1. 认识AI
1.1. 体验AI产品
体验AI产品,体验智能客服、语音助手、图像识别等应用,发现它们功能强大且操作便捷。从对话交流到任务执行,AI产品展现了高度的智能化水平。AI技术在多场景下展现了广泛应用和潜力,为生活和工作带来显著改变。
1.1.1. 文本类产品
文本类的产品有很多,比如:Deepseek、通义千问、ChatGPT等。这里以Deepseek为例,让它帮我写一个Java的HelloWorld程序。
1.1.2. 文生图产品
这里以通义千问为例。
1.1.3. 文生视频产品
可以通过文字来生成视频,这里以 智谱清言 为例。
文案:
当你的双脚在峭壁颤抖时,请记住:真正的高峰不是用海拔丈量,而是用跌倒的次数刻下的勋章。黑暗最浓时星光最亮,荆棘最深处玫瑰最艳,每个被汗水浸透的脚印都在重塑命运的轨迹。别怕山峦遮住太阳------你站直脊梁的瞬间,就是地平线升起的时刻。向前跑,带着裂缝里透进的光!
1.2. AI是什么
人工智能(AI,A rtificial Intelligence)是让机器模拟人类智能的技术,使其能像人一样学习、推理、感知和决策。例如,它能识别语音、推荐视频或汽车的自动驾驶等。
AI之所以智能,是因为它底层是基于Transformer 架构实现的,Transformer是AI处理语言的核心架构(比如ChatGPT、Deepseek都是基于它实现)。它的核心突破是"自注意力机制"**,让AI能像人一样,通过上下文理解每个词的含义。例如:
举例: 她吃了一个苹果
- 传统模型只能逐字分析,可能忽略"吃"和"苹果"之间的关联。
- Transformer会自动让"吃"关注"苹果",理解动作和对象的关系。
- Transformer让AI学会"联系上下文",像人类一样理解语言逻辑,是当前AI爆发(如ChatGPT)的核心技术。
1.3. 大模型原理
大模型 = 通过海量数据 训练出的"超级自动补全工具 ",核心能力是根据输入内容预测下一个词。
核心原理拆解:
- 底层架构:Transformer(积木块结构)
- 核心组件:自注意力机制(Self-Attention)
- 作用:让模型像人类一样,自动关注输入内容中哪些词更重要(例如:"她吃了一个苹果"中,"吃"是核心动词)。
- 训练过程:
-
预训练:用全网文本(书籍/网页等)学习语言规律,建立"知识库"。
-
例:输入"天空是__",模型学习预测"蓝色"。
-
微调:用特定任务数据(如对话/问答)调整模型,让它更"听话"。
- 运行本质:概率
- 每次输出一个词时,模型计算所有可能词的概率,选择最高概率的词(或随机选高概率词增加多样性)。
- 例:输入"The boy went to the",模型可能输出"Cafe"(概率0.1)、"Hospital"(0.05)、"Playground"(0.4)、"Park"(0.15)、"School"(0.3)。
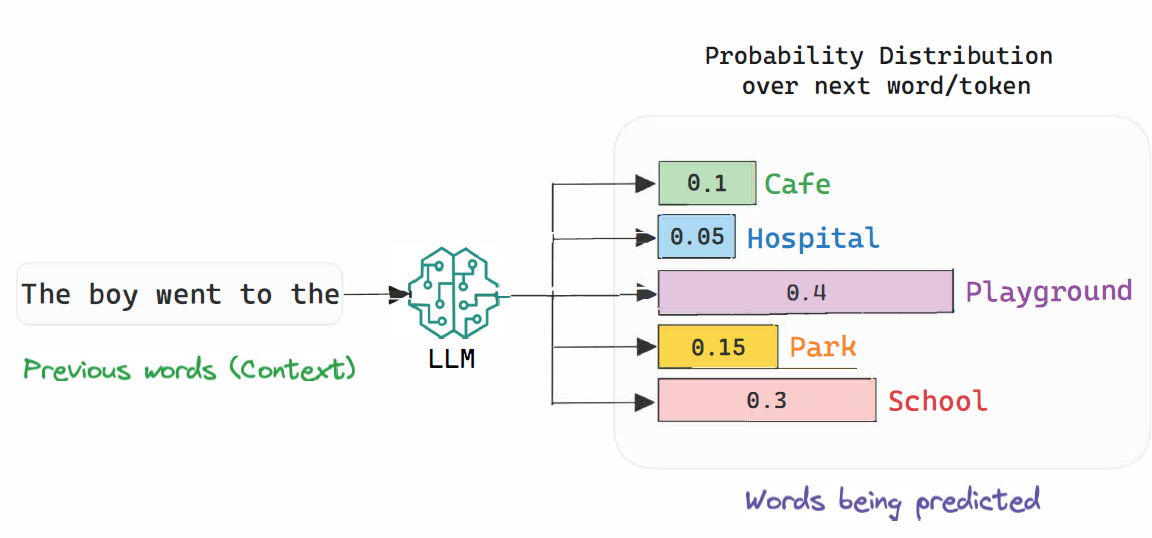
- 大模型输出时,会选择概率值最高的词,最终会输出:The boy went to the Playground(男孩去了游乐场)
- 这里的概率,是指条件概率,也就是说,【游乐场】是【男孩去的地方】概率0.4
‼️大模型正是因为依据概率回答,所以会存在"AI幻觉",也就是所谓的"胡说八道"。所以,对于大模型生成的数据,需要进行优化数据、加入人工审核、提醒用户自行验证等。
1.4. 大模型应用架构
基于大模型开发应用有多种方式,接下来我们就来了解下常见的大模型开发技术架构。
1.4.1. 技术架构
目前,大模型应用开发的技术架构主要有四种:
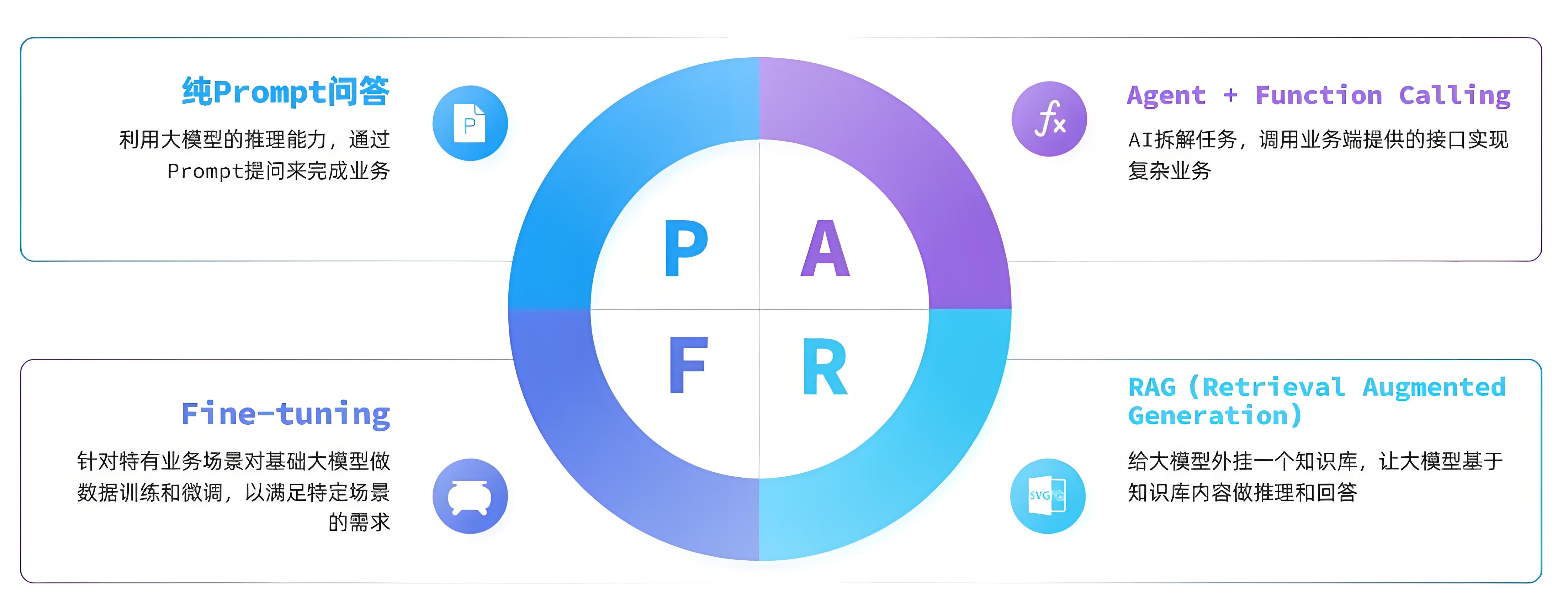
1.4.2. 纯Prompt模式
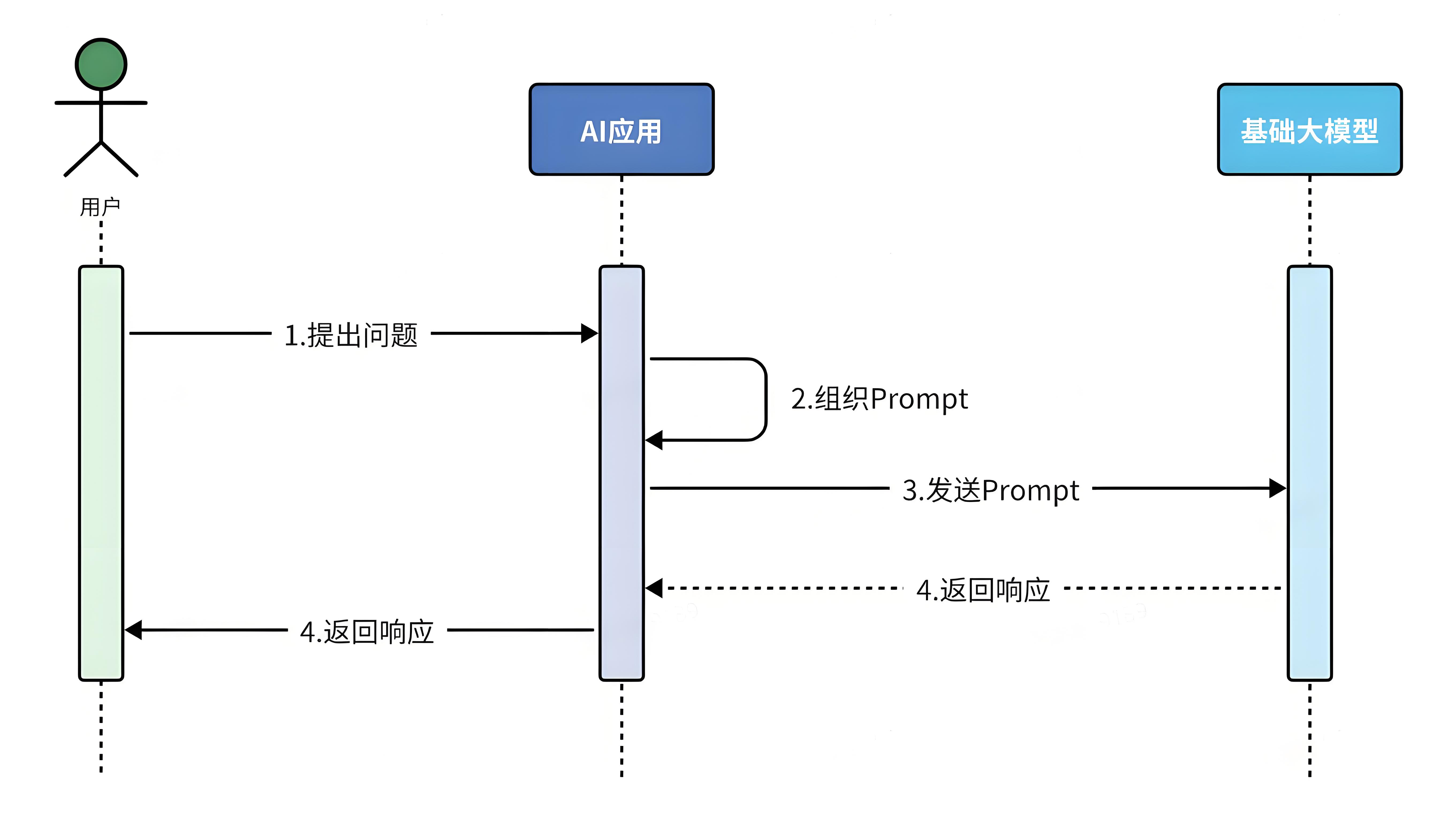
Prompt是指提示词,很多简单的AI应用,仅仅靠一段足够好的提示词就能实现了,这种模式就是纯Prompt模式。
由于不同的提示词,能够让大模型给出差异巨大的答案。不断雕琢提示词,使大模型能给出最理想的答案 ,这个过程就叫做提示词工程 (Prompt Engineering)。
其流程如图:
1.4.3. Function Calling(Tool Calling)
大模型虽然可以理解自然语言,更清晰弄懂用户意图,但是确无法直接操作数据库、执行严格的业务规则。这个时候我们就可以整合传统的应用,来增强大模型的能力。
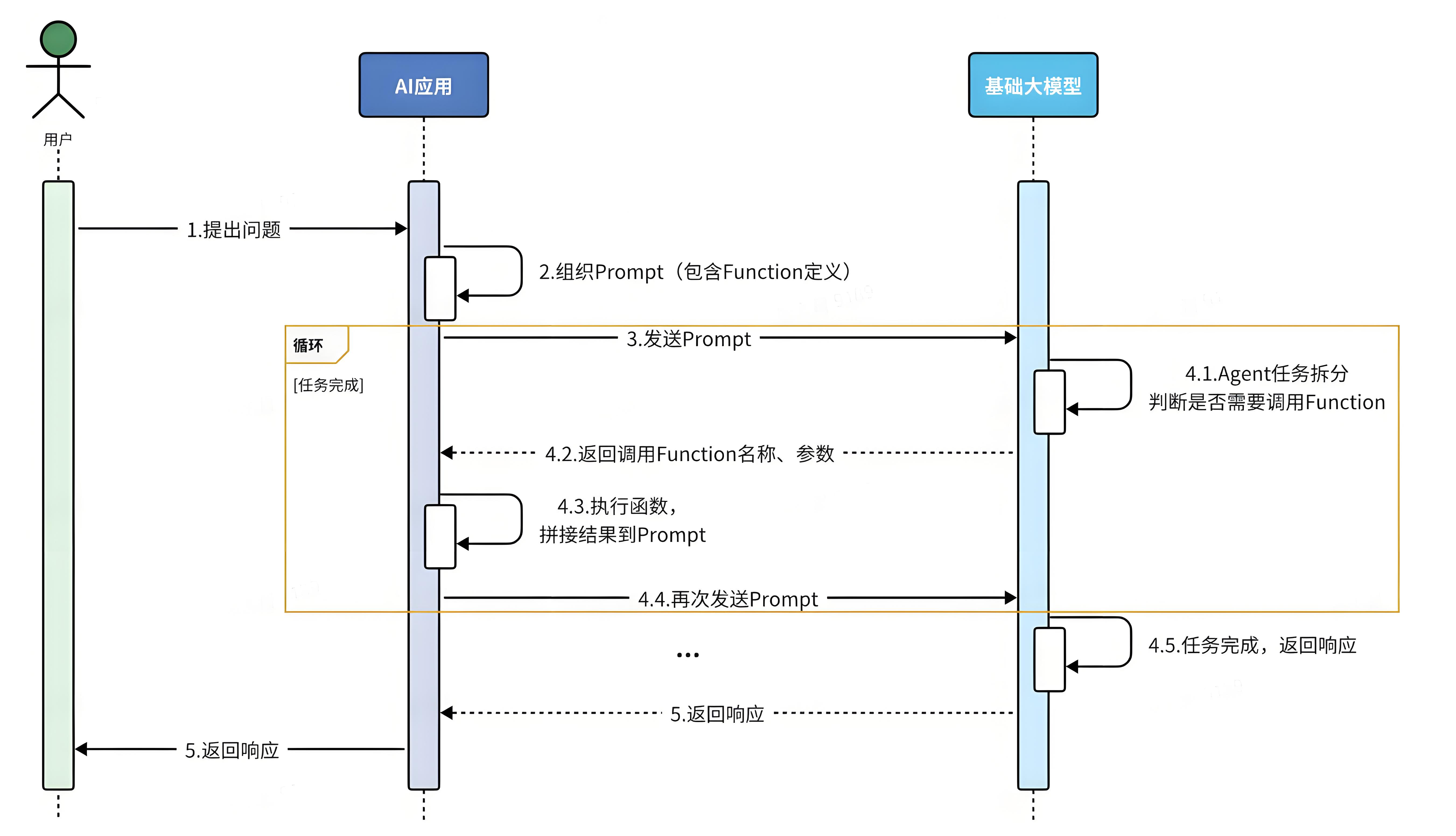
简单来说,可以分为以下步骤:
- 我们可以把传统应用中的部分功能封装成一个个函数(Function 或 Tool)。
- 然后在提示词中描述用户的需求,并且描述清楚每个函数的作用,要求AI理解用户意图,判断什么时候需要调用哪个函数,并且将任务拆解为多个步骤(Agent)。
- 当AI执行到某一步,需要调用某个函数时,会返回要调用的函数名称、函数需要的参数信息。
- 传统应用接收到这些数据以后,就可以调用本地函数。再把函数执行结果封装为提示词,再次发送给AI。
- 以此类推,逐步执行,直到达成最终结果。
流程如图:
‼️注意 :并不是所有大模型都支持Function Calling。可参阅Spring AI官方文档,点击这里。
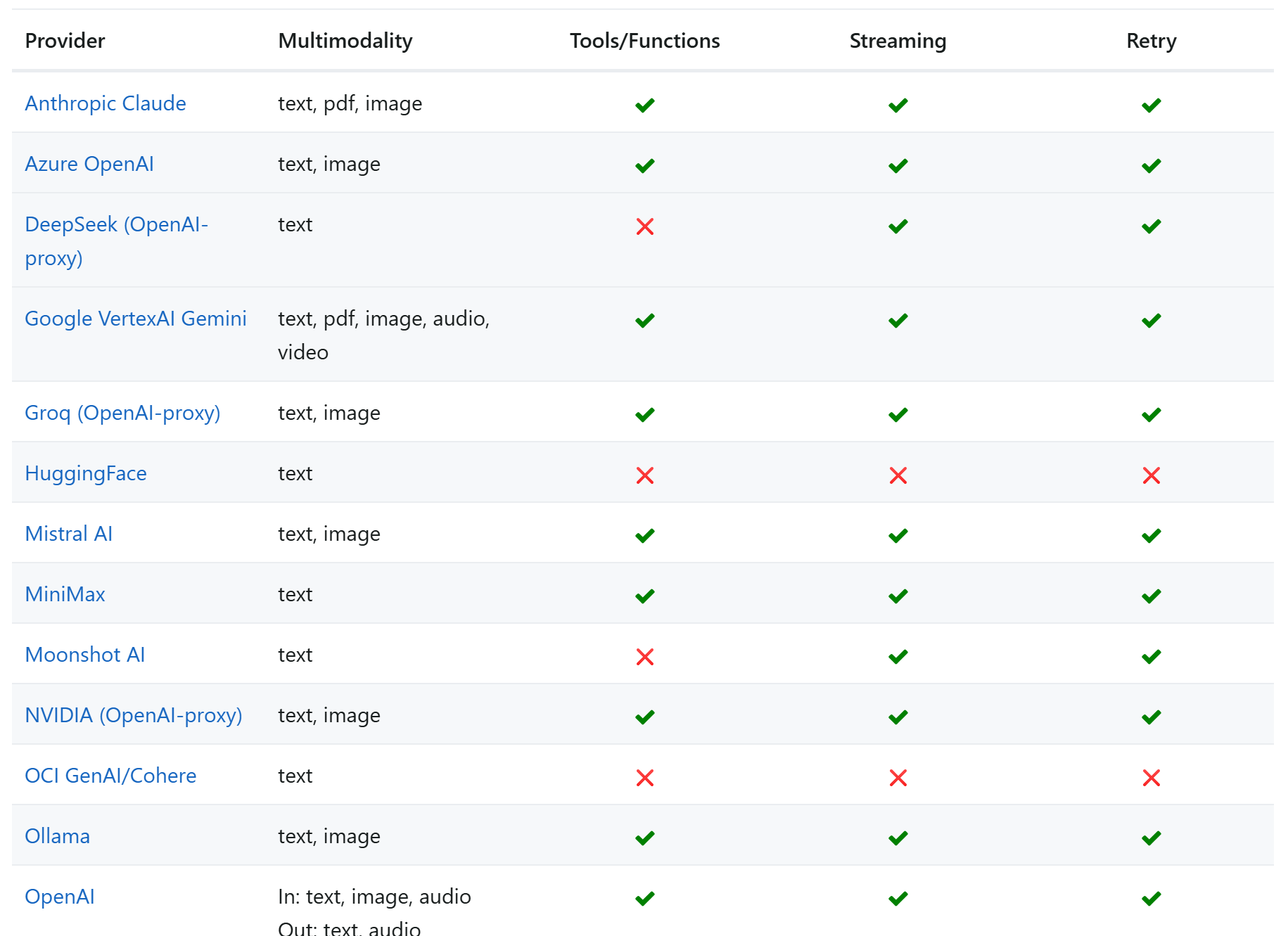
1.4.4. RAG
RAG(R etrieval**-Augmented Generation)叫做检索增强生成。简单来说就是把 信息检索技术和大模型**结合的方案。
大模型从知识角度存在很多限制:
- 时效性差:大模型训练比较耗时,其训练数据都是旧数据,无法实时更新
- 缺少专业领域知识:大模型训练数据都是采集的通用数据,缺少专业数据
流程如图:
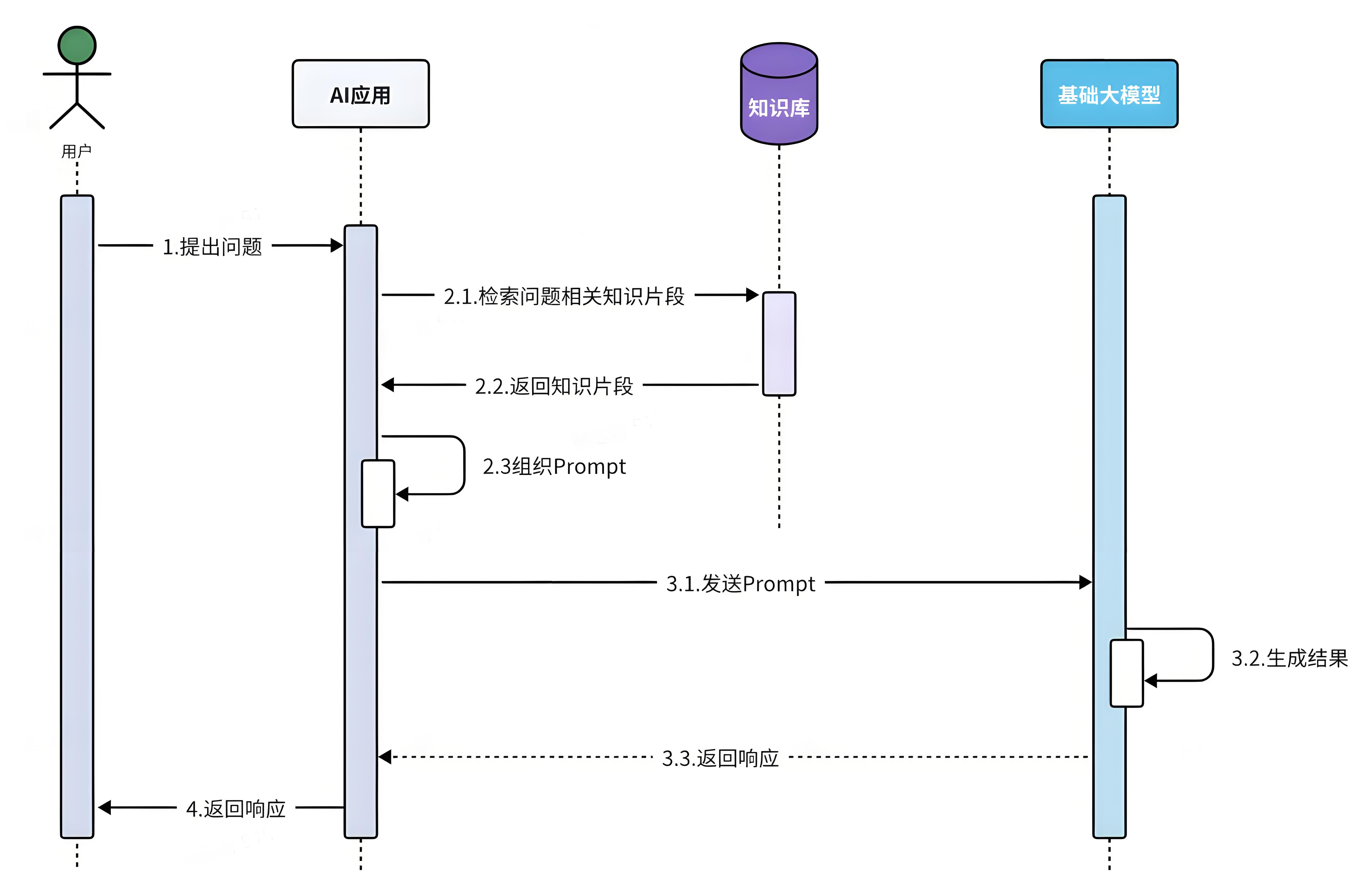
❓思考:
这里有个问题,为什么不可以把最新的数据或者专业文档都拼接到提示词中,一起发给大模型,这样就不用RAG了?
这是不可以的,现在的大模型都是基于Transformer神经网络,Transformer的强项就是所谓的注意力机制。它可以根据上下文来分析文本含义,所以理解人类意图更加准确。
但是,这里上下文的大小是有限制 的,GPT3刚刚出来的时候,仅支持2000个token的上下文。现在领先一点的模型支持的上下文数量也不超过 200K token,所以海量知识库数据是无法直接写入提示词的。
Token是什么?

🚦需要注意的是,大模型的输入和输出都是分别计算token的,也就是双向收费。
RAG就是利用信息检索技术来拓展大模型的知识库,解决大模型的知识限制。整体来说RAG分为两个模块:
-
检索模块(Retrieval):负责存储和检索拓展的知识库
-
文本拆分:将文本按照某种规则拆分为很多片段,最好每一个片段都是相关信息
-
文本嵌入(Embedding):使用向量模型将文本片段转为向量,方便根据向量计算文本相似度
-
向量存储和搜索:将得到的向量存储到向量数据库中,将来根据用户提问来检索文本片段
-
生成模块(Generation):
-
组合提示词:将检索到的片段与用户提问组织成提示词,形成更丰富的上下文信息
-
生成结果:调用生成式模型(例如DeepSeek)根据提示词,生成更准确的回答
由于每次都是从向量库中找出与用户问题相关的数据,而不是整个知识库,所以上下文就不会超过大模型的限制,同时又保证了大模型回答问题是基于知识库中的内容,完美!
1.4.5. Fine-tuning
Fine-tuning 就是模型微调,就是在预训练大模型(比如DeepSeek、Qwen)的基础上,通过企业自己的数据做进一步的训练,使大模型的回答更符合自己企业的业务需求。这个过程通常需要在模型的参数上进行细微的修改,以达到最佳的性能表现。
在进行微调时,通常会保留模型的大部分结构和参数,只对其中的一小部分进行调整。这样做的好处是可以利用预训练模型已经学习到的知识,同时减少了训练时间和计算资源的消耗。微调的过程包括以下几个关键步骤:
- 选择合适的预训练模型:根据任务的需求,选择一个已经在大量数据上进行过预训练的模型,如Qwen-2.5。
- 准备特定领域的数据集:收集和准备与任务相关的数据集,这些数据将用于微调模型。
- 设置超参数:调整学习率、批次大小、训练轮次等超参数,以确保模型能够有效学习新任务的特征。
- 训练和优化:使用特定任务的数据对模型进行训练,通过前向传播、损失计算、反向传播和权重更新等步骤,不断优化模型的性能。
模型微调虽然更加灵活、强大,但是也存在一些问题:
- 需要大量的计算资源
- 调参复杂性高
- 过拟合风险(指模型在训练数据上表现过于完美 ,但在新数据上表现明显变差的风险)
总之,Fine-tuning成本较高,难度较大,并不适合大多数企业。而且前面三种技术方案已经能够解决常见问题了。
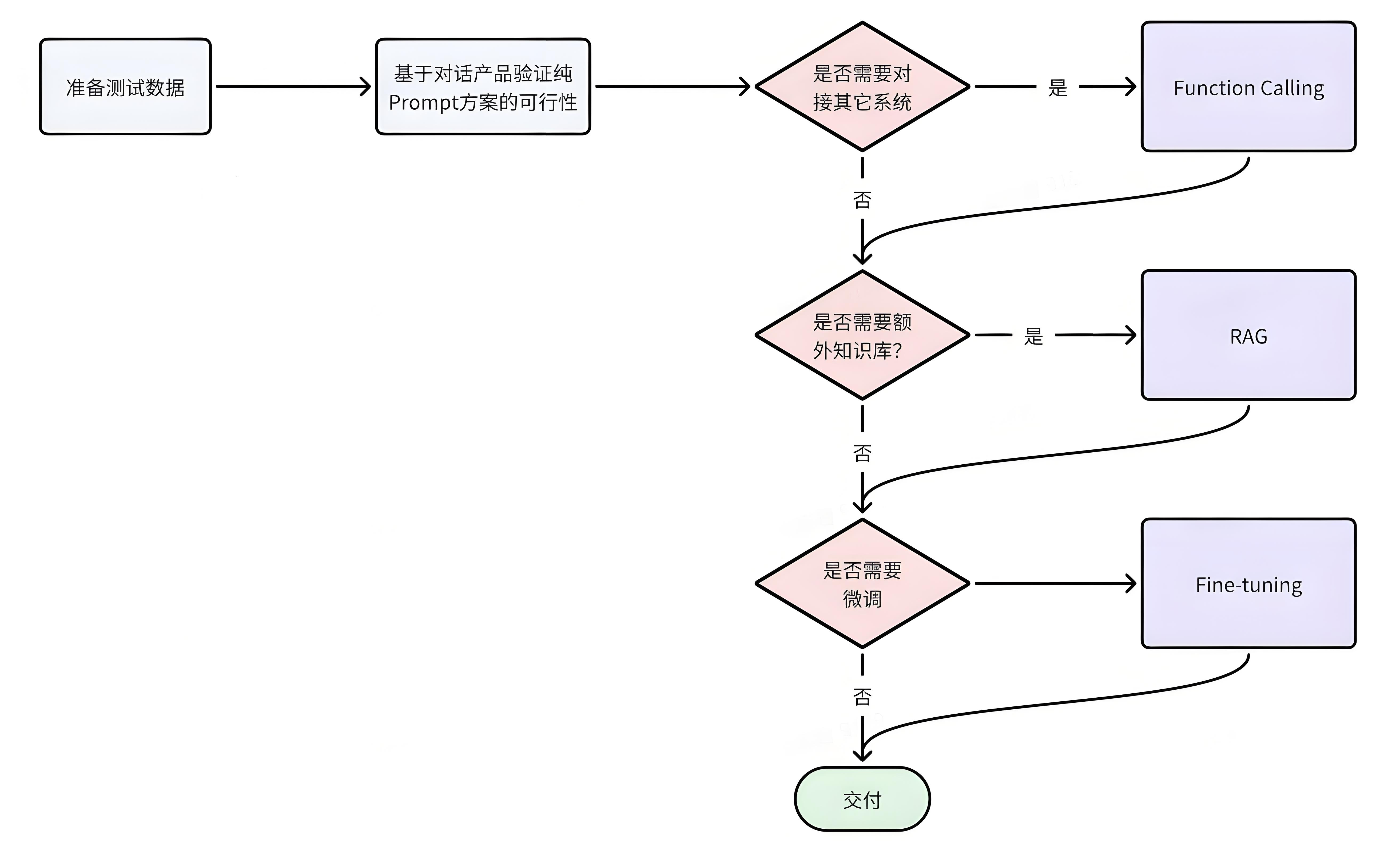
1.4.6. 技术选型
从开发成本由低到高来看,四种方案排序如下:
Prompt < Function Calling < RAG < Fine-tuning
所以我们在选择技术时通常也应该遵循"在达成目标效果的前提下,尽量降低开发成本"这一首要原则。可以参考以下流程来思考:
2. 对接AI大模型
AI大模型一般分为两类,一种是公共大模型,另一种是私有大模型。我先学习公共大模型。
2.1. 公共大模型
常用的公共大模型平台有:
| 平台 | 公司 | 链接 |
|---|---|---|
| OpenAI | OpenAI(美国) | https://openai.com/ |
| 阿里云百炼 | 阿里巴巴 | https://bailian.aliyun.com/ |
| Deepseek | 深度求索 | https://www.deepseek.com/ |
| 腾讯混元 | 腾讯 | https://hunyuan.tencent.com/ |
| 千帆平台 | 百度 | https://cloud.baidu.com/product-s/qianfan_home |
| 智谱AI | 智谱华章科技 | https://bigmodel.cn/ |
| 火山方舟 | 字节跳动 | https://www.volcengine.com/product/ark |
太多了,就不一一列举了。😀
🚀 需要说明的是,这些平台一般都不是免费的,会按照token进行收费,并且是双向收费(请求和回答),这些平台一般对于新用户新用户都会赠送免费token额度,例如:阿里云百炼平台会赠送100w的token额度。
2.2. 阿里云百炼
以阿里云百炼平台为例介绍如何使用这些公共平台。
2.2.1. 注册账号
如果没有阿里云账号,您需要先注册阿里云账号。
2.2.2. 开通百炼服务
使用阿里云主账号前往百炼控制台,开通百炼的模型服务,新用户开通即享每个模型100万免费tokens。
🔔说明 :如果开通服务时提示"您尚未进行实名认证",请先进行实名认证。
如果开通成功,可以看到百炼的模型广场页面:
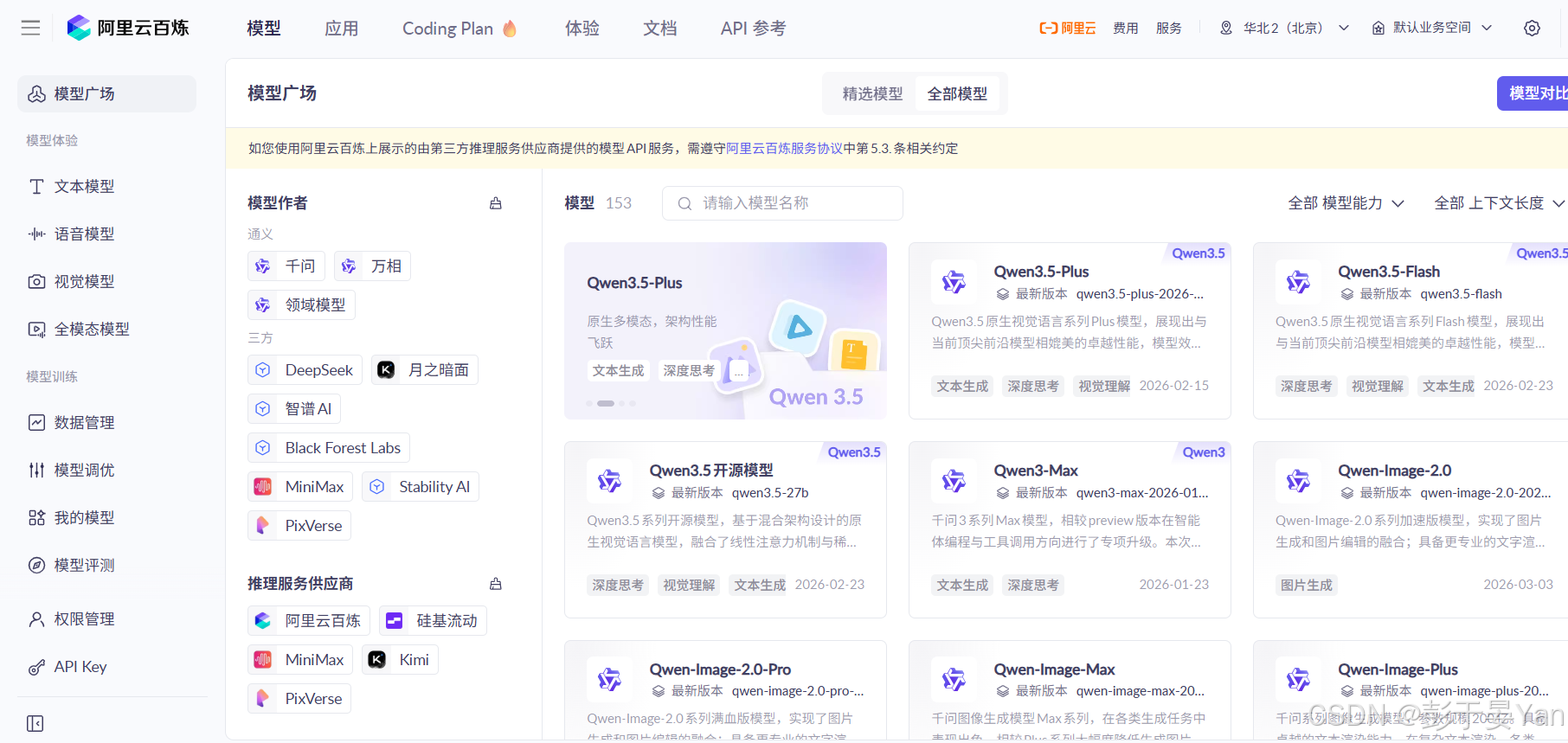
可以看到,有非常多的模型可供选择,点击模型的【查看详情】链接可以查看模型名称、价格、免费额度等信息。
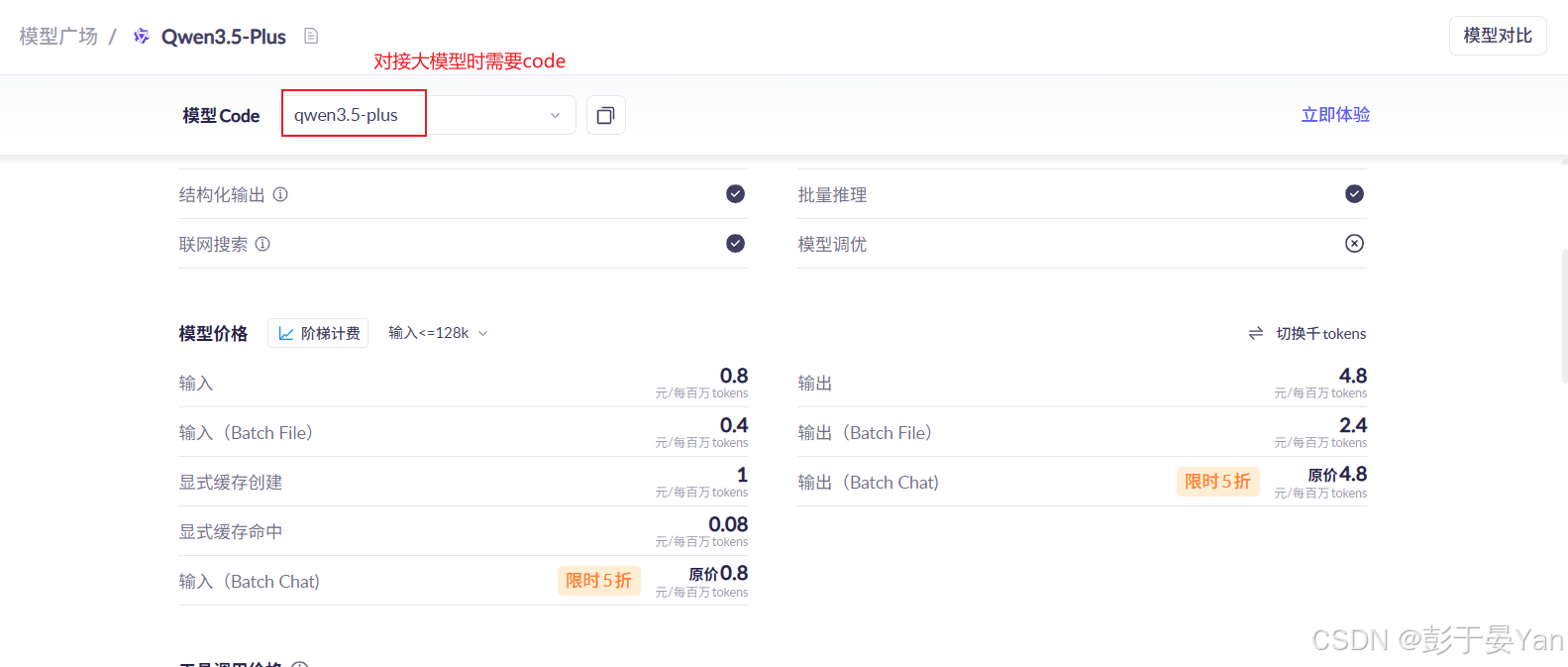
2.2.3. 申请API KEY
对接大模型,需要申请API KEY,步骤如下:
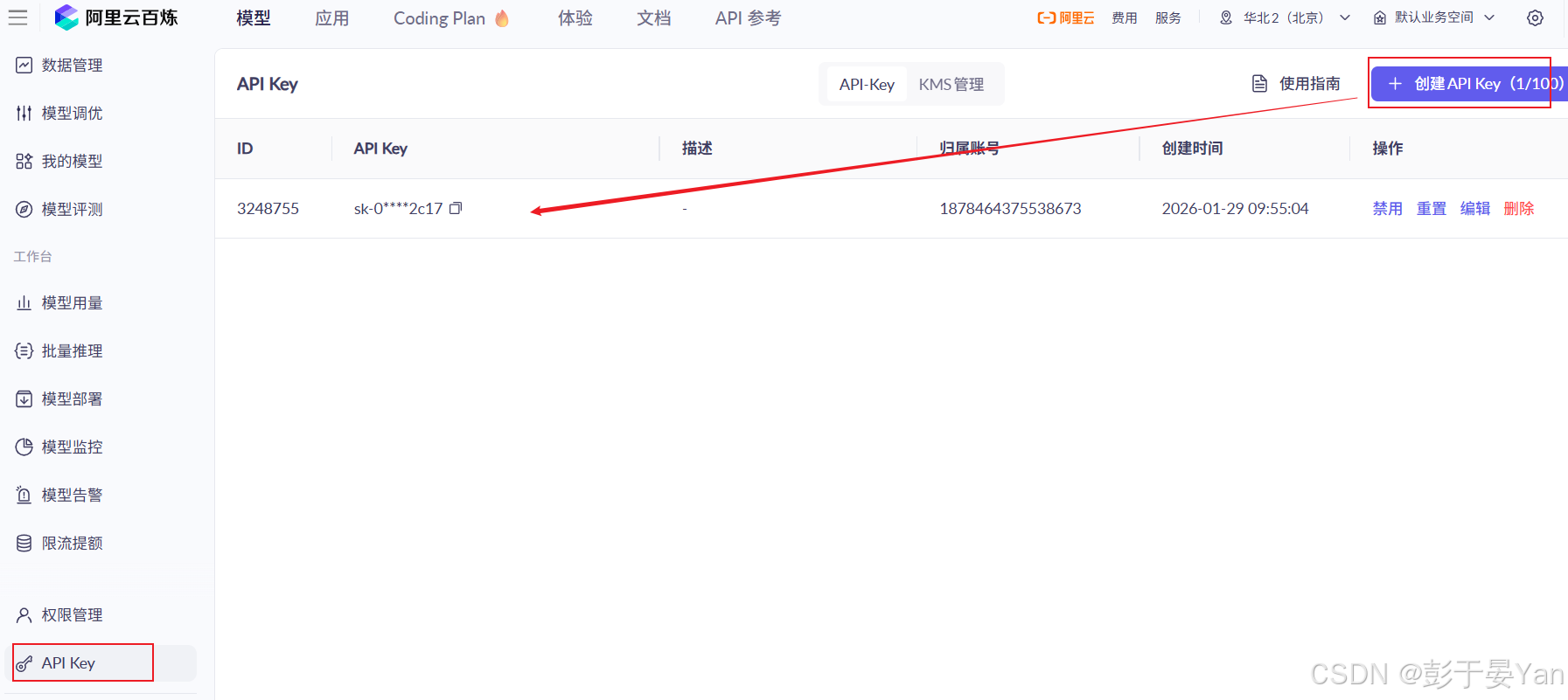
⛔ 这个key一定不能泄露出去...
2.2.4. 体验文本调试
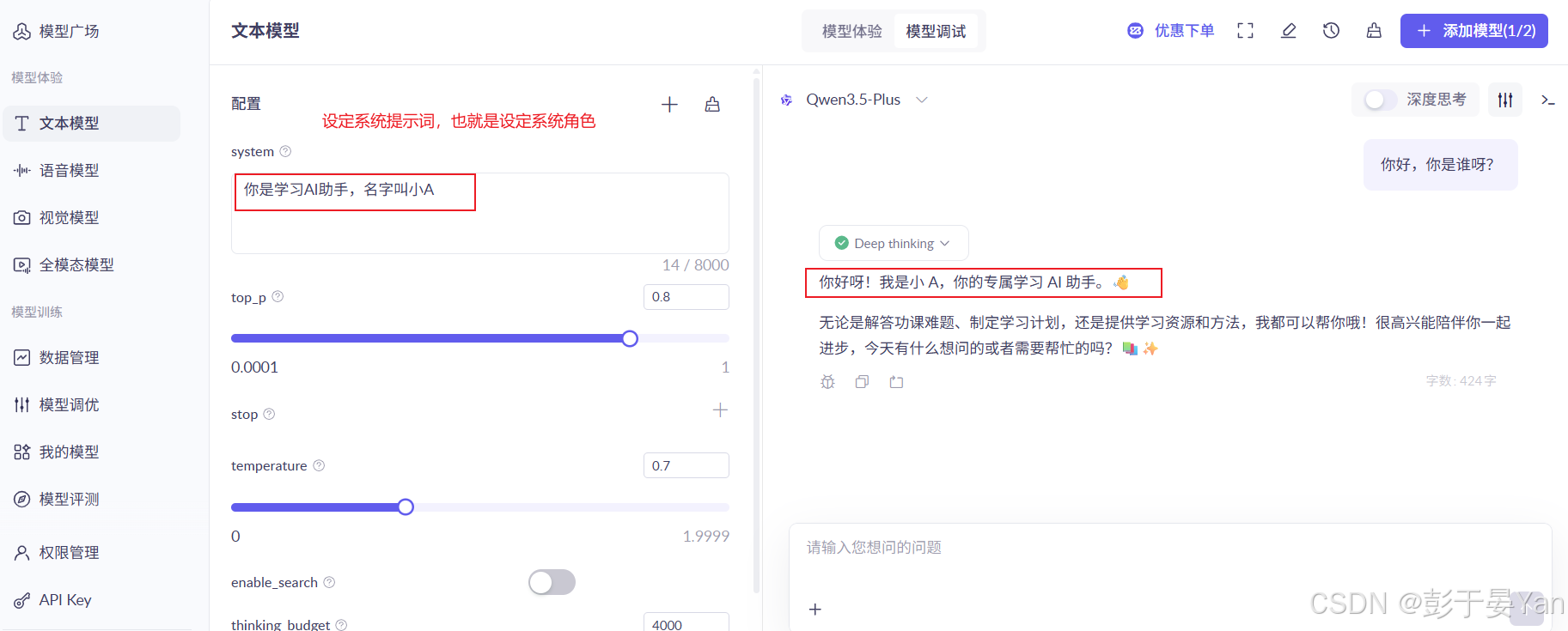
🚀 参数说明:
-
temperature
- 采样温度,控制模型生成文本的多样性。
- temperature 越高,生成的文本更多样,反之,生成的文本更确定。
- 取值范围: [0, 2)
-
top_p
- 核采样的概率阈值,控制模型生成文本的多样性。
- top_p越高,生成的文本更多样。反之,生成的文本更确定。
- 取值范围:(0,1.0]
-
⚡由于
temperature与top_p均可以控制生成文本的多样性,因此建议只设置其中一个值。推荐设置 temperature,因为这是大部分模型的通用参数。 -
更多内容,可以参见阿里云文档。👉 Temperature 和 top_p-阿里云帮助中心
-
不同的模型,设置的值是不一样的,例如,DeepSeek的建议如下:👉 Temperature 设置 | DeepSeek API Docs
2.3. OpenAI
OpenAI算是最早一批做AI的公司了,它设计的API接口标准现在被很多其他公司采用,已经成为了行业的标准。每个大模型平台都有自己的API接口,比如网址、请求方式和响应格式等,但这些通常都不太一样。不过,大多数平台都会支持OpenAI的标准API。
这意味着,学会了OpenAI的API,你就可以更容易地使用其他很多大模型平台了。所以,学习AI是绕不开OpenAI的。
2.3.1. 介绍
OpenAI是美国一家成立于2015年的人工智能研究机构,致力于推动人工智能的安全与普惠发展,其目标是确保通用人工智能(AGI)造福全人类。它以开发前沿技术如GPT系列语言模型(如ChatGPT、GPT-4)和图像生成模型DALL-E而闻名,通过公开发布研究成果和API接口,推动AI技术在多个领域的应用与创新。
官网:(OpenAI官网是无法直接访问的,需要科学上网才能访问)
📚OpenAI 与 ChatGPT是什么关系?
OpenAI 是开发 ChatGPT 的公司,而 ChatGPT 是 OpenAI 基于 GPT 系列技术(如 GPT-3.5、GPT-4)构建的对话型人工智能产品。也就是说,ChatGPT 是 OpenAI 研发的落地应用之一,用于实现自然语言交互,体现其推动 AI 普惠的技术目标。
2.3.2. 申请账号
由于网络缘故,无法直接使用OpenAI的大模型服务,可以使用OpenAI的代理服务来使用,使用方式和效果都是一样的,在国内使用起来更加顺畅。
代理商地址:👉 ChatAnywhere
代理商提供的账号分为两种,免费和收费。只演示免费账号如何申请。
查看所支持的大模型以及价格,👉 ChatAnywhere API 帮助文档
2.3.2.1. 免费账号
🚀 申请免费账号。
第一步:打开github地址:
https://github.com/chatanywhere/GPT_API_free
第二步:点击申请免费账号:
转发地址:https://api.chatanywhere.tech/v1
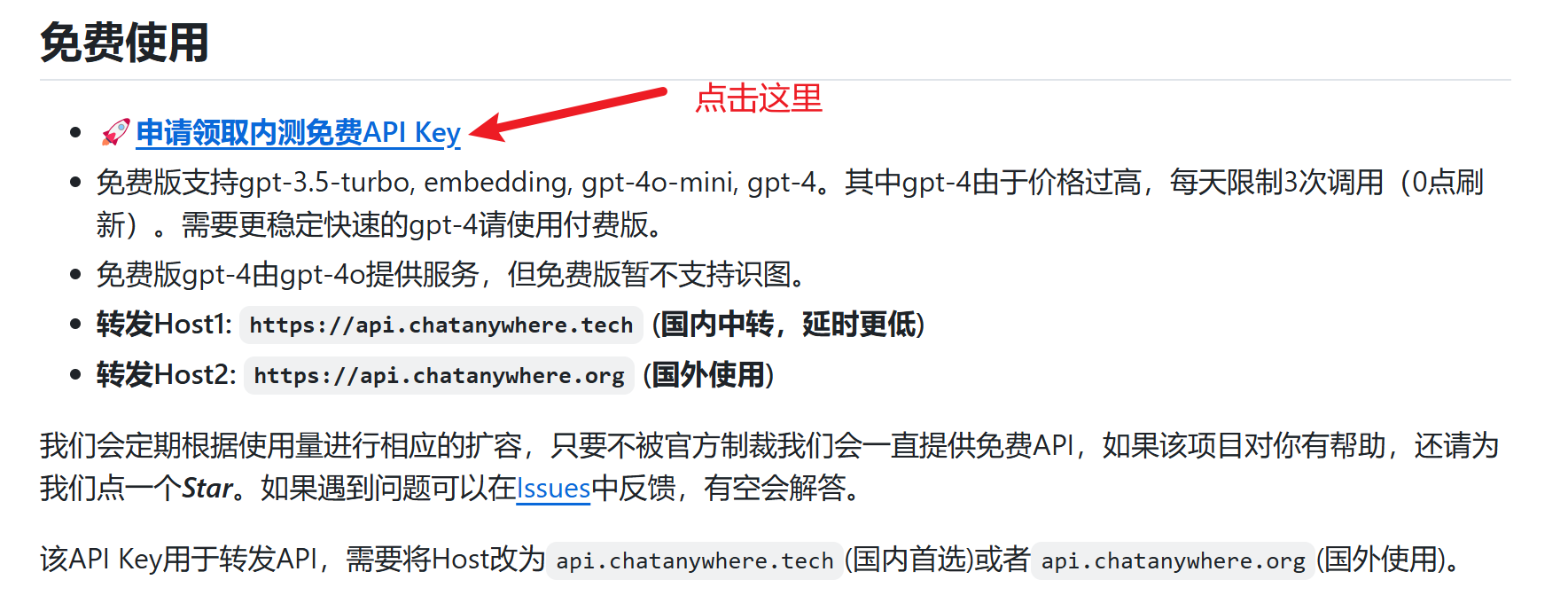
第三步 :输入github账号,就可以看到自己的免费账号了。

2.3.2.2. Message分类
📚 在大模型中,message(消息)通常被分为四类,分别是:
- system(系统消息):设定对话背景或模型角色(如"翻译助手")。
- user(用户消息):用户输入的问题或指令,触发模型回应。
- assistant(助手回复):AI根据用户的输入生成的回答
- tool(工具调用):使AI能够与外部服务连接,执行如查询天气、预订座位等功能,扩展其服务能力。
2.4. 如何在idea中使用
🚀 创建maven项目,该项目需要有两个前置环境条件:
- jdk的版本要求是17
- Kotlin版本要2.1.0以上,建议将idea升级到2024版本以上
可以在pom.xml文件中看到引入了openai-java依赖:
xml
<dependency>
<groupId>com.openai</groupId>
<artifactId>openai-java</artifactId>
<version>0.34.1</version>
</dependency>2.4.1. 普通聊天
java
import com.openai.client.OpenAIClient;
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.models.ChatModel;
import com.openai.models.chat.completions.ChatCompletionCreateParams;
public class CompletionsDemo {
public static void main(String[] args) {
// 创建客户端,指定 API Key 与 baseUrl,其中API KEY从系统环境变量中获取
OpenAIClient client = OpenAIOkHttpClient.builder()
.baseUrl("https://api.chatanywhere.tech/v1")
.apiKey(System.getenv("OPENAI_API_KEY"))
.build();
// 构造聊天参数
ChatCompletionCreateParams createParams = ChatCompletionCreateParams.builder()
.model(ChatModel.GPT_3_5_TURBO) // 指定模型
.addSystemMessage("你是一位Java程序员助理,具备扎实的Java编程基础和良好的代码理解能力。") // 添加系统消息
.addUserMessage("你是谁?") // 添加用户消息
.build();
// 调用接口,获取结果并打印
client.chat().completions()
.create(createParams)
.choices()
.stream()
.flatMap(choice -> choice.message().content().stream())
.forEach(System.out::println);
}
}2.4.2. 流式聊天
一般大模型生成的内容会比较多,所以会采用流式输出的方式,类似打字机的效果。
java
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.models.ChatModel;
import com.openai.models.chat.completions.ChatCompletionCreateParams;
public class CompletionsStreamingDemo {
public static void main(String[] args) {
// 创建异步通信客户端,指定 API Key 与 baseUrl,其中API KEY从系统环境变量中获取
var client = OpenAIOkHttpClient.builder()
.baseUrl("https://api.chatanywhere.tech/v1")
.apiKey(System.getenv("OPENAI_API_KEY"))
.build();
// 构造聊天参数
var createParams = ChatCompletionCreateParams.builder()
.model(ChatModel.GPT_3_5_TURBO) // 指定模型
.addSystemMessage("你是一位Java程序员助理,具备扎实的Java编程基础和良好的代码理解能力。") // 添加系统消息
.addUserMessage("帮我写一个java的入门案例,有详细的描述") // 添加用户消息
.build();
// 调用聊天接口,获取流式响应
try (var response = client.chat().completions().createStreaming(createParams)) {
// 获取流式响应的数据流
response.stream()
// 将每个 ChatCompletionChunk 的 choices() 转换为流进行处理
.flatMap(chatCompletionChunk -> chatCompletionChunk.choices().stream())
// 提取每个选择对象中的增量内容流(delta.content)
.flatMap(choice -> choice.delta().content().stream())
// 实时打印流式返回的文本内容
.forEach(System.out::println);
}
}
}2.4.3. 多轮对话
java
import com.openai.client.OpenAIClient;
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.models.ChatModel;
import com.openai.models.chat.completions.ChatCompletionCreateParams;
public class CompletionsMultipleRoundsDemo {
private static OpenAIClient client;
public static void main(String[] args) {
// 创建客户端,指定 API Key 与 baseUrl,其中API KEY从系统环境变量中获取
client = OpenAIOkHttpClient.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(System.getenv("ALIYUN_API_KEY"))
.build();
// 第一次对话
chat("我叫花和尚,请记住我");
System.out.println("------------------------");
// 第二次对话
chat("我是谁?");
}
public static void chat(String userMessage) {
// 构造聊天参数
var createParams = ChatCompletionCreateParams.builder()
.model("qwen-plus") // 指定模型
.addUserMessage(userMessage) // 添加用户消息
.build();
// 调用接口,获取结果并打印
client.chat().completions()
.create(createParams)
.choices()
.stream()
.flatMap(choice -> choice.message().content().stream())
.forEach(System.out::println);
}
}运行后发现大模型没有记住!!!
📚这是为什么呢?大模型怎么没有记住呢?
其实,这是因为大模型在聊天时是"健忘"的,它不会自动记住之前的对话(也就是聊天无状态的)。如果你想让它记得你之前说了什么,就得每次都把前面的聊天内容告诉它。不然的话,它就不知道上下文,就像每次都是第一次和你聊天一样。
下面改造代码:(⚡该示例使用阿里云百炼的大模型服务)
java
import com.openai.client.OpenAIClient;
import com.openai.client.okhttp.OpenAIOkHttpClient;
import com.openai.models.chat.completions.ChatCompletionAssistantMessageParam;
import com.openai.models.chat.completions.ChatCompletionCreateParams;
import com.openai.models.chat.completions.ChatCompletionMessageParam;
import com.openai.models.chat.completions.ChatCompletionUserMessageParam;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
/**
* 多轮对话示例代码
*/
public class CompletionsMultipleRoundsDemo {
private static OpenAIClient client;
public static void main(String[] args) {
// 创建客户端,指定 API Key 与 baseUrl,其中API KEY从系统环境变量中获取
client = OpenAIOkHttpClient.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(System.getenv("ALIYUN_API_KEY"))
.build();
// 创建消息集合,用于存储对话历史记录
var messageParamList = new ArrayList<ChatCompletionMessageParam>();
// 第一次对话
chat("我叫花和尚,请记住我", messageParamList);
System.out.println("------------------------");
// 第二次对话
chat("我是谁?", messageParamList);
}
public static void chat(String userMessage, List<ChatCompletionMessageParam> messageParamList) {
// 手动构建 user 消息对象,并且放到消息集合中
messageParamList.add(ChatCompletionMessageParam.ofUser(ChatCompletionUserMessageParam.builder()
.content(userMessage)
.build()));
// 构造聊天参数
var createParams = ChatCompletionCreateParams.builder()
.model("qwen-plus") // 指定模型
.messages(messageParamList) // 指定消息集合
.build();
// 调用接口,获取结果并打印
client.chat().completions()
.create(createParams)
.choices()
.stream()
.flatMap(choice -> {
// 获取 assistant 消息
Optional<String> contentOptional = choice.message().content();
// 如果有 assistant 消息,则手动构建 assistant 消息对象,并且放到消息集合中
if (contentOptional.isPresent()) {
// 手动构建 assistant 消息对象,并且放到消息集合中
ChatCompletionAssistantMessageParam assistantMessageParam = ChatCompletionAssistantMessageParam.builder()
.content(contentOptional.get())
.build();
messageParamList.add(ChatCompletionMessageParam.ofAssistant(assistantMessageParam));
}
// 返回 assistant 消息流
return contentOptional.stream();
})
// 打印结果
.forEach(System.out::println);
}
}所以,实现多轮对话的核心就是要把前面的聊天内容,都发给大模型,否则他不知道聊天的上下文。
📚 优秀的prompt分享: