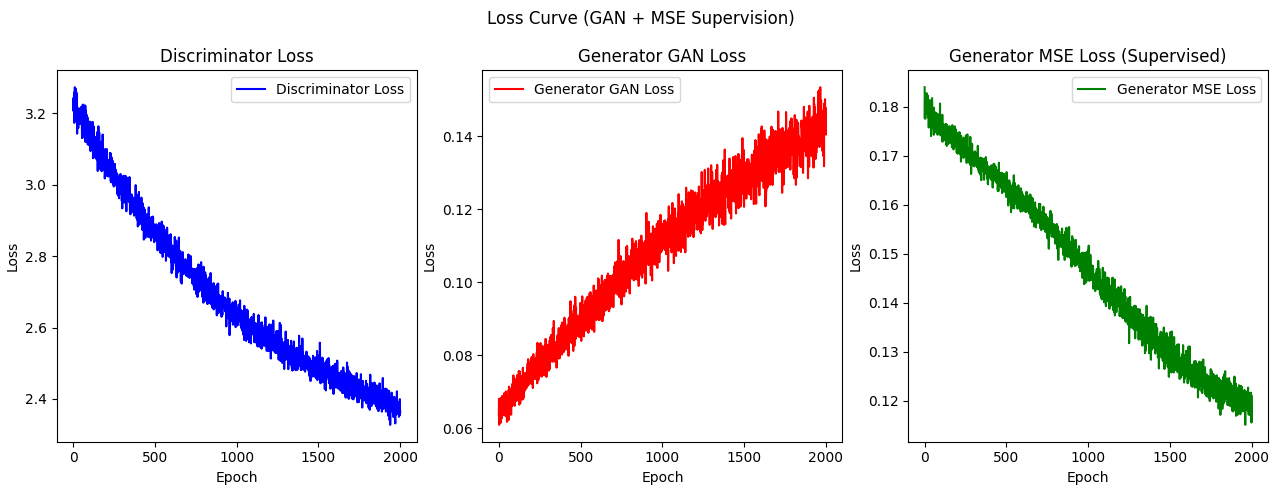
由此图可知,GAN误差与MSE误差变化趋势相反,所以此时GAN式的训练已经是反作用了。
迭代过程图和最终结果图:


结合生成器的训练过程可知,模型的GAN训练确实起到了反作用,生成器生成的数据逐渐接近全零矩阵了。用原始数据抵消不了
三、总结
GAN在训练极小样本集时很容易出现模型崩溃。