基于 Scaling Law 的大模型训练算力规划与 GPU 资源配置
1. 什么是 Scaling Law
1.1 定义
Scaling Law(缩放定律)是描述大型语言模型性能与模型规模、数据量、计算量之间关系的经验规律。它揭示了:当增加模型参数量、训练数据量或计算资源时,模型性能会如何变化。
1.2 核心发现
研究表明,大模型的性能(通常用困惑度 Perplexity 或下游任务准确率衡量)与以下三个因素呈幂律关系:
- N(Number of Parameters):模型参数量
- D(Data Tokens):训练数据量
- C(Compute):计算量(FLOPs)
1.3 为什么 Scaling Law 重要
- 预测性:可以在训练前预估模型性能
- 资源规划:帮助确定最优的模型规模和数据量配比
- 成本控制:避免盲目扩大模型导致的资源浪费
2. Scaling Law 的核心公式
2.1 性能与参数量的关系
模型性能(损失函数值)与参数量的关系可表示为:
L(N)=(NcN)αN L(N) = \left(\frac{N_c}{N}\right)^{\alpha_N} L(N)=(NNc)αN
其中:
- L 是损失值(Loss)
- N 是模型参数量
- N_c 是临界参数量
- α_N 是幂律指数(通常约 0.07~0.35)
2.2 性能与数据量的关系
L(D)=(DcD)αD L(D) = \left(\frac{D_c}{D}\right)^{\alpha_D} L(D)=(DDc)αD
其中:
- D 是训练 Token 数量
- D_c 是临界数据量
- α_D 是幂律指数(通常约 0.27~0.5)
2.3 性能与计算量的关系
L(C)=(CcC)αC L(C) = \left(\frac{C_c}{C}\right)^{\alpha_C} L(C)=(CCc)αC
其中:
- C 是总计算量(FLOPs)
- CcC_cCc 是临界计算量
- αCα_CαC是幂律指数(通常约 0.05~0.23)
3. 计算量估算:6ND 方法
3.1 什么是 6ND
在大模型训练中,**总计算量(FLOPs)**可以通过 6ND 公式快速估算:
总计算量=6×N×D \text{总计算量} = 6 \times N \times D 总计算量=6×N×D
计算流程图:
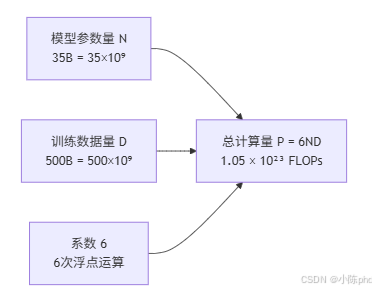
3.2 公式解读
| 符号 | 含义 | 说明 |
|---|---|---|
| 6 | 系数 | 每个参数和每个 Token 需要约 6 次浮点运算(乘法和加法) |
| N | 参数量 | 模型的总参数个数,单位通常是 Billion(十亿) |
| D | 数据量 | 训练数据的 Token 数量,单位通常是 Billion(十亿) |
3.3 计算示例
假设我们要训练一个 35B 参数 的模型,使用 500B Token 的数据:
python
# 参数设置
N = 35 × 10^9 # 35B 参数
D = 500 × 10^9 # 500B Token
# 总计算量
P = 6 × N × D
= 6 × 35 × 10^9 × 500 × 10^9
= 1.05 × 10^23 FLOPs4. GPU 资源需求计算
4.1 计算公式
确定总算力需求后,可以计算所需的 GPU 数量:
GPU数量=总计算量训练时长×GPU使用率×单卡性能 \text{GPU数量} = \frac{\text{总计算量}}{\text{训练时长} \times \text{GPU使用率} \times \text{单卡性能}} GPU数量=训练时长×GPU使用率×单卡性能总计算量
GPU 资源计算流程:
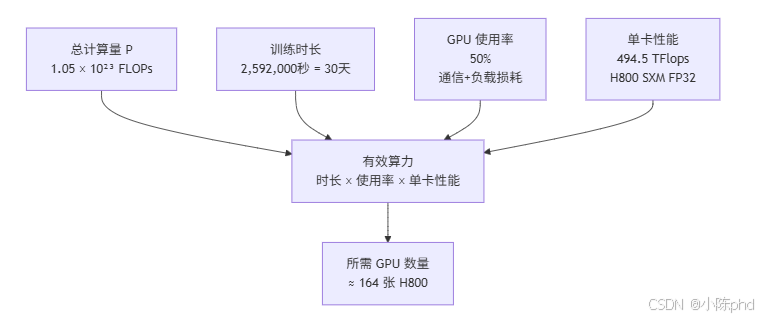
4.2 关键参数说明
4.2.1 训练时长
将天数转换为秒数:
训练秒数=天数×24×60×60 \text{训练秒数} = \text{天数} \times 24 \times 60 \times 60 训练秒数=天数×24×60×60
例如,30 天训练:
30×24×60×60=2,592,000 秒 30 \times 24 \times 60 \times 60 = 2,592,000 \text{ 秒} 30×24×60×60=2,592,000 秒
4.2.2 GPU 使用率
为什么 GPU 使用率达不到 100%?
实际训练中,GPU 利用率通常在 30%~55% 之间,主要受以下因素影响:
- 通信开销:多 GPU 之间需要同步参数和梯度,产生网络延迟
- 负载不均衡:数据分配不均或不同 GPU 处理速度差异
- 硬件限制:内存带宽、PCIe 带宽等瓶颈
- 软件限制:数据加载、预处理等环节的等待时间
4.2.3 单卡性能(TFlops)
TFlops 是衡量 GPU 计算能力的指标:
- T:Tera,表示"万亿"(10^12)
- Flops:Floating Point Operations Per Second,每秒浮点运算次数
- 1 TFlops = 每秒 1 万亿次浮点运算
精度格式说明:
| 精度格式 | 全称 | 说明 | 适用场景 |
|---|---|---|---|
| FP64 | Float64 | 双精度浮点 | 科学计算 |
| FP32 | Float32 | 单精度浮点 | 通用训练 |
| TF32 | TensorFloat32 | TensorCore 加速的单精度 | 深度学习默认 |
| FP16 | Float16 | 半精度浮点 | 混合精度训练 |
| FP8 | Float8 | 8位浮点 | 推理加速 |
| INT8 | Integer8 | 8位整数 | 量化推理 |
GPU 接口类型:
| 接口 | 全称 | 特点 |
|---|---|---|
| PCIe | Peripheral Component Interconnect Express | 通用接口,带宽相对较低,兼容性好 |
| SXM | Mezzanine | NVIDIA 专有接口,更高带宽、更低延迟 |
| NVL | NVLink | GPU 之间高速直连,支持多卡高速数据交换 |
Tensor Core:
NVIDIA 在 Volta、Turing、Ampere、Hopper 架构中引入的专用硬件单元,专门加速矩阵乘法和累加运算,可显著提升深度学习训练速度。
4.3 主流 GPU 性能对比
| GPU 型号 | 显存 | 接口 | FP32 (TFlops) | FP16 TensorCore (TFlops) |
|---|---|---|---|---|
| A100 | 80GB | PCIe | 19.5 | 312 |
| A100 | 80GB | SXM | 19.5 | 624 |
| A800 | 80GB | PCIe | 19.5 | 624 |
| A800 | 80GB | SXM | 19.5 | 624 |
| H100 | 80GB | SXM | 67 | 1979 |
| H100 | 80GB | PCIe | 51 | 1513 |
| H800 | 80GB | SXM | 989 | 1979 |
| H800 | 80GB | PCIe | 51 | 1513 |
接口说明:
- PCIe:通用接口,带宽相对较低
- SXM:NVIDIA 专有接口,提供更高带宽和更低延迟
- NVL:NVLink 接口,支持 GPU 之间高速直连
4.4 完整计算示例
假设我们要在 30 天 内完成上述 35B 模型、500B Token 的训练:
python
# 1. 计算总计算量
P = 6 × 35 × 10^9 × 500 × 10^9 = 1.05 × 10^23 FLOPs
# 2. 训练时长(秒)
training_duration = 30 × 24 × 60 × 60 = 2,592,000 秒
# 3. GPU 使用率
use_ratio = 0.5 # 50%
# 4. 单卡性能(H800 SXM FP32)
single_gpu = 989 / 2 = 494.5 TFlops = 494.5 × 10^12 FLOPs/s
# 5. 计算所需 GPU 数量
how_many_gpu = P / (training_duration × use_ratio × single_gpu)
= 1.05 × 10^23 / (2,592,000 × 0.5 × 494.5 × 10^12)
≈ 163.8 张
# 6. 实际采购(向上取整)
实际 GPU 数量 = 164 张
# 7. 计算服务器数量(按每台 8 卡计算)
服务器数量 = 164 / 8 = 20.5 → 21 台5. 代码实战案例
5.1 完整 Python 代码
完整算力估算代码:
python
# encoding=utf-8
import math
# ============================================
# 步骤 1: 定义模型和训练参数
# ============================================
# 系数:每个参数和每个 Token 需要约 6 次浮点运算
coefficient = 6
# 模型参数量(单位:Billion)
number_of_parameters = 35 # 35B 参数
N = number_of_parameters * 10 ** 9 # 转换为实际数量
# 训练数据 Token 数量(单位:Billion)
data_tokens = 500 # 500B Token
D = data_tokens * 10 ** 9 # 转换为实际数量
# ============================================
# 步骤 2: 计算总计算量(6ND 方法)
# ============================================
P = coefficient * N * D
print(f"总计算量: {P:.2e} FLOPs")
# ============================================
# 步骤 3: 定义训练时间参数
# ============================================
# 期望训练天数(单位:Day)
expected_training_days = 30
# 转换为秒数
training_duration = expected_training_days * 24 * 60 * 60
print(f"训练时长: {training_duration:,} 秒 ({expected_training_days} 天)")
# ============================================
# 步骤 4: 设置 GPU 使用率
# ============================================
# 集群算力达到 100% 利用率非常困难,原因:
# 1. 通信开销:GPU 间需要同步参数和梯度
# 2. 负载不均衡:数据分配不均或处理速度差异
# 3. 硬件和软件限制
use_ratio = 0.5 # 50% 使用率
print(f"GPU 使用率: {use_ratio * 100}%")
# ============================================
# 步骤 5: 选择 GPU 型号和性能
# ============================================
# H800 SXM FP32 性能(单位:TFlops)
H800_80G_SXM_FP32 = 989
# 如果是 H800 40G,性能约为 80G 的一半
single_gpu = H800_80G_SXM_FP32 / 2 # 494.5 TFlops
single_gpu_flops = single_gpu * 10 ** 12 # 转换为 FLOPs/s
print(f"单卡性能: {single_gpu} TFlops")
# ============================================
# 步骤 6: 计算所需 GPU 数量
# ============================================
# 公式: GPU数量 = 总计算量 / (训练时长 × GPU使用率 × 单卡性能)
how_many_gpu = P / (training_duration * use_ratio * single_gpu_flops)
how_many_gpu_rounded = round(how_many_gpu, 2)
print(f"\n========== 计算结果 ==========")
print(f"理论需要: {how_many_gpu_rounded} 张 H800 40G 卡")
print(f"实际采购: {math.ceil(how_many_gpu)} 张 H800 40G 卡")
# ============================================
# 步骤 7: 计算服务器数量
# ============================================
gpu_count = math.ceil(how_many_gpu)
server_count_exact = gpu_count / 8 # 每台服务器 8 卡
server_count = math.ceil(server_count_exact)
print(f"理论需要: {server_count_exact:.1f} 台 GPU 服务器")
print(f"实际采购: {server_count} 台 GPU 服务器")5.2 代码运行结果
总计算量: 1.05e+23 FLOPs
训练时长: 2,592,000 秒 (30 天)
GPU 使用率: 50.0%
单卡性能: 494.5 TFlops
========== 计算结果 ==========
理论需要: 163.76 张 H800 40G 卡
实际采购: 164 张 H800 40G 卡
理论需要: 20.5 台 GPU 服务器
实际采购: 21 台 GPU 服务器5.3 不同场景对比
使用上述代码,我们可以快速计算不同配置下的资源需求:
| 场景 | 模型参数 | 数据量 | 训练天数 | GPU 使用率 | 所需 GPU |
|---|---|---|---|---|---|
| 快速迭代 | 7B | 140B | 7 天 | 50% | ~47 张 |
| 标准训练 | 35B | 500B | 30 天 | 50% | ~164 张 |
| 大规模预训练 | 70B | 1.4T | 60 天 | 55% | ~186 张 |
| 超大规模 | 175B | 3.5T | 90 天 | 55% | ~315 张 |
5.4 关键参数调整建议
提高 GPU 使用率的方法:
- 优化通信:使用 NVLink、InfiniBand 高速网络
- 负载均衡:优化数据并行策略,确保各 GPU 负载均匀
- 混合精度训练:使用 FP16/BF16 减少显存占用,提高吞吐
- 梯度累积:减少通信频率,提高计算占比
- 流水线并行:合理划分模型层,减少气泡时间
降低 GPU 数量的方法:
- 延长训练时间:用时间换资源
- 提高单卡性能:选择更高性能的 GPU(如 H100 替代 A100)
- 优化算法:使用更高效的优化器和学习率策略,加速收敛
6. Scaling Law 的实践指导
6.1 模型规模与数据量的配比
根据 Scaling Law 的研究,模型参数量 N 和训练 Token 数 D 应该等比例增长:
D≈20×N D \approx 20 \times N D≈20×N
模型与数据配比关系:
高数据配比 (Token/Param > 20)
理想配比 (Token/Param ≈ 20)
低数据配比 (Token/Param < 10)
数据不足
增加数据
超量数据
GPT-3
175B Param
300B Token
比例: 1.7
Chinchilla
70B Param
1.4T Token
比例: 20
LLaMA-2
70B Param
2T Token
比例: 28
LLaMA-3
70B Param
15T Token
比例: 214
上图展示了不同模型的参数量与训练数据量配比:
- GPT-3(比例 1.7):早期模型,数据量相对不足
- Chinchilla(比例 20):论文推荐的计算最优比例
- LLaMA-2(比例 28):使用更多数据训练
- LLaMA-3(比例 214):使用超量数据训练,性能更优
即:每 1B 参数需要约 20B Token 的训练数据。
常见模型的配置参考:
| 模型 | 参数量 | 训练 Token | Token/参数比 |
|---|---|---|---|
| GPT-3 | 175B | 300B | ~1.7 |
| Chinchilla | 70B | 1.4T | 20 |
| LLaMA-2 | 70B | 2T | ~28 |
| LLaMA-3 | 70B | 15T | ~214 |
6.2 计算最优 vs 性能最优
在实际训练中,需要在计算成本 和模型性能之间做权衡:
- 计算最优(Compute-optimal):给定计算预算下,使 N 和 D 达到最佳平衡
- 性能最优(Performance-optimal):追求最佳性能,可能使用更多数据训练较小的模型
6.3 资源受限时的决策
当资源有限时,可以参考以下优先级:
- 数据质量优先:高质量数据比大量低质量数据更重要
- 适度规模:不要盲目追求超大模型,应匹配数据量
- 训练效率:使用混合精度、梯度累积等技术提高效率
7. Scaling Law 的局限性与挑战
7.1 局限性
- 经验性规律:Scaling Law 是基于实验观察的统计规律,非严格理论
- 任务依赖性:不同下游任务可能有不同的最优缩放比例
- 数据质量敏感:公式假设数据质量恒定,实际中数据质量差异很大
7.2 当前挑战
- 数据瓶颈:高质量训练数据即将耗尽
- 计算成本:超大规模训练的成本呈指数增长
- 推理成本:大模型部署和推理成本高昂
7.3 未来方向
- 数据效率:研究如何用小数据训练大模型
- 模型压缩:知识蒸馏、量化、剪枝等技术
- 新架构:MoE(混合专家模型)等稀疏架构
8. 总结
Scaling Law 为大模型训练提供了重要的理论指导:
- 6ND 公式可以快速估算训练所需的计算量
- 资源计算公式帮助确定 GPU 采购数量
- N 与 D 的配比影响模型的最终性能
- 实际应用中需要考虑 GPU 使用率、通信开销等因素
掌握 Scaling Law,可以帮助 AI 团队更科学地规划大模型训练项目,避免资源浪费,提高训练效率。
参考资源
- Kaplan et al. "Scaling Laws for Neural Language Models" (2020)
- Hoffmann et al. "Training Compute-Optimal Large Language Models" (Chinchilla, 2022)
- NVIDIA 官方 GPU 性能规格文档