目录
[5讲解LinkedHashSet 为什么能保持去重和有序?](#5讲解LinkedHashSet 为什么能保持去重和有序?)
6问题:char类型的.isDigit()和isLetter()是什么意思?
[8 八道sql语句编写](#8 八道sql语句编写)
1KMP算法?
是什么?
该算法用于高效判断一个子串是否包含于另一个字符串
原理?
KMP 通过预处理模式串得到 next 数组 ,利用前缀与后缀的公共长度 ,在匹配失败时不回退文本指针,只移动模式串,
为什么用前缀与后缀的公共长度就可以确保在匹配失败时不回退文本指针?
最本质的道理(面试就说这句)
因为前面已经匹配成功的一段里,后缀 = 前缀,说明文本里刚匹配过的内容,和模式串开头的前缀是一模一样的。既然已经匹配过,就不需要再比一遍,所以文本指针不用回退,模式串直接跳到前缀位置继续比就够了。
代码实现?
javapackage com.heima; public class KMPAlgorithm { /** * 构建 KMP 核心的 next 数组(前缀表) * @param pattern 模式串 * @return next 数组:next[i] 表示模式串前 i+1 个字符的最长相等前后缀长度 */ public static int[] buildNextArray(String pattern) { int m = pattern.length(); int[] next = new int[m]; // j:最长相等前后缀的长度(也是前缀指针) int j = 0; // i:后缀指针,从1开始(单个字符前后缀为空,默认0) for (int i = 1; i < m; i++) { // 1. 前后缀不相等时,j 回退到上一个可能的位置(核心) while (j > 0 && pattern.charAt(i) != pattern.charAt(j)) { j = next[j - 1]; } // 2. 前后缀相等时,j 后移,记录长度 if (pattern.charAt(i) == pattern.charAt(j)) { j++; } // 3. 赋值 next 数组 next[i] = j; } return next; } /** * KMP 核心匹配方法 * @param text 文本串(被查找的大字符串) * @param pattern 模式串(要找的小字符串) * @return 模式串在文本串中首次出现的起始索引,未找到返回 -1 */ public static int kmpMatch(String text, String pattern) { // 边界处理:模式串为空直接返回0,文本串更短返回-1 if (pattern.isEmpty()) return 0; if (text.length() < pattern.length()) return -1; int[] next = buildNextArray(pattern); int n = text.length(); // 文本串长度 int m = pattern.length();// 模式串长度 int j = 0; // 模式串指针(永不回退到0,除非完全不匹配) // i:文本串指针(永不回退,核心优化点) for (int i = 0; i < n; i++) { // 1. 字符不匹配时,模式串指针按 next 数组回退 while (j > 0 && text.charAt(i) != pattern.charAt(j)) { j = next[j - 1]; } // 2. 字符匹配时,模式串指针后移 if (text.charAt(i) == pattern.charAt(j)) { j++; } // 3. 模式串完全匹配,返回起始索引 if (j == m) { return i - m + 1; } } // 未找到匹配 return -1; } // 测试用例(直接运行main方法即可验证) public static void main(String[] args) { // 测试案例1:基础匹配 String text1 = "ABABABCABX"; String pattern1 = "ABABC"; int index1 = kmpMatch(text1, pattern1); System.out.println("案例1:模式串首次出现位置 = " + index1); // 输出:2 // 测试案例2:无匹配 String text2 = "ABCDEFG"; String pattern2 = "XYZ"; int index2 = kmpMatch(text2, pattern2); System.out.println("案例2:模式串首次出现位置 = " + index2); // 输出:-1 // 测试案例3:模式串等于文本串 String text3 = "HELLO"; String pattern3 = "HELLO"; int index3 = kmpMatch(text3, pattern3); System.out.println("案例3:模式串首次出现位置 = " + index3); // 输出:0 // 测试案例4:模式串是文本串前缀 String text4 = "123456789"; String pattern4 = "123"; int index4 = kmpMatch(text4, pattern4); System.out.println("案例4:模式串首次出现位置 = " + index4); // 输出:0 } }
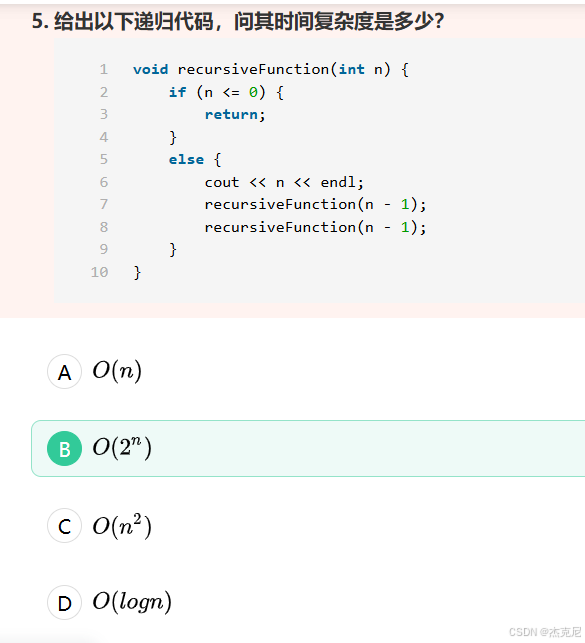
2时间复杂度的计算
"普通递归"的时间复杂度没有一个固定的值,它完全取决于递归的具体逻辑和递推关系。不同的递归算法,其时间复杂度差异巨大。
通常,我们通过建立递推关系式 T(n) 来分析其时间复杂度,其中 T(n) 代表解决规模为 n 的问题所需的时间。
以下是几种常见递归模式及其时间复杂度的分析:
📈 线性递归
这类递归每次调用自身一次,问题规模线性减小。
* 典型例子: 计算阶乘
* 递推关系: T(n) = T(n-1) + O(1)
* 时间复杂度: O(n)
* 分析: 函数会连续调用 n 次,每次执行常数时间的操作,因此总时间与 n 成正比。
🌳 二分递归
这类递归每次将问题分解为两个规模减半的子问题。
* 典型例子: 归并排序
* 递推关系: T(n) = 2T(n/2) + O(n)
* 时间复杂度:O(n log n)
* 分析: 递归树的深度为 log n,每一层都需要 O(n) 的时间来合并结果,因此总时间复杂度为 O(n log n)。
🔍 单路分支递归
这类递归每次将问题规模减半,但只在一个分支上继续递归。
* 典型例子: 二分查找
* 递推关系: T(n) = T(n/2) + O(1)
* 时间复杂度:O(log n)
* 分析: 每次递归调用都将搜索范围缩小一半,因此递归深度为 log n,每次执行常数时间的操作。
💥指数级递归
这类递归由于缺乏优化,会进行大量重复的计算。
* 典型例子: 朴素的斐波那契数列递归实现
* 递推关系: T(n) = T(n-1) + T(n-2) + O(1)
* 时间复杂度: O(2ⁿ)
* 分析: 每次调用会生成两个新的调用,形成一棵近似满二叉树,节点总数随 n 呈指数级增长,因此效率极低。
3习题
1
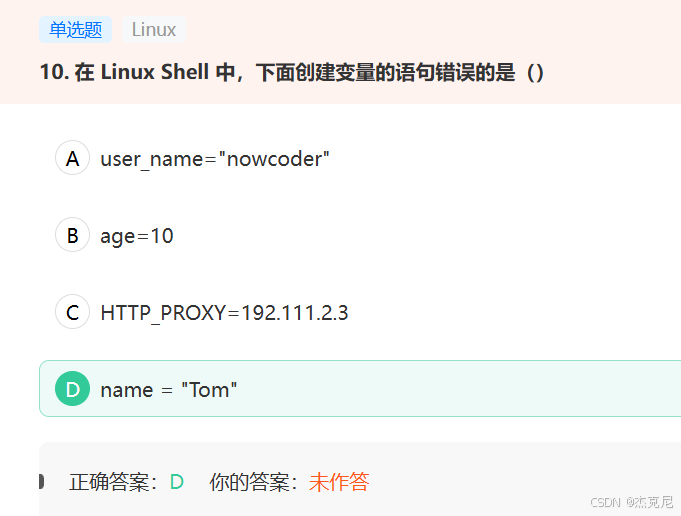
2在Linux Shell中变量赋值时,等号"="两边不能有空格,这是Shell的语法规则。
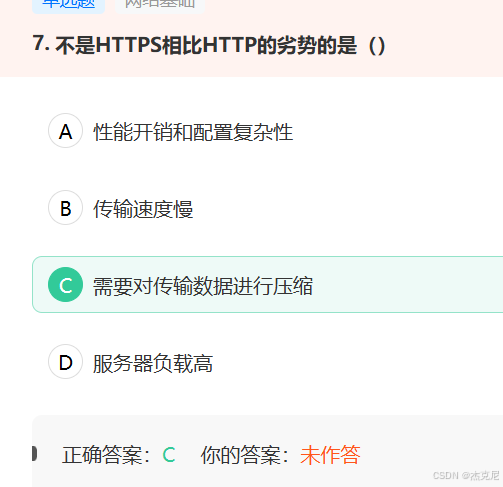
C. 需要对传输数据进行压缩:这不是HTTPS的要求。数据压缩是为了提高传输效率,减少带宽使用,但这与是否使用HTTPS无关。HTTP和HTTPS都可以通过压缩技术(如gzip)来优化数据传输。
3
4
5
6
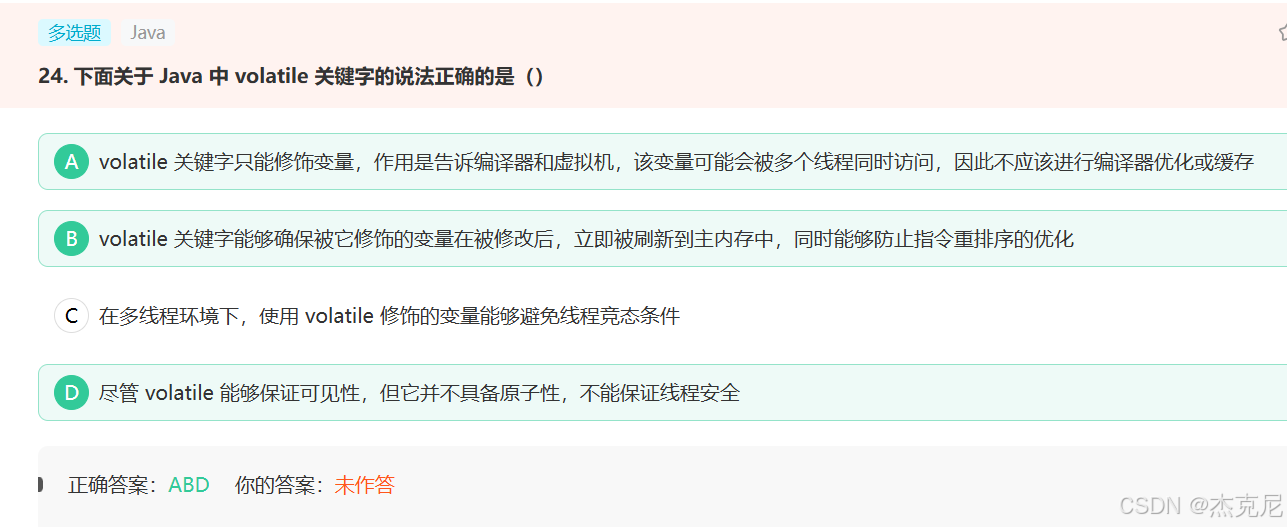
因为它volatile不保证原子性,不保证原子性就会出现竞态性

4解释如下代码?
int mice = (int) Math.ceil(Math.log(mushrooms) / Math.log(2));
Math.ceil()//向上取整,返回值类型double
里面的就是计算 ln (2)
对数换底公式:
log₂(m) = ln(m)/ln(2),算出表示 m 个数字需要的二进制位数(可能是小数)
5讲解LinkedHashSet 为什么能保持去重和有序?
LinkedHashSet 去重靠「HashMap key 唯一性」,有序靠「双向链表记录插入顺序」;
6问题:char类型的.isDigit()和isLetter()是什么意思?
判断某个字符是不是数字和字母
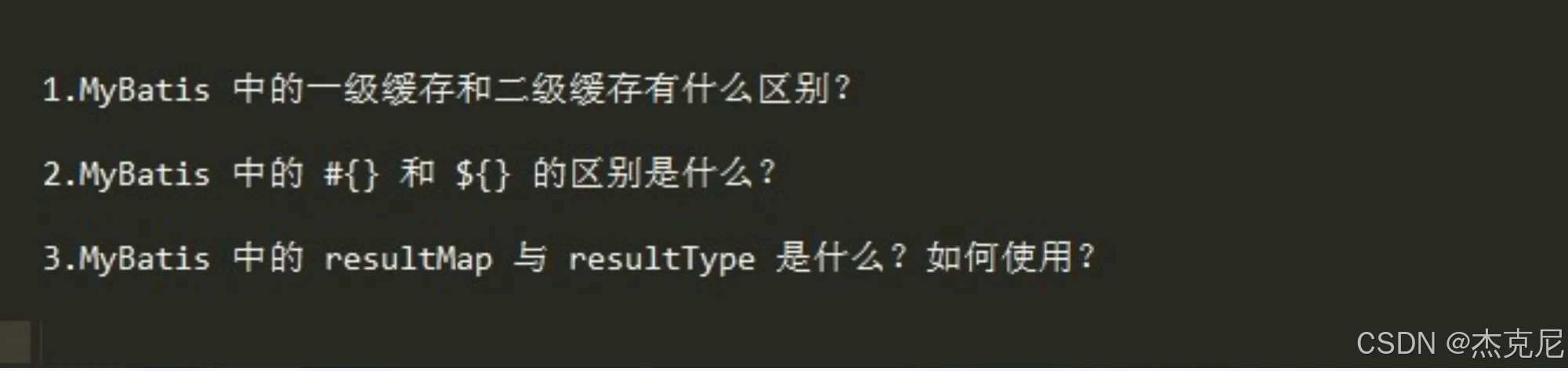
7MyBatis的3到面试题
1
- 一级缓存 :是 SqlSession 级别 的缓存,默认开启,生命周期和当前会话绑定,会话关闭或执行增删改时会清空,只在当前会话内共享数据。
- 二级缓存 :是 SqlSessionFactory 级别 的缓存,默认关闭,需要手动配置开启,生命周期和应用一致,可跨会话共享数据,但存在脏读风险,且实体类必须实现
Serializable接口。2
#{}是 预处理占位符 ,底层用PreparedStatement,会自动给参数加引号,能防止 SQL 注入,适合传递参数值。${}是 字符串直接拼接,不会加引号,直接把参数拼到 SQL 里,无法防止 SQL 注入,只适合动态拼接表名、列名这类场景。3
resultMap:是自定义映射,可以手动指定字段和属性的对应关系,还能处理多表关联(一对一、一对多),灵活度更高,适合复杂场景。
java<resultMap id="UserMap" type="com.example.User"> <id column="id" property="id"/> <result column="user_name" property="userName"/> </resultMap> <select id="selectUser" resultMap="UserMap"> SELECT id, user_name FROM user </select>
resultType:是自动映射,要求数据库字段名和 Java 属性名一致(或开启驼峰映射),写法简单,适合简单查询。
java<select id="selectUser" resultType="com.example.User">
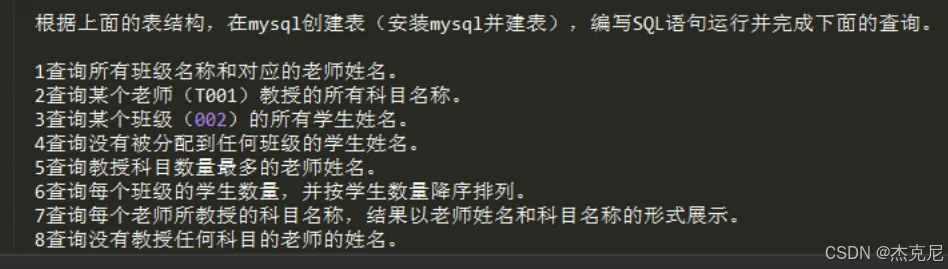
8 八道sql语句编写
sql表
java-- 班级表 CREATE TABLE class ( class_id VARCHAR(10) PRIMARY KEY, class_name VARCHAR(20), teacher_id VARCHAR(10) ); -- 老师表 CREATE TABLE teacher ( teacher_id VARCHAR(10) PRIMARY KEY, teacher_name VARCHAR(20) ); -- 学生表 CREATE TABLE student ( student_id VARCHAR(10) PRIMARY KEY, student_name VARCHAR(20), class_id VARCHAR(10) ); -- 科目表 CREATE TABLE subject ( subject_id VARCHAR(10) PRIMARY KEY, subject_name VARCHAR(20) ); -- 老师-科目关联表(多对多) CREATE TABLE teacher_subject ( teacher_id VARCHAR(10), subject_id VARCHAR(10), PRIMARY KEY (teacher_id, subject_id) );
- 查询所有班级名称和对应的老师姓名
sqlSELECT c.class_name, t.teacher_name FROM class c LEFT JOIN teacher t ON c.teacher_id = t.teacher_id;
- 查询某个老师(T001)教授的所有科目名称
sqlSELECT s.subject_name FROM teacher_subject ts JOIN subject s ON ts.subject_id = s.subject_id WHERE ts.teacher_id = 'T001';
- 查询某个班级(002)的所有学生姓名
sqlSELECT student_name FROM student WHERE class_id = '002';
- 查询没有被分配到任何班级的学生姓名
sqlSELECT student_name FROM student WHERE class_id IS NULL;
- 查询教授科目数量最多的老师姓名
sqlSELECT t.teacher_name FROM teacher t JOIN teacher_subject ts ON t.teacher_id = ts.teacher_id GROUP BY t.teacher_id, t.teacher_name ORDER BY COUNT(ts.subject_id) DESC LIMIT 1;
- 查询每个班级的学生数量,并按学生数量降序排列
sqlSELECT c.class_name, COUNT(s.student_id) AS student_count FROM class c LEFT JOIN student s ON c.class_id = s.class_id GROUP BY c.class_id, c.class_name ORDER BY student_count DESC;
- 查询每个老师所教授的科目名称,结果以老师姓名和科目名称的形式展示
sqlSELECT t.teacher_name, s.subject_name FROM teacher t LEFT JOIN teacher_subject ts ON t.teacher_id = ts.teacher_id LEFT JOIN subject s ON ts.subject_id = s.subject_id;
- 查询没有教授任何科目的老师的姓名
sqlSELECT t.teacher_name FROM teacher t LEFT JOIN teacher_subject ts ON t.teacher_id = ts.teacher_id WHERE ts.subject_id IS NULL;
9vue10道面试题
1. Vue.js 生命周期函数及执行顺序
核心执行顺序(Vue 2.x):
- 创建阶段 :
beforeCreate→created- 挂载阶段 :
beforeMount→mounted- 更新阶段 :
beforeUpdate→updated- 销毁阶段 :
beforeDestroy→destroyed2. v-bind 指令和 v-model 指令的区别
v-bind是单向数据绑定 ,只将数据从 Vue 实例流向视图,用于动态绑定 HTML 属性(如src、class、disabled),语法简写为:。v-model是双向数据绑定 ,本质是v-bind+input事件的语法糖,既可以将数据同步到视图,也能将视图变化同步回数据,主要用于表单元素3. Vue.js 的组件通信方式及其优缺点
- props/$emit:父子组件通信,优点是简单直观、Vue 原生支持,缺点是无法跨级或兄弟组件通信。
- EventBus:通过全局事件总线实现任意组件通信,优点是轻量无依赖,缺点是复杂场景下事件混乱、难以调试。
- Vuex/Pinia:全局状态管理,优点是状态集中管理、可追踪变化,缺点是增加代码复杂度,小型项目会显得冗余。
- provide/inject:跨级组件通信,优点是无需逐层传递数据,缺点是 Vue 2 中数据非响应式,且破坏组件封装性。
- ref/parent/children:父子组件直接访问实例,优点是调用方便,缺点是耦合度高,不推荐频繁使用。
4. Vue.js 父子组件之间的数据传递
- 父传子 :父组件通过
props向子组件传递数据,子组件通过props选项接收。- 子传父 :子组件通过
$emit触发自定义事件,父组件通过@事件名监听并处理。5. Vue.js 中的响应式原理
- Vue 2 核心是通过
Object.defineProperty()劫持对象的getter和setter:
- 初始化时遍历 data 对象,为每个属性添加
getter/setter- 组件渲染时收集依赖,建立属性与 Watcher 的关联
- 属性更新时触发
setter,通知 Watcher 更新视图- Vue 3 改用
Proxy代理整个对象,支持监听数组、新增属性,性能和兼容性更好。6. Vue.js 实现路由跳转
- 声明式跳转 :使用
<router-link to="路径">标签,渲染为<a>标签。- 编程式跳转 :通过
this.$router实例方法实现:
push(路径):跳转到新页面,新增历史记录replace(路径):替换当前页面,不新增历史记录go(n):前进 / 后退 n 步(如go(-1)为后退)7. computed 和 watch 的区别
computed是计算属性,基于依赖缓存,只有依赖数据变化时才会重新计算,适合复杂计算、模板复用场景,必须返回结果。watch是监听器,无缓存,监听数据变化后执行回调,适合异步操作、数据变化时触发副作用,无需返回值。8. v-for 指令和 v-if 指令的区别
v-for用于循环渲染列表,语法为v-for="(item, index) in list" :key="唯一值",优先级高于v-if(Vue 2)。v-if用于条件渲染,控制元素是否存在于 DOM,配套v-else/v-else-if使用。- 注意:不推荐在同一元素上同时使用
v-for和v-if,会先循环再判断导致性能浪费,应在外层包裹<template>或用计算属性过滤列表。9. mixins 和 extends 的作用及区别
mixins用于复用组件选项(data、methods、生命周期等),可传入多个 mixin,同名选项按 "组件> mixin" 优先级覆盖,适合跨组件复用通用逻辑。extends用于继承另一个组件的选项,只能继承一个,继承的选项优先级低于当前组件,适合组件继承、扩展基础组件场景。10. keep-alive 组件的作用及使用
- 作用:缓存不活跃的组件实例,避免重复创建 / 销毁,提升页面性能,保留组件状态(如滚动位置、表单输入)。
- 使用 :包裹需要缓存的组件或路由视图,如
<keep-alive><router-view /></keep-alive>。- 进阶 :可通过
include/exclude属性指定缓存 / 排除的组件,缓存组件会触发activated(激活)和deactivated(失活)生命周期。

10Java集合面试编程题

页尾
本文摘要:本文涵盖了多个计算机科学核心知识点,包括KMP字符串匹配算法及其实现、递归时间复杂度分析、SQL查询编写、Vue面试题集锦以及Java集合框架等内容。重点解析了KMP算法通过next数组实现高效匹配的原理,介绍了线性/二分/指数级递归的时间复杂度计算方法,提供了8个典型SQL查询示例,总结了Vue生命周期、组件通信等10个面试要点,并包含MyBatis缓存机制等常见面试问题。内容涵盖算法、数据库、前端框架等多个技术领域的关键知识点。