数学推理一直是大模型的难点,复杂的逻辑结构和严谨的计算要求让很多模型望而却步。而 GPT-4、Gemini-Ultra 这类顶尖模型又不对外开放,开源模型的性能始终差一截。针对这个问题,来自 DeepSeek-AI、清华大学和北京大学的团队提出了 DeepSeekMath 大模型,通过高质量数据构建和优化的强化学习算法,让开源模型的数学推理能力追上了闭源巨头的水平。

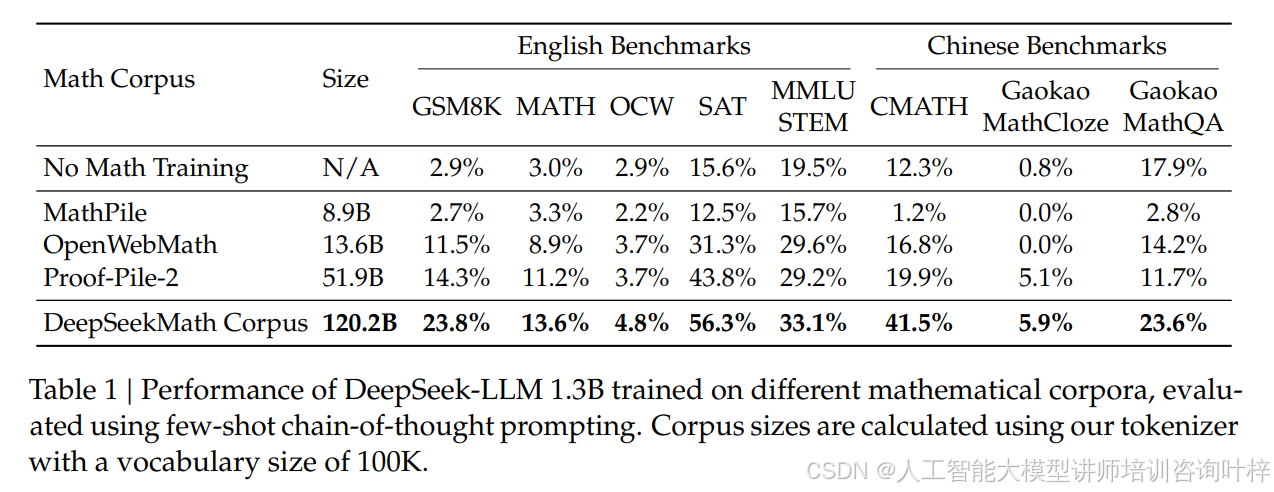
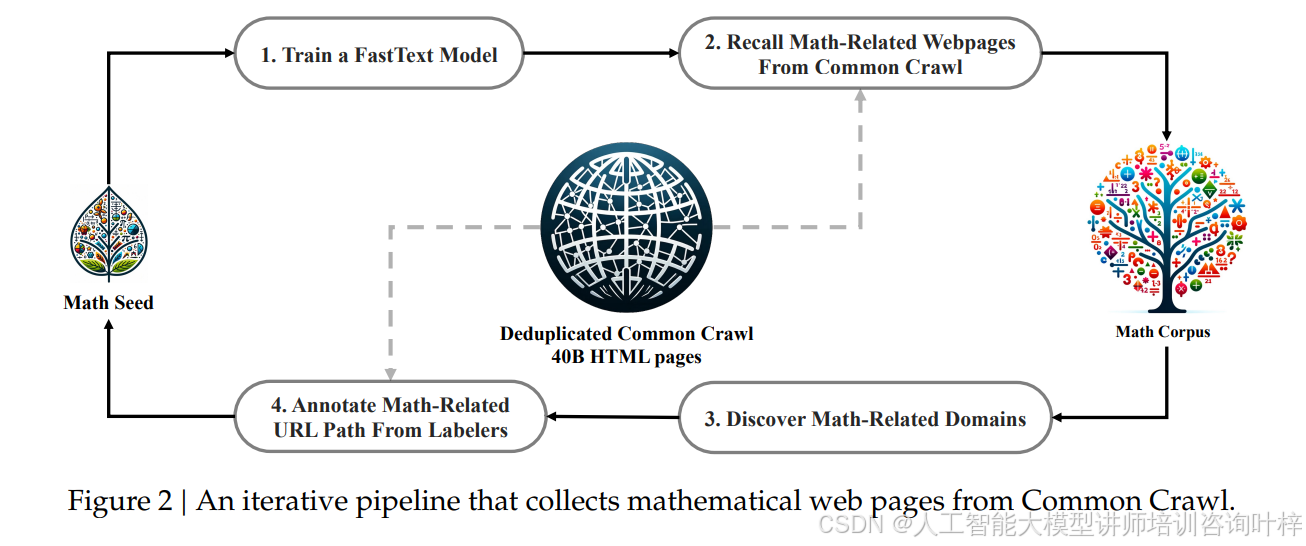
DeepSeekMath 的核心突破首先来自数据。团队没有依赖常见的 arXiv 论文,反而从 Common Crawl 网页数据中挖掘出了 120B tokens 的数学相关内容,构建了 DeepSeekMath Corpus 数据集。这个数据集是 Minerva 所用数学网页数据的 7 倍,OpenWebMath 的 9 倍,还支持中英双语。为了验证数据质量,他们用 1.3B 参数的模型在不同数据集上训练,结果显示用 DeepSeekMath Corpus 训练的模型在 GSM8K 上准确率达 23.8%,MATH 上达 13.6%,远超 MathPile、OpenWebMath 等其他数据集的表现,表格 1清晰展示了这种差距。更关键的是,这个数据集不是一次性收集的,而是通过四次迭代优化:先用 OpenWebMath 训练 fastText 分类器,从 40B 去重网页中筛选数学内容,再通过人工标注扩充种子数据,最后过滤掉基准测试污染内容,图 2详细呈现了这个迭代采集流程。
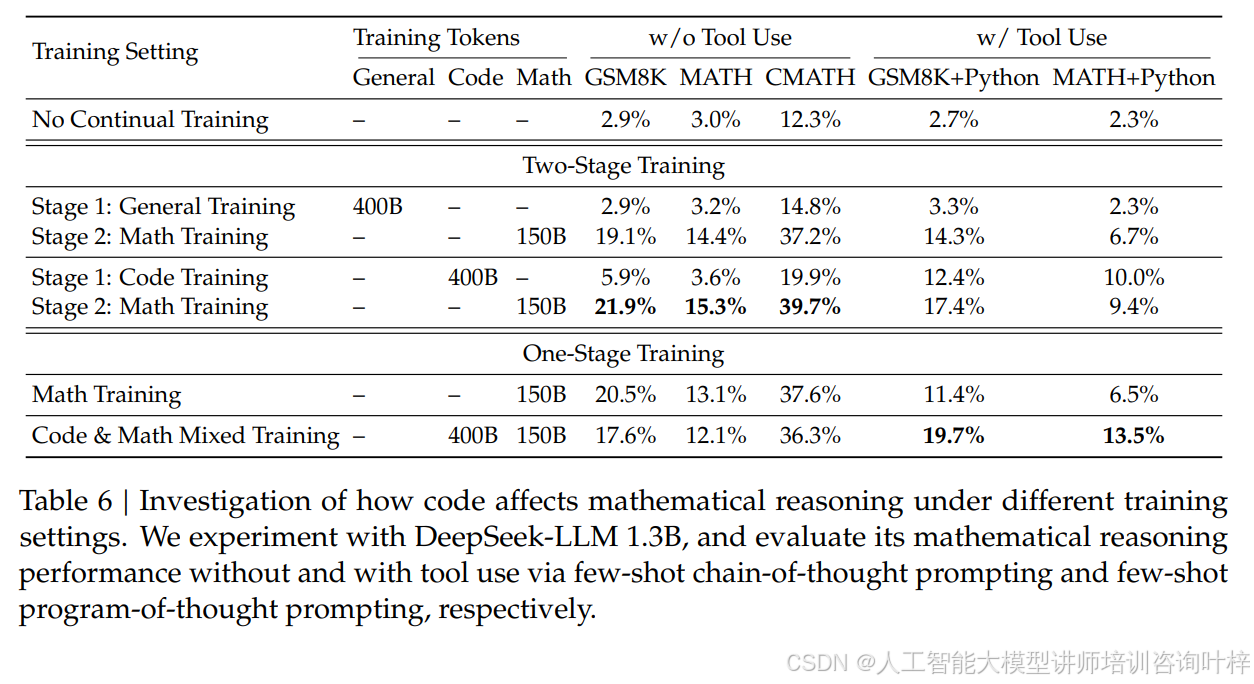
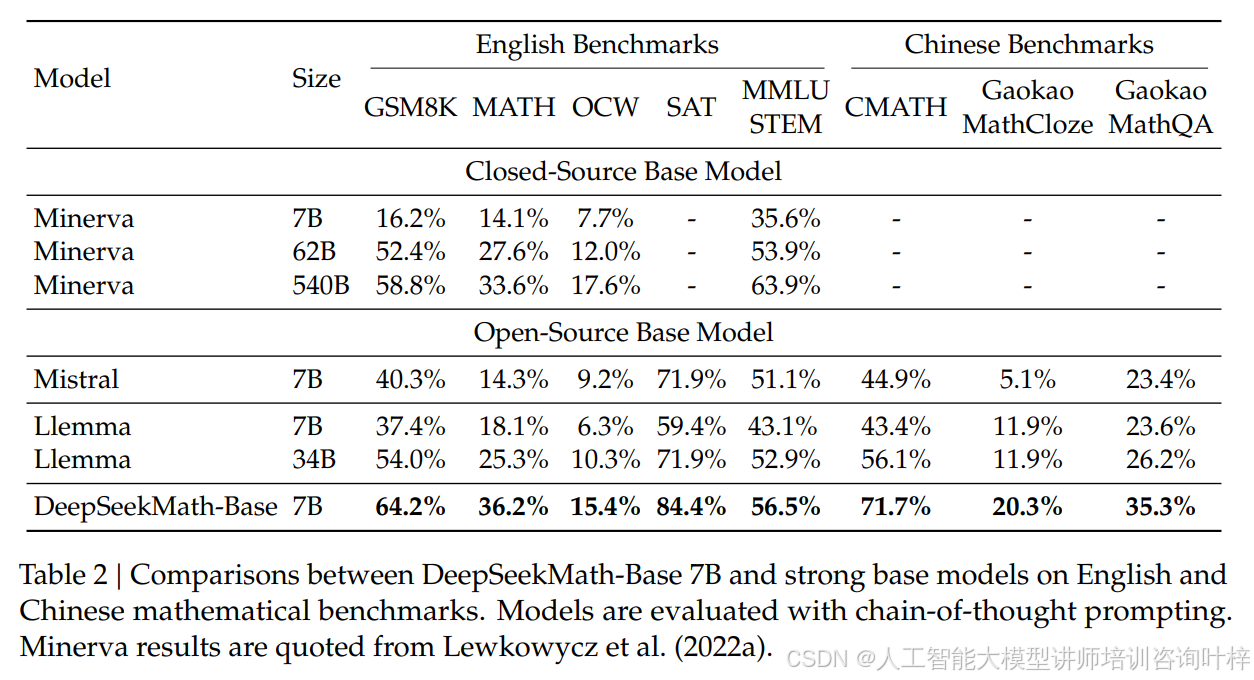
数据之外,模型的初始化选择也很有讲究。团队没有用通用大模型,而是以 DeepSeek-Coder-Base-v1.5 7B 为基础继续训练,因为代码训练能显著提升数学推理能力。实验证明,先进行 400B 代码训练再做 150B 数学训练的模型,在 GSM8K 上准确率达 21.9%,MATH 上达 15.3%,比先做通用训练再做数学训练的效果好得多,表格 6中的数据充分验证了这一点。最终的 DeepSeekMath-Base 7B 在 MATH 基准上达到 36.2% 的准确率,超过了比它大 77 倍的 Minerva 540B,表格 2中能直观看到它在中英双语多个基准上都领先于其他开源模型。
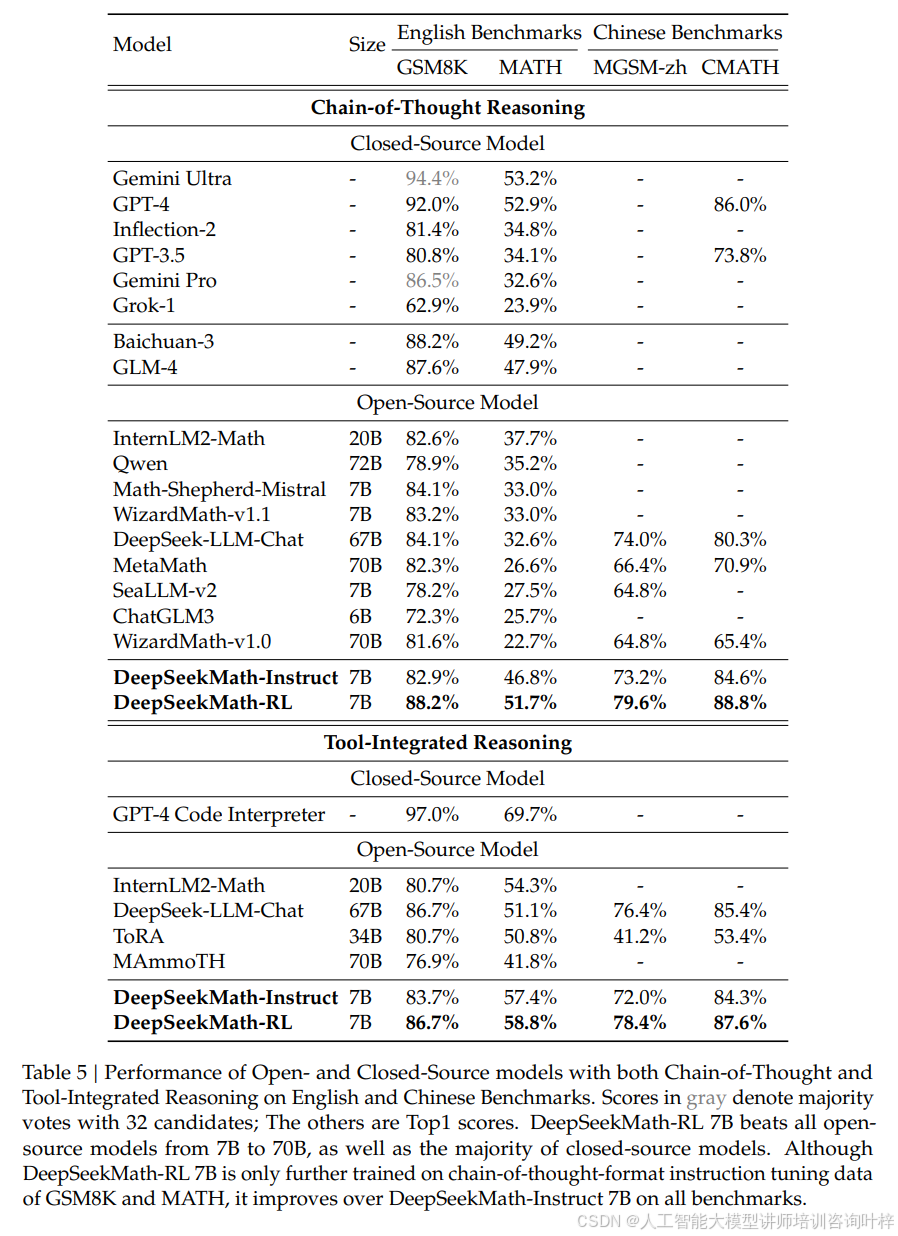
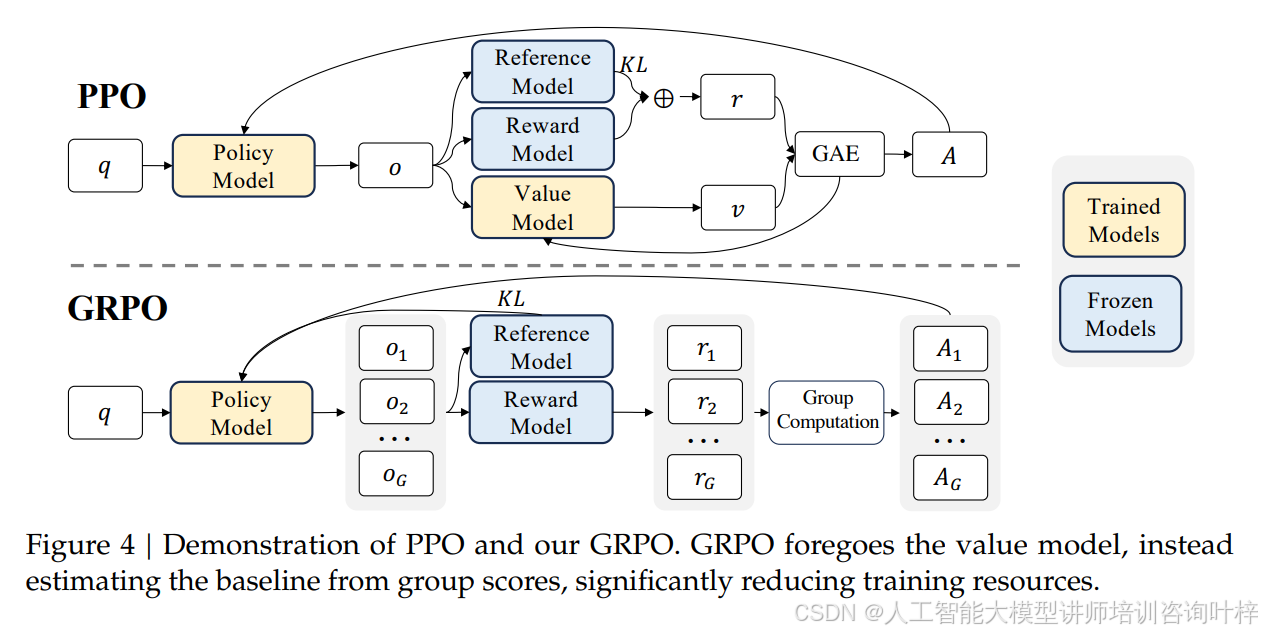 光有预训练还不够,团队还开发了全新的强化学习算法 GRPO(Group Relative Policy Optimization)。传统的 PPO 算法需要同时训练策略模型和价值模型,内存消耗巨大,而 GRPO 直接去掉了价值模型,用同一问题的一组输出的平均奖励作为基准,大幅降低了训练成本。图 4清晰对比了两者的结构差异,GRPO 通过分组相对优势估计,既保证了效果又节省了资源。在实际训练中,GRPO 让 DeepSeekMath-Instruct 7B 的性能再上一个台阶:GSM8K 准确率从 82.9% 提升到 88.2%,MATH 从 46.8% 提升到 51.7%,就连中文的 CMATH 基准也从 84.6% 涨到 88.8%,表格 5中的数据证明它不仅超过了所有 7B 到 70B 规模的开源模型,还打败了大部分闭源模型。
光有预训练还不够,团队还开发了全新的强化学习算法 GRPO(Group Relative Policy Optimization)。传统的 PPO 算法需要同时训练策略模型和价值模型,内存消耗巨大,而 GRPO 直接去掉了价值模型,用同一问题的一组输出的平均奖励作为基准,大幅降低了训练成本。图 4清晰对比了两者的结构差异,GRPO 通过分组相对优势估计,既保证了效果又节省了资源。在实际训练中,GRPO 让 DeepSeekMath-Instruct 7B 的性能再上一个台阶:GSM8K 准确率从 82.9% 提升到 88.2%,MATH 从 46.8% 提升到 51.7%,就连中文的 CMATH 基准也从 84.6% 涨到 88.8%,表格 5中的数据证明它不仅超过了所有 7B 到 70B 规模的开源模型,还打败了大部分闭源模型。
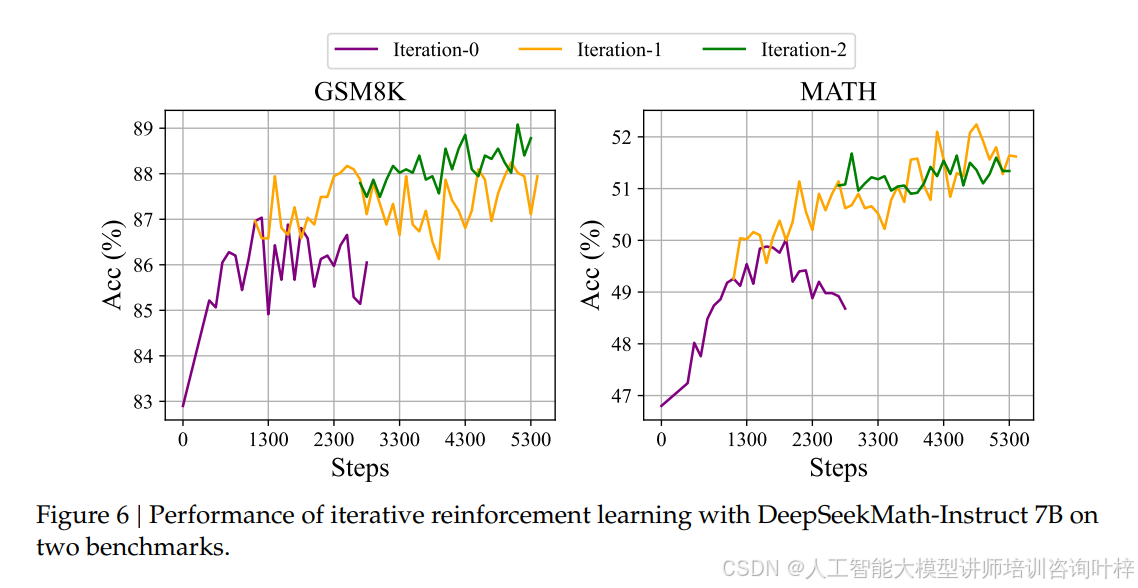
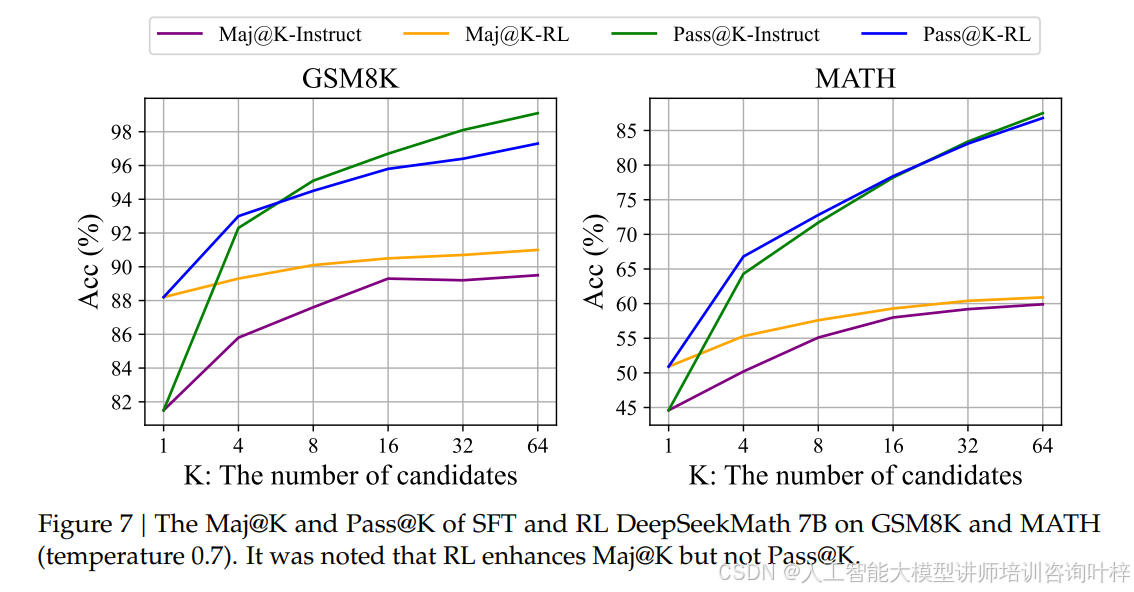
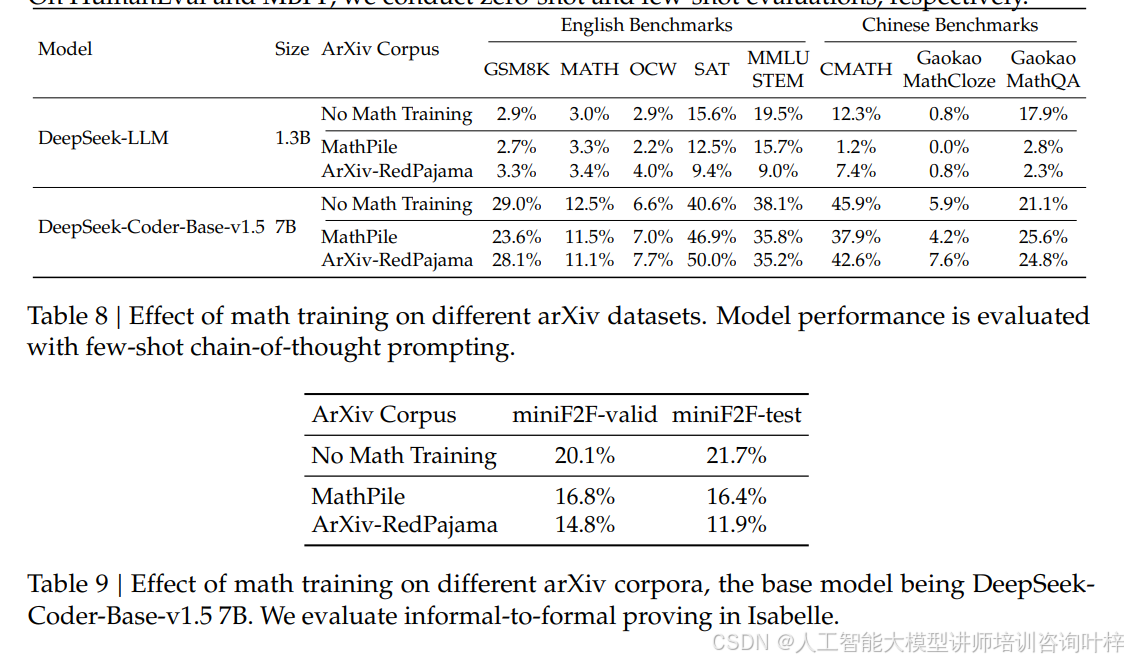 值得一提的是,团队还发现了很多反常识的训练经验。比如大家默认有用的 arXiv 论文,在实验中居然对数学推理提升没什么帮助,甚至会让部分基准的性能下降,表格 8和表格 9的数据显示,用 arXiv 相关数据集训练的模型在 GSM8K 和 miniF2F 等基准上表现还不如无数学训练的模型。而迭代式的强化学习能持续提升性能,图 6显示经过两轮迭代后,MATH 基准的准确率又有明显上涨。另外,RL 的提升并不是因为模型学会了新技能,而是让输出分布更稳定,图 7中 Maj@K(多数投票准确率)显著提升但 Pass@K(单次采样准确率)变化不大,就说明 RL 是让正确答案更容易被选中,而非增强了基础推理能力。
值得一提的是,团队还发现了很多反常识的训练经验。比如大家默认有用的 arXiv 论文,在实验中居然对数学推理提升没什么帮助,甚至会让部分基准的性能下降,表格 8和表格 9的数据显示,用 arXiv 相关数据集训练的模型在 GSM8K 和 miniF2F 等基准上表现还不如无数学训练的模型。而迭代式的强化学习能持续提升性能,图 6显示经过两轮迭代后,MATH 基准的准确率又有明显上涨。另外,RL 的提升并不是因为模型学会了新技能,而是让输出分布更稳定,图 7中 Maj@K(多数投票准确率)显著提升但 Pass@K(单次采样准确率)变化不大,就说明 RL 是让正确答案更容易被选中,而非增强了基础推理能力。
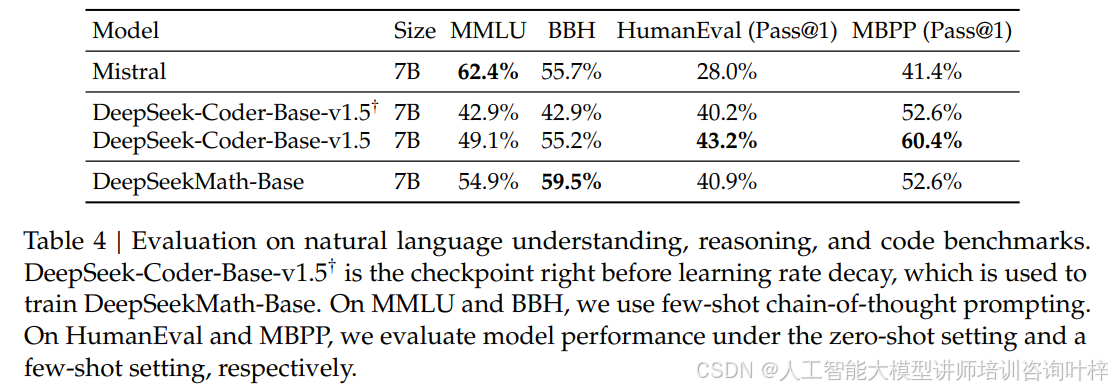
 除了数学能力,DeepSeekMath 的综合表现也很亮眼。经过数学训练后,它在 MMLU 和 BBH 这类通用推理基准上的性能也超过了前身 DeepSeek-Coder-Base-v1.5,表格 4显示其 MMLU 准确率达 54.9%,BBH 达 59.5%,同时还保持了不错的编码能力。在工具使用场景下,它用 Python 解题的准确率也领先同类模型,表格 3中 GSM8K+Python 的准确率达 66.9%,远超 Llemma 34B 的 64.6%。
除了数学能力,DeepSeekMath 的综合表现也很亮眼。经过数学训练后,它在 MMLU 和 BBH 这类通用推理基准上的性能也超过了前身 DeepSeek-Coder-Base-v1.5,表格 4显示其 MMLU 准确率达 54.9%,BBH 达 59.5%,同时还保持了不错的编码能力。在工具使用场景下,它用 Python 解题的准确率也领先同类模型,表格 3中 GSM8K+Python 的准确率达 66.9%,远超 Llemma 34B 的 64.6%。

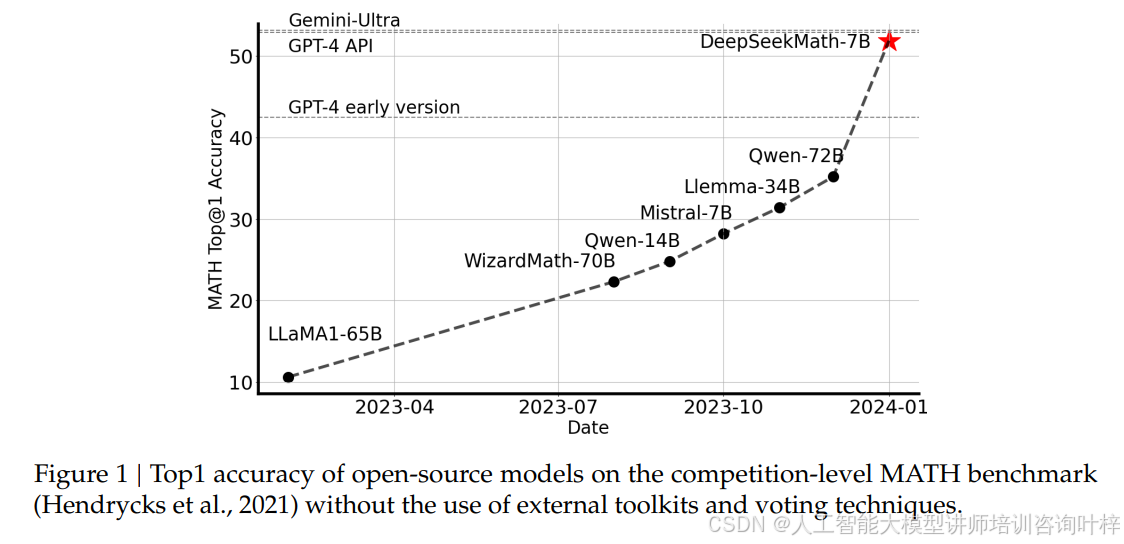
 当然 DeepSeekMath 也有短板,比如在几何题和定理证明上还不如闭源模型,处理三角形、椭圆相关问题时容易出错,而且少样本学习能力比 GPT-4 弱。但作为开源模型,它已经实现了巨大突破,图 1的趋势图也能看出,它在 MATH 基准上的表现远超同期其他开源模型,直奔 GPT-4 和 Gemini-Ultra 的水平。
当然 DeepSeekMath 也有短板,比如在几何题和定理证明上还不如闭源模型,处理三角形、椭圆相关问题时容易出错,而且少样本学习能力比 GPT-4 弱。但作为开源模型,它已经实现了巨大突破,图 1的趋势图也能看出,它在 MATH 基准上的表现远超同期其他开源模型,直奔 GPT-4 和 Gemini-Ultra 的水平。