前言:为什么要学 ELF?
我们在 Linux 下写 C/C++,编译出来的 .o、.so、.a、可执行程序,全都是 ELF 文件。
- 编译报错?链接报错?运行找不到库?
- 想理解静态库 / 动态库原理?程序怎么被加载进内存?
- 想做逆向、调试、性能优化?
一、ELF文件
1.1 知识补充:.a , .so , .o
静态库(.a)
- 编译链接时 :把库代码直接拷贝进可执行文件
- 运行时 :不再依赖静态库
- 优点:程序独立,不挑环境
- 缺点:可执行文件大,多个程序不能共享同一份库代码
动态库(.so)
- 编译时 :只记录函数入口,不拷贝代码
- 运行时 :系统加载库到内存,多个程序共享同一份
- 优点:省磁盘、省内存,库更新不用重新编译程序
- 缺点:运行需要依赖库存在,否则报错
目标文件 (.o )
我们写
.c→ 编译 → 生成.o(目标文件)。本质 :ELF 格式的可重定位文件,包含:
- 编译好的机器指令
- 符号表(函数名、变量名)
- 重定位信息(告诉链接器哪里地址需要修改)
- 未解决的外部符号(比如调用 printf、其他文件函数)
一句话:.o 是半成品,还不能直接运行,必须经过链接。
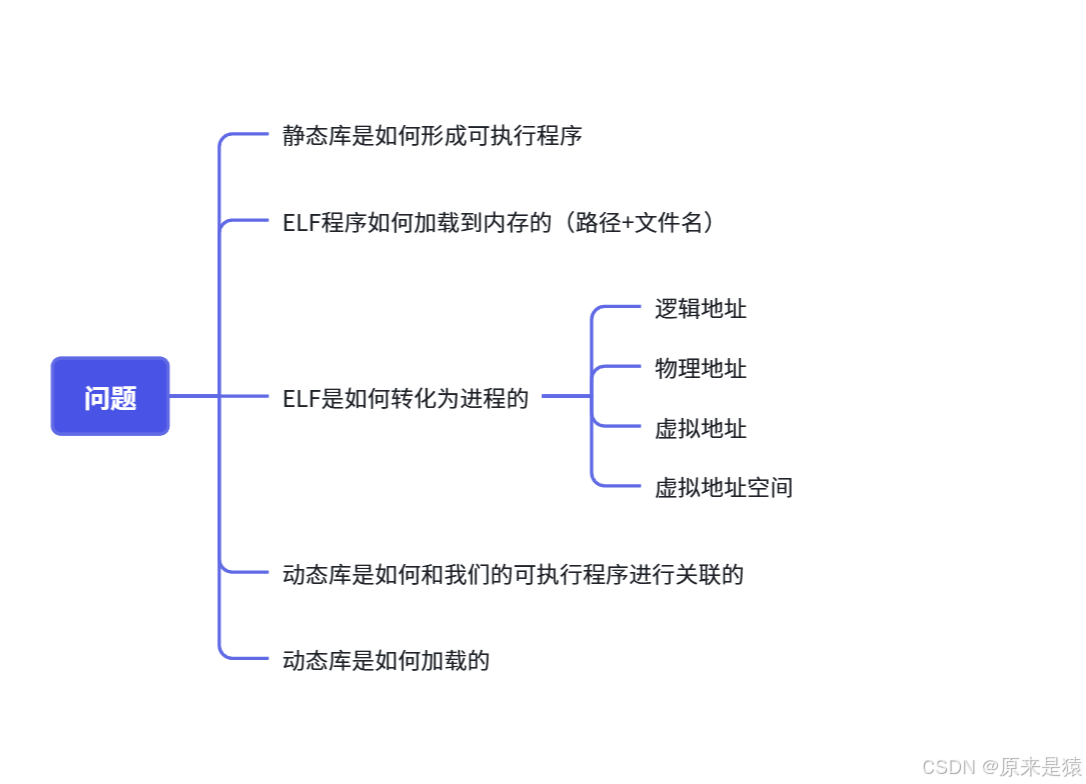
1.2 ELF文件
**ELF = Executable and Linkable Format,Linux 标准二进制格式。**它有以下四种类型:
可重定位文件(.o):包含代码和数据,可与其他目标文件链接成可执行文件或共享库。
可执行文件(a.out):可以直接运行的进程映像。
共享目标文件(.so):动态库。
核心转储文件(core dump):进程崩溃时的内存映像。
一个可执行程序是由代码和数据组成的,但是不能这么简浅的去认识,因为代码和数据是结构化的。
一个ELF文件由以下部分组成:
-
ELF头(ELF header) :位于文件开头,描述文件类型、机器架构、入口点地址、程序头表和节头表的位置和大小等。
-
程序头表(Program header table) :告诉系统如何创建进程映像,即可执行文件加载到内存时的段(segment)信息。
-
节头表(Section header table) :描述文件中各个节(section)的信息,用于链接和调试。
-
节(Sections) :存放具体内容,如代码、数据、符号表等。
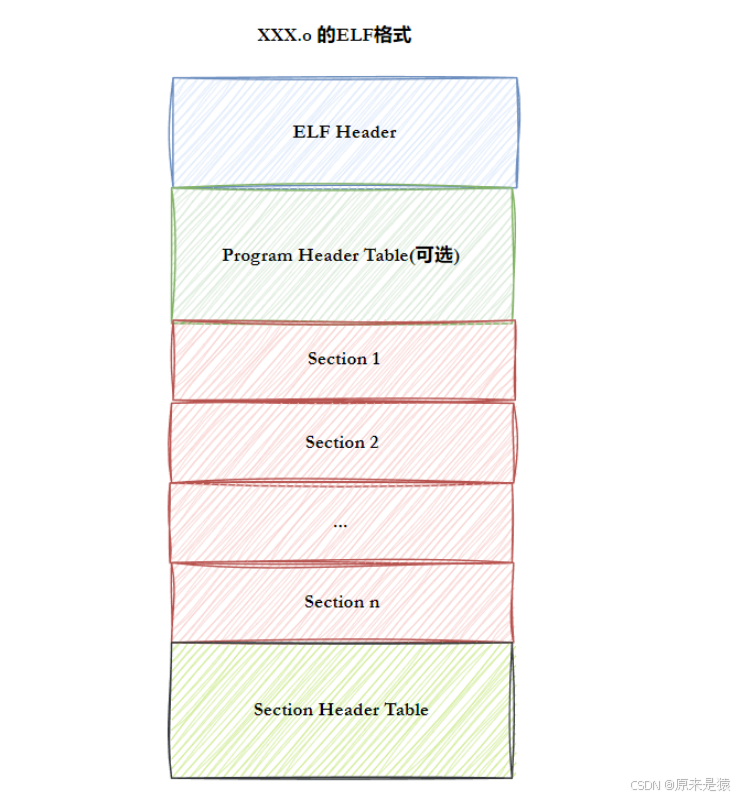
常用节:
-
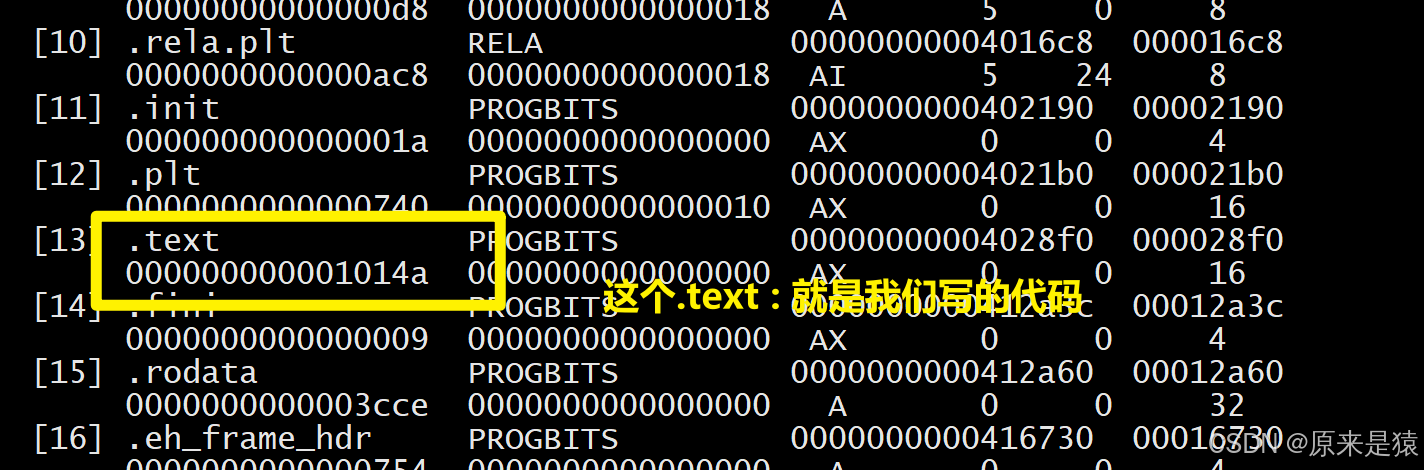
.text:代码段,存放机器指令。 -
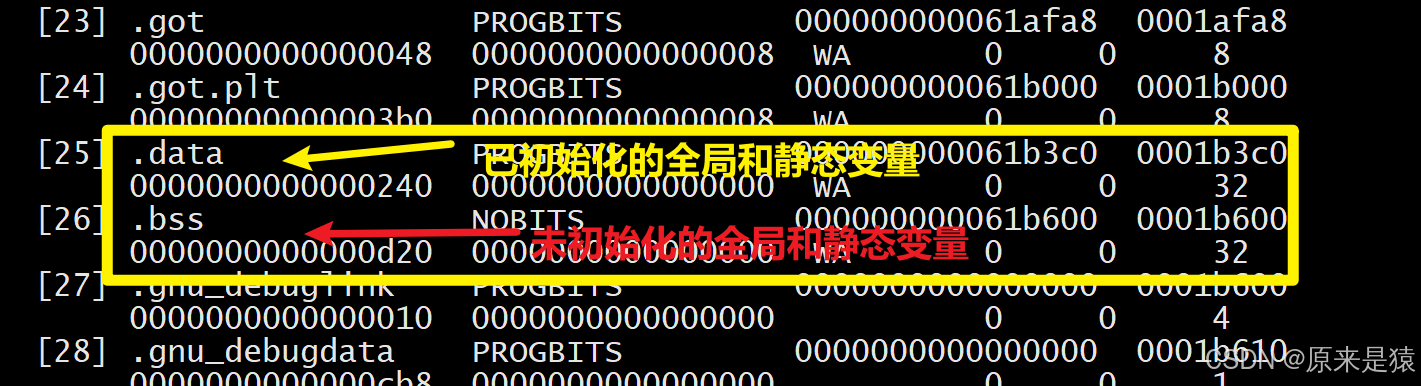
.data:已初始化的全局变量和静态变量。 -
.bss:未初始化的全局变量和静态变量(不占文件空间,加载时清零)(只占位,不占文件空间)。
bbs(better save space)
存未初始化 的全局 / 静态变量(比如
int b;)这类变量默认值是 0 ,编译器不需要在文件里存一堆
0,只需要 记录 "需要多大内存、放哪里" 就行。它****只描述内存布局,不存储实际数据。
-
.rodata:只读数据,如字符串常量。 -
.symtab:符号表,记录函数名、变量名等。 -
.strtab:字符串表,存储符号名。 -
.got:全局偏移表(用于动态链接)。 -
.plt:过程链接表(用于动态链接)。
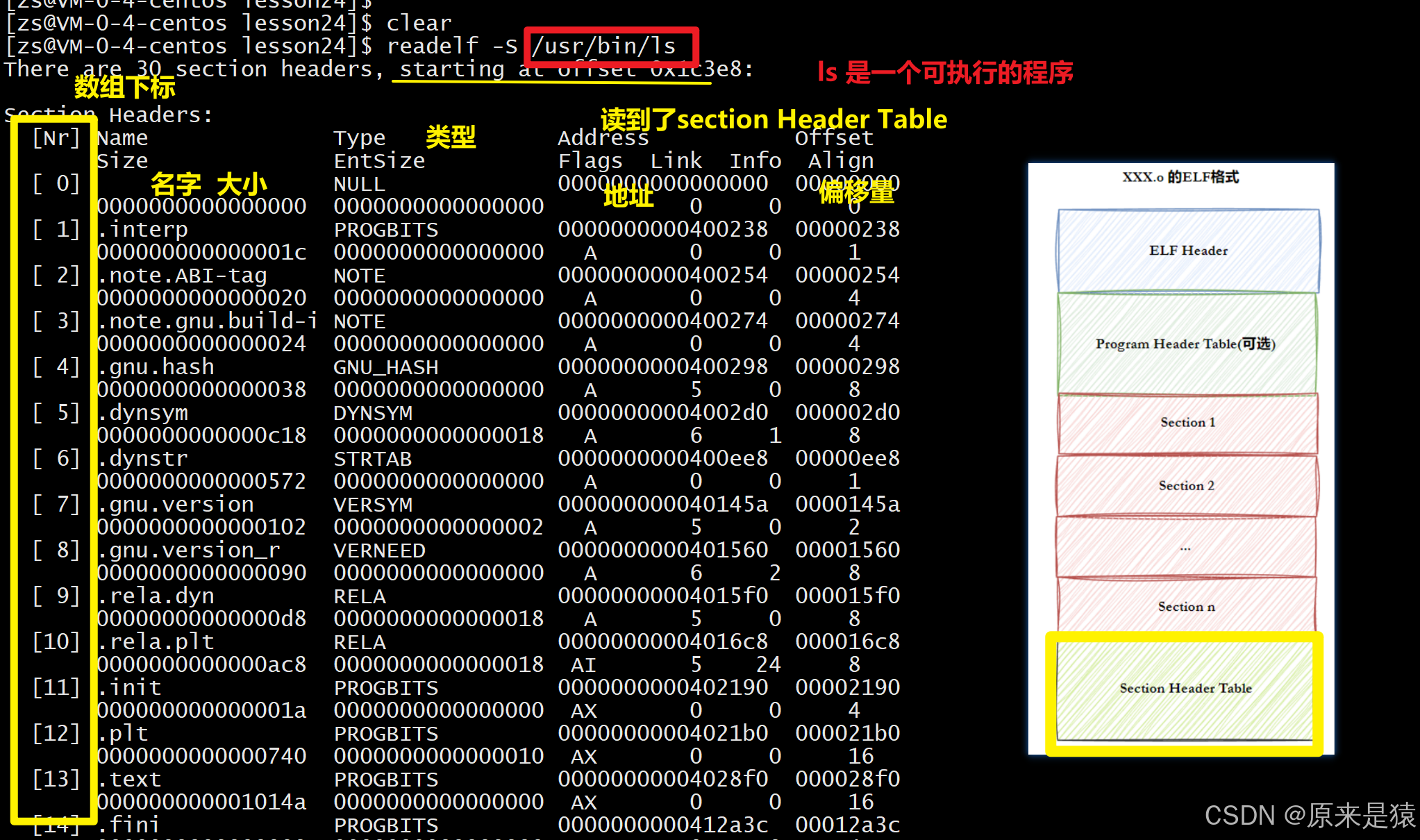
1.3 查看ELF信息
查看ELF头
readelf -h 文件名
- 告诉操作系统哪些模块可以被加载进内存
- 加载进内存之后 , 哪些是分段可读可写 , 那些是分段只读 , 哪些分段是可执行
位置:文件最前面作用:描述整个文件,告诉系统这是什么文件、入口在哪、头表在哪。
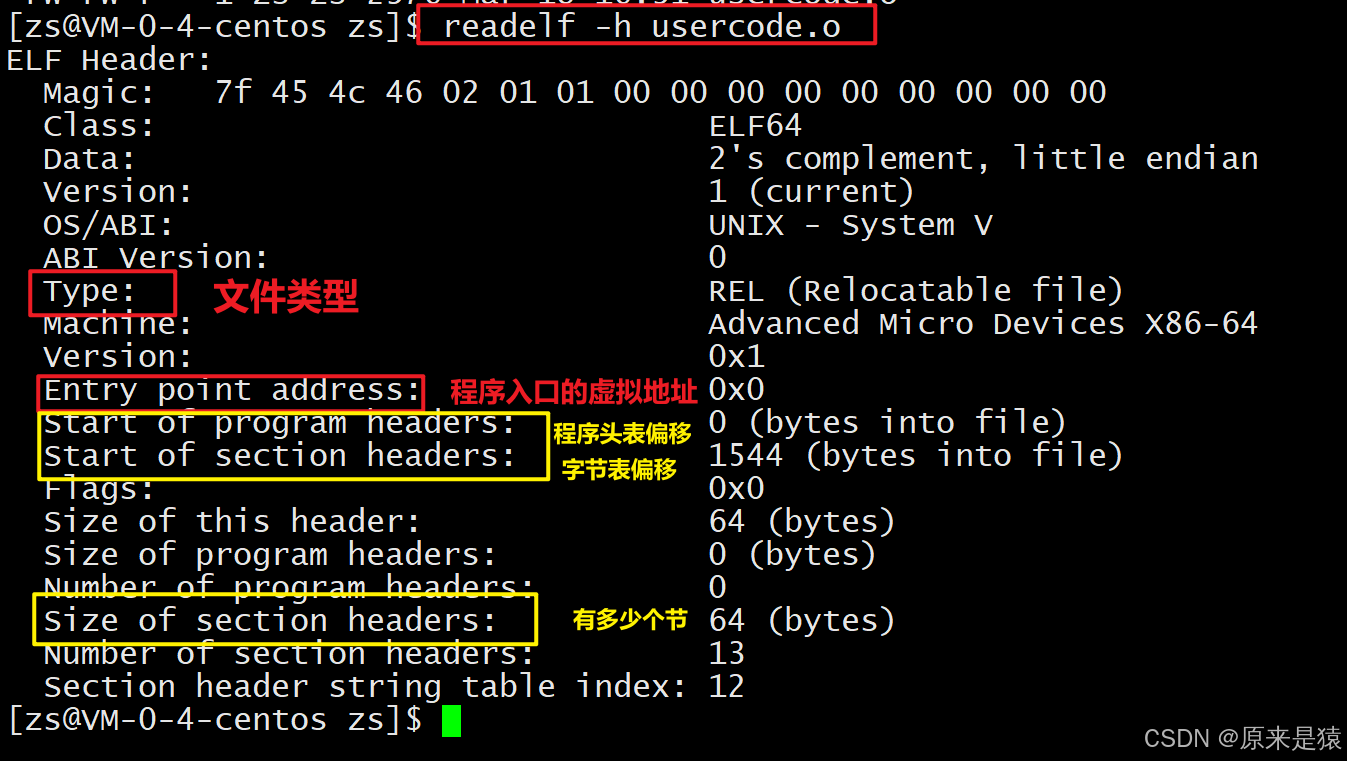
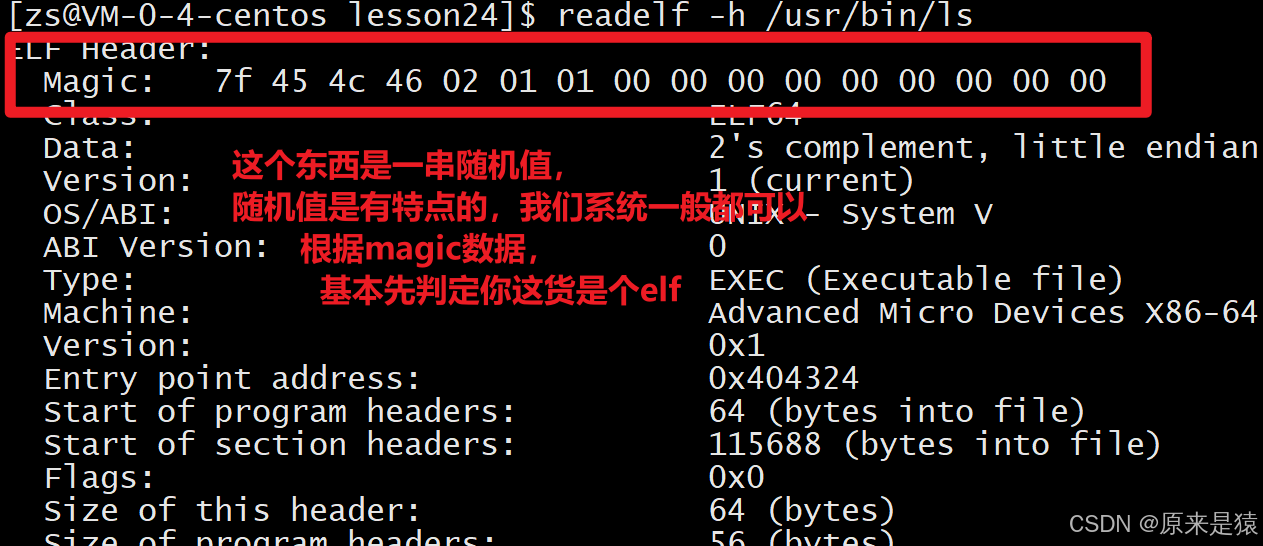
- Type:文件类型(REL 可重定位 / EXEC 可执行 / DYN 动态库)
- Entry point address:程序入口虚拟地址
- Start of program headers:程序头表偏移
- Start of section headers:节头表偏移
- Number of section headers:有多少个节
可重定位文件的程序头表大小为0,因为它不需要加载到内存执行。
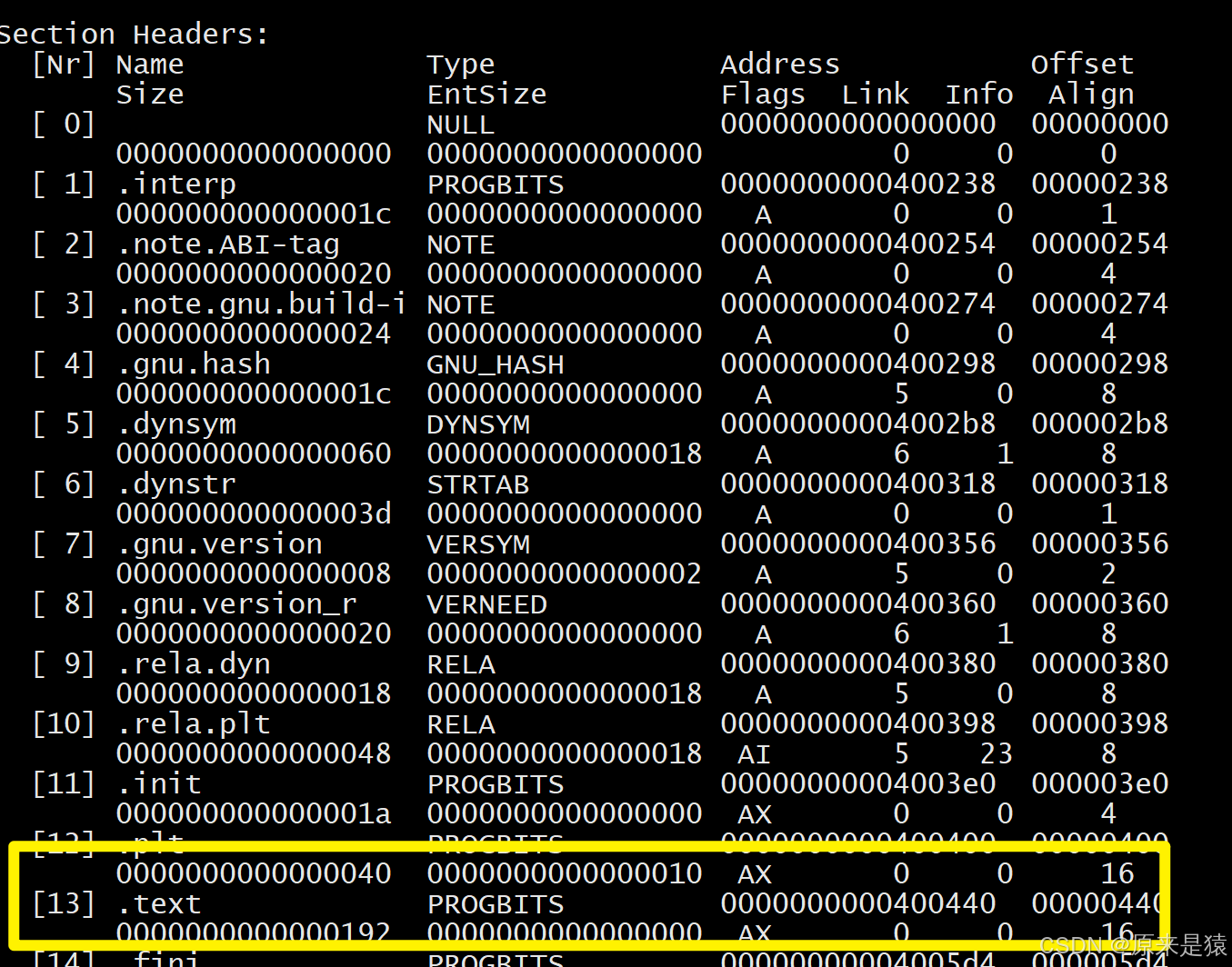
查看节头表
readelf -S 文件名
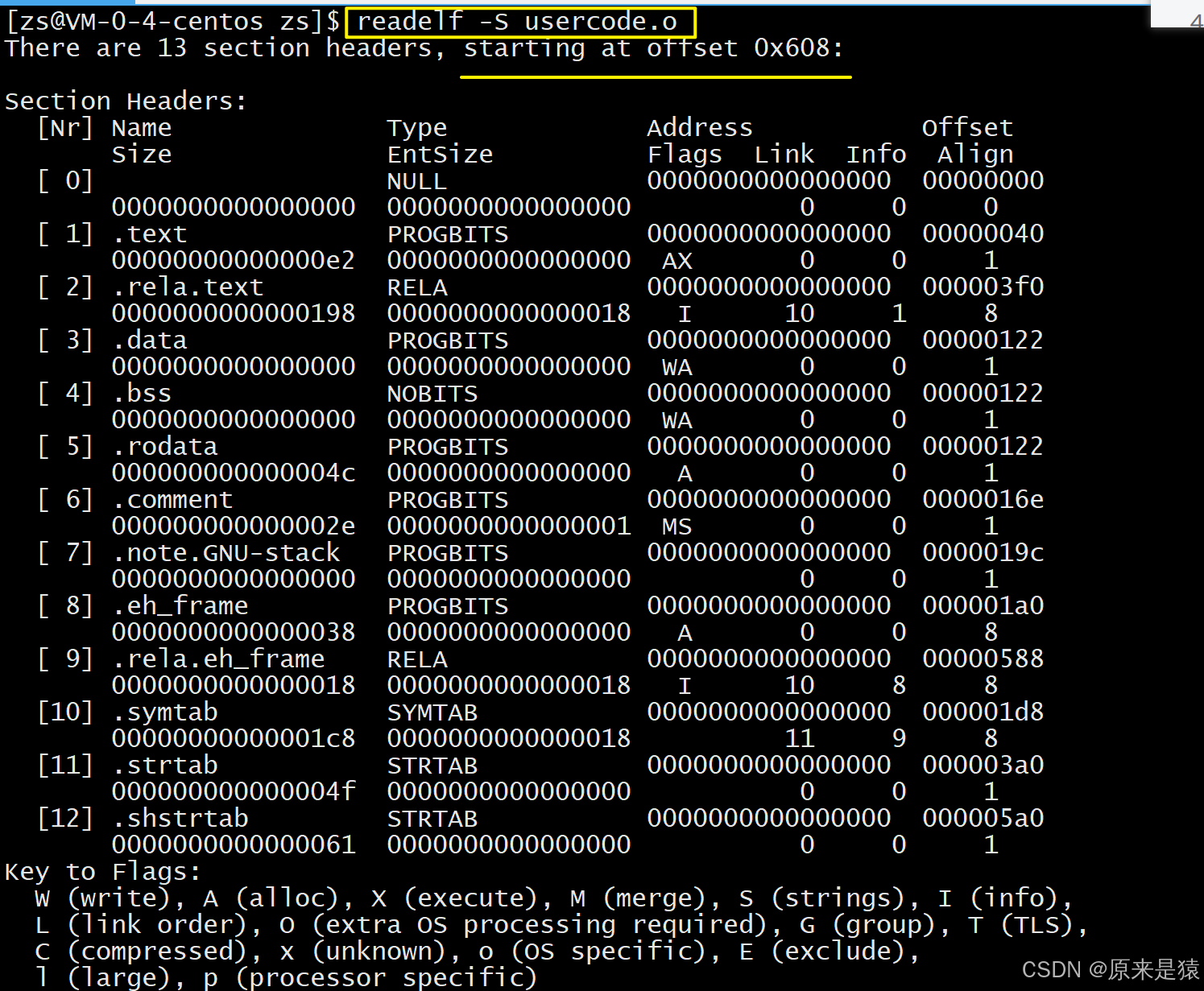
-
Address:节的加载地址(可重定位文件中为0,链接时再分配)。 -
Offset:节在文件中的偏移。 -
Size:节的大小。 -
Flags:A(alloc,加载时分配内存),X(可执行),W(可写)等。 -
String Table :
char lable[] = "helloworld\0func\0libc\0a\0obj\o";就是字符串表的简化版。字符串表是一块连续的内存,用\0分隔不同的字符串(比如函数名、变量名、节名),符号表只存字符串在这块内存里的偏移量,这样能节省空间。
划分 section 的本质:通过节头表中每个表项的 Offset 和 Size 字段,确定该 section 在 ELF 文件中的字节范围,再结合节名和类型进行功能分类。偏移量 + size
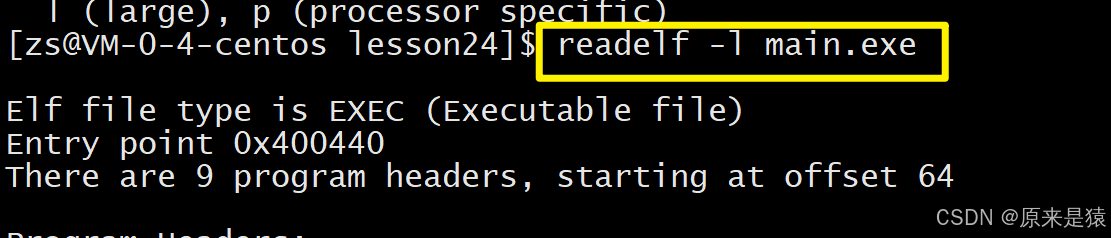
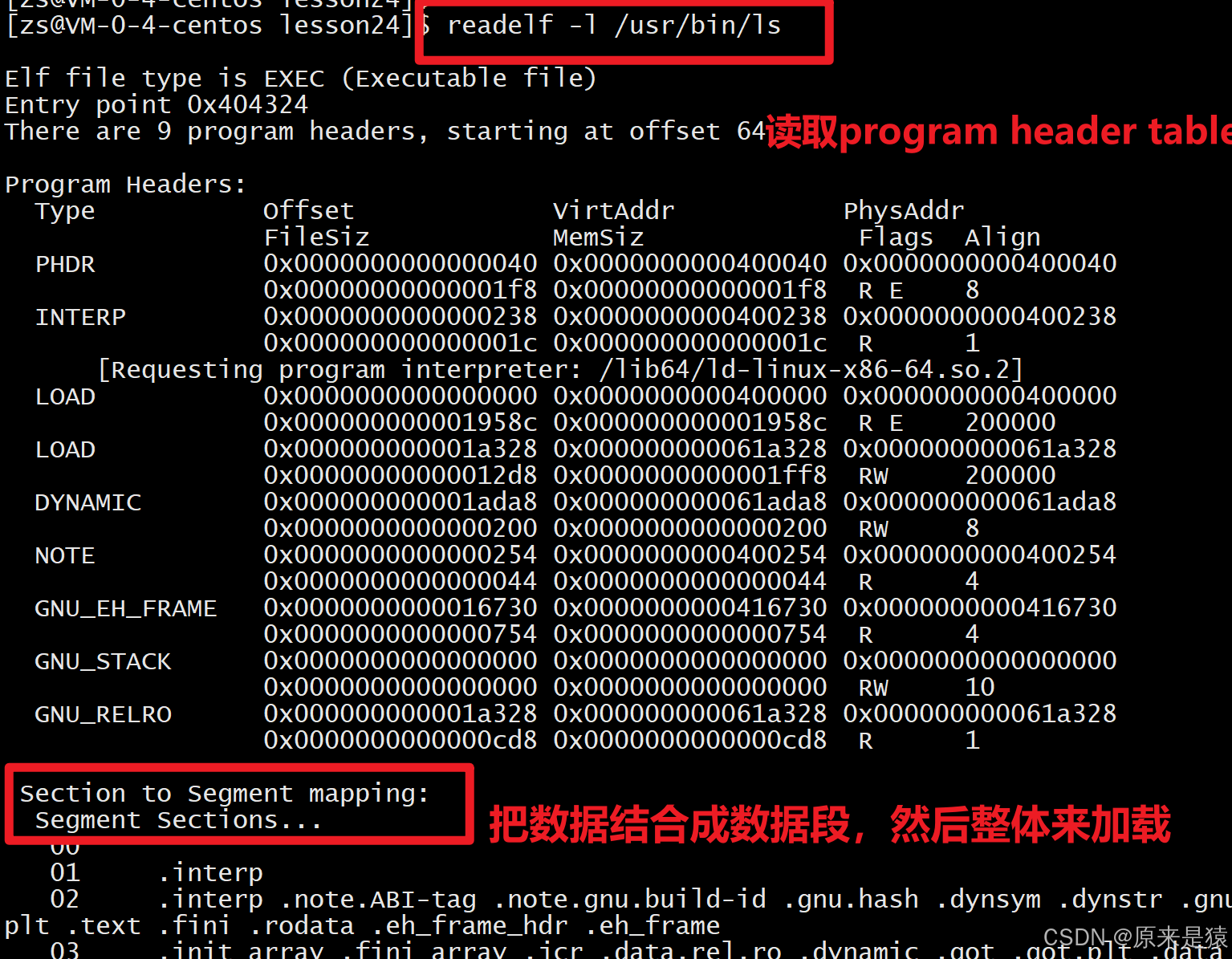
查看程序头表(可执行文件)
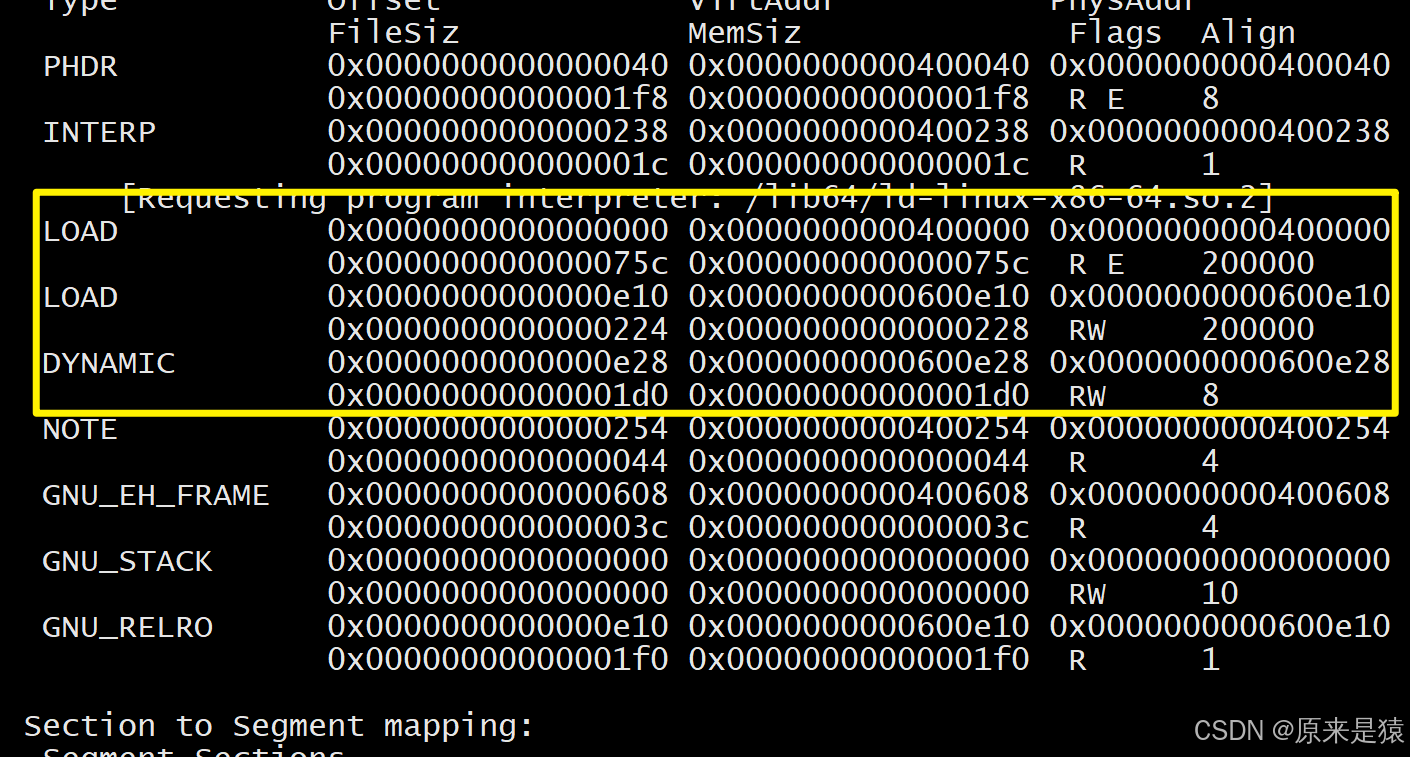
readelf -l 文件名
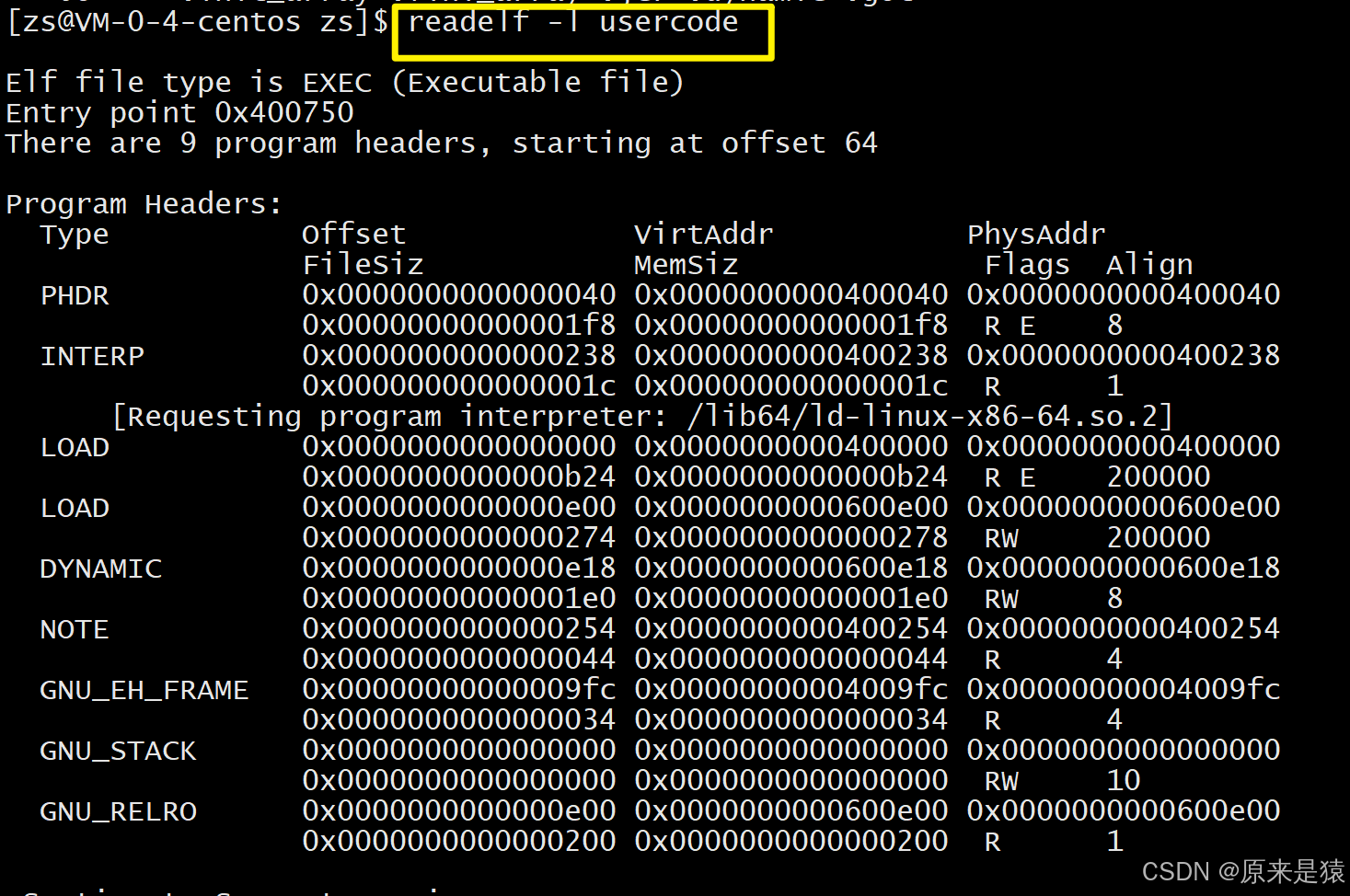

- LOAD :**需要加载到内存的部分,**第一个LOAD段(R E)是代码段,第二个LOAD段(RW)是数据段。
- Flags:权限 R (读) W (写) X (执行)
- VirtAddr:虚拟地址
- Offset:文件内偏移
-
DYNAMIC段:包含动态链接信息。 -
INTERP段:指定动态链接器的路径。
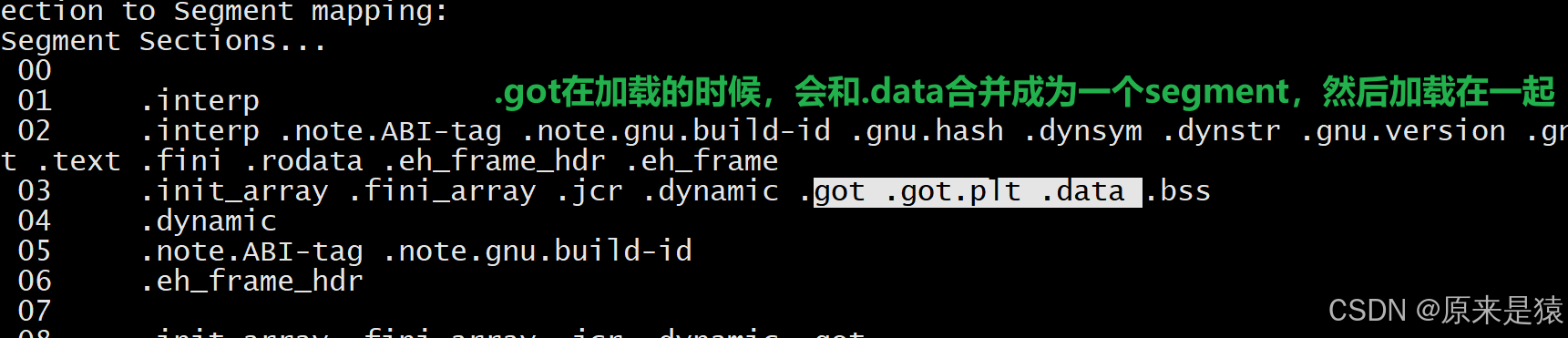
节与段的映射 :链接器会将多个属性相似的节合并成一个段,比如**
.text、.init等可读可执行的节合并到代码段** ,.data、.bss、.got等可读可写的节合并到数据段。这样减少了内存页面的碎片,提高了内存利用率。
二、ELF从形成到加载轮廓
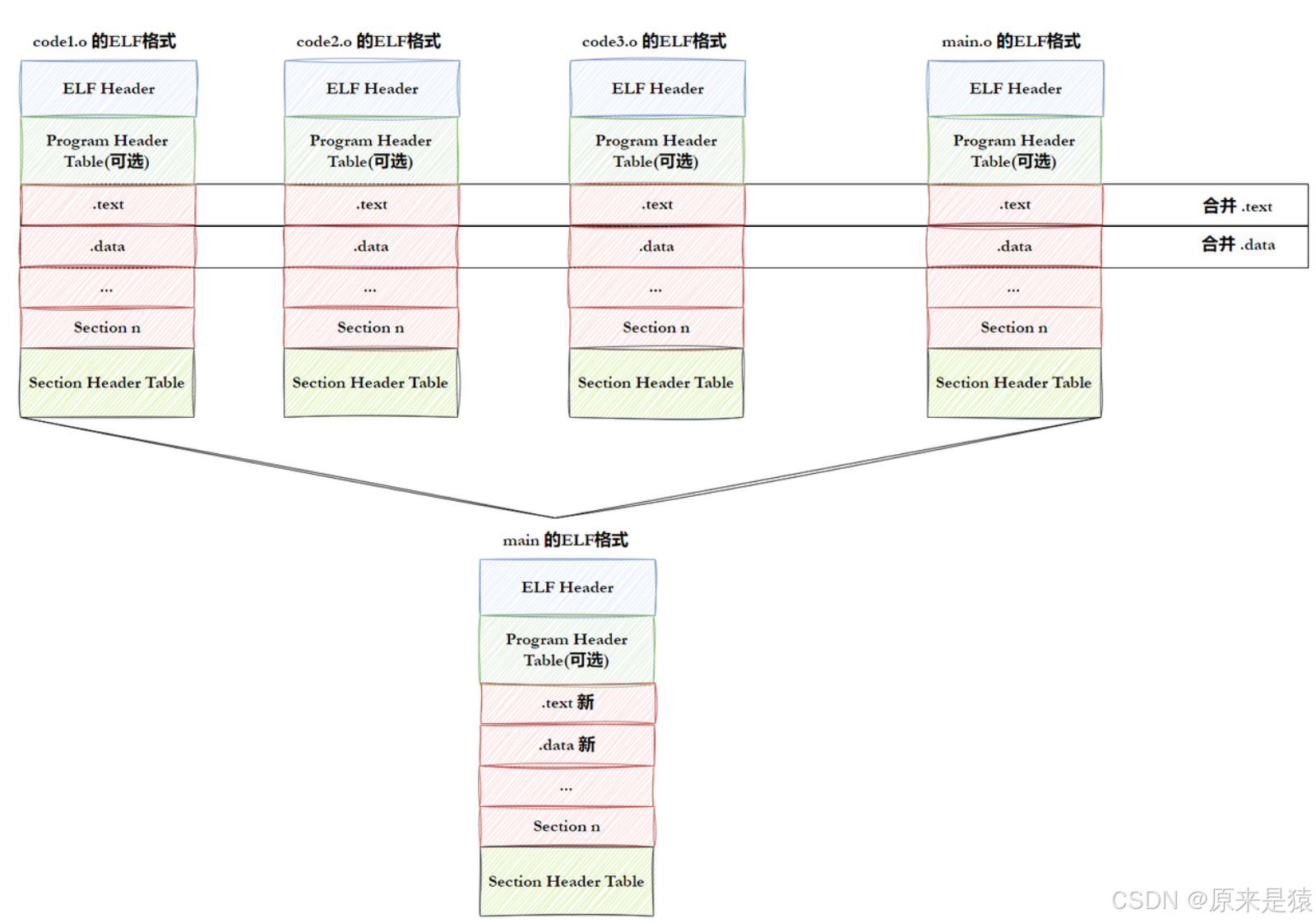
2.1 ELF形成可执行
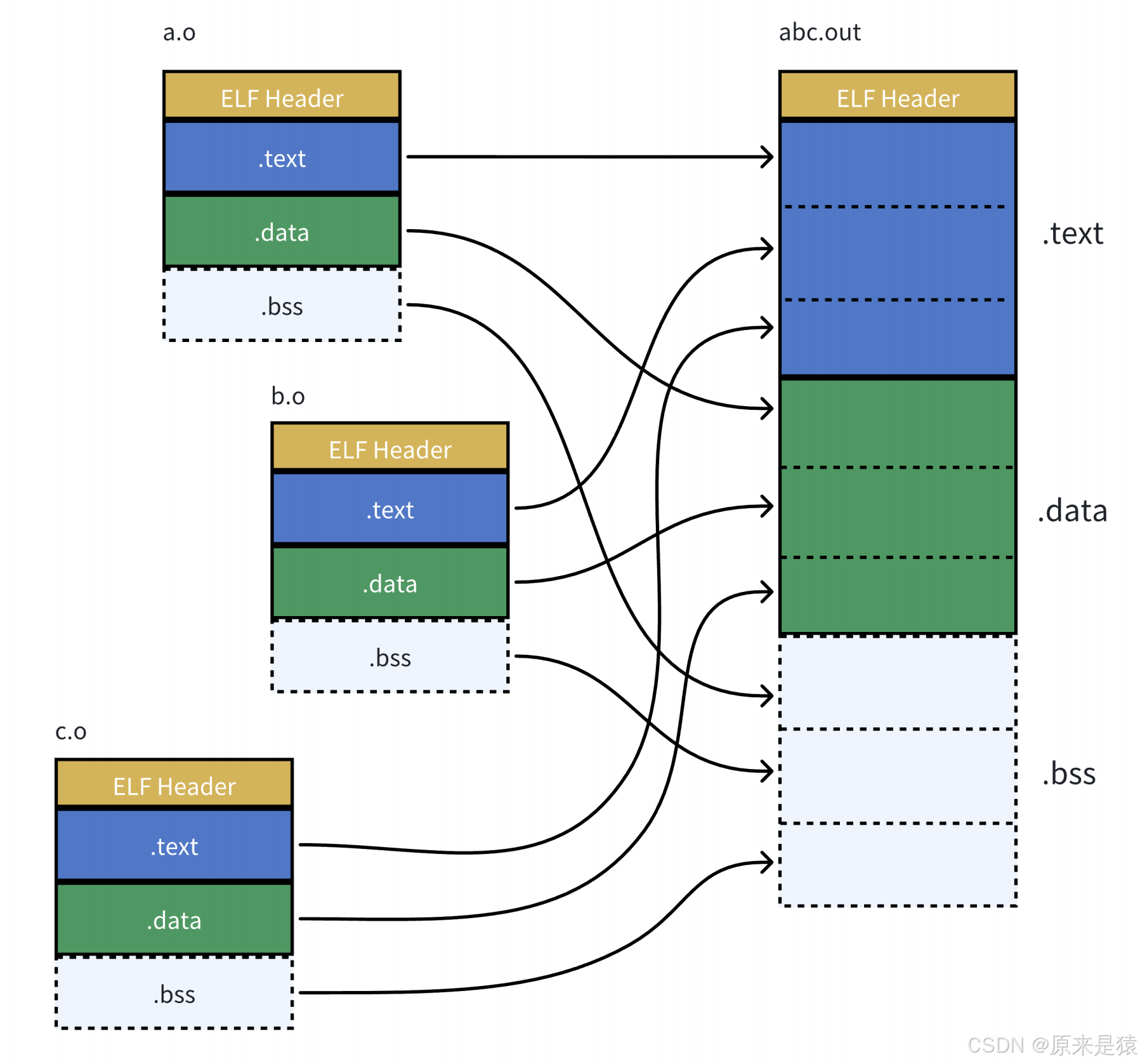
- step-1 : 将多份 C/C++ 源代码 , 翻译成为目标 .o 文件
- step-2 :将多份 .o 文件section 进行合并

2.2 ELF可执行文件加载
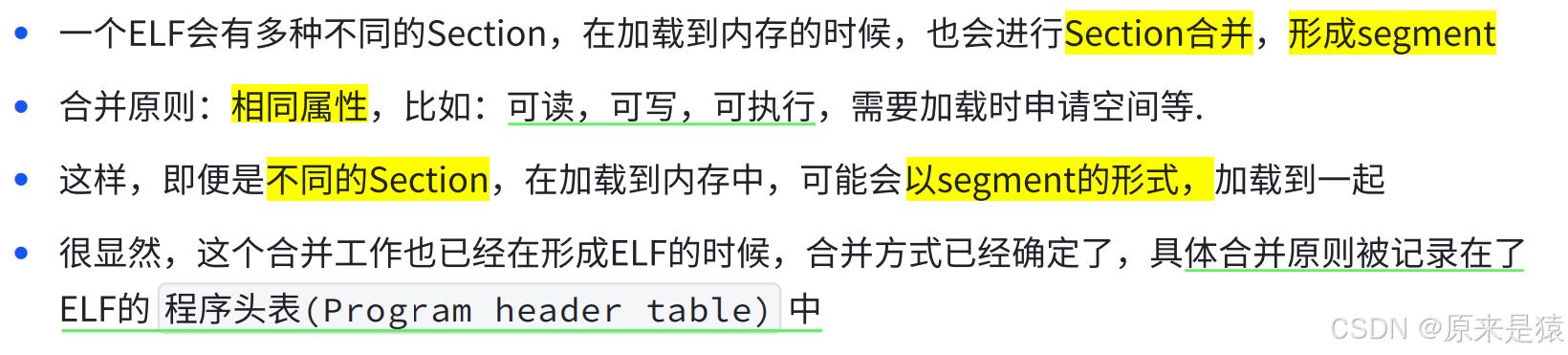
- 查找可执行程序的section

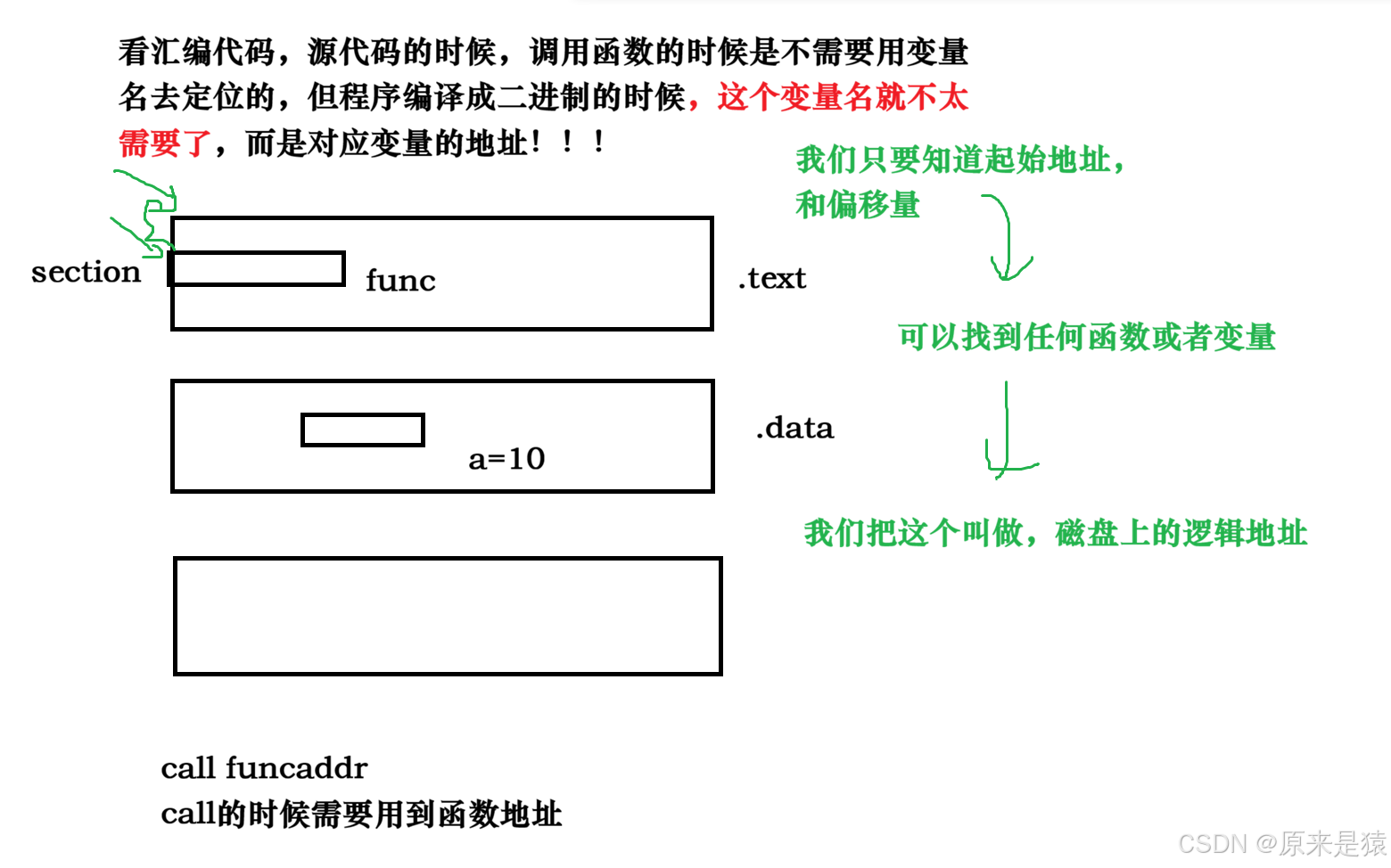
我的section 相较于整个文件的开头 , 知道我的偏移量 , 知道我的长度,那么此时我们就能在文件部分用起始的文件偏移量加上我们的section 的长度 , 就能把section 表示出来!!!
- 全局变量需要在加载的时候确定好!
2 . 变量宏观上分两种 , 全局 和 局部 !
局部的临时变量 , 是程序在运行期间产生的!在栈上或者堆上等开辟
未初始化的全局变量默认为 0
- 查看section合并的segment

Section(节)
- 链接器用
- 按功能划分:代码、数据、只读数据...
- 粒度细
Segment(段)
- 操作系统加载用
- 按权限 / 属性合并 Section
- 目的:减少内存页碎片,优化加载
例如:
.text+.rodata+.init→ 合并成 只读可执行段.data+.got+.bss→ 合并成 可读可写段链接看 Section,运行看 Segment。

-
进行IO的基本单位是4KB ; **OS把内存也看成一个大数组,而内存大数组每一个元素空间就是4KB。**所以说,磁盘文件4KB的内存,就可以放在内存划分好的4KB的空间里 , 它们交互的时候,是以4KB为单位进行交互的。
-
之前new , malloc 向系统申请内存的基本单位都是4KB (哪怕你只要一个比特位,一个字节,OS都是直接给你4KB)
-
对于 程序头表 和 节头表 有什么用呢,其实 ELF 文件提供 2 个不同的视图/视角来让我们理解这两个部分:

- 执行视图(execution ciew) - 对应程序头表 Program header table
- 告诉操作系统,如何加载可执行文件,完成进程内存初始化 。 一个可执行程序的格式中,一定有program header table ;
- 说白了 , 一个是在链接时作用 , 一个运行加载时作用。
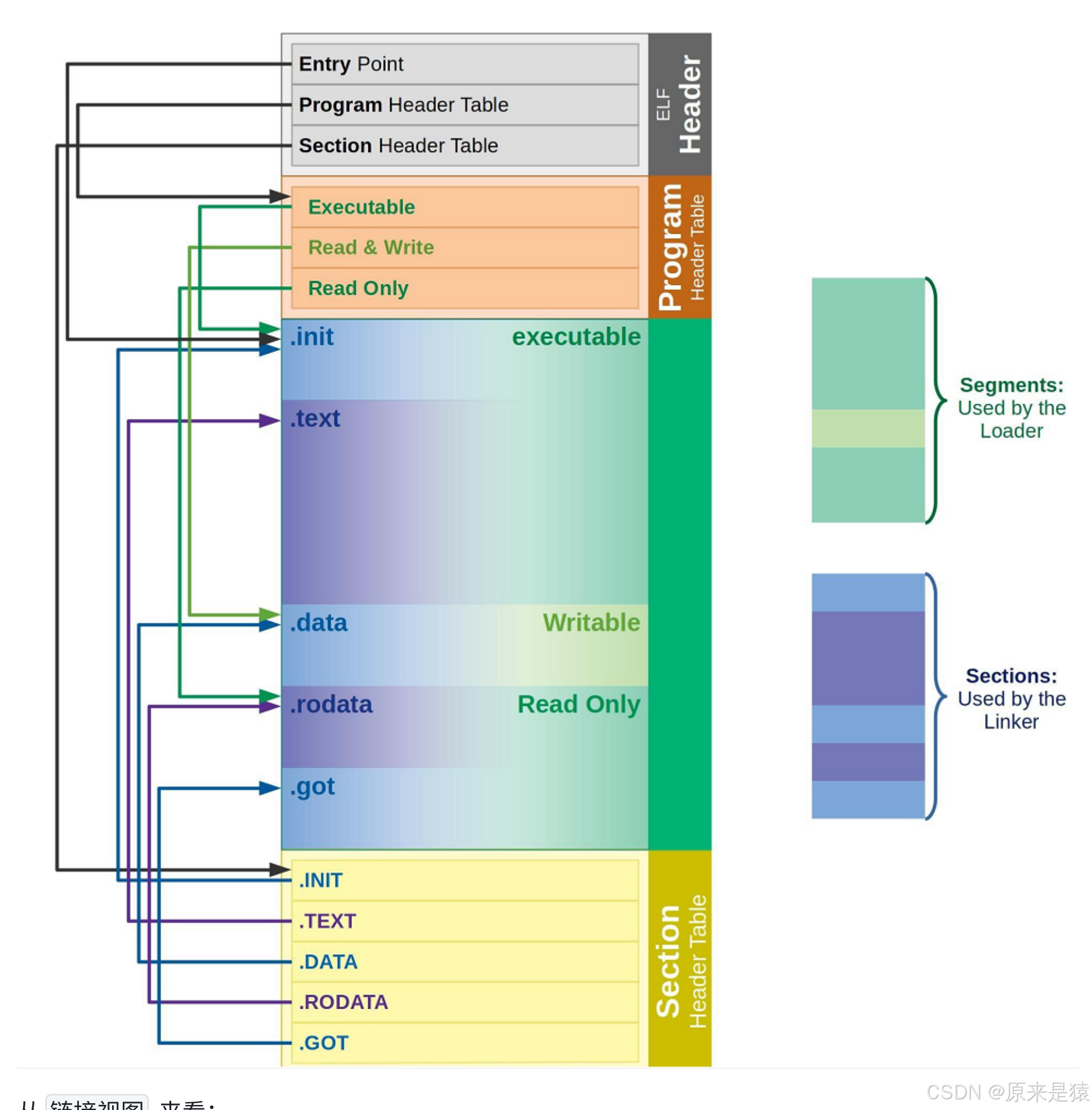
对于ELF HEAED 这部分来说 , 我们只用知道其作用即可 ,他的目的主要是定位文件的其他部分
三、理解连接与加载
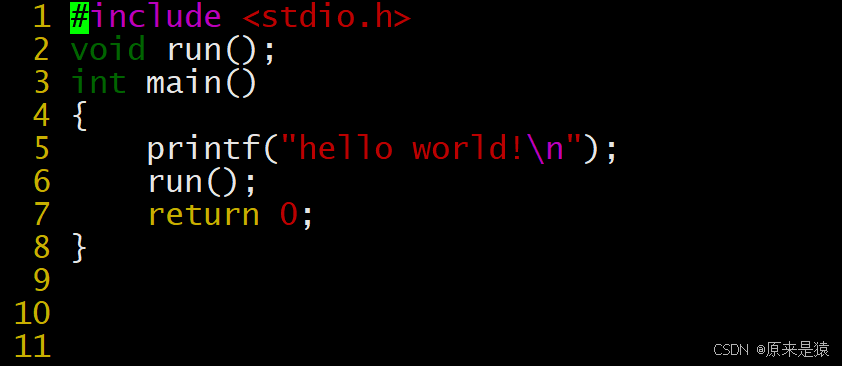
3.1 静态连接
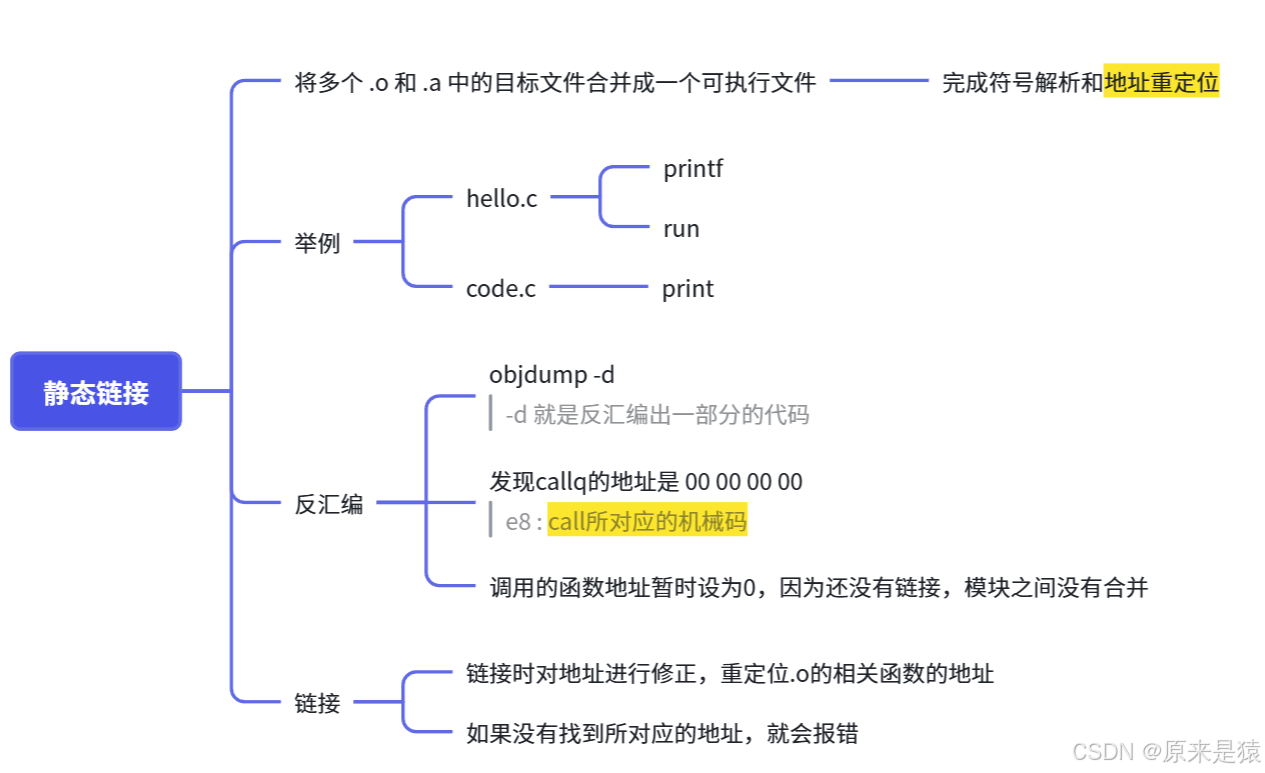
静态链接就是将多个目标文件(.o)和静态库(.a)中的目标文件合并成一个可执行文件 ,并完成符号解析和地址重定位。
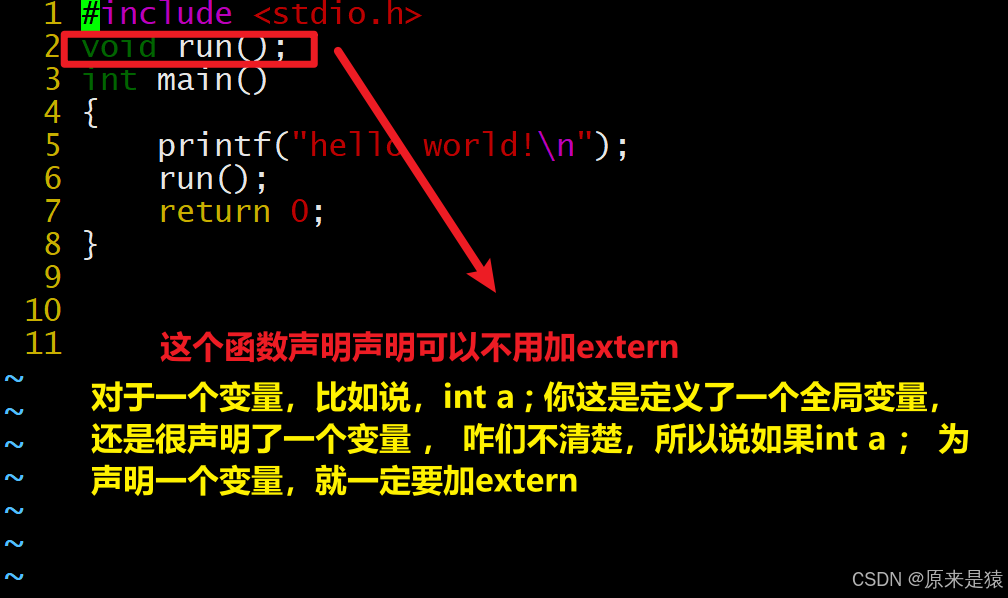
1. 两个源文件 :
hello.c
#include <stdio.h>
void run();
int main() {
printf("hello world!\n");
run();
return 0;
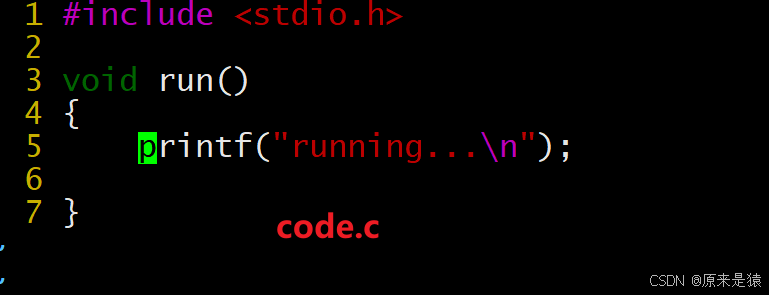
}
code.c
#include <stdio.h>
void run() {
printf("running...\n");
}编译得到目标文件:
$ gcc -c hello.c code.c
$ ls
code.c code.o hello.c hello.o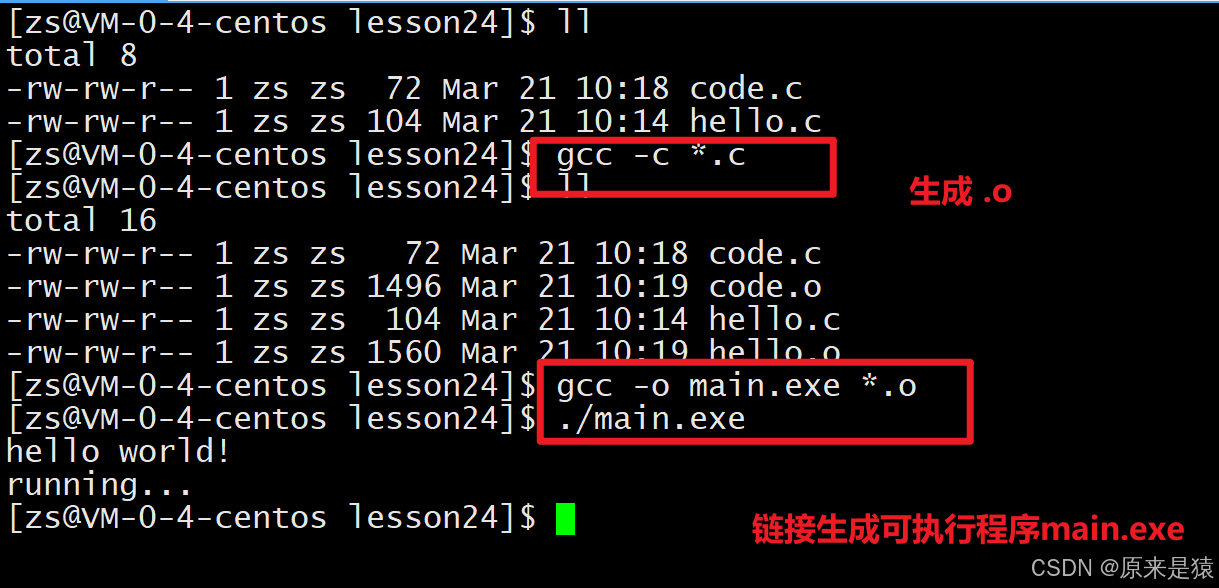
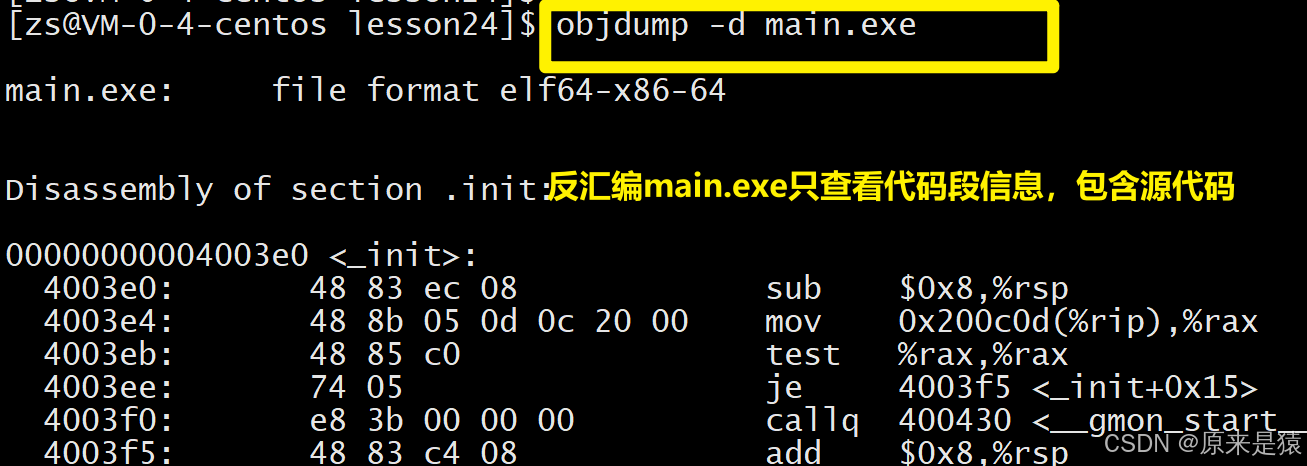
objdump -d xxxx 对可执行程序进行反汇编
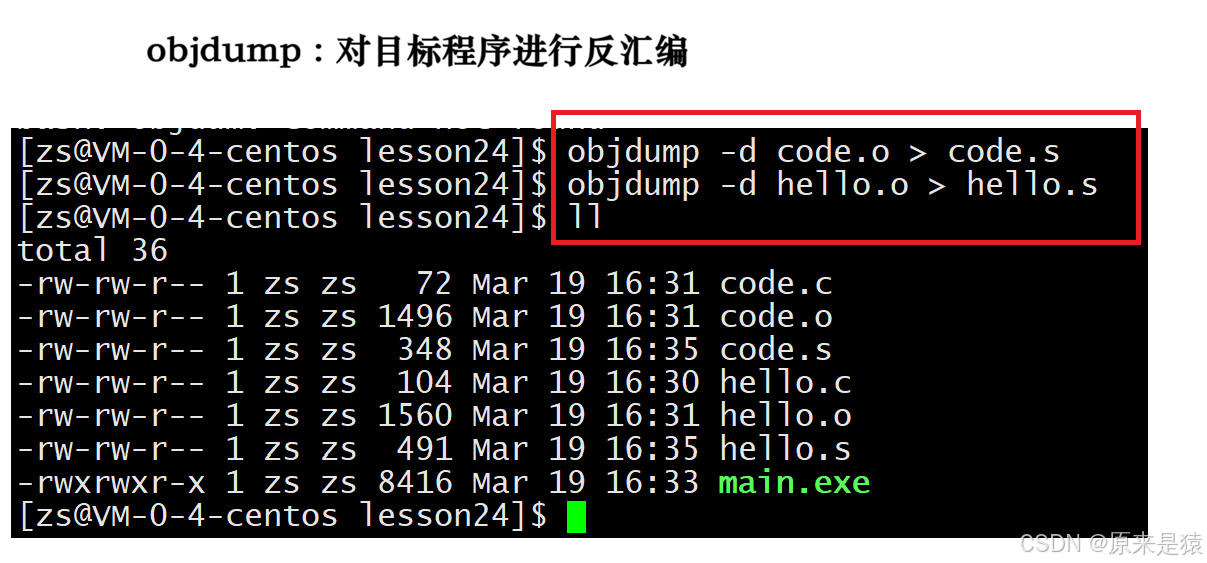
注意
call指令的目标地址都是00 00 00 00,这是因为编译器在编译hello.c时并不知道printf和run函数的地址**【还没有链接,模块之间没有合并】**,它们被暂时设为0,等待链接时修正。
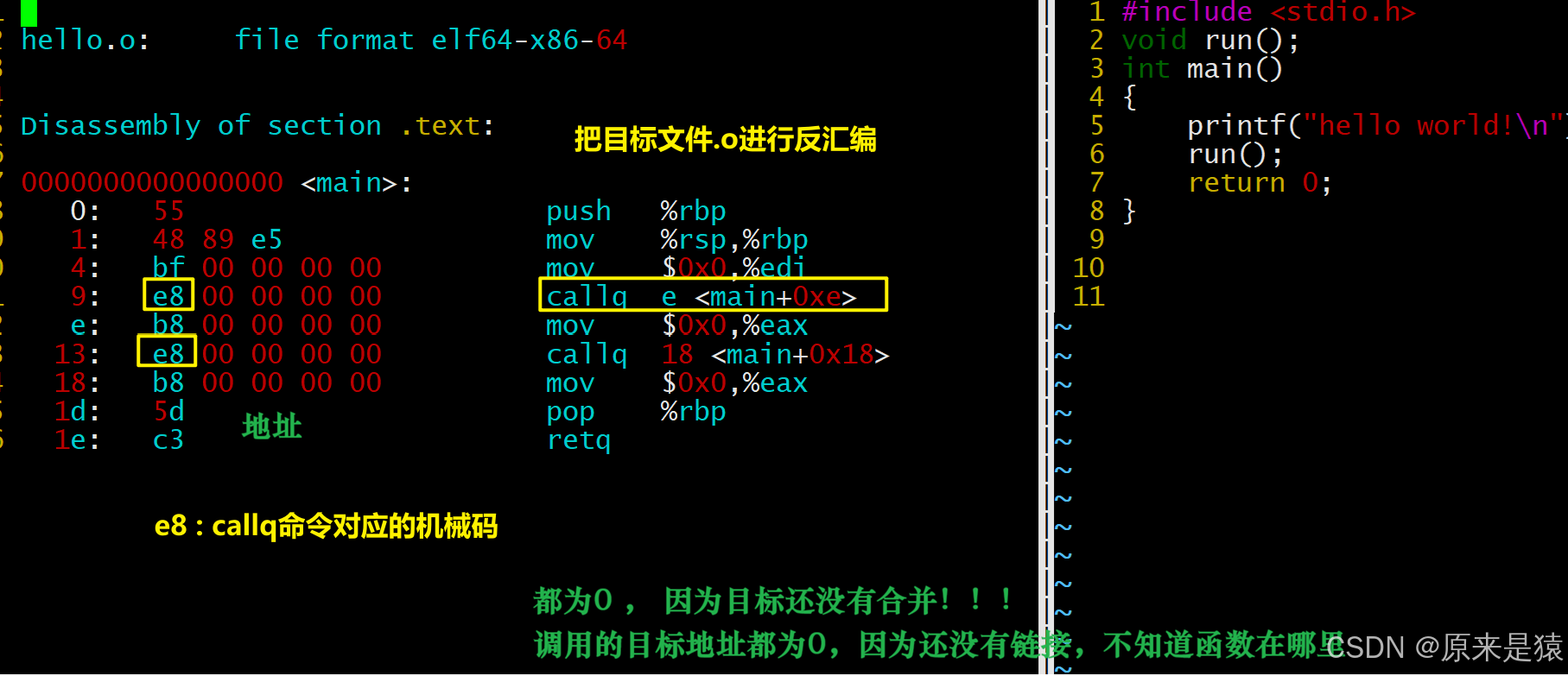
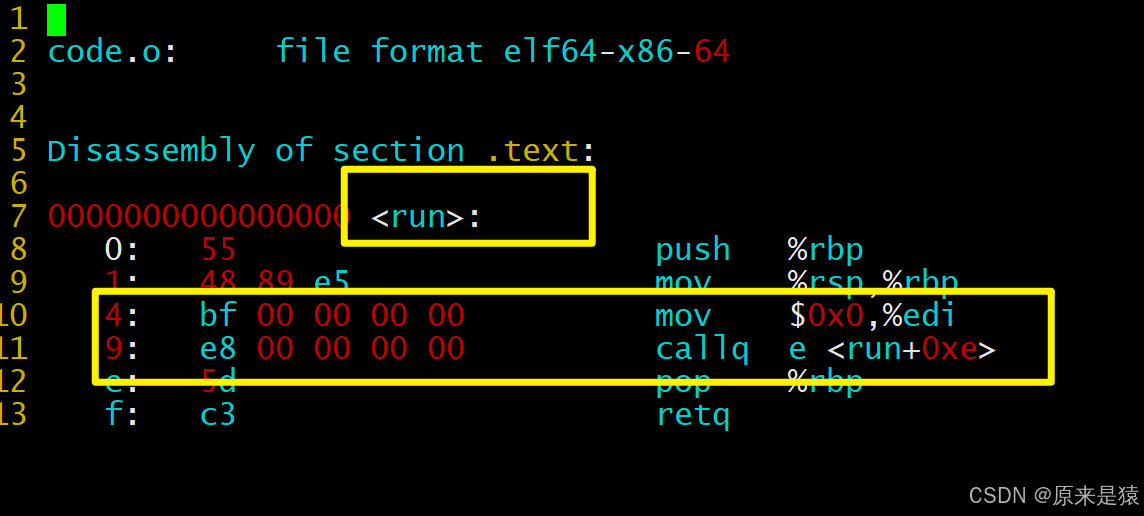

- objdump -d 命令 :将代码段 (.text)进行反汇编进行查看
- hello.o 中的main函数不认识printf 和 run 函数
我们试一下在code.c下加一个不存在的函数,发现没有报错

其实就是在编译 hello.c 的时候,编译器是完全不知道 printf 和 run 函数的存在的,比如他们位于内存的哪个区块,代码长什么样都是不知道的。因此,编辑器只能将这两个函数的跳转地址先暂
时设为0。

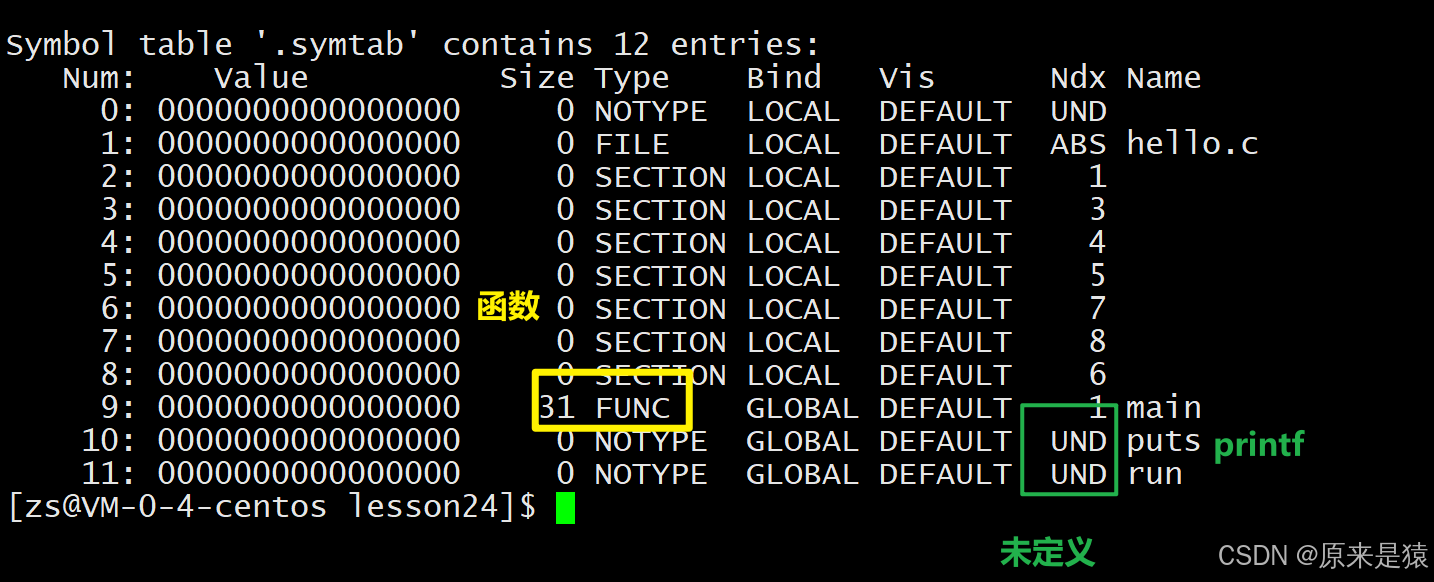
2.符号表查看
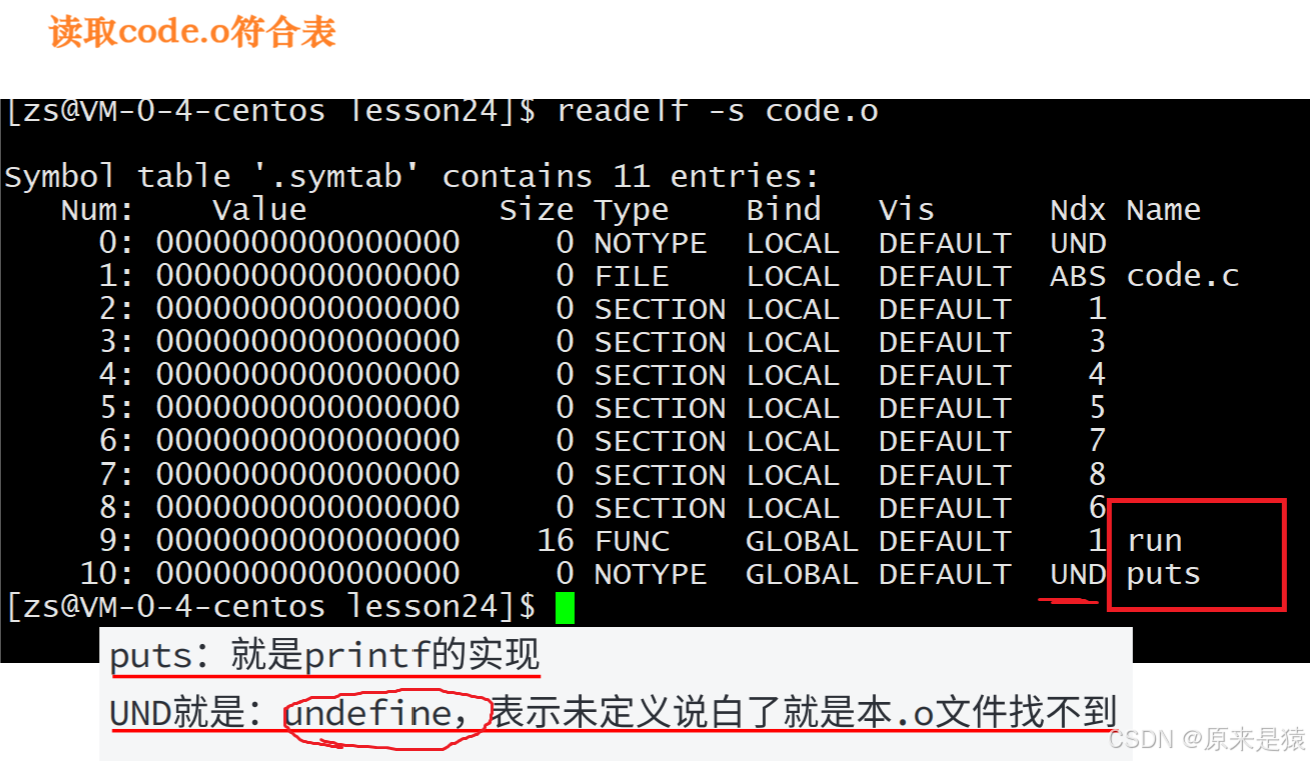
读取code.o的符号表
读取main.exe符号表
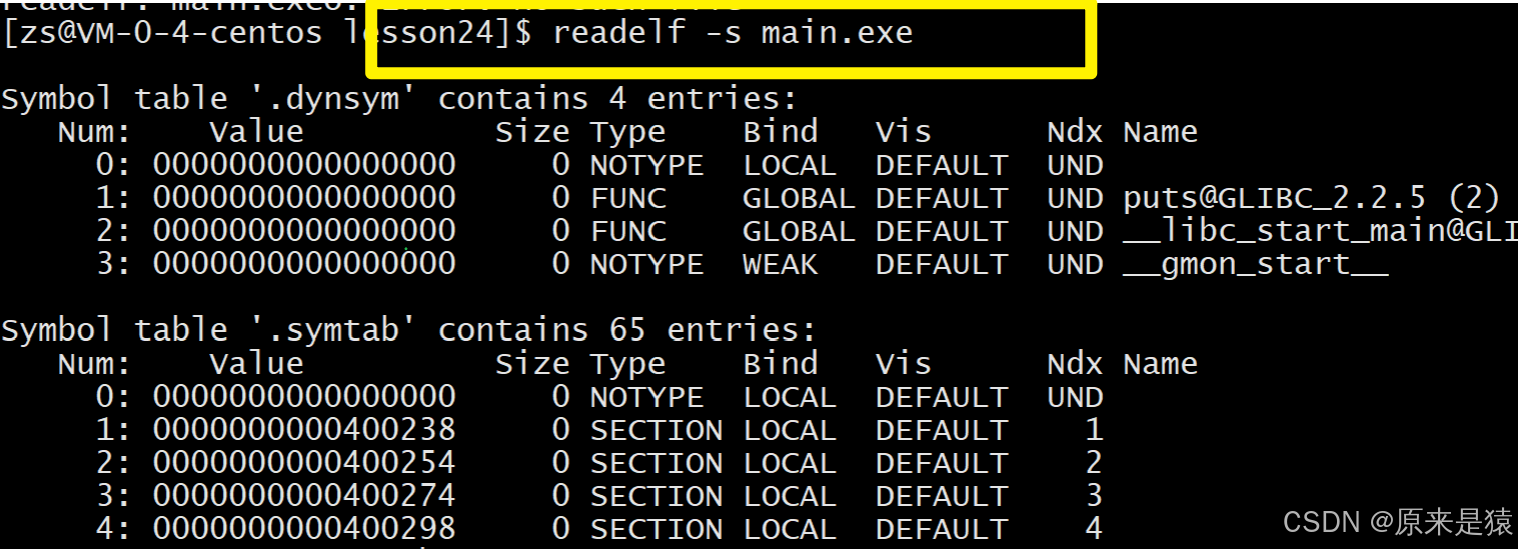
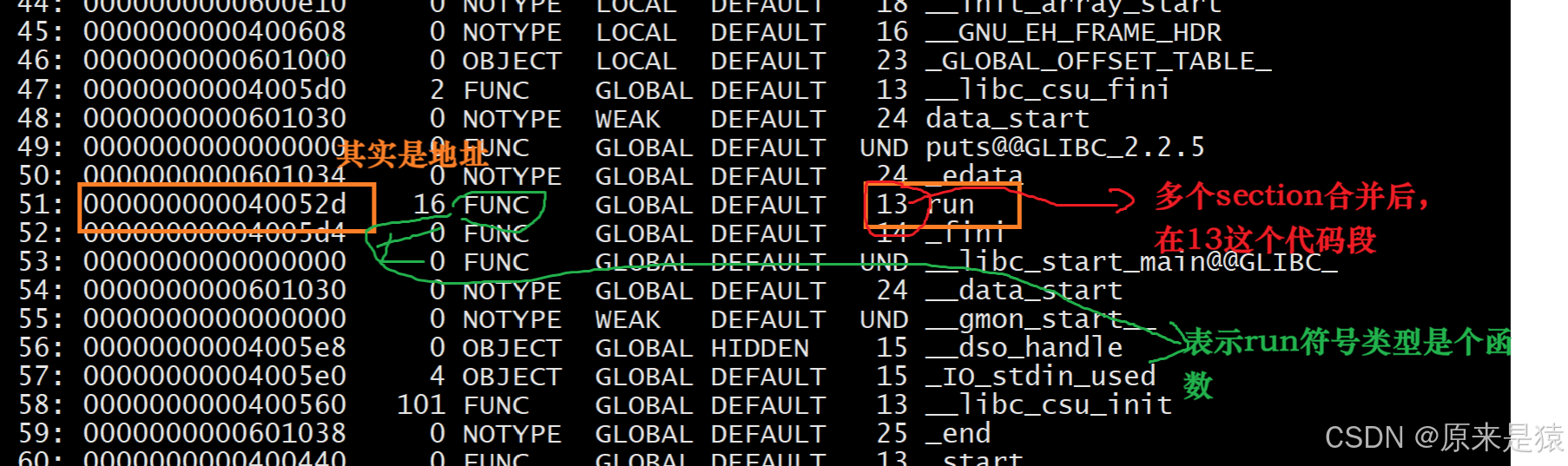
- hello.o和code.o的.text被合并了,是main.exe的第13个section
关于hello.o或者code.o call后面的00 00 00 00有没有被修改成为具体的最终函数地址呢?
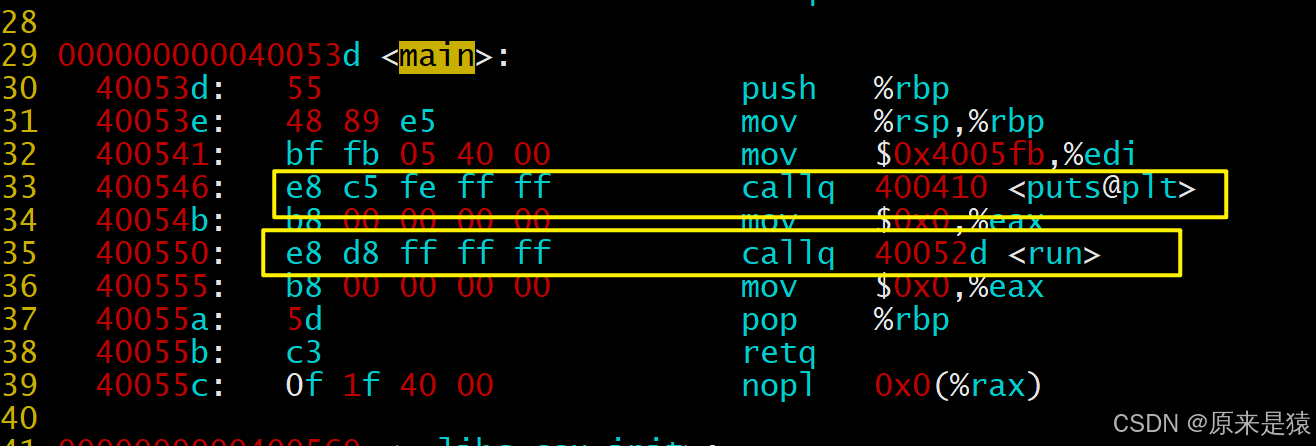
链接的时候,会修改.o中没有确定的函数地址,在合并完成之后,进行相关call地址,完成代码调
用

所以 ,链接过程中会涉及到对 .o 中外部符号进行重定位!!!!
3.2 ELF加载与进程地址空间
3.2.1 虚拟地址/逻辑地址
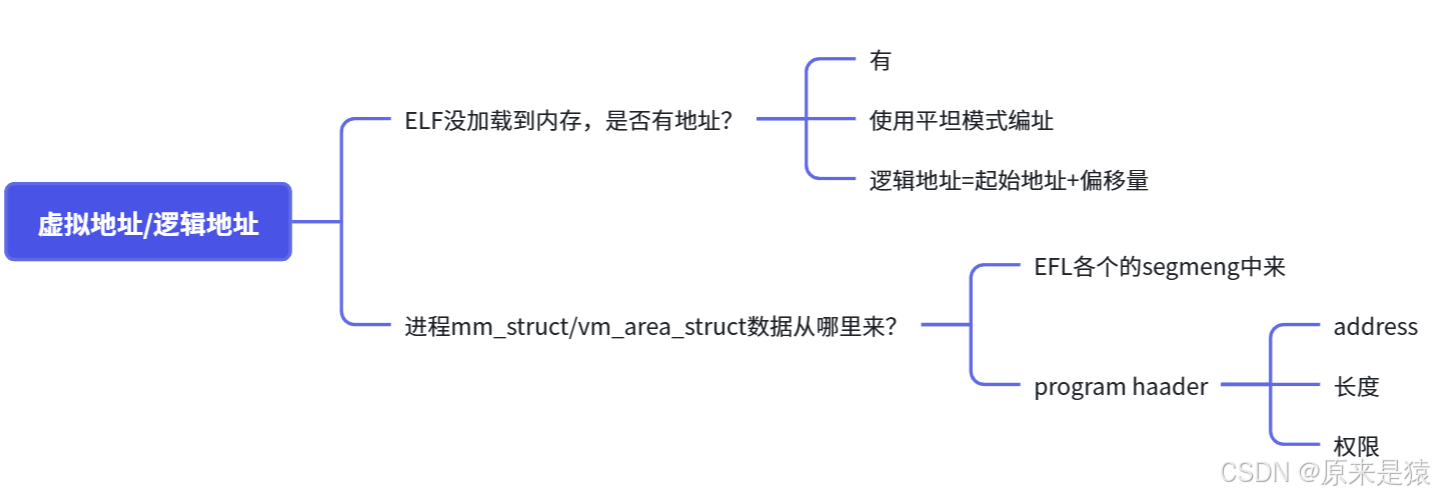
问题:
- ELF 没加载到内存时,有地址吗?
- 进程的 **
mm_struct/vm_area_struct**初始化数据从哪来?
先回答问题一:
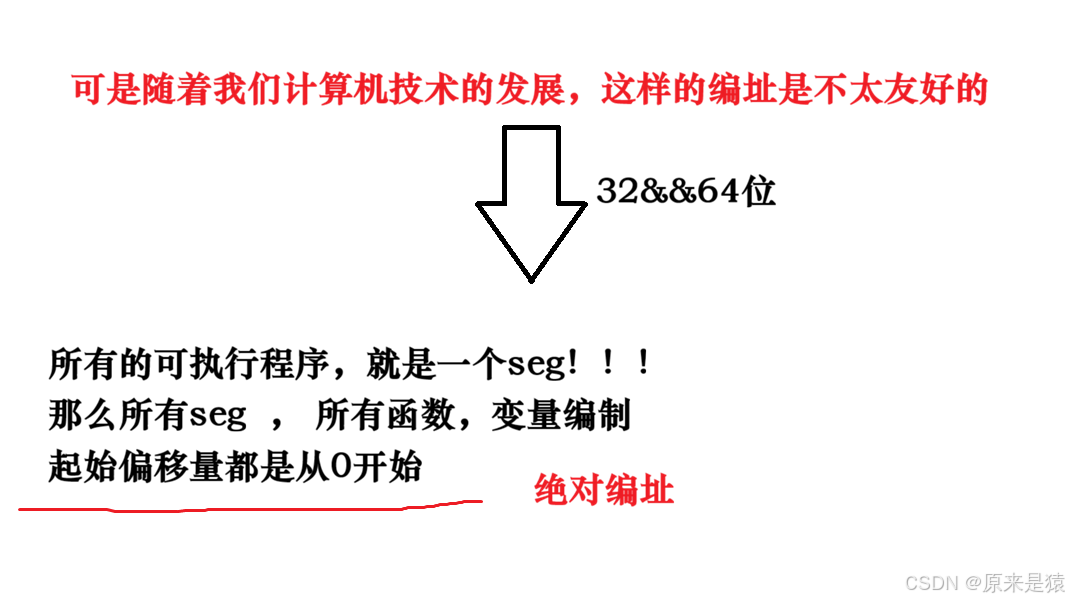
一个ELF可执行文件在被加载到内存之前,就已经有了虚拟地址。编译器在生成目标文件和链接成可执行文件时,就已经按照虚拟地址空间布局进行了编址(例如 main 函数的地址可能是 0x1160)。这就是所谓的**"平坦模式"(flat model)**,即程序认为它自己独占整个地址空间。

下面是 objdump -S 反汇编之后的代码
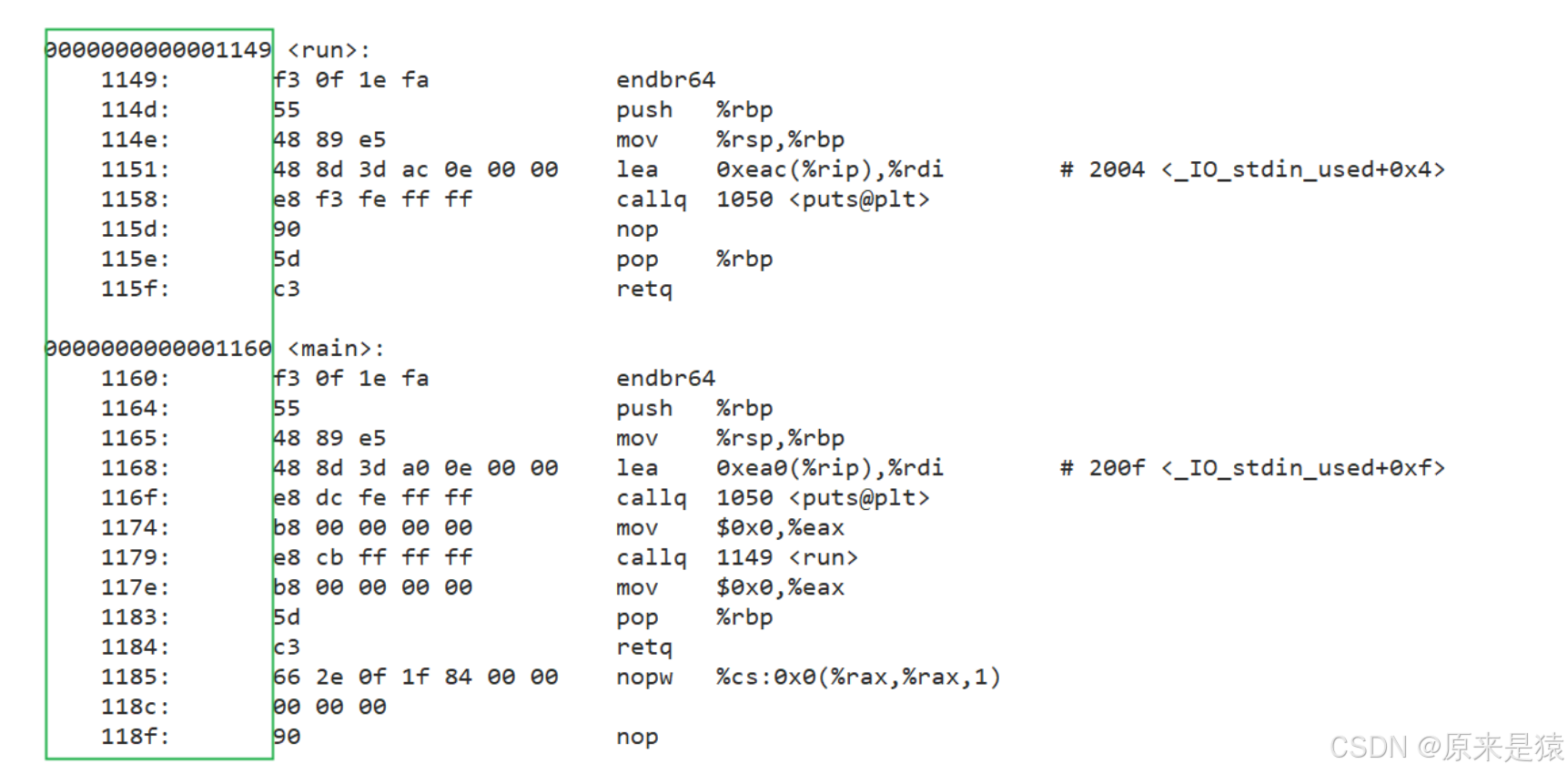
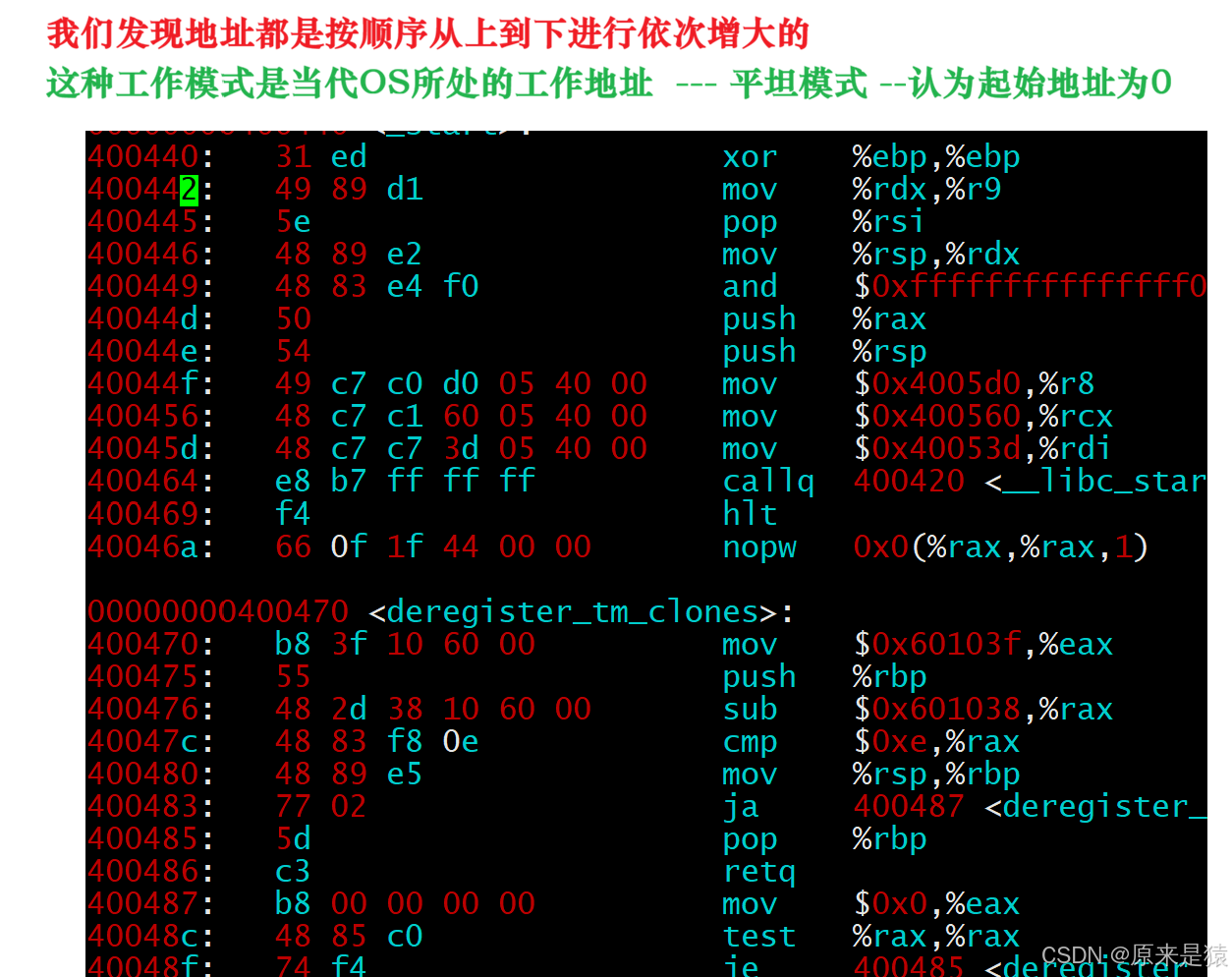
最左侧的就是ELF的虚拟地址 , 起始 , 严格意义上应该叫做逻辑地址(起始地址 + 偏移量) , 但是我们认为起始地址是 0 , 也就是说 ,起始地址在我们程序还没有加载到内存的时候,就已经把可执行程序进行统一编址了!!!
回答问题二:
进程mm_struct 、 vm_area_struct 在进程刚刚创建的时候,初始化数据从ELF各个的segment 中来 , 每个segment 有自己的起始地址和自己的长度,用来初始化内核结构中的start ,end等范围数据, 另外在详细地址,填充表!!!
mm_struct:进程的虚拟地址空间总管家,记录整个小区的布局。vm_area_struct:小区里的每一栋楼,代表一段连续的虚拟地址范围(比如代码段、数据段、栈段)。
ELF 文件里的**Program Header 会告诉内核:**
我有一段代码,要从虚拟地址
0x400000开始,长度0x1000,权限是只读可执行;我有一段数据,要从虚拟地址
0x600000开始,长度0x2000,权限是读写。
内核拿到这些信息后:
- 给进程创建
mm_struct,作为总管家。 - 为每个
Segment创建一个vm_area_struct,记录这段虚拟地址的[start, end]范围和权限。 - 后续加载程序时,再把这些段映射到物理内存,填充页表。
所以,虚拟地址机制 , 不光光需要OS支持,编译器也要支持!!
把多个section 文件合并 , 就是对可执行程序进行统一编址
3.2.2 重新理解进程虚拟地址空间
ELF在编译好之后,会把自己未来程序的入口地址记录在ELF header的entry字段中!!!
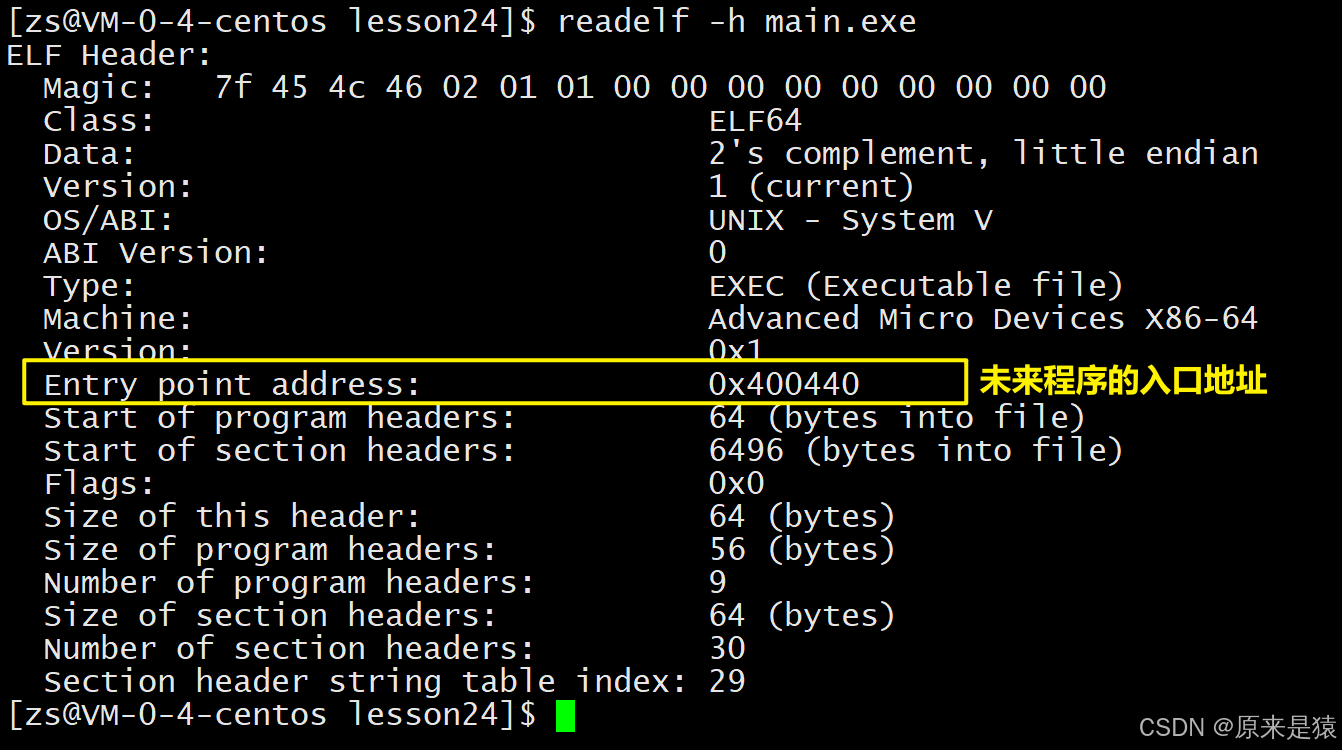
- 操作系统加载程序时,就从这个地址开始执行,就像你回家必须先开家门。
- 这个地址也是虚拟地址,不是物理内存地址。
这里再来讲解一下什么是虚拟地址空间:
虚拟地址空间:进程的 "独立小区"
每个进程都觉得自己独占整个内存空间,这就是虚拟地址空间:
- 它是 "假的",是操作系统给进程画的 "大饼"。
- 真正的物理内存是 "共享的大楼",操作系统通过页表把虚拟地址翻译成物理地址。
- 好处:进程之间互不干扰,一个进程崩溃不会影响其他进程。

- 程序一开始只是磁盘上的文件 , 里面有代码指令 , 虚拟地址规划 , 入口地址
- 程序想要执行起来 , 就要加载到内存里 ;
- 内核读取磁盘上的可执行程序,解析段信息(.text , .data ....)
- 代码和数据拷贝到物理内存的某个位置
- 内核创建进程PCB , task_struct , mm_struct , 多个vm_area_struct
- 最后建立页表 , 把虚拟地址映射到物理地址
- 内核EIP把程序的入口地址和CPU说
- CR3寄存器设为当前进程的页表地址
- CPU每次取一条指令**【虚拟地址 -> 页表 -> 物理地址】**,找到指针在物理内存的位置,然后执行
- EIP :指令指针,存着下一条要执行指令的虚拟地址,CPU 靠它知道 "下一步该干啥"。
- CR3 :页表基址寄存器**,存着当前进程页表的物理地址**,CPU 靠它找到 "虚拟地址→物理地址" 的映射表。
- 进程看到的都是 虚拟地址 ,它和物理地址没有直接关系。
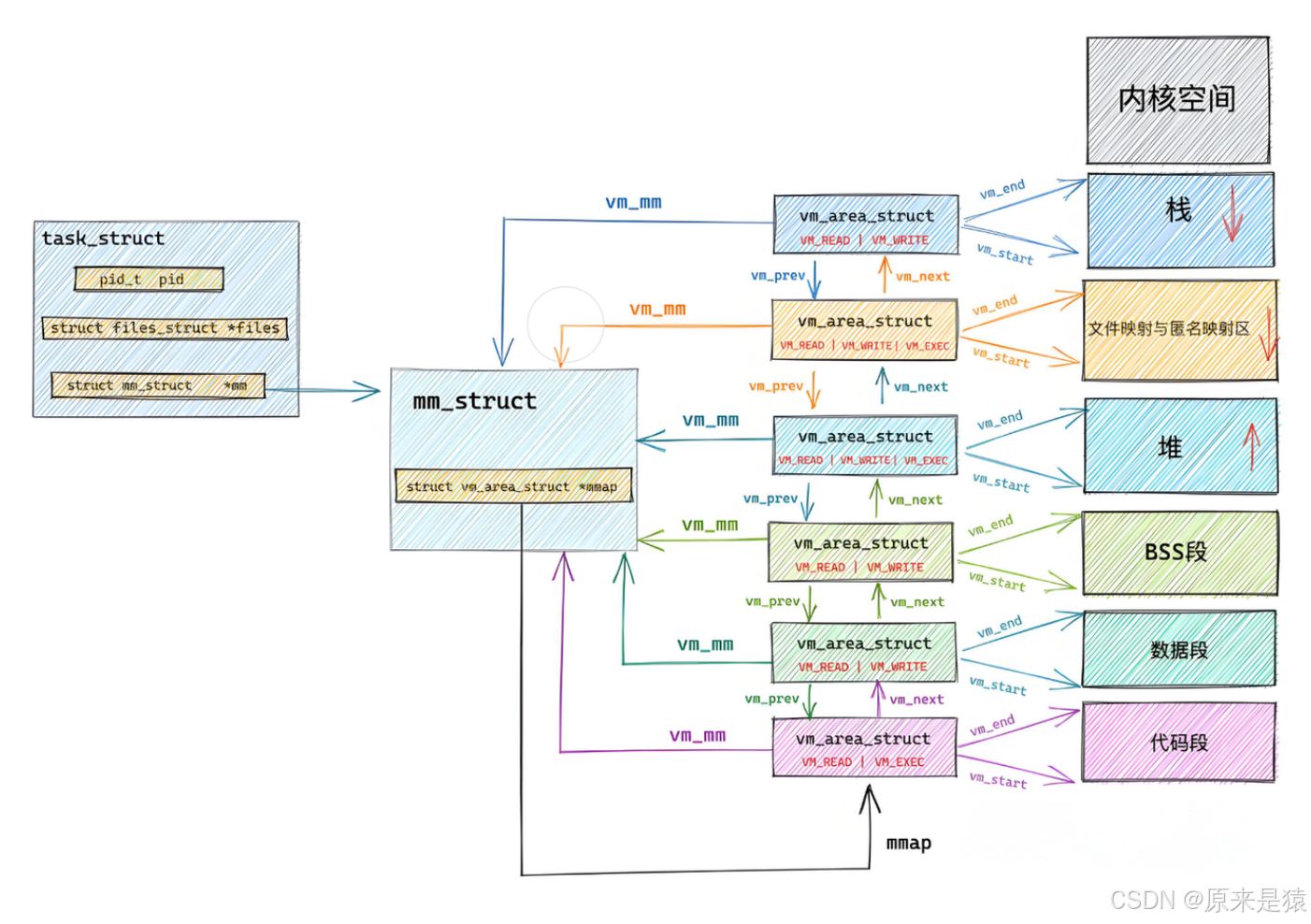
vm_area_struct就是内核根据 ELF 的Segment信息创建的:
- 解析 ELF 文件,发现有代码段、数据段、BSS 段等。
- 为每个段创建一个
vm_area_struct,记录vm_start、vm_end和权限。- 把这些
vm_area_struct挂到mm_struct的链表上。- 后续加载时,再把这些段映射到物理内存,填充页表。
3.3 动态链接与动态库加载
动态库是如何和我们的可执行程序关联 ?
---> 通过 地 址 空 间
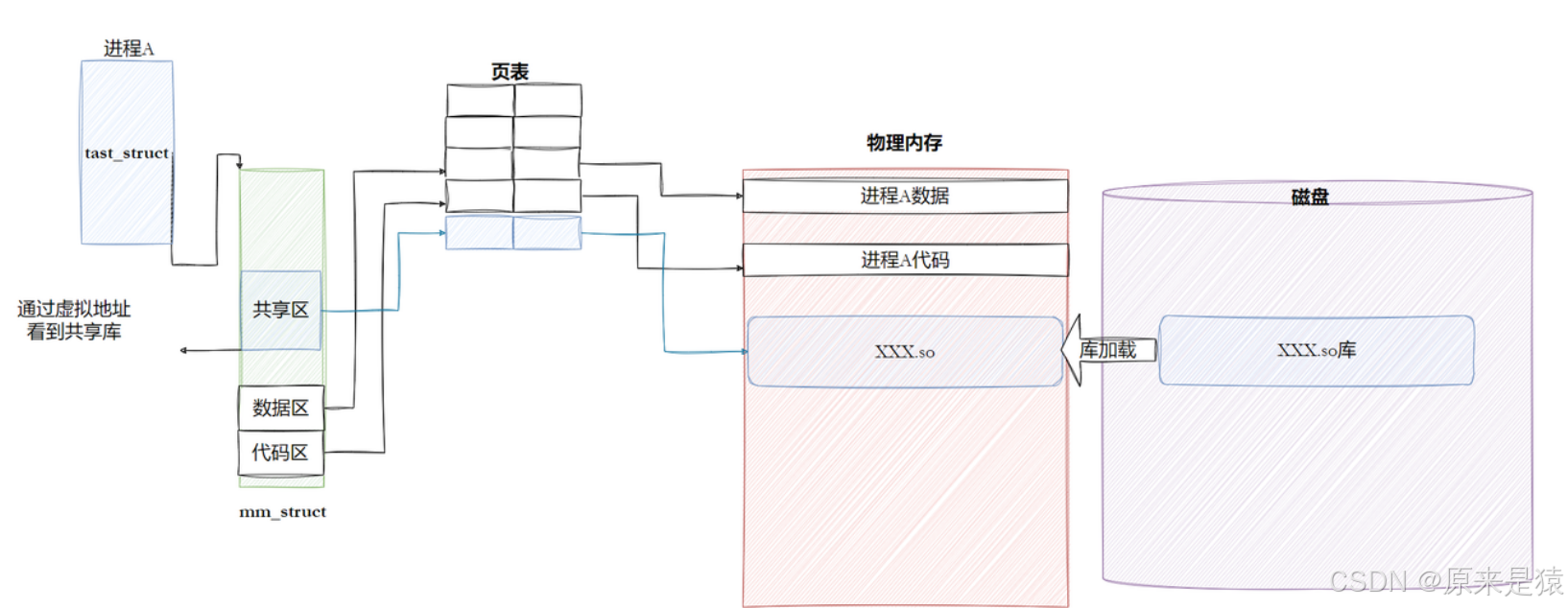
3.3.1 进程如何看到动态库

3.3.2 进程如何共享库
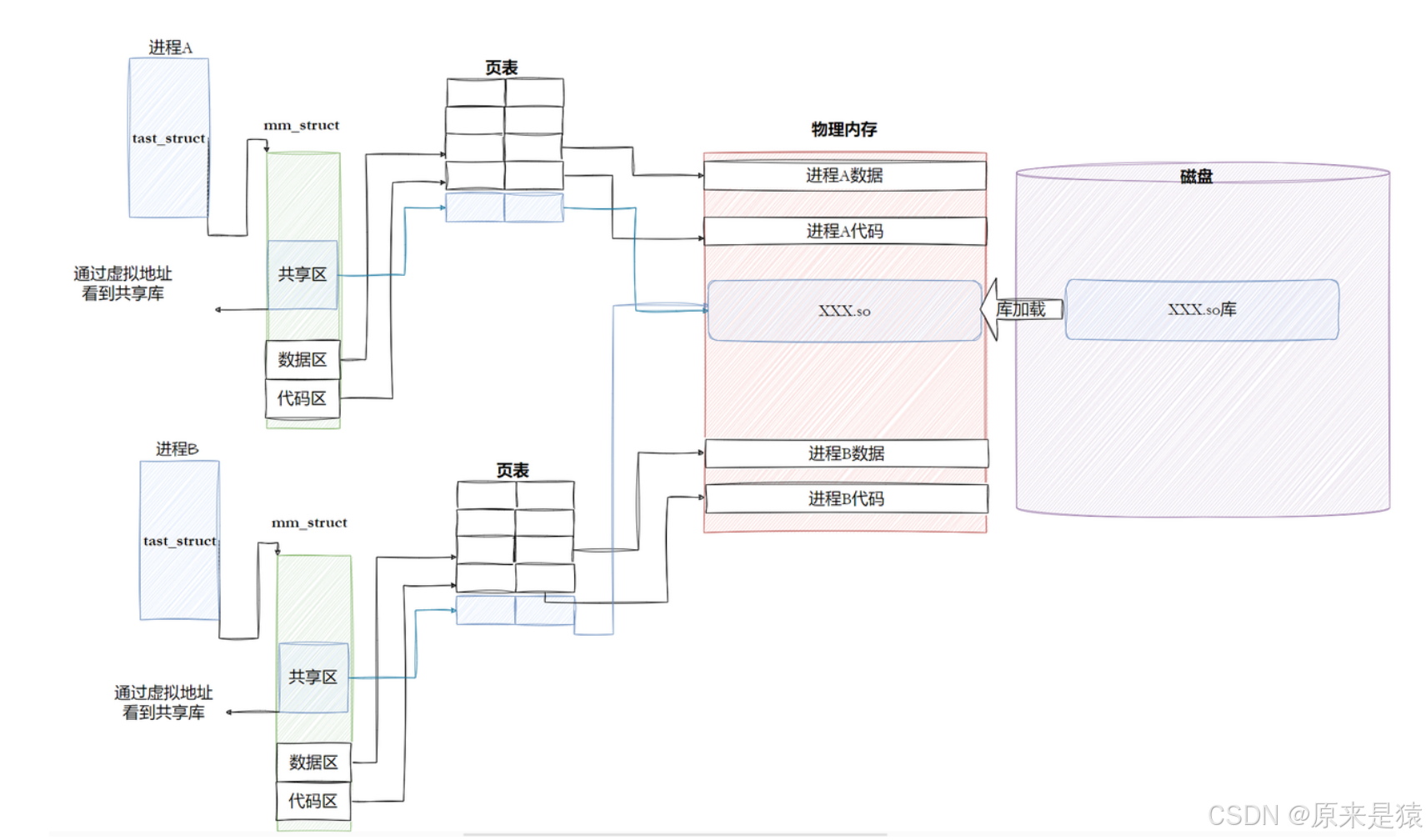
- 动态库(
.so)在物理内存中只存一份,却被多个进程共享访问 - 多个进程通过各自的页表,把动态库映射到自己的地址空间里,在各自的虚拟地址空间中,它们的地址可以不同,但是在物理空间上都是同一个地址!!!!
- 既实现了代码复用和内存节省,又保证了进程之间的地址隔离和独立性。
3.3.3 动态链接
动态链接的核心思想是将链接过程推迟到程序加载时甚至运行时。这样,多个程序可以共享内存中的同一份库代码。
3.3.3.1 概要
动态链接起始远比静态链接要常用得多 ;

ldd 命令用户打印程序或者库文件所依赖的共享库列表


3.3.3.2 我们的可执行程序被编译器动过手脚
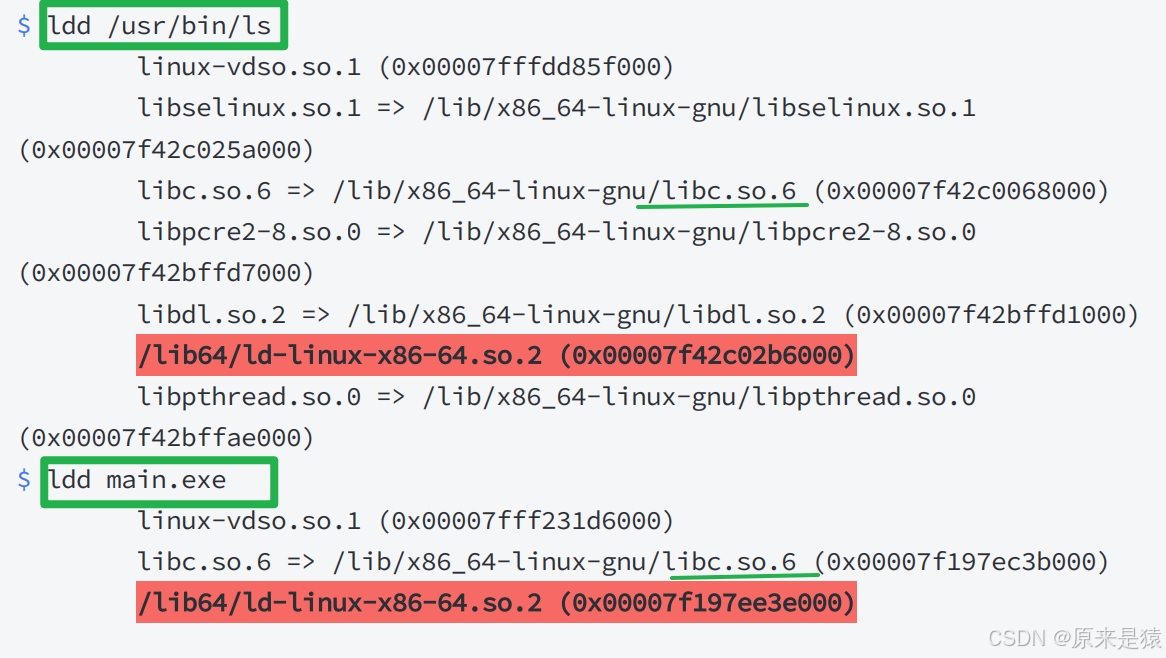
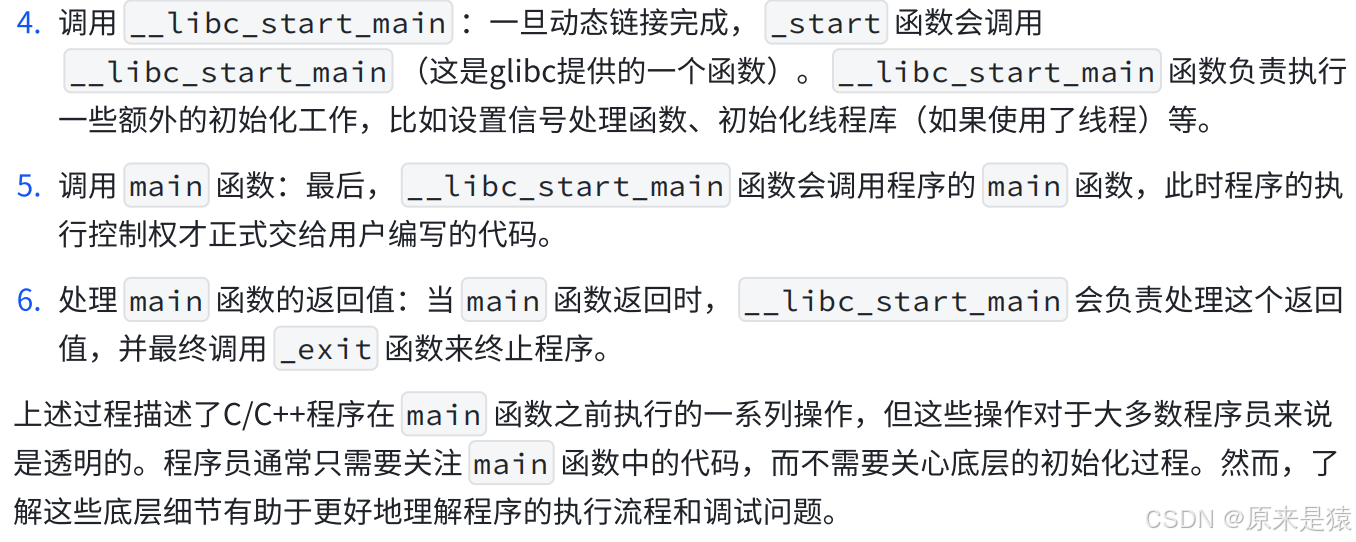
在C/C++程序中 , 当程序开始运行的时候,他首先并不会直接跳到 main 函数 。实际上程序入口为 _start 。 这是一个由C运行时库 (通常是glibc) 或链接器(如Id) 提供的函数



3.3.3.3 动态库中的相对地址
**动态库为了随时进行加载,**为了支持并映射到任意进程的任意位置 , 对动态库中的方法,统一编址 , 采用相对编址的方案进行编址的 (其实可执行程序【起始地址(0)+偏移量】也一样 , 都要遵守平坦模式 , 只不过exe是直接加载的)

3.3.3.4 我们的程序,怎么和库具体映射起来的
- 动态库也是一个文件,要访问也是先要被加载,要加载也是要被打开的。
- 让我们的进程找到动态库的本质 ,也是文件操作,不过我们访问库函数,通过虚拟地址进行跳转访问的, 所以需要把动态库映射到进程的地址空间中。
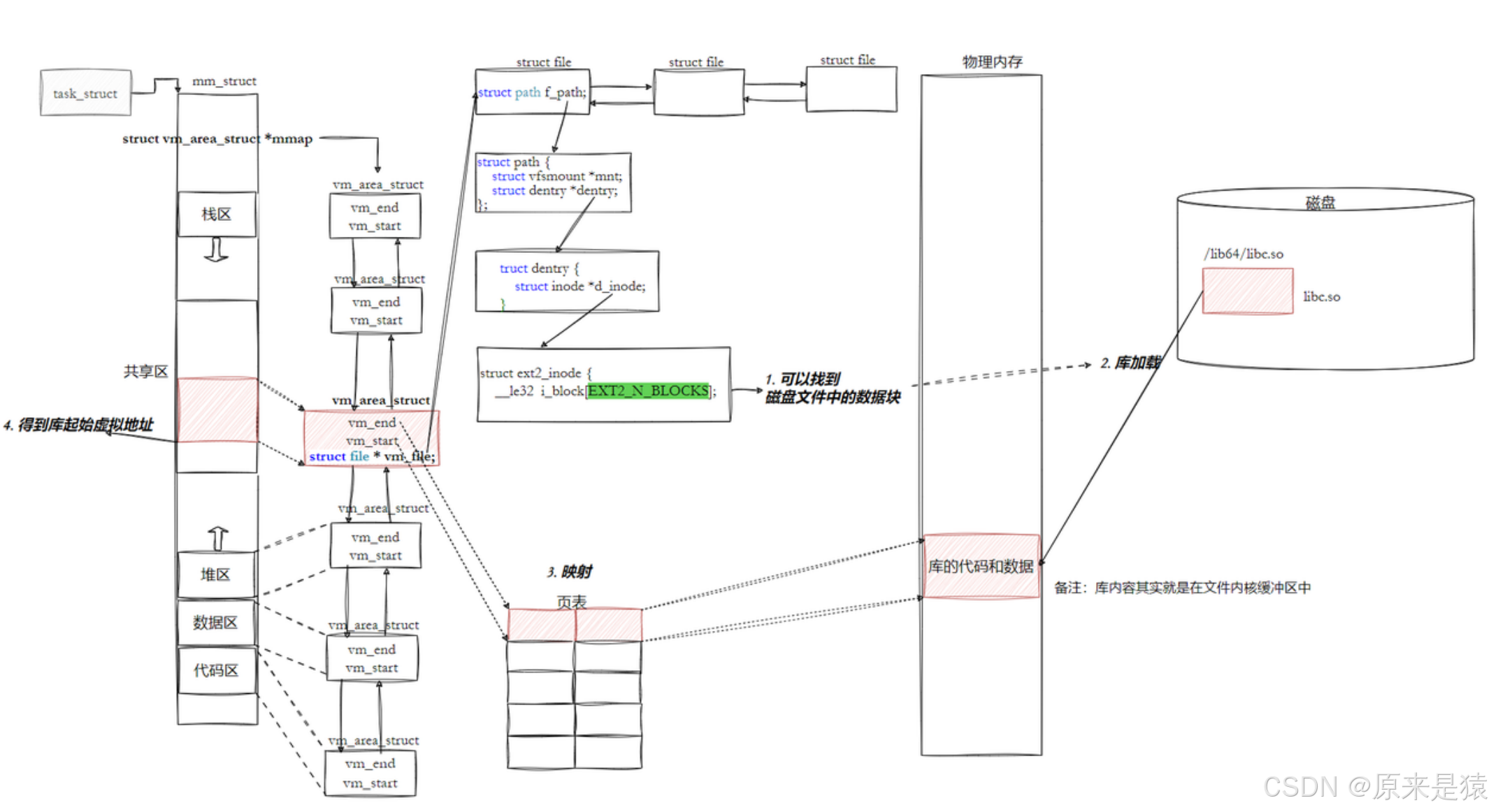
3.3.3.5 我们的程序,怎么进行库函数调用
- 库已经被我们映射到了当前进程的地址空间中
- 库的虚拟起始地址我们也已经知道了
- 库中每一个方法的偏移量地址我们也知道
- 所有 : 访问库中任意方法 , 只需要知道库的起始虚拟地址 + 方法偏移量即可定位库中的方法
- 而且:整个调用过程 , 是从代码区跳转到共享区,调用完毕再返回到代码区 , 整个过程完全在进程地址空间中进行 。
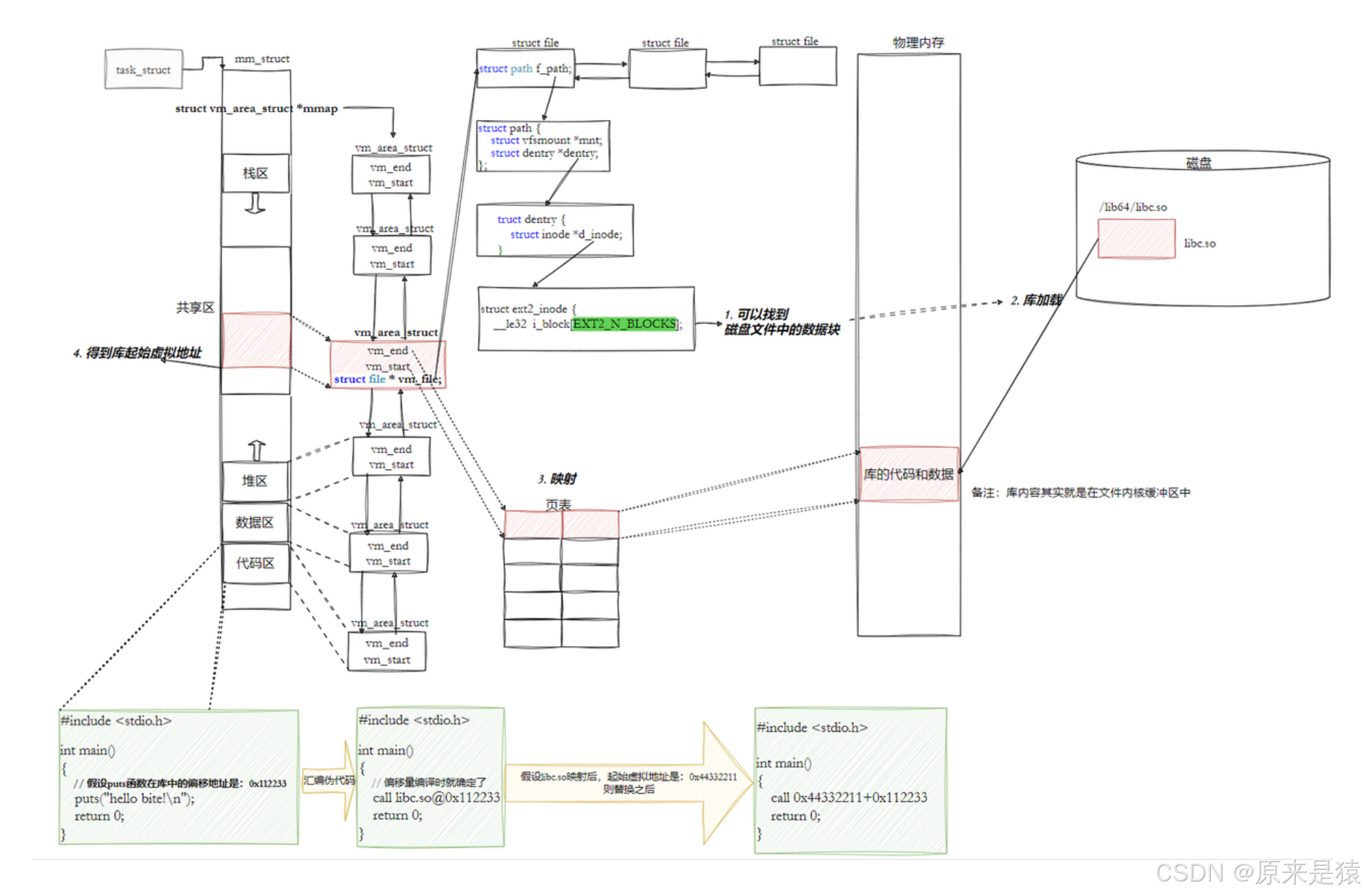

- 编译的时候要对我们的代码进行编址
3.3.3.6 全局偏移量表GOT
- 也就是说 , 我们的程序在运行之前,先把所有库加载并映射,所有库的起始虚拟地址都应该提前知道
- 然后对我们加载到内存中的程序的库函数调用进行地址修改 ,在内存中二次完成地址设置(这这叫做加载地址重定位)
代码区在进程中不是只读的吗 ? 那么如何进行修改?
---> 所以 : 动态链接采用的做法是 在**.data(可执行程序或者库自己)中专门预留一片区域用来存放函数的跳转地址 ,**也被叫做全局偏移表 GOT, 表中每一项都是本运行模块要引用的一个全局变量或函数的地址。
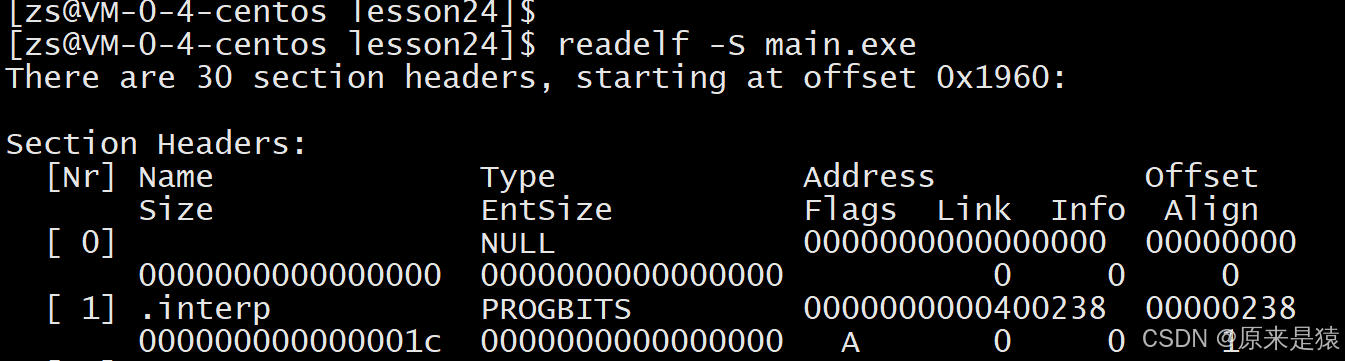
因为 .data区域是可读写的 , 所以可以支持动态进行修改

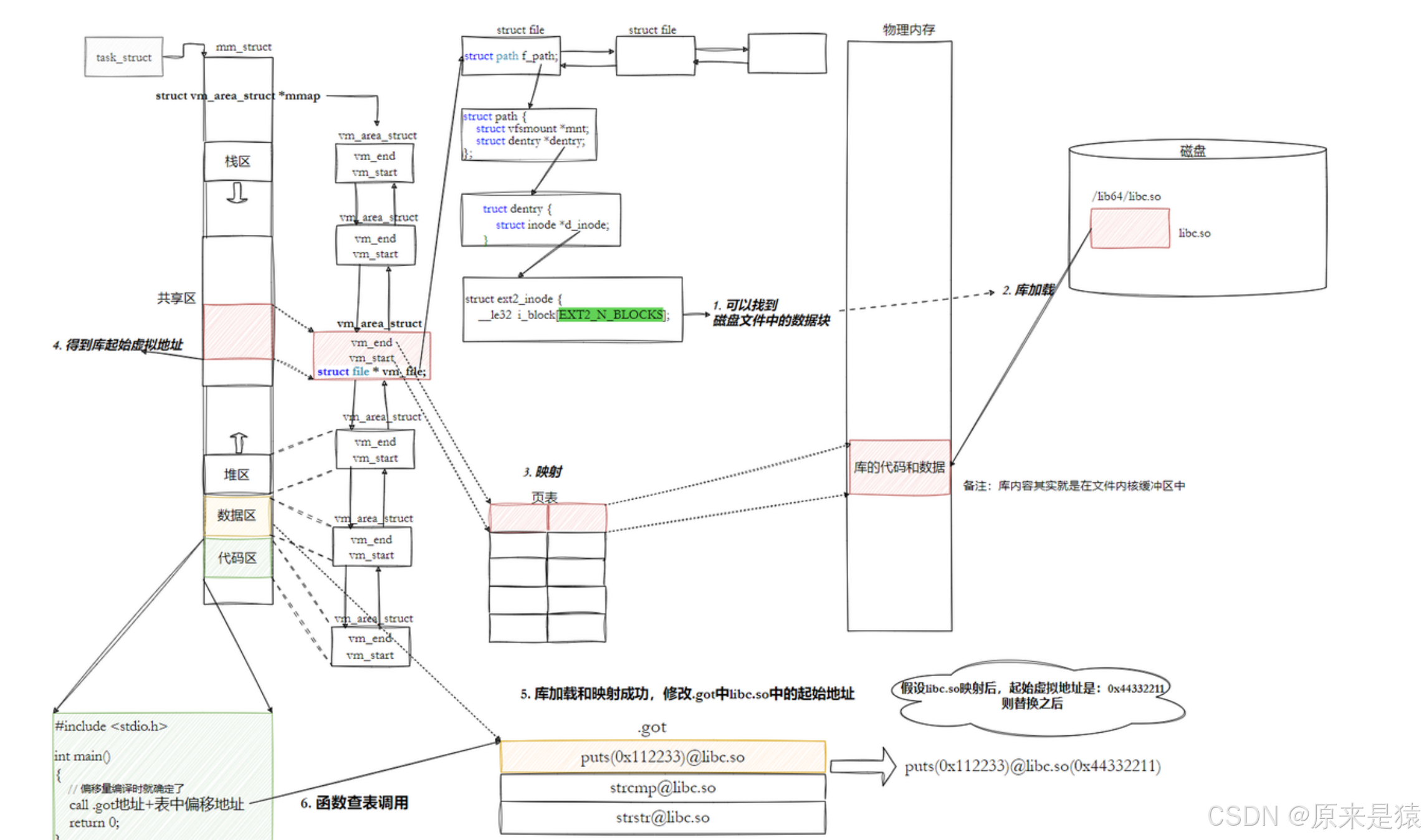
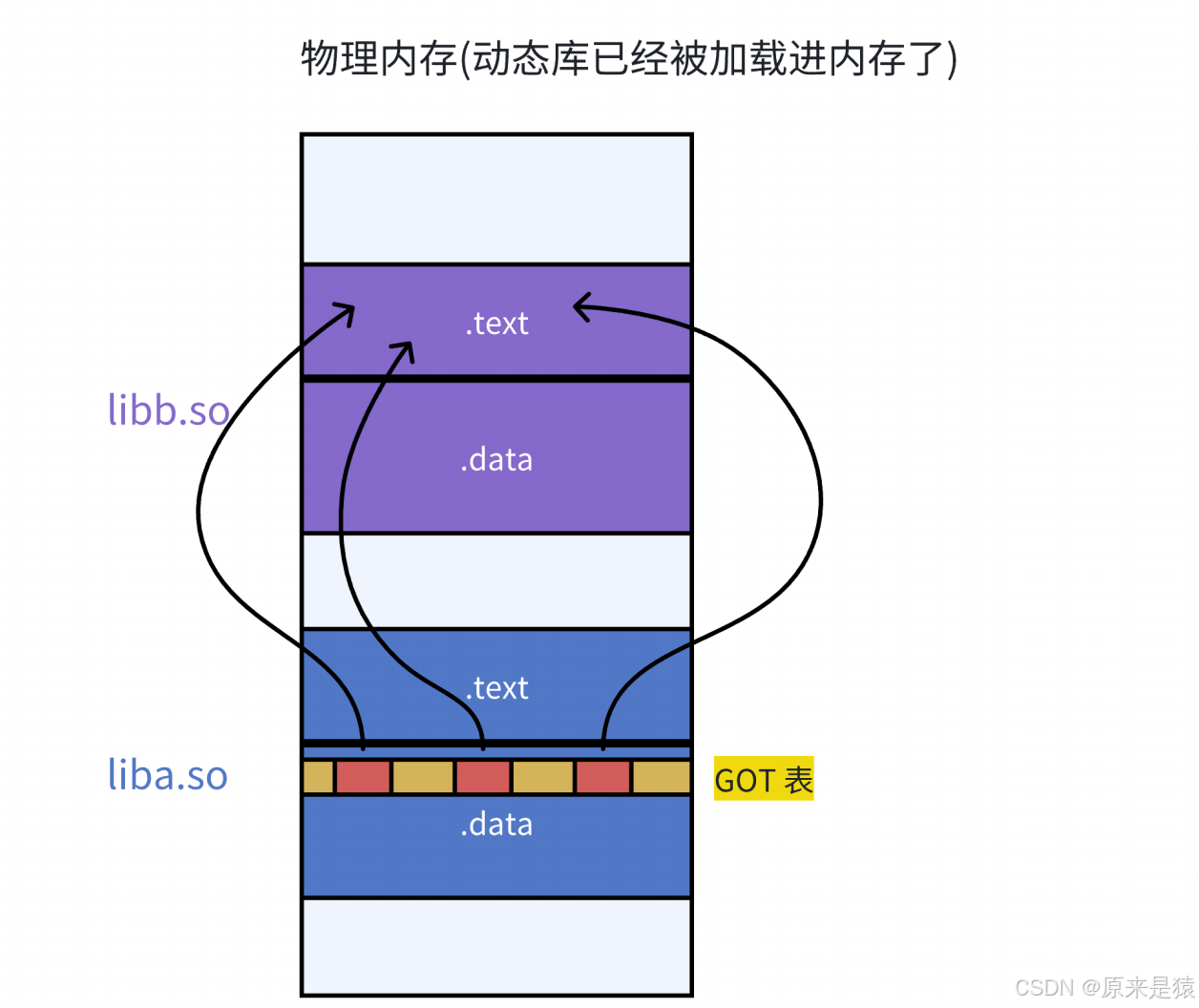
- 由于代码段只读 , 我们不能直接修改代码段 。 但是有了GOT表,代码就可以被所有进程共享。但是在不同的进程地址空间中 , 各动态库的绝对地址 、 相对地址都不同 。 反应到GOT表上 , 就是每个进程的每个动态库都有独立的GOT表 , 所以进程间不能共享GOT表。
- 在单个 .so 下 , 由于GOT表 与 .text 的相对位置是固定的 , 我们完全可以利用CPU的相对寻址来找到GOT表
- 在调用函数的时候会先查表 , 然后根据表中的地址来进行跳转。这些地址在动态库加载的时候会被修改为真正的地址
- 这种方式实现的动态链接就被叫做PIC地址无关代码 。 换句话说 , 我们的动态库不需要做任何修改 , 被加载到任意内存地址都能正常运行 , 并且能被所有进程共享 , 这也是为什么之前我们给编译器指定 -fPIC参数的原因 , PIC = 相对编址 + GOT
3.3.3.7 库间依赖

3.3.4 总结
