- 引言
车牌识别(License Plate Recognition, LPR)是智能交通系统中的关键环节,广泛应用于停车场管理、电子警察、高速收费等场景。相比传统方法,基于深度学习的端到端车牌识别模型能够直接从图像中输出车牌字符序列,无需繁琐的字符分割步骤。LPRNet 是一种轻量级、高性能的端到端车牌识别网络,它结合了卷积神经网络与循环神经网络的思想,但通过巧妙的设计去除了循环结构,使其更易于训练和部署。
本文将详细介绍如何使用 PyTorch 实现 LPRNet,涵盖模型结构、数据准备、训练流程、测试以及模型导出(TorchScript 和 ONNX)。我们将基于提供的完整代码进行讲解,帮助你快速掌握 LPRNet 在车牌识别任务上的应用。
- LPRNet 模型结构解析
LPRNet 的核心设计思想是:使用全卷积网络提取特征,并通过多尺度特征融合来捕获不同感受野的上下文信息,最后直接输出时序分类结果(CTC 解码)。模型不包含循环层,因此计算效率高,且对输入长度不敏感。
2.1 整体架构
LPRNet 由三部分组成:
骨干网络(Backbone):一系列卷积层、批归一化、激活函数和池化层,用于提取图像特征。
多尺度特征融合(Global Context):从骨干网络的不同阶段提取特征,进行下采样后融合,增强模型对全局信息的感知。
分类头(Container):一个卷积层将融合后的特征映射到类别空间,最终通过平均池化输出序列概率。
下面我们逐层分析代码实现。
2.2 small_basic_block 模块
python
class small_basic_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(small_basic_block, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(ch_in, ch_out // 4, kernel_size=1),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(3, 1), padding=(1, 0)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(1, 3), padding=(0, 1)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out, kernel_size=1),
)这是一个轻量级的残差块变体,采用 1×1 卷积降维 → 非对称卷积(3×1 和 1×3)→ 1×1 卷积升维 的结构。非对称卷积可以在保持感受野的同时减少参数量,同时适应车牌字符的细长形状。
2.3 骨干网络(Backbone)
骨干网络由 nn.Sequential 定义,包含多个卷积、批归一化、池化以及上述 small_basic_block。关键层及特征图尺寸变化如下(输入图像 24×94×3):
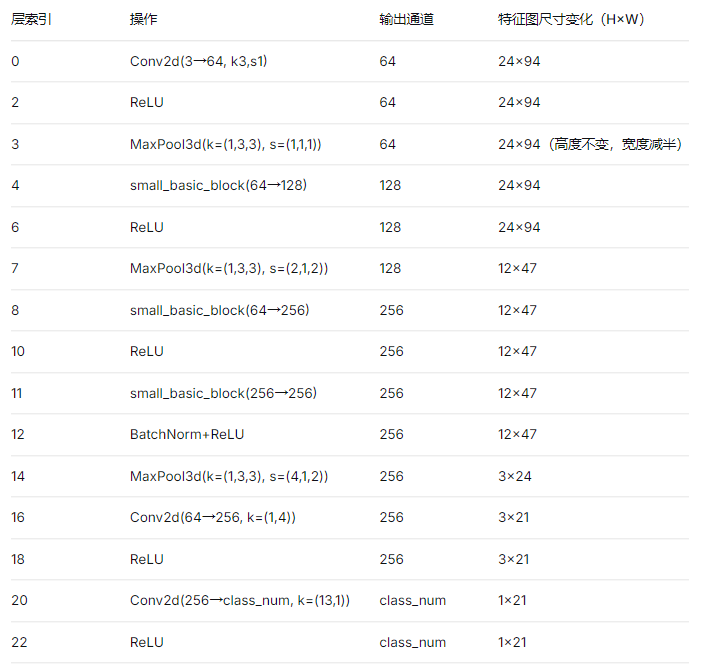
最终骨干网络的输出是一个形状为 B, class_num, 1, T 的特征图,其中 T = 21 是时序长度(对应车牌字符的最大可能个数)。
2.4 多尺度特征融合(Global Context)
在 forward 函数中,骨干网络的前向传播过程中会收集指定层的输出(层索引 2, 6, 13, 22)。这些特征图分别对应不同尺度的特征:
层2:高分辨率(24×94)
层6:中等分辨率(12×47)
层13:低分辨率(3×24)
层22:最低分辨率(1×21)
然后对这些特征图进行下采样,使它们统一到相同的空间尺寸,并经过 功率归一化(f_pow = torch.pow(f, 2); f_mean = torch.mean(f_pow); f = torch.div(f, f_mean))来稳定训练。最后将它们拼接在一起,得到融合后的特征。
2.5 分类头(Container)
python
self.container = nn.Sequential(
nn.Conv2d(in_channels=448 + class_num, out_channels=class_num, kernel_size=(1, 1), stride=(1, 1)),
)这里 448 + class_num 是拼接后的通道数(具体数值取决于各层特征图的通道数)。经过 1×1 卷积后,输出通道数等于类别数,然后通过 torch.mean(x, dim=2) 去除高度维度,得到形状 B, class_num, T 的 logits。
- 数据准备与预处理
3.1 数据集格式
训练数据应按照以下结构组织:
python
train/
├── 0001.jpg
├── 0001.txt
├── 0002.jpg
├── 0002.txt
...每张图片对应一个同名的 .txt 文件,其中包含一行车牌字符串,例如:
python
京A123453.2 标签映射
代码中定义了包含所有可能字符的列表 LABELS,包括各省简称、数字、字母和短横线(代表空白)。注意短横线 "-" 被用作 CTC 的 blank 索引。
python
LABELS = [
"京", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "皖", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁",
"新", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "L",
"M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X",
"Y", "Z", "-"
]
BLANK_INDEX = len(LABELS) - 1 # 最后一个字符 "-" 作为 blank3.3 数据加载器
PlateDataSet 继承自 torch.utils.data.Dataset,主要完成:
读取图片路径和对应的标签文本
将字符序列转换为索引列表
应用图像变换(缩放、归一化)
返回图像张量、标签张量和长度张量
python
def __getitem__(self, index):
img = Image.open(img_path).convert("RGB")
label_str = self._read_label_text(txt_path)
labels = [self.labels.index(ch) for ch in label_str]
labels = torch.tensor(labels, dtype=torch.long)
length = torch.tensor(len(labels), dtype=torch.long)
if self.transform:
img = self.transform(img)
return img, labels, length由于每个样本的标签长度不同,需要使用 collate_fn 将多个样本打包成 batch。在 utils.collate_fn 中,会填充标签序列并记录每个样本的真实长度。
- 模型训练
4.1 训练配置
训练相关的超参数集中在 params.py 中,包括:
图像尺寸:IMG_H = 24, IMG_W = 94
批次大小:train_batch_size = 128, val_batch_size = 64
学习率:learning_rate = 0.001
学习率调度:lr_milestones = 20, 40, 60, gamma = 0.1
最大轮数:max_epoch = 80
CTC 损失参数:blank_index = len(LABELS)-1, zero_infinity = True
4.2 损失函数
LPRNet 使用 CTC Loss(Connectionist Temporal Classification)作为损失函数,它能够处理未对齐的序列输出,非常适合端到端的车牌识别。
python
criterion = nn.CTCLoss(
blank=params.blank_index,
reduction='mean',
zero_infinity=params.zero_infinity
)在训练循环中,我们需要将模型的 logits 转换为 CTC 损失所需的格式:
log_probs:形状 T, B, C(T 为时间步长,B 为批次大小,C 为类别数)
labels:形状 S(S 为所有标签的总和)
input_lengths:每个样本的 T 长度(这里统一为 params.T_length = 21)
target_lengths:每个样本的真实标签长度
python
logits = model(images) # [B, C, T]
log_probs = logits.permute(2, 0, 1) # [T, B, C]
log_probs = log_probs.log_softmax(2) # 对数概率
loss = criterion(log_probs, labels, input_lengths, target_lengths)4.3 训练循环
训练脚本 train.py 主要包含:
train_one_epoch:遍历训练集,计算损失,反向传播,更新参数。
validate:在验证集上计算损失和准确率(通过 CTC 解码得到字符串,比较是否相同)。
学习率调度器 MultiStepLR。
模型保存与恢复(保存 last.pth 和 best.pth,支持断点续训)。
4.4 解码与评估
验证时需要将模型的输出转换为字符串,这通过 utils.batch_decode_logits 完成,它使用贪婪解码(CTC 去重+去除 blank):
python
def ctc_greedy_decode(logits, blank_index):
preds = logits.argmax(dim=1) # [B, T]
batch_texts = []
for i in range(preds.size(0)):
raw = preds[i].tolist()
decoded = []
prev = None
for idx in raw:
if idx == blank_index:
prev = idx
continue
if idx == prev:
continue
decoded.append(idx)
prev = idx
text = ''.join([LABELS[idx] for idx in decoded])
batch_texts.append(text)
return batch_texts准确率则计算预测字符串与真实字符串完全匹配的比例。
- 模型测试与部署
训练完成后,我们需要对单张图片进行推理,并导出模型以便在生产环境中使用。test.py 提供了完整的测试与导出功能。
5.1 单张图片推理
推理流程:
加载模型权重。
对输入图片进行预处理(缩放、归一化、添加 batch 维度)。
前向传播得到 logits,形状 B, C, T。
对 logits 进行 argmax,得到每个时间步的预测索引。
应用 CTC 贪婪解码得到字符串。
python
@torch.no_grad()
def predict_one(model, image_tensor, device, show_raw=False):
image_tensor = image_tensor.to(device)
logits = model(image_tensor) # [B, C, T]
pred_ids = logits.argmax(dim=1) # [B, T]
raw_ids = pred_ids[0] # [T]
decoded_ids = ctc_greedy_decode(raw_ids, BLANK_INDEX)
pred_text = indices_to_string(decoded_ids, LABELS)
return pred_text5.2 导出 TorchScript
TorchScript 是 PyTorch 的中间表示,可以脱离 Python 环境运行,适合 C++ 部署
python
traced_model = torch.jit.trace(model, example_input)
traced_model.save("lprnet.pt")注意:example_input 是经过预处理的单张图片张量(形状 1,3,24,94)。由于模型不包含动态控制流,使用 trace 即可导出。
5.3 导出 ONNX
ONNX 是一种开放的模型格式,支持多种推理引擎(如 ONNX Runtime、TensorRT)。
python
torch.onnx.export(
model,
example_input,
"lprnet.onnx",
export_params=True,
opset_version=13,
input_names=["input"],
output_names=["output"],
dynamic_axes={"input": {0: "batch"}, "output": {0: "batch"}}
)这里设置了 dynamic_axes,允许 batch 维度变化,提高灵活性。
- 总结与展望
本文从模型结构、数据准备、训练、测试到部署,详细介绍了基于 PyTorch 的 LPRNet 车牌识别实现。LPRNet 凭借其全卷积设计、多尺度特征融合和轻量级模块,在保持高精度的同时具备良好的实时性,非常适合实际应用。
完整工程链接:https://download.csdn.net/download/weixin_45776000/92749876,里面有ccpd数据集训练的模型,正确率最好的是99.70%,当然也跟我只用ccpd_base数据集有关,也有车牌生成器训练的模型,正确率最好的是92.20%
我这里使用的车牌生成器生成的数据集链接:https://download.csdn.net/download/weixin_45776000/92747109
使用的ccpd数据集链接:请参考我的上一篇博客,里面有详细的数据集链接:https://editor.csdn.net/md/?articleId=159278272