
一、如何理解隔离性
多个事务并发执行时,如果互相干扰,会产生各种问题。SQL标准定义了四种隔离级别,用来平衡并发性能与数据一致性。

隔离性就是让并发执行的多个事务,看起来像在 "串行" 执行一样 ,每个事务都感觉不到其他事务的存在,从而保证数据的一致性。
- 完全隔离会让数据库并发性能变差,所以数据库设计了隔离级别,允许事务受到不同程度的干扰,在 "性能" 和 "数据安全" 之间做权衡。
- 不同隔离级别会解决不同的并发问题(比如脏读、不可重复读、幻读)。
二、隔离级别
- 读未提交【Read Uncommitted】: 在该隔离级别,所有的事务都可以看到其他事务没有提交的执行结果。(实际生产中不可能使用这种隔离级别的),但是相当于没有任何隔离性,也会有很多并发问题,如脏读,幻读,不可重复读等**,我们上面为了做实验方便,用的就是这个隔离性。**
- 读提交【Read Committed】:该隔离级别是大多数数据库的默认的隔离级别(不是 MySQL 默认的)。它满足了隔离的简单定义:**一个事务只能看到其他的已经提交的事务所做的改变。这种隔离级别会引起不可重复读,**即一个事务执行时,如果多次 select, 可能得到不同的结果。
- 可重复读【Repeatable Read】: 这是 MySQL 默认的隔离级别,它确保同一个事务,在执行中,多次读取操作数据时,会看到同样的数据行。但是会有幻读问题。
- 串行化【Serializable】: 这是事务的最高隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决了幻读的问题。它在每个读的数据行上面加上共享锁,。但是可能会导致超时和锁竞争 (这种隔离级别太极端,实际生产基本不使用)
- 隔离级别如何实现:隔离,基本都是通过锁实现的,不同的隔离级别,锁的使用是不同的。常见有,表****锁,行锁,读锁,写锁,间隙锁(GAP),Next-Key锁(GAP+行锁) **等。**不过,我们目前现有这个认识就行,先关注上层使用。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 加锁读 |
|---|---|---|---|---|
| 读未提交(READ UNCOMMITTED) | ✓ | ✓ | ✓ | 不加锁 |
| 读已提交(READ COMMITTED) | ✗ | ✓ | ✓ | 不加锁 |
| 可重复读(REPEATABLE READ) | ✗ | ✗ | ✗(MySQL解决) | 不加锁 |
| 串行化(SERIALIZABLE) | ✗ | ✗ | ✗ | 加锁 |
- 级别越高,越安全,并发越慢!
三、查看与设置隔离性
3.1 查看
-- 查看全局隔离级别
SELECT @@global.tx_isolation;
-- 查看当前会话隔离级别
SELECT @@session.tx_isolation;
-- 简写
SELECT @@tx_isolation;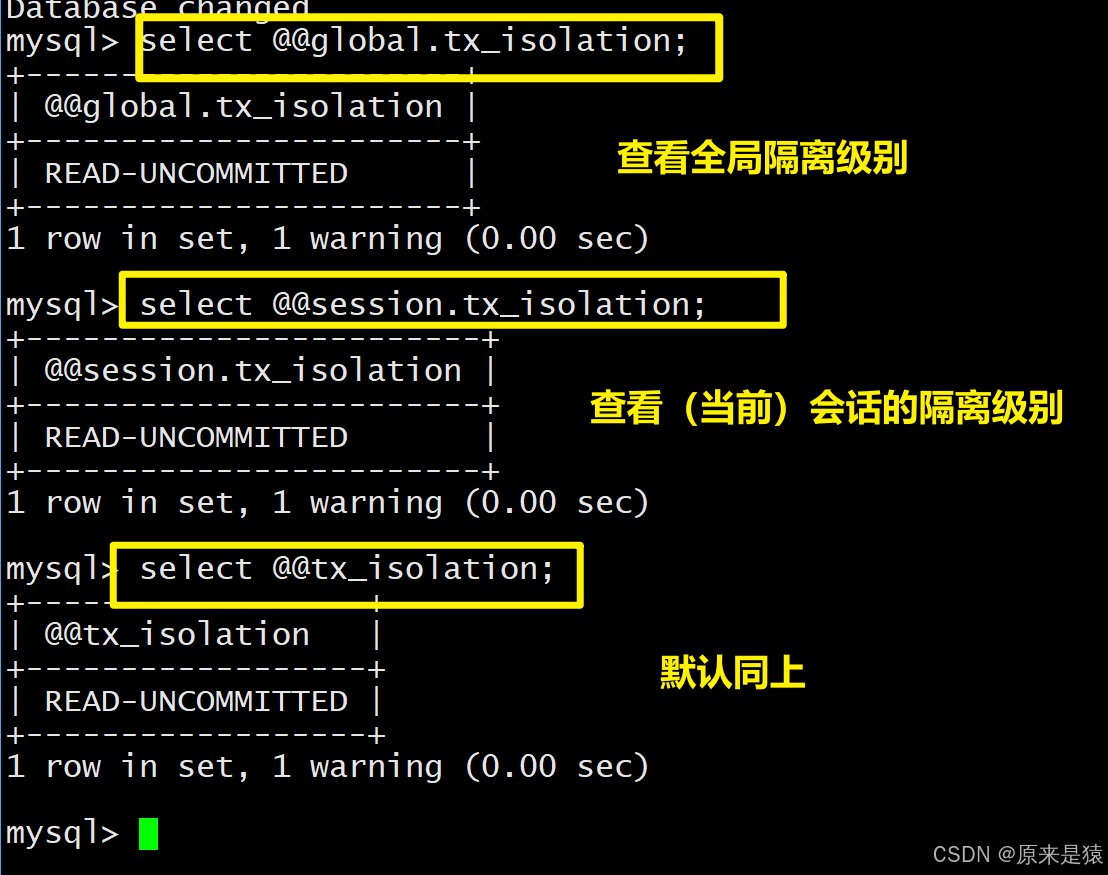
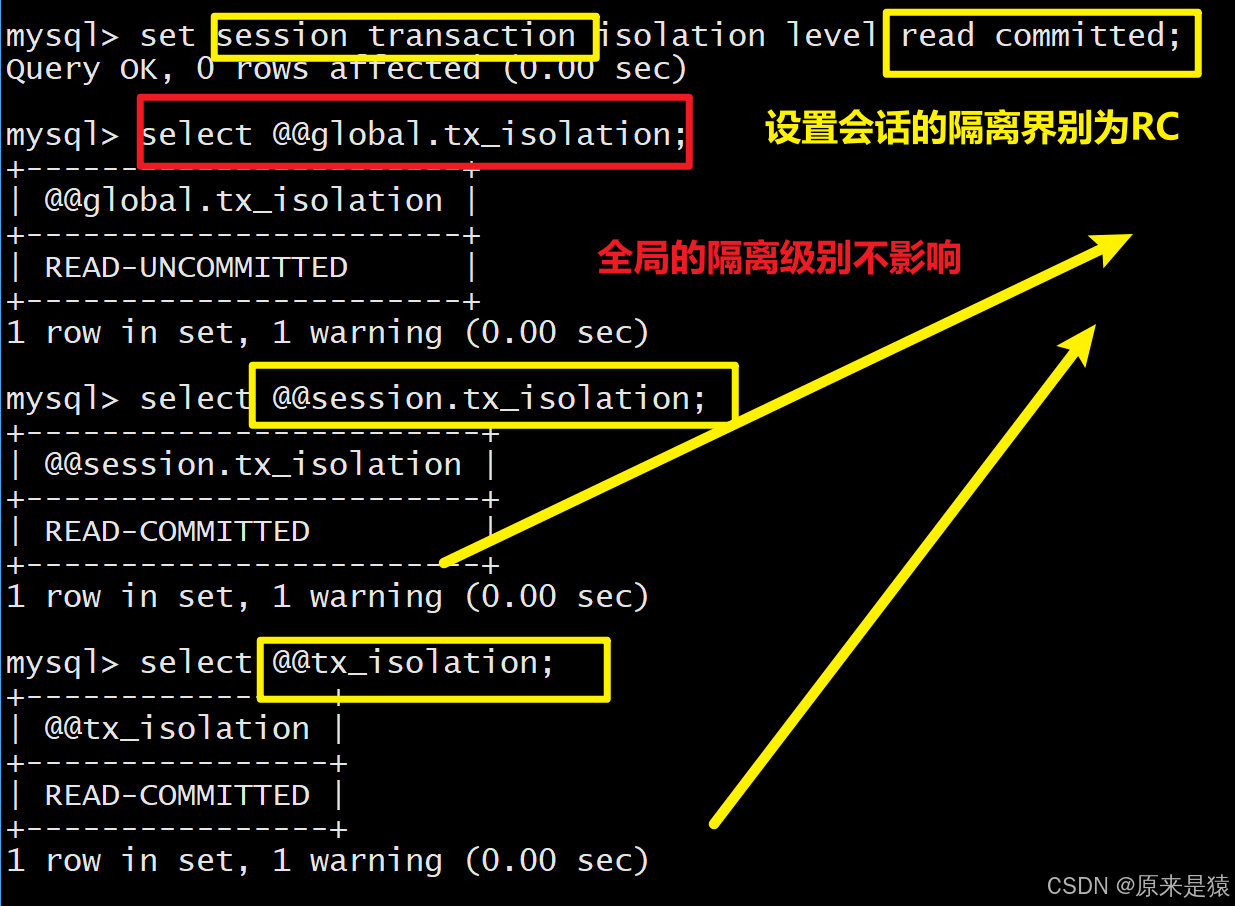
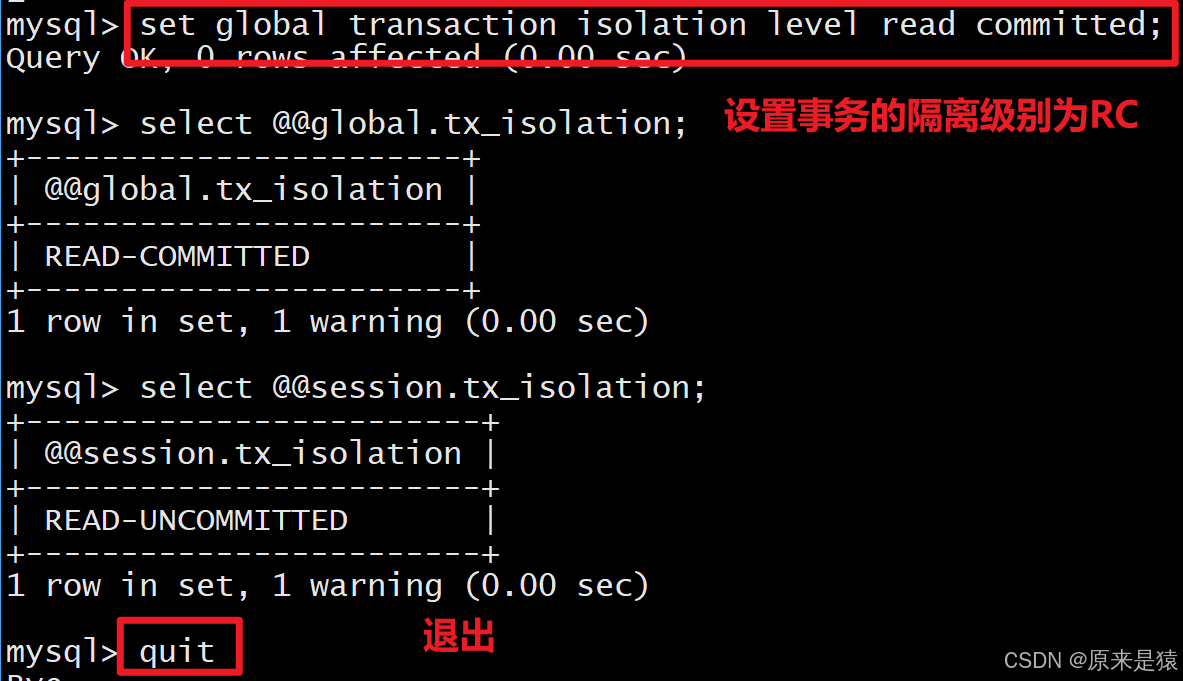
3.2 设置隔离级别
-- 设置当前会话为读未提交
set session transaction isolation level READ UNCOMMITTED;
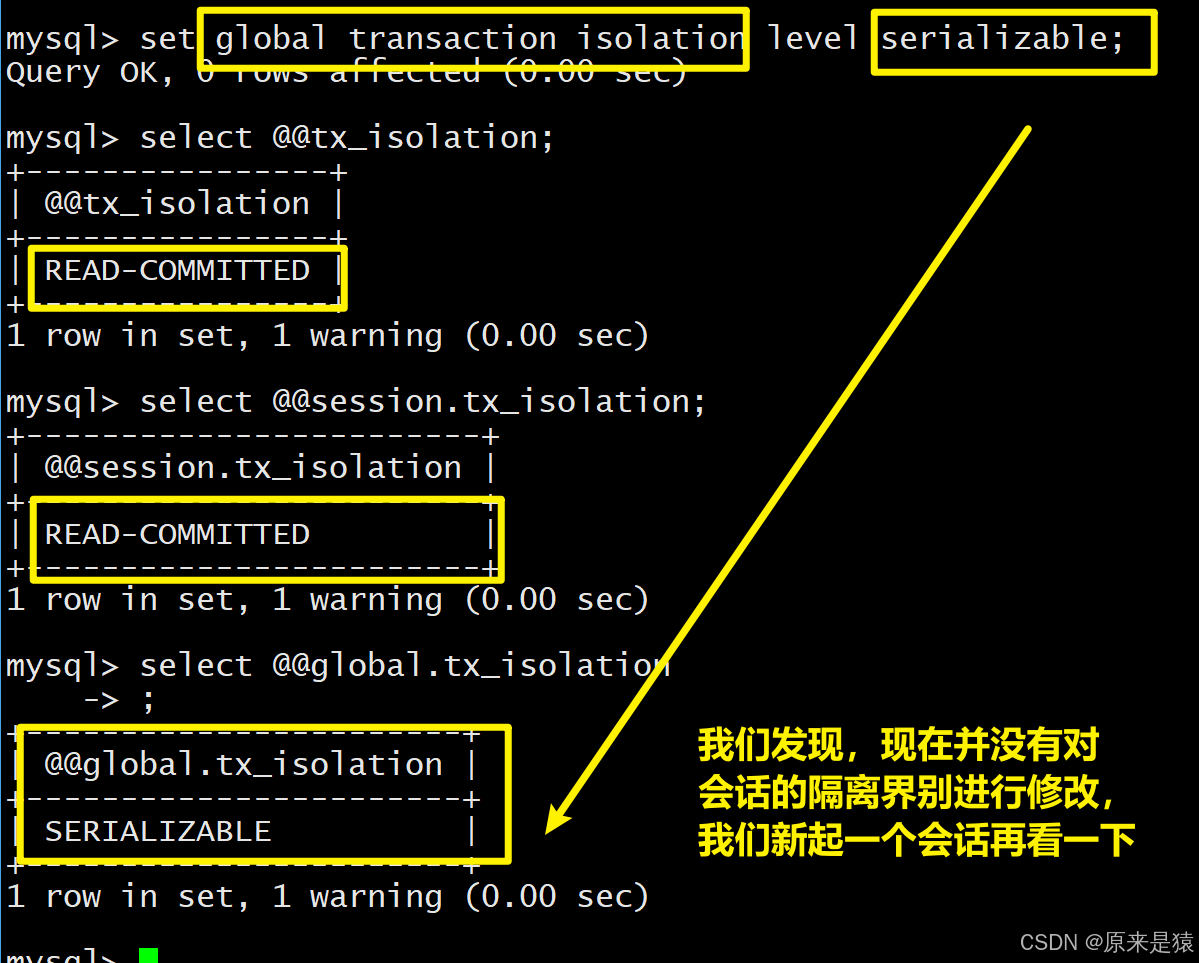
-- 设置全局为可重复读(MySQL默认)
set global transaction isolation level REPEATABLE READ;1. 设置当前会话隔离性,另起一个会话,并不会一起改,所以在某个会话中设置隔离性,只影响当前会话
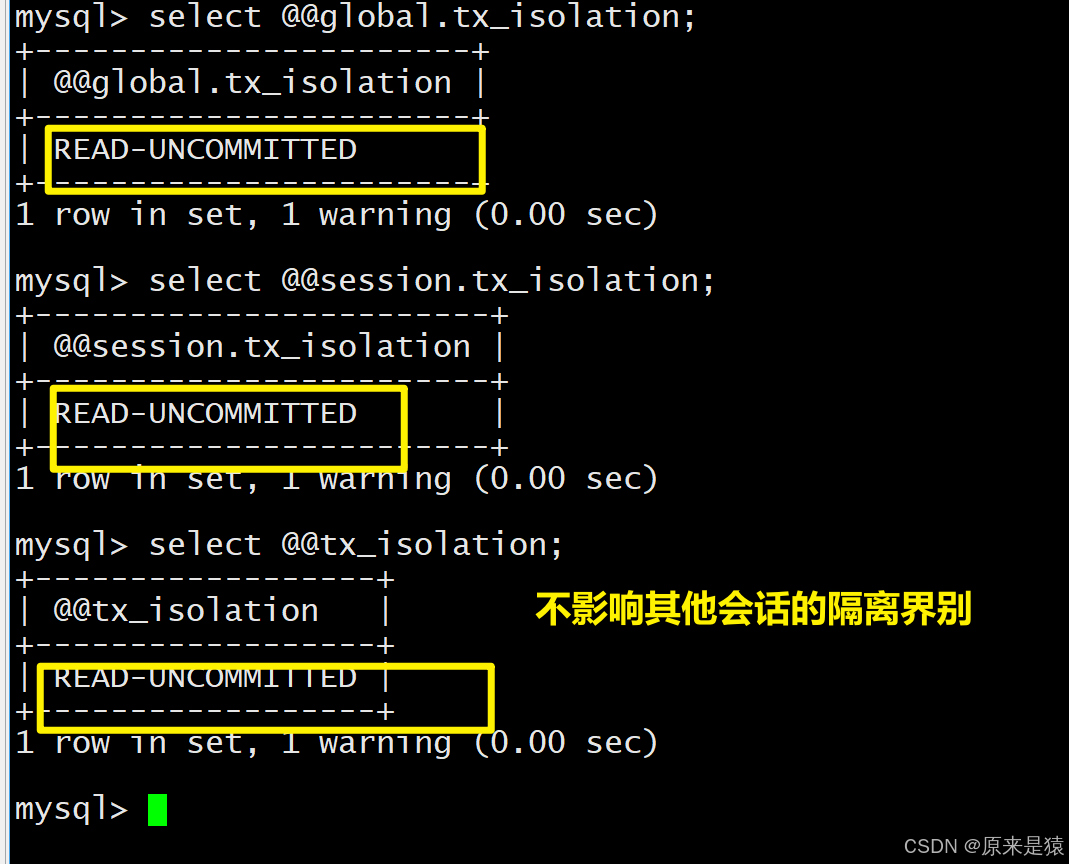
2.设置全局隔离性,另起一个会话,会被影响 。 新起的隔离级别默认为全局的隔离级别
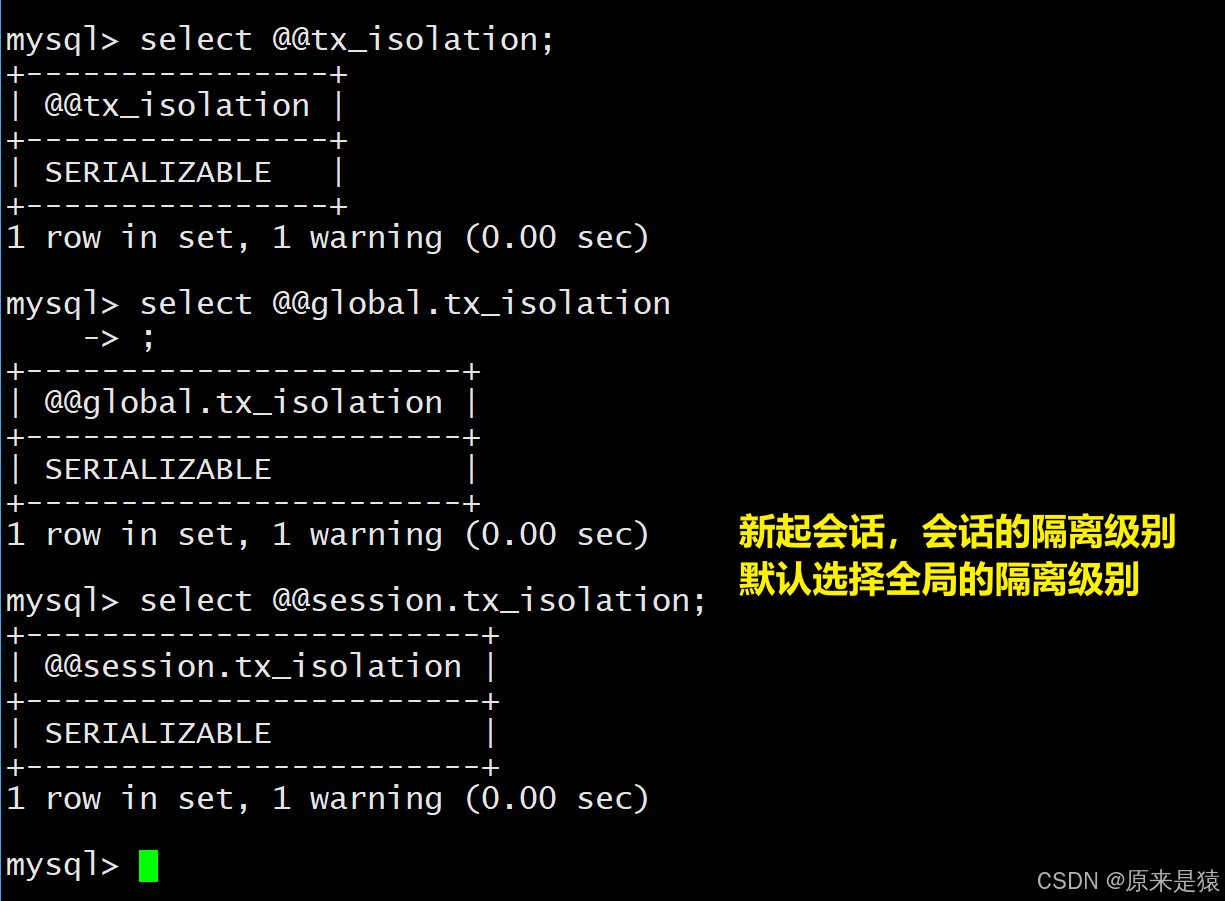
3.4 读未提交

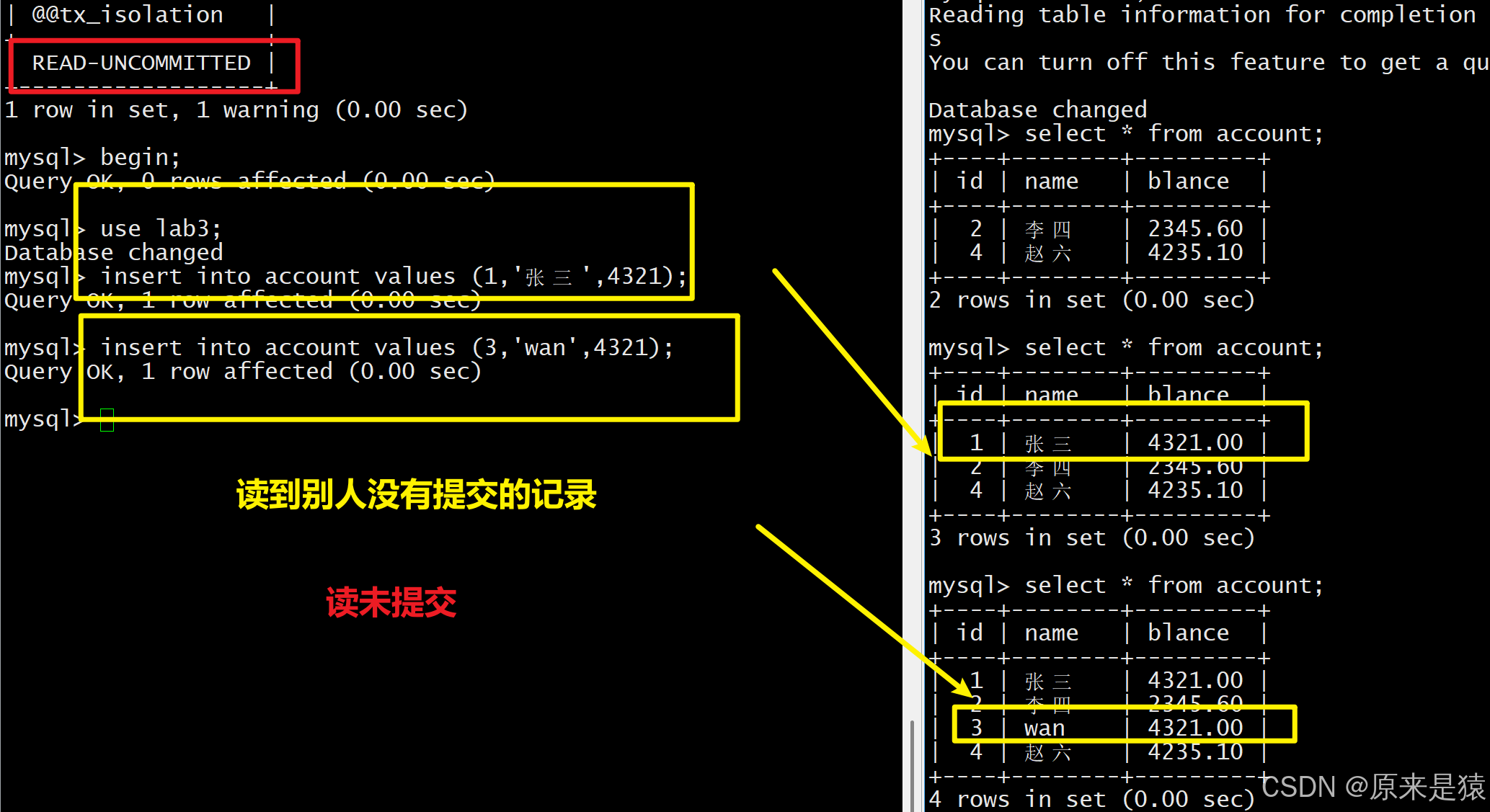

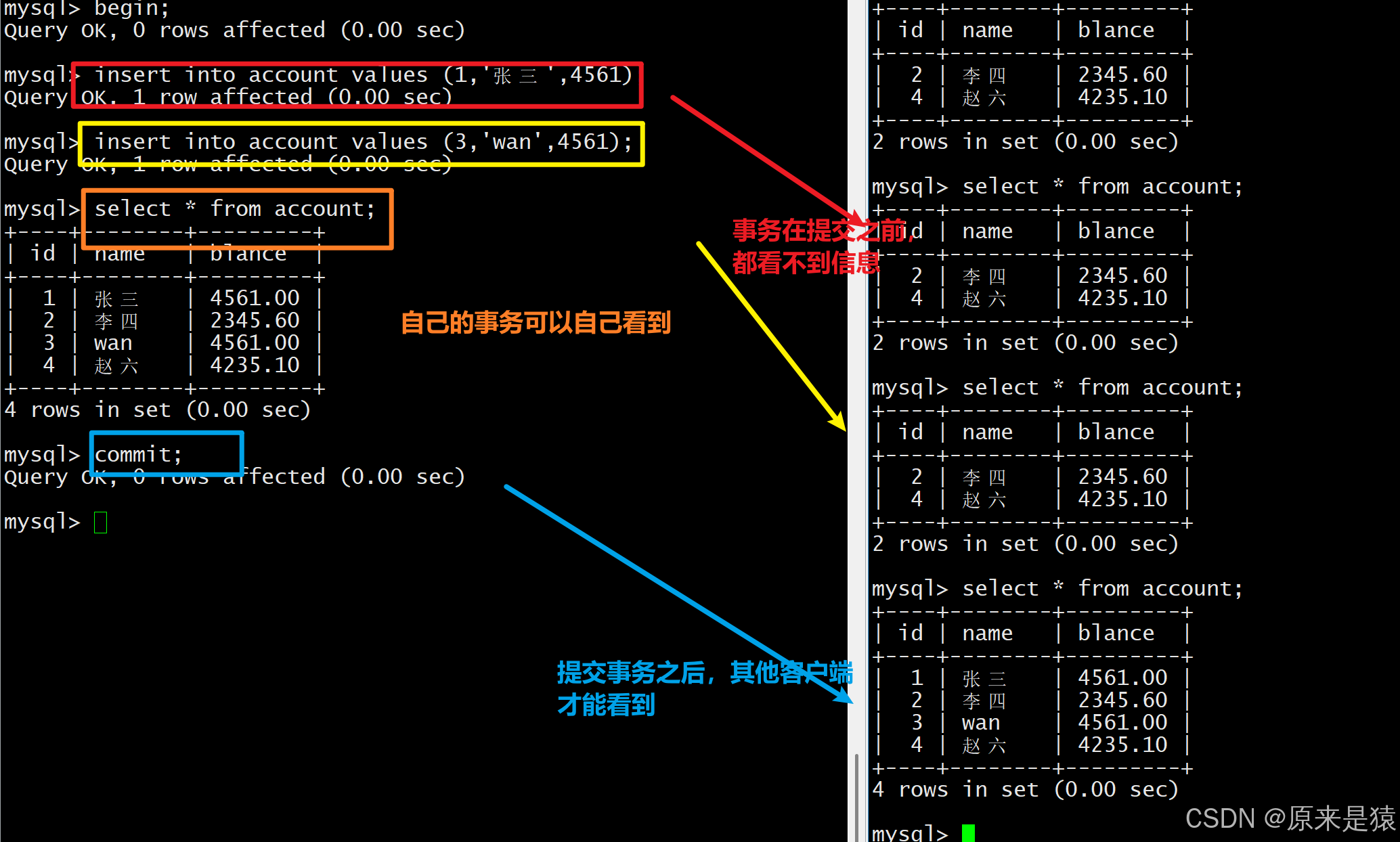
终端B读到了终端A未提交的数据,这就是脏读。如果终端A回滚,终端B读到的就是无效数据。
个事务在执行中,读到另一个执行中事务的更新 ( 或其他操作 ) 但是未 commit 的数据,这种现象叫做脏读 (dirty read)
一个事务读到另一个事务未提交的数据。
- 读未提交级别会出现
- 对方回滚后,数据变成 "脏数据"
3.2 读提交
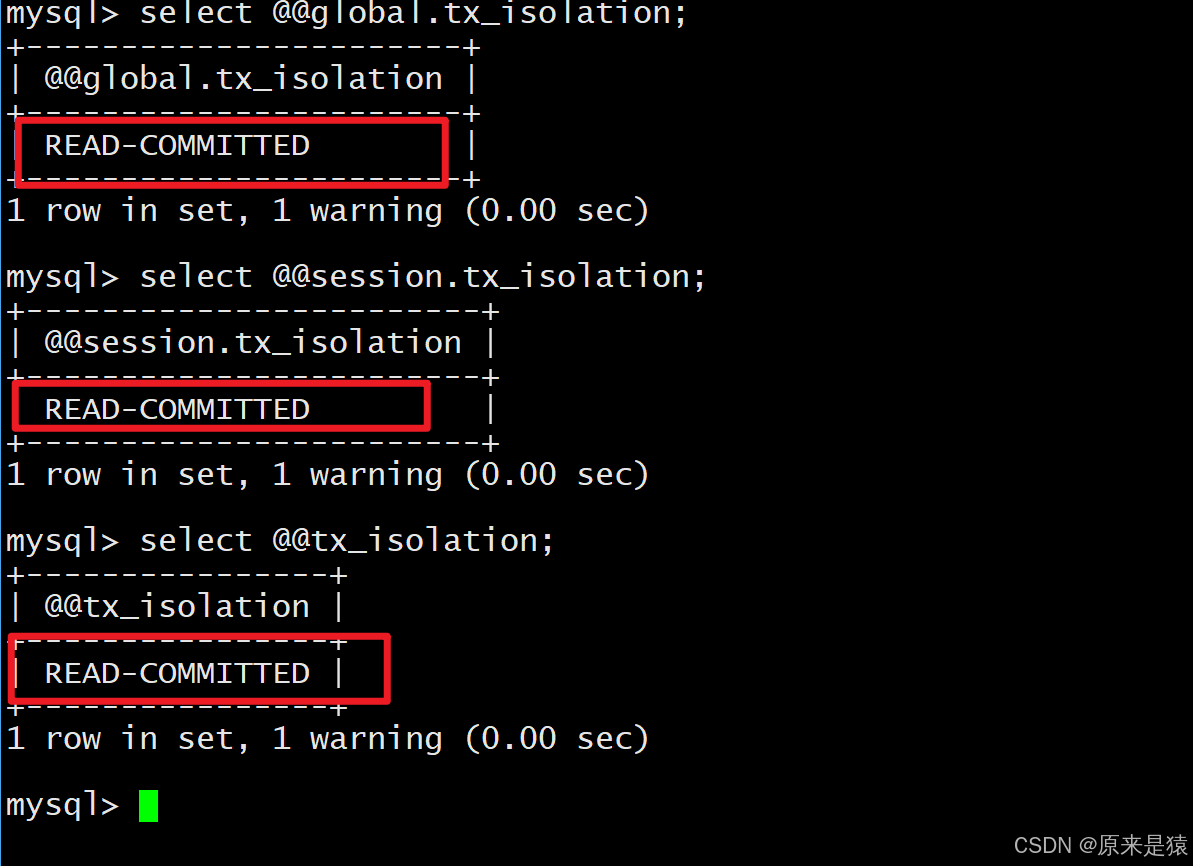
在同一个事务B中,两次查询得到不同结果,这就是不可重复读。因为事务A提交了修改,事务B每次读都是当前已提交的数据。
- 终端 A commit 之后,才可以看到对应CURD的记录!
- but ,此时还在当前事务中,并未 commit,那么就造成了,同一个事务内,同样的读取,在不同的时间段 (依旧还在事务操作中! ) ,读取到了不同的值,这种现象叫做不可重复读 (non reapeatable read) !!
同一事务内,多次查询结果不同(其他事务修改了数据)。
- 读已提交级别会出现
- 针对
update/delete操作
不可重复读,这是一个问题吗 ?数据修改了 , 我就要同步显示 , 这有问题的吗 ?我举一个场景进行说明 :比如一个公司的一个职员,接受了一个任务,就是统计在每一个薪资区间的职员,因为要年底了,要发一些福利 , 而不同的薪资区间对应的奉献度不同 , 福利也不同。
- 小张 :开启了一个事务,正在分区间统计员工薪资(
[1000,2000)、[2000,3000)...) - 小王:在小张事务执行过程中,修改了 Tom 的薪资并提交
- 数据库隔离级别:READ COMMITTED(读已提交)
1. 初始数据
员工薪资表:
| 名字 | 薪资 |
|---|---|
| ... | 1000 |
| ... | 2000 |
| Tom | 3200 |
| ... | 8900 |
| ... | 4300 |
Tom 初始薪资是 3200 ,属于 [3000,4000) 区间。
2. 小张的事务执行顺序
-- 小张开启事务
BEGIN;
-- 第一次查询:[1000,2000) → 结果正常
SELECT name FROM emp WHERE sal>=1000 AND sal<2000;
-- 第二次查询:[2000,3000) → 结果正常
SELECT name FROM emp WHERE sal>=2000 AND sal<3000;
-- 第三次查询:[3000,4000) → 查到 Tom(sal=3200)
SELECT name FROM emp WHERE sal>=3000 AND sal<4000;
-- ⚠️ 此时小王介入:修改 Tom 薪资为 4500 并提交
-- 小王的操作:
-- BEGIN;
-- UPDATE emp SET sal=4500 WHERE name='tom';
-- COMMIT;
-- 小张继续第四次查询:[4000,5000) → 又查到了 Tom!(sal=4500)
SELECT name FROM emp WHERE sal>=4000 AND sal<5000;
-- 后续查询...
-- 小张提交事务
COMMIT;
- 规则:每次 SELECT 都会看到其他事务已经提交的最新数据
- 后果:小张在同一个事务里,前后两次查询看到了 Tom 的不同状态 :
- 查
[3000,4000)时,Tom 在这个区间- 查
[4000,5000)时,Tom 又出现在这个区间这就导致:
- 小张原本想做「全区间统计」,结果同一个人被算到了两个不同区间
- 统计结果会出现逻辑错误(比如总人数会多算 1 次)
✅ 结论:不可重复读在业务统计场景下,就是典型的问题,会破坏数据一致性。