目录
- [1 Overview](#1 Overview)
- [2 线性模型](#2 线性模型)
- [3 梯度下降算法](#3 梯度下降算法)
- [4 反向传播](#4 反向传播)
- [5 使用 PyTorch 实现线性回归](#5 使用 PyTorch 实现线性回归)
- [6 逻辑斯蒂回归](#6 逻辑斯蒂回归)
- [7 处理多维特征的输入](#7 处理多维特征的输入)
- [8 加载数据集](#8 加载数据集)
- [9 多分类问题](#9 多分类问题)
- [10 卷积神经网络(基础篇)](#10 卷积神经网络(基础篇))
- [11 卷积神经网络(高级篇)](#11 卷积神经网络(高级篇))
最近学习了以下 bilibili 博主刘二大人的PyTorch深度学习实践教程,做成笔记方便回顾并且分享给大家。
1 Overview
1 监督学习
监督学习是指通过让机器学习大量带有标签的样本数据,训练出一个模型,并使该模型可以根据输入得到相应输出的过程。通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。
2 过拟合
过拟合:在训练集上测试正确度较高,在测试集上测试正确度较低。
3 泛化能力
泛化能力:是指机器学习算法对新鲜样本的适应能力。
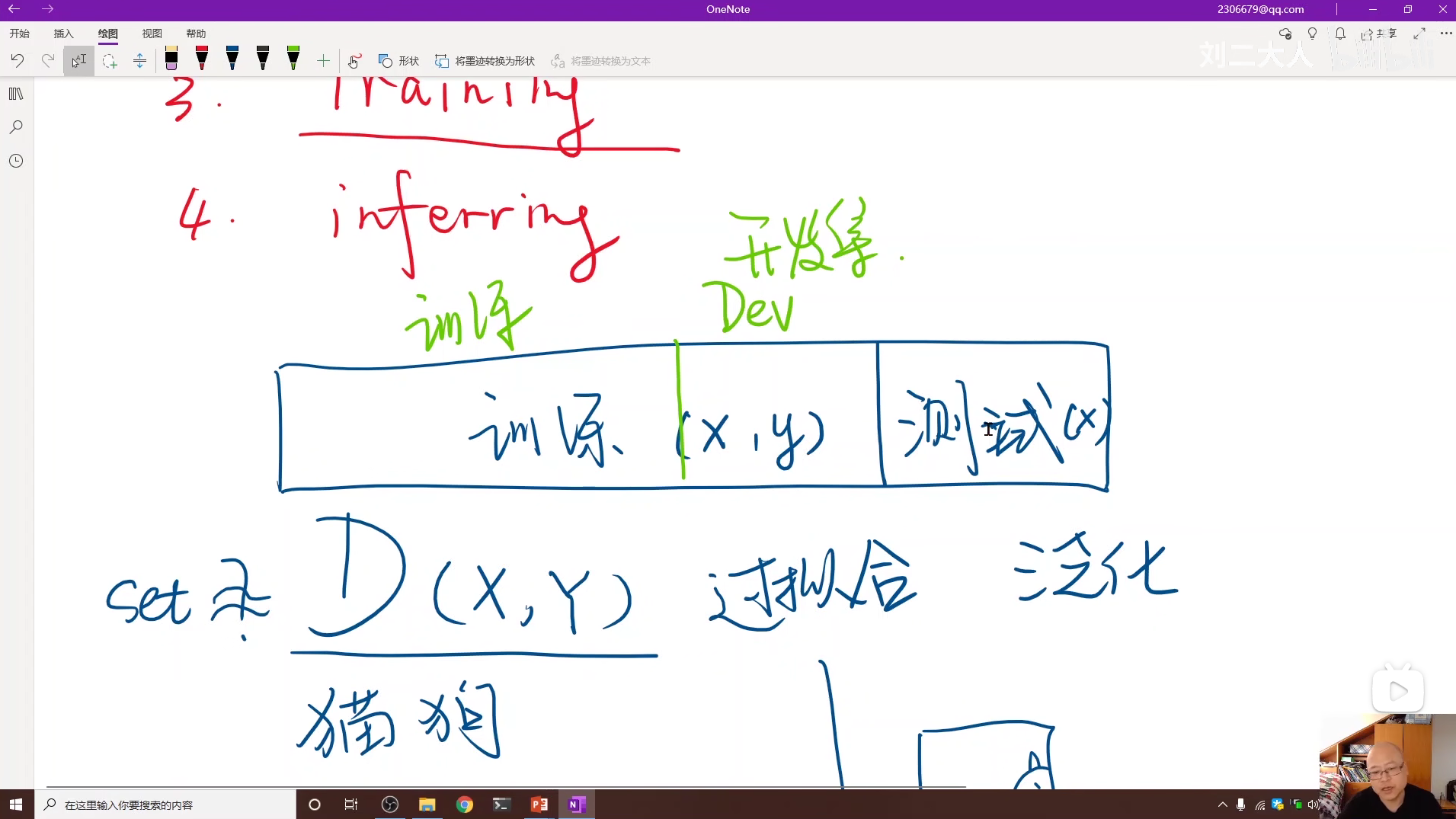
4 数据集的划分
将训练集中一部分分离出来用于评估。
5 损失函数
损失函数是针对一个样本的。而成本函数(平均平方误差)是针对于整个数据集的。

2 线性模型
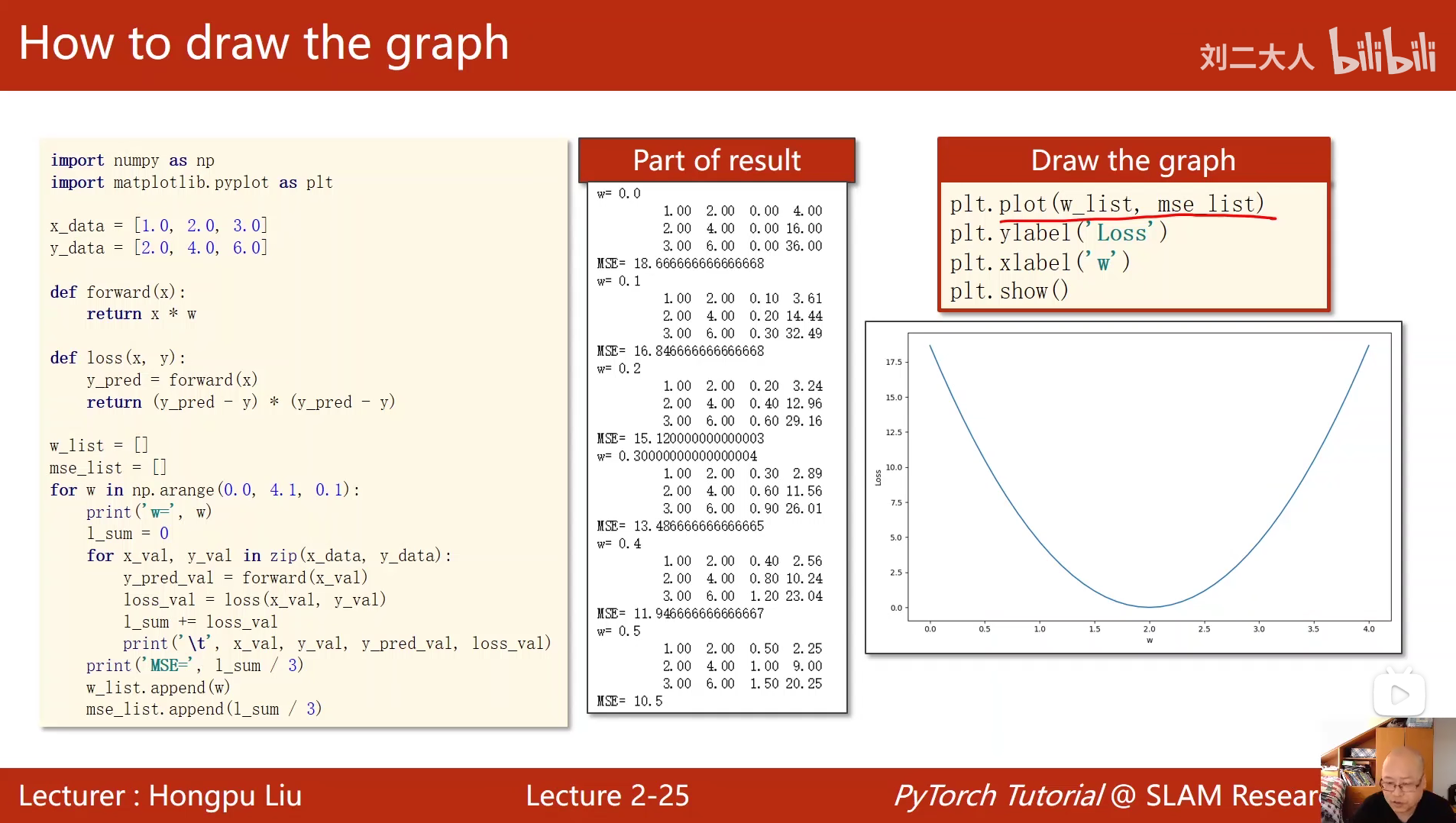
python
import numpy as np
import matplotlib.pyplot as plt
#定义数据集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
#定义前馈函数
def forward(x):
return x * w
#定义损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
#定义权重参数和对应平均平方误差
w_list = []
mse_list = []
#穷举不同权重
for w in np.arange(0.0, 4.1, 0.1):
print('w=', w)
l_sum = 0
#循环计算不同权重的损失值
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE=', l_sum / 3)
w_list.append(w)
mse_list.append(l_sum / 3)
#绘图
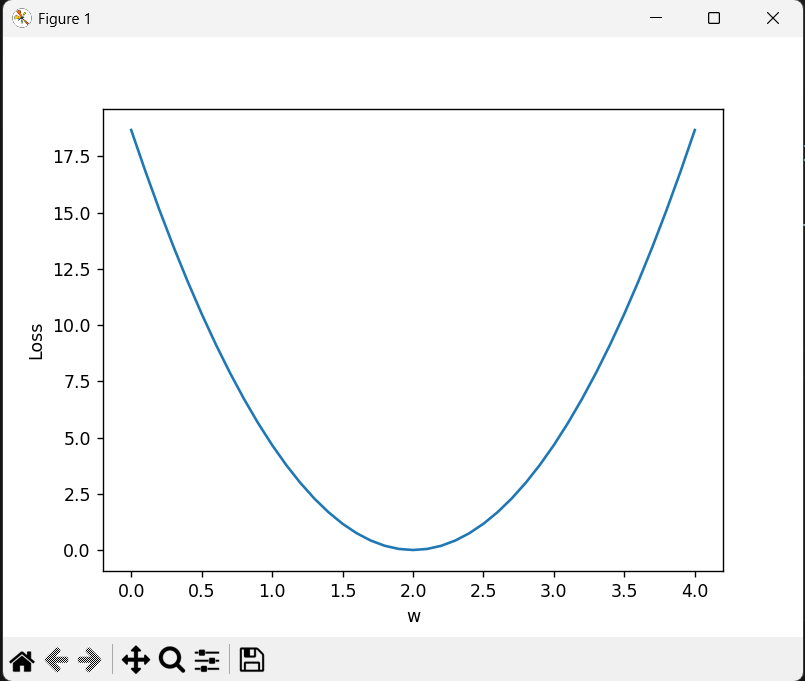
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
3 梯度下降算法
梯度下降算法,建立 cost 关于 参数 ω 的函数,求 cost 关于 ω 的偏导数,然后利用函数在 ω 的偏导数,不断对参数 ω 进行更新,以找到函数 cost 的最低点。
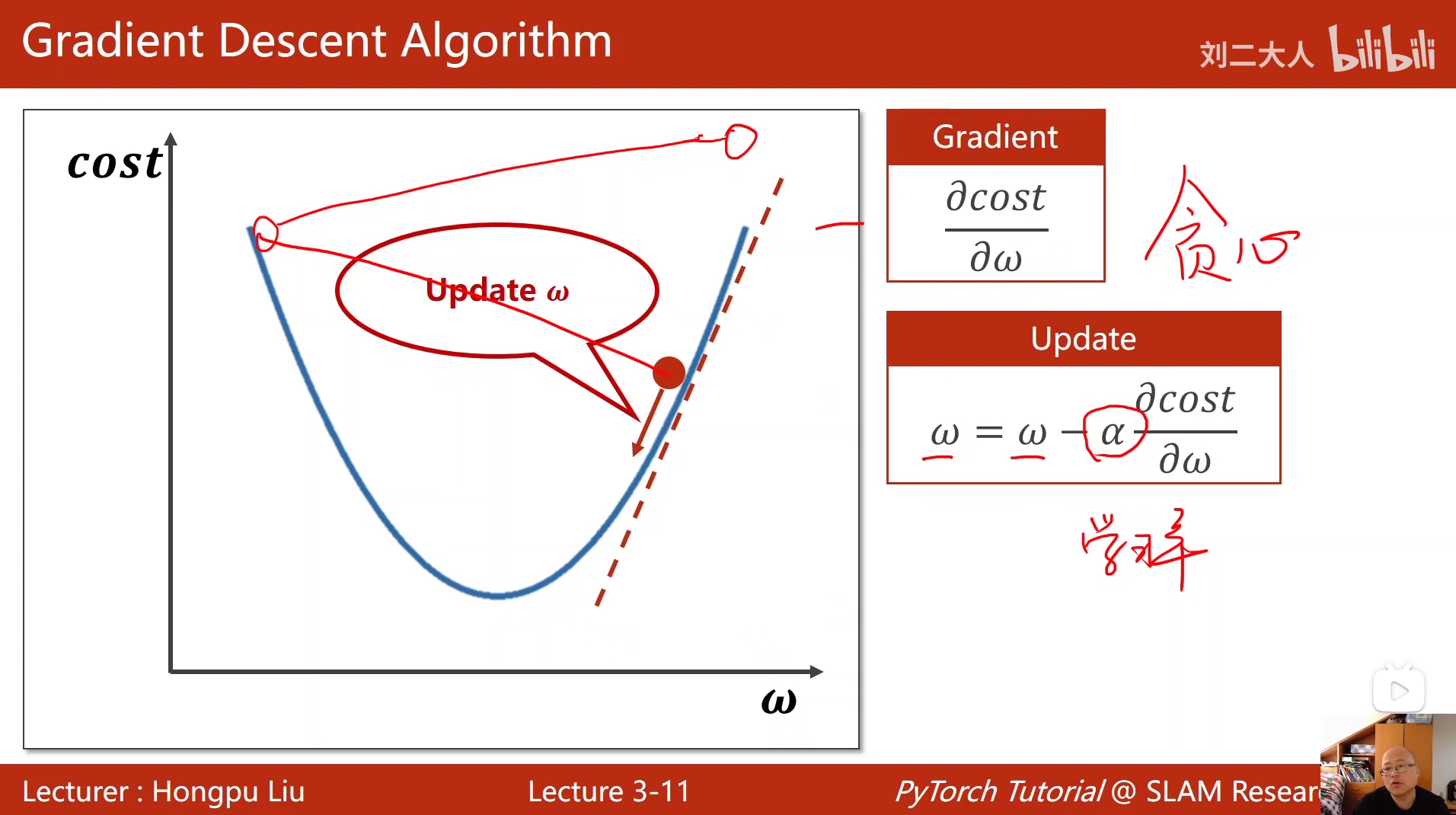
梯度下降 类似于从左右两边向最低点进行收敛,是一种贪心算法 ,所以有一个缺点就是只能找到局部最低点,找不到全局最低点。
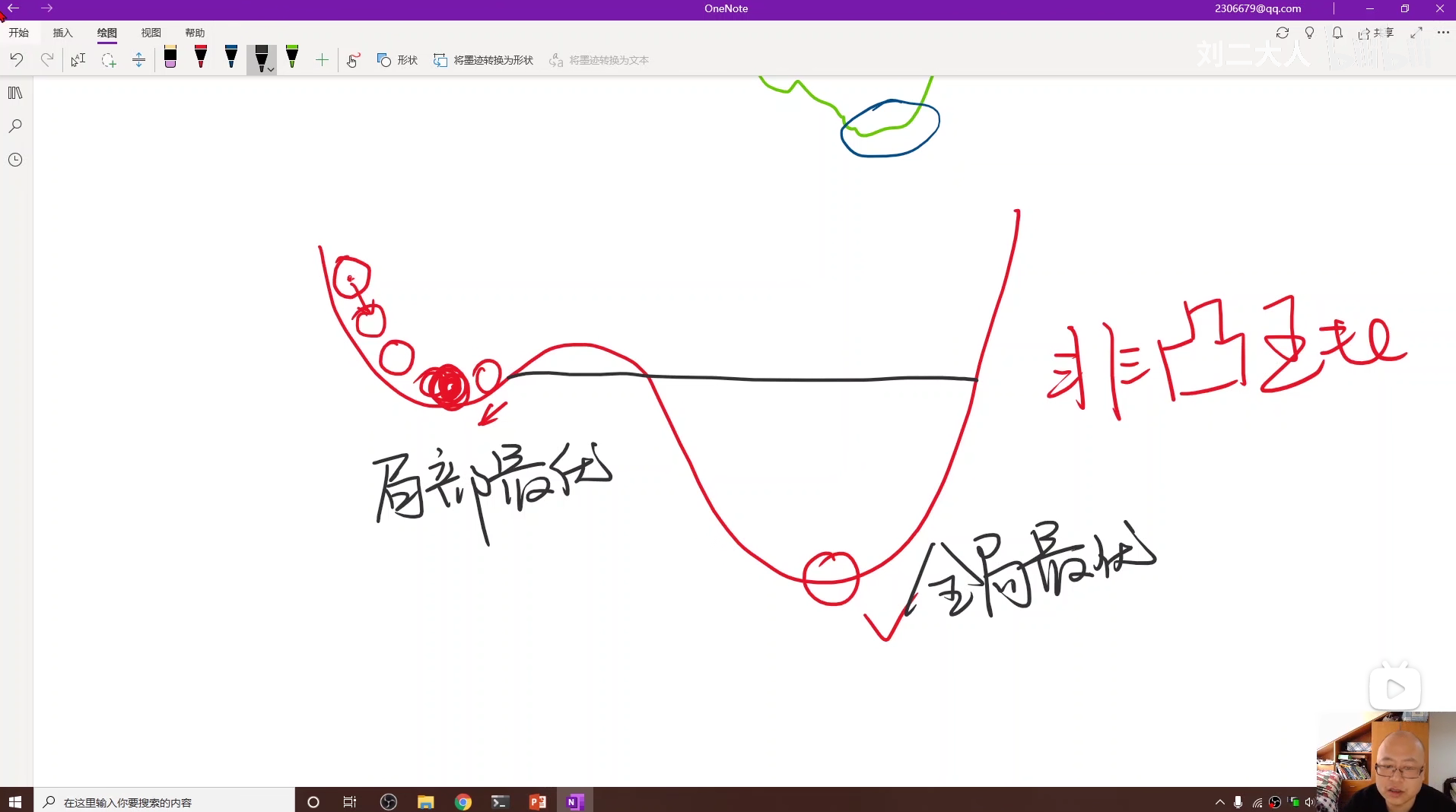
梯度下降还有一个缺点,就是不好解决鞍点问题。
第一种是图像是直线,这样的话偏导数为0,从而导致 ω 无法更新,算法就起不到迭代的效果。
第二种是对于类似马鞍面的多元函数,那么函数的最值既是最高点又是最低点。
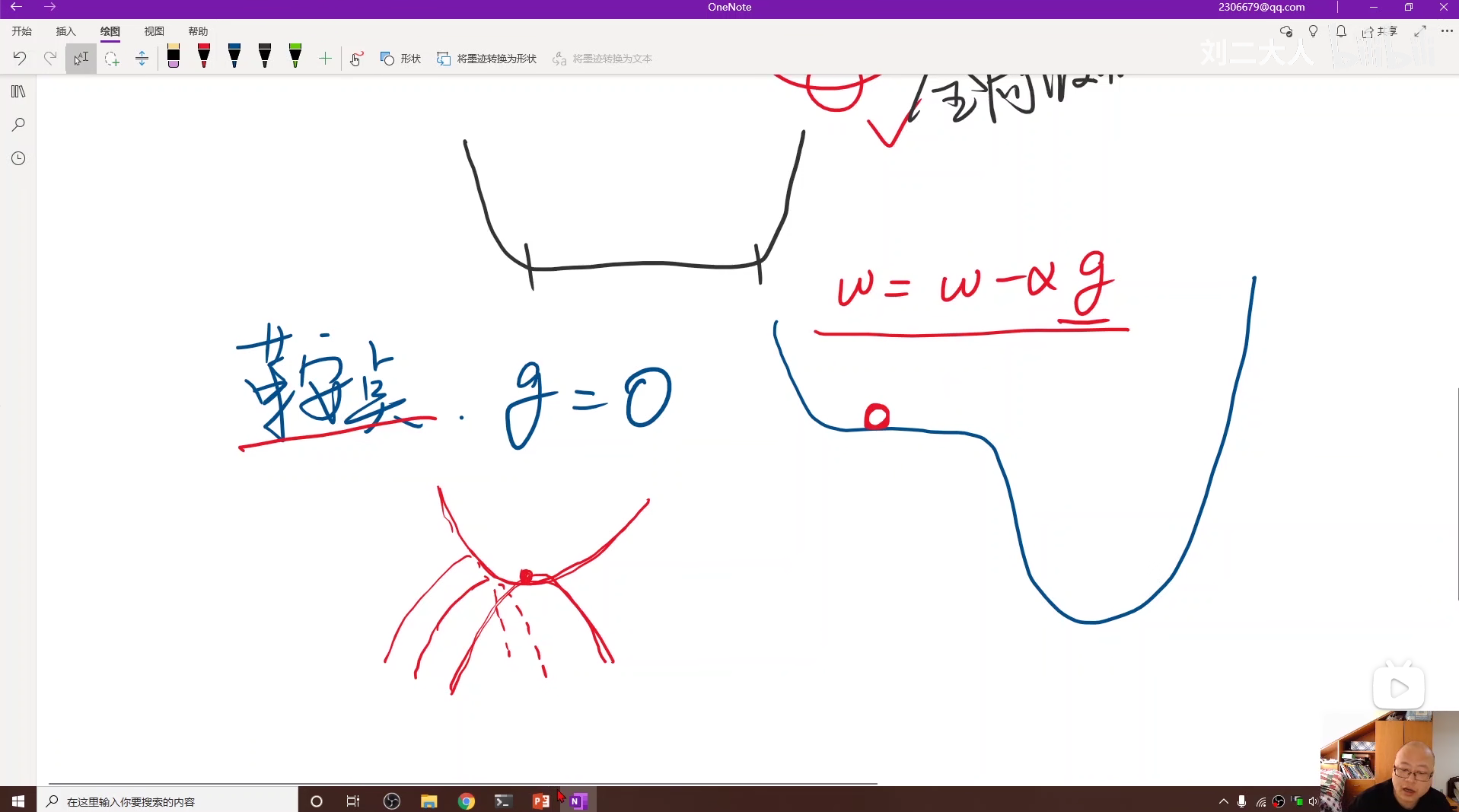


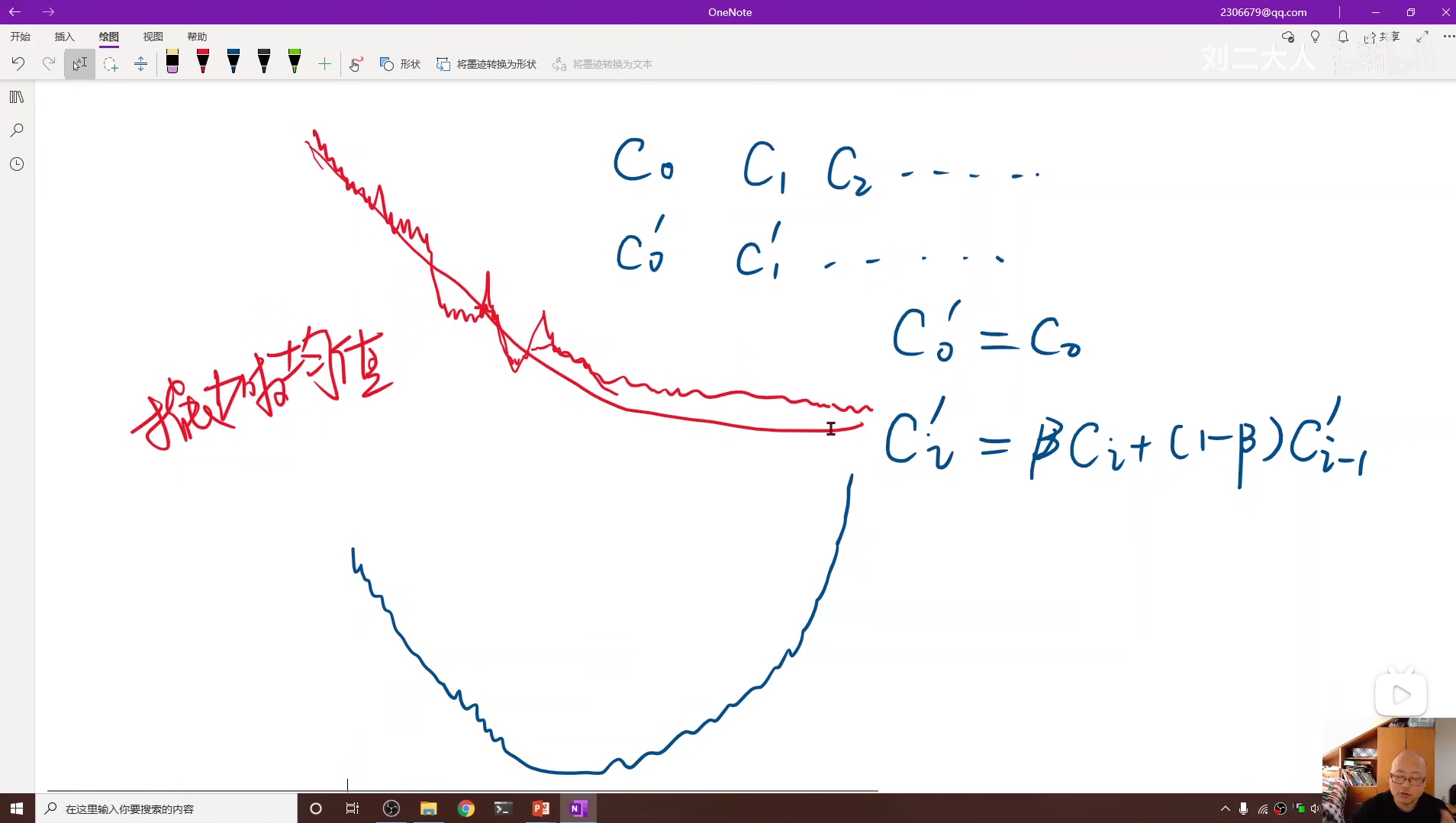
由于 cost 通常由于噪声的影响并不是平滑的,所以我们可以用求加权均值的方法让它的图像变平滑。
由于 cost 函数可能存在图像水平的鞍点,从而造成梯度下降不能正常收敛,所以我们引进随机梯度下降(SGD),这样可以利用训练数据的随机性去跨越鞍点。

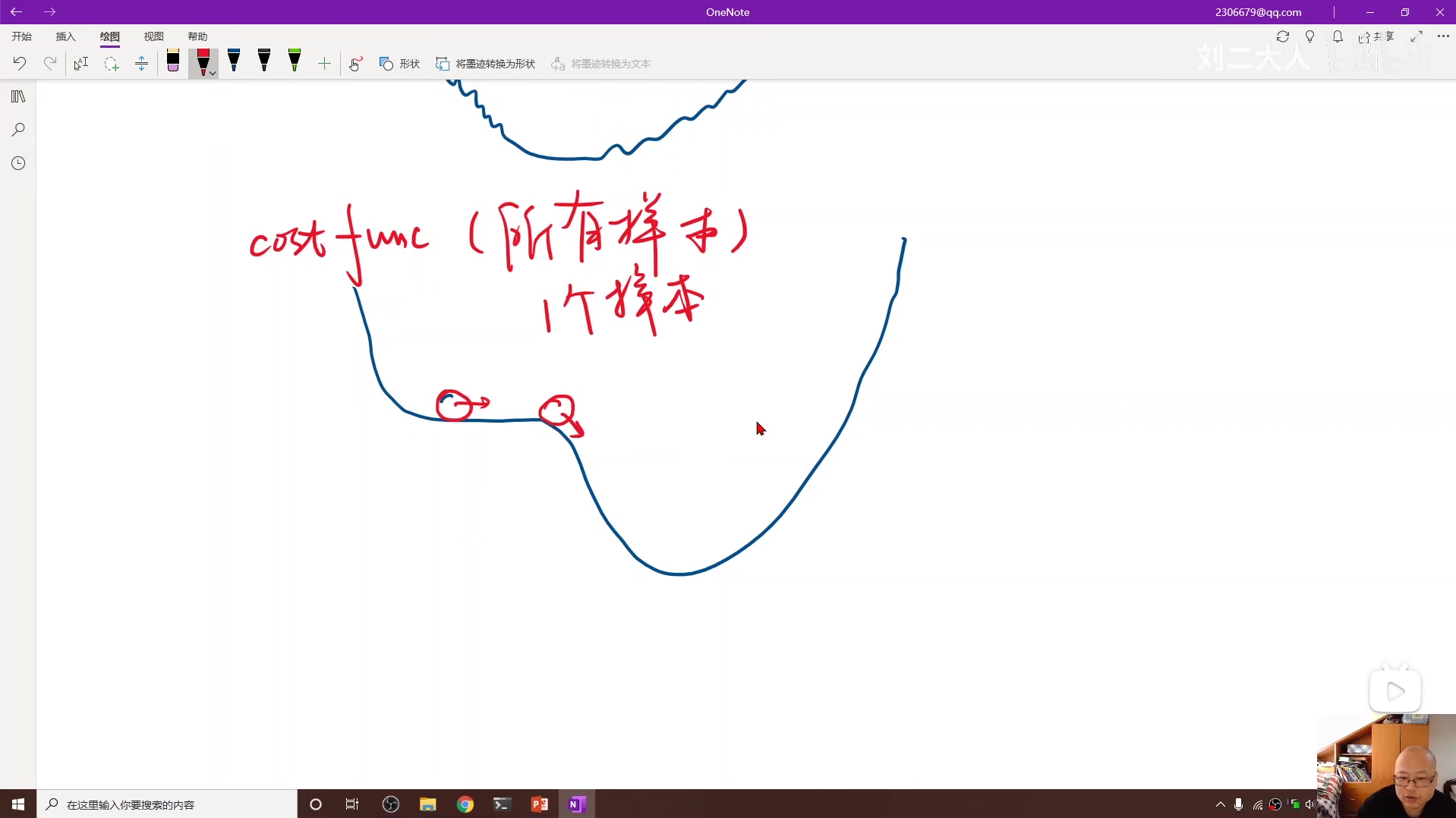
随机梯度下降不再在每轮的迭代中求平均梯度,平均损失,而是转化为在每次迭代中分别针对每个数据求梯度和损失。

在普通的梯度下降算法中,由于参数 ω 每次在一轮迭代完以后才更新,所以各个数据样本的梯度计算就无相关性,就可以实现并行计算以提高算法效率。
但是在随机梯度下降算法中,由于要对每个数据要求梯度并且更新,所以相邻数据的梯度计算就产生了相关,所以不能采用并行计算,这就造成了算法效率的低下。
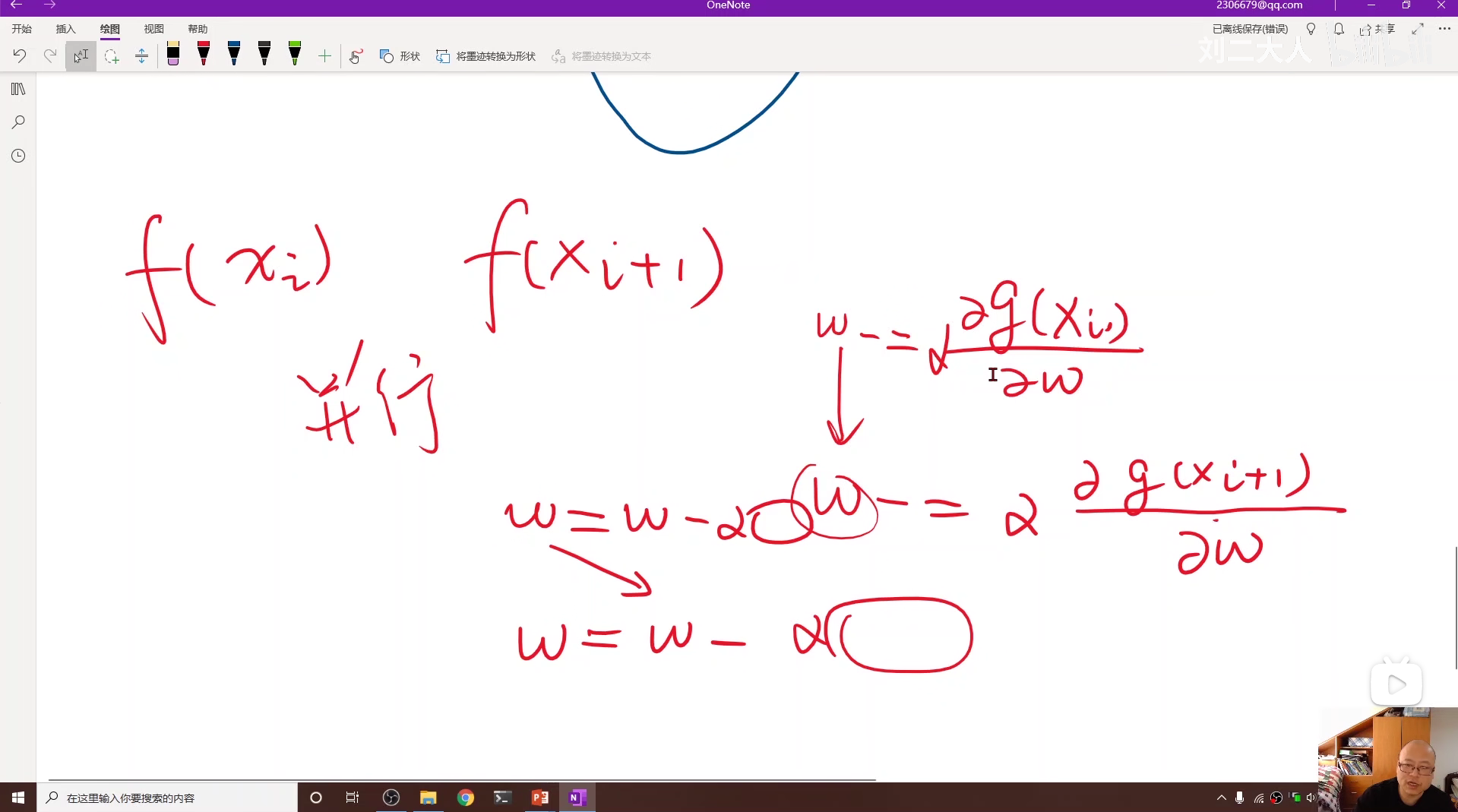
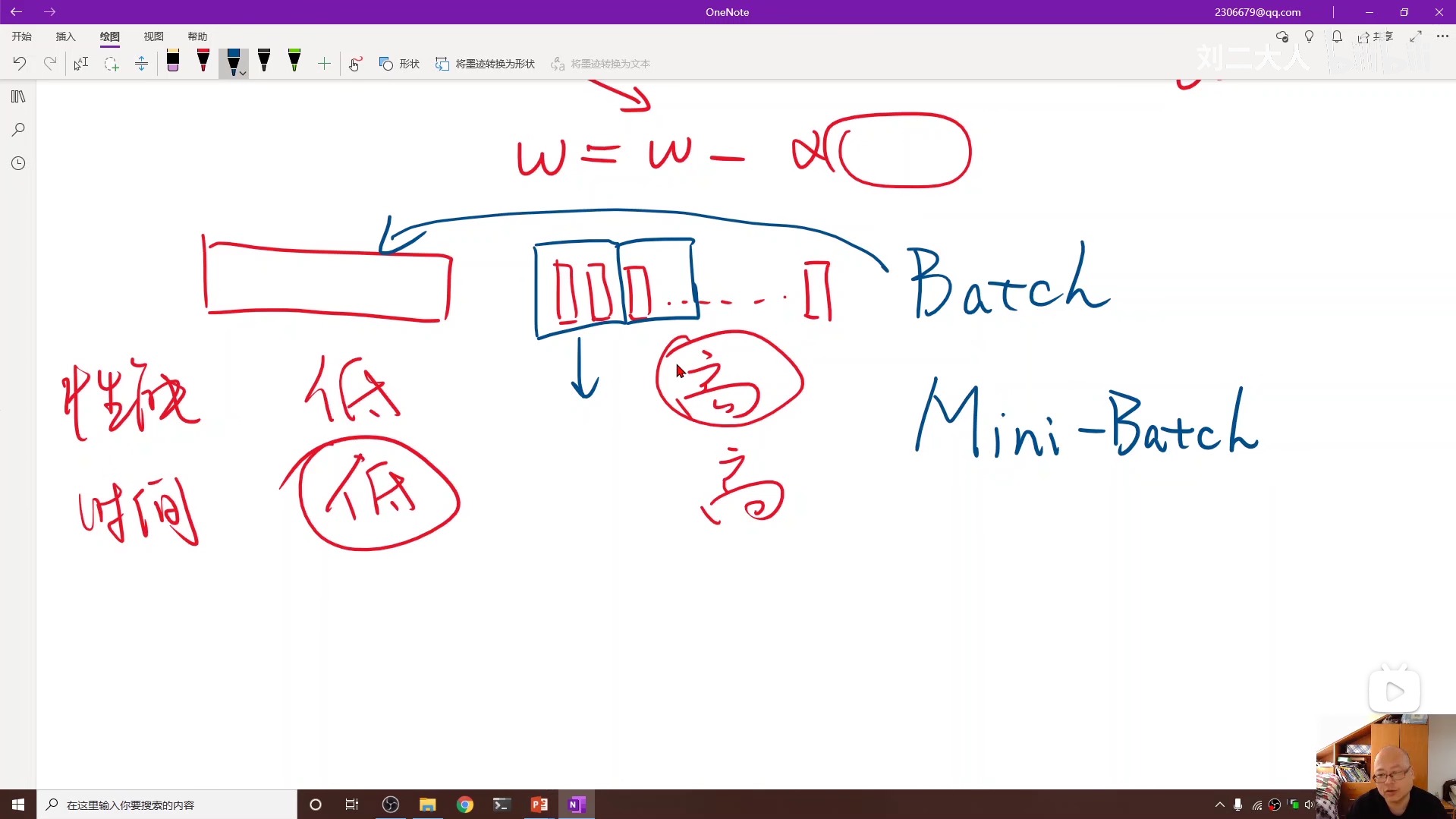
针对以上问题,我们可以将随机梯度下降进行改进,对数据进行相邻分组,然后分组中采用普通梯度下降,分组间采用随机梯度下降,这样就对两种梯度下降算法的性能和时间进行了折中。
4 反向传播
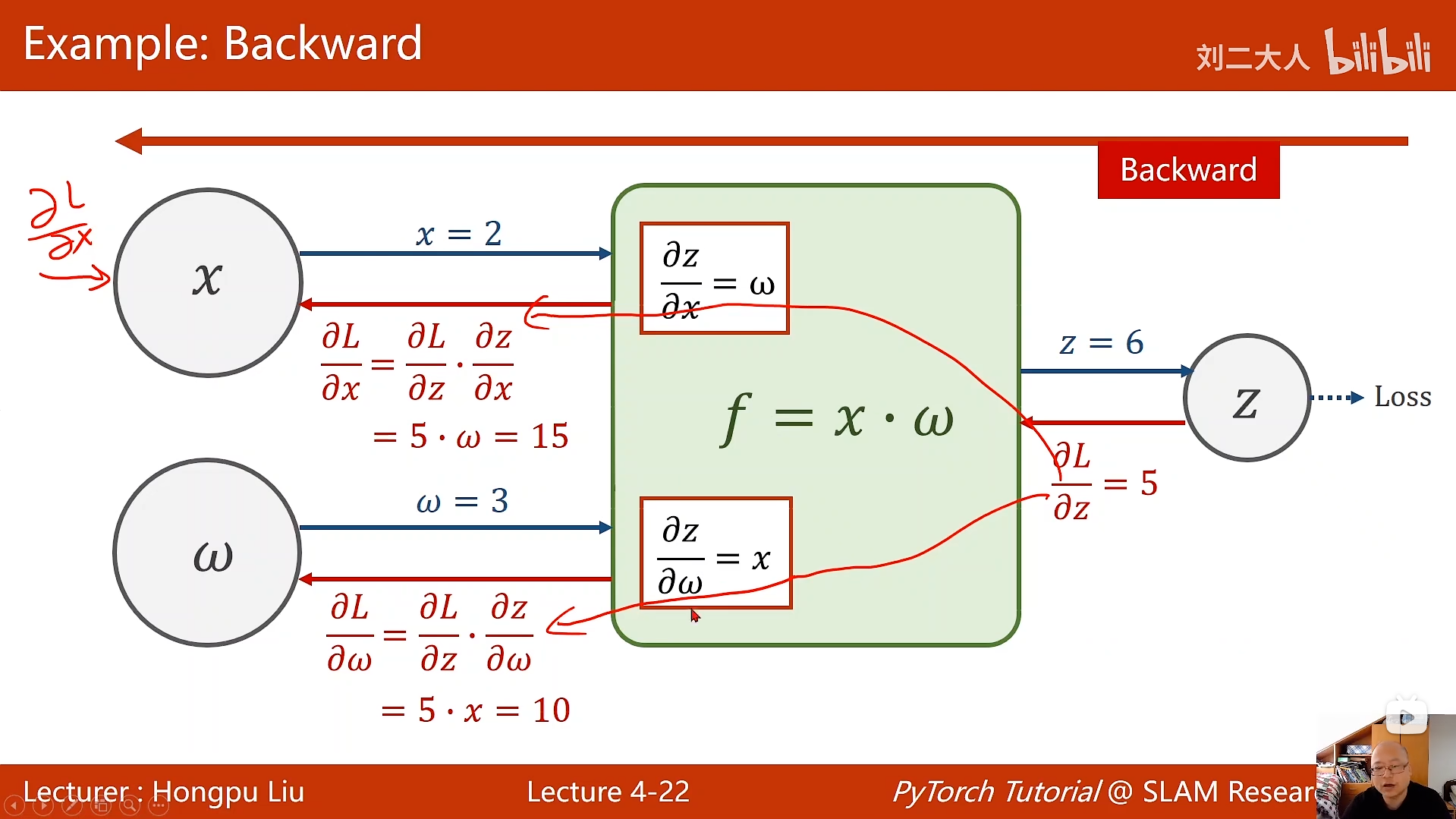
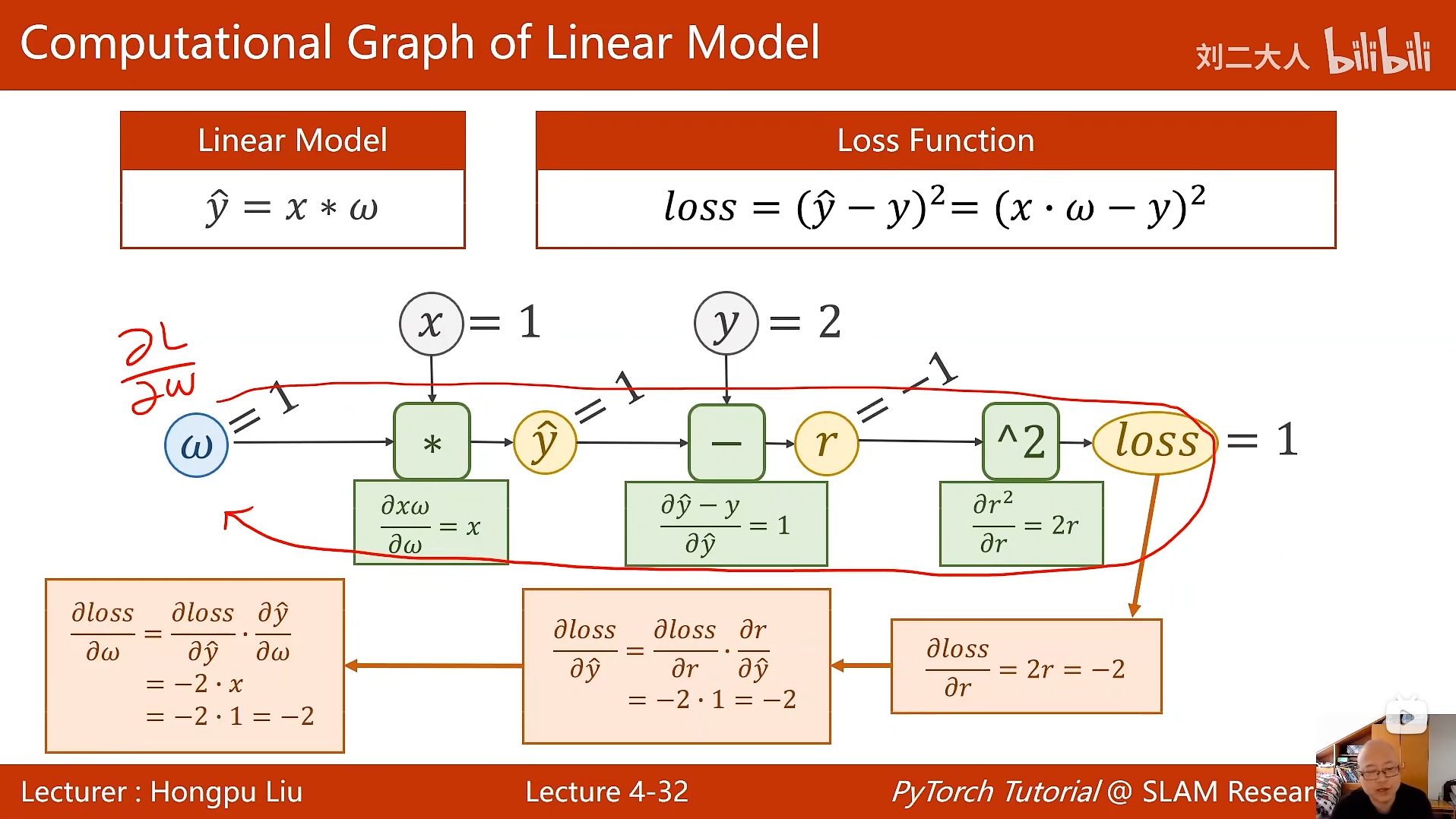
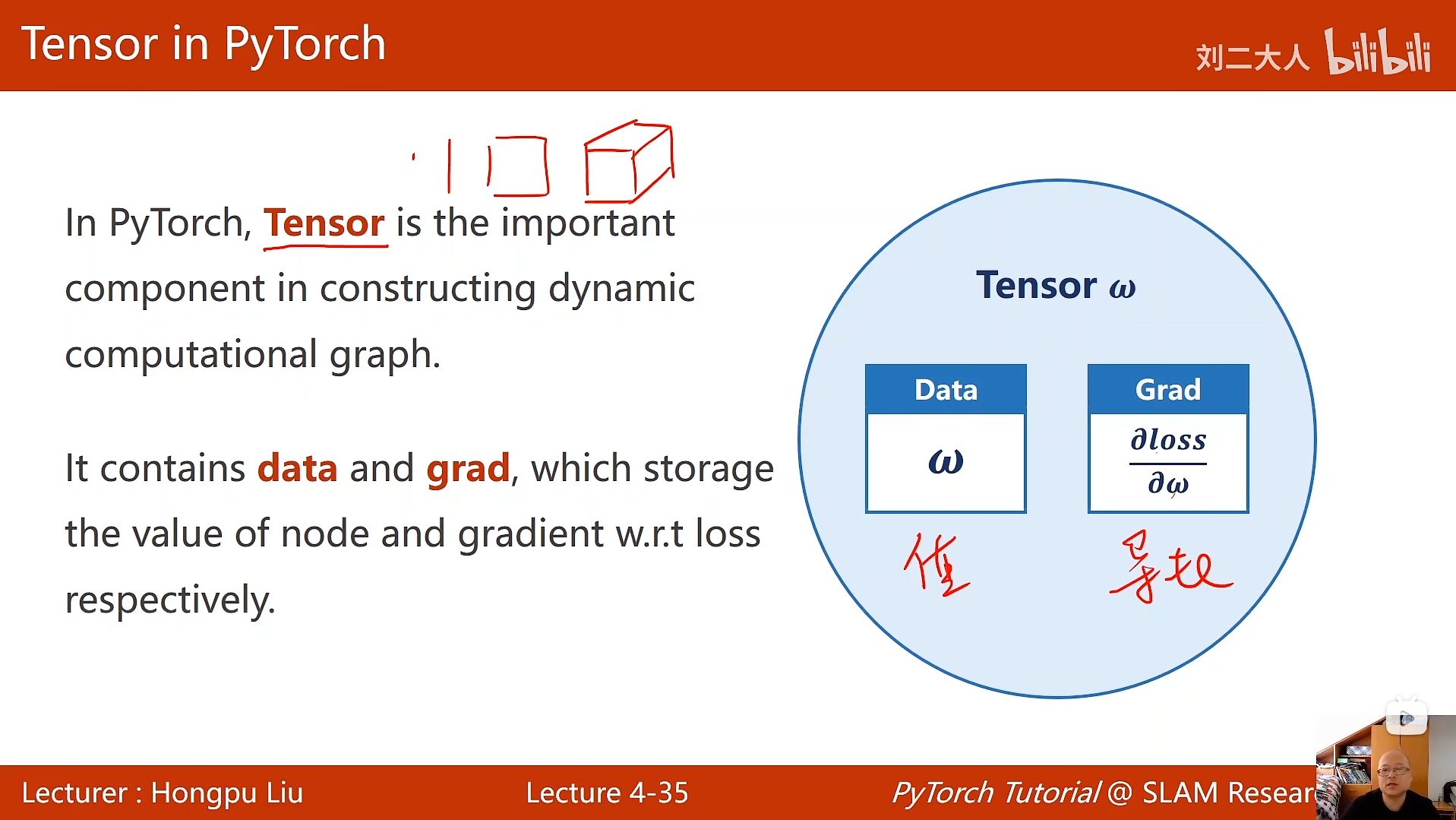


python
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True
#前馈函数(非普通标量计算)
def forward(x):
return x * w
#损失函数(非普通标量计算)
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
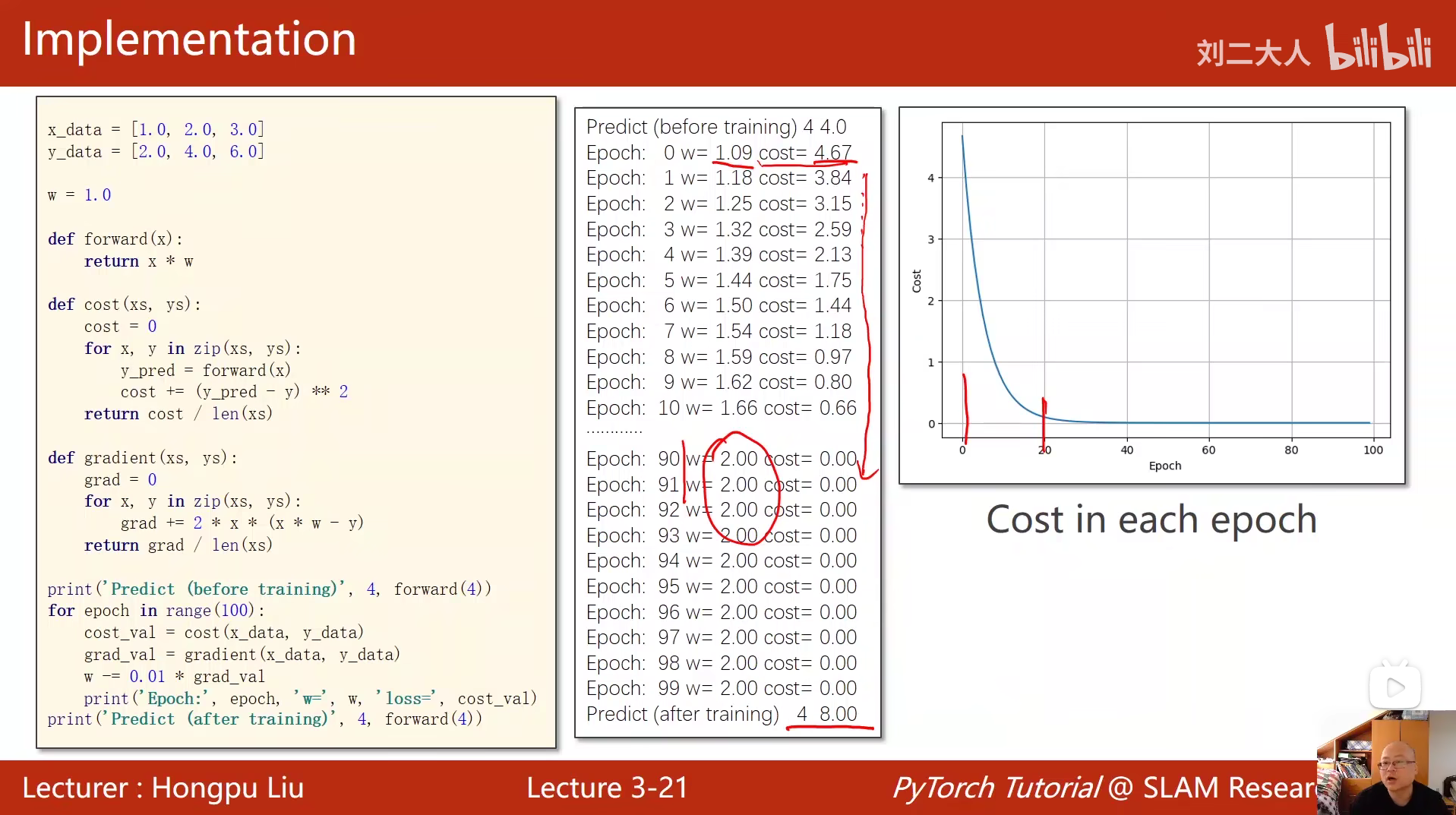
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) #计算损失
l.backward() #反向传播
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data #更新权重
w.grad.data.zero_() #清零梯度数据
print("progress:", epoch, l.item())
print("predict (after training)", 4, forward(4).item())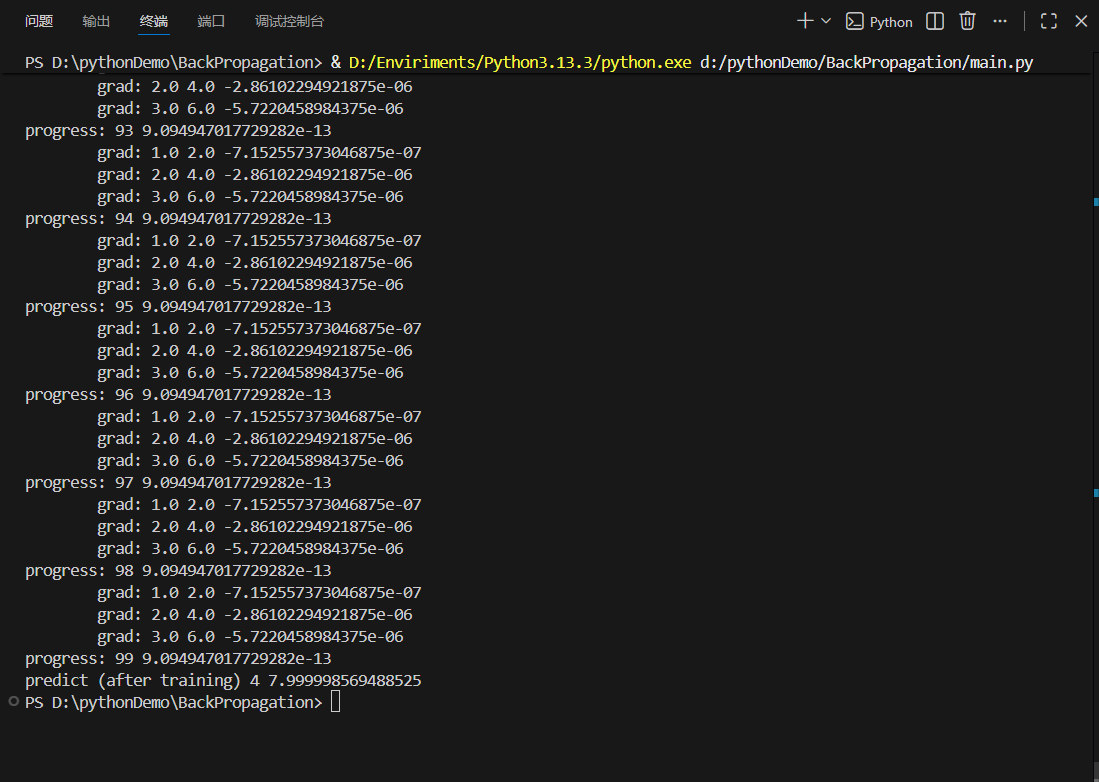
5 使用 PyTorch 实现线性回归






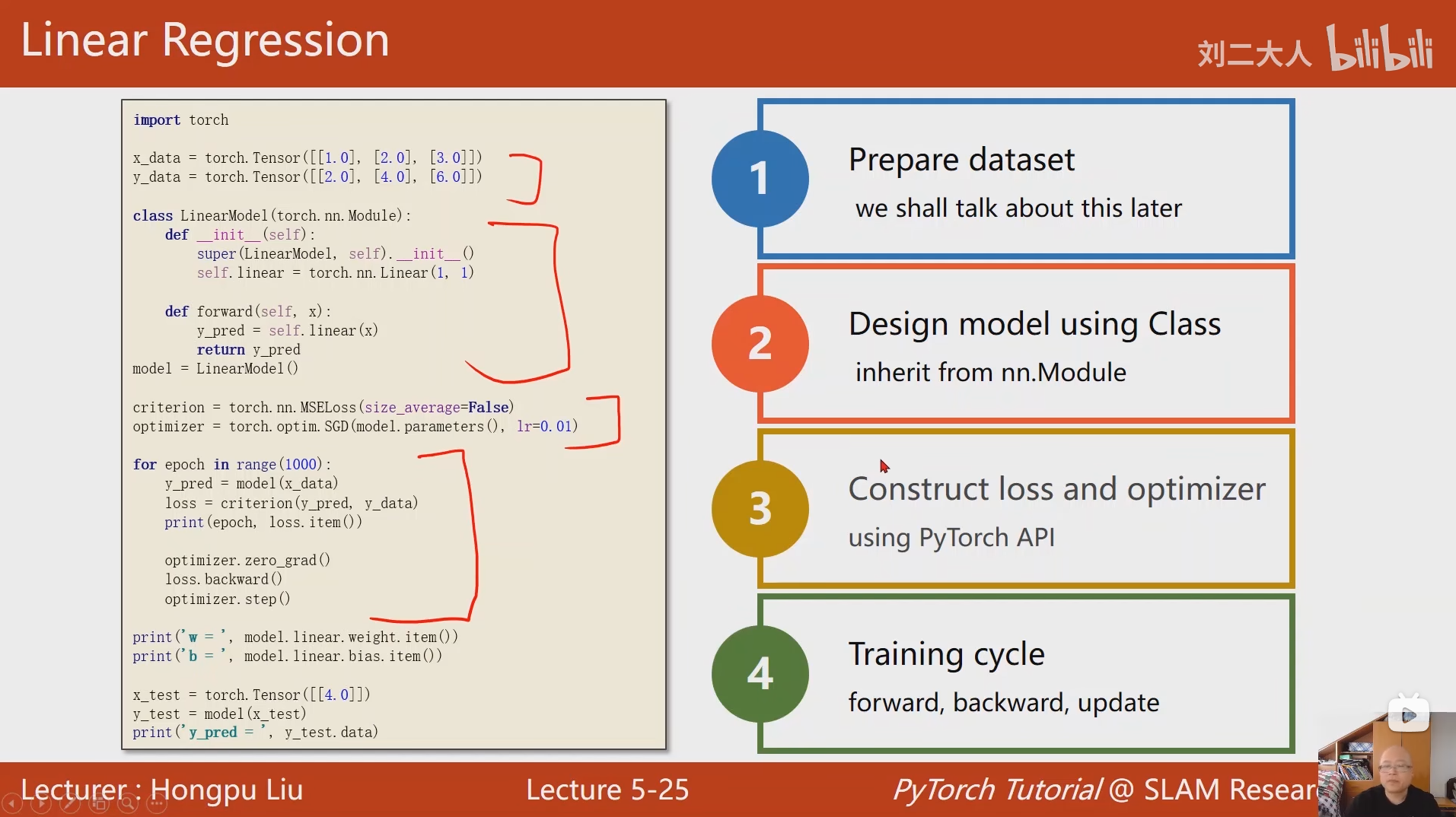
python
import torch
# 定义训练数据
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
# 定义线性模型
class LinearModel(torch.nn.Module):
# 构造函数
def __init__(self):
# 调用父类的构造函数,必须执行
super(LinearModel, self).__init__()
# 定义线性层:torch.nn.Linear(in_features, out_features)
# in_features=1:输入特征维度为1
# out_features=1:输出特征维度为1
# 该层会自动创建可训练的权重w和偏置b
self.linear = torch.nn.Linear(1, 1)
# 前向传播函数:定义模型的计算逻辑
# x: 输入张量
def forward(self, x):
# 通过线性层计算预测值y_pred
y_pred = self.linear(x)
return y_pred
# 创建线性模型的实例
model = LinearModel()
# 定义损失函数:均方误差损失(MSE)
# size_average=False:不计算均值,直接求和(PyTorch新版本建议用reduction='sum')
criterion = torch.nn.MSELoss(size_average=False)
# 定义优化器:随机梯度下降(SGD)
# model.parameters():获取模型中所有可训练的参数(w和b)
# lr=0.01:学习率,控制参数更新的步长
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# 训练循环:迭代1000次
for epoch in range(1000):
# 前向传播:将输入数据传入模型,得到预测值y_pred
y_pred = model(x_data)
# 计算损失:预测值与真实值之间的均方误差
loss = criterion(y_pred, y_data)
# 打印当前迭代次数和损失值
print(epoch, loss)
# 梯度清零:重置优化器的梯度缓存(避免梯度累积)
optimizer.zero_grad()
# 反向传播:计算损失对所有参数的梯度
loss.backward()
# 优化器更新:根据梯度更新模型参数(w和b)
optimizer.step()
# 输出训练后的权重w:.item()将张量转换为标量值
print('w=', model.linear.weight.item())
# 输出训练后的偏置b:修正原代码的笔误(pirnt→print)
print('b=', model.linear.bias.item())
# 测试模型:创建测试输入x=4.0(注意形状为[1,1],与训练数据一致)
x_test = torch.Tensor([[4.0]])
# 前向传播:获取测试数据的预测值
y_test = model(x_test)
# 打印预测结果:修正原代码的错误(y_test.x_data→y_test.item())
print('y_pred=', y_test.item())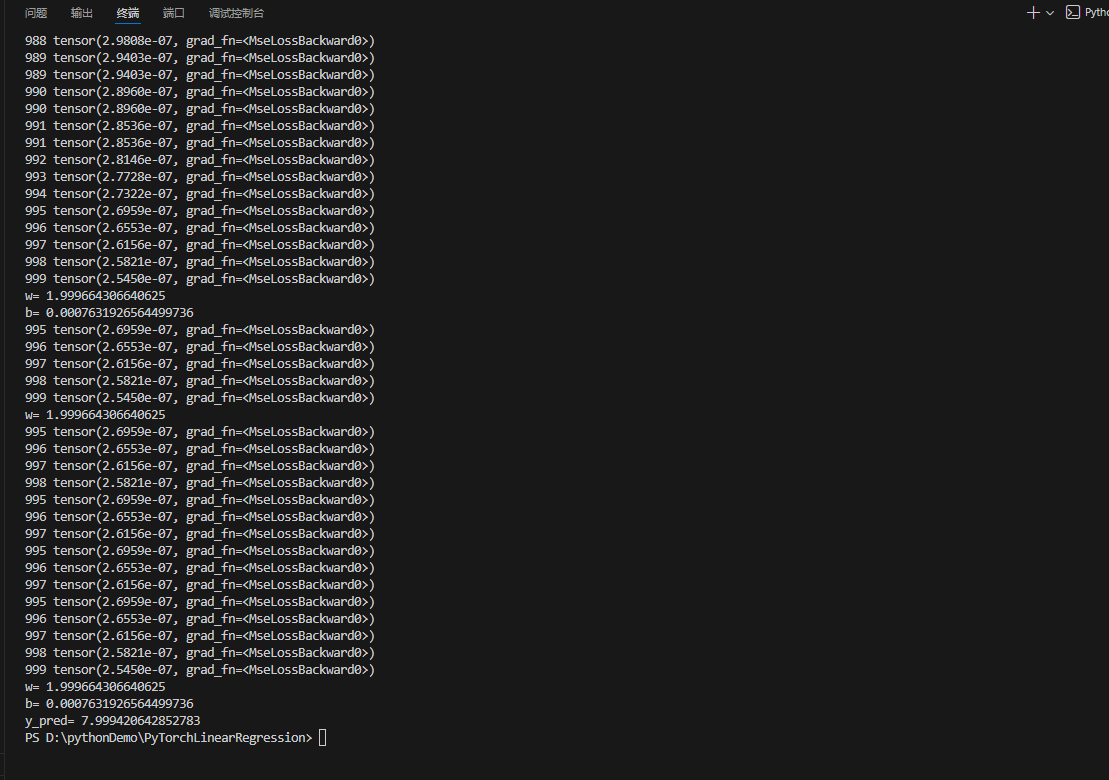
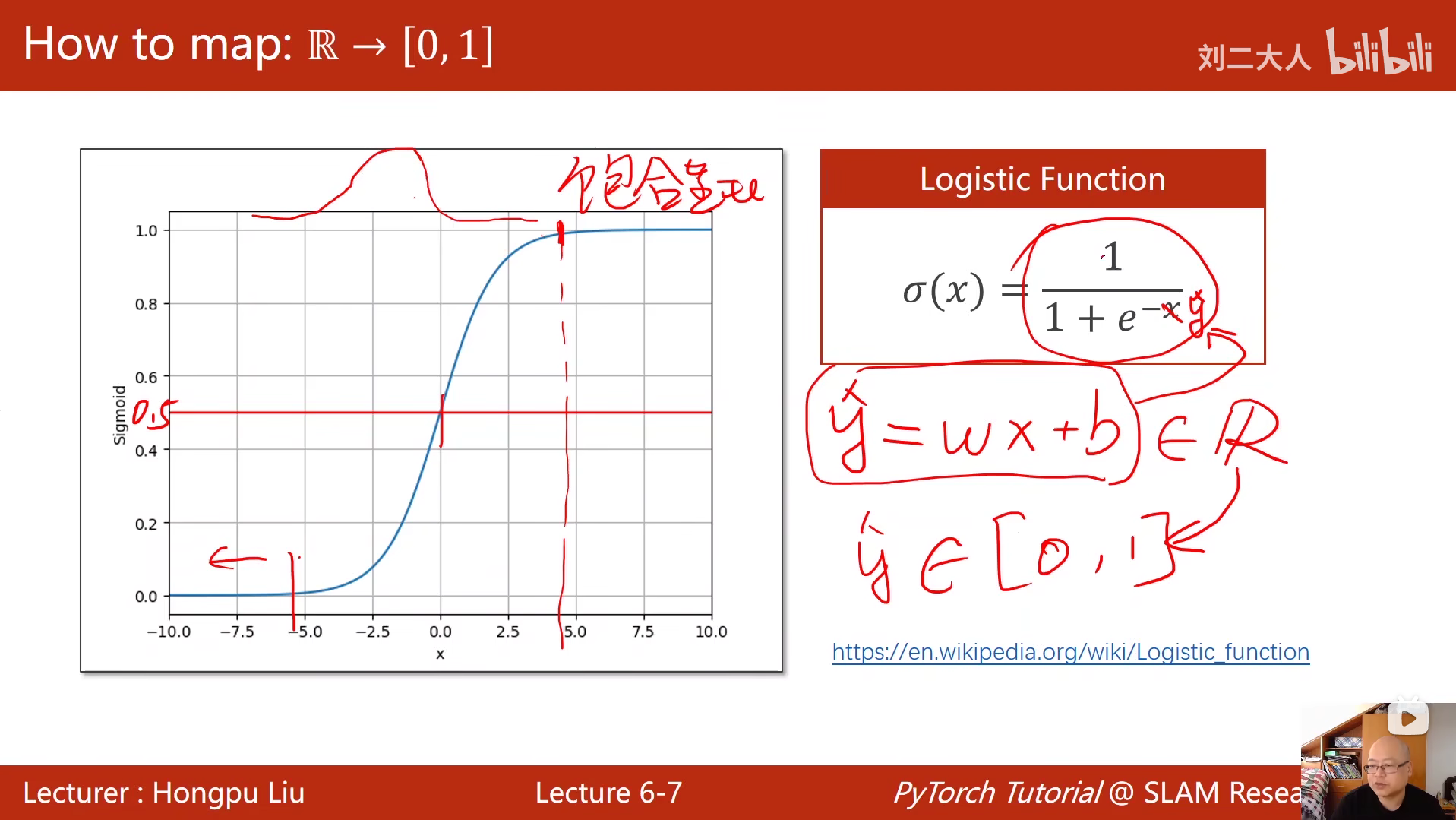
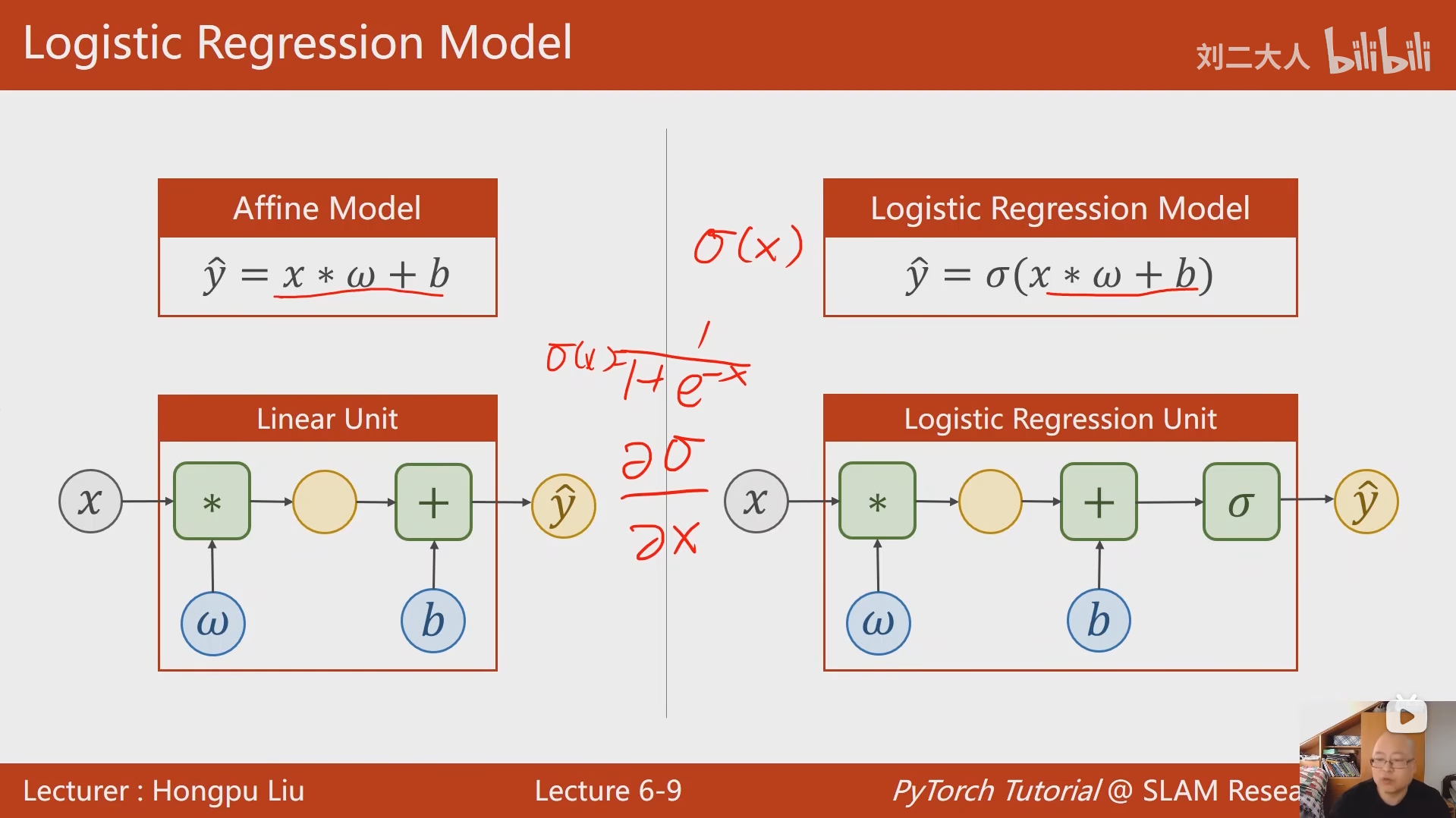
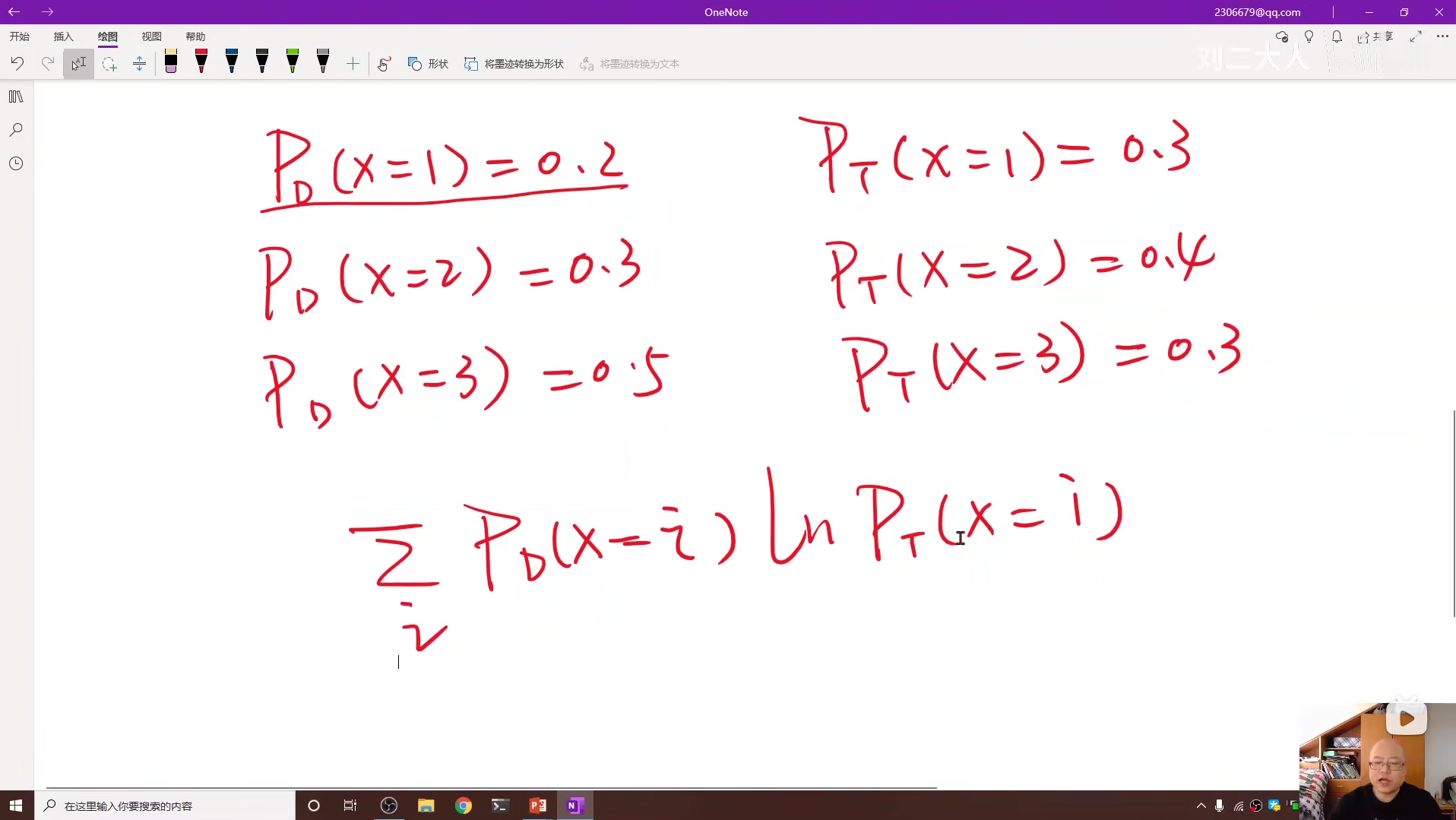
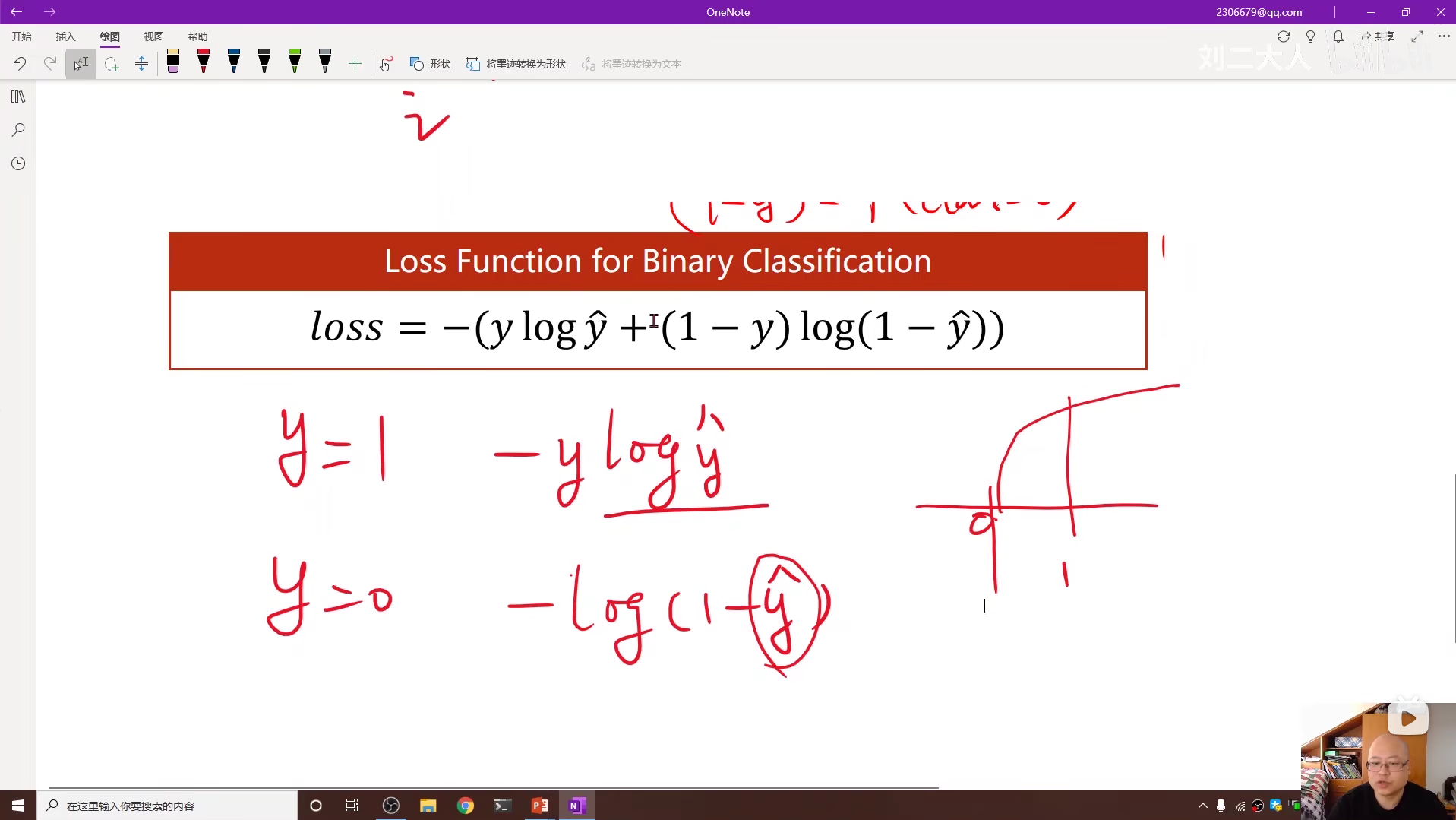
6 逻辑斯蒂回归





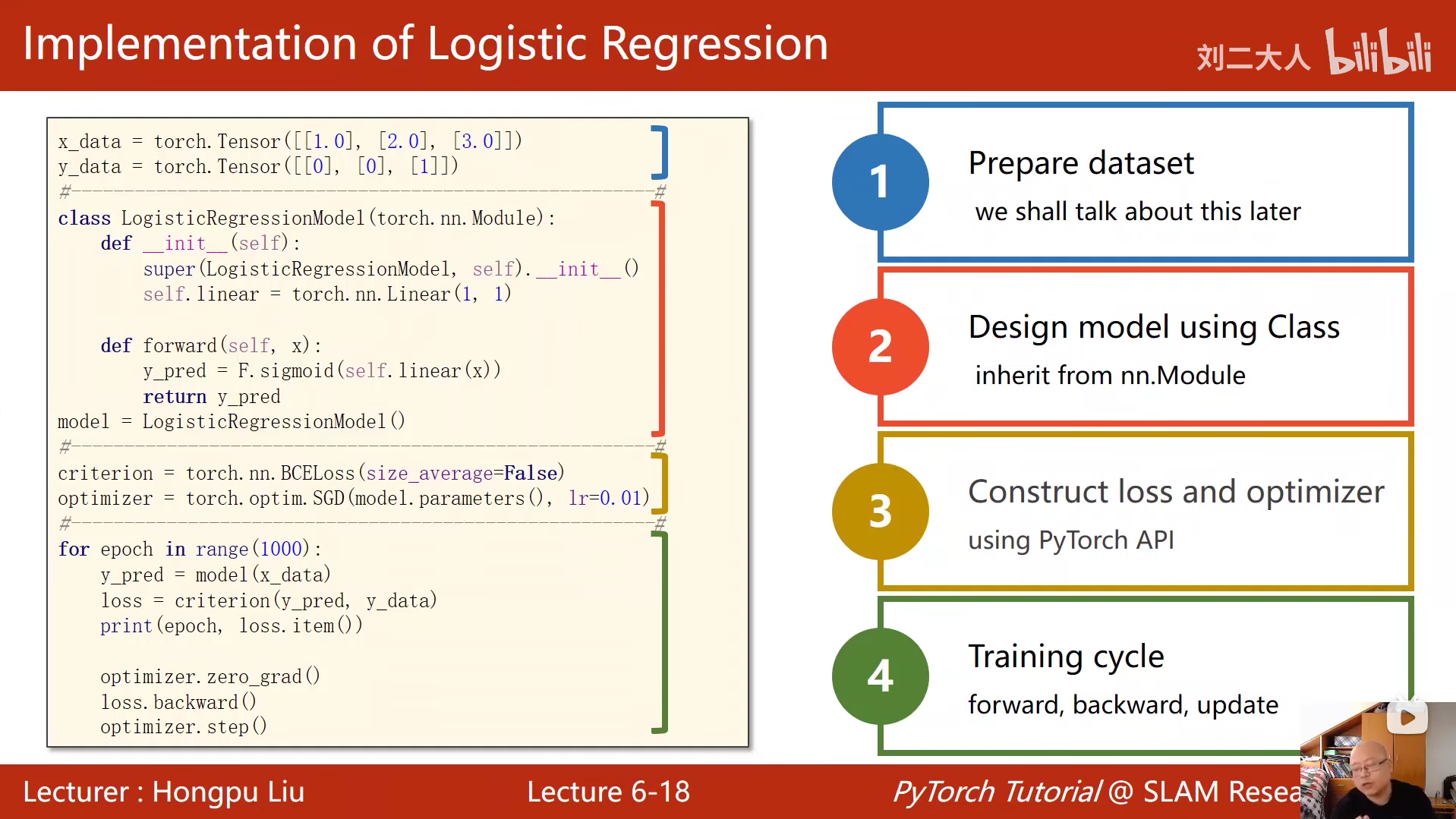
python
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# 定义训练数据
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
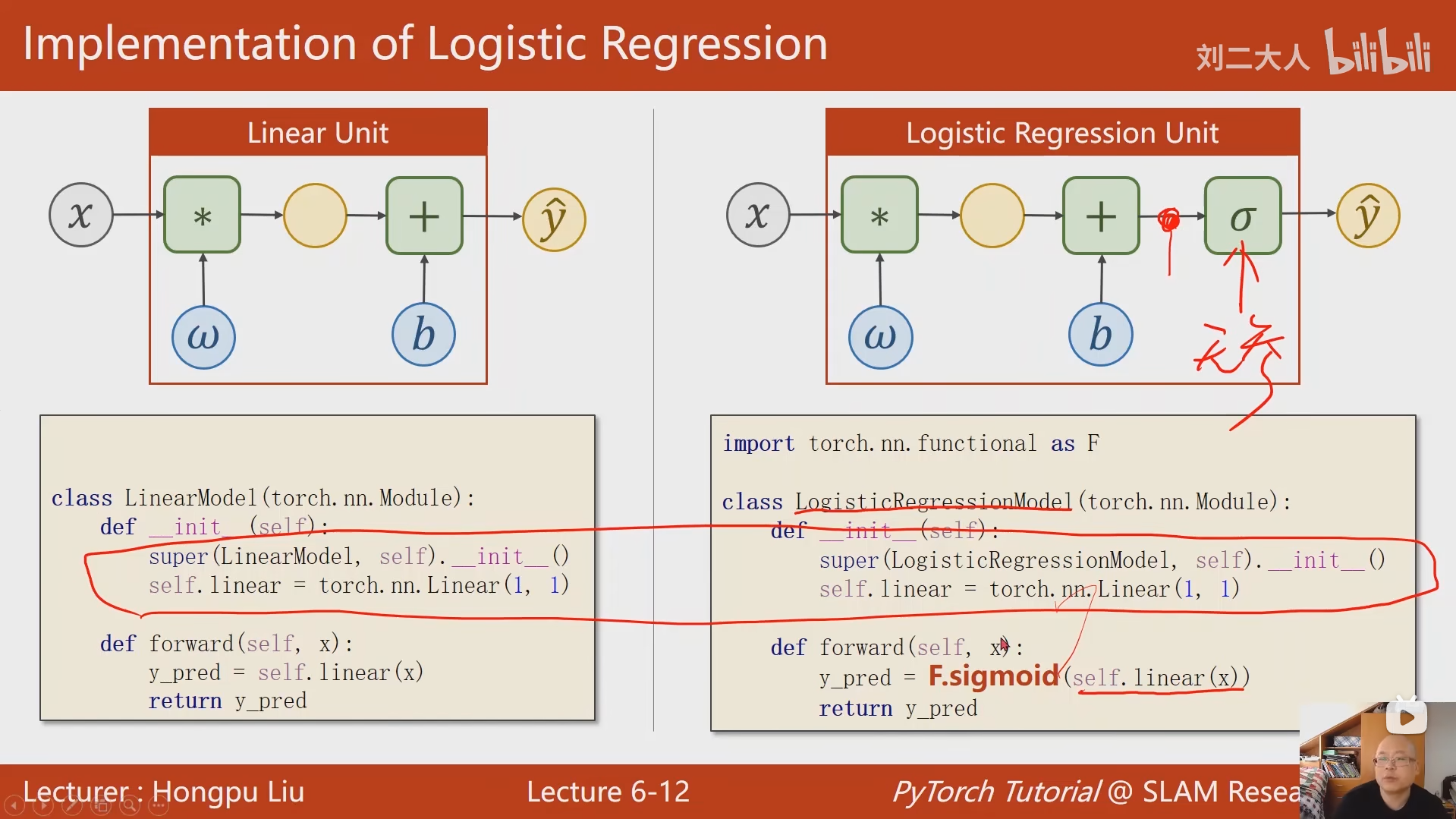
# 定义逻辑斯蒂回归模型
class LogisticRegressionModel(torch.nn.Module):
# 构造函数
def __init__(self):
# 调用父类的构造函数,必须执行
super(LogisticRegressionModel, self).__init__()
# 定义线性层:torch.nn.Linear(in_features, out_features)
# in_features=1:输入特征维度为1
# out_features=1:输出特征维度为1
# 该层会自动创建可训练的权重w和偏置b
self.linear = torch.nn.Linear(1, 1)
# 前向传播函数:定义模型的计算逻辑
# x: 输入张量
def forward(self, x):
# 通过线性层计算预测值y_pred
y_pred = F.sigmoid(self.linear(x))
return y_pred
# 创建线性模型的实例
model = LogisticRegressionModel()
# 定义损失函数:二分类交叉熵(BCE)
# size_average=False:不计算均值,直接求和(PyTorch新版本建议用reduction='sum')
criterion = torch.nn.BCELoss(size_average=False)
# 定义优化器:随机梯度下降(SGD)
# model.parameters():获取模型中所有可训练的参数(w和b)
# lr=0.01:学习率,控制参数更新的步长
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# 训练循环:迭代1000次
for epoch in range(1000):
# 前向传播:将输入数据传入模型,得到预测值y_pred
y_pred = model(x_data)
# 计算损失:预测值与真实值之间的均方误差
loss = criterion(y_pred, y_data)
# 打印当前迭代次数和损失值
print(epoch, loss.item())
# 梯度清零:重置优化器的梯度缓存(避免梯度累积)
optimizer.zero_grad()
# 反向传播:计算损失对所有参数的梯度
loss.backward()
# 优化器更新:根据梯度更新模型参数(w和b)
optimizer.step()
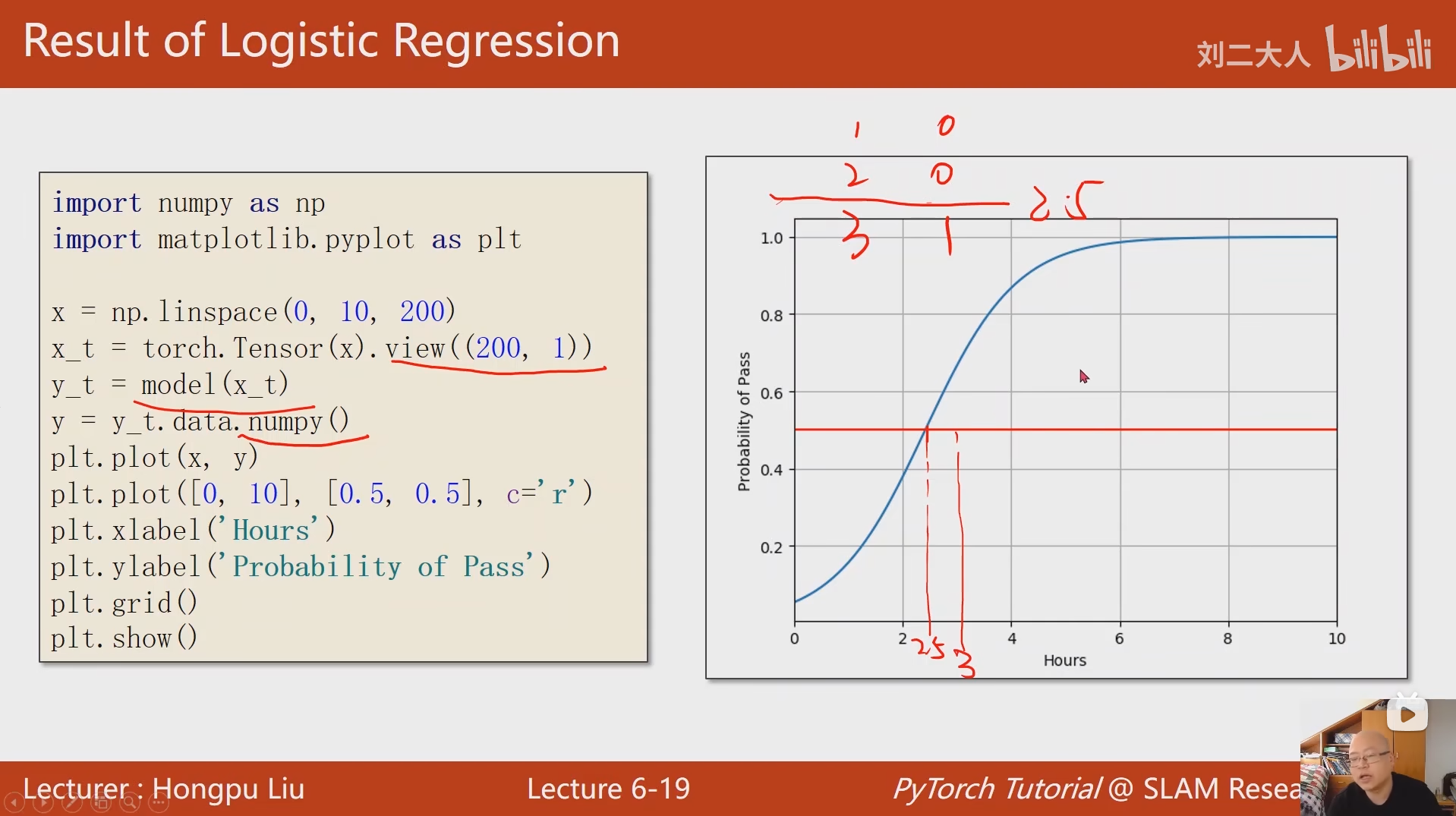
# 生成0到10之间的200个均匀分布的数,作为绘图的x轴(学习时长)
x = np.linspace(0, 10, 200)
# 将numpy数组转换为PyTorch张量,并调整形状为[200,1](匹配模型输入维度)
x_t = torch.Tensor(x).view((200, 1))
# 将张量传入模型,得到每个x对应的预测概率
y_t = model(x_t)
# 将预测结果从张量转换为numpy数组,用于绘图
y = y_t.data.numpy()
# 绘制模型预测曲线(学习时长 vs 及格概率)
plt.plot(x, y)
# 绘制阈值线:0.5是二分类的默认决策边界(>0.5预测为1,<0.5预测为0)
plt.plot([0, 10], [0.5, 0.5], c = 'r') # c='r'设置为红色
# 设置x轴标签
plt.xlabel('Hours')
# 设置y轴标签
plt.ylabel('Probability of Pass')
# 显示网格线,便于观察
plt.grid()
# 显示绘制的图形
plt.show()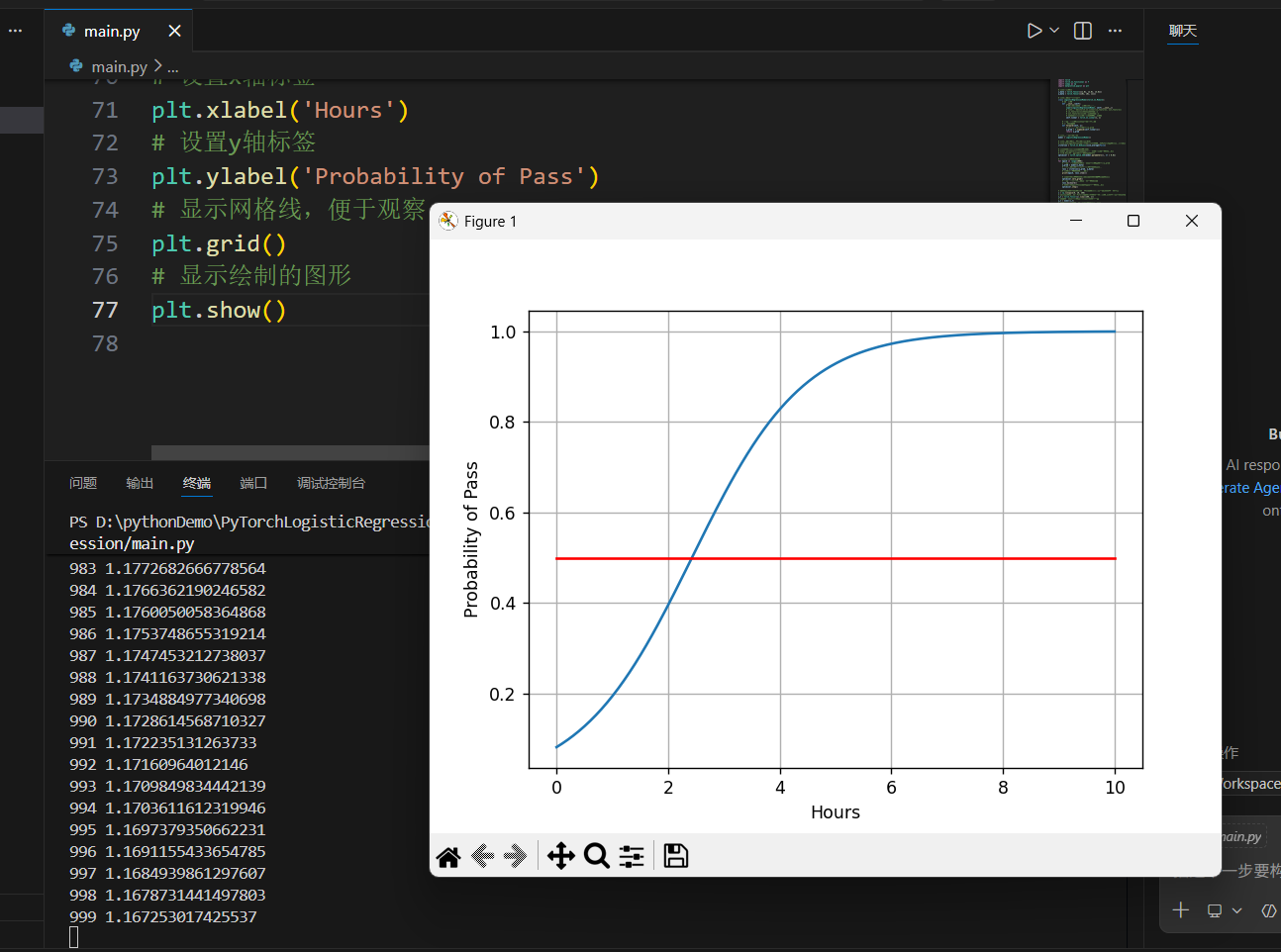
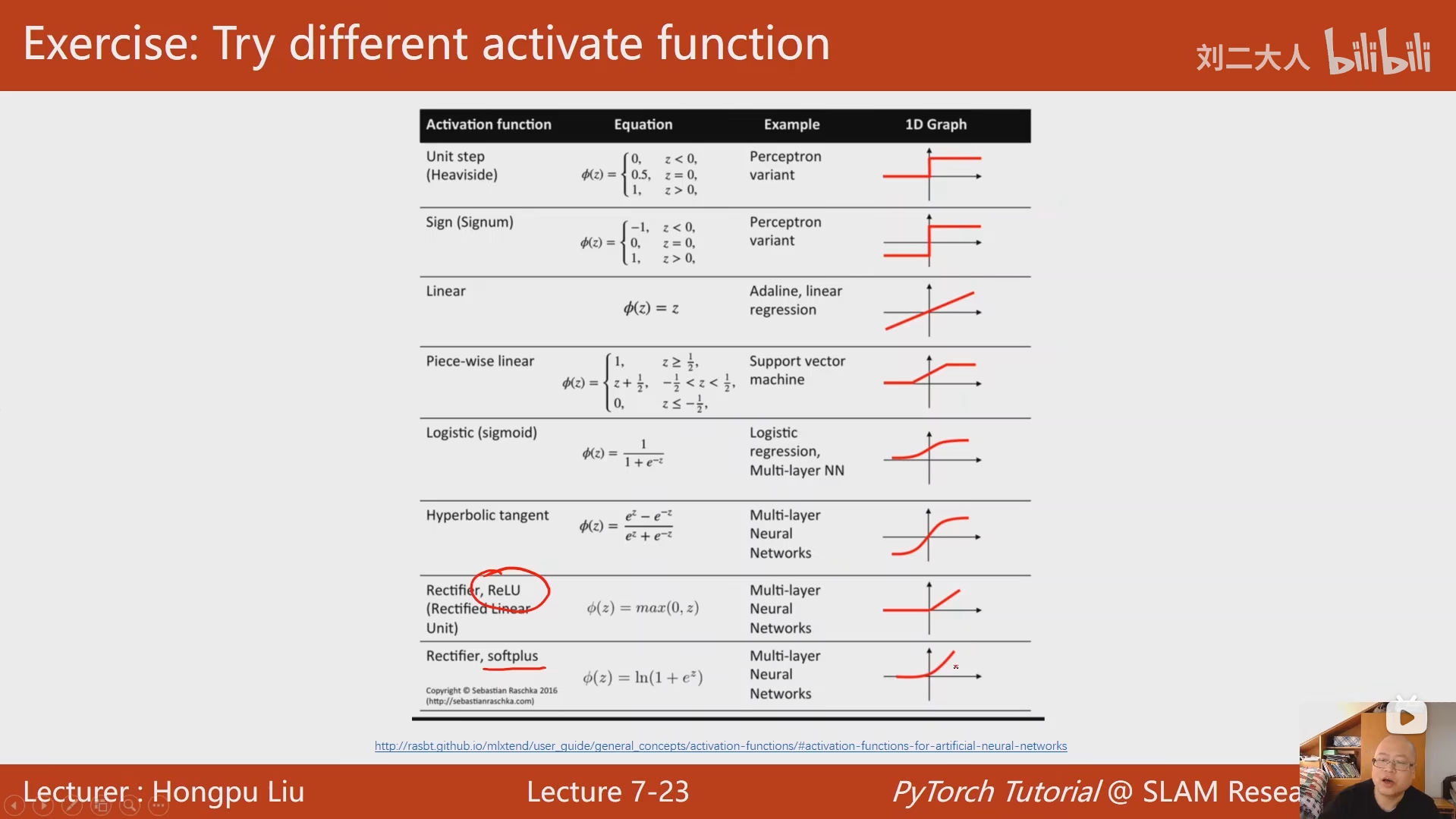
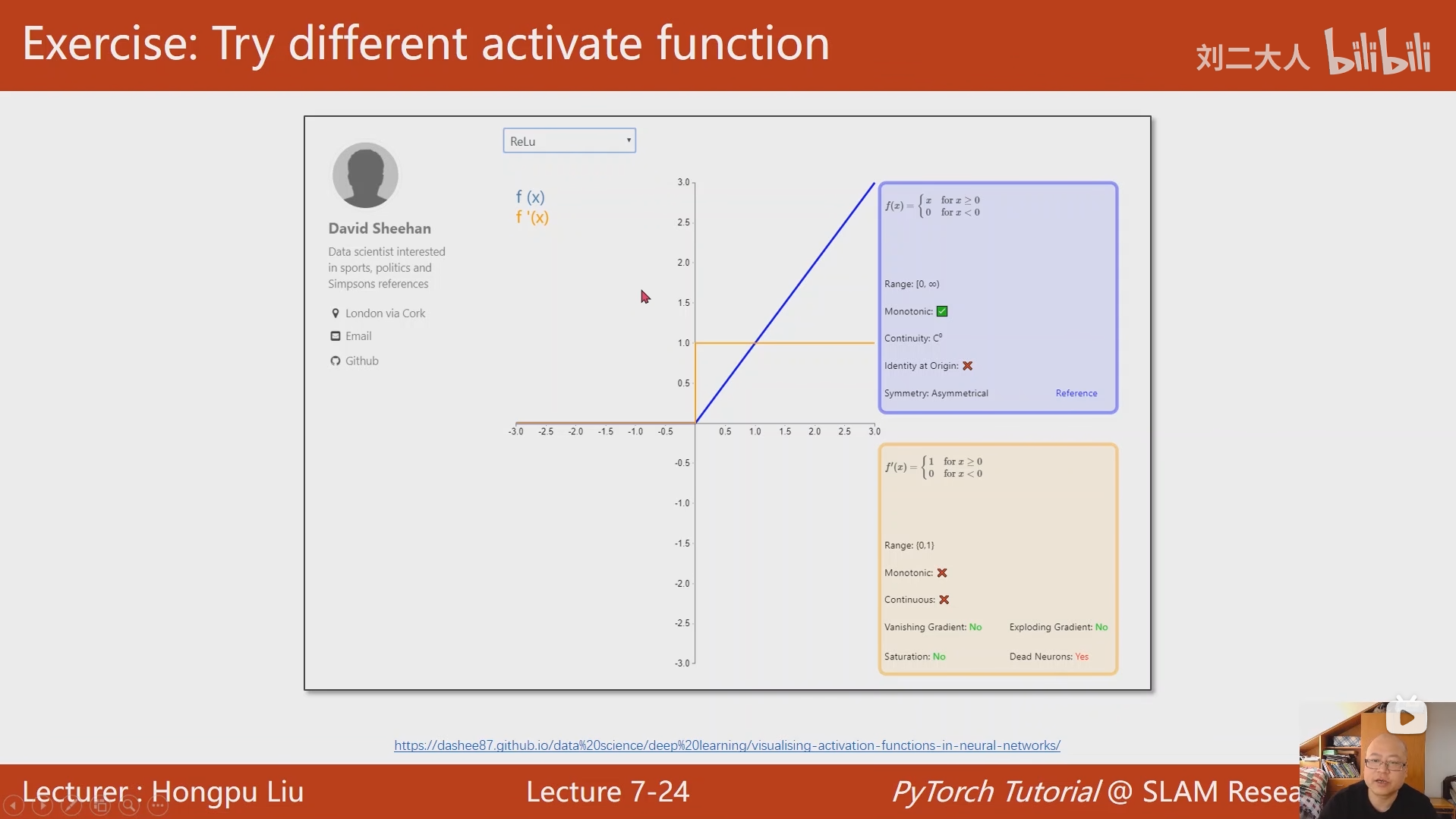
7 处理多维特征的输入
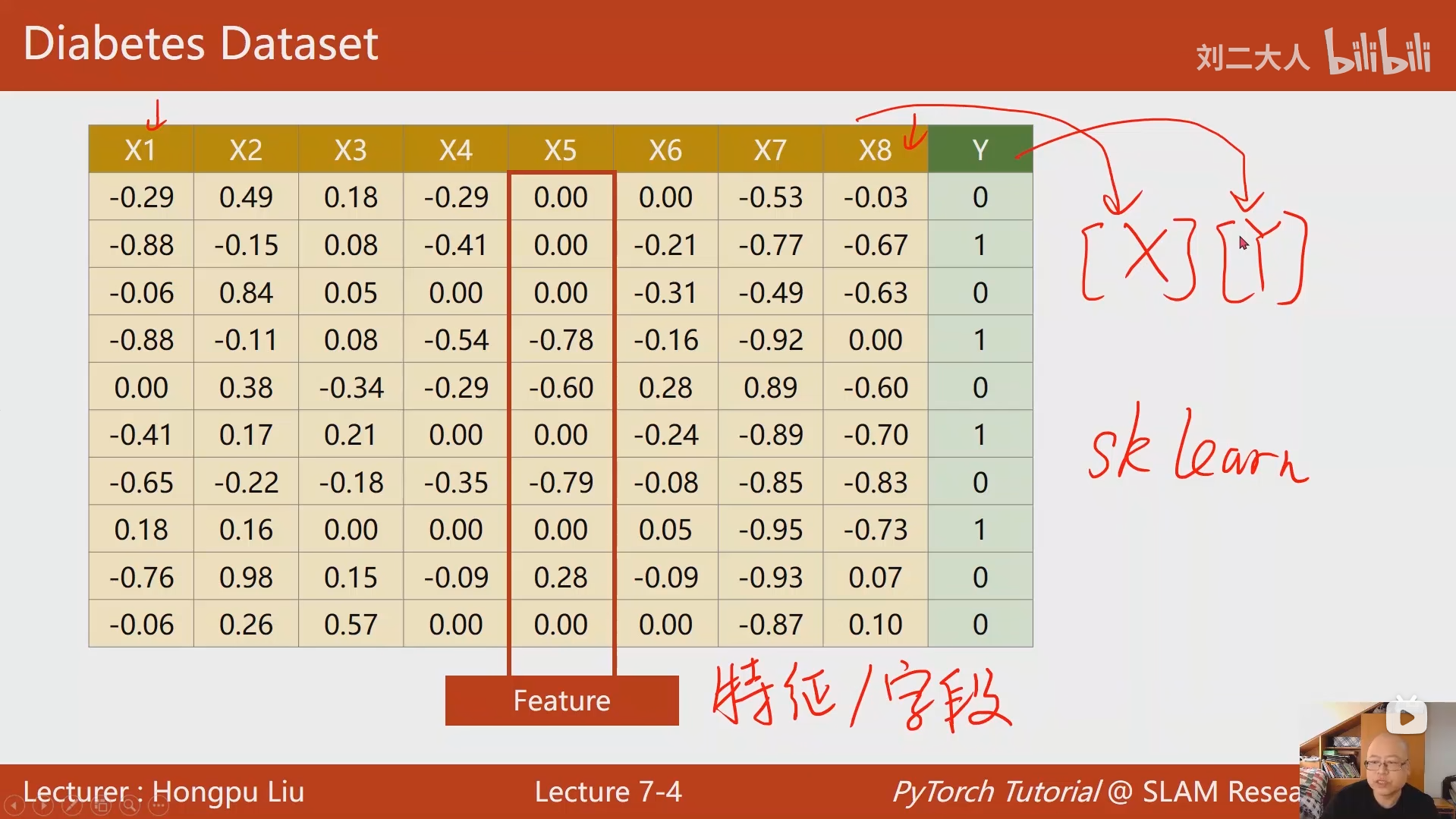
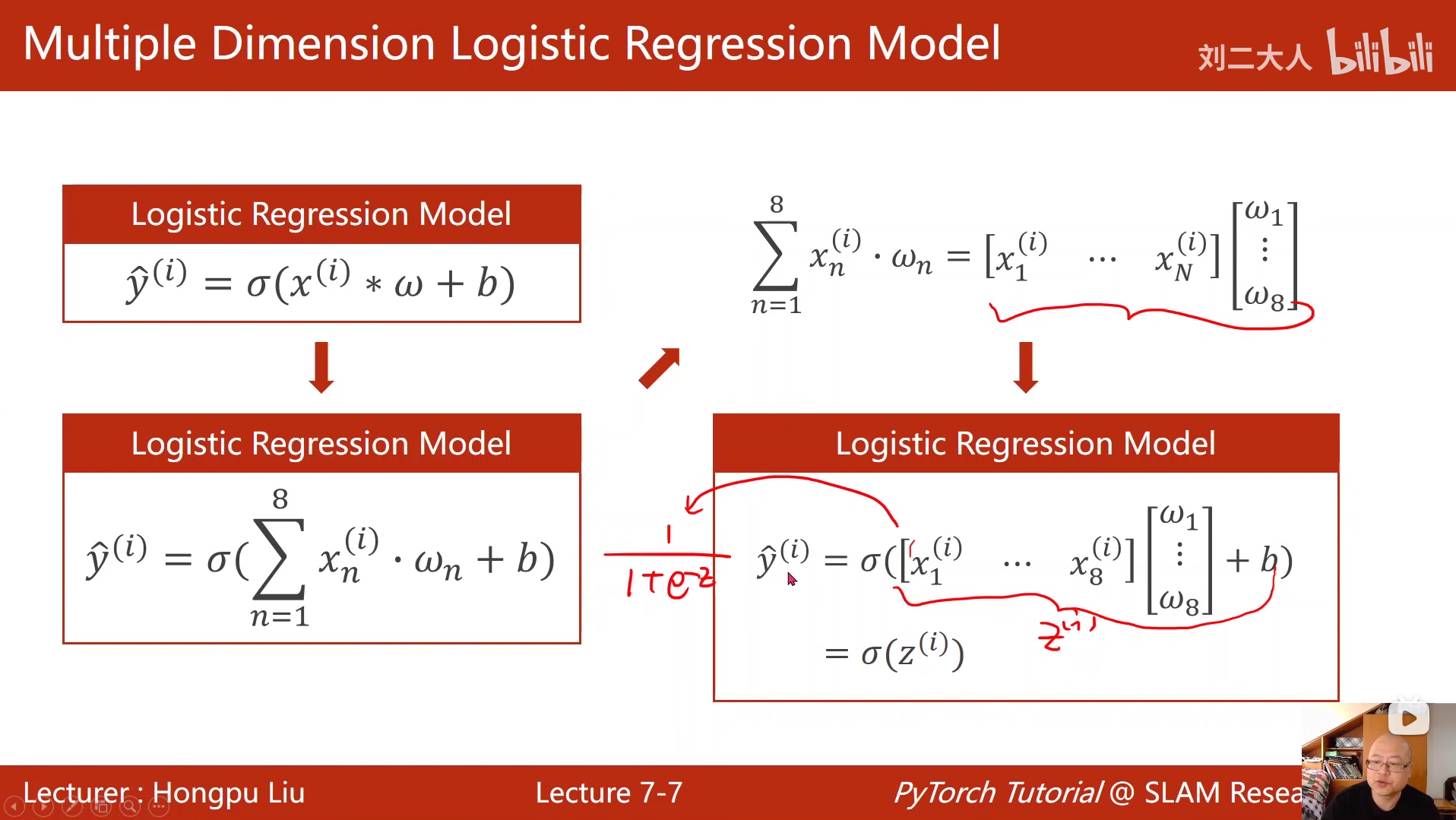
之所以要把数据排列成矩阵然后与参数进行矩阵运算,是为了充分利用到处理器的并行运算能力,避免因为常规循环造成训练速度过慢。

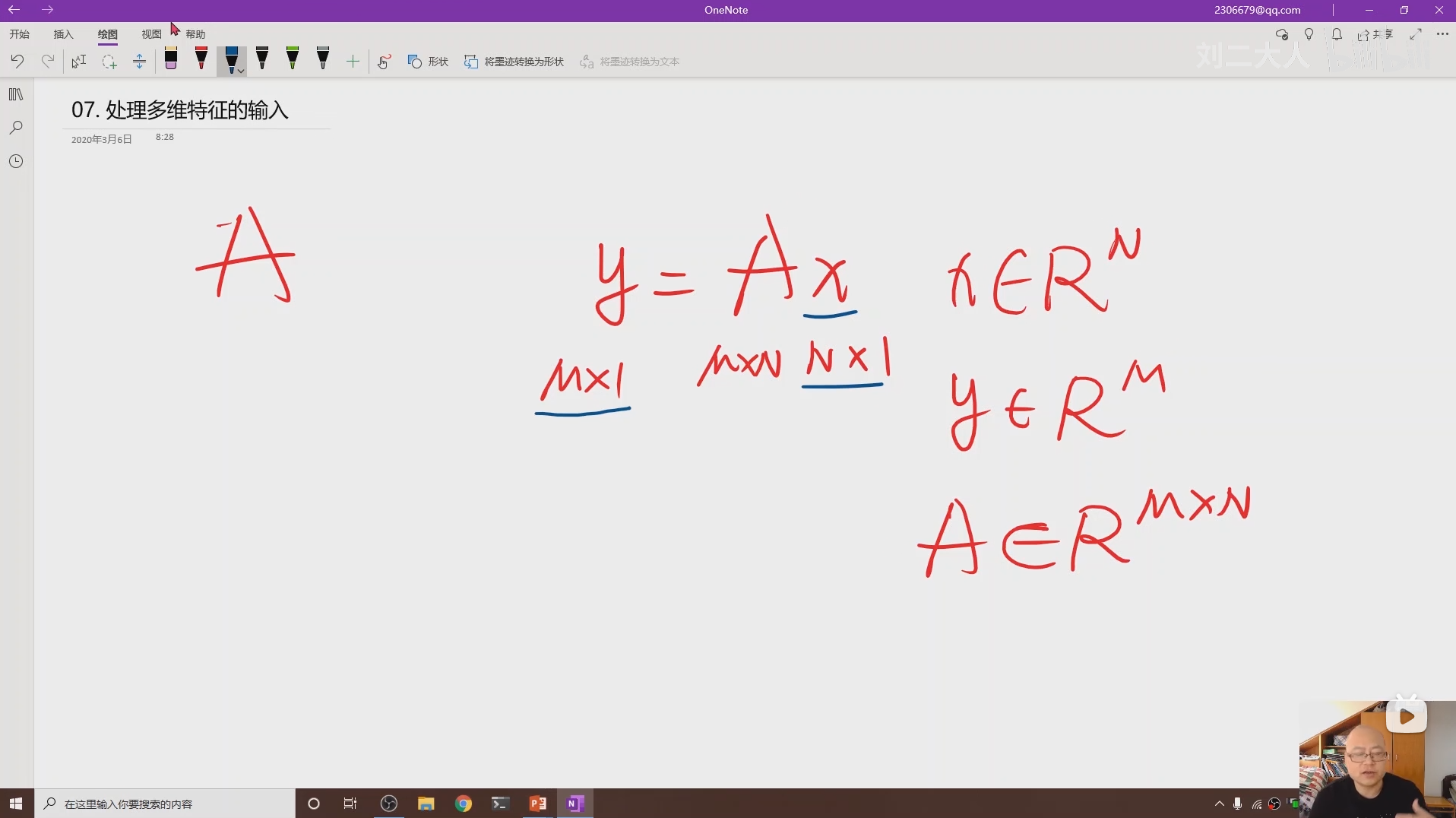
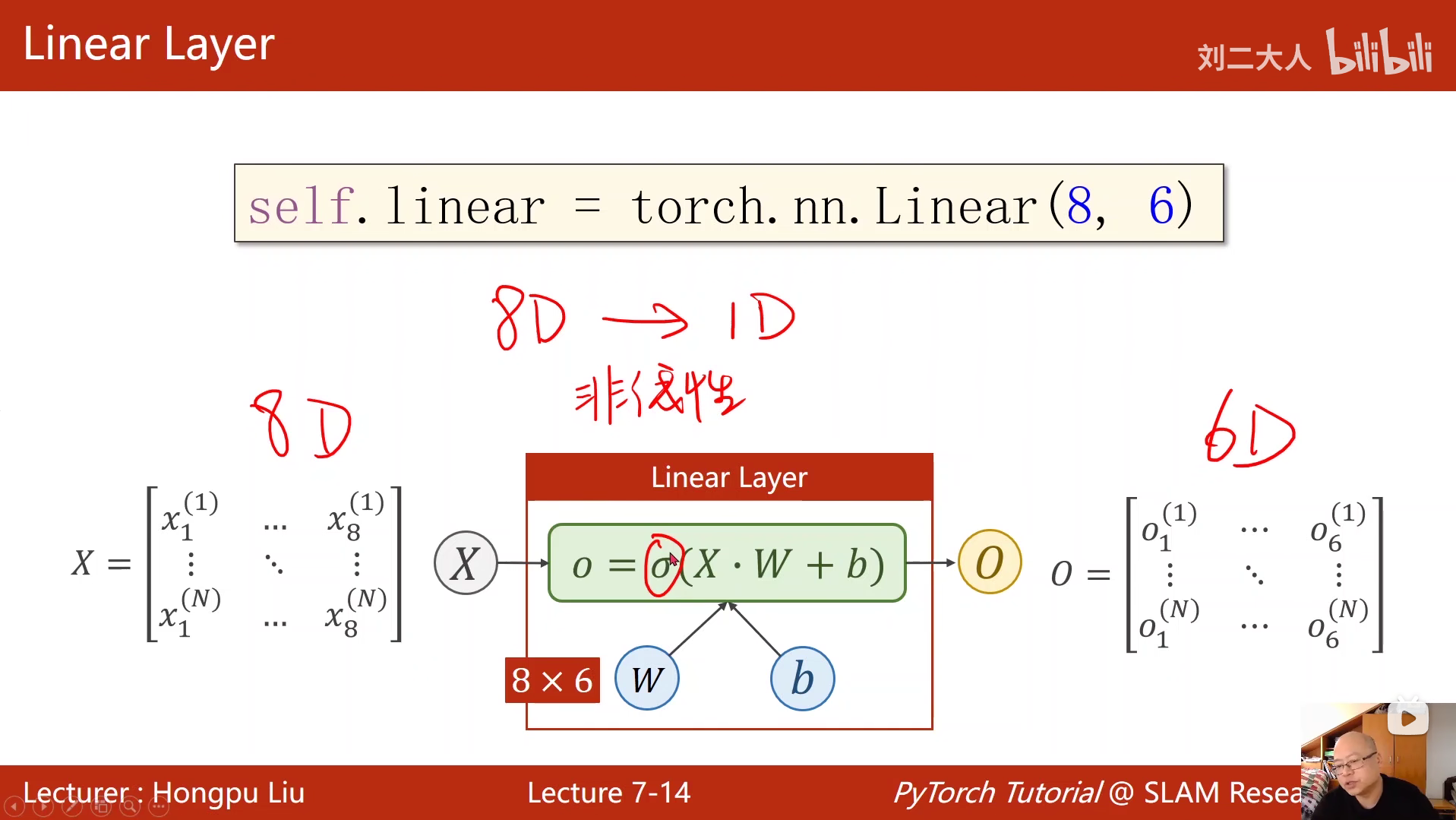
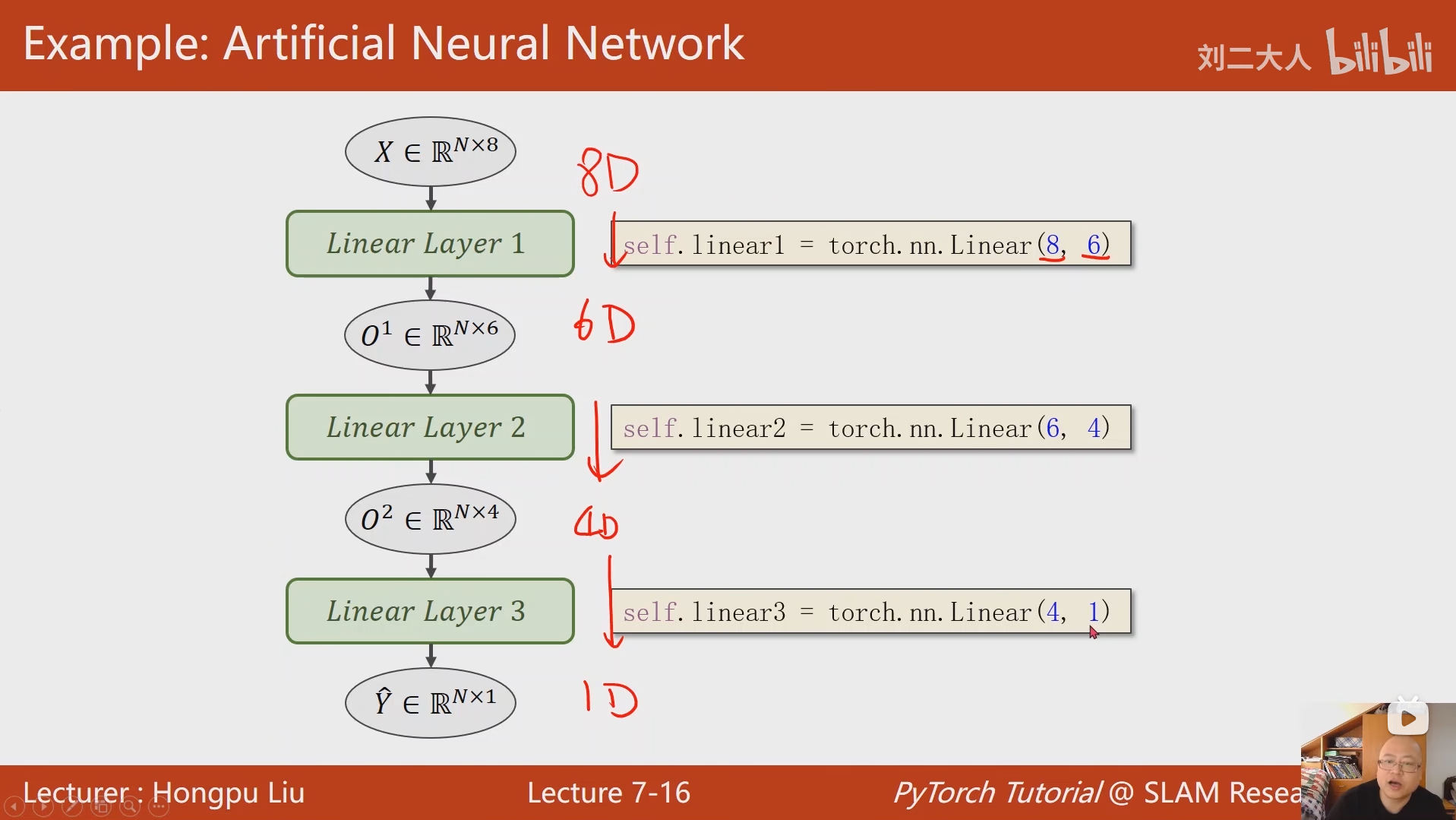
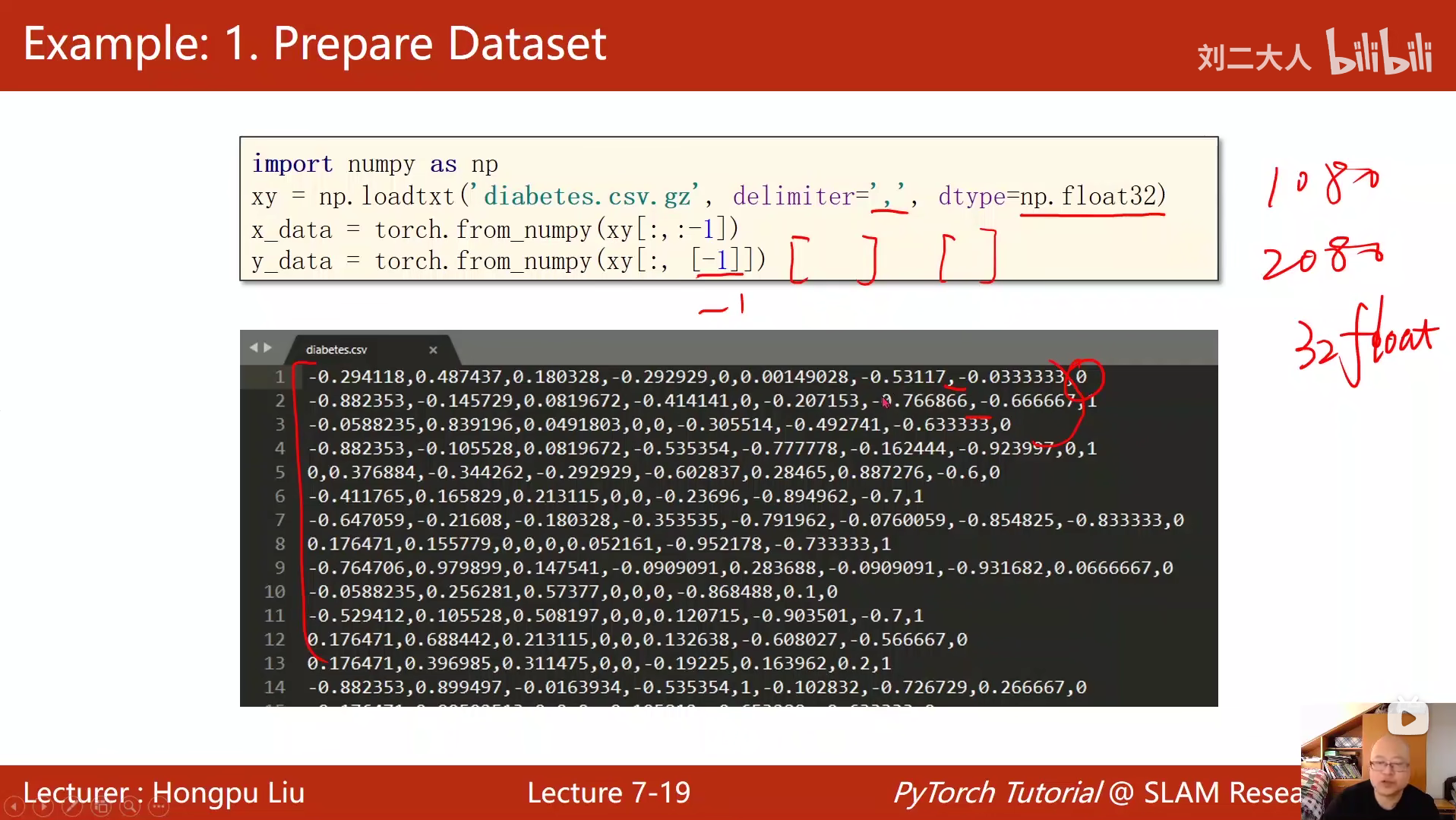




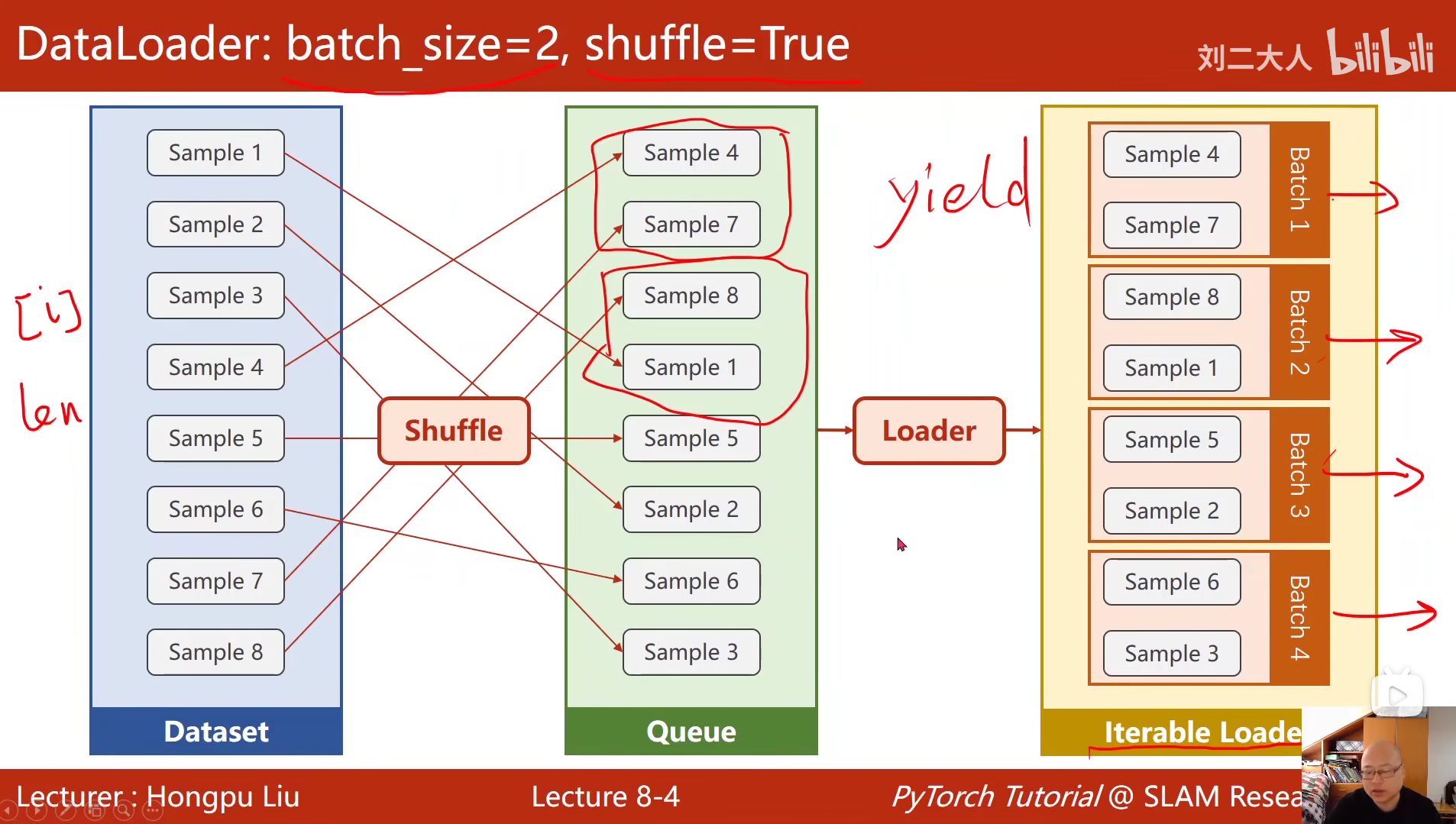
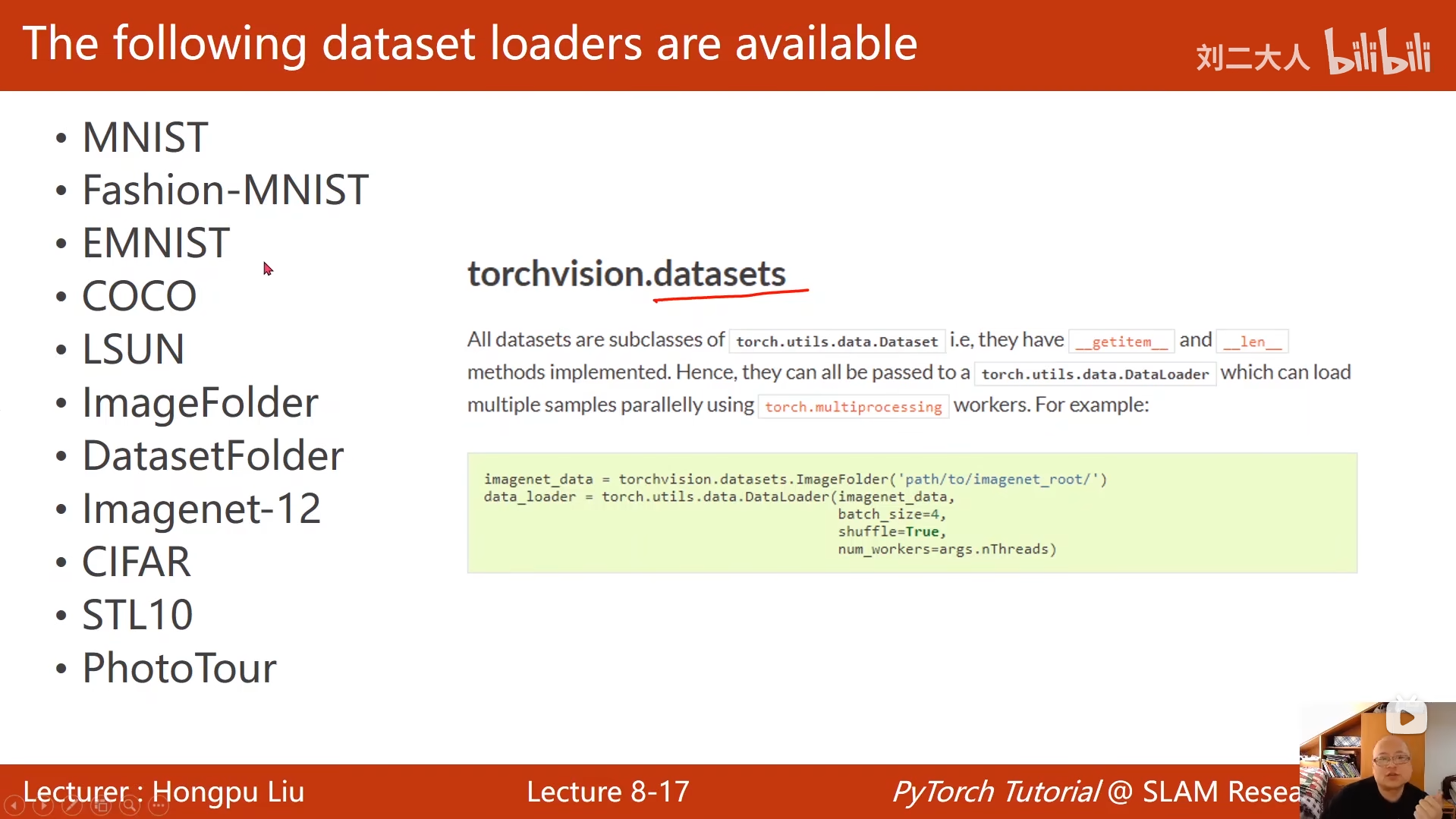
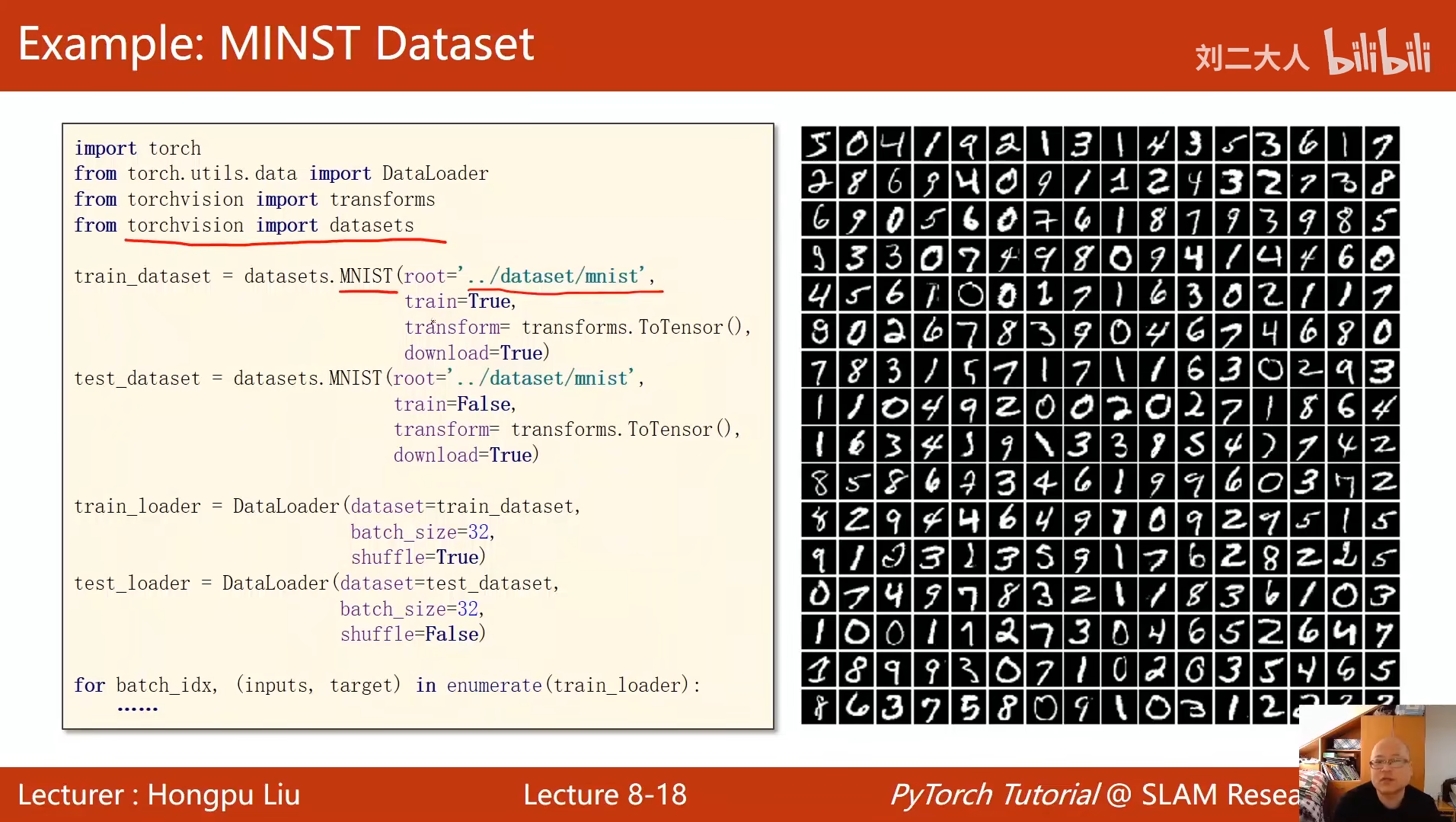
8 加载数据集





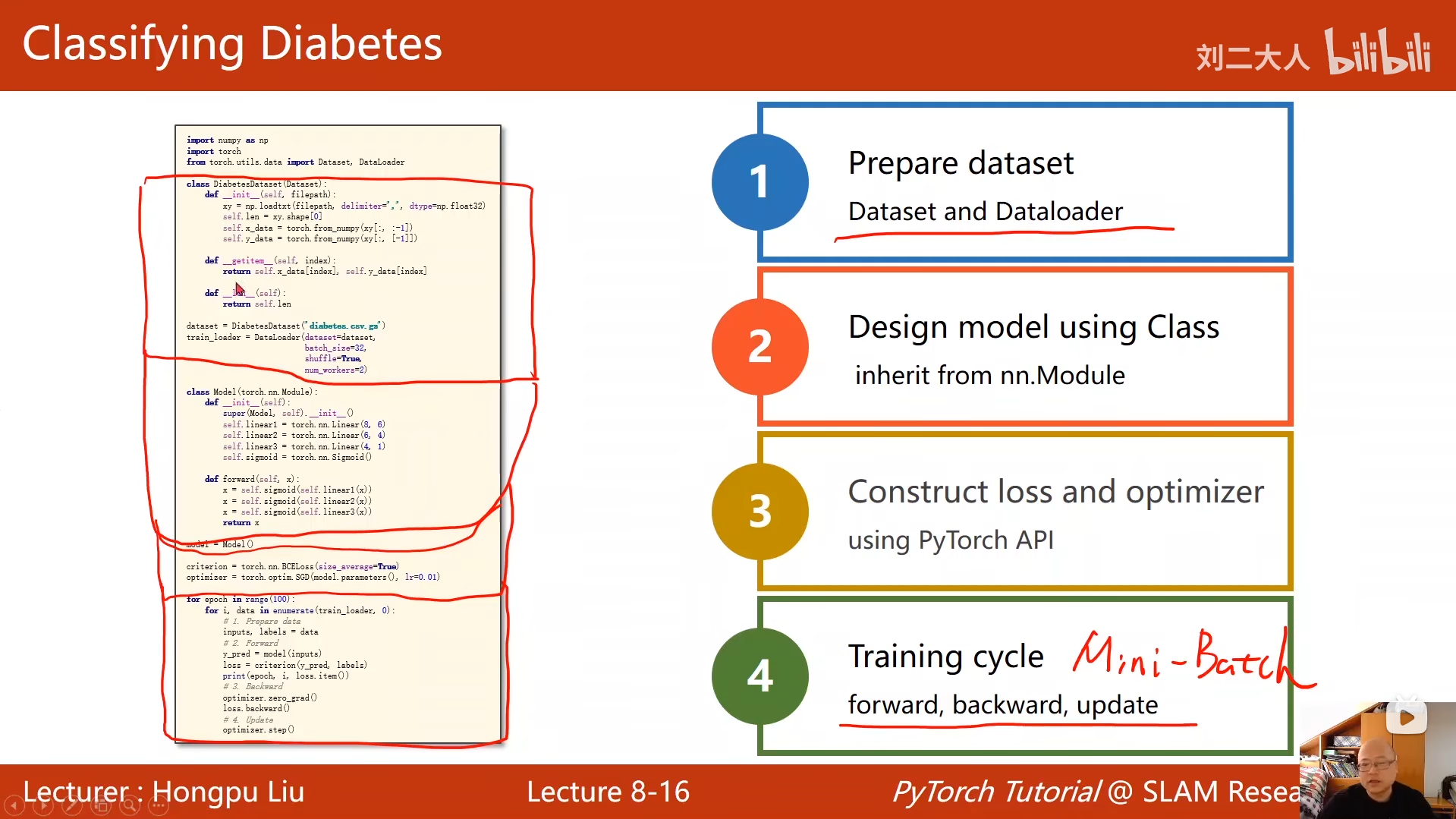
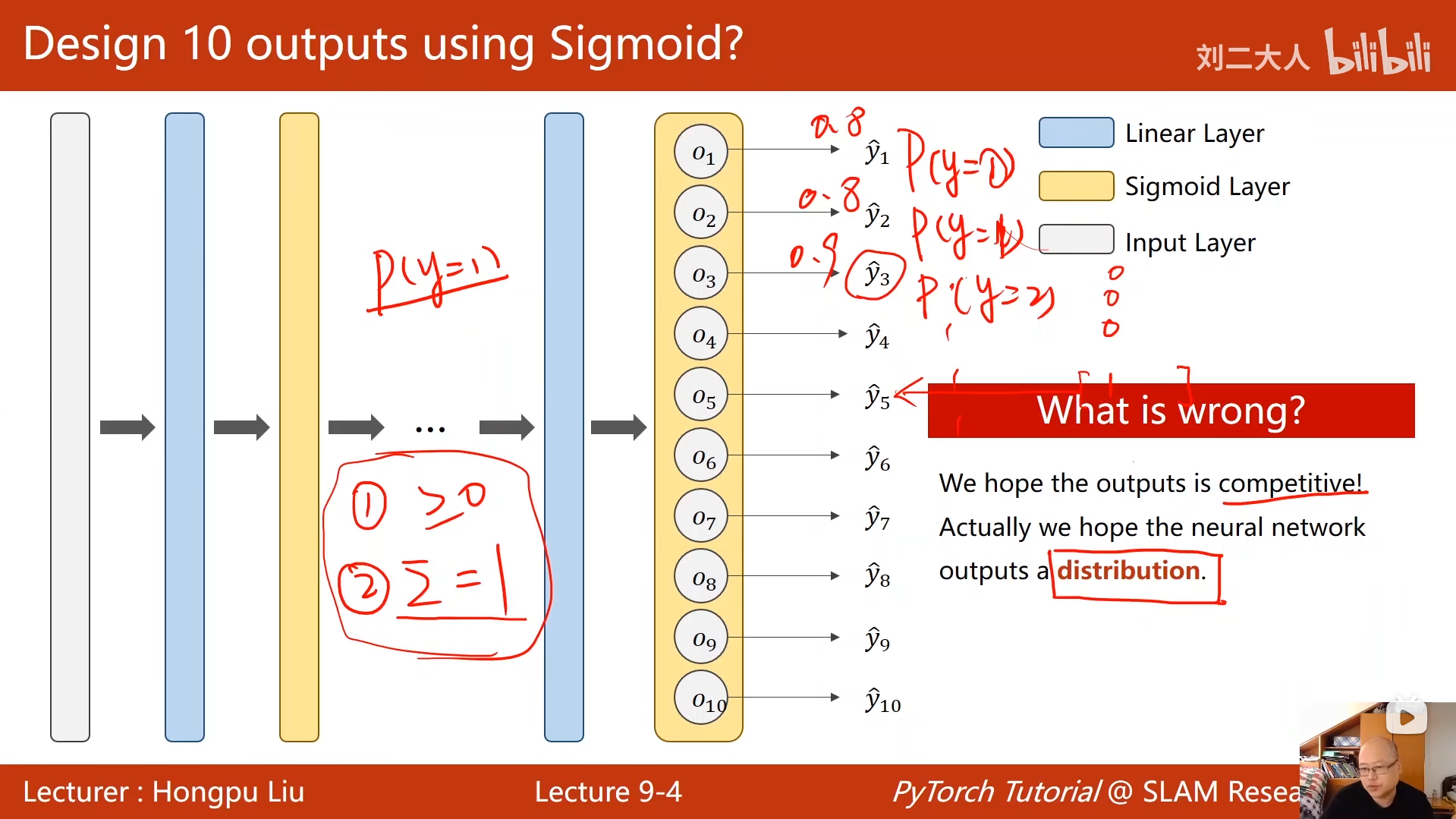
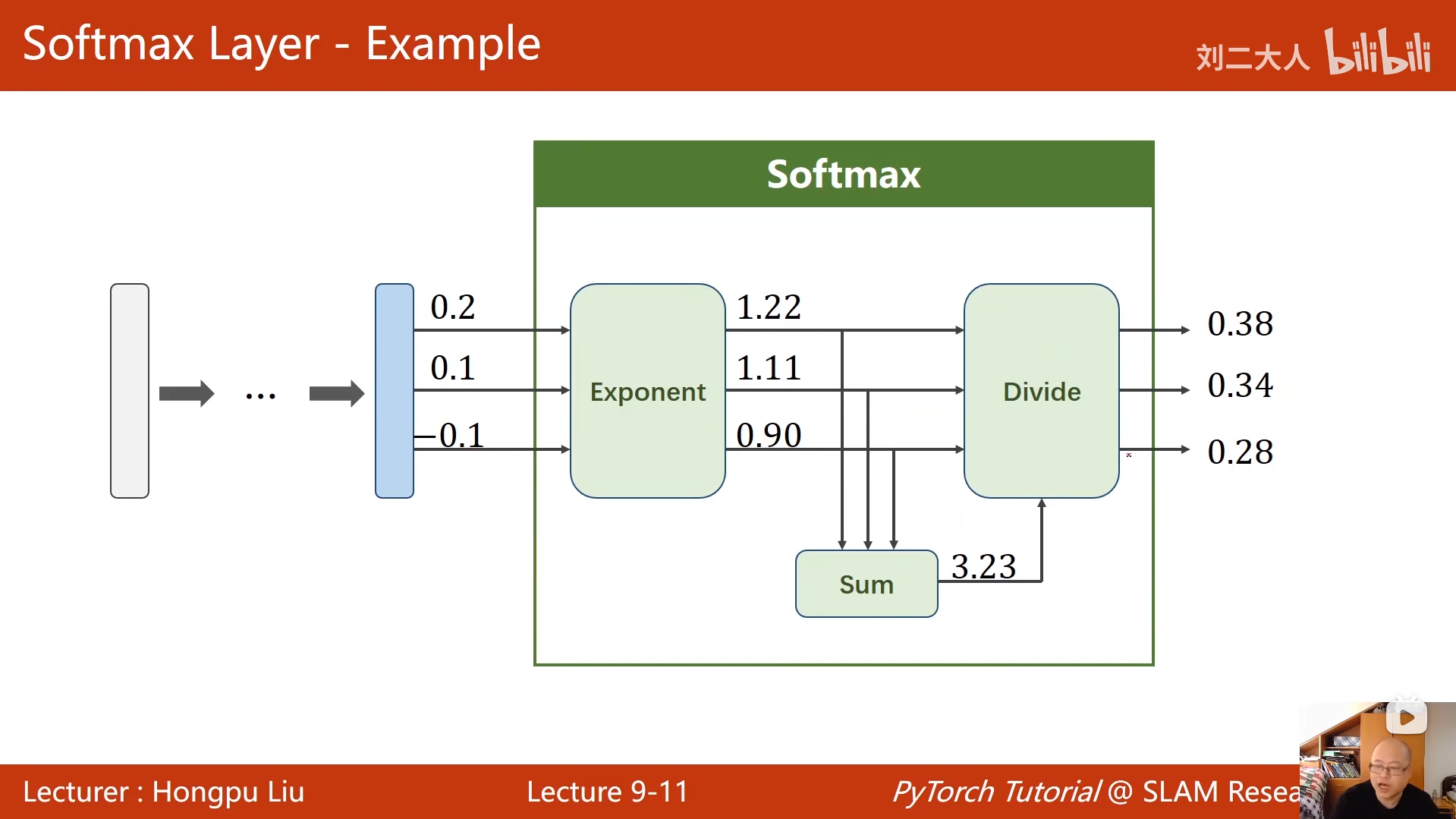
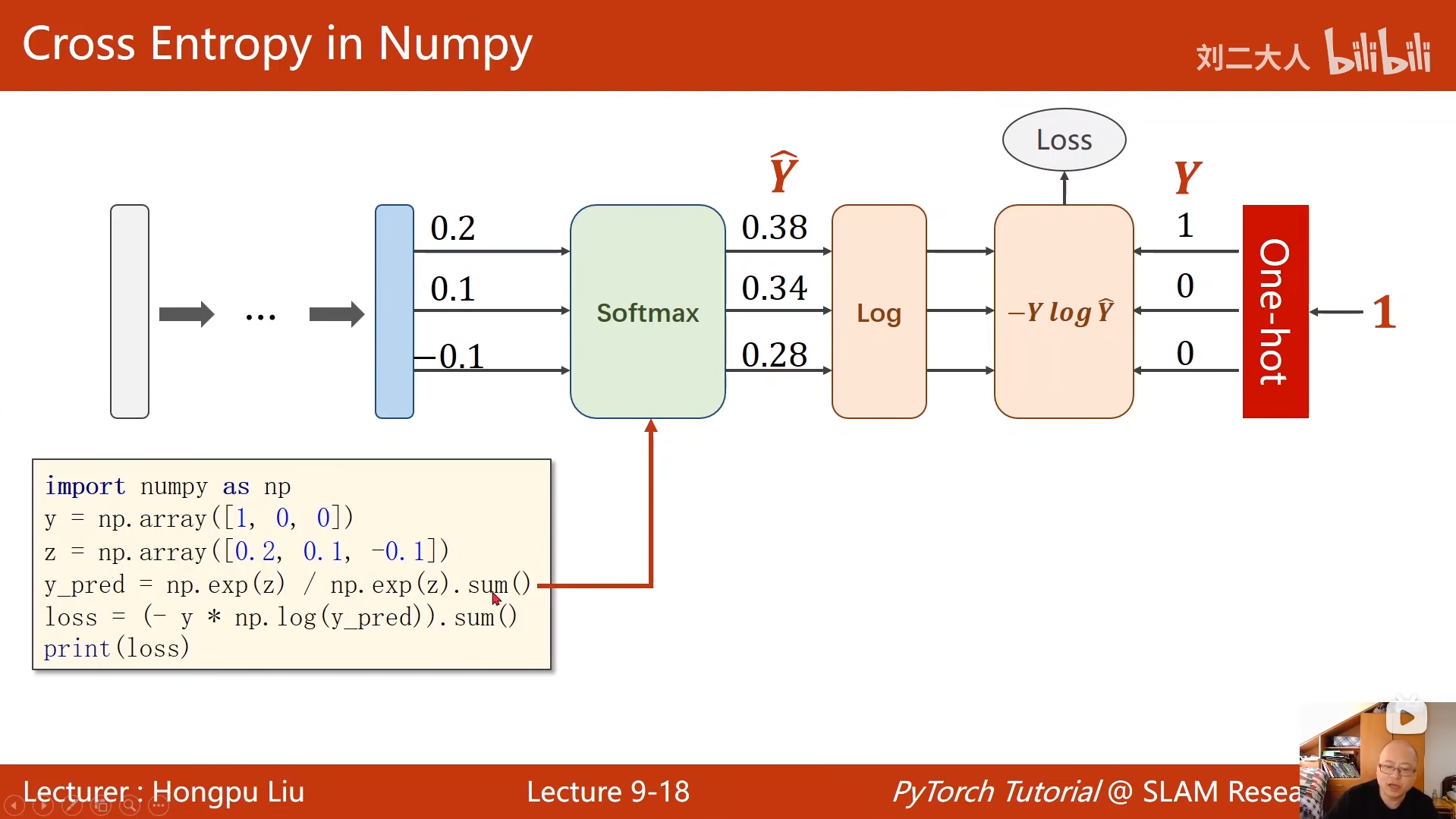
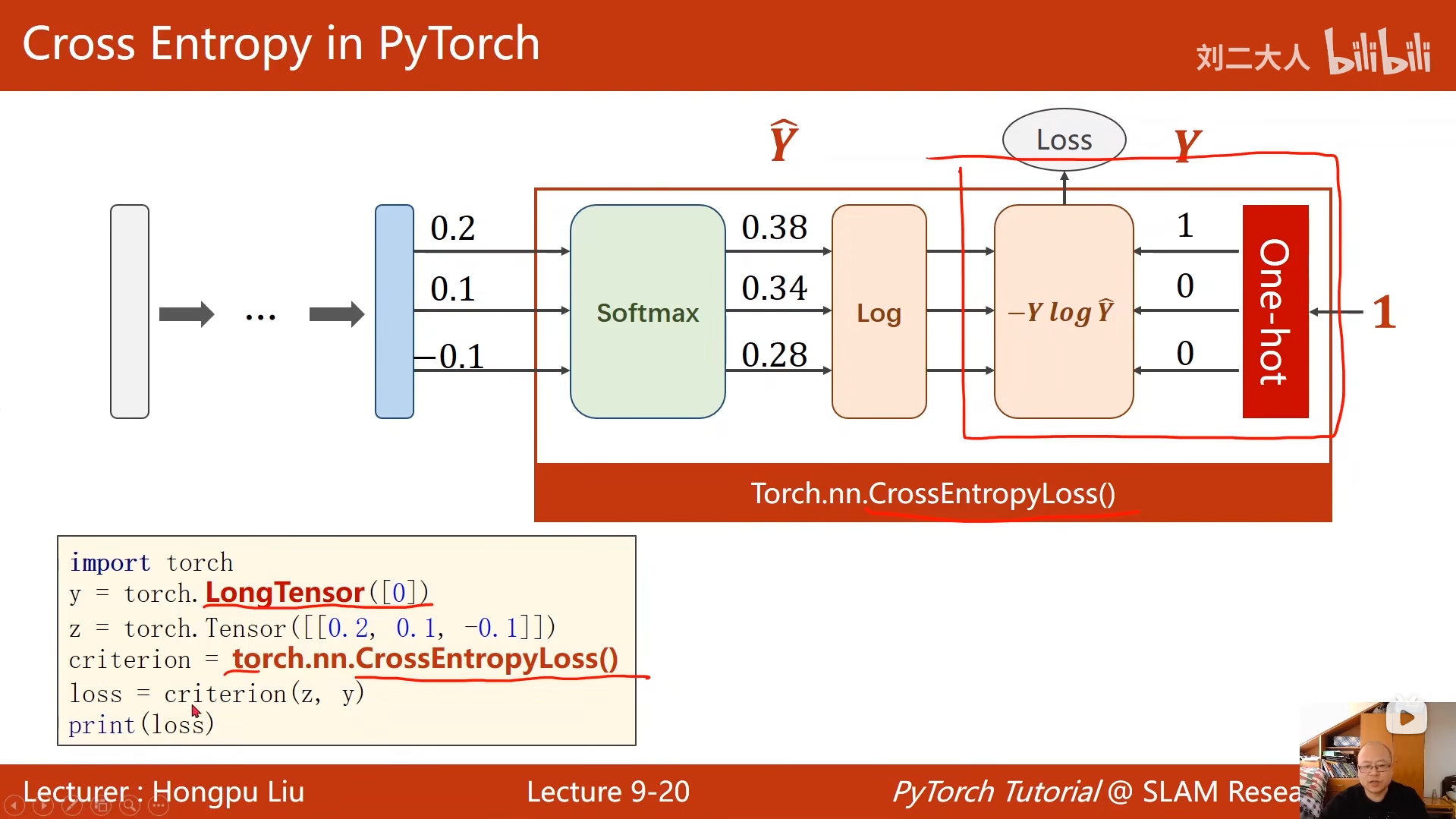
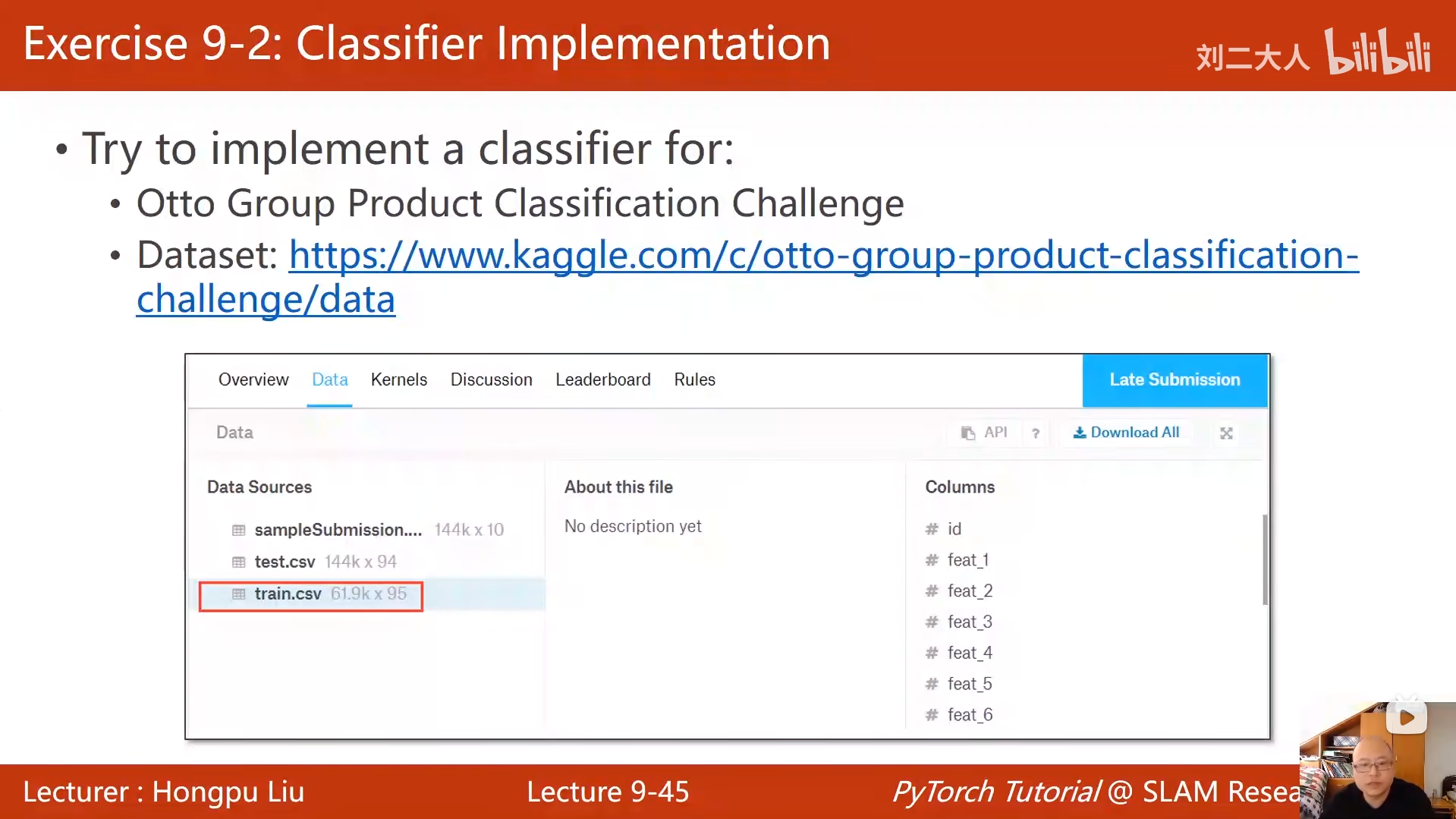
9 多分类问题
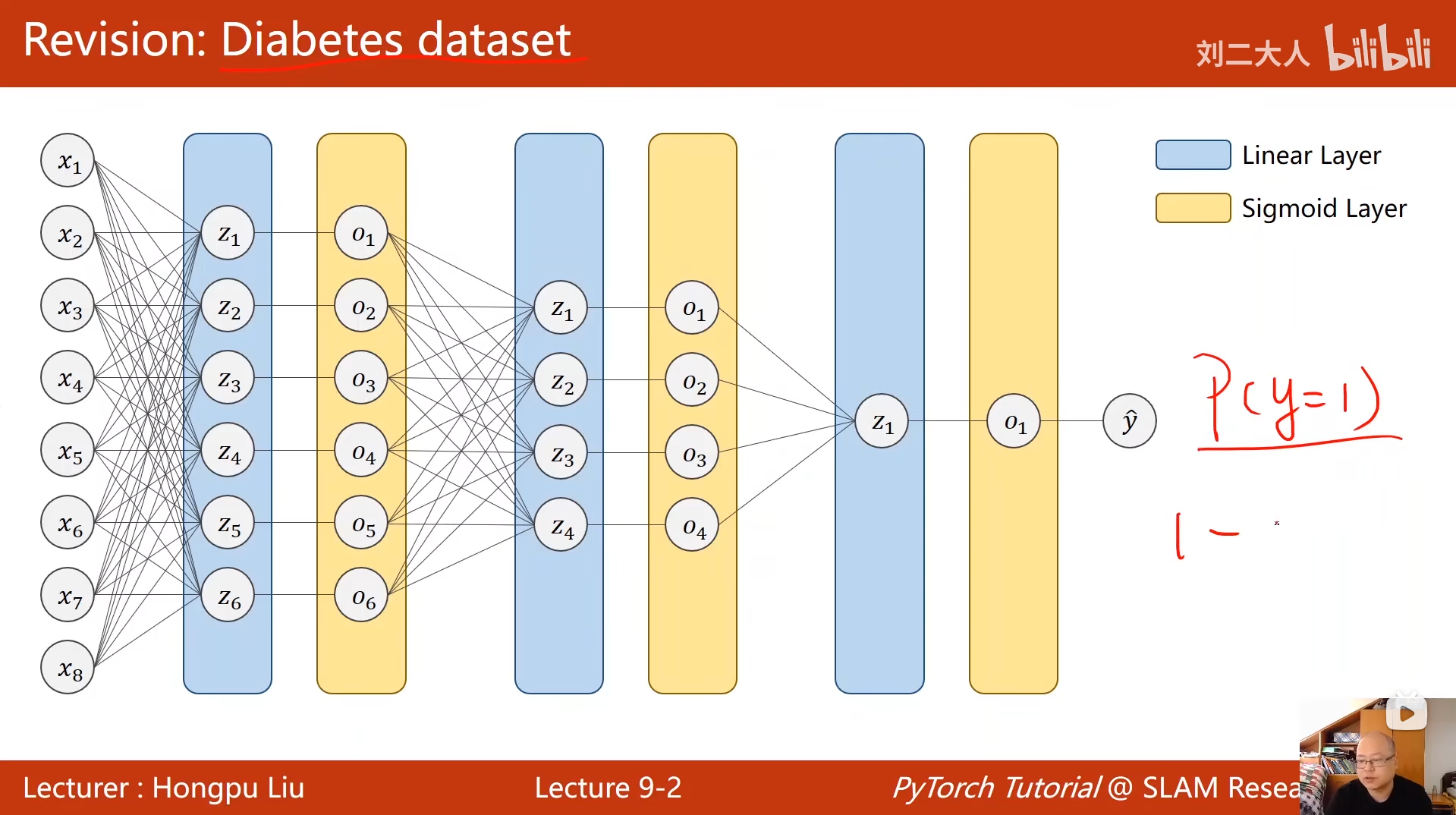









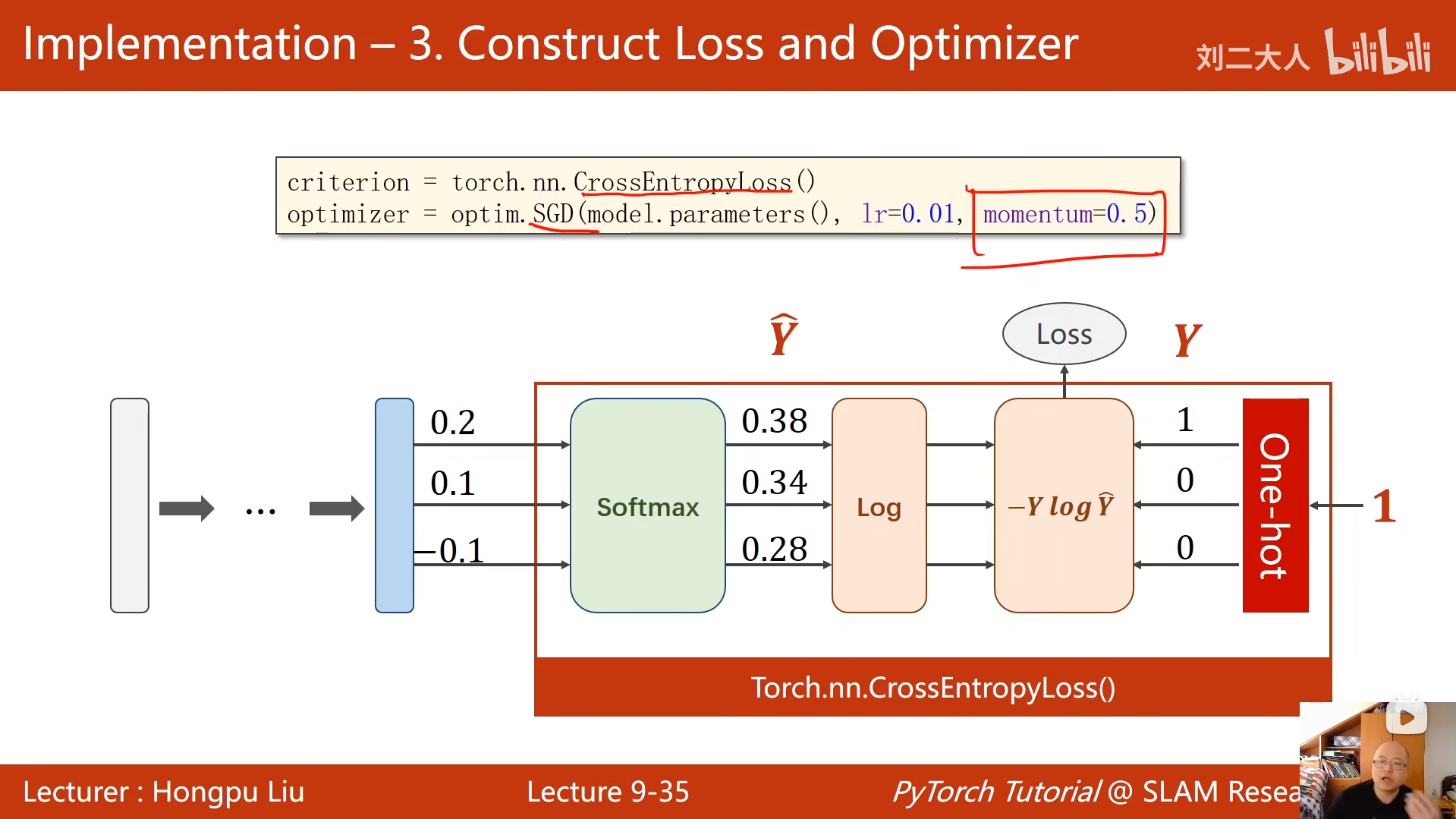
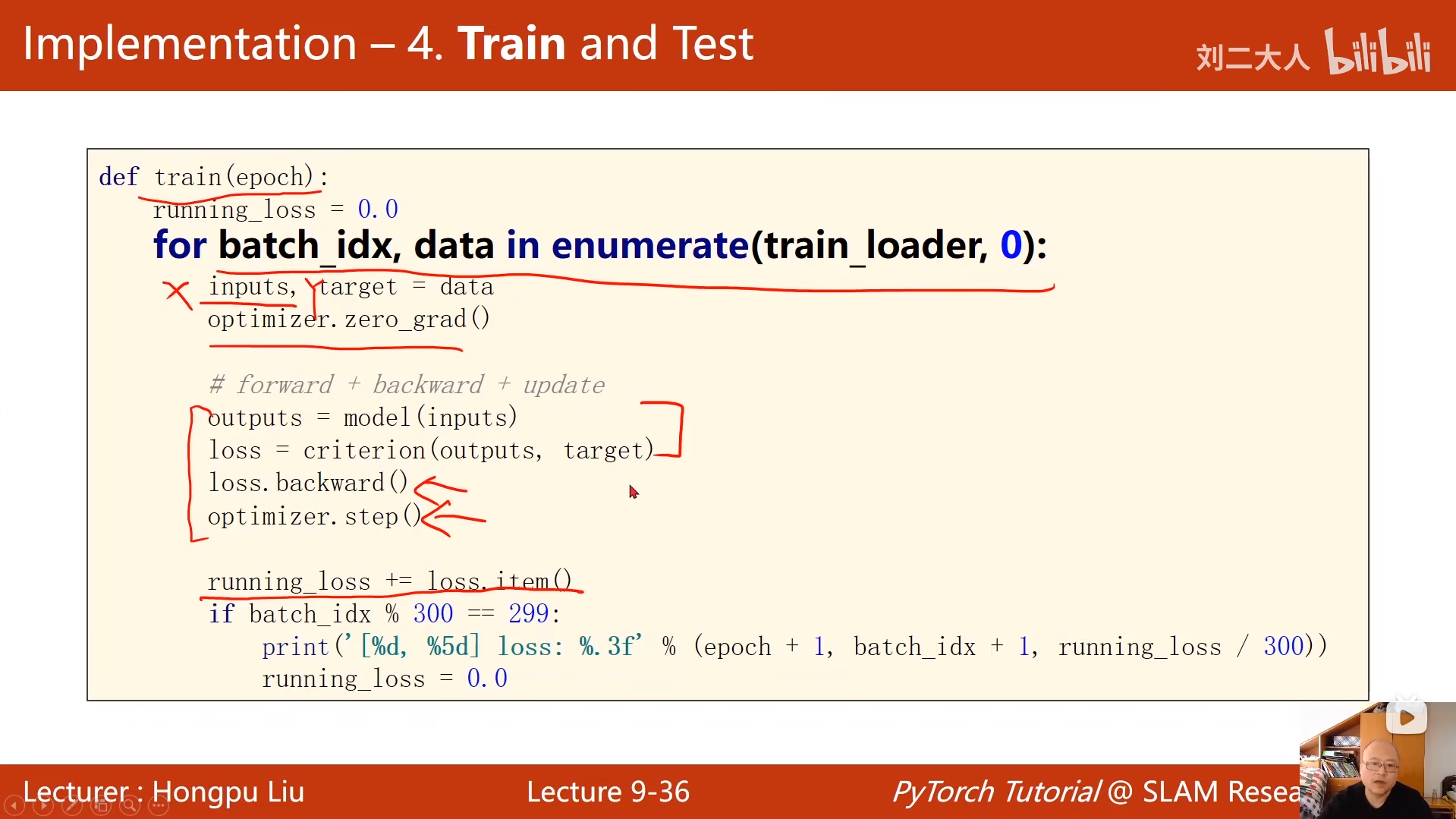
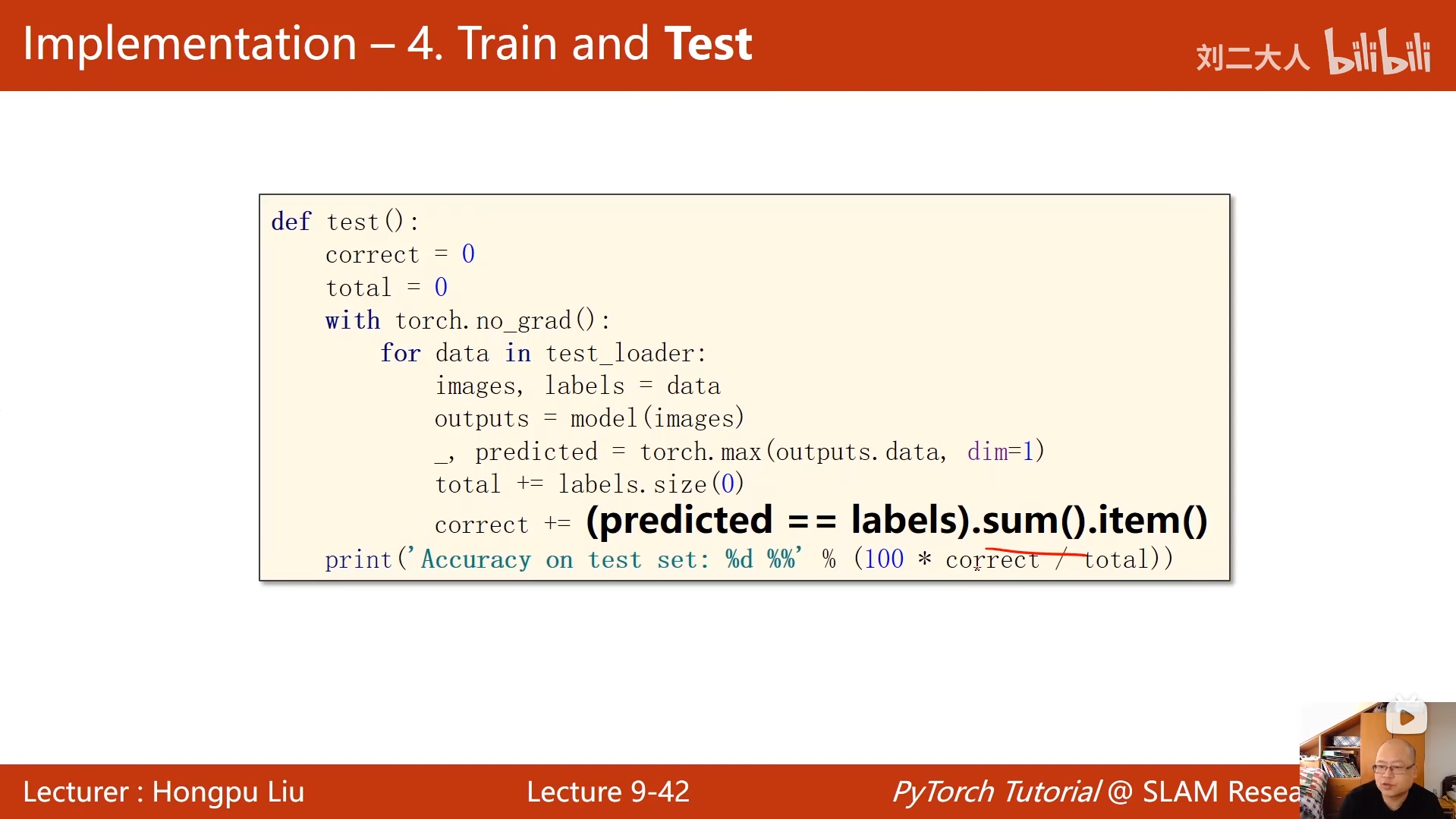

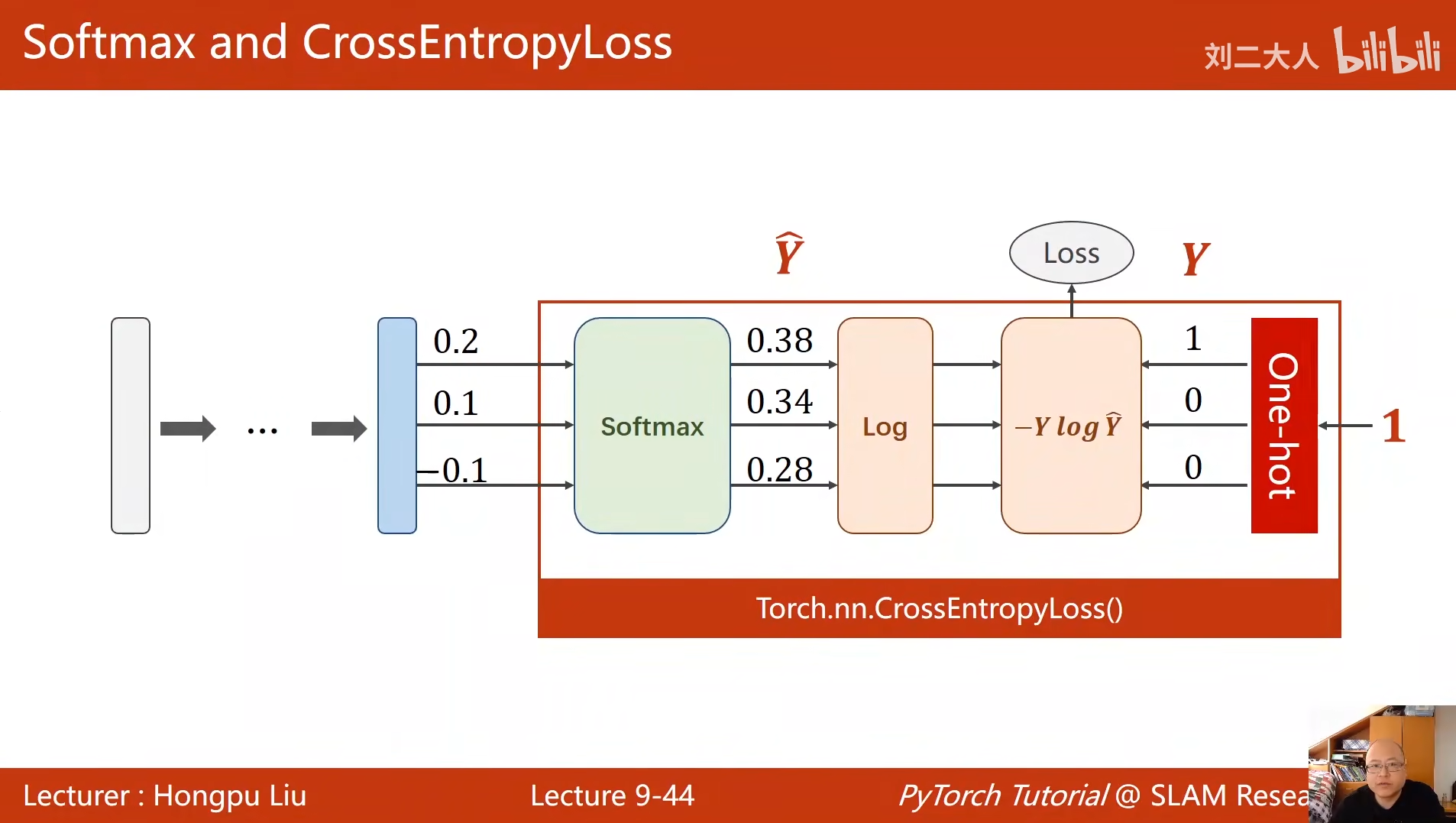
python
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
# 定义图像预处理流水线
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL图像转换为Tensor(范围0~1)
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差归一化
])
# 加载训练集
train_dataset = datasets.MNIST(
root='../dataset/mnist/', # 数据集存储路径
train=True, # 标记为训练集
download=True, # 若本地不存在则自动下载
transform=transform # 应用预处理
)
# 训练集数据加载器
train_loader = DataLoader(
train_dataset,
shuffle=True, # 训练时打乱数据顺序,防止过拟合
batch_size=batch_size # 每批次加载64个样本
)
# 加载测试集
test_dataset = datasets.MNIST(
root='../dataset/mnist/',
train=False, # 标记为测试集
download=True,
transform=transform
)
# 测试集数据加载器
test_loader = DataLoader(
test_dataset,
shuffle=False, # 测试时无需打乱顺序
batch_size=batch_size
)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 定义5层全连接层
self.l1 = torch.nn.Linear(784, 512) # 输入: 28x28=784 → 隐藏层1: 512
self.l2 = torch.nn.Linear(512, 256) # 隐藏层1 → 隐藏层2: 256
self.l3 = torch.nn.Linear(256, 128) # 隐藏层2 → 隐藏层3: 128
self.l4 = torch.nn.Linear(128, 64) # 隐藏层3 → 隐藏层4: 64
self.l5 = torch.nn.Linear(64, 10) # 隐藏层4 → 输出层: 10(对应MNIST 10个数字类别)
def forward(self, x):
# 将输入张量展平为 (batch_size, 784),-1 表示自动计算 batch 维度
x = x.view(-1, 784)
# 前向传播:逐层经过 ReLU 激活函数
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 最后一层不激活,直接输出 logits(交给 CrossEntropyLoss 处理)
return self.l5(x)
# 实例化模型
model = Net()
# 定义损失函数:交叉熵损失(多分类任务标配)
criterion = torch.nn.CrossEntropyLoss()
# 定义优化器:带动量的随机梯度下降(SGD with momentum)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
# 遍历训练集,enumerate同时获取批次索引和数据,索引起始为0
for batch_idx, data in enumerate(train_loader, 0):
# 解包数据:输入样本和对应标签
inputs, target = data
# 梯度清零:避免上一批次的梯度累积到当前批次
optimizer.zero_grad()
# forward + backward + update
# 前向传播:模型根据输入得到预测输出
outputs = model(inputs)
# 计算损失:对比预测输出与真实标签
loss = criterion(outputs, target)
# 反向传播:计算梯度
loss.backward()
# 更新参数:根据梯度优化模型权重
optimizer.step()
# 累加当前批次的损失值(.item()取出标量值,避免计算图占用内存)
running_loss += loss.item()
# 每300个批次打印一次平均损失
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0 # 记录预测正确的样本数
total = 0 # 记录测试集总样本数
# 关闭梯度计算,节省内存、加速推理(测试时不需要反向传播)
with torch.no_grad():
# 遍历测试集数据
for data in test_loader:
images, labels = data # 解包测试样本和标签
outputs = model(images) # 前向传播,得到模型预测输出
# 取每行最大值的索引,即预测类别(_ 是最大值本身,不需要)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0) # 累加当前批次的样本数
correct += (predicted == labels).sum().item() # 累加预测正确的样本数
# 打印测试集准确率
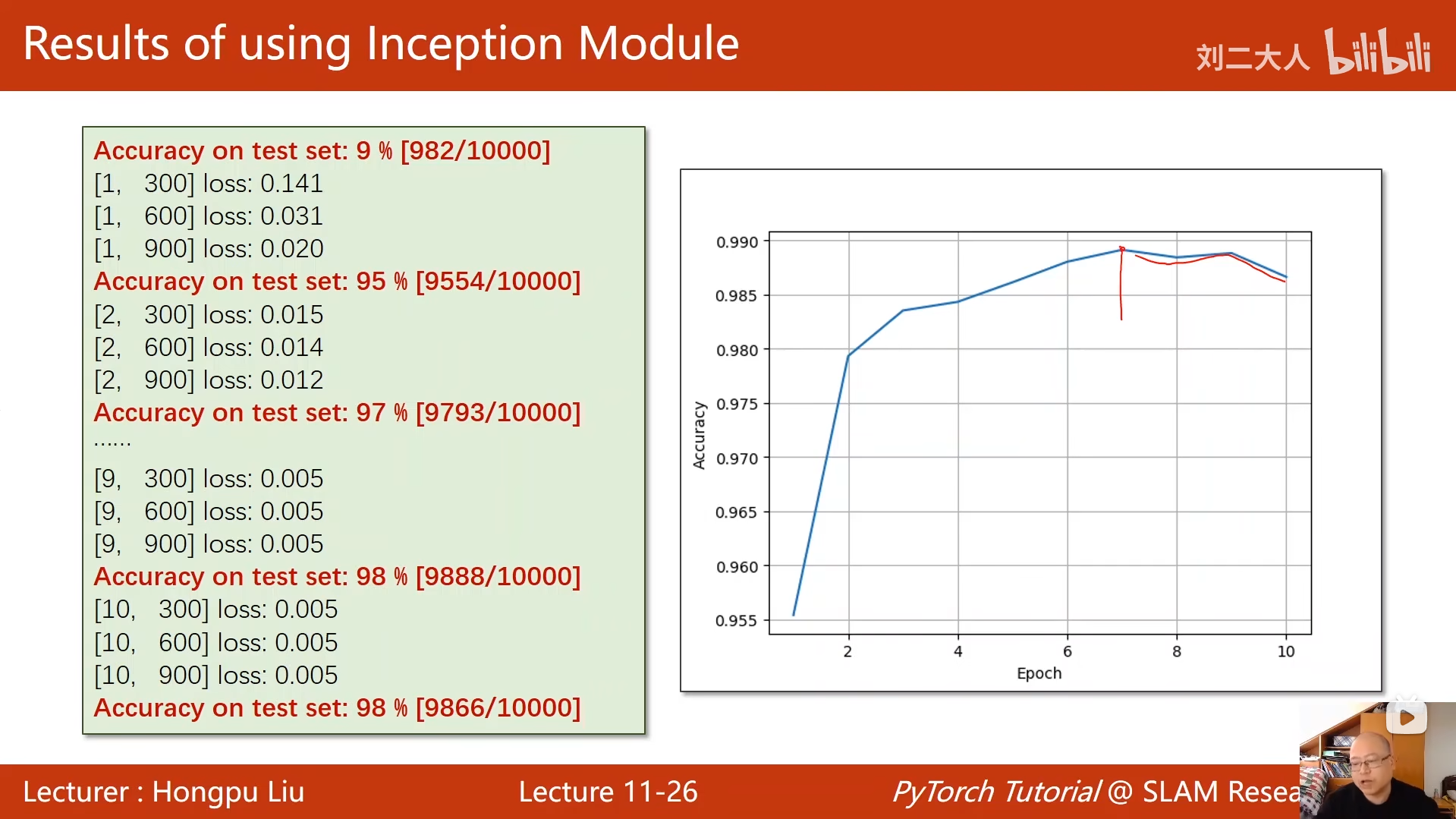
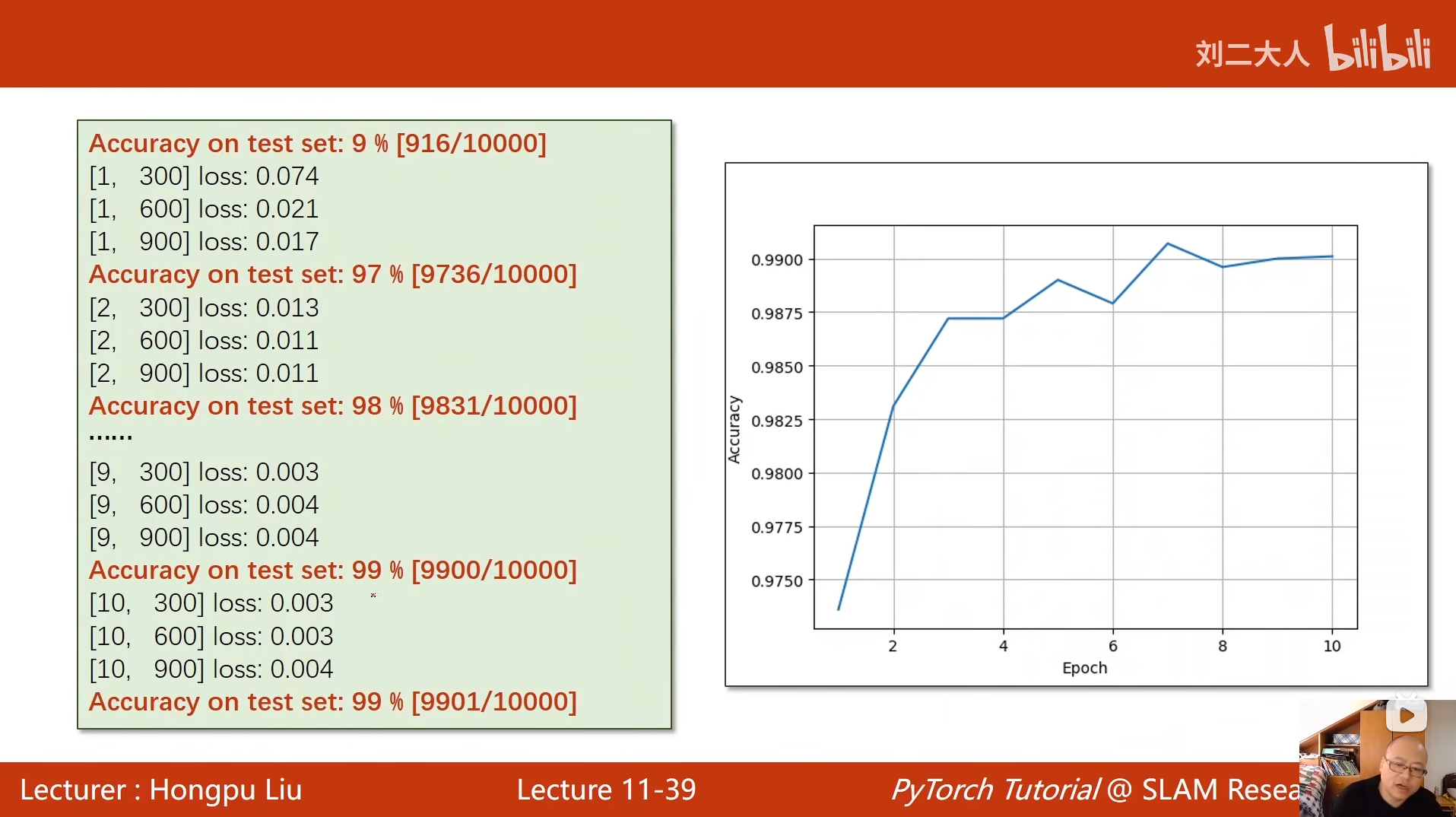
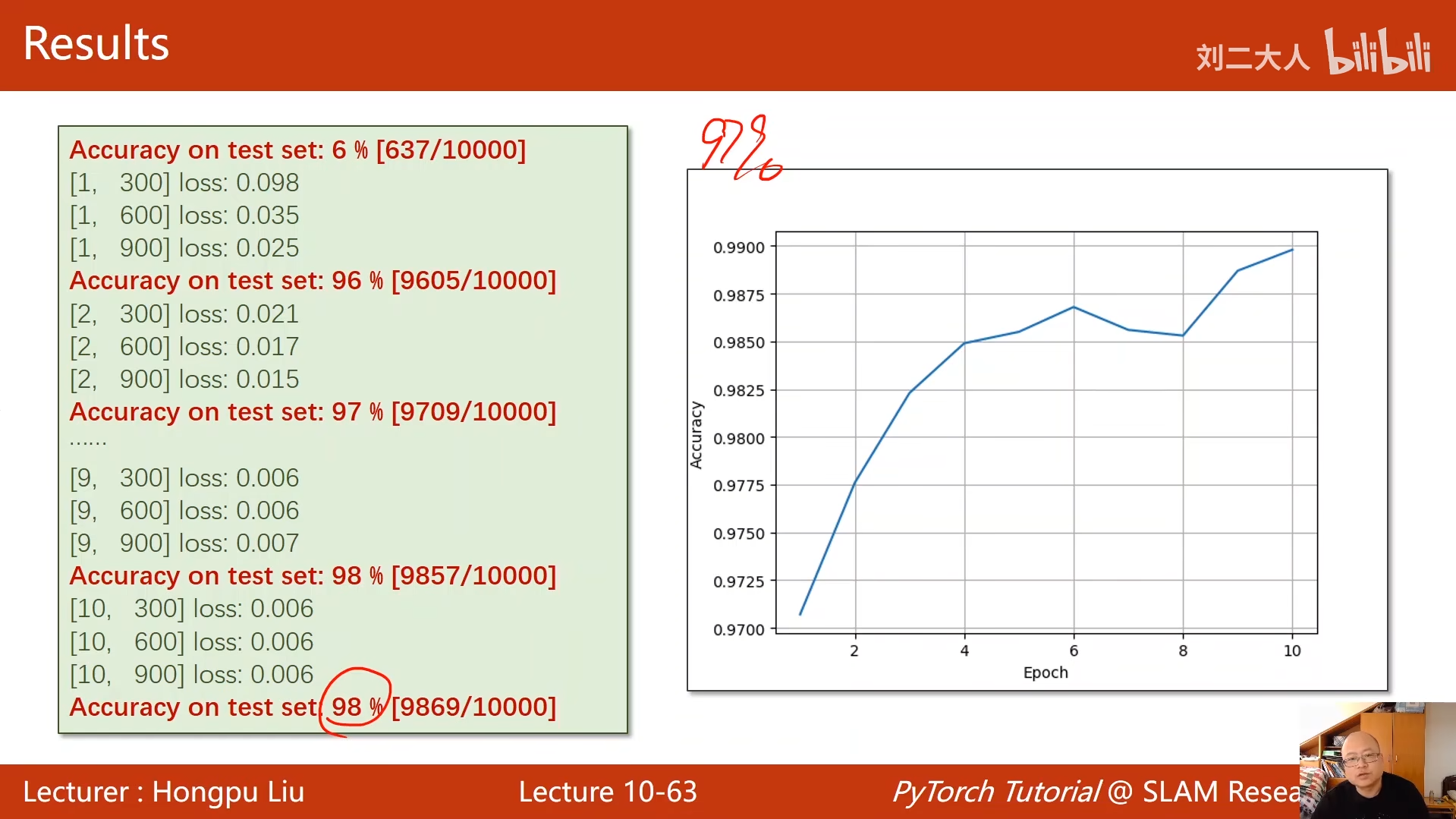
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
# 训练 10 个 epoch(epoch 取值为 0~9,共10轮)
for epoch in range(10):
train(epoch) # 执行当前轮次的训练
test() # 训练后立即在测试集上评估模型性能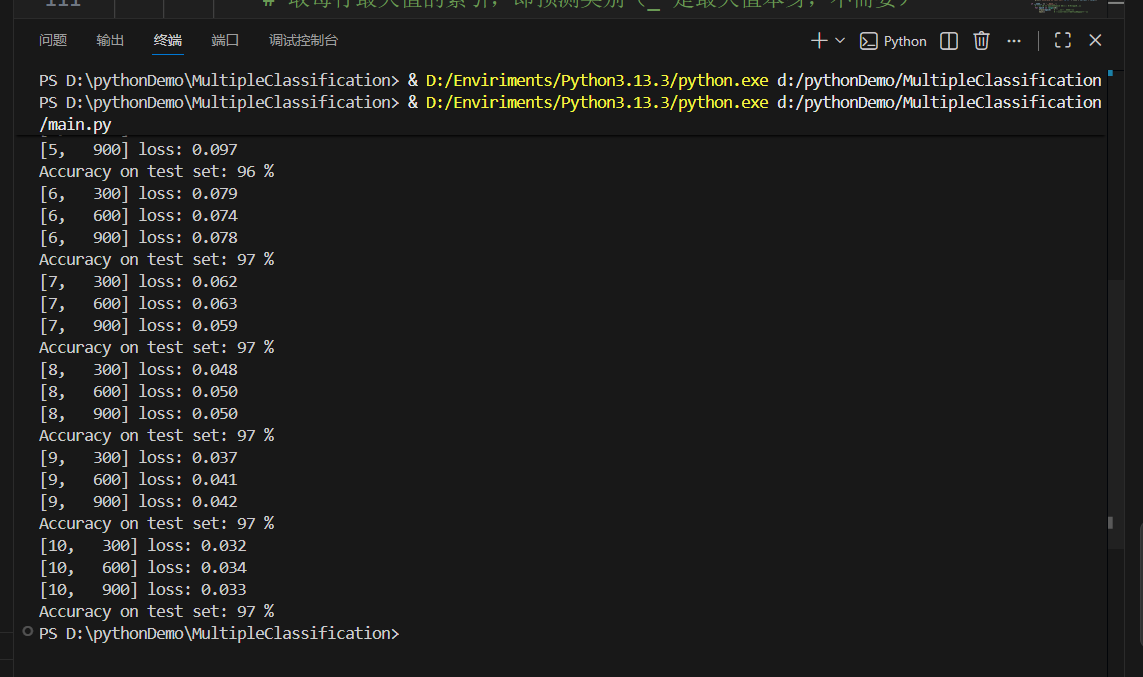
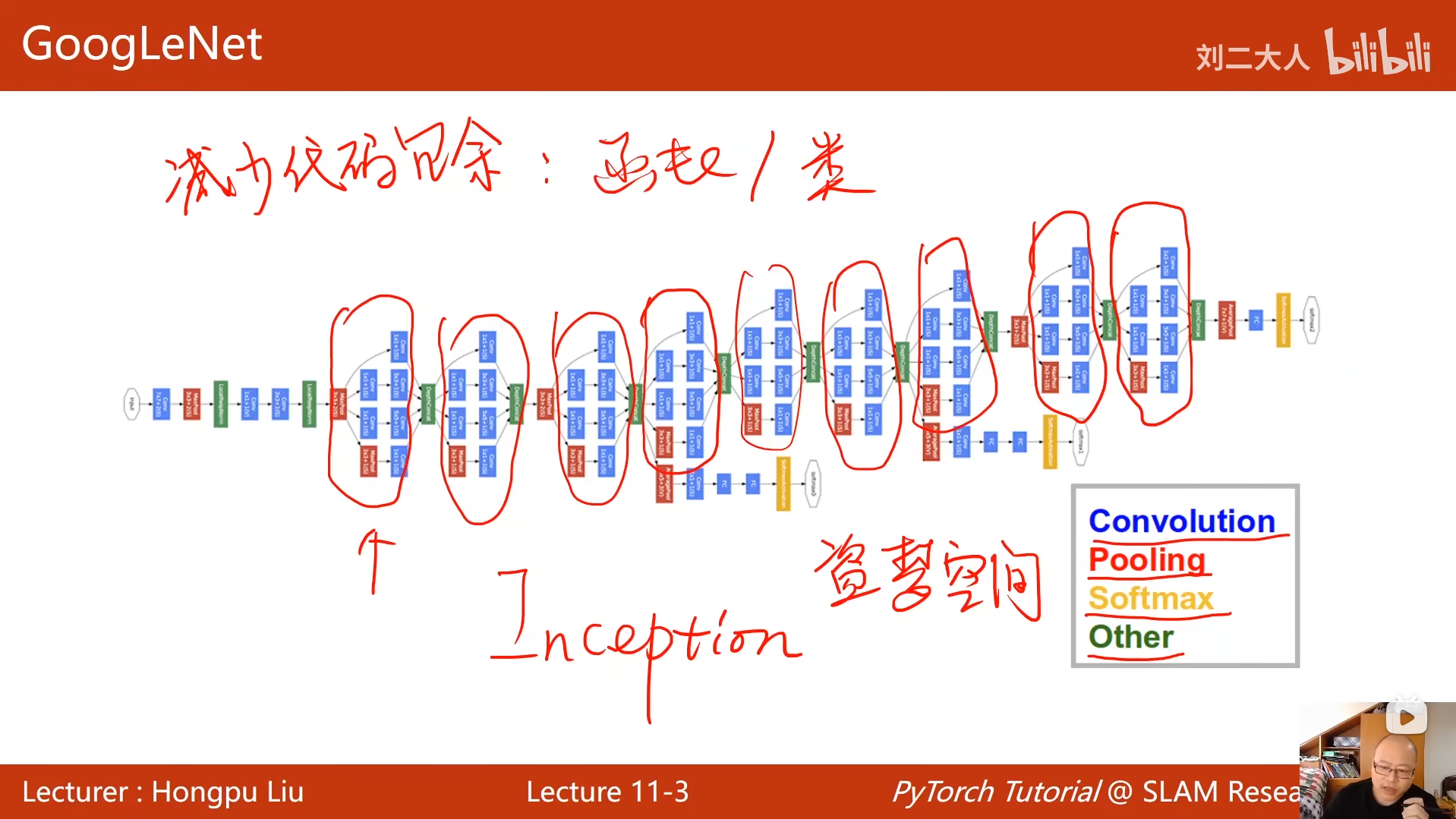
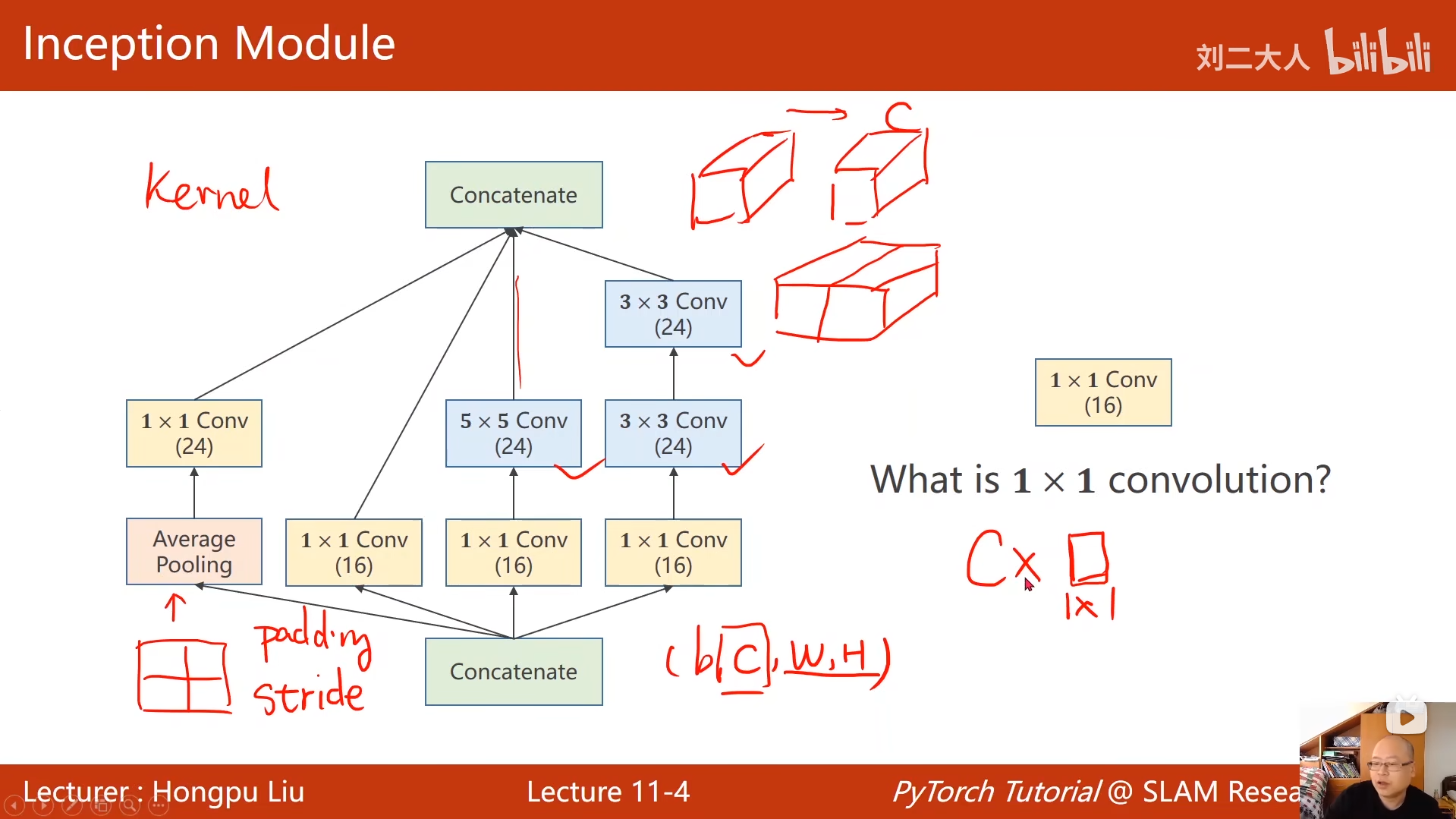
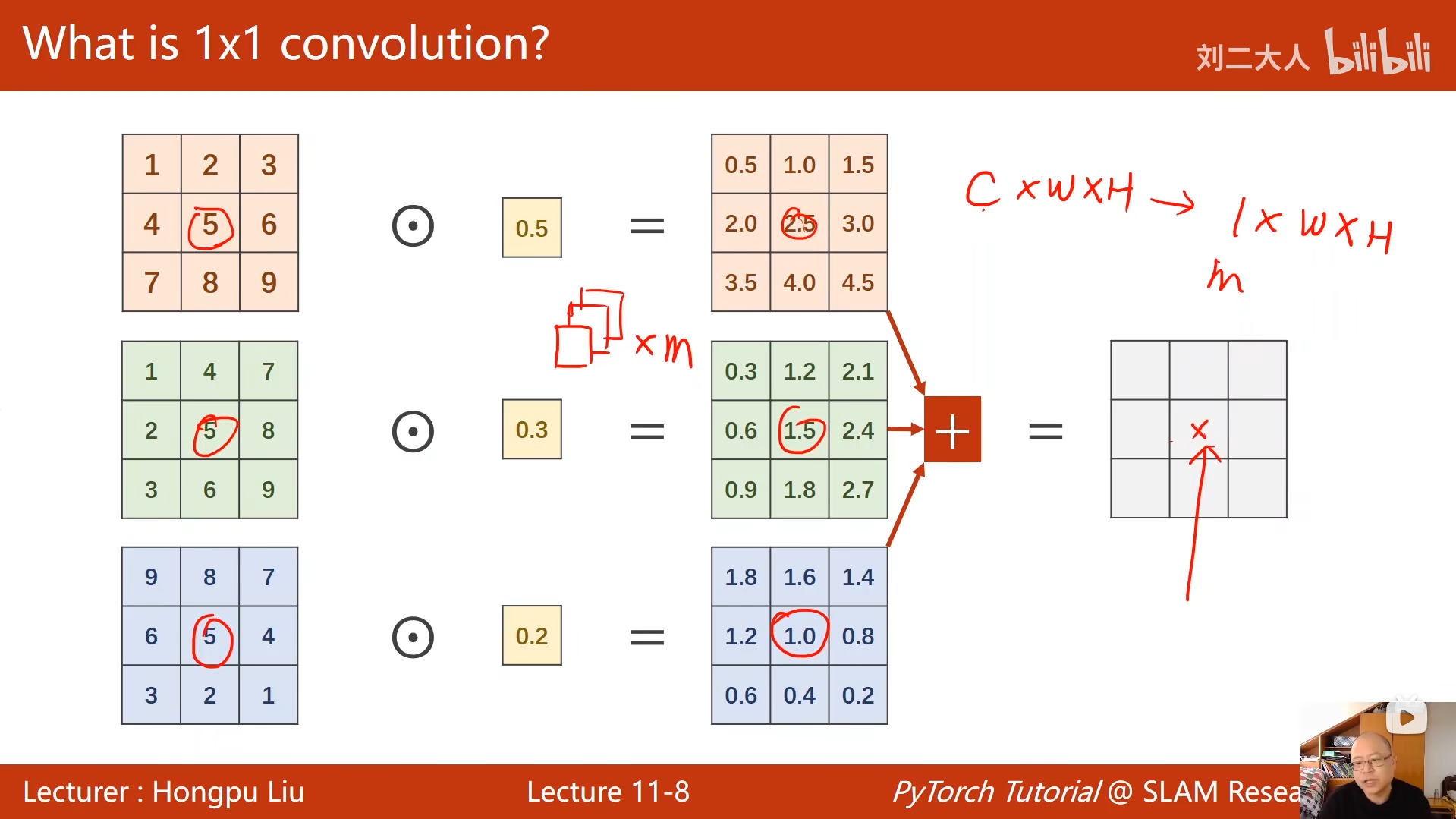
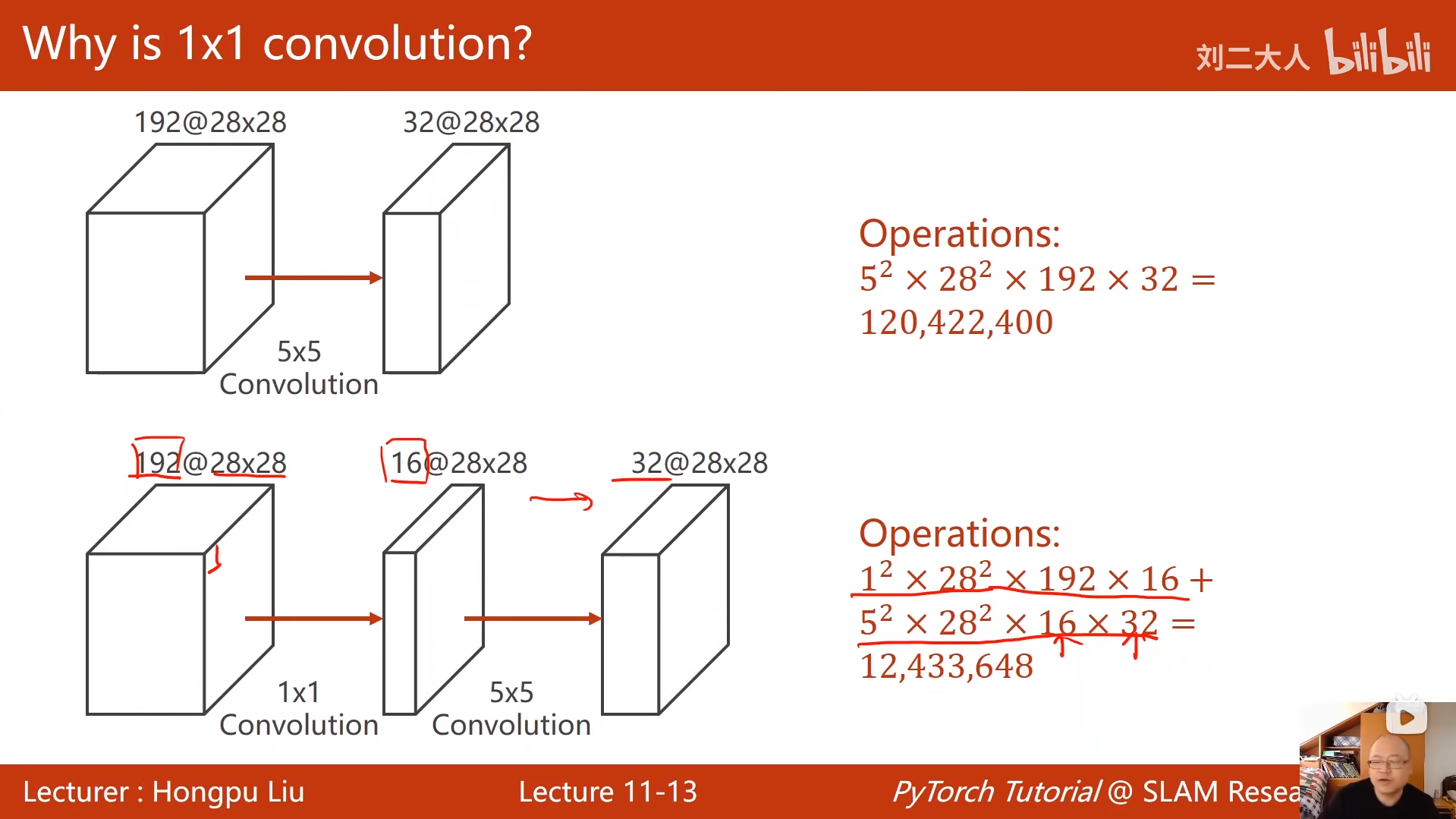
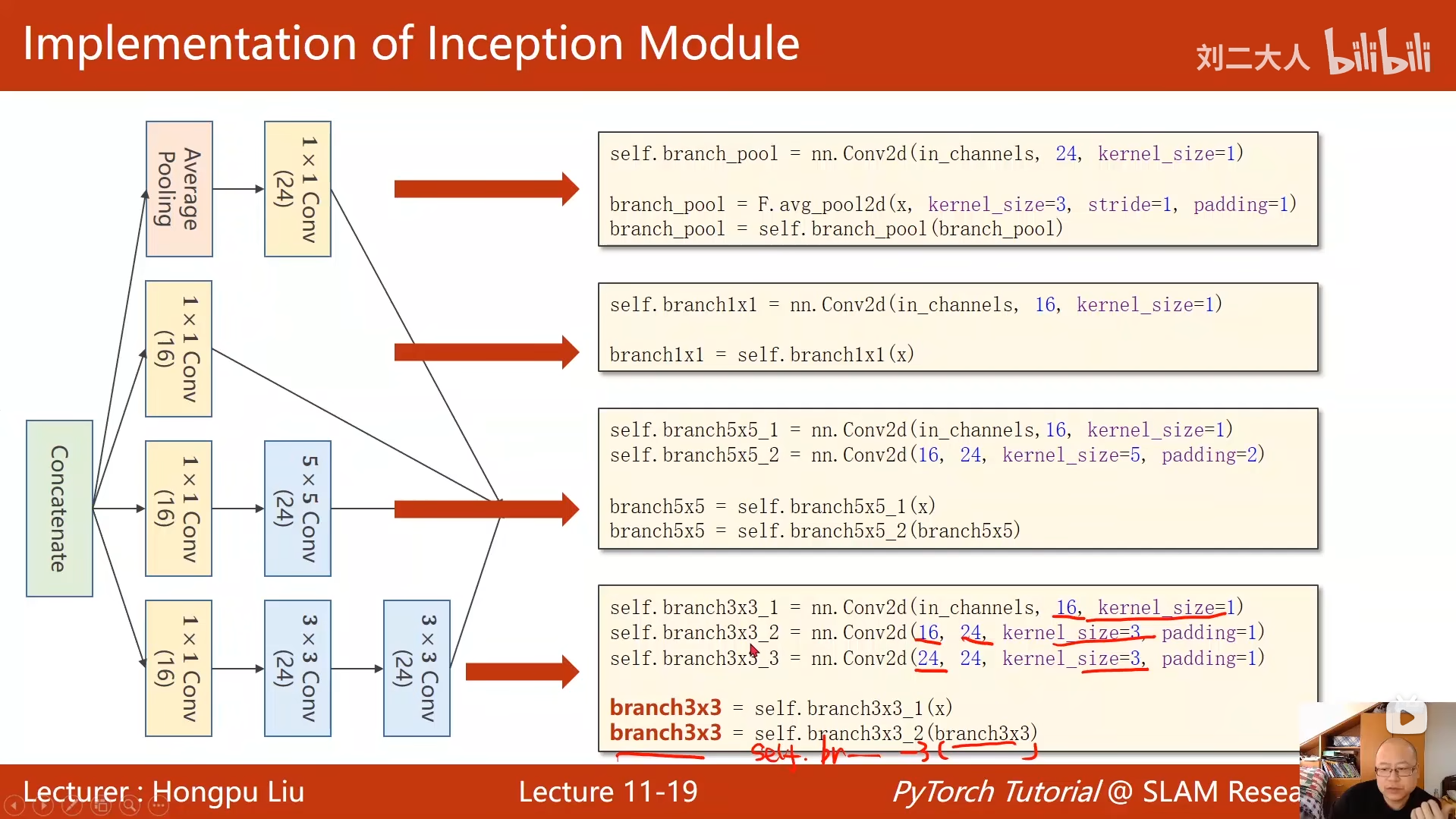
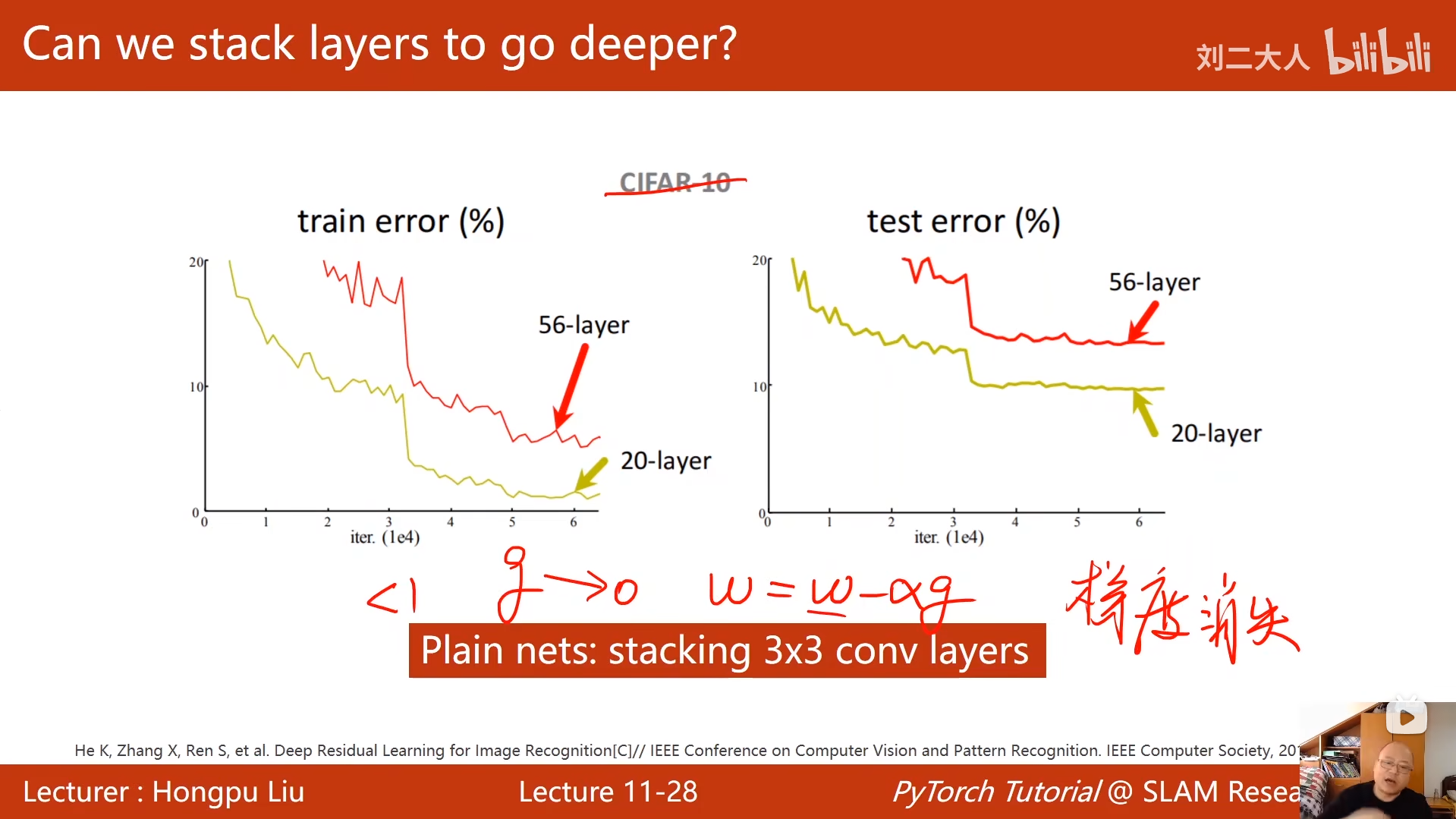
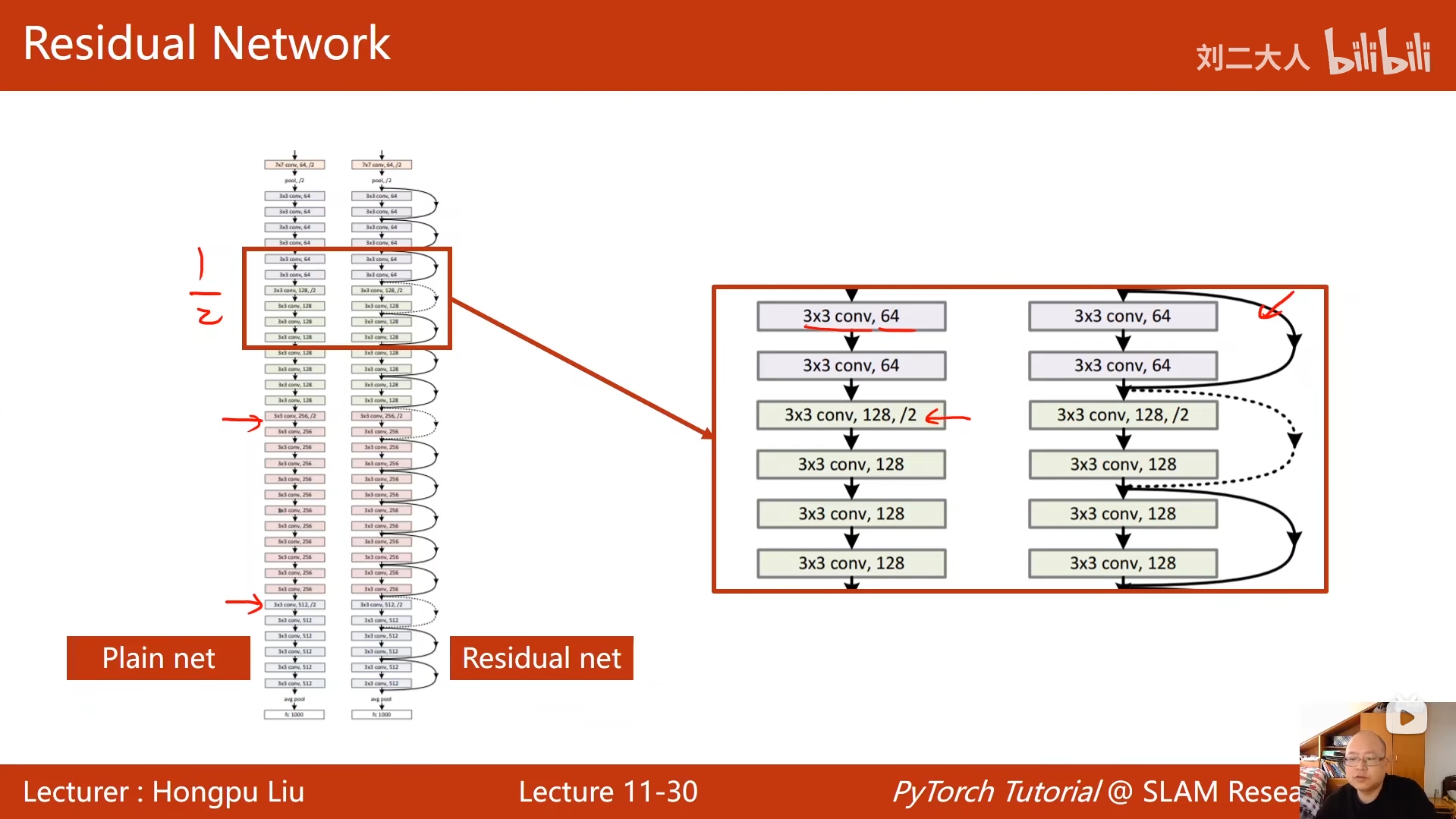
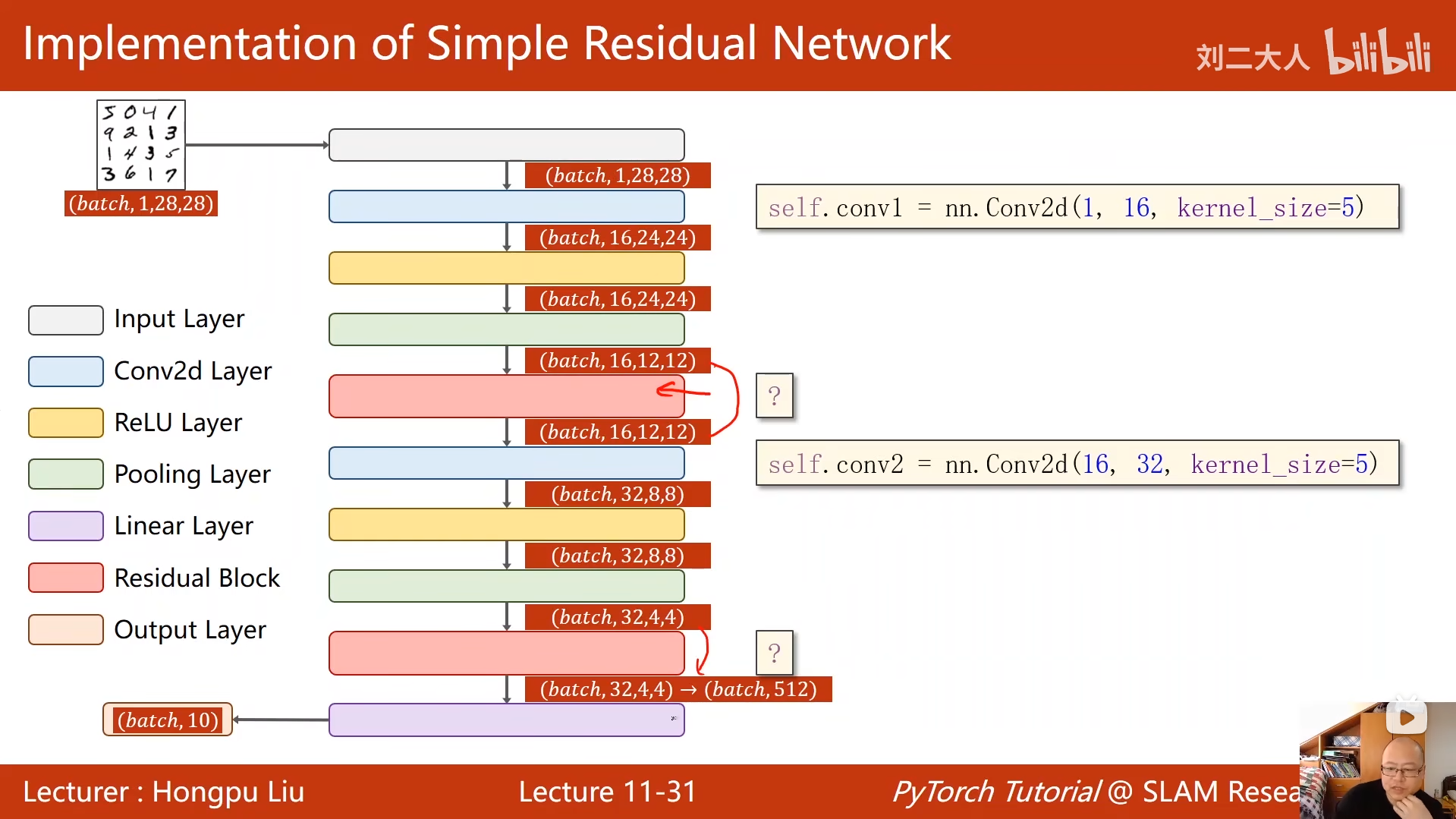
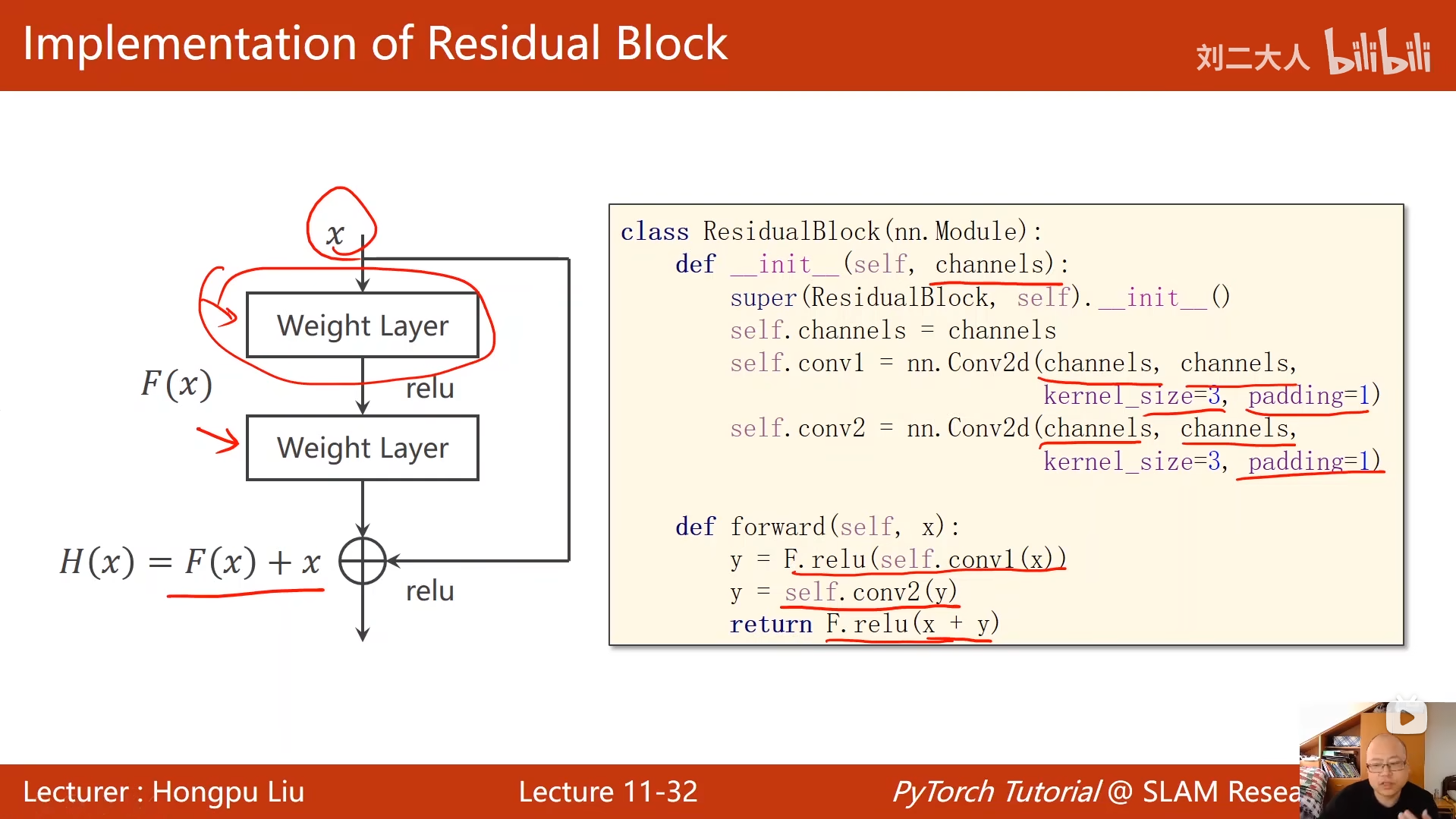
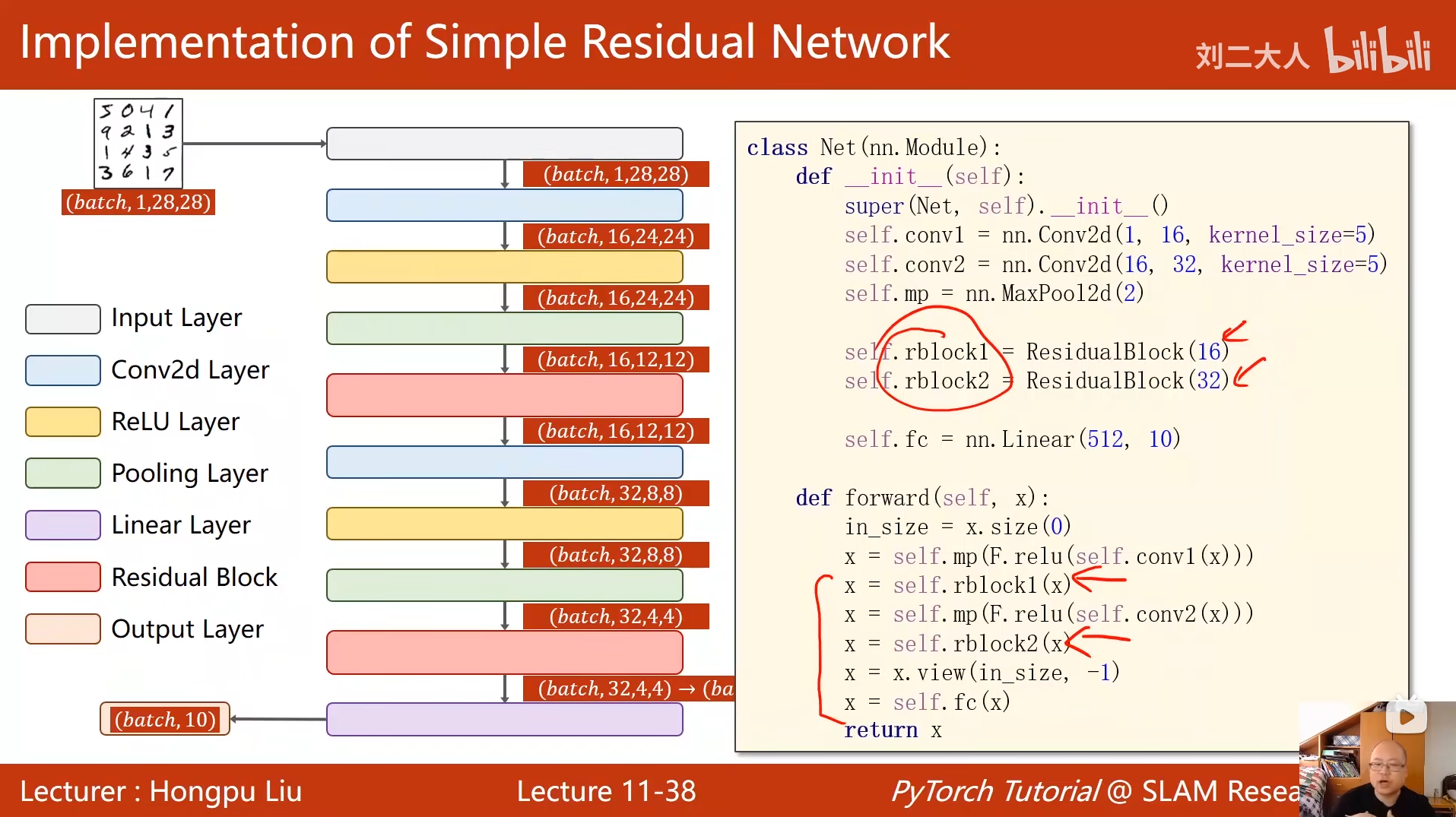
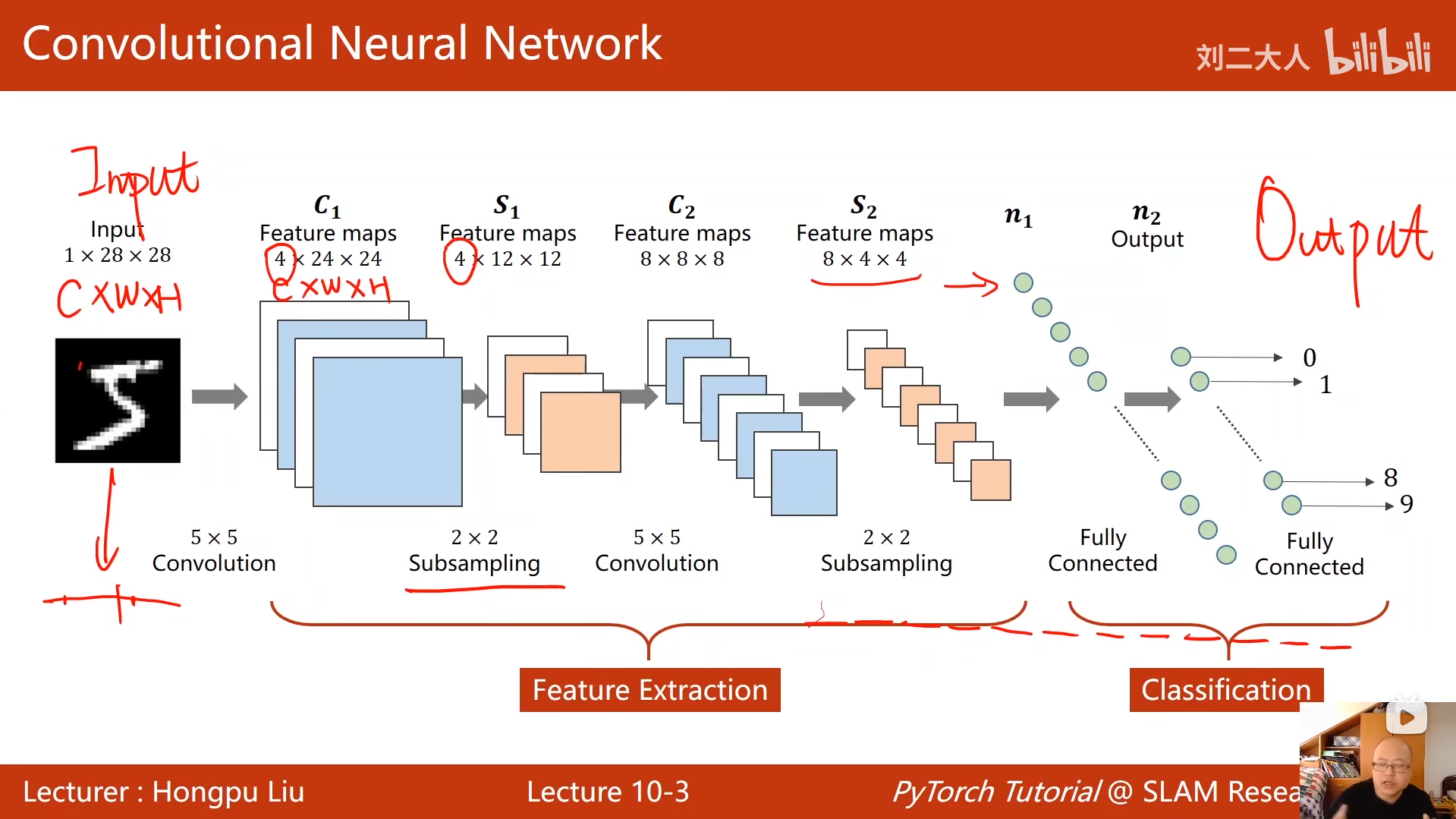
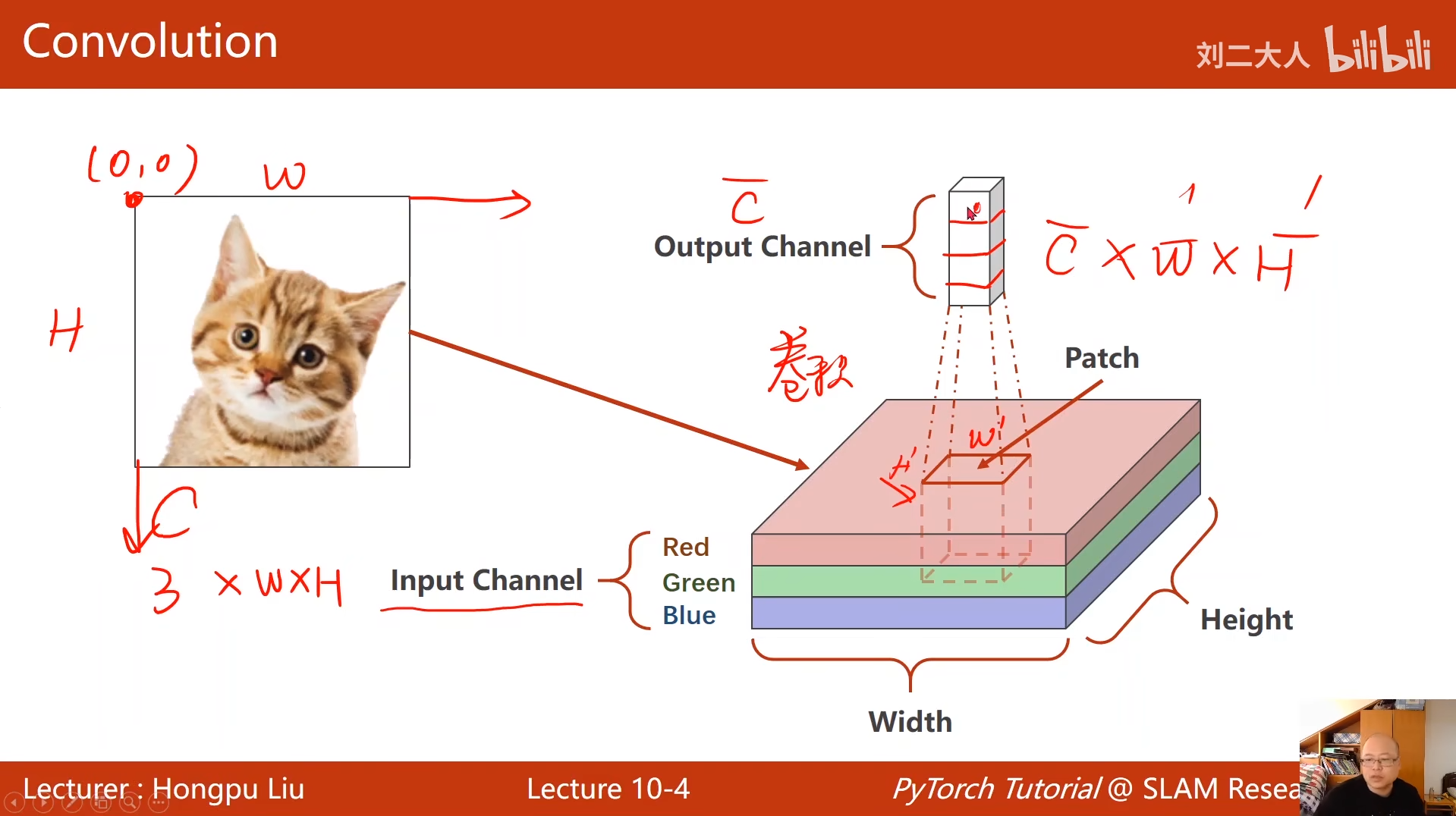
10 卷积神经网络(基础篇)
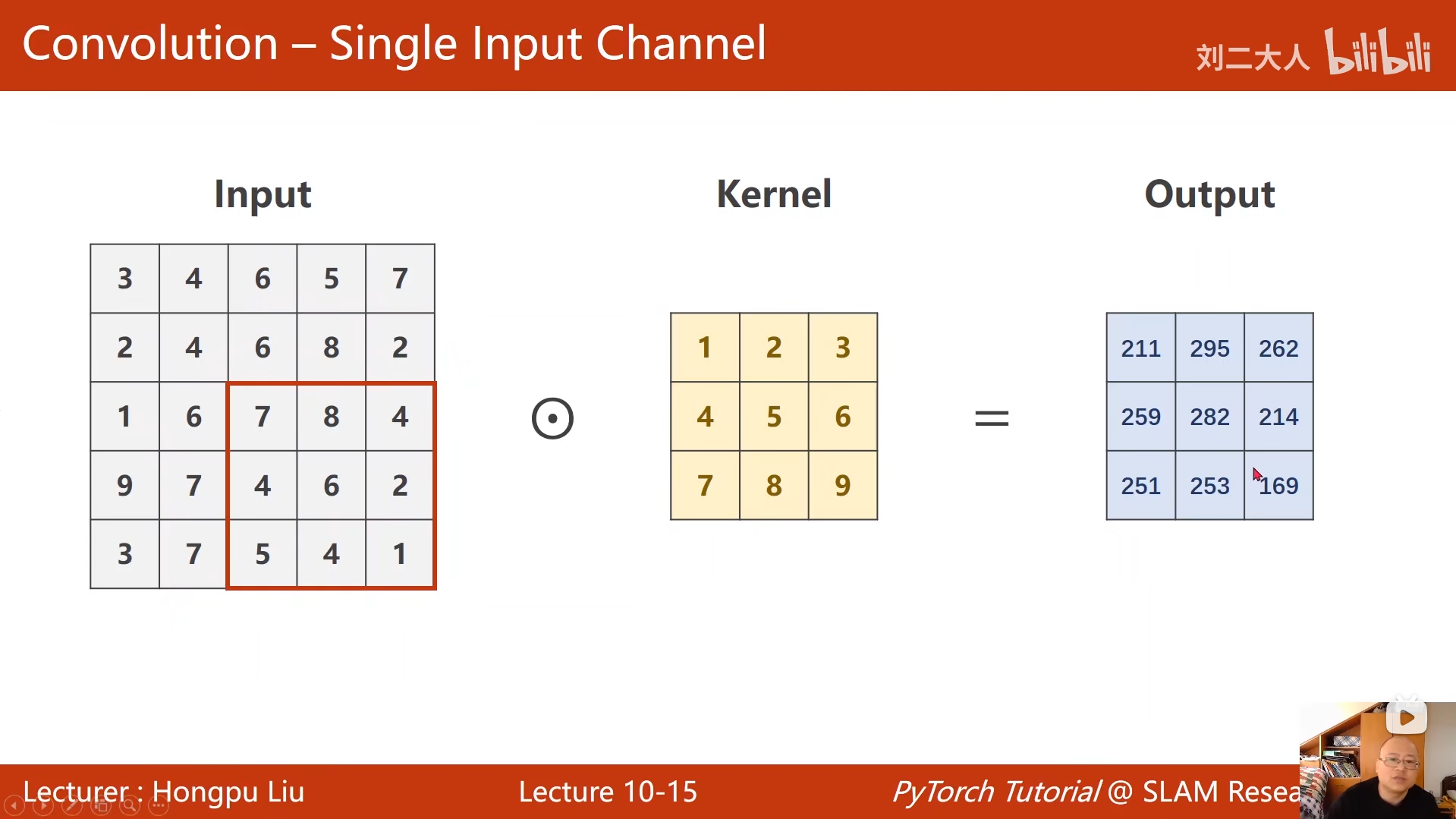
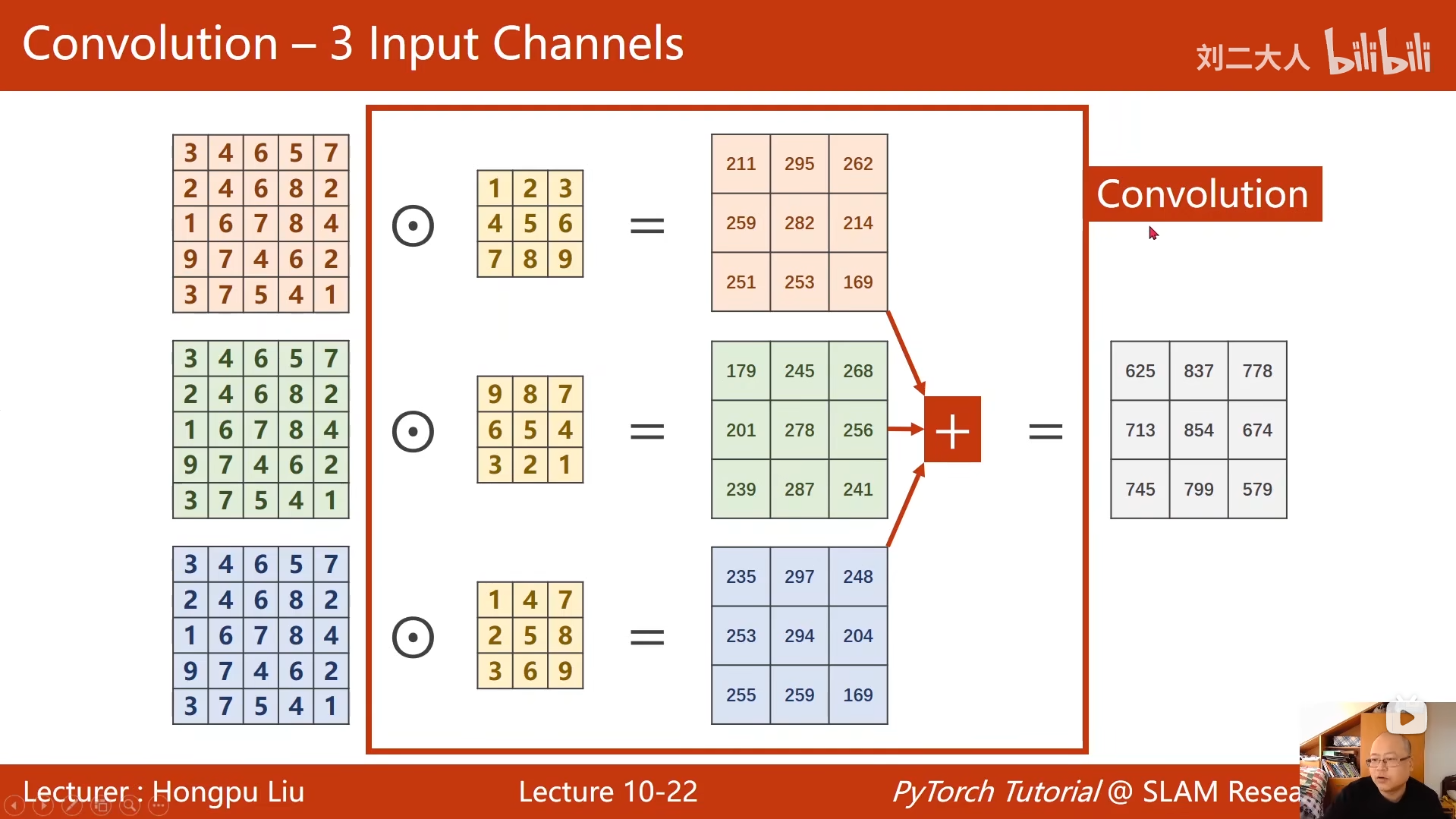
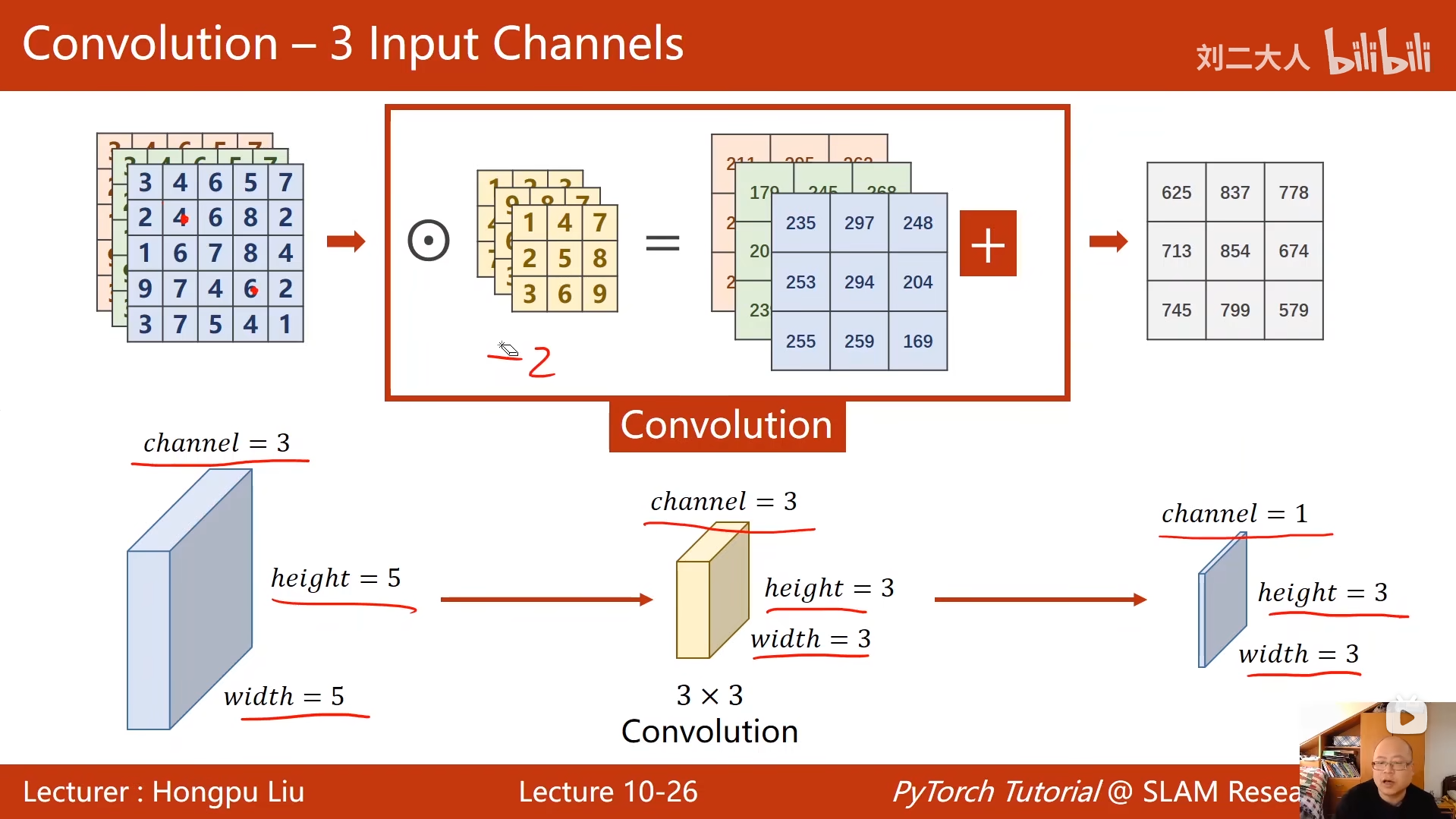
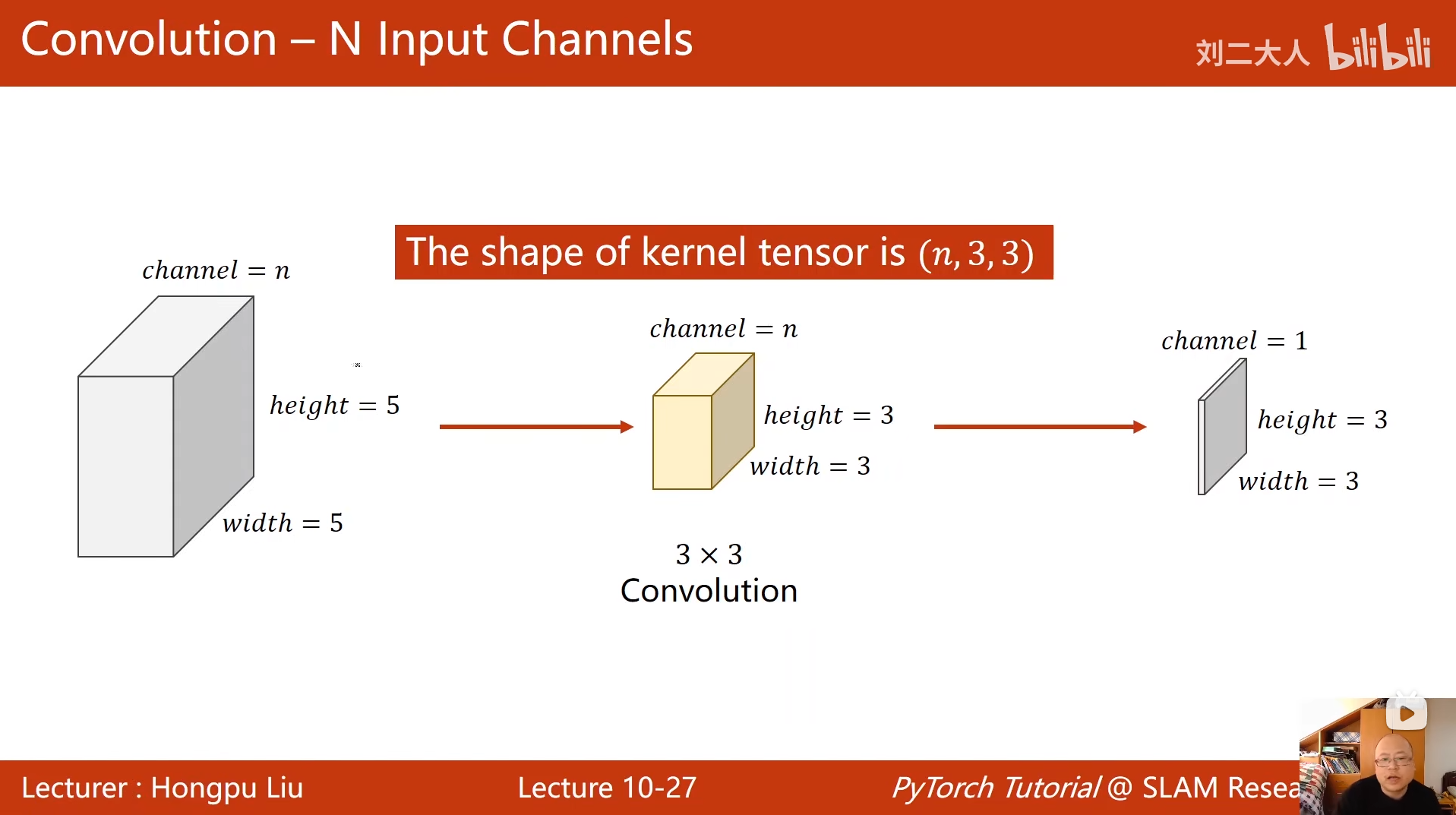
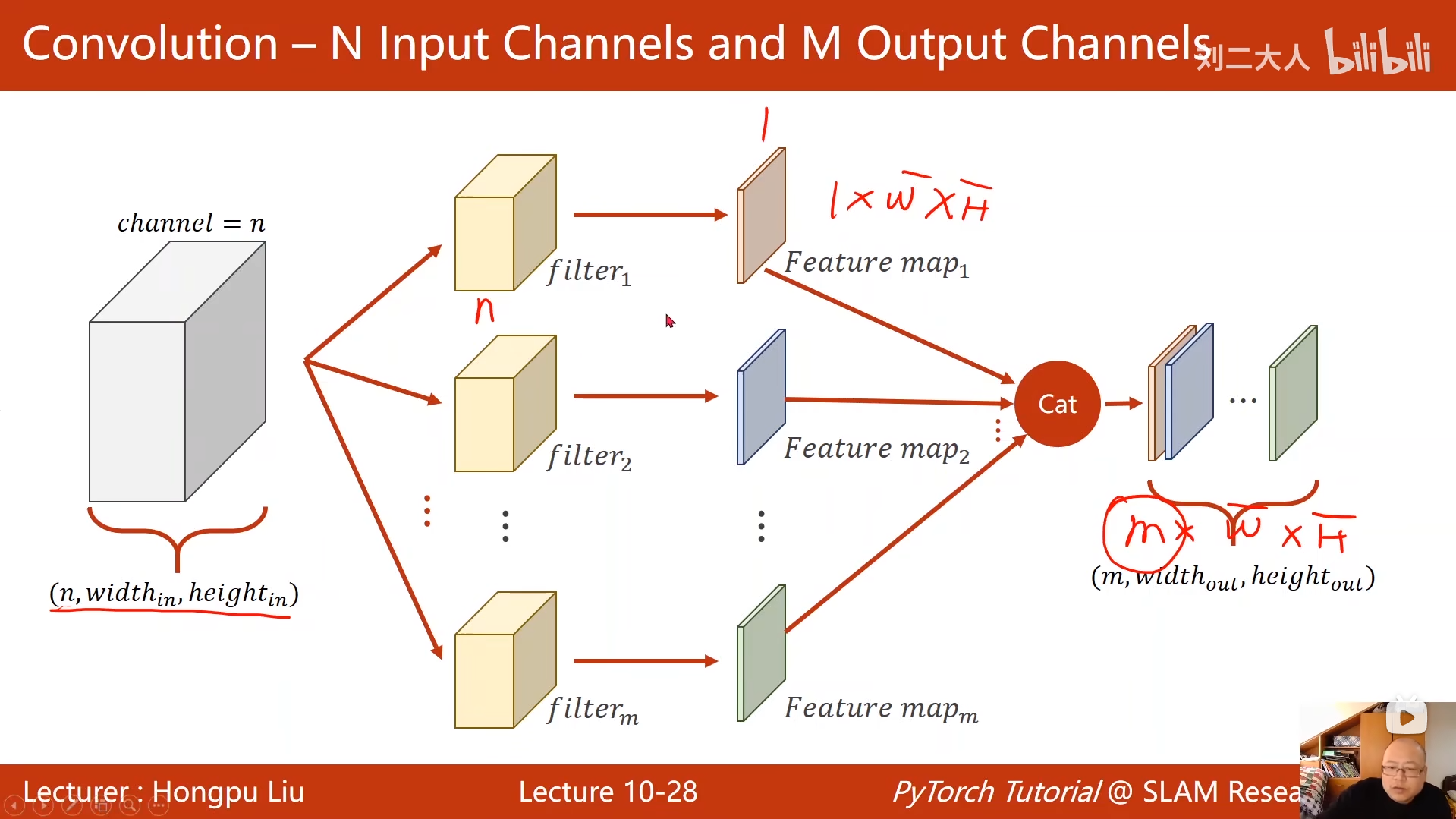

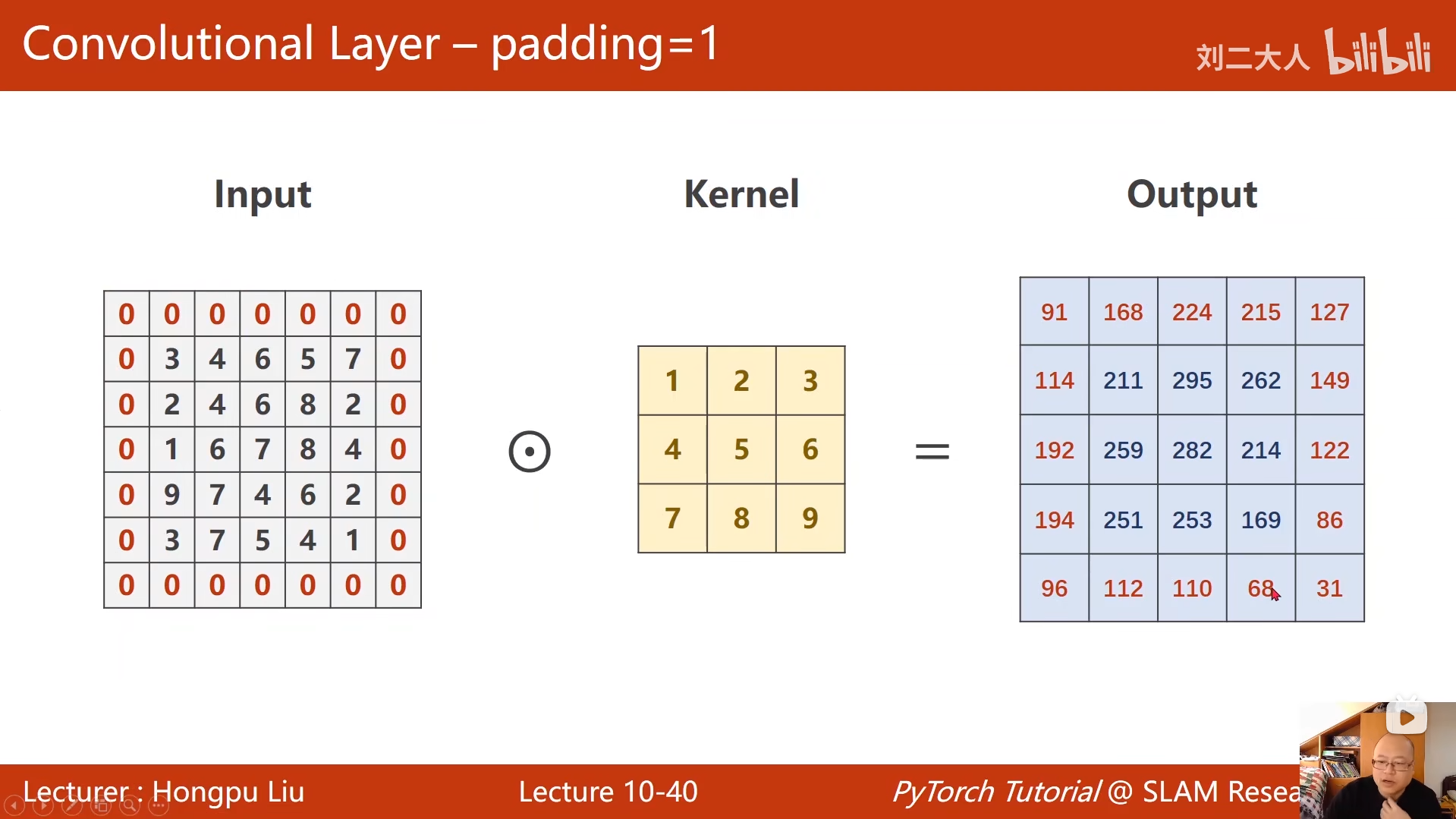

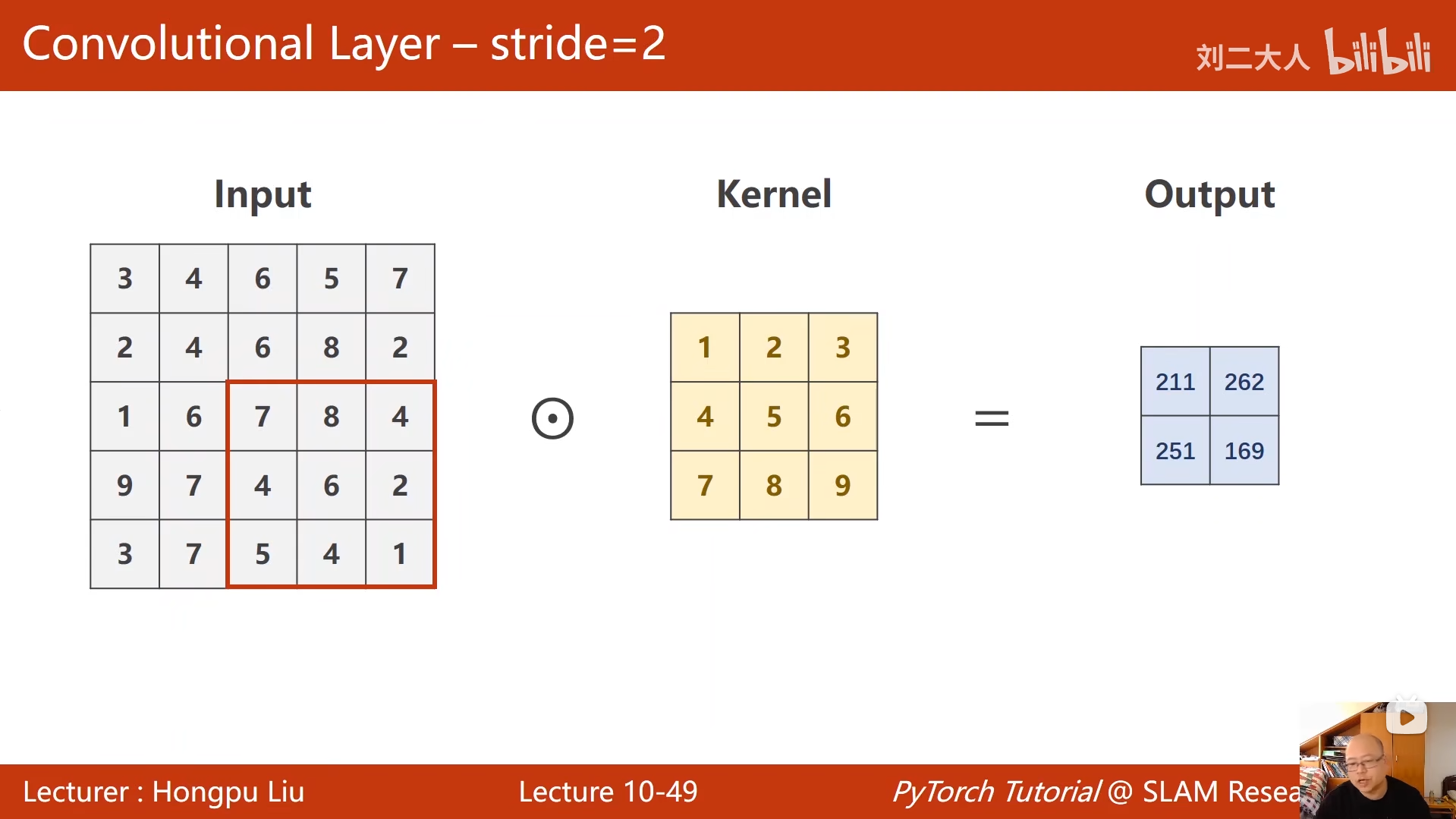

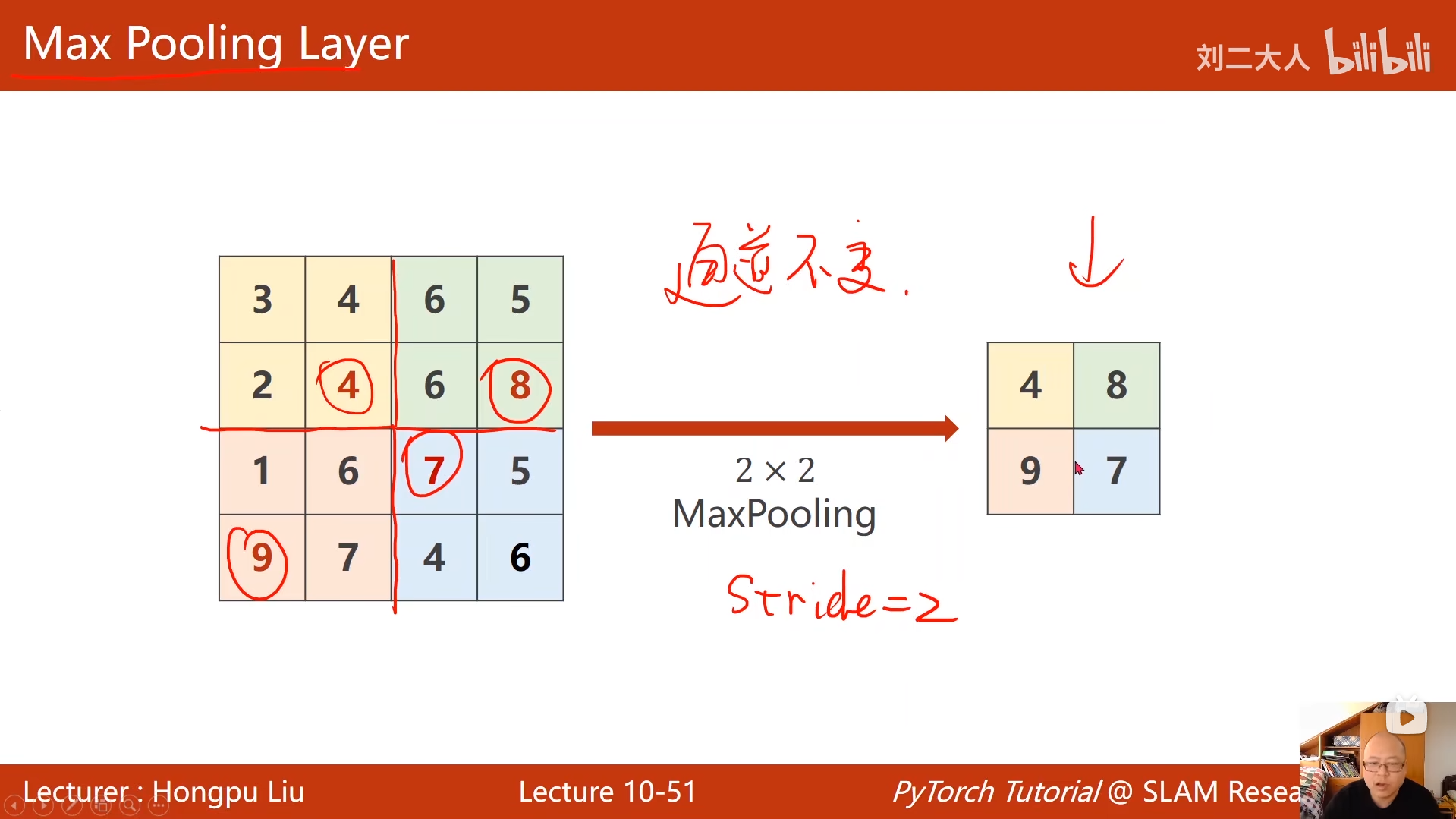

python
import torch
import torch.nn.functional as F
# 导入数据集加载相关库(MNIST是torchvision内置数据集)
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# ===================== 神经网络模型定义 =====================
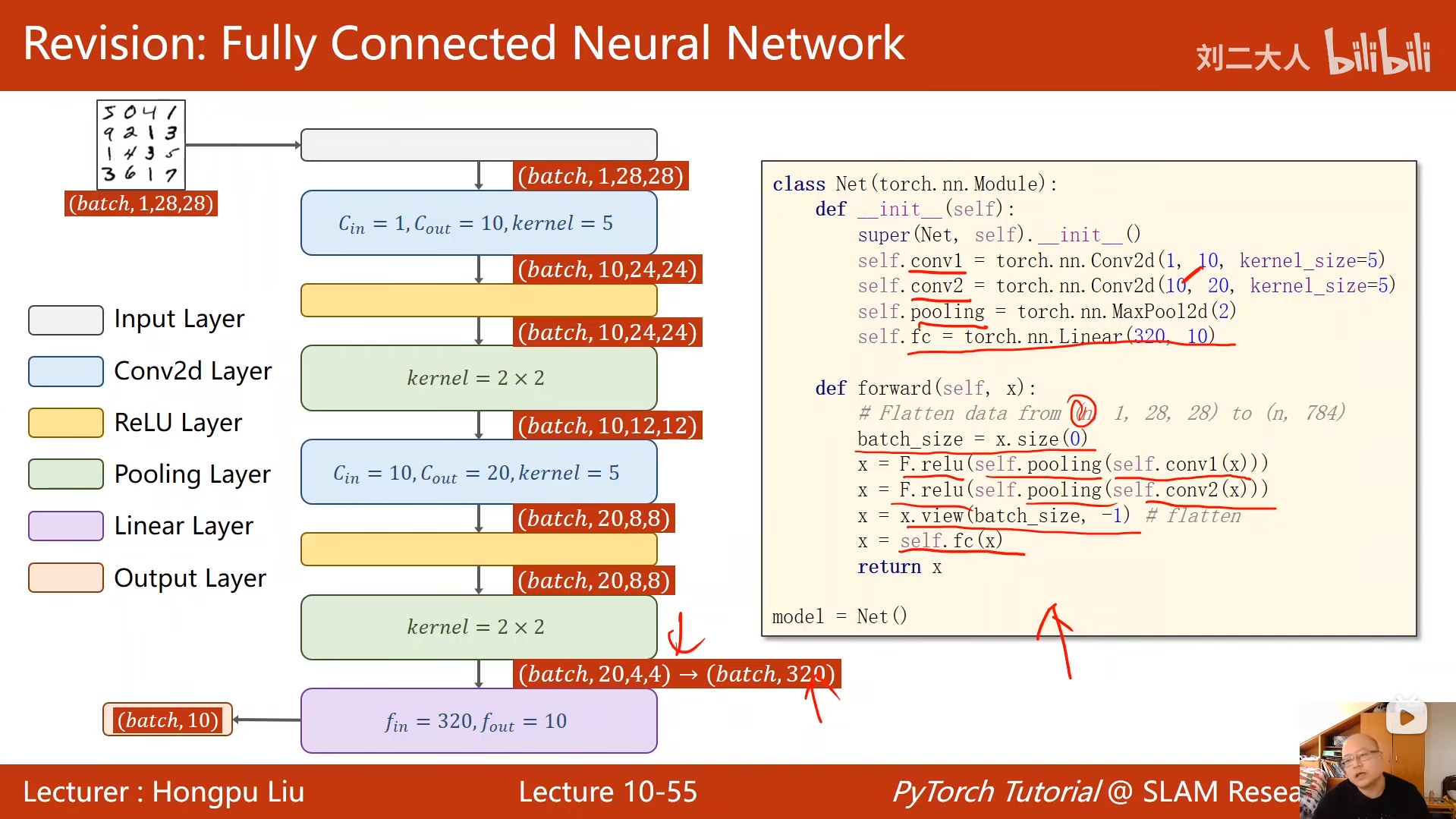
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
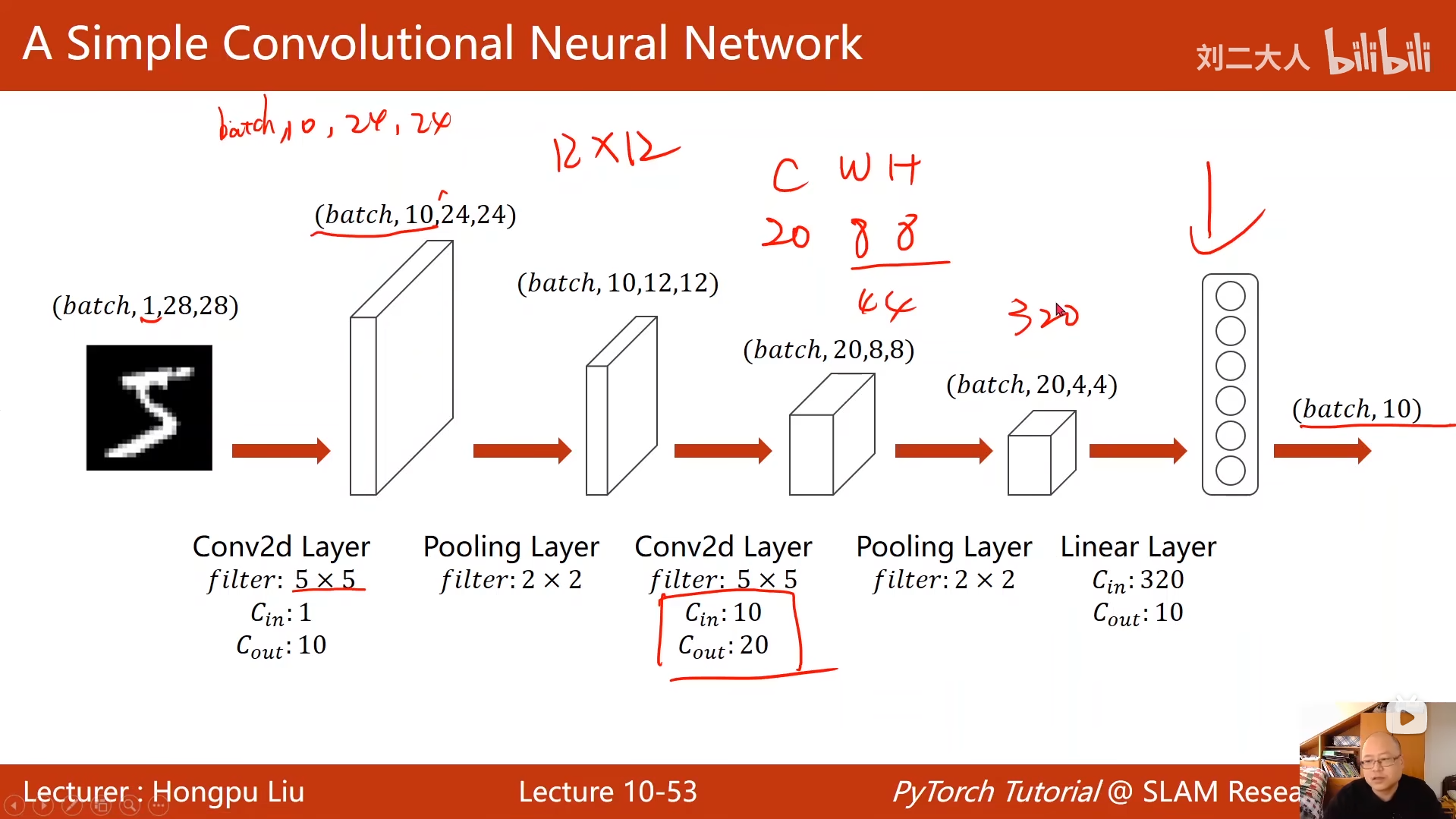
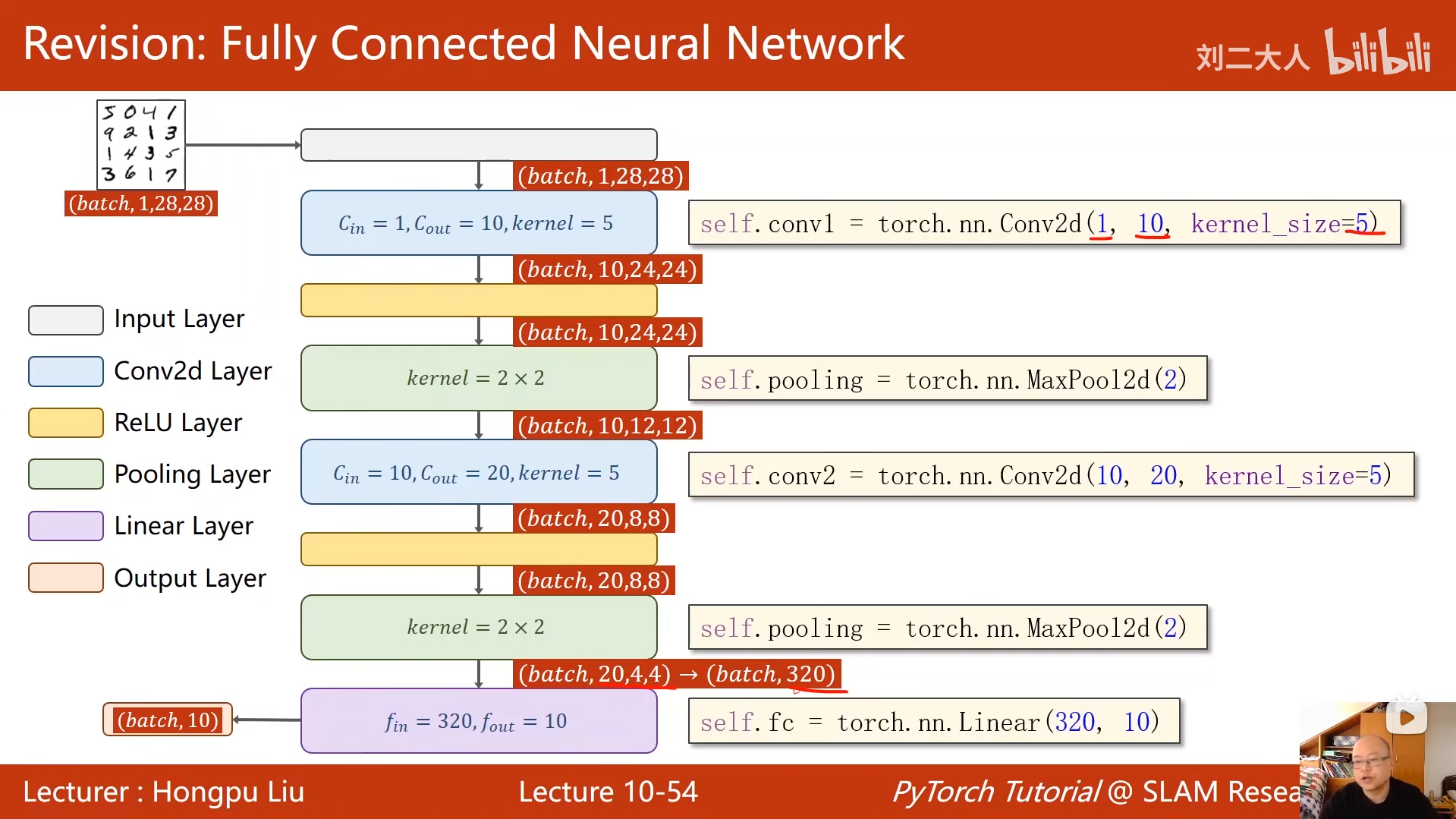
# 第一层卷积:1通道(灰度图)→10通道,卷积核5x5
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
# 第二层卷积:10通道→20通道,卷积核5x5
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
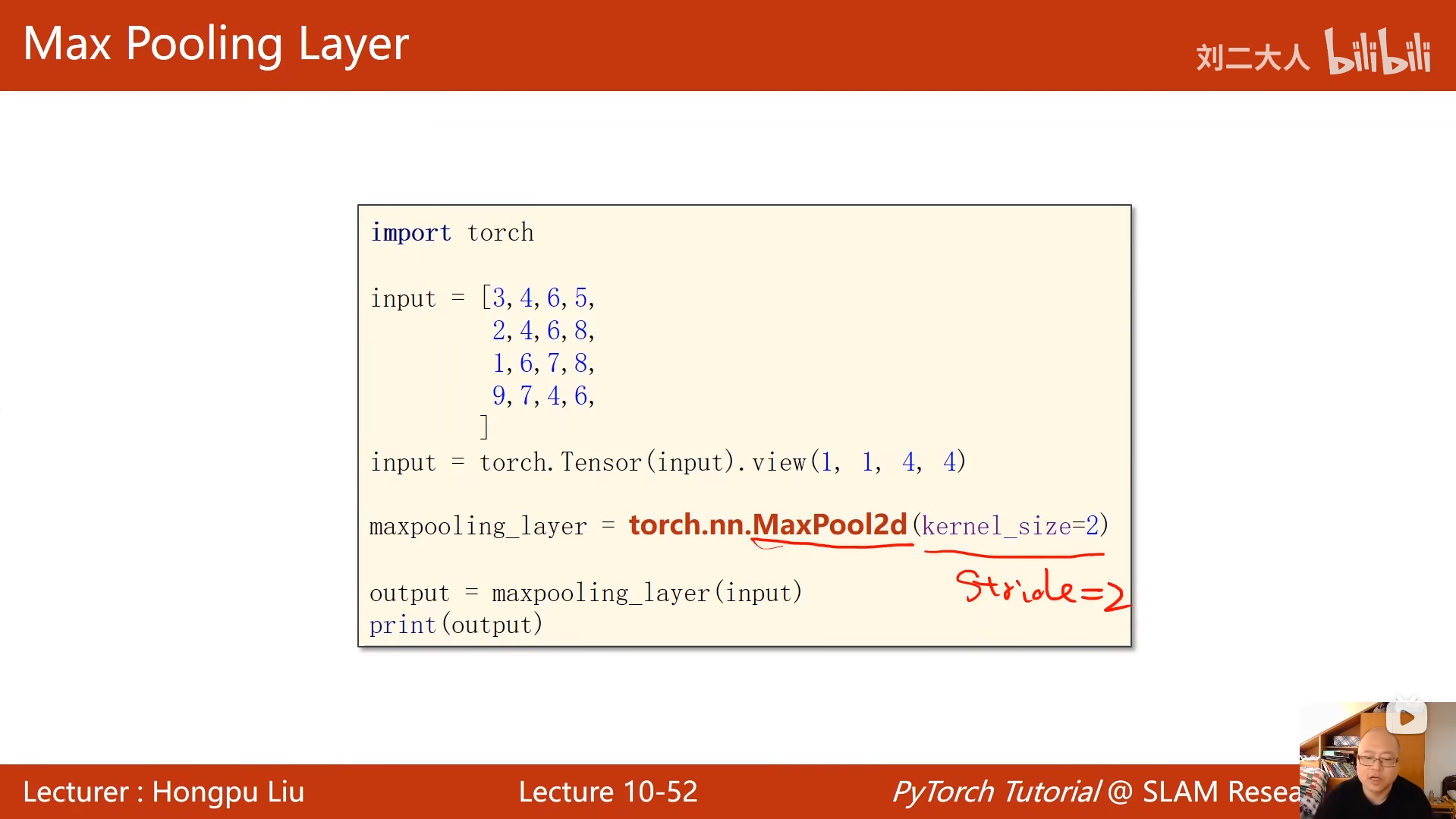
# 最大池化层:2x2池化核,步长默认2
self.pooling = torch.nn.MaxPool2d(2)
# 全连接层:320维特征→10类(0-9数字)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
# 卷积1 → 池化 → ReLU激活
x = F.relu(self.pooling(self.conv1(x)))
# 卷积2 → 池化 → ReLU激活
x = F.relu(self.pooling(self.conv2(x)))
# 展平:将4维张量(batch, 20, 4, 4)转为2维(batch, 320)
x = x.view(batch_size, -1)
# 全连接层输出(未加Softmax,后续用CrossEntropyLoss自动处理)
x = self.fc(x)
return x
# ===================== 训练/测试函数定义 =====================
def train(epoch, train_loader, model, criterion, optimizer, device):
"""
训练函数(参照参考代码,增加参数传入避免全局变量依赖)
:param epoch: 当前训练轮数
:param train_loader: 训练数据加载器
:param model: 模型实例
:param criterion: 损失函数
:param optimizer: 优化器
:param device: 训练设备(CPU/GPU)
"""
model.train() # 切换为训练模式(启用Dropout/BatchNorm等)
running_loss = 0.0
# 遍历训练批次(参照参考代码的enumerate写法)
for batch_idx, data in enumerate(train_loader, 0):
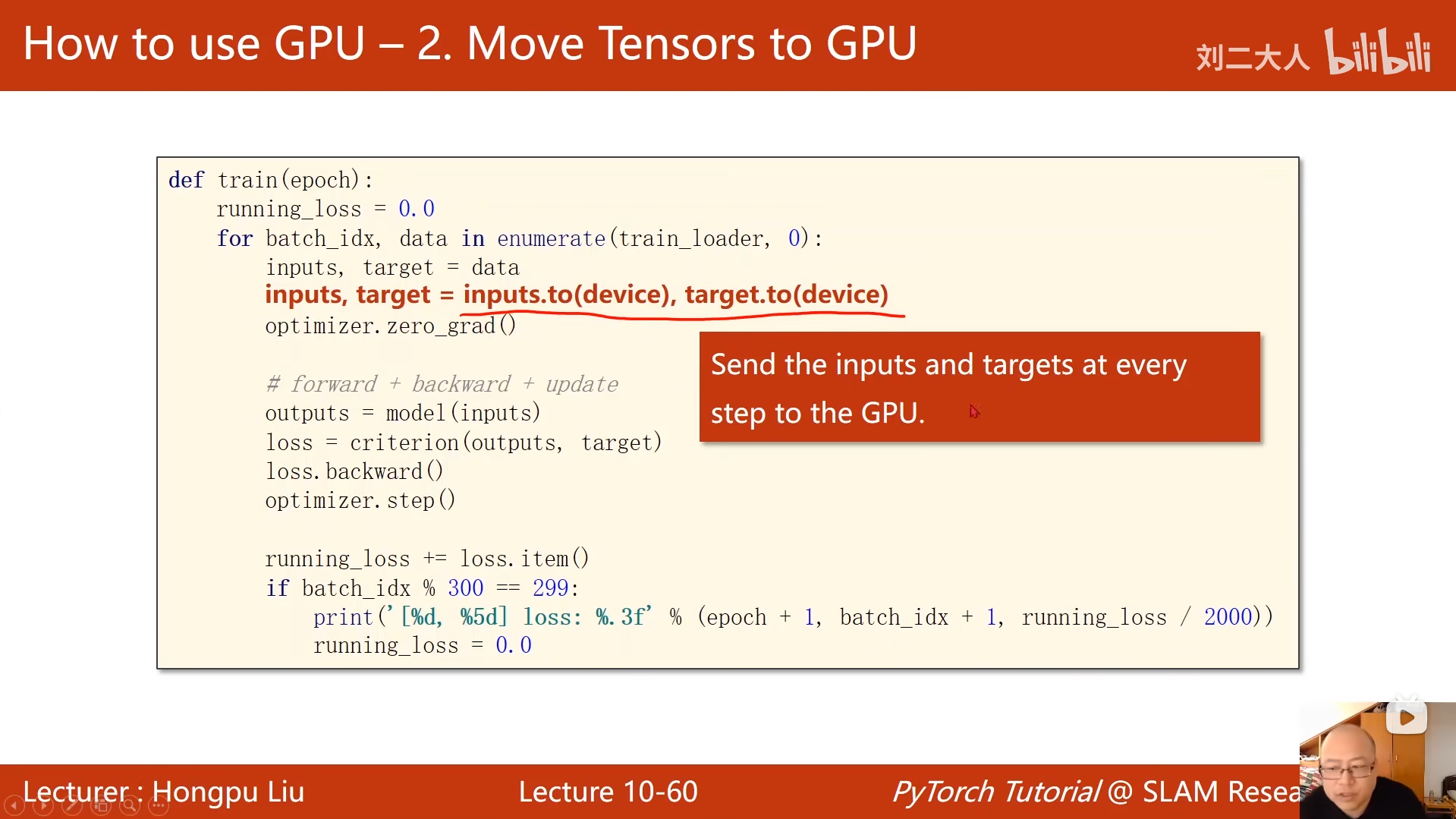
inputs, target = data
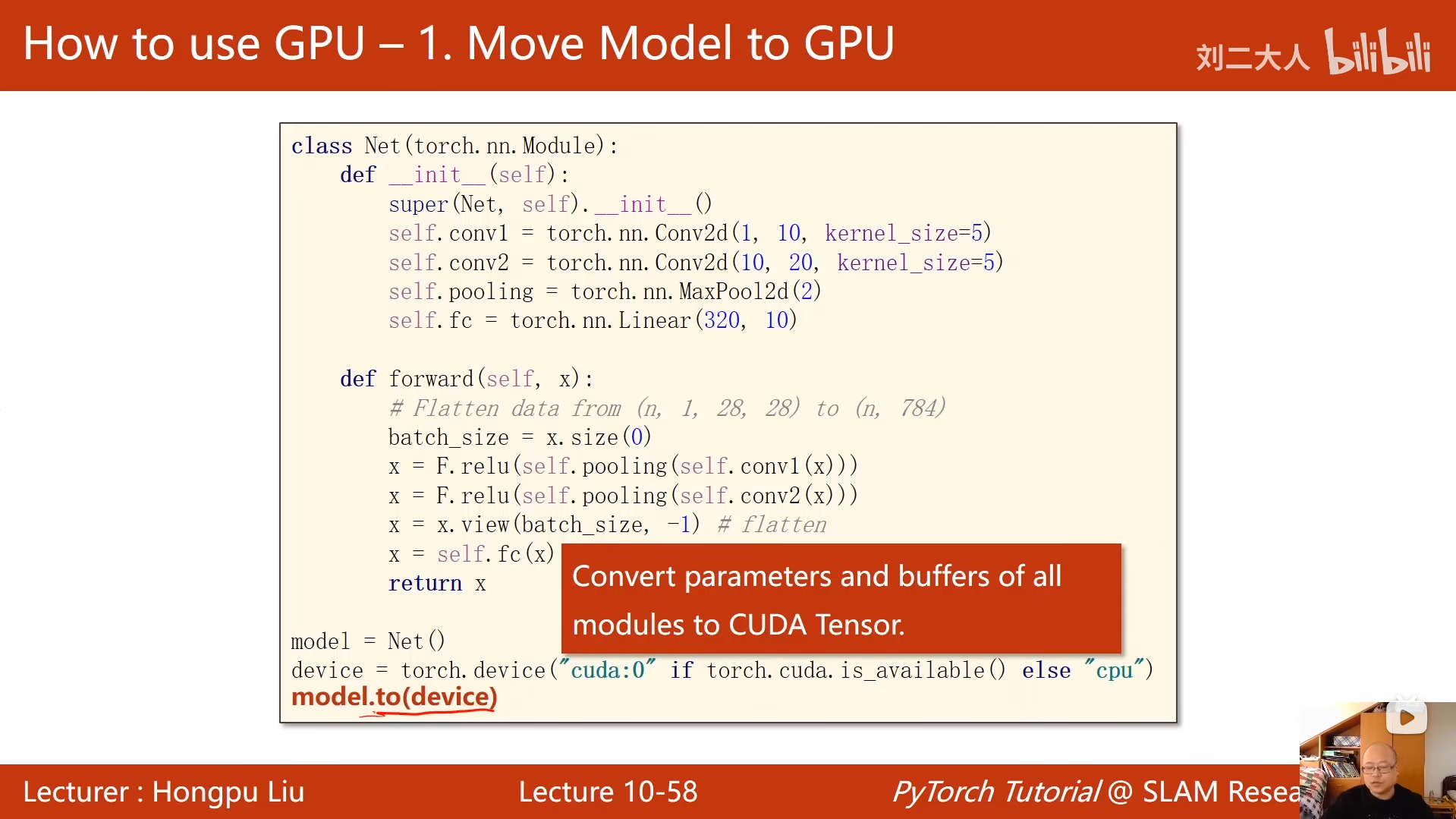
# 将数据移到指定设备(CPU/GPU)
inputs, target = inputs.to(device), target.to(device)
# 梯度清零 → 前向传播 → 计算损失 → 反向传播 → 参数更新
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 每300个批次打印一次损失(参照参考代码的打印格式)
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0 # 修正:原代码除以2000是笔误,应除以300
def test(test_loader, model, criterion, device):
"""
测试函数(参照参考代码风格,补充损失计算,增加鲁棒性)
:param test_loader: 测试数据加载器
:param model: 模型实例
:param criterion: 损失函数
:param device: 测试设备(CPU/GPU)
"""
model.eval() # 切换为评估模式(禁用Dropout/BatchNorm等)
correct = 0
total = 0
test_loss = 0.0
# 禁用梯度计算(加速测试,节省显存)
with torch.no_grad():
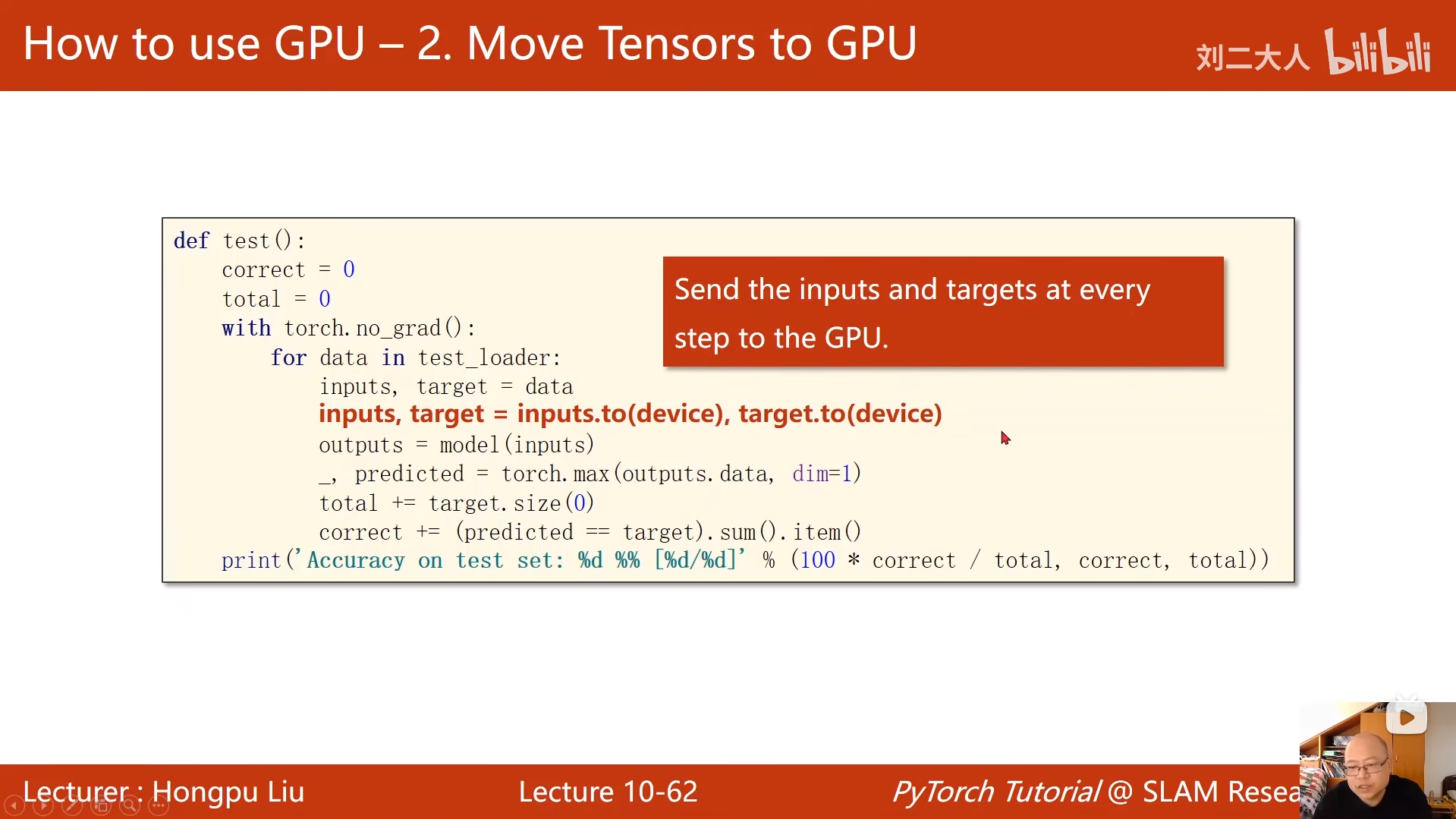
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
# 计算测试损失
loss = criterion(outputs, target)
test_loss += loss.item()
# 取预测概率最大的类别
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
# 打印测试集准确率和平均损失(修正原代码打印格式错误)
avg_loss = test_loss / len(test_loader)
accuracy = 100 * correct / total
print('Test set: Average loss: %.4f, Accuracy: %d/%d (%d %%)\n' %
(avg_loss, correct, total, accuracy))
# ===================== 主程序入口 =====================
# Windows多进程必须加此代码块,避免子进程重复执行
if __name__ == '__main__':
# 1. 设备配置(参照参考代码,优先使用GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 2. 数据集加载与预处理(核心补充部分)
# 数据预处理:转为张量 + 归一化(MNIST像素值0-255→0-1,均值0.1307,标准差0.3081)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST训练集(自动下载到./data目录)
train_dataset = datasets.MNIST(
root='./data', # 数据集保存路径
train=True, # 训练集
download=True, # 本地没有则自动下载
transform=transform # 应用预处理
)
# 加载MNIST测试集
test_dataset = datasets.MNIST(
root='./data',
train=False, # 测试集
download=True,
transform=transform
)
# 创建DataLoader(参照参考代码的参数风格)
# num_workers=0:Windows下先关闭多进程,避免报错;Linux/Mac可设为2
train_loader = DataLoader(
dataset=train_dataset,
batch_size=32, # 批次大小(与参考代码一致)
shuffle=True, # 训练集打乱
num_workers=0
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=32,
shuffle=False, # 测试集无需打乱
num_workers=0
)
# 3. 实例化模型并移到指定设备
model = Net().to(device)
# 4. 训练配置(参照参考代码的损失函数/优化器选择)
# 损失函数:交叉熵损失(适配多分类任务,自动包含Softmax)
criterion = torch.nn.CrossEntropyLoss(reduction='mean')
# 优化器:随机梯度下降(SGD),学习率0.01(可根据需要调大到0.05)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 5. 模型训练与测试循环(参照参考代码的外层循环风格)
epochs = 10 # 训练10轮(可根据需要调整)
for epoch in range(epochs):
# 训练一轮
train(epoch, train_loader, model, criterion, optimizer, device)
# 每轮训练后测试一次
test(test_loader, model, criterion, device)
print('Finished Training')
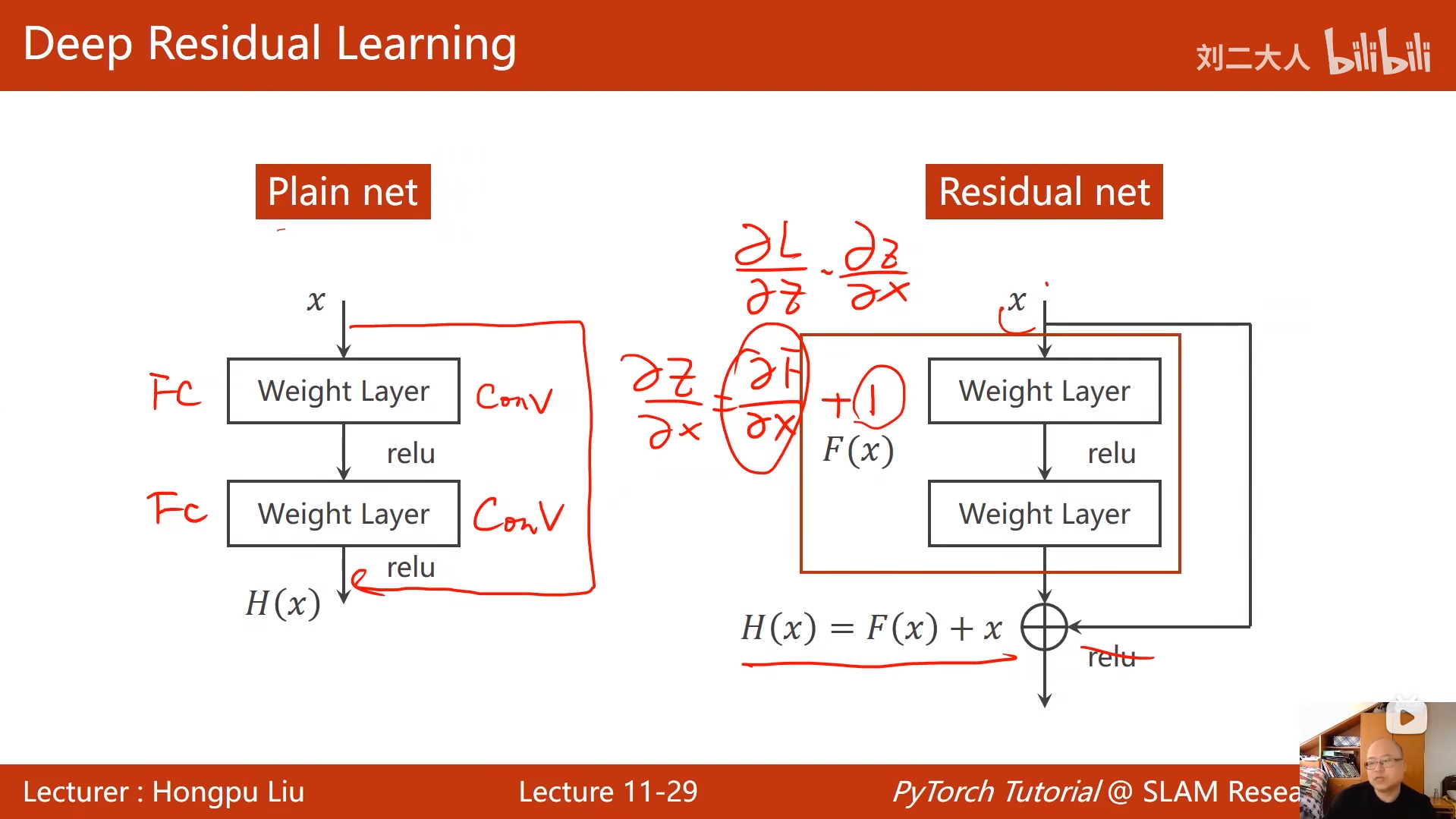
11 卷积神经网络(高级篇)