一、背景------重复劳动与命名混乱之痛
在建筑工程等行业,档案归档是一项高频的日常工作。每当一批项目日志截图或附件资料从各方汇集过来,运营人员往往需要面对以下几重困境:
C:\pythoncode\new\file_renamer.py
|------------|----------------------------------------------|
| 困境 | 具体表现 |
| 命名不统一 | 同一项目的文件可能叫「某路改造工程_截图」「某路截图0812」「某某路项目」等十余种变体 |
| 体量庞大 | 一批次往往数十至数百个文件,人工逐一比对极易出错 |
| 状态难追踪 | 已收到哪些项目的资料,需要在 Excel 台账中手动勾选,极易遗漏 |
| 压缩包乱码 | Windows 下打包的 zip 文件,在其他系统解压后中文文件名变成乱码 |
| 预览不便 | 确认文件内容需要逐一打开 Word/Excel,切换成本高 |
这些问题看似琐碎,却在实际工作中消耗了大量人力。一位熟练的运营人员每周可能要在这类重命名、核对、记录工作上花费 2--4 小时。而且手工操作极易出现「张冠李戴」------将 A 项目的文件错误归入 B 项目名下,造成档案混乱。
核心矛盾在于:文件名和项目名之间存在 语义上的相似性 ,但缺乏 字面上的精确匹配 。传统的字符串匹配无法处理缩写、错别字、拼音混用等情况,而大语言模型恰恰擅长这类语义理解任务。这正是本工具诞生的起点。
二、目标------定义「好用」的边界
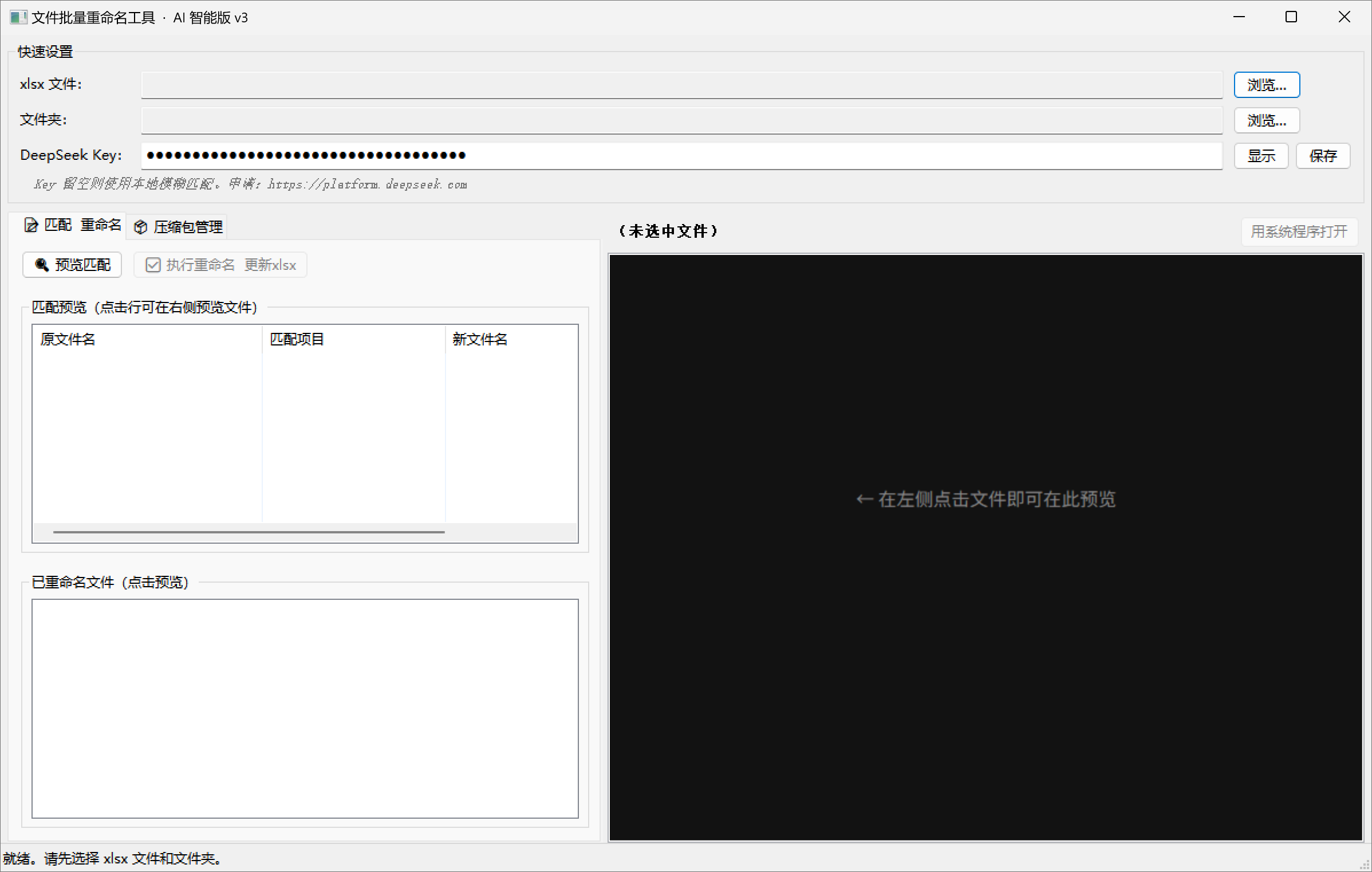
在开始编码之前,需要把「好用」具体化为可验证的功能目标。经过需求梳理,最终确定以下五大核心目标:
- 智能匹配:给定 Excel 项目名称列表和文件夹,自动将每个文件匹配到最可能的项目
- 批量重命名:按统一格式「项目名称_2025年下半年日志截图.原后缀」重命名
- 状态回写:匹配成功后在 Excel 的「是否收到」列自动填写「已收到」
- 内嵌预览:单击文件列表即可在右侧面板预览 Word 文档和 Excel 表格内容
- 压缩包管理:列出文件夹内所有压缩包,树状展示内部结构,支持中文文件名无损解压
在技术选型上,同样有明确约束:
- 界面框架:wxPython(跨平台原生 GUI,无需安装浏览器依赖)
- AI 匹配:DeepSeek API(推理能力强,成本低,支持中文语义理解)
- 降级保障:无 API Key 时自动切换三级本地模糊匹配,保证离线可用
- 零数据库:所有状态存于内存或原始文件,不引入额外存储依赖
|--------------------------------------------------------------------|
| �� 设计原则 「能本地解决的不联网,能自动化的不手动,能实时反馈的不延迟」------这三条原则贯穿整个设计过程。 |
三、方法------架构设计与核心技术
3.1 整体架构
程序按「数据层 → 逻辑层 → 表现层」三层组织,共约 1100 行代码:
|------------|-------------------------------------------------------------------|
| 层级 | 组成模块与职责 |
| 数据层 | xlsx 读写(pandas + openpyxl)、压缩包解析(zipfile + tarfile)、本地配置(JSON) |
| 逻辑层 | 本地三级模糊匹配、DeepSeek API 批量调用、zip 中文文件名编码修正 |
| 表现层 | MainFrame 主窗口、PreviewPanel 预览面板、ArchiveDlg 压缩包浏览器、ProgressDlg 进度框 |
主窗口采用「顶部设置栏 + 左侧 Notebook + 右侧预览」的经典三区布局,以 wx.SplitterWindow 实现左右可拖拽分割,用户可以根据屏幕宽度自由调整预览区大小。
3.2 匹配引擎:三级本地 + AI 双轨并行
匹配是整个工具的核心难题。程序实现了「双轨并行」策略:
轨道一:本地三级模糊匹配
当用户未配置 DeepSeek API Key 时,程序依次尝试三种匹配策略,命中即止:
|-----------------|------------------------------------------------------------|
| 级别 | 策略说明 |
| 第一级:直接包含 | 文件名(去后缀)normalize 后是否包含项目名称;多个命中取最长者,避免短名称误匹配 |
| 第二级:去标点包含 | 用正则去除空格、连字符、括号等标点后再做包含判断,处理「某-路(改造)」→「某路改造」的情形 |
| 第三级:difflib 相似度 | 使用 Python 内置 difflib.get_close_matches,相似度阈值 0.6,兜底处理轻微错别字 |
其中 normalize 函数是一个关键的预处理步骤,它将全角字符(A~Z、0~9等)统一转为半角,确保「A工程」和「A工程」能够匹配:
def normalize(text: str) -> str:
for ch in str(text).strip():
cp = ord(ch)
if 0xFF01 <= cp <= 0xFF5E: # 全角区间
result.append(chr(cp - 0xFEE0)) # 转半角
elif ch == '\u3000':
result.append(' ') # 全角空格→半角
轨道二:DeepSeek AI 批量匹配
当用户提供了 API Key,程序将所有文件名和项目名称列表一起提交给 DeepSeek,由大模型做语义级别的模糊匹配。这能处理本地规则完全无法覆盖的情形,例如:
- 拼音缩写:「HJLGC」→「环境路工程」
- 同音字替换:「某路改在工程」→「某路改造工程」
- 顺序调换:「截图2025改造某路」→「某路改造工程」
为防止单次请求超出 token 限制,程序以 BATCH_SIZE=30 为单位分批发送。提示词(Prompt)被精心设计为结构化指令,要求模型只返回 JSON,不含任何 Markdown 格式:
你是文件命名匹配助手。规则:
-
允许错别字、缩写、拼音、顺序调换,做语义模糊匹配
-
无法匹配则返回 null
-
只返回 JSON,不含任何 Markdown 或解释
模型返回后,程序还会做一道校验:只接受返回值在原始项目名称集合中的结果,防止模型「幻觉」出一个不存在的项目名。
|--------------------------------------------------------------------------------------------------------------------------------------------|
| �� 降级保护 若 DeepSeek API 调用失败(网络超时、Key 无效等),程序不会直接报错退出,而是弹出确认框,询问用户是否降级使用本地模糊匹配继续执行。整个流程在后台线程中运行,通过 wx.CallAfter 回到主线程更新 UI,不阻塞界面响应。 |
3.3 zip 中文文件名乱码修正
这是一个在中文 Windows 环境下极为普遍、却鲜有工具妥善处理的问题。根本原因在于 zip 文件的历史遗留设计:
- zip 规范(PKWARE APPNOTE)中,文件名编码原本默认为 CP437(IBM PC 字符集)
- Windows 下的压缩软件通常用 GBK/GB18030 编码写入文件名,但不设置 UTF-8 标志位(flag_bits bit 11)
- Python 的 zipfile 模块在遇到非 UTF-8 标志的文件名时,统一用 CP437 解码,导致中文变乱码
本工具的修正策略是:
- 检测 flag_bits bit 11,若已设置则文件名为合法 UTF-8,直接使用
- 否则将 zipfile 解析到的 CP437 字符串重新编码为原始字节
- 依次尝试 UTF-8 → GBK → GB18030 → latin-1 解码,首个成功的结果即为正确文件名
- 解压时完全绕开 zipfile 的文件名处理:手动读取字节数据,按修正后的文件名写出到目标路径
def _fix_zip_name(raw: str, flag_bits: int) -> str:
if flag_bits & 0x800: # 已是 UTF-8
return raw
encoded = raw.encode('cp437') # 还原原始字节
for enc in ('utf-8', 'gbk', 'gb18030', 'latin-1'):
try: return encoded.decode(enc)
except UnicodeDecodeError: continue
return raw # 兜底
3.4 内嵌预览:文档 → HTML → 渲染器
内嵌预览的技术路径是:将 Word/Excel 解析为 HTML 字符串,再交给界面渲染器显示。这样既避免了嵌入 Office COM 控件的复杂性,又能在所有平台运行。
Word 预览(word_to_html)
通过 python-docx 逐段解析 Word 文档:
- 段落样式:Heading 1/2/3 映射为 <h1>/<h2>/<h3>
- 行内格式:逐 Run 检查 bold/italic 属性,输出 <strong>/<em> 标签
- 表格:嵌套遍历 tbl.rows → row.cells,输出带样式的 HTML 表格
- 特殊字符:全部通过 html.escape() 转义,防止 XSS
Excel 预览(excel_to_html)
通过 pandas 读取所有 Sheet:
- 多 Sheet 支持:每个 Sheet 输出一个带蓝色下划线标题的 HTML 表格段
- 交替行色:CSS nth-child(even) 实现斑马纹,提升可读性
- dtype=str:强制以字符串读取,避免数字/日期格式丢失
渲染器选择
|------------------------|---------------------------------------------------|
| 渲染器 | 适用情况 |
| wx.html2.WebView(优先) | 支持现代 CSS(flex、nth-child 等),渲染效果好;启动时尝试实例化测试,失败则降级 |
| wx.html.HtmlWindow(降级) | 内置于 wxPython,无额外依赖,但仅支持 HTML 3.2 子集,样式较简单 |
四、过程------关键实现细节
4.1 xlsx 的智能列定位
真实世界的 Excel 台账格式千变万化:标题行可能在第 1 行、第 2 行,「项目名称」列可能叫「项目」「工程名称」「建设单位」,「是否收到」列可能叫「收件情况」「接收状态」等。
find_columns() 函数用正则表达式扫描前 5 行、所有列,通过关键词模式自动定位这两列:
if re.search(r"项目|工程|名称|单位", v) and proj_col < 0:
proj_col = col_idx
if re.search(r"是否收到|收到|收件|接收", v) and recv_col < 0:
recv_col = col_idx
定位结果以字典形式保存(sheet 名、列索引、标题行号),供后续读写操作复用,避免每次操作都重新扫描文件。
write_received() 在写入前同样使用 normalize() 对项目名称做全半角统一,再与 Excel 单元格中的值做精确比较,确保不会写错行:
norm_t = normalize(project_name)
for row in ws.iter_rows(min_row=hrow):
cell_val = rowp_col - 1.value
if cell_val and normalize(str(cell_val)) == norm_t:
rowr_col - 1.value = '已收到'
wb.save(xlsx_path)
return True
4.2 线程安全与 UI 响应
DeepSeek API 调用可能需要数十秒。若在主线程中同步调用,界面会完全冻结。程序使用 threading.Thread 将 API 调用放入后台线程,并通过 wx.CallAfter 将结果回传到主线程更新 UI:
def worker():
try:
container'data' = deepseek_match_all(...)
except Exception as e:
container'error' = str(e)
finally:
wx.CallAfter(prog.tick, len(files)) # 安全更新进度条
wx.CallAfter(self._ai_done, ...) # 安全回调主线程
这里有一个细节值得注意:
进度对话框(ProgressDlg)使用 ShowModal() 阻塞当前线程,但 wxPython 的事件循环仍在运行,因此 wx.CallAfter 投递的更新函数能够正常执行,进度条可以实时刷新。当 done >= total 时,EndModal() 被调用,对话框关闭,主流程继续。
4.3 压缩包树状结构的构建
压缩包内部是一个扁平的路径列表(如 'a/b/c.txt', 'a/d.txt'),需要将其还原为树形结构显示在 wx.TreeCtrl 中。
_fill_tree() 方法的核心思路是「前缀树(Trie)」:
- 按字母顺序遍历所有路径
- 将每个路径按「/」分割为部分(parts)
- 逐层检查节点字典(nodes),若不存在则在父节点下创建新的 TreeCtrl 节点
- 只有叶节点(文件)才在 SetItemData 中存储 (display_name, raw_key) 元组
- 目录节点的 ItemData 为 None,点击时禁用「解压选中文件」按钮
通过 isinstance(data, tuple) 判断节点类型,比用字符串标记更简洁、也更 Pythonic。
4.4 用户体验细节
以下几处细节在开发过程中经历了反复打磨:
|------------------|---------------------------------------------------------------------------|
| 问题 | 解决方案 |
| API Key 明文显示安全风险 | ToggleButton 切换 wx.TE_PASSWORD 样式;Key 仅保存在本机 ~/.file_renamer_config.json |
| 文件夹选定后压缩包列表未刷新 | on_choose_folder 末尾调用 _refresh_arc_list(),选定即刷新 |
| 匹配预览显示旧文件名 | 单击列表时优先检测改名后的路径是否存在,再检测原路径 |
| 重命名冲突(两文件匹配同一项目) | 执行前用 Counter 检测新文件名重复,有冲突则中止并弹窗说明 |
| xlsx 未找到「是否收到」列 | 不报错,仅在状态栏提示「将跳过更新」,重命名流程正常进行 |
五、结果------程序功能演示
5.1 完整操作流程
最终程序的操作流程极为简洁,从启动到完成只需五步:
|-----------------|------------------------------------------|
| 步骤 | 操作说明 |
| ① 选 xlsx | 点击「浏览...」选择含项目名称的 Excel 台账,程序自动定位「是否收到」列 |
| ② 选文件夹 | 选择含待重命名文件的文件夹,压缩包列表同步刷新 |
| ③ 填 API Key(可选) | 填入 DeepSeek Key 并保存,留空则用本地三级匹配 |
| ④ 点「预览匹配」 | AI 或本地引擎运行,右侧列表显示「原文件名 → 新文件名」,可单击预览内容 |
| ⑤ 点「执行重命名」 | 批量重命名 + xlsx 状态回写,完成后下方列表刷新,单击可再次预览 |
5.2 各模块效果
AI 匹配效果对比
|--------------------------|----------------|
| 原始文件名 | 匹配项目名称 |
| 某路(2025)改造-截图0812.png | 某路改造工程 |
| HJLGC_日志_8月.xlsx | 环境路改造工程 |
| 某某市政道路_log截图(审定稿).docx | 某某市政道路改造项目 |
| 20250801_某路工程_施工日志截图.jpg | 某路改造工程 |
压缩包解压效果
以一个含中文文件名的 zip 为例,解压前后对比:
|-----------------|---------------------------------------|
| 对比项 | 说明 |
| 系统 unzip / 旧版程序 | 解压后文件名显示为「鏌愯矾鏀规棗宸ョ▼_鏃ュ織.docx」(乱码) |
| 本工具 | 解压后文件名正确显示「某路改造工程_日志.docx」,四级编码探测成功修正 |
Word/Excel 内嵌预览
- Word:Heading 1/2/3 自动渲染为不同级别标题,加粗/斜体保留,表格完整显示
- Excel:多 Sheet 分段展示,斑马纹行色,表头蓝色底色,视觉层次清晰
- 其他格式(jpg、png 等):显示文件大小信息,提示用系统程序打开
5.3 性能指标
|--------------------------|-----------------------|
| 指标 | 实测数据 |
| 本地三级匹配(50个文件) | < 0.1 秒 |
| DeepSeek AI 匹配(50个文件,1批) | 约 8--15 秒(取决于网络和模型负载) |
| xlsx 读取(200行台账) | < 0.5 秒 |
| Word 预览渲染(20页文档) | 约 1--2 秒 |
| zip 解压修正(100个文件) | < 2 秒 |
六、总结------经验与展望
6.1 技术收获
这次开发过程带来了几个值得沉淀的技术认知:
认知一:大模型最适合做「语义桥梁」
本地规则匹配(包含、去标点、difflib)能覆盖约 70% 的情形,但剩余 30% 的拼音缩写、同音替换、顺序调换,规则越加越复杂,维护成本极高。将这部分交给 DeepSeek,用一段精心设计的 Prompt 即可解决,代码量反而更少,效果更好。这是「规则 + AI」双轨架构的典型价值体现。
认知二:编码问题要溯源而非绕过
zip 中文乱码的修复,关键是理解 zipfile 模块的底层行为:它默认以 CP437 解析文件名字节。一旦理解了这一点,修复方案就变得清晰:重新编码为字节,再用正确的字符集解码。绕过(直接用 extractall)会掩盖问题,溯源才能彻底解决。
认知三:wxPython 线程安全必须通过 wx.CallAfter
wxPython 的 GUI 元素只能在主线程中操作。任何在子线程中直接调用 SetLabel()、Gauge.SetValue() 等方法都可能导致崩溃或死锁。wx.CallAfter 是官方推荐的唯一安全跨线程通信方式,必须严格遵守。
认知四:「渐进增强」的降级设计
WebView → HtmlWindow、AI 匹配 → 本地匹配、xlsx 有「是否收到」列 → 跳过更新......每个功能都有明确的降级路径。这使得工具在不同环境(无网络、无 Key、老版 wxPython)下都能保持核心功能可用,而不是直接崩溃或报错退出。
6.2 已知局限
- RAR 格式:RAR 使用私有格式,需要商业库(rarfile + unrar),本工具暂未集成
- doc 格式(旧版 Word):python-docx 不支持 .doc,需要先转换为 .docx
- 超大 Excel:pandas 读取内存占用较大,百万行以上的文件建议分块读取
- AI 幻觉风险:DeepSeek 偶尔会返回列表外的项目名,已通过集合校验拦截,但根本上依赖模型质量
6.3 后续可拓展的方向
- 支持子文件夹递归扫描:目前仅处理文件夹第一层文件
- 撤销功能:记录重命名日志,支持一键回滚
- PDF 预览:集成 pymupdf 渲染 PDF 首页缩略图
- 规则配置化:将「是否收到」→「已收到」等字段名做成可配置项,增强通用性
- 本地向量检索:将项目名称嵌入向量库,支持离线语义匹配,降低对 API 的依赖
── 全文完 ──