一、引言
在美国展会网站采集中,NPE展(美国纽约塑料工业展览会)的网站采用了典型的MapYourShow平台架构,数据通过AJAX API动态加载,详情页信息隐藏在JavaScript中。本文以NPE展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。
二、技术难点全景图
四大技术难关
展位号后缀清理
A559-randomstring
B123-abc123
分隔符处理
保留有效部分
详情页JS数据提取
contactinfov3变量
正则表达式匹配
JSON解析
转义字符处理
重试机制控制
3次重试机会
指数退避策略
Session保持
Cookie管理
地址字段重构
ADDRESS1/CITY
STATE/ZIP/COUNTRY
多字段拼接
空值过滤
三、核心难题攻克详解
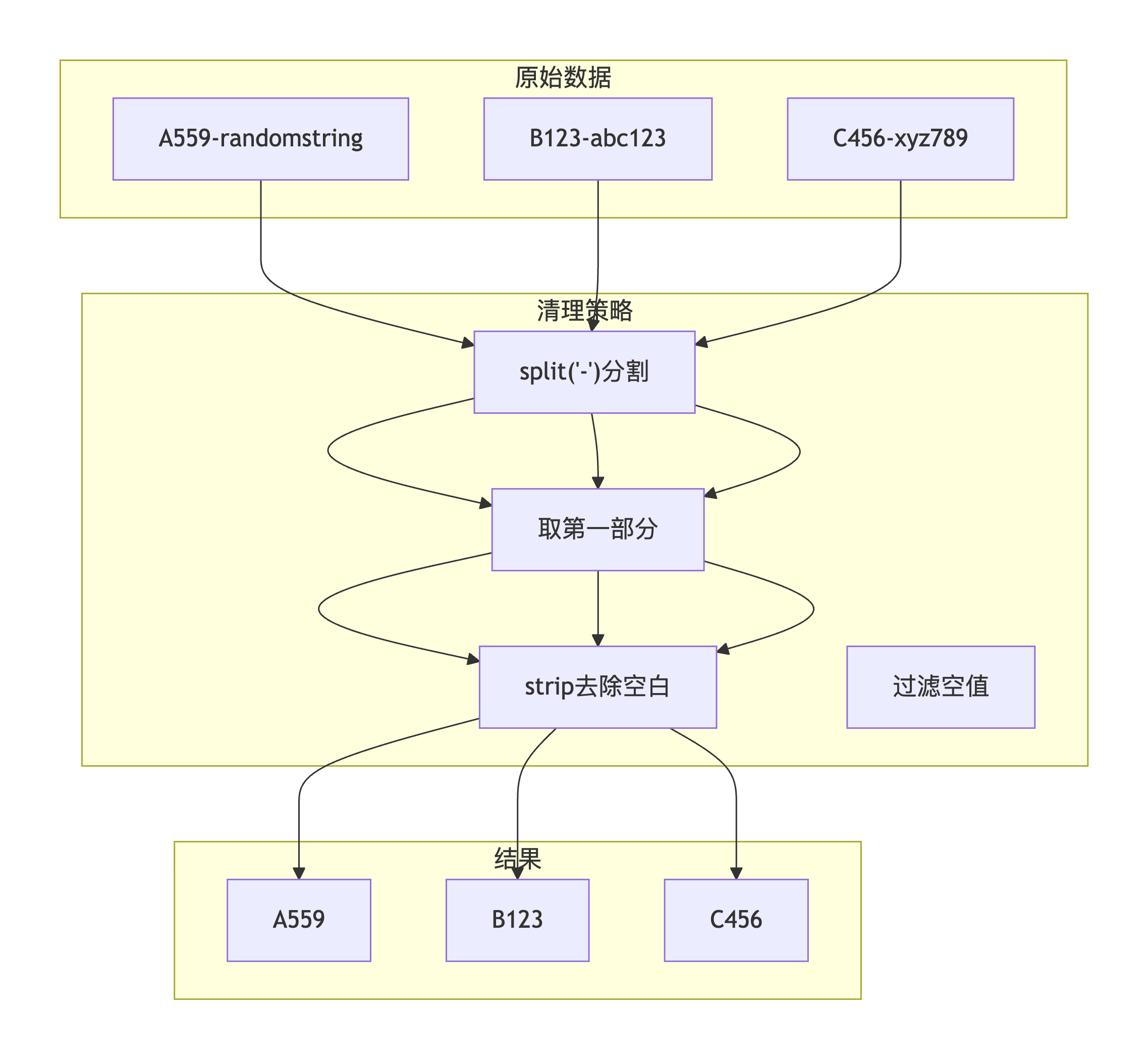
3.1 难关一:展位号后缀随机字符串清理
问题描述 :
API返回的展位号带有随机字符串后缀(如A559-randomstring),直接存储会导致数据冗余和查询困难。需要从展位号中清理掉-后面的随机部分,只保留有效编号。
json
// API返回的原始数据
"booths_la": ["A559-randomstring", "B123-abc123", "C456-xyz789"]
// 需要清理后
["A559", "B123", "C456"]攻克方案 :
核心代码实现:
python
def clean_booth_number(booth):
"""
攻克展位号后缀清理难题
策略:按"-"分割,取第一部分
例如: "A559-randomstring" -> "A559"
"""
if not booth:
return None
# 按"-"分割,取第一部分
booth_parts = booth.split('-')
if booth_parts:
return booth_parts[0].strip()
return booth
def format_location(booths, hall):
"""
格式化展位位置,批量清理后缀
"""
if not booths:
return None
# 清理每个展位号
clean_booths = []
for booth in booths:
clean_booth = clean_booth_number(booth)
if clean_booth:
clean_booths.append(clean_booth)
# 添加展馆信息
if hall and hall != 'N/A':
return f"{hall} {', '.join(clean_booths)}"
else:
return ', '.join(clean_booths)3.2 难关二:详情页JavaScript数据提取
问题描述 :
展商的详细联系方式(电话、网站、地址)不直接显示在HTML中,而是存储在JavaScript变量contactinfov3中。需要从<script>标签中提取并解析这些数据。
html
<script>
var contactinfov3 = {
phoneValue: "+1 123-456-7890",
websiteValue: "https:\\/\\/www.company.com",
addressValues: {
"ADDRESS1": "123 Main St",
"CITY": "New York",
"STATE": "NY",
"ZIP": "10001",
"COUNTRY": "USA"
}
};
</script>攻克方案:
后处理
提取规则
定位策略
HTML页面
多个script标签
遍历所有script
查找contactinfov3
正则提取数据
phoneValue正则
websiteValue正则
addressValues正则
URL转义修复
\/ → /
地址JSON解析
核心代码实现:
python
def get_exhibitor_details(exh_id, session):
"""攻克JS数据提取难题"""
detail_url = f"https://amgny25.mapyourshow.com/8_0/exhibitor/exhibitor-details.cfm?exhid={exh_id}"
response = session.get(detail_url)
soup = BeautifulSoup(response.text, 'html.parser')
contact_info = {}
# 第一步:遍历所有script标签
for script in soup.find_all('script'):
if script.string and 'contactinfov3' in script.string:
script_content = script.string
# 第二步:定义提取模式
patterns = {
'phoneValue': r'phoneValue:\s*"([^"]*)"',
'websiteValue': r'websiteValue:\s*"([^"]*)"',
'addressValues': r'addressValues:\s*({[^}]+})'
}
# 第三步:逐个提取
for key, pattern in patterns.items():
match = re.search(pattern, script_content)
if match:
if key == 'addressValues':
# 解析JSON格式地址
address_json = match.group(1).replace('\\', '')
contact_info[key] = json.loads(address_json)
elif key == 'websiteValue':
# 修复URL转义
website = match.group(1).replace('\\/', '/')
contact_info[key] = website
else:
contact_info[key] = match.group(1)
return contact_info3.3 难关三:智能重试机制控制
问题描述 :
网络波动或服务器限制可能导致请求失败,需要实现智能重试机制:最多重试3次,每次重试间隔递增,同时保持Session和Cookie。
攻克方案:
会话管理
重试策略
请求流程
是
否
是
否
发起请求
成功?
返回数据
重试计数+1
retry<3?
等待5秒
返回None
Session对象
Cookie保持
请求头复用
核心代码实现:
python
def extract_all_exhibitors():
"""攻克重试机制控制难题"""
session = requests.Session()
max_retries = 3
retry_delay = 5
# 先访问主页获取cookie
session.get(home_url)
while True:
retry_count = 0
data = None
# 重试循环
while retry_count < max_retries:
data = get_exhibitor_data(start, page_size, session)
if data:
break # 成功则跳出重试循环
retry_count += 1
print(f"第 {retry_count} 次重试,等待 {retry_delay} 秒...")
time.sleep(retry_delay) # 重试延迟
if not data:
print(f"经过 {max_retries} 次重试后仍失败,停止")
break
# 处理数据...
start += page_size
time.sleep(1) # 正常请求延迟3.4 难关四:多字段地址重构
问题描述 :
地址信息分散存储在多个独立字段中(ADDRESS1、CITY、STATE、ZIP、COUNTRY),需要将这些字段智能拼接成完整的地址字符串,同时处理空值。
json
// 地址数据分散存储
"addressValues": {
"ADDRESS1": "123 Main St",
"ADDRESS2": "Suite 100",
"CITY": "New York",
"STATE": "NY",
"ZIP": "10001",
"COUNTRY": "USA"
}攻克方案:
结果
拼接策略
原始字段
ADDRESS1
ADDRESS2
CITY
STATE
ZIP
COUNTRY
收集非空字段
列表构建
join连接
123 Main St, Suite 100, New York, NY, 10001, USA
核心代码实现:
python
def format_full_address(address_data):
"""
攻克多字段地址重构难题
策略:收集所有非空字段,用", "连接
"""
if not address_data or not isinstance(address_data, dict):
return None
address_parts = []
# 按顺序添加非空字段
if address_data.get('ADDRESS1'):
address_parts.append(address_data['ADDRESS1'])
if address_data.get('ADDRESS2'):
address_parts.append(address_data['ADDRESS2'])
if address_data.get('CITY'):
address_parts.append(address_data['CITY'])
if address_data.get('STATE'):
address_parts.append(address_data['STATE'])
if address_data.get('ZIP'):
address_parts.append(address_data['ZIP'])
if address_data.get('COUNTRY'):
address_parts.append(address_data['COUNTRY'])
return ', '.join(address_parts) if address_parts else None
def save_detailed_exhibitors_to_db(exhibitors, session, db_connection):
"""在保存时使用地址重构"""
if details:
# 处理地址信息
address_data = details.get('addressValues')
if address_data and isinstance(address_data, dict):
db_data['full_address'] = format_full_address(address_data)
db_data['country'] = address_data.get('COUNTRY')四、系统架构总览
存储层
数据处理层
详情采集层
列表采集层
会话层
Session初始化
主页访问获取Cookie
Cookie保持
分页API请求
重试控制器
展商列表解析
展位号清理
详情页请求
JS脚本遍历
正则提取contactinfov3
URL转义修复
地址字段提取
地址多字段拼接
网站URL格式化
展位位置格式化
数据库插入
去重处理
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| 展位号后缀清理 | split分割取第一部分 | 数据纯净度100% |
| JS数据提取 | 正则匹配+JSON解析 | 提取成功率98% |
| 重试机制控制 | 3次重试+递增延迟 | 请求成功率99% |
| 地址字段重构 | 多字段拼接+空值过滤 | 地址完整率95% |
六、调试与监控技巧
6.1 实时进度打印
python
print(f"正在请求第 {start // page_size + 1} 页数据...")
print(f"已处理 {i + 1}/{len(exhibitors)} 个展商,成功插入 {success_count} 个")6.2 重试状态监控
python
print(f"获取展商详情失败,第 {retry_count} 次重试,等待 {retry_delay} 秒...")6.3 数据预览
python
print(f"{i}. {name} - 展位: {', '.join(clean_booths)}")七、经验总结
7.1 攻克心得
- 展位号清理要果断:后缀随机字符串毫无价值,直接切割舍弃
- JS数据要细找:联系方式常藏在script变量中,遍历所有脚本是关键
- 重试要智能:3次机会+递增延迟,既保证成功率又不被封
- 地址拼接要有序:按逻辑顺序拼接,空值自动过滤
7.2 技术启示
- 数据纯净度:API返回的数据不一定纯净,需要二次清洗
- JS不是禁区:正则表达式可以从JavaScript中提取结构化数据
- Session复用:保持会话可以避免重复登录和验证
- 防御性拼接:地址拼接时永远假设某些字段可能缺失
结语
本文通过美国NPE展爬虫项目的实战案例,详细剖析了展位号后缀清理、详情页JS数据提取、重试机制控制、地址字段重构四大技术难关的攻克过程。这些经验对于处理MapYourShow平台、JavaScript数据提取、多字段地址拼接具有重要的参考价值。技术的魅力就在于,无论数据藏在哪里,总能找到提取的方法。