随着大语言模型技术的飞速发展,检索增强生成(RAG)已经从实验室走向企业级应用的核心舞台。无论是医疗诊断中的精准建议、金融服务里的合规回复,还是客服场景下的高效应答,RAG技术都在悄悄改变我们的工作方式。它就像一个"开卷考试"系统,检索器负责从海量知识库中找"参考资料",生成器则根据这些资料写出最终答案。但很多人不知道的是,一个RAG系统的好坏,不仅取决于技术架构,更取决于一套科学、全面的评估体系。没有合理的评估,再复杂的RAG系统也可能只是"碰运气",甚至在关键场景中出现致命错误。
今天,我们就来全面拆解RAG评估体系,从基础概念、核心指标到框架工具、行业实践,用最通俗的语言讲清楚每一个关键点,无论是技术开发者、产品经理,还是刚接触RAG的学生、行业从业者,都能从中找到自己需要的知识,真正把RAG评估用起来、用到位。
一、先搞懂:为什么RAG评估如此重要?
在聊评估体系之前,我们先弄明白一个核心问题:为什么一定要做RAG评估?很多人觉得,只要搭建好检索器和生成器,RAG系统就能正常工作,评估只是"锦上添花"。但实际上,评估是RAG系统的"生命线",尤其是在关键行业场景中,其重要性甚至超过技术本身。
RAG系统的本质是一个流水线作业,检索器和生成器环环相扣,而错误在这个流水线中是"乘法关系"而非"加法关系"。举个简单的例子,如果检索器的准确率是80%,生成器的准确率也是80%,那么整个系统端到端的理论准确率只有64%,这就是行业里常说的"级联失败"。也就是说,只要其中一个环节出问题,整个系统的性能就会大幅下降。
更关键的是,传统的"人工抽查+问答准确率"评估方式,早已无法满足复杂场景的需求。比如在医疗场景中,遗漏一个关键的病症信息可能导致误诊;在金融场景中,一个错误的政策解读可能引发合规风险;在法律咨询中,虚构一条法律条款可能造成严重的法律纠纷。这些场景都要求RAG系统的每一个环节都足够可靠,而这种可靠性,只能通过科学的评估体系来保障。
业界有句名言:"没有可观测性,你的系统只是在碰运气。"而RAG评估,就是实现系统可观测性的核心手段。它能帮我们找到系统的薄弱环节,比如检索器是不是找错了资料,生成器是不是在"瞎编"答案,进而有针对性地优化,让系统从"碰运气"变成"稳输出"。
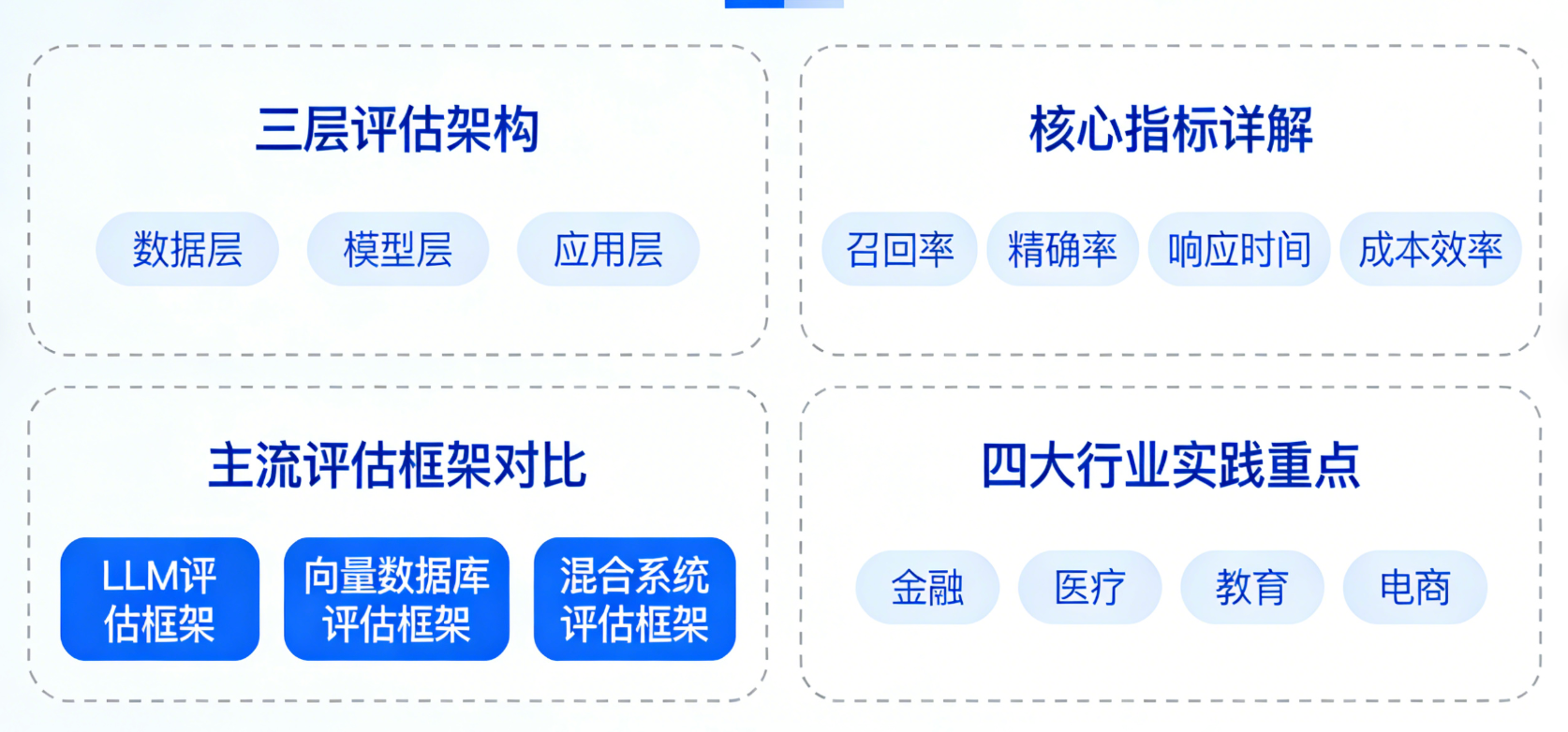
二、RAG评估体系的核心逻辑:从"两层"到"三层"的全面覆盖
很多新手刚接触RAG评估时,会觉得指标繁多、杂乱无章,其实只要抓住核心逻辑,就会变得很简单。RAG评估体系的核心,是围绕"检索+生成"两个核心环节展开的,在此基础上,延伸出"系统层"的综合评估,形成了"检索层+生成层+系统层"的三层评估架构。
我们可以用一个生活化的例子来理解这三层架构:假设你是一个学生,要完成一篇课程论文。检索层评估,就相当于检查你找的参考资料是不是准确、全面;生成层评估,相当于检查你写的论文是不是基于这些资料,有没有跑题、有没有编造内容;系统层评估,就是检查这篇论文的整体质量、是否符合要求,以及老师对你的满意度。
2.1 检索层评估:找对资料,是做好RAG的第一步
检索层是RAG系统的"地基",如果检索器找错了资料、漏掉了关键信息,哪怕生成器再强大,也无法输出正确的答案。检索层的评估,核心就是判断"检索器能不能准确找到相关文档,并正确排序",主要有四个核心指标,我们一个个讲清楚。
第一个指标是上下文召回率,它衡量的是检索到的资料,是否覆盖了回答问题所需的所有关键信息。简单来说,就是"该找的资料有没有都找到"。比如,回答"糖尿病的治疗方案",需要5个关键信息,检索到的资料只覆盖了4个,那么上下文召回率就是80%。
这个指标的重要性不言而喻,尤其是在对信息完整性要求高的场景。比如医疗场景,召回率必须达到85%以上,因为遗漏任何一个关键的治疗信息,都可能给患者带来风险;而客服场景对召回率的要求相对宽松,75%左右即可,但对另一个指标------上下文精确度,要求会更高。
第二个指标是上下文精确度,它衡量的是检索到的资料中,真正和问题相关的比例。也就是说,"找的资料有没有废话"。比如,查询"糖尿病治疗方案",系统返回了10篇文档,其中只有6篇是真正讨论治疗的,其余4篇讲的是饮食和并发症,那么上下文精确度就是60%。
精确度直接影响生成质量,无关的资料就像"噪声",会干扰生成器的判断,甚至导致生成错误答案。有一个金融行业的案例很有代表性:某企业将合同条款按"责任条款""赔偿条款"精细分块后,检索的精确度从52%提升到89%,生成的合同解读准确率也随之大幅提升。
第三个指标是平均倒数排名(MRR),这个指标主要关注"正确的资料排在第几名"。比如,用户查询一个问题,检索器返回了10篇文档,其中第3篇是正确的,那么这一次查询的倒数排名就是1/3;如果第1篇就是正确的,倒数排名就是1。MRR就是所有查询的倒数排名的平均值,取值范围在0到1之间,数值越高,说明正确资料的平均位置越靠前,用户体验也越好。
除了这三个核心指标,还有一些常用的检索指标,比如NDCG,它考虑了检索结果的排序权重,排在前面的资料权重大,后面的权重逐渐衰减,适合评估多相关文档的场景;还有Top-K准确率,分为Precision@k和Recall@k,用于评估在不同检索数量下的系统性能,比如检索前3篇、前5篇资料的准确率和召回率。
2.2 生成层评估:说好话,是RAG系统的核心能力
如果说检索层是"找对资料",那么生成层就是"用好资料"。生成层的评估,核心是判断"生成器能不能基于检索到的资料,生成正确、相关、流畅的答案",其中最关键的指标,就是答案忠实度。
答案忠实度是生成质量的"生死线",它衡量的是生成的答案是否严格基于检索到的上下文,有没有产生"知识幻觉"------也就是编造不存在的信息。计算公式很简单:答案忠实度=上下文能够推断出的事实数量/答案拆解出的事实总数量。比如,生成的答案有5个事实陈述,其中3个能在检索资料中找到依据,2个是编造的,那么忠实度就是60%,幻觉率就是40%。
很多RAG系统的失败,都源于忠实度不足。有一个法律行业的惨痛案例:某法律RAG系统在86%的案例中虚构法律条款细节,因为没有设置忠实度监控,导致后续出现大量纠纷,后来通过优化,忠实度提升到98%,才解决了这个问题。这也提醒我们,无论什么场景,忠实度都是必须重点监控的指标。
第二个核心指标是答案相关性,它衡量的是生成的答案是否紧扣问题本质,有没有答非所问。比如,用户问"糖尿病的治疗方案",生成的答案却一直在讲糖尿病的病因,这就是相关性不足。评估相关性有一个很巧妙的方法,叫做"逆向提问":用生成的答案反推可能的问题,然后计算反推问题与原问题的语义相似度,相似度越高,说明答案越切题。
除了忠实度和相关性,生成层还有两个重要指标:答案完整性和流畅性。答案完整性衡量的是生成的答案是否覆盖了用户需求的所有要点,比如用户问"糖尿病的治疗方案有哪些",答案只说了药物治疗,没说饮食治疗和运动治疗,就是完整性不足;流畅性则衡量生成文本的语言质量,比如语法是否正确、逻辑是否连贯,这直接影响用户的阅读体验。
2.3 系统层评估:看整体,检验RAG的实际价值
检索层和生成层的评估,关注的是系统的"局部性能",而系统层评估,关注的是RAG系统的"整体表现"和"业务价值"。它不局限于某个环节,而是从端到端的角度,判断系统是否能满足实际业务需求,主要包括四个核心指标。
第一个是噪声鲁棒性,考验的是系统的抗干扰能力。实际应用中,知识库中难免会混入一些无关内容,比如医疗知识库中混入菜谱、金融知识库中混入营销材料,噪声鲁棒性就是测试系统在这种情况下,能否保持回答稳定。有一个银行的案例:某银行的RAG系统因为噪声鲁棒性不足,在混入营销材料后给出了错误的利率建议,造成了严重的业务损失,这也说明,噪声鲁棒性是企业级RAG系统必须重视的指标。
第二个是负样本拒绝率,相当于系统的"安全阀"。对于一些无法回答的问题,比如"火星的人口有多少",优质的RAG系统应该坦然说"不知道",而不是编造答案。负样本拒绝率就是评估系统对这类问题的处理能力,达标线通常要求超过90%,这也是提升用户信任度的关键------当系统能够诚实告知"我不知道"时,反而能建立更好的用户关系。
第三个是上下文利用率,衡量的是系统对检索到的资料的使用效率。比如,检索器返回了8篇相关文档,但生成器只引用了2篇,说明存在"检索过载",很多有用的资料没有被利用起来。上下文利用率的理想值应该超过70%,如果过低,就需要优化检索策略,或者引入重排序(Re-Ranker),筛选出最有价值的资料。
第四个是端到端延迟,直接影响用户体验。延迟分为三个部分:检索延迟,受向量库规模影响,百万级数据的检索延迟应该控制在800ms以内;生成延迟,与模型参数量相关,7B模型的生成延迟宜控制在1.5s以内;总延迟如果超过2.5秒,就会显著降低用户体验,尤其是在客服、实时咨询等场景。
这里需要特别提醒的是,各个指标之间不是孤立的,而是相互关联的。比如,低精确率+低忠实度,通常说明检索模块有缺陷,找了太多无关资料,导致生成器出现幻觉;高召回率+低相关性,说明检索器找对了资料,但生成器的指令不当,没有紧扣问题;高精确率+低利用率,说明检索到的资料质量很高,但生成器没有充分利用。理解这种关联性,能帮我们快速定位系统问题,高效优化。
三、RAG评估的"工具包":主流框架与工具怎么选?
搞懂了评估指标,接下来就是实际操作------用什么工具来做评估?随着RAG技术的发展,业界已经出现了很多成熟的评估框架和工具,不用我们从零开始搭建,只需根据自己的需求选择合适的工具,就能高效完成评估。
我们先对比一下目前主流的四个评估框架,看看它们的优势、劣势和适用场景,方便大家快速选择。
3.1 四大主流评估框架对比:各有侧重,按需选择
第一个框架是RAGAS,堪称RAG评估的"行业老大哥",由IBM Research开源,核心标签是"无参考评估"------不需要人工标注大量的黄金标准答案,仅上下文召回率需要少量参考数据,极大降低了评估门槛。它的优势很明显,首创了RAG的四大核心指标,生态也非常好,能无缝对接LangChain、LlamaIndex等常用的RAG开发框架,还内置了数据集生成功能,适合快速验证RAG系统的核心功能。不过它也有缺点,内部写死了很多Prompt,修改起来不太灵活,大规模评测的速度也比较慢。总体来说,RAGAS是RAG专项评估的首选,尤其适合开发初期使用。
第二个框架是DeepEval,主打"全家桶+工程化",语法和PyTest很像,对CI/CD极其友好。它的优势是提供了Confident AI可视化面板,不仅能评估RAG的核心指标,还能测试大语言模型的偏见、毒性等全方位指标,适合研发团队搭建自动化的生产回归测试。缺点是概念稍微庞杂,有一定的学习曲线,需要花时间熟悉它的用法。
第三个框架是TruLens,核心理念是"监控+评估",主打可观测性驱动。它的最大优势是能清晰看到LangChain内部每一个组件的耗时和得分,比如检索器的耗时、生成器的忠实度得分,非常适合生产环境的实时监控和Debug。不过它的缺点也很明显,需要深入嵌入业务代码,侵入性较强,对技术开发能力有一定要求。
第四个框架是Giskard,主打"安全与漏洞扫描",核心是红蓝对抗(Red Teaming)。它不仅能评估常规指标,还能自动生成Prompt注入攻击,测试系统的鲁棒性,适合金融、政务等对安全合规要求极高的系统。不过它在RAG专项的细粒度指标上,不如RAGAS丰富,更适合做安全层面的补充评估。
3.2 常用评估工具详解:从入门到进阶
除了上述四个主流框架,还有一些常用的评估工具,适合不同的场景和需求,我们重点介绍几个最实用的。
首先是微软Azure RAG评估器,微软官方推出的评估工具,分为系统评估和过程评估两大类,特点是提供了丰富的复合指标,特别适合企业级应用。系统评估器包括Groundedness(忠实度)、Relevance(相关性)、Response Completeness(响应完整性)等,其中Groundedness Pro还能使用Azure AI内容安全服务进行严格的忠实度检测;过程评估器主要评估文档检索的质量,包括Fidelity、NDCG等多个复合指标,适合对评估精度要求高的企业。
其次是LangSmith,一个综合性的LLM应用评估平台,特别适合企业流水线集成。它的功能非常全面,支持自定义评估器,比如合规性检查;能进行版本对比,AB测试不同模型的性能;还能遮蔽敏感数据,避免信息泄露。另外,它的Trace可视化功能非常优秀,能看到每一步的检索结果和Prompt,方便排查Bad Case,适合企业级RAG系统的全面评估。
还有一个工具是DeepEval,我们前面提到过它的框架,这里重点说它的自动化测试功能。它专为CI/CD设计,可以设置自动化质量关卡,比如将忠实度的阈值设为0.92,答案相关性的阈值设为0.85,当评估指标未达标时,系统会自动阻断部署,确保生产环境的质量,非常适合研发团队的自动化测试流程。
3.3 工具选择策略:按场景、按技术栈、按需求
很多人面对这么多工具,会不知道该选哪一个。其实很简单,我们可以从三个维度来选择,确保工具能贴合自己的需求。
按开发阶段选择:开发初期,用RAGAS快速验证核心功能,降低评估门槛;集成测试阶段,用DeepEval进行自动化质量把关,确保代码合并和部署的质量;生产监控阶段,用TruLens进行实时可观测性监控,及时发现问题;安全测试阶段,用Giskard进行红蓝对抗测试,保障系统安全。
按技术栈选择:如果项目是基于LangChain开发的,优先选择RAGAS,能无缝集成;如果是企业级部署,选择微软Azure评估器,能获得企业级的技术支持;如果需要自定义评估逻辑,选择LangSmith,灵活性更高。
按业务需求选择:对安全性要求极高的场景,比如金融、政务,选择Giskard;需要实时监控的场景,选择TruLens;需要自动化测试的场景,选择DeepEval;需要全面评估RAG核心指标的场景,选择RAGAS。
四、行业实践:不同领域的RAG评估怎么做?
理论和工具都讲完了,接下来就是最关键的实践环节。不同行业的业务需求不同,RAG评估的重点也不一样,我们结合医疗、金融、客服、制造四个核心行业的案例,看看实际场景中,RAG评估是怎么落地的,有哪些最佳实践可以借鉴。
4.1 医疗行业:以"精准"为核心,守住安全底线
医疗行业是RAG技术应用最成功的领域之一,也是对评估要求最严格的领域,因为每一个错误的回答,都可能影响患者的生命健康。医疗行业的RAG评估,核心是"高召回率+高忠实度",确保不遗漏关键医疗信息,不编造医疗建议。
IBM Watson Health的案例很有代表性,该系统构建了包含3亿节点的医疗知识图谱,将症状、药品、基因突变等信息整合起来,通过系统性的评估和优化,将误诊率从12%降至3.5%,诊断时间缩短60%。它的评估体系重点关注上下文召回率,将其阈值设定在85%以上,确保所有关键的医疗信息都能被检索到;同时严格监控忠实度,确保生成的诊断建议都能在知识库中找到依据。
国内某三甲医院的实践也很值得借鉴,该医院引入RAG技术打造医疗助手,可学习上亿病例,通过建立完善的评估体系,诊断准确率提升20%,医生工作效率提高30%,患者咨询响应时间从平均15分钟缩短至30秒。它的评估体系不仅包括核心指标,还引入了临床专家评审机制,将AI评估与专家判断相结合,确保评估结果的准确性。
医疗行业的评估最佳实践总结下来有三点:一是建立严格的召回率标准,确保不遗漏关键信息;二是实施多层次评估体系,从单一指标升级到多维度综合评估;三是建立持续监控体系,定期评估系统性能,及时纠正偏差。
4.2 金融行业:以"合规"为前提,兼顾效率与准确
金融行业对准确性和合规性的要求极高,RAG评估不仅要关注系统的性能指标,还要重点关注合规性,确保所有回答都符合监管要求。金融行业的评估重点是"高精确率+合规性",避免无关信息干扰,同时确保回答符合监管政策。
某大型国有银行的智能投顾系统,整合了2000+金融产品说明书、500+监管政策文件,通过建立完善的评估体系,实现了显著的效果:金融产品咨询的人工客服压力降低40%,回答准确率达92%,合规投诉率下降35%。它的评估体系重点监控上下文精确度,将其阈值设定在90%以上,确保检索到的资料都是与金融产品、监管政策相关的,避免无关信息导致的合规风险;同时建立了合规性评估模块,确保生成的回答符合监管要求。
在合同处理领域,某法律咨询系统通过RAG架构,建立了细粒度的评估指标体系,将合同条款解析准确率从78%提升至96%,响应时间缩短至传统人工审核的1/20。它的评估重点是上下文精确度和答案完整性,确保合同条款的每一个细节都能被准确检索和解读,不遗漏任何关键条款。
金融行业的评估特色的是:一是强调合规性评估,确保回答符合监管要求;二是优先保证精确率,减少无关信息的干扰;三是重视实时性,交易相关查询需要毫秒级响应;四是要求可追溯性,每一个回答都必须有明确的依据,便于审计。
4.3 客服行业:以"体验"为目标,平衡效率与质量
客服行业是RAG技术应用最广泛的领域,其评估体系的核心是"效率+质量",既要提升客服响应速度,也要保证回答的准确性和相关性,最终提升客户满意度。
某电商平台的实践很有参考价值,该平台通过建立包括响应时间、准确率、满意度等多维度的评估体系,AI客服机器人能够自动引用最新促销政策与退换货条款,投诉率下降25%。它的评估重点是端到端延迟和答案相关性,将总延迟控制在20秒以内,确保客户能快速获得响应;同时监控答案相关性,避免答非所问,提升客户体验。
行业基准数据显示,RAG技术在客服领域的效果非常显著:实施RAG前,平均响应时间为5-8分钟,客户满意度为72%;实施后,平均响应时间缩短至10-15秒,客户满意度提升至88%,改善幅度达22%。这背后,正是完善的评估体系在发挥作用------通过监控响应时间、答案相关性、忠实度等指标,持续优化系统性能。
客服行业的评估要点包括:一是24/7可用性评估,确保系统全天候稳定运行;二是多语言支持评估,验证不同语言的处理能力;三是情感分析集成,评估回答的情感适宜性,避免生硬的回复;四是个性化评估,验证针对不同客户群体的定制能力。
4.4 制造业:以"实用"为导向,聚焦知识传承与智能维护
制造业的RAG应用,主要集中在知识传承和智能维护两个场景,评估体系的核心是"多模态处理+实时性",确保系统能处理CAD图纸、现场笔记等多模态数据,同时快速响应生产需求。
某汽车工厂的案例很有代表性,该工厂通过RAG系统建立了完善的故障诊断评估体系,能够提前48小时预测故障,准确率达91%。它的评估体系重点关注预测准确性和实时性,将检索延迟控制在毫秒级,确保故障信息能快速被检索和分析;同时评估维护建议的质量,确保生成的维护建议具有可操作性。
在知识传承方面,面对熟练工人退休、知识流失的问题,某制造企业通过在RAG数据库中存入故障对策、开发事例等信息,建立了知识传承评估体系,使非熟练员工也能快速获取必要的信息,有效降低了技术传承的难度。它的评估重点是上下文召回率和答案完整性,确保所有关键的技术知识都能被检索到,并且生成的指导信息完整、易懂。
制造业评估的特殊需求包括:一是多模态数据处理能力,能处理图像、CAD图纸等非文本数据;二是实时性要求,生产环境需要毫秒级响应;三是安全性评估,确保生成的维护建议不会产生安全隐患;四是可维护性评估,确保系统长期稳定运行。
五、不同人群的RAG评估指南:按需学习,快速上手
不同人群的需求不同,学习和使用RAG评估的重点也不一样。我们针对技术开发者、产品经理、学生、其他行业从业者四个群体,分别给出针对性的指南,帮助大家快速找到自己的学习重点和实践方向。
5.1 技术开发者:聚焦技术实现,打造可靠系统
对于技术开发者来说,核心需求是理解RAG评估的技术原理,掌握评估指标的实现方法,并用工具搭建自动化评估流程,确保系统的可靠性。
首先,要理解RAG的级联失败机制,明白检索层和生成层的错误会相互放大,因此评估时要兼顾两个环节,不能只关注其中一个。其次,要掌握核心指标的技术实现,比如用Python计算召回率、MRR等指标,下面给大家一个可直接复用的Python代码示例,用NumPy加速计算:
python
import numpy as np
from typing import List
# 模拟数据:retrieved_lists是RAG检索回来的文档ID
retrieved = [
['doc_2', 'doc_3', 'doc_4', 'doc_5'], # Query 1检索结果
['doc_9', 'doc_8', 'doc_7', 'doc_6', 'doc_5'] # Query 2检索结果
]
relevant = [
['doc_1', 'doc_3'], # Query 1真正相关的文档
['doc_10'] # Query 2真正相关的文档(不幸没搜到)
]
def eval_recall_at_k(retrieved_lists: List[List[str]], relevant_lists: List[List[str]], k: int = 3) -> float:
"""计算Recall@k"""
scores = []
for ret, rel in zip(retrieved_lists, relevant_lists):
if not rel:
continue # 无相关文档,跳过
ret_k = ret[:k] # 截取前K个检索结果
intersect = len(set(ret_k) & set(rel))
scores.append(intersect / len(rel))
return np.mean(scores)
def eval_mrr(retrieved_lists: List[List[str]], relevant_lists: List[List[str]]) -> float:
"""计算MRR(Mean Reciprocal Rank)"""
rr = []
for ret, rel in zip(retrieved_lists, relevant_lists):
rel_set = set(rel)
found = False
for rank, doc in enumerate(ret, start=1):
if doc in rel_set:
rr.append(1.0 / rank)
found = True
break
if not found:
rr.append(0.0)
return np.mean(rr)
k_val = 3
print(f"🔥 Recall@{k_val}: {eval_recall_at_k(retrieved, relevant, k_val):.4f}")
print(f"🔥 MRR: {eval_mrr(retrieved, relevant):.4f}")另外,要熟练使用RAGAS等开源框架进行实战,比如用RAGAS评估自己搭建的RAG系统,根据评估结果优化分块策略、检索算法等。同时,要建立CI/CD质量门禁,每次代码或模型合并前,自动化跑一遍评估,分数下降则阻止合并,确保生产环境的质量。
技术开发者的优化建议:不要过度追求召回率,关注精确率,减少送到生成器的"垃圾"信息,才是减少幻觉的根本;语义分块优于固定长度分块,能更好地捕捉上下文连续性;融合关键词检索(BM25)与语义检索,覆盖不同术语体系,提升检索质量。
5.2 产品经理:聚焦商业价值,制定合理策略
对于产品经理来说,核心需求是理解RAG评估的商业价值,通过评估体系量化RAG项目的ROI,制定合理的产品策略,推动项目落地和优化。
首先,要量化RAG技术的商业价值。RAG带来的价值是可量化的,比如客户服务效率提升300%,响应时间从4小时缩短至30秒;知识管理效率提升80%,员工获取信息的速度大幅提升;培训成本降低75%,新员工能快速掌握业务知识。这些数据,都可以通过评估体系来验证。
其次,要建立ROI分析框架,判断RAG项目的投资回报。简单的ROI计算公式是:年度收益=(减少的人工成本+提升的用户满意度带来的增收)-年度成本,简单ROI=年度收益/投资成本。举个例子,某企业原本需要100个客服,部署RAG后只需要20个,节省80个客服的年薪(假设24万/年),即1920万,若投资成本为250万,那么简单ROI就非常高。根据麦肯锡的报告,RAG项目相比训练专属模型可节省95%的开发成本,大部分企业可在3-6个月内实现正向ROI。
产品经理的产品策略建议:采用分阶段实施策略,先选择1-2个核心业务场景试点,建立基础评估体系,再逐步扩展到更多场景;打造差异化竞争优势,通过优秀的评估体系确保产品质量领先,提供定制化的评估和优化服务;建立风险控制机制,设置质量门控,未达标自动阻断部署,实施AB测试,对比不同方案效果。
5.3 学生群体:聚焦基础学习,通过实践提升能力
对于学生群体来说,核心需求是理解RAG评估的基础概念,掌握基本的实践方法,通过项目实战加深理解,为未来的职业发展打下基础。
首先,要搞懂基础概念,用通俗易懂的语言理解核心指标。比如,上下文召回率就是"图书管理员有没有把所有需要的资料都找到",上下文精确度就是"找的资料有没有废话",忠实度就是"学霸有没有根据资料回答,还是自己编答案"。理解了这些基础概念,再学习复杂的指标和工具就会轻松很多。
其次,要制定合理的学习路径:第一阶段,用1-2周时间学习RAG的基本原理和四大核心指标,掌握向量检索和语义相似度计算的基础;第二阶段,用2-3周时间安装配置RAGAS环境,完成官方教程,用RAGAS评估简单的RAG系统;第三阶段,用3-4周时间做项目实战,比如构建小型问答系统,用RAGAS评估并优化;第四阶段,用2-3周时间学习其他评估框架,了解LLM-as-Judge的原理,探索自定义评估指标的方法。
推荐几个适合学生的实践项目:简易问答系统评估,用SQuAD等公开数据集构建问答系统,用RAGAS评估性能;领域知识问答系统,选择自己感兴趣的领域,构建知识库,实现RAG系统并评估;多语言RAG评估,对比不同语言的RAG性能,分析语言特性对评估指标的影响。
5.4 其他行业从业者:聚焦应用价值,掌握实施要点
对于非技术背景的行业从业者来说,核心需求是理解RAG评估的应用价值,掌握实施要点,推动RAG技术在本行业的落地,发挥其商业价值。
首先,要明确RAG评估的应用价值:提升决策质量,通过准确的信息检索和可靠的答案生成,为决策提供支持;降低运营成本,自动化处理大量重复性工作,减少人工错误;提升客户满意度,提供快速、准确、全天候的服务;保护知识资产,保存和传承企业知识,防止关键人员流失造成的知识损失。
其次,要掌握实施要点:选择合适的评估时机,在项目启动阶段建立评估基准线,开发过程中定期评估,上线前全面评估,运营阶段持续监控;建立跨部门协作机制,业务部门提供需求和评估标准,技术部门实施技术方案,质量部门制定质量标准,培训部门确保员工理解使用;设定合理的期望,明白RAG不是万能的,评估指标需要根据业务特点调整;关注数据安全和合规,确保评估数据安全,遵守行业合规要求。
另外,不同行业的成功经验可以相互借鉴,比如制造业的预防性维护机制、金融行业的合规审查机制、互联网行业的快速迭代模式,都可以用到自己的行业中,提升RAG评估的效果。
六、总结与展望:RAG评估,是优化的起点而非终点
通过以上的全面解析,我们不难发现,RAG评估体系不是一个简单的"指标集合",而是一套贯穿RAG系统全生命周期的"优化工具"。它从检索层、生成层、系统层三个维度,全面衡量系统的性能和价值,帮助我们找到问题、解决问题,让RAG系统从"不稳定"走向"可靠",从"能使用"走向"好用"。
从技术发展趋势来看,RAG评估正经历从传统IR指标到LLM-as-Judge的重大转变。以前的评估方法,比如BLEU、ROUGE,只能判断字面重合度,无法识别语义相同但词汇不同的表达;而LLM-as-Judge范式,用强大的大语言模型作为"评审员",能够理解语义、识别逻辑关系、判断事实准确性,极大提升了评估的准确性和可靠性。未来,随着AI技术的进步,RAG评估将更加智能、高效、易用,评估工具也将更加完善,形成开放、共享、标准化的评估生态。
最后,我们要强调的是,RAG评估不是终点,而是持续优化的起点。无论是技术开发者、产品经理,还是学生、行业从业者,都需要认识到,评估不是一次性的工作,而是贯穿RAG系统开发、部署、运营全流程的持续过程。只有建立了完善的评估体系,才能实现RAG系统的持续改进和不断进化,才能真正发挥RAG技术的价值,为企业和行业创造更多价值。