一:楔子
在流处理的应用中,最佳的数据源当然就是可重置偏移量的消息队列了;它不仅可以提供数据重放的功能,而且天生就是以流的方式存储和处理数据的。所以作为大数据工具中消息队列的代表,Kafka可以说与Flink是天作之合,实际项目中也经常会看到以Kafka作为数据源和写入的外部系统的应用。在本小节中,我们就来具体讨论一下Flink和Kafka连接时,怎样保证端到端的exactly-once状态一致性。
二:Flink写入到Kafka的两阶段提交
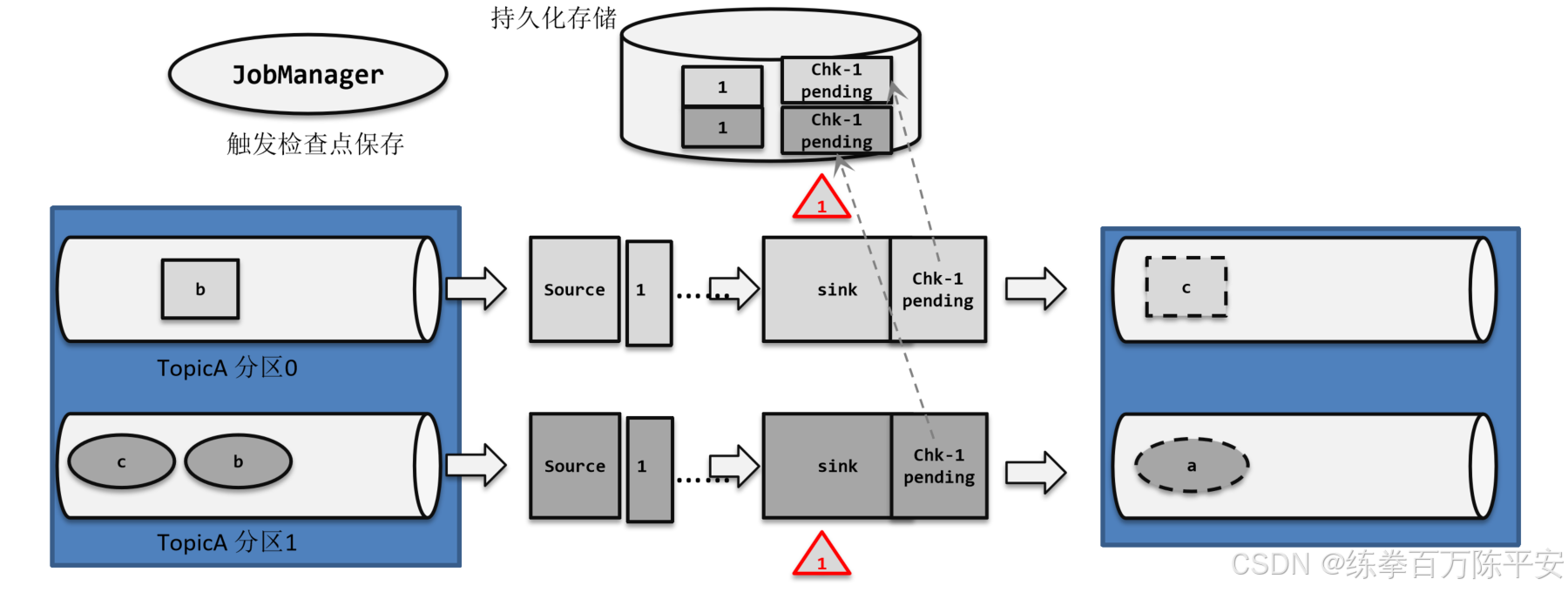
①JobManager 发送指令,触发检查点的保存:所有 Source 节点插入一个 id=1 的 barrier,触发 source 节点将偏移量保存到远程的持久化存储中
②sink 节点接收到 Flink 启动后的第一条数据,负责开启 Kafka 的第一次事务,预提交开始。同时会将事务的状态保存到状态里
③预提交阶段:到达 sink 的数据会调用 kafka producer 的 send (),数据写入缓冲区,再 flush ()。此时数据写到 kafka 中,标记为 "未提交" 状态如果任意一个 sink 节点预提交过程中出现失败,整个预提交会放弃
④id=1 的 barrier 到达 sink 节点,触发 barrier 节点的本地状态保存到 hdfs,本地状态包含自身的状态和事务快照。同时,开启一个新的 Kafka 事务,用于该 barrier 后面数据的预提交,如:分区 0 的 b,分区 1 的 b、c。只有第一个事务由第一条数据开启,后面都是由 barrier 开启事务
⑤全部节点做完本地 checkpoint,jobmanager 向所有节点发送一个本轮成功的回调消息,预提交结束。
⑥sink 收到 checkpoint 完成的通知,进行事务正式提交,将写入 kafka 数据的标记修改成 "已提交",如果发生故障,回滚到上次成功完成快照的时间点
三:将流中数据写入到Kafka生产者代码
在 Sink 端,要想保证写入到 kafka 的一致性,需要做如下操作:
- 开启检查点
- 设置一致性级别为精准一次
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)- 设置事务 id 的前缀
.setTransactionalIdPrefix("flink01_kafka_sink_")- 设置事务的超时时间
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,15*60*1000 + "")检查点超时时间 <事务的超时时间 <= 事务最大超时时间 (默认 15min)- 在消费端,设置消费数据的隔离级别为读已提交
package com.dashu.day10;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.producer.ProducerConfig;
// 在Sink端,想要保证写入到kafka的一致性,需要做如下操
// 在 Sink 端,要想保证写入到 kafka 的一致性,需要做如下操作:
//开启检查点
//设置一致性级别为精准一次
//.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
//设置事务 id 的前缀
//.setTransactionalIdPrefix("flink01_kafka_sink_")
//设置事务的超时时间
//.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,15*60*1000 + "")
//检查点超时时间 <事务的超时时间 <= 事务最大超时时间 (默认 15min)
//在消费端,设置消费数据的隔离级别为读已提交
public class Flink01_kafka_sink {
public static void main(String[] args) throws Exception {
//1: 构建环境,设置并行度。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000L);
//2: 从指定网口读取数据
DataStreamSource<String> socketDS = env.socketTextStream("bigdata137", 8888);
//3: 将数据写入到kafka主题
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("bigdata137:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema.builder()
.setTopic("first")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)//根据这个属性判断要不要开启事务
.setTransactionalIdPrefix("flink01_kafka_sink")
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,15*60*1000 + "")
.build();
socketDS.sinkTo(kafkaSink);
//4: 提交作业
env.execute();
}
}四:两阶段提交到kafka案例演示
public class Flink02_kafka_sink {
public static void main(String[] args) throws Exception {
//1.1 指定流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.2 设置并行度
env.setParallelism(1);
//TODO 2. 从kafka主题中读取数据
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("bigdata137:9092")
.setTopics("first")
.setGroupId("test")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
.setProperty(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed")
.build();
DataStreamSource<String> kafkaStrDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka_source");
//TODO 3. 打印输出
kafkaStrDS.print();
//TODO 4. 提交作业
env.execute();
}
}1:启动zookeeper和kafka
用自己的脚本命令即可
2:nc监听8888端口
3:查看消费者和控制台消费者的消费情况
代码中消费的时候,10秒钟消费一次,控制台什么时候有消息,什么时候消费。