文章目录
- 1、机器学习定义
- 2、监督学习
-
- [2.1 线性回归模型](#2.1 线性回归模型)
- [2.2 逻辑回归模型](#2.2 逻辑回归模型)
- [2.3 Softmax回归模型](#2.3 Softmax回归模型)
- [2.4 一些概念](#2.4 一些概念)
-
- [2.4.1 过拟合和欠拟合](#2.4.1 过拟合和欠拟合)
- [2.4.2 正则化](#2.4.2 正则化)
- [2.4.3 特征处理](#2.4.3 特征处理)
- [2.4.4 模型评估](#2.4.4 模型评估)
- [2.4.5 高偏差和高方差](#2.4.5 高偏差和高方差)
- [2.4.6 学习曲线](#2.4.6 学习曲线)
- [2.4.7 Adam算法](#2.4.7 Adam算法)
- [2.8 迁移学习](#2.8 迁移学习)
- [2.9 精确率、召回率和F1系数](#2.9 精确率、召回率和F1系数)
- [2.5 神经网络](#2.5 神经网络)
- [2.6 决策树](#2.6 决策树)
- [2.7 一些流程](#2.7 一些流程)
- 3、无监督学习
-
- [3.1 K-means聚类算法](#3.1 K-means聚类算法)
- [3.2 异常事件检测](#3.2 异常事件检测)
- [3.3 基于评分的推荐系统](#3.3 基于评分的推荐系统)
- [3.4 基于内容的推荐系统](#3.4 基于内容的推荐系统)
- [3.5 PCA算法](#3.5 PCA算法)
- 4、强化学习
1、机器学习定义
简单来说是根据输入的内容通过模型输出结果
2、监督学习
监督学习: 具有特征x和标签y,然后进行拟合
2.1 线性回归模型
一般用于线性拟合
利用以下线性函数拟合
f w , b ( x ( i ) ) = w x ( i ) + b f_{w,b}(x^{(i)})=wx^{(i)}+b fw,b(x(i))=wx(i)+b
代价函数(cost function)
y ^ ( i ) = f w , b ( x ( i ) ) J ( w , b ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 \widehat{y}^{(i)}=f_{w,b}(x^{(i)})\\ J(w,b)=\frac{1}{2m}\sum^m_{i=1}(\widehat{y}^{(i)}-y^{(i)})^2 y (i)=fw,b(x(i))J(w,b)=2m1i=1∑m(y (i)−y(i))2
学习目标: 找到使得代价函数最小的参数值w和b
方法: 梯度下降,重复以下公式过程,其中 α \alpha α是 学习率 , 值越大下降越快,值越小下降越慢
{ w = w − α ∂ ∂ w J ( w , b ) b = b − α ∂ ∂ b J ( w , b ) \begin{cases} w=w-\alpha \frac{\partial}{\partial w}J(w,b) \\ b=b-\alpha \frac{\partial}{\partial b}J(w,b) \end{cases} {w=w−α∂w∂J(w,b)b=b−α∂b∂J(w,b)
多维特征公式
f w → , b ( x → ) = w → ⋅ x → + b f_{\overrightarrow{w},b}(\overrightarrow{x})=\overrightarrow{w}·\overrightarrow{x}+b fw ,b(x )=w ⋅x +b
判断梯度下降是否收敛,一般是取 ϵ \epsilon ϵ值,当代价函数的下降率小于某个值我们认为已经收敛
2.2 逻辑回归模型
一般用于进行二元分类
一般使用以下 s i g m o d sigmod sigmod函数
g ( z ) = 1 1 + e − z 0 < g ( z ) < 1 z = f w , b ( x ) g(z)=\frac{1}{1+e^{-z}} \quad 0 <g(z) <1\\ z =f_{w,b}(x) g(z)=1+e−z10<g(z)<1z=fw,b(x)
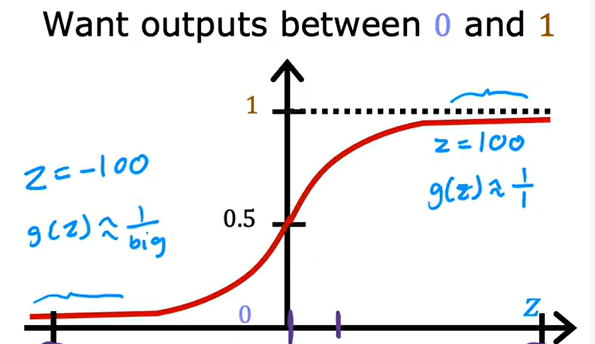
拟合完成后一般会形成一个决策边界,将数据空间分为两部分
其代价函数由新定义的损失函数 组成
L ( f w → , b ( x → ( i ) ) , y ( i ) ) = − y ( i ) l o g ( f w → , b ( x → ( i ) ) ) − ( 1 − y ( i ) ) l o g ( 1 − l o g ( f w → , b ( x → ( i ) ) ) J ( w → , b ) = 1 m ∑ i = 1 m L ( f w → , b ( x → ( i ) ) , y ( i ) ) L(f_{\overrightarrow{w},b}(\overrightarrow{x}^{(i)}),y^{(i)})=-y^{(i)}log(f_{\overrightarrow{w},b}(\overrightarrow{x}^{(i)}))-(1-y^{(i)})log(1-log(f_{\overrightarrow{w},b}(\overrightarrow{x}^{(i)}))\\ J({\overrightarrow{w},b})=\frac{1}{m}\sum^m_{i=1}L(f_{\\overrightarrow{w},b}(\\overrightarrow{x}\^{(i)}),y\^{(i)}) L(fw ,b(x (i)),y(i))=−y(i)log(fw ,b(x (i)))−(1−y(i))log(1−log(fw ,b(x (i)))J(w ,b)=m1i=1∑mL(fw ,b(x (i)),y(i))
2.3 Softmax回归模型
用于多分类问题
z j = w → j ⋅ x → + b j j = 1 , . . . , N a j = e z j ∑ k = 1 N e z k = P ( y = j ∣ x → ) z_j=\overrightarrow{w}j·\overrightarrow{x}+b_j \quad j=1,...,N\\ a_j=\frac{e^{z_j}}{\sum{k=1}^Ne^{z_k}}=P(y=j|\overrightarrow{x}) zj=w j⋅x +bjj=1,...,Naj=∑k=1Nezkezj=P(y=j∣x )
损失函数
l o s s ( a 1 , . . . , a N , y ) = { − log a 1 i f y = 1 − log a 2 i f y = 2 . . . − log a N i f y = N loss(a_1,...,a_N,y)=\begin{cases} -\log a_1 \quad if \quad y=1\\ -\log a_2 \quad if \quad y=2\\ ...\\ -\log a_N \quad if \quad y=N\\ \end{cases} loss(a1,...,aN,y)=⎩ ⎨ ⎧−loga1ify=1−loga2ify=2...−logaNify=N
2.4 一些概念
2.4.1 过拟合和欠拟合
过拟合: 是模型过于收敛于训练集数据,具有高方差
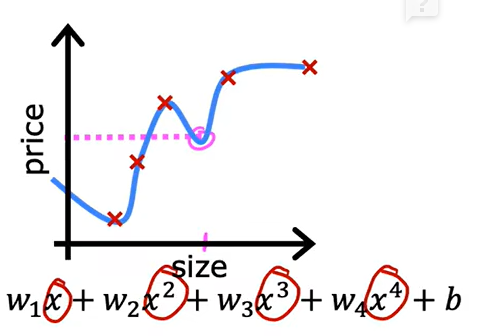
欠拟合: 模型不太收敛于训练集数据,具有高偏差
解决过拟合方法:
- 收集更多数据进行训练
- 挑选合适特征
- 正则化
2.4.2 正则化
通过减小各个特征的系数来减少特征的影响,使得函数不易过拟合
线性回归正则化
J ( w → , b ) = 1 2 m ∑ i = 1 m ( f w → , b ( x → ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J({\overrightarrow{w},b})= \frac{1}{2m}\sum^m_{i=1}(f_{\overrightarrow{w},b}(\overrightarrow{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum^n_{j=1}w_j^2 J(w ,b)=2m1i=1∑m(fw ,b(x (i))−y(i))2+2mλj=1∑nwj2
逻辑回归正则化
J ( w → , b ) = − 1 m ∑ i = 1 m ( y ( i ) l o g ( f w → , b ( x → ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − f w → , b ( x → ( i ) ) ) + λ 2 m ∑ j = 1 n w j 2 J ( w → , b ) = 1 m ∑ i = 1 m L ( f w → , b ( x → ( i ) ) , y ( i ) ) ) 2 + λ 2 m ∑ j = 1 n w j 2 J({\overrightarrow{w},b})= -\frac{1}{m}\sum^m_{i=1}(y\^{(i)}log(f_{\\overrightarrow{w},b}(\\overrightarrow{x}\^{(i)}))+(1-y\^{(i)})log(1-f_{\\overrightarrow{w},b}(\\overrightarrow{x}\^{(i)}))+\frac{\lambda}{2m}\sum^n_{j=1}w_j^2\\ J({\overrightarrow{w},b})=\frac{1}{m}\sum^m_{i=1}L(f_{\\overrightarrow{w},b}(\\overrightarrow{x}\^{(i)}),y\^{(i)}))^2+\frac{\lambda}{2m}\sum^n_{j=1}w_j^2 J(w ,b)=−m1i=1∑m(y(i)log(fw ,b(x (i)))+(1−y(i))log(1−fw ,b(x (i)))+2mλj=1∑nwj2J(w ,b)=m1i=1∑mL(fw ,b(x (i)),y(i)))2+2mλj=1∑nwj2
2.4.3 特征处理
特征工程:对已有特征进行加工形成更加复杂的特征,比如 x 1 2 , x 1 x 2 x_1^2,x_1x_2 x12,x1x2等,然后形成多项式回归
特征缩放: 为了保证特征数据的聚集,便于计算,通常会对数据进行缩放,方法如下
- 均值归一化
- Z分数归一化
2.4.4 模型评估
训练集 训练数据,交叉验证集 进行在多个模型参数之中的参数选择,测试集验证模型效果
2.4.5 高偏差和高方差
一般模型不收敛就是高偏差,模型过拟合就是高方差
函数最高次方对模型影响
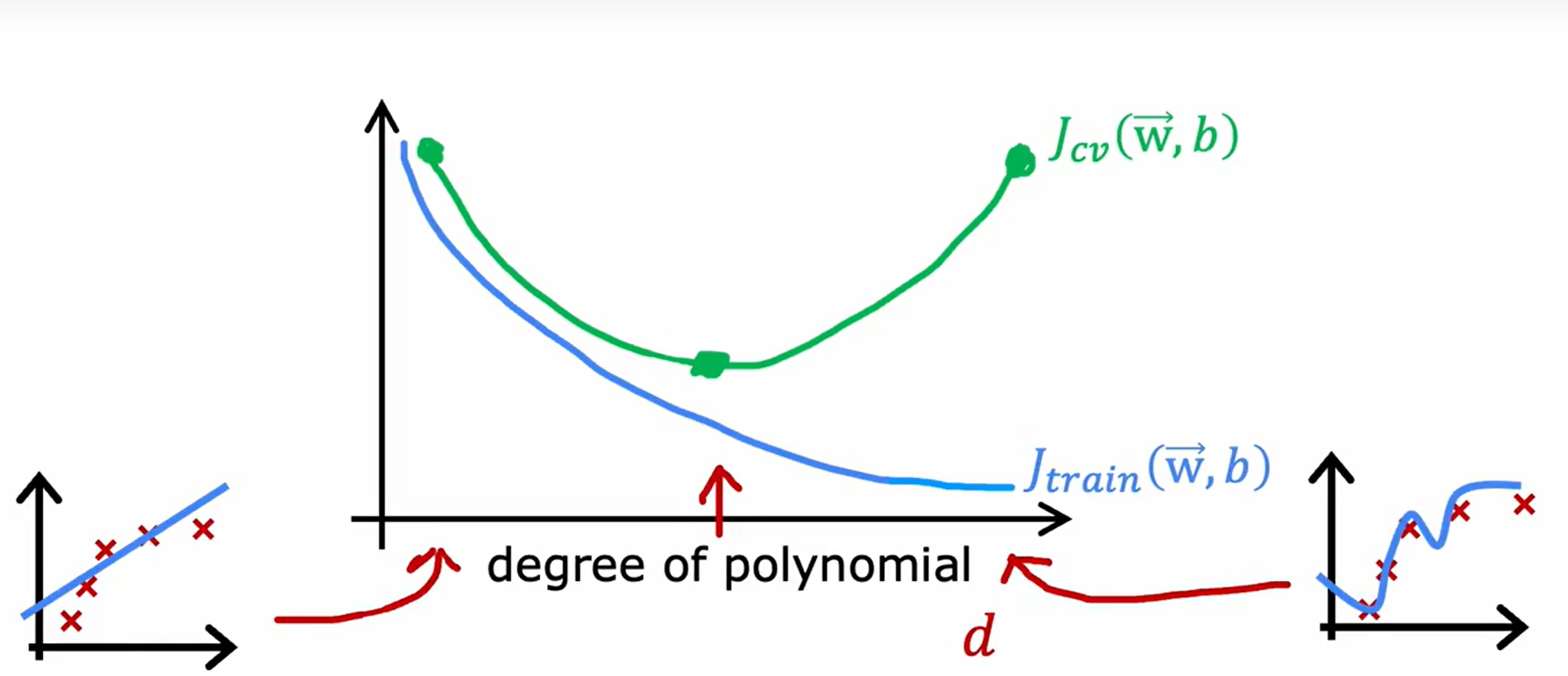
正则化对模型的影响
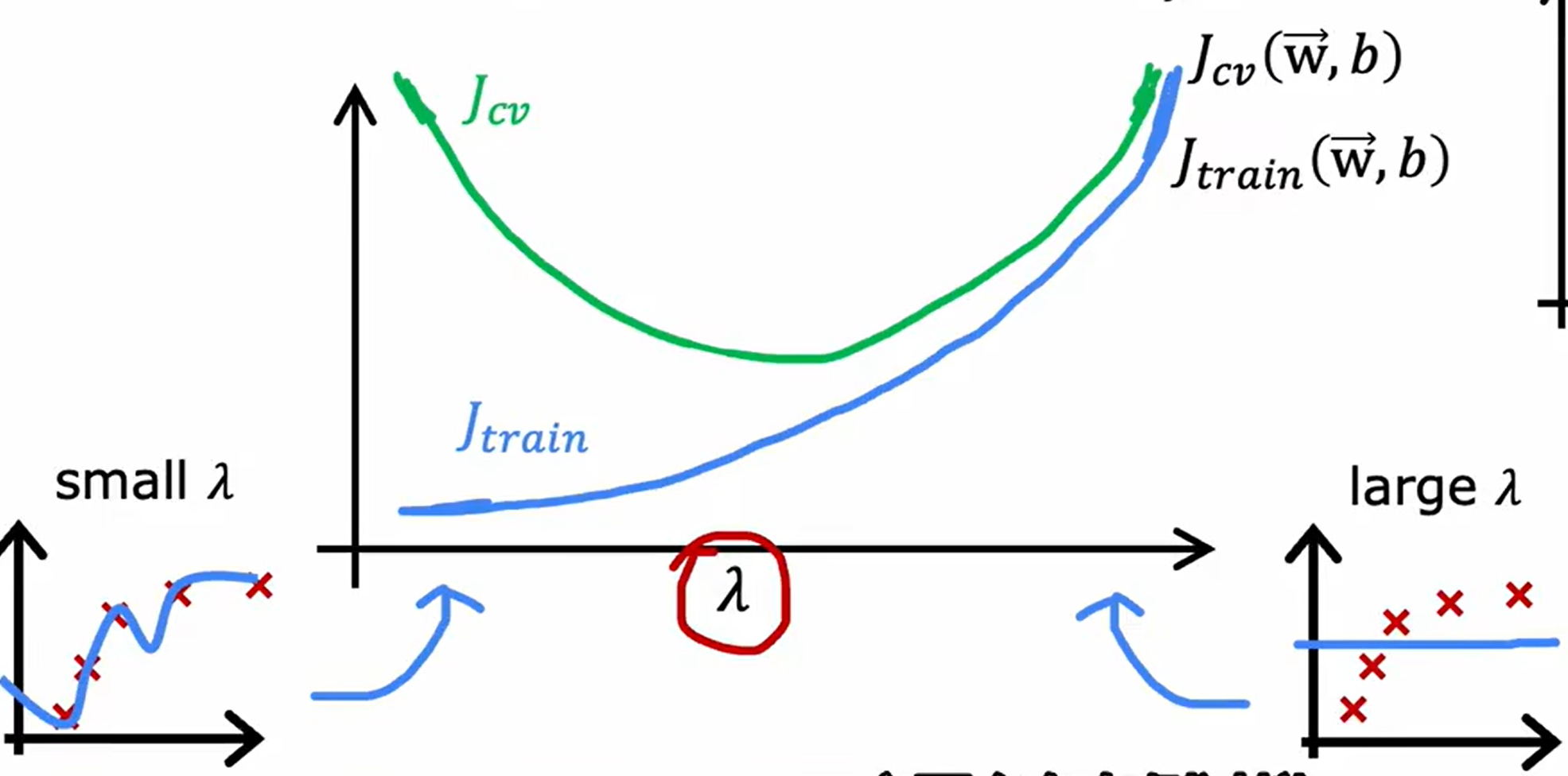
一般来说如果训练后的代价函数值很高于基准值则出现高偏差
交叉验证后的的代价函数值很高于训练后的代价函数值则出现高方差
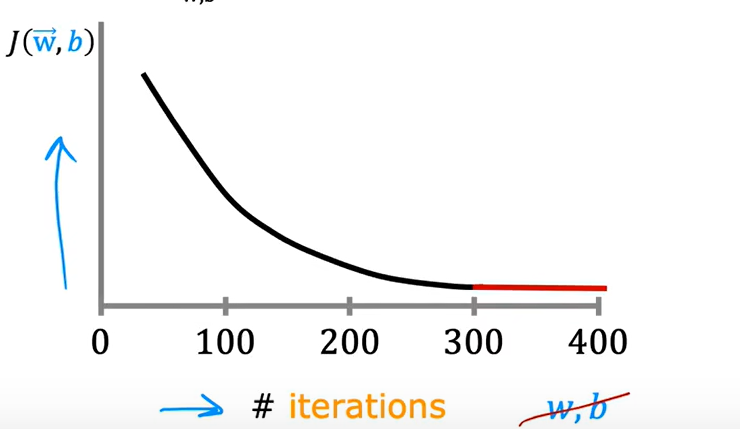
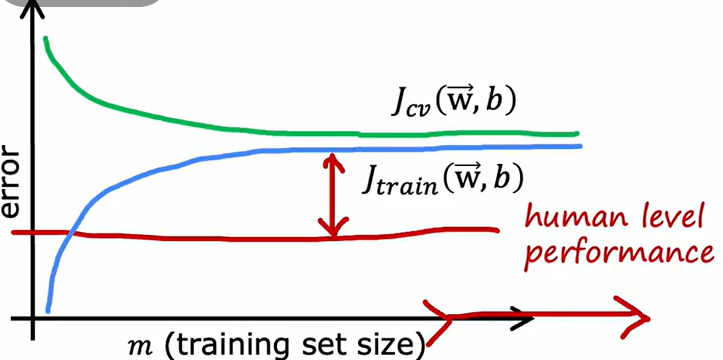
2.4.6 学习曲线
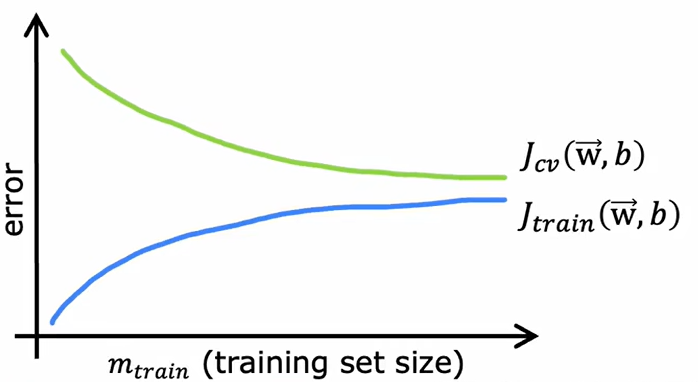
对应的高偏差和高方差情况
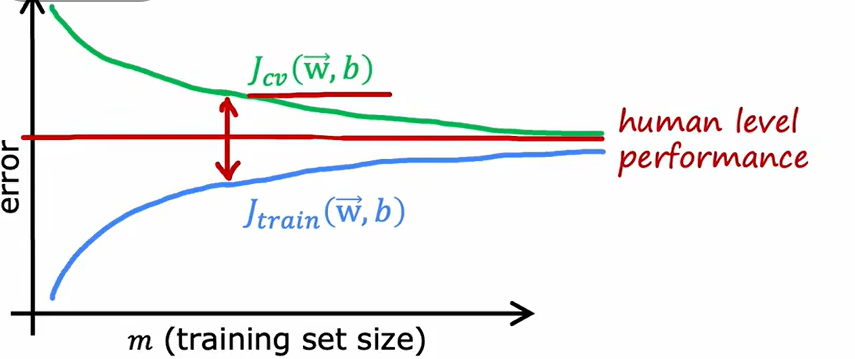
2.4.7 Adam算法
实现梯度下降,但在梯度下降过程中会控制学习率的大小
2.8 迁移学习
例如图像分类问题,如果目标数据集很少,可以先使用其他数据集对神经网络进行预训练,训练出参数后替换输出层,用目标数据集只训练输出层参数或者训练整个网络的参数。
加快训练速度
2.9 精确率、召回率和F1系数
精确率是预测的准确度,召回率是模型能在患者人群里能识别出疾病的准确度
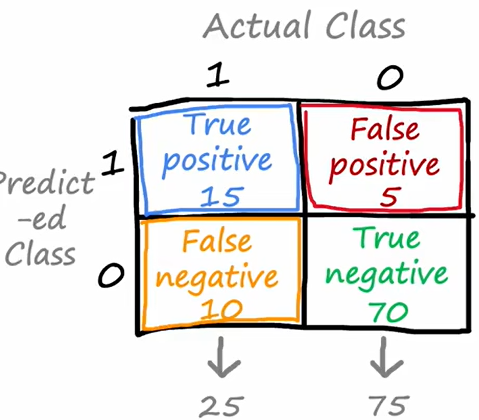
p e r c i s i o n = T r u e p o s i t i v e s T r u e p o s i t i v e s + F a l s e p o s i t i v e s r e c a l l = T r u e p o s i t i v e s T r u e p o s i t i v e s + F a l s e n e g a t i v e s percision = \frac{True \ positives}{True \ positives+False \ positives}\\ recall = \frac{True \ positives}{True \ positives+False \ negatives}\\ percision=True positives+False positivesTrue positivesrecall=True positives+False negativesTrue positives
F1系数用于总结精确率和召回率的优良程度
F 1 = 1 1 2 ( 1 P + 1 R ) F1=\frac{1}{\frac{1}{2}(\frac{1}{P}+\frac{1}{R})} F1=21(P1+R1)1
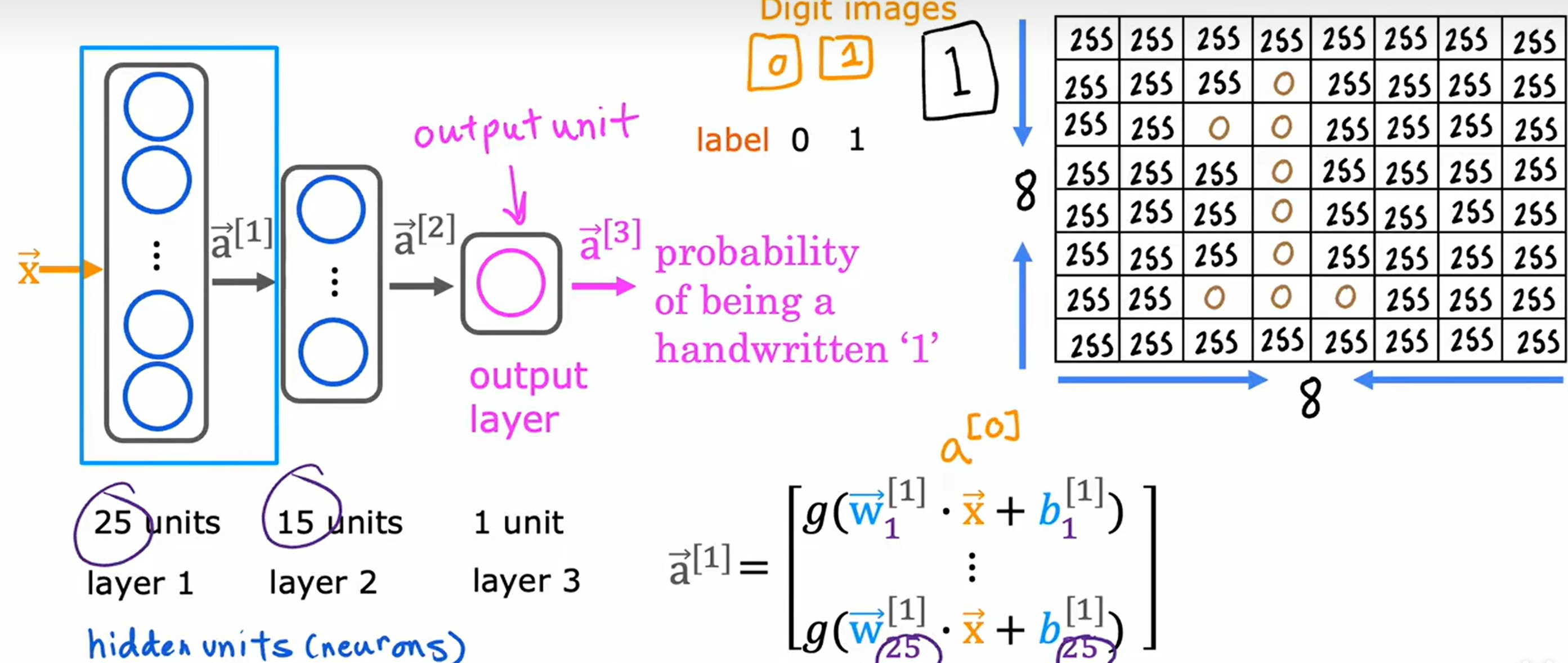
2.5 神经网络
基于以上两种模型的神经元构成的神经网络,具有输入层,隐藏层和输出层。
一般使用 s i g m o d sigmod sigmod函数 作为激活函数 ,除此之外还有 R e L U ReLU ReLU函数 和 线性函数 , S o f t m a x Softmax Softmax函数
-
s i g m o d sigmod sigmod函数用于二元分类
-
R e L U ReLU ReLU函数用于y值均不小于0的情况
-
线性函数用于y值有正有负的情况
-
S o f t m a x Softmax Softmax函数用于多分类
2.6 决策树
进行分类或者回归
数据纯度
H ( p 1 ) = − p 1 log 2 ( p 1 ) − ( 1 − p 1 ) log 2 ( 1 − p 1 ) H(p_1)=-p_1\log_2(p_1)-(1-p_1)\log_2(1-p_1) H(p1)=−p1log2(p1)−(1−p1)log2(1−p1)
这里认为 0 log 0 = 0 0\log 0=0 0log0=0
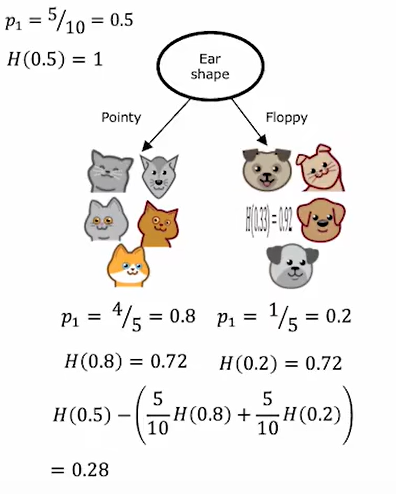
得到的值越高说明纯度越高
独热编码: 使用二进制标记三个以上的分类,保证实现决策树的二分类性
回归树 也是同理,不过使用的是方差值
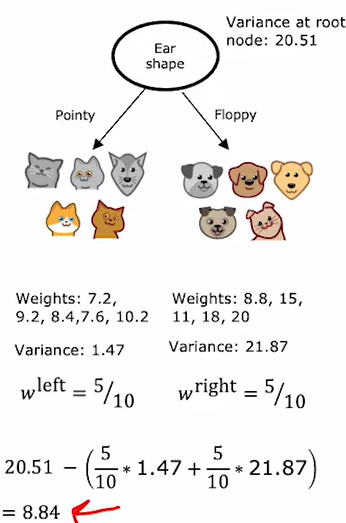
决策森林: 构建决策树集,对每种分类都构建一棵树,然后一同进行决策,通过投票得出最终结果
随机森林: 通过 有放回抽样 每次获得不同的数据集构建一棵树,最终构建成一个随机森林
XGBoost算法: 使用该算法构建随机森林,每次构建完一棵树后会利用这棵树进行决策,决策结果出错的会更容易被放到下一个用于构建树的数据集里
2.7 一些流程
神经网络训练流程
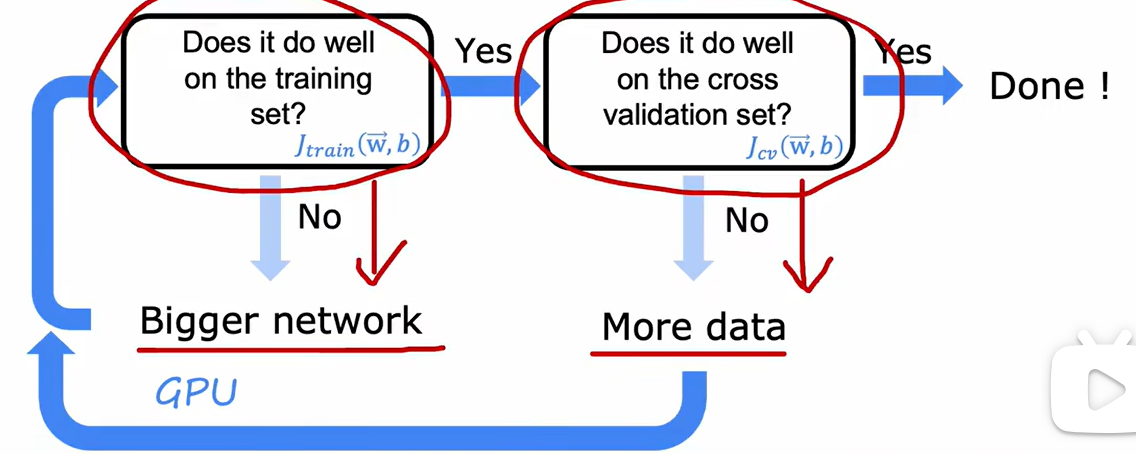
机器学习训练流程
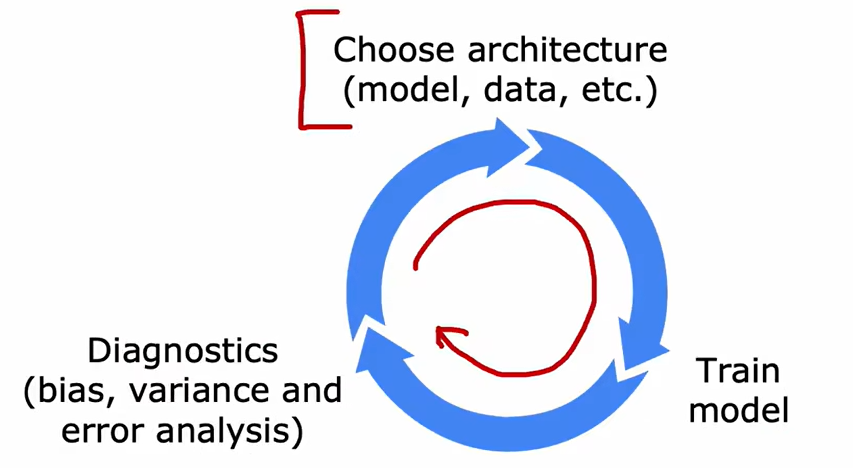
3、无监督学习
无监督学习: 只有特征数据x,让模型自己寻找特征之间的联系,然后进行拟合
3.1 K-means聚类算法
根据特征分布分出一定数量类
代价函数
J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ k ) = 1 m ∑ i = 1 m ∣ ∣ x ( i ) − μ c ( i ) ∣ ∣ 2 J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_k)=\frac{1}{m}\sum^m_{i=1}||x^{(i)}-\mu_{c^{(i)}}||^2 J(c(1),...,c(m),μ1,...,μk)=m1i=1∑m∣∣x(i)−μc(i)∣∣2
c ( i ) c^{(i)} c(i):对应 x x x所属的分类
μ k \mu_k μk:对应中心点
μ c ( i ) \mu_{c^{(i)}} μc(i): x x x对应的分类
一般对中心的初始化都是随机的,随机多次取代价函数最小的
聚类数量曲线
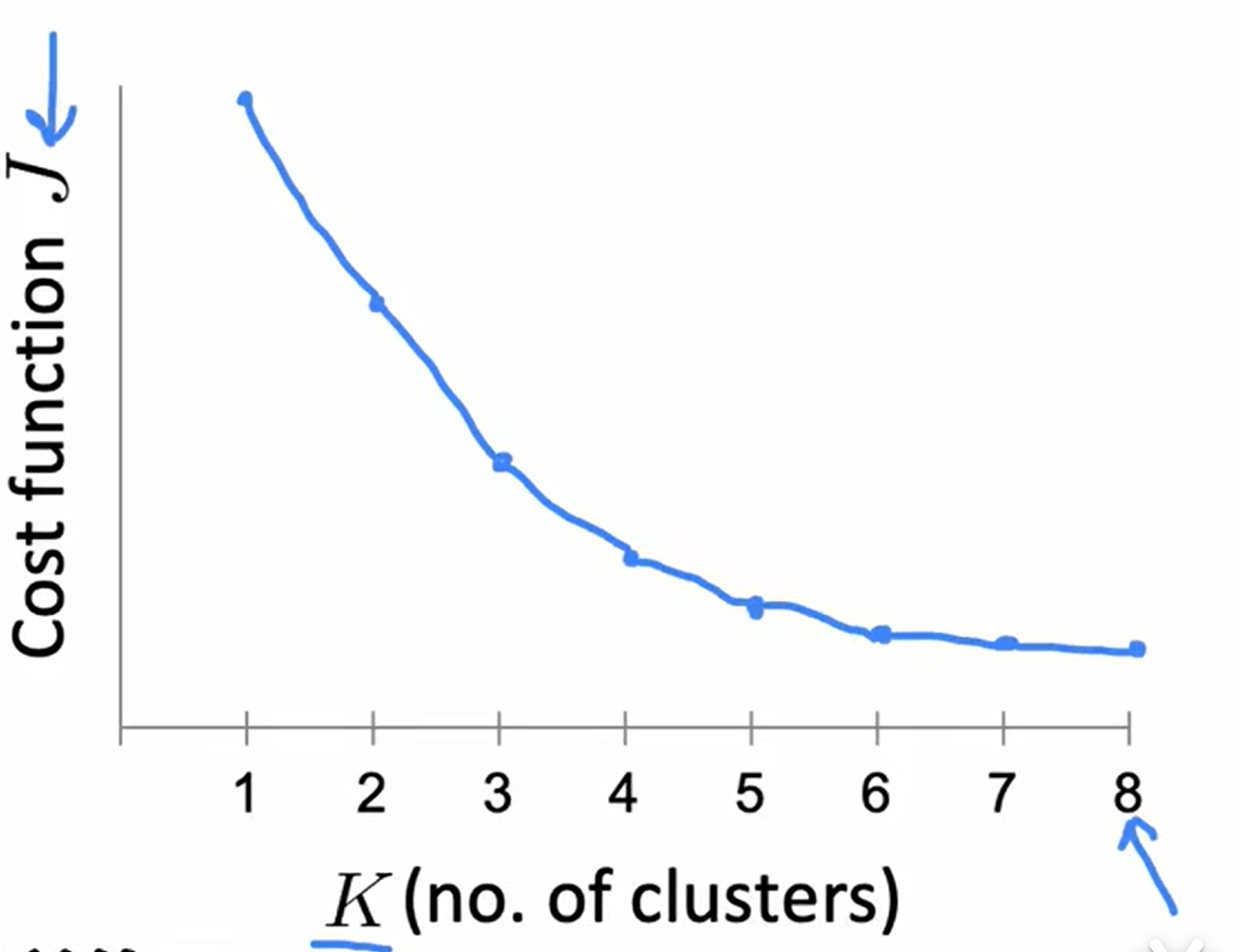
3.2 异常事件检测
通过寻找数据中心,然后计算测试数据的偏移概率,来判断是否是异常事件
p ( x t e s t ) < ϵ p(x_{test}) < \epsilon p(xtest)<ϵ
一般这个概率函数是使用高斯分布函数 ,通过计算得到每个特征在数据集上的高斯分布
p ( x ) = ∏ j = 1 n p ( x j ; μ j , σ j 2 ) p(x) = \prod^n_{j=1}p(x_j;\mu_j,\sigma^2_j) p(x)=j=1∏np(xj;μj,σj2)
有些特征分布不是高斯分布,但一般都会转换为高斯分布并且会对数据进行一定的放缩
3.3 基于评分的推荐系统
使用协同过滤算法去计算特征和对应参数
r ( i , j ) r(i,j) r(i,j):是否评价
y ( i , j ) y^{(i,j)} y(i,j):用户评分
J ( w , b , x ) = 1 2 ∑ ( i , j ) : r ( i , j ) = 1 ( w ( j ) ⋅ x ( i ) + b ( j ) − y ( i , j ) ) 2 + λ 2 ∑ j = 1 n μ ∑ k = 1 n ( w k ( j ) ) 2 + λ 2 ∑ i = 1 n m ∑ k = 1 n ( x k ( i ) ) 2 J(w,b,x)=\frac{1}{2}\sum_{(i,j):r(i,j)=1}(w^{(j)}·x^{(i)}+b^{(j)}-y^{(i,j)})^2+\frac{\lambda}{2}\sum^{n_\mu}{j=1}\sum^n{k=1}(w_k^{(j)})^2+\frac{\lambda}{2}\sum^{n_m}{i=1}\sum^n{k=1}(x_k^{(i)})^2 J(w,b,x)=21(i,j):r(i,j)=1∑(w(j)⋅x(i)+b(j)−y(i,j))2+2λj=1∑nμk=1∑n(wk(j))2+2λi=1∑nmk=1∑n(xk(i))2
二进制标签也就是二元分类会使用 s i g m o d sigmod sigmod函数,使用损失函数
L ( f ( w , b , x ) ( x , y ( i , j ) ) = − y ( i , j ) l o g ( f ( w , b , x ) ( x , y ( i , j ) ) ) − ( 1 − y ( i , j ) ) l o g ( 1 − f ( w , b , x ) ( x , y ( i , j ) ) ) J ( w , b , x ) = ∑ ( i , j ) : r ( i , j ) = 1 L ( f ( w , b , x ) ( x , y ( i , j ) ) L(f_{(w,b,x)}(x,y^{(i,j)})=-y^{(i,j)}log(f_{(w,b,x)}(x,y^{(i,j)}))-(1-y^{(i,j)})log(1-f_{(w,b,x)}(x,y^{(i,j)}))\\ J(w,b,x)=\sum_{(i,j):r(i,j)=1}L(f_{(w,b,x)}(x,y^{(i,j)}) L(f(w,b,x)(x,y(i,j))=−y(i,j)log(f(w,b,x)(x,y(i,j)))−(1−y(i,j))log(1−f(w,b,x)(x,y(i,j)))J(w,b,x)=(i,j):r(i,j)=1∑L(f(w,b,x)(x,y(i,j))
均值归一化: 初始化那些没有评任何电影的用户的数据
3.4 基于内容的推荐系统
x μ x_{\mu} xμ是用户特征, x m x_m xm是电影特征两者经过神经网络得到 v μ v_\mu vμ和 v m v_m vm(两个的长度一样,确保能点积)
J ( w , b , x ) = 1 2 ∑ ( i , j ) : r ( i , j ) = 1 ( v μ ( j ) ⋅ v m ( i ) − y ( i , j ) ) 2 + 正则化 J(w,b,x)=\frac{1}{2}\sum_{(i,j):r(i,j)=1}(v_\mu^{(j)}·v_m^{(i)}-y^{(i,j)})^2+正则化 J(w,b,x)=21(i,j):r(i,j)=1∑(vμ(j)⋅vm(i)−y(i,j))2+正则化
3.5 PCA算法
把特征数据降维,并尽可能保证特征的信息不变。
4、强化学习
状态和行动,奖励,折扣因子组成的一套体系,目标是寻找函数 π ( s ) = a \pi(s)=a π(s)=a
MDP(马尔科夫决策)
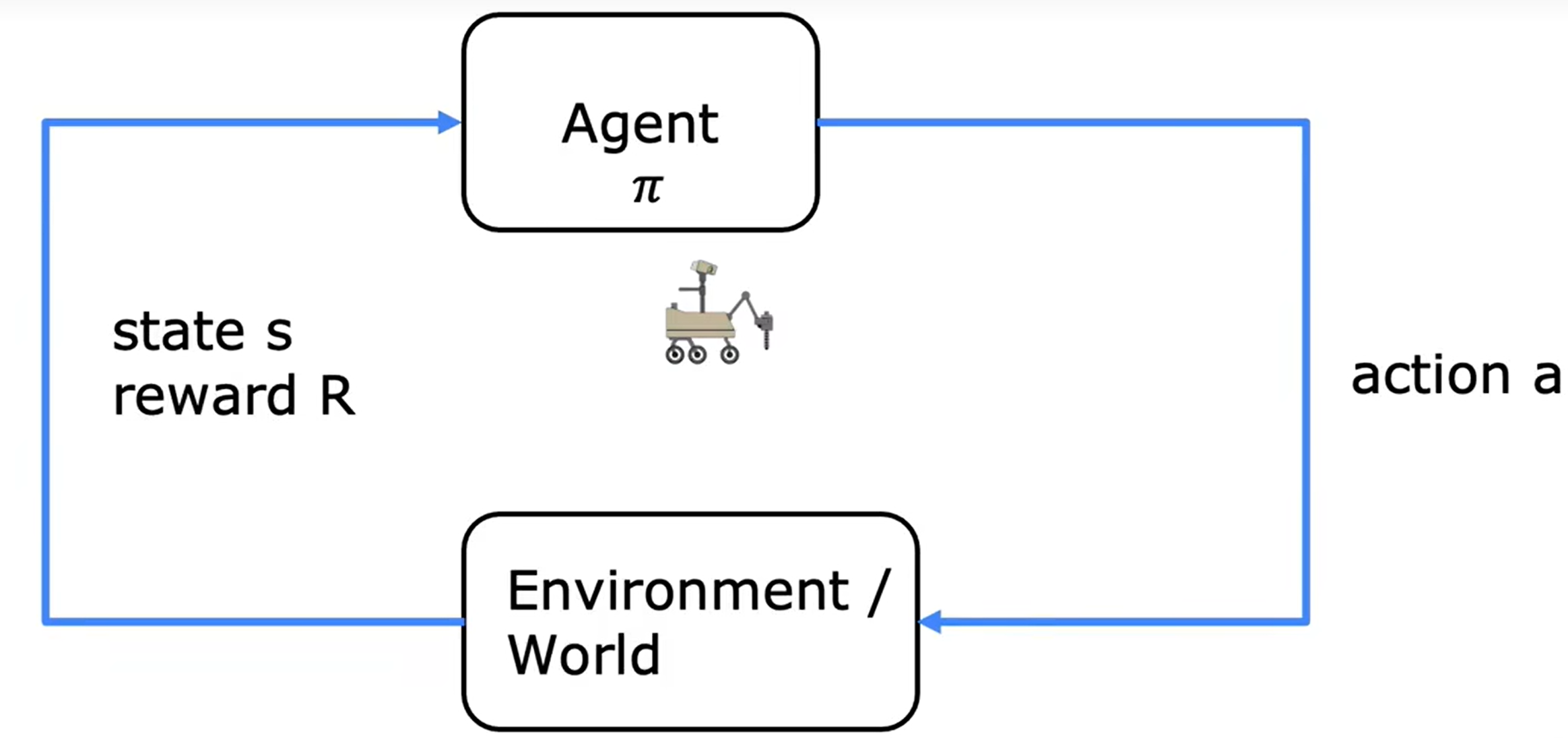
Q ( s , a ) Q(s,a) Q(s,a):在状态 s s s下使用 a a a会得到的价值
γ \gamma γ:折扣因子
R ( s ) R(s) R(s):状态 s s s的价值
贝尔曼方程
Q ( s , a ) = R ( s ) + γ max Q ( s ′ , a ′ ) Q(s,a)=R(s)+\gamma \ \max Q(s',a') Q(s,a)=R(s)+γ maxQ(s′,a′)
收集 x x x和 y y y,构建训练集,训练神经网络训练
x = ( s , a ) y = R ( s ) + γ max Q ( s ′ , a ′ ) x=(s,a)\\ y=R(s)+\gamma \ \max Q(s',a') x=(s,a)y=R(s)+γ maxQ(s′,a′)
一些优化方法:
-
输入当前状态,可以选择一次性输出 所有对应行动下的 Q Q Q,然后选择最大的那个
-
使用小概率 ϵ \epsilon ϵ,在状态 s s s下会有这么小的概率实现随机行动,达到更多随机化的目的,使模型更灵活
-
使用多批次训练,每次得到 Q n e w Q_{new} Qnew,每批次训练结束再更新 Q Q Q函数,一般是 W = 0.01 W n e w + 0.99 W W=0.01W_{new}+0.99W W=0.01Wnew+0.99W这样的取部分值更新, B B B也是,多批次避免一次训练太多数据时间过长