文章目录
-
- 引言:监督学习的"武器库"思维
- 一、算法家族全景:两大任务领域的核心利器
-
- [1. 回归预测:从趋势捕捉到关系量化](#1. 回归预测:从趋势捕捉到关系量化)
- [2. 分类判别:从概率输出到边界划分](#2. 分类判别:从概率输出到边界划分)
- 二、核心思想与哲学对比
- 三、关键特性与应用场景横向对比
- 四、算法选择指南:如何为你的问题匹配合适的工具
- 五、算法演进脉络:从简单假设到复杂现实
- 六、可视化建议与学习路径
-
- [1. 算法分类思维导图](#1. 算法分类思维导图)
- [2. 算法演进时间线](#2. 算法演进时间线)
- [3. 算法选择决策树](#3. 算法选择决策树)
- 七、总结与启示
引言:监督学习的"武器库"思维
在机器学习的版图中,监督学习犹如一支训练有素的主力军,专注于从带有标签的数据中学习预测模型。无论是预测连续值还是判断离散类别,选择合适的算法是成功的关键。本文将为监督学习领域的八大经典算法绘制一幅全景图,通过系统性的归纳、对比与脉络梳理,构建清晰的算法选型框架,助你在解决回归与分类问题时精准选择"武器"。
一、算法家族全景:两大任务领域的核心利器
1. 回归预测:从趋势捕捉到关系量化
-
核心任务:基于输入特征预测一个连续的数值型输出。
-
核心算法:
- 线性回归:通过拟合线性方程,最小化预测值与真实值之间的误差,量化特征与目标间的线性关系。
- 多项式回归:通过引入特征的高阶项,将非线性关系映射到高维空间进行线性拟合,以捕捉曲线趋势。
- 正则化回归:在损失函数中加入惩罚项,约束模型复杂度,防止过拟合,提升泛化能力。
2. 分类判别:从概率输出到边界划分
-
核心任务:基于输入特征预测样本所属的离散类别标签。
-
核心算法:
- 逻辑回归:通过对数几率函数将线性回归结果映射为概率,适用于二分类,并输出具有解释性的概率值。
- 决策树:通过一系列"if-then"规则递归地划分特征空间,形成树形结构,实现直观的分类。
- 随机森林:集成多棵决策树,通过 Bagging 和随机特征子集提升模型精度与稳定性。
- 支持向量机:寻找能使不同类别样本间隔最大化的最优分割超平面,追求最强的泛化能力。
- K 近邻:根据待预测样本的 K 个最近邻居的多数类别来决定其类别,是一种基于实例的惰性学习算法。
二、核心思想与哲学对比
| 算法 | 核心思想比喻 | 技术哲学核心 | 关键洞察 |
|---|---|---|---|
| 线性回归 | "最佳趋势线绘制师" | 最小化均方误差,寻找特征与目标间的最优线性映射。 | 追求全局的、简洁的线性解释,奠基性强但假设严格。 |
| 逻辑回归 | "概率边界雕刻家" | 将线性回归结果通过 Sigmoid 函数转化为概率,用对数几率建立线性关系。 | 在概率框架下进行线性判别,输出具有决策价值的置信度。 |
| 决策树 | "分层决策向导" | 递归地选择最优特征进行数据划分,构建树状规则集。 | 模仿人类决策过程,模型完全透明,但路径依赖导致不稳定。 |
| 随机森林 | "集体智慧陪审团" | 集成多棵差异化决策树的结果,通过投票或平均降低方差。 | 群体智慧优于个体,通过多样性获得稳健与高精度,但牺牲了部分可解释性。 |
| 支持向量机 | "最佳隔离带规划师" | 最大化分类间隔,寻找最鲁棒的分界超平面,可通过核函数处理非线性。 | 追求几何上最安全的决策边界,理论坚实,尤其适合小样本高维问题。 |
| K 近邻 | "民主投票员" | 一个样本的类别由其最近邻的多数票决定。 | 无需显式训练,假设局部相似性,是"数据即模型"的典型代表。 |
| 多项式回归 | "曲线绘图师" | 通过基函数扩展将非线性关系升维至线性空间进行拟合。 | 通过增加模型复杂度来逼近复杂模式,是理解非线性建模的桥梁。 |
| 正则化回归 | "模型健身教练" | 在损失函数中加入参数范数惩罚项,权衡拟合度与模型复杂度。 | 奥卡姆剃刀原理的体现,最好的模型是足够简单且解释良好的模型。 |
三、关键特性与应用场景横向对比
| 维度 | 线性回归 | 逻辑回归 | 决策树 | 随机森林 | 支持向量机 | K 近邻 | 多项式回归 | 正则化回归 |
|---|---|---|---|---|---|---|---|---|
| 任务类型 | 回归 | 分类 | 分类/回归 | 分类/回归 | 分类/回归 | 分类/回归 | 回归 | 回归/分类 |
| 核心参数 | 无 | 正则化系数 C | 树深、叶子节点最小样本数 | 树数量、最大特征数 | 核函数、C、γ | 近邻数 K、距离度量 | 多项式阶数 | 正则化系数 α、L1/L2 混合比 |
| 可解释性 | 极高 | 高 | 极高 | 低(整体)中(特征重要性) | 中(线性核)低(非线性核) | 中 | 中 | 高 |
| 对异常值鲁棒性 | 敏感 | 敏感 | 较鲁棒 | 鲁棒 | 较鲁棒(取决于核与 C) | 敏感 | 非常敏感 | 敏感(但 L1 稍有改善) |
| 处理非线性 | 否 | 否(决策边界线性) | 是 | 是 | 是(通过核技巧) | 是 | 是 | 否(但可为非线性模型提供正则化) |
| 计算复杂度 | O(n*p) 低 | O(n*p) 低 | 训练: O(n log n) 预测: O(log n) | 训练: O(mn log n) 高 预测: O(mlog n) 中 | 训练: O(n²~n³) 高 预测: O(支持向量数) 中 | 训练: O(1) 低 预测: O(n*p) 高 | O(n*p^d) 随阶数 d 剧增 | 略高于对应线性模型 |
| 主要优势 | 简单、快速、可解释性强、统计推断完备 | 输出概率、可解释好、速度快 | 完全透明、无需标准化、处理混合特征 | 精度高、抗过拟合、可评估特征重要性 | 泛化能力强、理论优美、适合高维小样本 | 概念简单、无需训练、无模型假设 | 可捕捉简单非线性、基于线性框架 | 防止过拟合、L1 可做特征选择、处理共线性 |
| 主要局限 | 强线性假设、对共线性敏感 | 本质是线性分类器 | 极易过拟合、不稳定 | 黑箱、计算慢、内存占用大 | 大规模训练慢、调参敏感 | 预测慢、维度灾难、对噪声敏感 | 易过拟合、外推能力差 | 性能仍受基模型限制 |
| 典型应用场景 | 房价预测、因果效应分析 | 金融风控、广告点击预测 | 信用评分、医疗诊断(需解释性时) | 图像分类、推荐系统、各类预测大赛 | 文本分类、生物信息、人脸识别 | 简单分类原型、推荐系统(协同过滤) | 物理实验曲线拟合 | 特征数多于样本数的任何线性建模场景 |
四、算法选择指南:如何为你的问题匹配合适的工具
面对具体问题,可遵循以下决策路径:
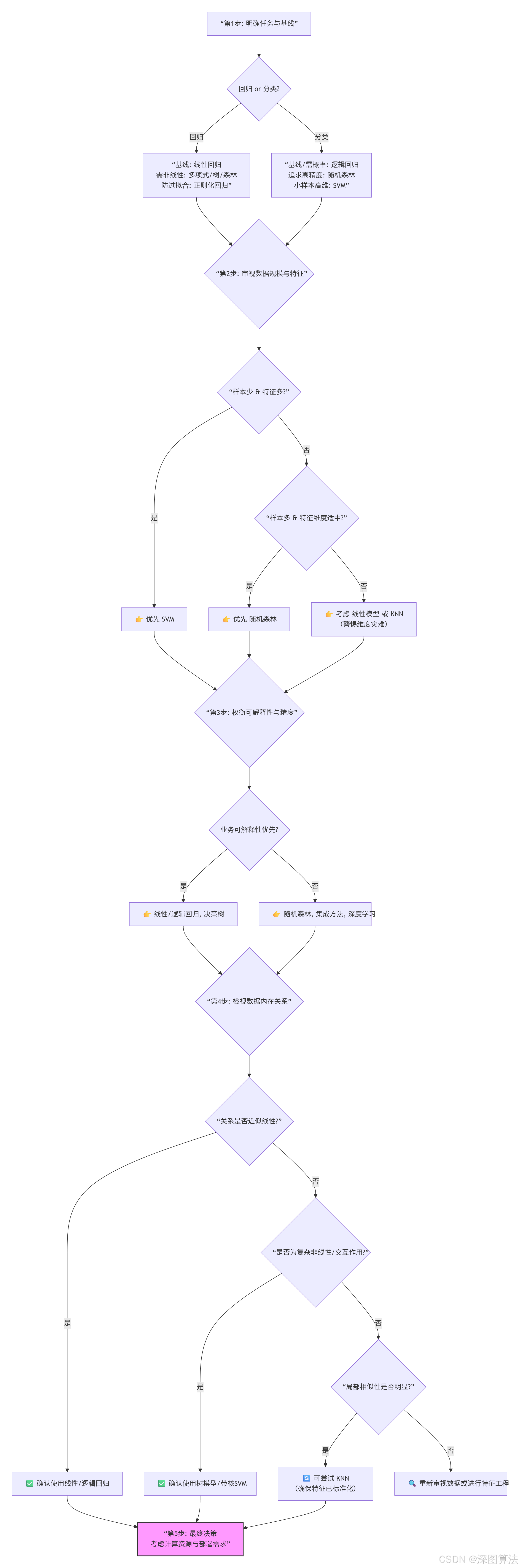
选择口诀:
- 要解释,追因果 → 线性/逻辑回归。
- 要精度,不怕黑箱 → 随机森林。
- 样本少,维度高 → SVM。
- 要简单,快速原型 → 逻辑回归/KNN/决策树。
- 特征多,防过拟合 → 正则化回归。
五、算法演进脉络:从简单假设到复杂现实
监督学习的演进史,是一部围绕模型复杂度、泛化能力与可解释性三角关系不断探索的历史。
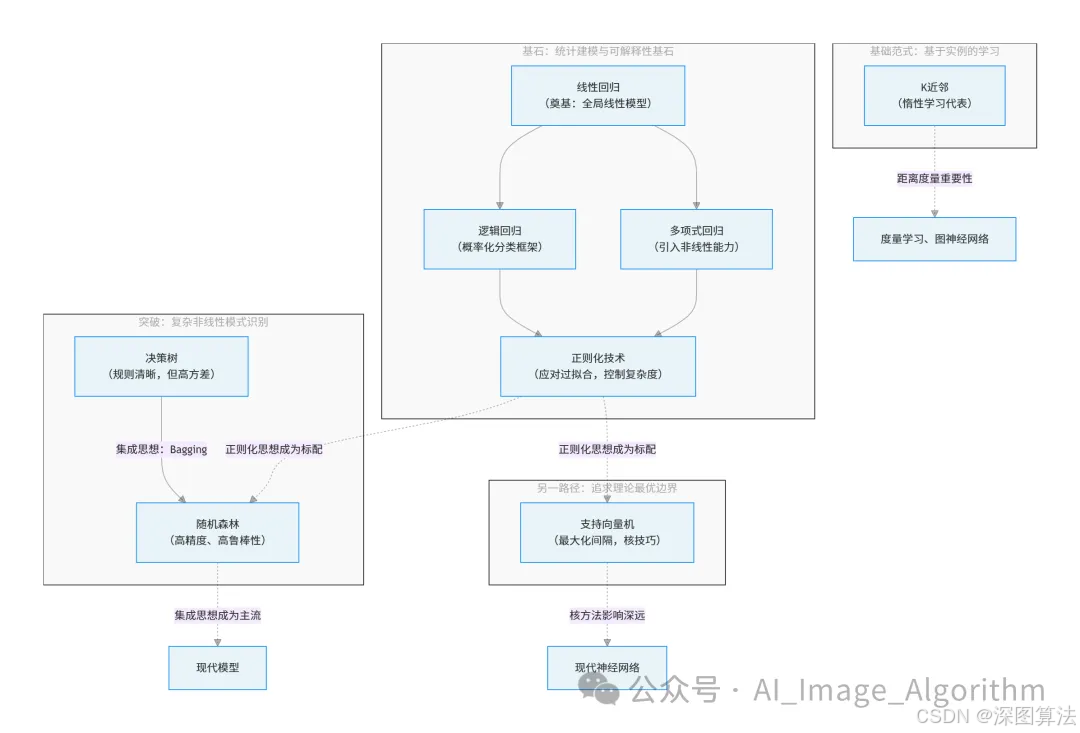
演进的主线:
- 从线性到非线性:线性回归的强假设被决策树、SVM(核方法)、随机森林逐步打破,算法捕捉复杂模式的能力不断增强。
- 从单一模型到模型集成:为克服决策树等高方差模型的不稳定性,集成学习(如随机森林)成为提升精度和鲁棒性的标准范式。
- 从追求拟合到关注泛化:正则化技术的出现和发展,标志着机器学习从一味追求训练集上的"完美拟合",转向追求在未知数据上"表现良好"的泛化能力。
- 不同哲学并存:参数化模型(回归族)、非参数化模型(树模型)、基于实例的模型(KNN)和基于边界最大化的模型(SVM)共同构成了多元的方法论生态。
六、可视化建议与学习路径
1. 算法分类思维导图
监督学习算法
├── 回归预测
│ ├── 线性模型
│ │ ├── 线性回归
│ │ ├── 多项式回归
│ │ └── 正则化回归 (Lasso, Ridge, ElasticNet)
│ └── 非线性模型
│ ├── 决策树回归 (CART)
│ └── 随机森林回归
├── 分类判别
│ ├── 线性分类器
│ │ └── 逻辑回归 (及正则化变体)
│ ├── 非线性分类器
│ │ ├── 决策树分类 (CART, C4.5)
│ │ ├── 随机森林分类
│ │ └── 支持向量机 (带核函数)
│ └── 基于实例的分类器
│ └── K近邻 (KNN)
└── 通用技术与思想
├── 正则化 (控制模型复杂度)
├── 集成学习 (Bagging, Boosting)
└── 核方法 (处理非线性)2. 算法演进时间线
· 监督学习主线:
线性回归(18-19世纪)→逻辑回归(1958)→决策树(1970s-1980s)→SVM(1990s)→随机森林(2001)
· 无监督学习主线(补充):
聚类:K-means(1967)→层次聚类(1950s)→DBSCAN(1996)
异常检测:3σ原则(19世纪)→箱线图法(1977)→LOF(2000)
关联规则:Apriori(1994)→FP-Growth(2000)
降维:PCA(1901)→t-SNE(2008)→UMAP(2018)3. 算法选择决策树
开始 → 任务类型是什么?
├── 监督学习任务
│ ├── 回归 → 数据关系与需求?
│ │ ├── 线性关系/可解释性优先 → 线性/正则化回归
│ │ ├── 简单非线性 → 多项式回归
│ │ └── 复杂非线性/精度优先 → 决策树/随机森林回归
│ └── 分类 → 数据与需求?
│ ├── 需概率输出/可解释性 → 逻辑回归
│ ├── 高精度/复杂模式 → 随机森林
│ ├── 小样本高维/清晰边界 → SVM
│ ├── 完全透明/规则提取 → 决策树
│ └── 快速原型/局部相似性 → KNN七、总结与启示
监督学习的经典算法构成了预测模型的坚实基石。它们的演进史,清晰地展现了一条从简单、可解释 的模型,向复杂、强大 的模型发展,再通过正则化、集成 等技术回归泛化本质的螺旋上升之路。
- 没有银弹,只有合适的工具:线性模型是可解释性的王者,树模型是复杂模式的捕手,SVM 是小样本高维问题的尖兵,KNN 是简单快速的基准。理解其哲学,方能正确选用。
- 演进的核心是对"过拟合"的对抗:从正则化到集成学习,大部分技术进步都围绕着如何让模型更好地泛化到新数据这一核心挑战展开。
- 经典是现代的基石:深度学习的很多思想(如非线性变换、层级结构、正则化)都能在这些经典算法中找到雏形。掌握经典,是通向理解现代人工智能的必经之路。