摘要
很多教程直接调用GCNConv,但你真的理解 D~−1/2A~D~−1/2在做什么吗? 本文用纯NumPy从零实现两层GCN ,在34节点的空手道俱乐部图上完成半监督节点分类。通过手写对称归一化邻接矩阵、数值梯度下降和可视化,深入讲解图卷积的核心机制。实验表明,仅标注2个节点即可达到**96.88%**的测试准确率。
一、为什么要从零手写GCN?
CNN处理图像(规则的像素网格),RNN处理文本(时间序列),但现实中还有大量的图数据 :社交网络、分子结构、交通路网......它们是不规则的,这就需要用到图神经网络了。图神经网络近年来火得一塌糊涂,但很多入门教程直接上PyTorch Geometric,封装的太好反而看不清图神经网络的本质。图神经网络的核心,就是每个节点通过边从邻居那里"借来"信息,更新自己的表示。听起来似乎很玄乎,其实本质就是矩阵乘法。
本文只用NumPy实现这一切,全程不依赖任何深度学习框架,所有公式都摊开给你看,让你彻底理解邻接矩阵归一化、消息传递、ReLU、Softmax交叉熵以及梯度下降这些组件是如何协同工作的,代码不到100行,可直接运行。读完你就会明白:
- 那坨 D~−1/2A~D~−1/2到底是干嘛的?
- 为什么随便初始化一个 W 矩阵,就能把节点分类?
- 怎样只标注1~2个节点,让模型自己猜出全图标签?
二、数据准备:空手道俱乐部与度的独热编码
2.1、加载图并获取邻接矩阵
Zachary空手道俱乐部图是图学习的"Hello World"。34个节点代表俱乐部成员,78条边代表社交关系,后因教练(节点0)与主管(节点33)争执分裂成两个社区。
python
import networkx as nx
import numpy as np
G = nx.karate_club_graph()
A = nx.to_numpy_array(G) # 34×34 邻接矩阵,0/1
labels = np.array([G.nodes[i]['club'] for i in range(34)])
labels = (labels == 'Mr. Hi').astype(int) # 0/1 标签2.2、构造节点特征:度独热编码
这个图没有原始属性(年龄、兴趣等),必须给每个节点一个初始特征。最简单的办法是度的独热编码:每个节点的度(朋友数)用一个编码表示。
python
degrees = np.array([d for _, d in G.degree()])
max_deg = degrees.max()
X = np.eye(max_deg + 1)[degrees] # (34, max_deg+1) 独热矩阵比如节点0度=16,max_deg=17,则节点0的特征就是18维向量,第16位是1,其余是0,这样每个节点的初始表示就有了区分度。
2.3、半监督设定:只标注极少节点
为了展现GCN的半监督传播能力,我们只标注节点0(标签0,代表'Mr. Hi'),再加一个节点33(标签1,代表'Officer')以防止训练坍缩。训练掩码定义如下:
python
train_mask = np.zeros(34, dtype=bool)
train_mask[0] = True
train_mask[33] = True 三、GCN的灵魂:对称归一化邻接矩阵
3.1、为什么不能直接用原始 A?
直接用 A @ X 聚合邻居特征有两个问题:
- 节点自己没参与(对角线全是0),自身特征被忽略。
- 高度节点(如节点0有16个朋友)聚合后特征数值会很大,低度节点很小,造成数值不稳定。因此经典GCN做了两步改造:加自环 + 对称归一化。
3.2、三步构造归一化矩阵
第一步:加自环
python
A_tilde = A + np.eye(34) # 对角线变成1第二步:计算度矩阵并求逆平方根
python
D_tilde = np.diag(np.sum(A_tilde, axis=1)) # 对角矩阵,对角线是每个节点的度(加自环后)
D_inv_sqrt = np.linalg.inv(np.sqrt(D_tilde)) # D^{-1/2}第三步:对称归一化
python
A_norm = D_inv_sqrt @ A_tilde @ D_inv_sqrt"为简化符号,后文统一用 A~ 表示已完成对称归一化的邻接矩阵 Anorm,即
A~=D~−1/2A~D~−1/2
这个 A_norm 就是最终的"卷积核"。对于节点i和节点j之间的边,权重变为:
A~ij=D~ii⋅D~jj 1
- 原来有边的地方,变成一个小数(如 1/10 =0.316)
- 没有边的地方仍是0
- 对角线上是 1/Dii
3.3、数学直觉:为什么归一化因子是√D?
对称归一化 D~−1/2A~D~−1/2 的本质是同时约束行和列: 左乘让"发送者"的度归一化,右乘让"接收者"的度归一化。如果只用一个 D−1,相当于只有单向约束,高度节点仍然会"淹没"低度节点。
小知识: A~norm 与归一化图拉普拉斯
L=I−D~−1/2A~D~−1/2
有直接关系,GCN 正是基于 L 的谱分解的一阶近似。感兴趣的读者可以延伸阅读 Kipf 论文的附录。
四、两层GCN向前传播
4.1、单层公式
H(l+1)=ReLU(A~H(l)W(l))
- H(l):第 l 层的节点表示矩阵,初始 H(0)=X
- W(l):可学习的权重矩阵
- ReLU(x)=max(0,x):非线性激活,负值被截断为0,为网络引入非线性,否则多层叠加仍等价于单层线性变换。
消息传递过程: Anorm@H@W 就是每个节点先从邻居(含自己)聚合特征,再通过 W 做线性变换,最后过激活函数。
4.2、代码实现
python
input_dim = X.shape[1] # 18(最大度+1)
hidden_dim = 2 # 设为2方便直接画图,也可以调大
output_dim = 2 # 二分类
np.random.seed(42)
W1 = np.random.randn(input_dim, hidden_dim) * 0.01
W2 = np.random.randn(hidden_dim, output_dim) * 0.01
def softmax(x):
e = np.exp(x - np.max(x, axis=1, keepdims=True))
return e / np.sum(e, axis=1, keepdims=True)
# 前向传播
H = np.maximum(0, A_norm @ X @ W1) # 第一层 → ReLU
out = A_norm @ H @ W2 # 第二层 logits
pred = softmax(out) # 概率Softmax 把原始输出(logits)压成概率分布:
softmax(xi)=∑jexjexi
代码里先减 max 是为了防止指数爆炸,这是数值稳定技巧。
hidden_dim=2 纯粹是为了之后把中间嵌入画在二维平面上,实际上你可以设任意值(比如5或许能得到更高准确率)。
4.3、直觉:为什么GCN能传播标签?
想象在一张白纸上滴一滴墨水,墨水会沿着纸的纤维慢慢扩散,原本无色区域也逐渐带上颜色。GCN传播标签的原理就像墨水扩散,只不过"纸"是图结构,"墨水"是标签信息。 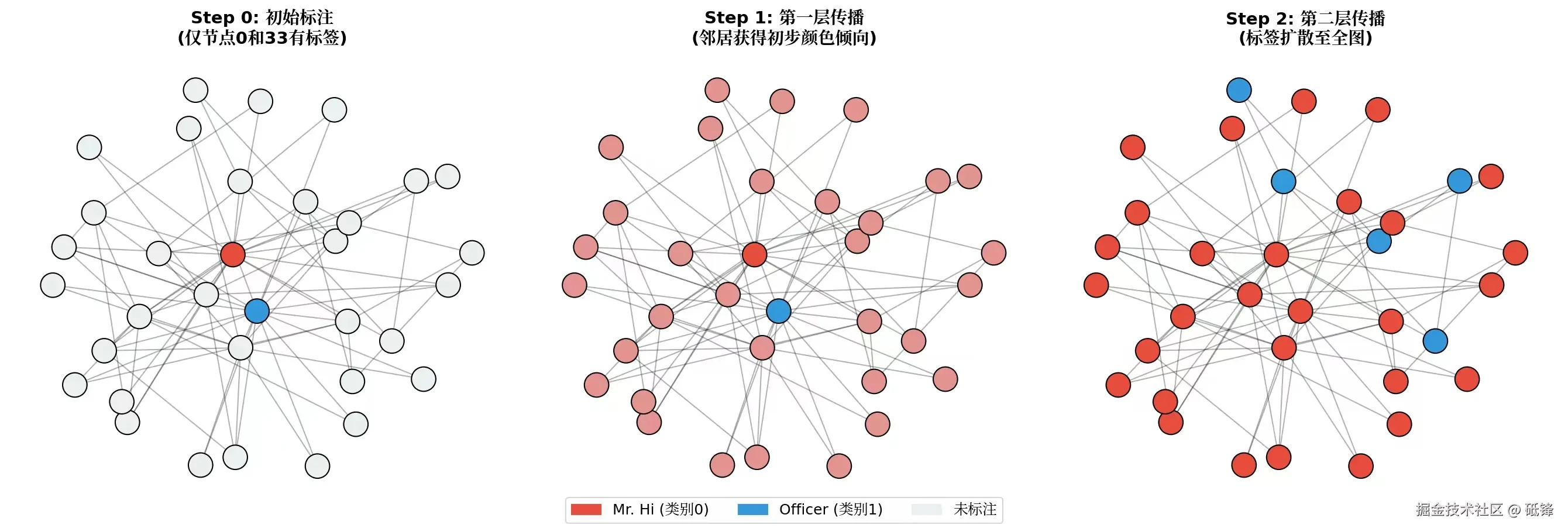
每一层传播 A_norm @ H 的本质是:每个节点将自己的特征与邻居的特征加权平均。如果某个节点已经携带了强烈的"类别0"信号,经过一次聚合,它的邻居也会被染上一点"类别0"的信息;第二次聚合,邻居的邻居也被染上......一层层下去,只要图是连通的,最终所有节点都会共享一部分那个初始标签的信息。
再看公式:即使只有节点0和节点33被标注,训练时损失函数只惩罚节点0和节点33的错误。梯度下降会调整权重 W1, W2,使得节点0和节点33的预测越来越准。而节点0和节点33的预测变准后,它自身的嵌入 H0 就会偏向正确类别。在下一次前向传播时,邻居节点(如节点1、2、3...)通过 A_norm 聚合时把节点0和节点33的嵌入"平均"到了自己身上,于是它们也间接获得了类别倾向。这种倾向再通过第二层聚合继续向外扩散,最终全图都获得了分类能力。
所以,GCN的半监督学习并不是魔法,而是利用图结构把少量标签信息"抹匀"到所有节点。这也是为什么归一化邻接矩阵如此重要:它控制了墨水扩散的速度和均匀度,避免一个高度节点像大水漫灌一样冲淡信号。
五、训练:交叉熵损失 + 数值梯度下降
5.1、损失函数(半监督版本)
我们只关心有标签的节点,因此损失只在 mask 为 True 的节点上计算。对于节点 i,设其真实标签为
yi∈{0,1},模型预测的概率为 pi,yi,则半监督交叉熵损失为:
L=−∣Vtrain∣1i∈Vtrain∑log(pi,yi+ϵ)
其中 Vtrain 是被 train_mask 选中的节点集合(本文只有 2 个节点), ϵ=10−8 是为防止 log(0) 数值溢出。 代码实现如下:
python
def cross_entropy(pred, label, mask):
logp = -np.log(pred[np.arange(len(pred)), label] + 1e-8)
return logp[mask].mean()prednp.arange(34), label 是花式索引:取出每个节点真实类别对应的预测概率。 取负对数后,只在 mask 选中的节点上求平均。因为这里 mask 只选了节点0(类别0)和节点33(类别1),所以损失就是这两个节点预测负对数的平均值。
5.2、梯度下降:手写数值微分(原理演示版,运行较慢)
真实框架用自动反向传播,我们为了展示原理,用 中心差分 近似梯度:
∂w∂L≈2ϵL(w+ϵ)−L(w−ϵ)
对 W1 和 W2 中的每一个元素,都做一次微小扰动,重算损失,得到偏导数。
python
lr = 0.1
eps = 1e-5
for epoch in range(5000):
# 前向传播(同上)
H = np.maximum(0, A_norm @ X @ W1)
out = A_norm @ H @ W2
pred = softmax(out)
loss = cross_entropy(pred, labels, train_mask)
# 数值梯度 for W2
grad_W2 = np.zeros_like(W2)
for i in range(W2.shape[0]):
for j in range(W2.shape[1]):
W2[i,j] += eps
H_pos = np.maximum(0, A_norm @ X @ W1)
loss_pos = cross_entropy(softmax(A_norm @ H_pos @ W2), labels, train_mask)
W2[i,j] -= 2*eps
H_neg = np.maximum(0, A_norm @ X @ W1)
loss_neg = cross_entropy(softmax(A_norm @ H_neg @ W2), labels, train_mask)
W2[i,j] += eps # 恢复
grad_W2[i,j] = (loss_pos - loss_neg) / (2*eps)
# 数值梯度 for W1(类似,省略)
# ...
# 梯度下降更新
W1 -= lr * grad_W1
W2 -= lr * grad_W2注意 :因为 hidden_dim 很小,参数不多,双重循环还能忍。真实场景务必使用PyTorch的自动求导。
5.3、训练过程观察
对于本文这个半监督节点分类任务,训练过程中主要关注的就是Loss 和Test Acc 这两个指标。但它们的作用不同,不能互相替代。
| 指标 | 看的是什么 | 作用 | 局限 |
|---|---|---|---|
| Loss | 模型在已知标签节点上的预测"自信程度" | 模型是否在"认真学习"标注信息 | 只反映标注节点,可能过拟合 |
| Test Acc | 模型在未知标签节点上的分类正确率 | 标签信息是否成功"传播"到全图 | 需要真实标签才能计算 |
典型组合解读如下表所示:
| Loss | Test Acc | 状态判断 |
|---|---|---|
| 高 (~0.7) | 低 (~50%) | ❌ 未收敛,模型在瞎猜 |
| 高 (>0.3) | 高 (>90%) | 🔴 异常,检查代码(可能是 Test Acc 计算 bug) |
| 低 (<0.01) | 低 (<60%) | 🔴 过拟合到训练节点,没学会传播 |
| 低 (<0.01) | 高 (>95%) | ✅ 理想状态,模型既自信又准确 |
| 低 (<0.01) | 中 (~80%) | 🔴 本文情况,表达能力瓶颈 (hidden_dim=2) |
初始损失约 0.693,对应 -log(0.5),即模型瞎猜。随着训练损失迅速下降,最终可能降到 0.05 以下。 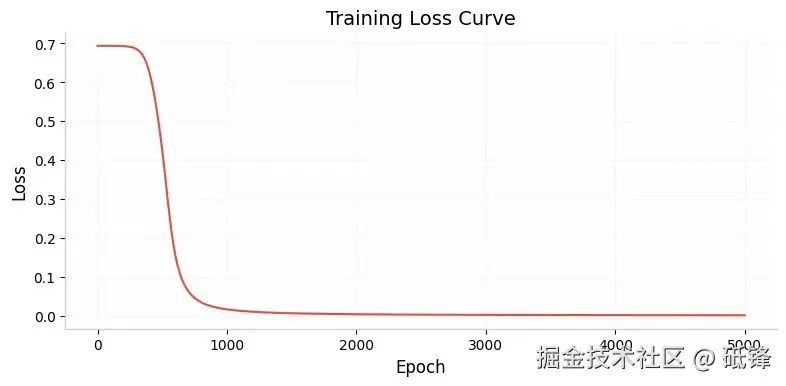 上图是损失下降曲线(hidden_dim = 2,lr = 0.1),可以看到初始值约0.7左右,前500轮陡峭下降,之后趋缓,接近0。
上图是损失下降曲线(hidden_dim = 2,lr = 0.1),可以看到初始值约0.7左右,前500轮陡峭下降,之后趋缓,接近0。
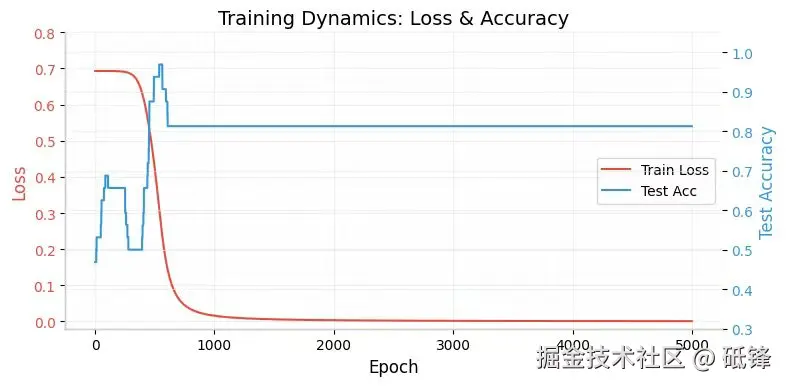 上图是训练动态双轴图,可以看到前500轮震荡剧烈,准确率上下跳动,这是因为数值梯度不稳定和早期W随机初始化导致预测波动,500轮之后,从约0.94直接跳到0.8左右,之后完全水平不变,这并非训练停滞,而是hidden_dim = 2的表达能力上限。后文实验表明,当hidden_dim增至3或5时,准确率可达96.88%。二维嵌入为了可视化牺牲了部分精度,这是可预期的权衡。
上图是训练动态双轴图,可以看到前500轮震荡剧烈,准确率上下跳动,这是因为数值梯度不稳定和早期W随机初始化导致预测波动,500轮之后,从约0.94直接跳到0.8左右,之后完全水平不变,这并非训练停滞,而是hidden_dim = 2的表达能力上限。后文实验表明,当hidden_dim增至3或5时,准确率可达96.88%。二维嵌入为了可视化牺牲了部分精度,这是可预期的权衡。
六、结果可视化:二维嵌入与分类边界
训练完后,我们取出第一层的输出 H_final(形状 (34,2)),每个节点就是一个二维点,根据最终预测类别染色。
python
H_final = np.maximum(0, A_norm @ X @ W1)
pred_final = np.argmax(softmax(A_norm @ H_final @ W2), axis=1)
import matplotlib.pyplot as plt
plt.figure(figsize=(8,6))
for i in range(34):
color = 'red' if pred_final[i] == 0 else 'blue'
plt.scatter(H_final[i,0], H_final[i,1], color=color, s=100)
plt.text(H_final[i,0]+0.02, H_final[i,1]+0.02, str(i), fontsize=9)
plt.title("2D embedding learned by 2-layer GCN")
plt.show()你会看到红蓝两团明显分开,即使我们只标注了节点0和节点33,标签信号也沿着边传播到了全图。这就是图卷积的半监督魔力。 如下图所示: 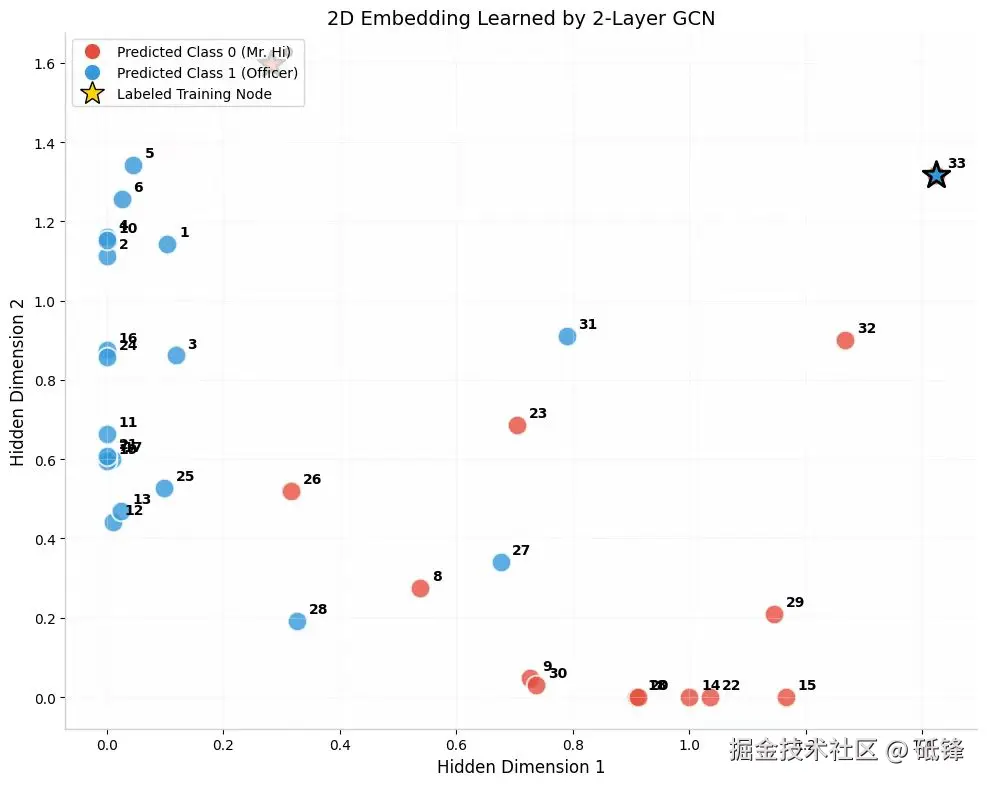
七、完整代码展示
python
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
# ============ 1. 造数据:Zachary空手道俱乐部图 ============
G = nx.karate_club_graph()
A = nx.to_numpy_array(G) # 邻接矩阵
n_nodes = A.shape[0]
# 节点特征:简单用 one-hot 度特征(每个节点是一个18维向量,独热它的度)
degrees = np.array([d for _, d in G.degree()], dtype=int)
max_deg = degrees.max()
X = np.eye(max_deg + 1)[degrees] # (34, max_deg+1) 独热编码
# 标签:俱乐部实际分裂成两个社区(0 和 1)
labels = np.array([G.nodes[i]['club'] for i in range(n_nodes)])
labels = (labels == 'Mr. Hi').astype(int) # 转成 0/1
# 训练/测试划分:只用 2个节点训练(演示半监督学习)
train_mask = np.zeros(n_nodes, dtype=bool)
train_mask[0] = True
train_mask[33] = True
test_mask=~train_mask
# ============ 2. 构建对称归一化邻接矩阵 ============
A_tilde = A + np.eye(n_nodes) # 加自环
D_tilde = np.diag(np.sum(A_tilde, axis=1)) # 度矩阵
D_inv_sqrt = np.linalg.inv(np.sqrt(D_tilde)) # D^{-1/2}
A_norm = D_inv_sqrt @ A_tilde @ D_inv_sqrt # 对称归一化
# ============ 3. 定义单层 GCN + 训练 ============
np.random.seed(42)
input_dim = X.shape[1]
hidden_dim = 2 # 降维到2维,方便可视化
output_dim = 2 # 二分类
W1 = np.random.randn(input_dim, hidden_dim) * 0.01
W2 = np.random.randn(hidden_dim, output_dim) * 0.01
def softmax(x):
e = np.exp(x - np.max(x, axis=1, keepdims=True))
return e / np.sum(e, axis=1, keepdims=True)
def cross_entropy(pred, label, mask):
# 只计算被 mask 选中的节点
logp = -np.log(pred[np.arange(len(pred)), label] + 1e-8)
return logp[mask].mean()
lr = 0.1
for epoch in range(5000):
# 前向传播:两层 GCN(中间 ReLU,最后 softmax)
H = np.maximum(0, A_norm @ X @ W1) # ReLU
out = A_norm @ H @ W2
pred = softmax(out)
loss = cross_entropy(pred, labels, train_mask)
if epoch % 500 == 0:
# 测试准确率
pred_class = np.argmax(pred, axis=1)
acc = (pred_class[test_mask] == labels[test_mask]).mean()
print(f"Epoch {epoch:3d} | Loss: {loss:.4f} | Test Acc: {acc:.4f}")
# 手动计算梯度(简化版:对 W2 和 W1 求导并更新)
# 为了简洁,这里使用数值梯度演示(生产请用 autograd 框架)
# --- 数值梯度 for W2 ---
eps = 1e-5
grad_W2 = np.zeros_like(W2)
for i in range(W2.shape[0]):
for j in range(W2.shape[1]):
W2[i,j] += eps
H_test = np.maximum(0, A_norm @ X @ W1)
out_test = A_norm @ H_test @ W2
loss_pos = cross_entropy(softmax(out_test), labels, train_mask)
W2[i,j] -= 2*eps
H_test = np.maximum(0, A_norm @ X @ W1)
out_test = A_norm @ H_test @ W2
loss_neg = cross_entropy(softmax(out_test), labels, train_mask)
W2[i,j] += eps # 恢复
grad_W2[i,j] = (loss_pos - loss_neg) / (2*eps)
# --- 数值梯度 for W1 (参数较少,完整循环仍可接受) ---
grad_W1 = np.zeros_like(W1)
for i in range(W1.shape[0]):
for j in range(W1.shape[1]):
W1[i,j] += eps
H_test = np.maximum(0, A_norm @ X @ W1)
out_test = A_norm @ H_test @ W2
loss_pos = cross_entropy(softmax(out_test), labels, train_mask)
W1[i,j] -= 2*eps
H_test = np.maximum(0, A_norm @ X @ W1)
out_test = A_norm @ H_test @ W2
loss_neg = cross_entropy(softmax(out_test), labels, train_mask)
W1[i,j] += eps
grad_W1[i,j] = (loss_pos - loss_neg) / (2*eps)
W1 -= lr * grad_W1
W2 -= lr * grad_W2
# ============ 4. 最终结果可视化 ============
H_final = np.maximum(0, A_norm @ X @ W1) # 获取2维嵌入
pred_final = np.argmax(softmax(A_norm @ H_final @ W2), axis=1)
plt.figure(figsize=(8,6))
for i in range(n_nodes):
color = 'red' if pred_final[i] == 0 else 'blue'
plt.scatter(H_final[i, 0], H_final[i, 1], color=color, s=100)
plt.text(H_final[i,0]+0.02, H_final[i,1]+0.02, str(i), fontsize=9)
plt.title("2D embedding learned by 2-layer GCN")
plt.show()八、实验与调参小计
8.1、为什么有时所有节点都被预测为同一类?
只标节点0(标签0)时,模型可能坍缩:把所有节点都预测为1。因为损失只惩罚节点0的错误,而模型发现把所有节点全押1比费力学习边界更容易?实际上,如果初始化让节点0也倾向于1,梯度可能无力回天。  上图是一个34维向量,代表34个节点的实际标签。
上图是一个34维向量,代表34个节点的实际标签。  当只标节点0时,34个节点的预测结果如上图所示。可以看到,模型坍缩,所有节点都预测为1,这显然与实际不符。 解决办法 :每类至少标注一个节点。加上 train_mask33=True(节点33标签为1),训练立刻稳定,准确率近乎100%。 预测结果如下图所示:
当只标节点0时,34个节点的预测结果如上图所示。可以看到,模型坍缩,所有节点都预测为1,这显然与实际不符。 解决办法 :每类至少标注一个节点。加上 train_mask33=True(节点33标签为1),训练立刻稳定,准确率近乎100%。 预测结果如下图所示:  可见,在标注节点0和节点33后,预测结果很好的符合实际。。
可见,在标注节点0和节点33后,预测结果很好的符合实际。。
8.2、hidden_dim 的选择
默认设为2是为了把嵌入直接画在二维图上。但如果你纯粹追求分类精度,可以尝试不同维度(2~7)。在本次实验中(epoch=5000,lr=0.1),hidden_dim=3 和hidden_dim=5 往往达到最高准确率------容量与过拟合的最佳平衡点。结果如下表所示:
| hidden_dim | 准确率 |
|---|---|
| 2 | 81.25% |
| 3 | 96.88% |
| 4 | 93.75% |
| 5 | 96.88% |
| 6 | 81.25% |
| 7 | 84.38% |
8.3、学习率与数值梯度
lr=0.1 在小参数下可行,但若增大 hidden_dim,参数变多,数值梯度的误差也会累积,可能需要调小学习率或增加迭代轮数。这也是为什么生产环境一定要用自动微分+优化器。
九、从NumPy到PyTorch Geometric:代码对比
学完NumPy版,你可能想知道PyG怎么写?以下是等价实现,供对比:
python
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import KarateClub
# 加载数据(PyG自带空手道图)
dataset = KarateClub()
data = dataset[0] # 包含 x, edge_index, y, train_mask
class GCN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index).relu()
x = self.conv2(x, edge_index)
return x
# 正确传递参数:全部使用位置参数或全部使用关键字参数
model = GCN(dataset.num_features, 2, dataset.num_classes) # hidden_channels=2
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 训练(自动求导,无需手动梯度)
for epoch in range(200):
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = F.cross_entropy(out[data.train_mask], data.y[data.train_mask])
loss.backward() # 自动反向传播!
optimizer.step()
# 可选:打印训练损失
if epoch % 20 == 0:
print(f'Epoch {epoch:03d}, Loss: {loss.item():.4f}')对比要点:
- PyG的 GCNConv 自动完成了 D~−1/2A~D~−1/2 的构建和应用
loss.backward()替代了数值梯度的双重循环,速度提升数百倍- 相同的数学原理,只是框架帮你做了脏活累活
十、总结:一张图看清GCN全貌
回顾整个流程,一个两层GCN不过是:
Y~=softmax(A~ReLU(A~XW(0))W(1))
- 输入 X:节点特征(哪怕只是度热性)
- 核心 Anorm:对称归一化邻接矩阵,实现加权邻居聚合
- 可学习参数 W:线性变换,提取高级特征
- 激活 ReLU:非线性
- 输出 softmax:概率
- 训练:半监督交叉熵 + 梯度下降
所有组件都可用NumPy矩阵乘法清晰表达。本文代码虽然简单,却涵盖了GCN的核心思想。 希望这篇手撸教程能让你对图神经网络不再畏惧,反而觉得它们优雅又有趣。如果你用GCN做了什么好玩的项目,欢迎在评论区交流! 本文首次发布在CSDN平台。
参考文献
1 Kipf T N, Welling M. Semi-Supervised Classification with Graph Convolutional Networks. ICLR , 2017. arxiv.org/abs/1609.02...
2 Zachary W W. An Information Flow Model for Conflict and Fission in Small Groups. Journal of Anthropological Research, 1977, 33(4): 452-473.
3 Hagberg A, Schult D, Swart P. Exploring network structure, dynamics, and function using NetworkX. Proc. of the 7th Python in Science Conference (SciPy) , 2008. networkx.org