目录
[一 进程创建](#一 进程创建)
[1 知识点回顾](#1 知识点回顾)
[2 写时拷贝](#2 写时拷贝)
[(1) 写时拷贝的原理--->部分](#(1) 写时拷贝的原理--->部分)
[3 关于进程创建的实际应用场景](#3 关于进程创建的实际应用场景)
[二 进程终止](#二 进程终止)
[1 进程终止的几种情况](#1 进程终止的几种情况)
[2 进程常见的退出方法](#2 进程常见的退出方法)
[(1)echo ? 命令](#(1)echo ? 命令)
(6)总结总结)
一 进程创建
我们先来引入两个结论:
(1)进程 = 内核数据结构(task_struct z + mm_struct + vm_area_struct) +代码和数据
其中:内核数据结构更侧重于进程管理 ,代码和数据侧重于进程完成任务
(2)进程创建的本质:就是系统内多了一个进程
进程是具有独立性:内核各自独立,代码和数据也各自独立!
1 知识点回顾
(1)fork函数初识
在 Linux 中,fork函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
bash
#include <unistd.h>
pid_t fork(void);
返回值:⼦进程中返回0,⽗进程返回⼦进程id,出错返回-1
1. 为什么要给⼦进程返回0,⽗进程返回⼦进程pid?
2. 为甚⼀个函数fork会有两个返回值?
3. 为什么⼀个id即等于0,⼜⼤于0?进程调用 fork,当控制转移到内核中的 fork 代码后,内核会执行以下操作:
・分配新的内存块和内核数据结构给子进程
・将父进程部分数据结构内容拷贝至子进程
・添加子进程到系统进程列表当中
・fork 返回,开始由调度器进行调度
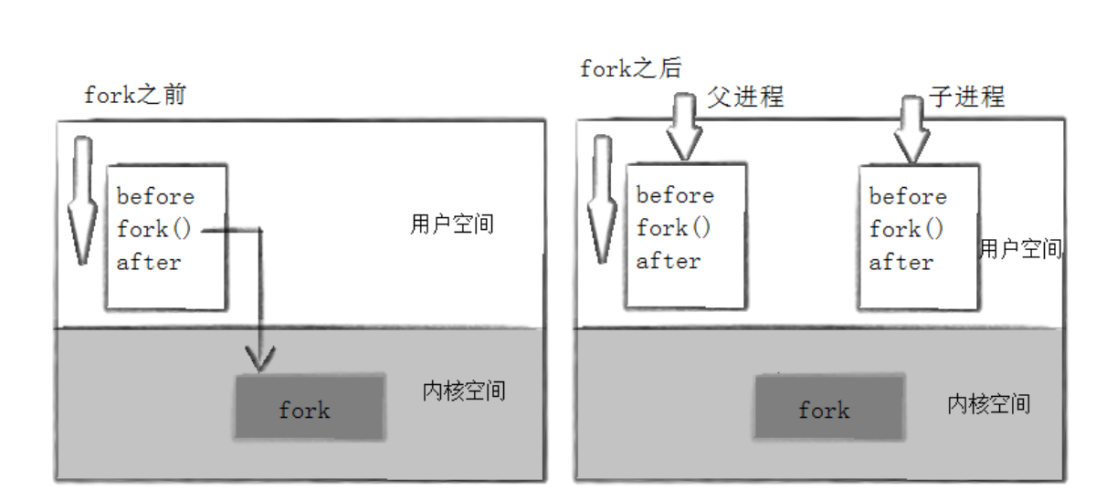
当一个进程调用 fork 之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程,看如下程序。
bash
int main( void )
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ( (pid=fork()) == -1 )perror("fork()"),exit(1);
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}
运⾏结果:
[root@localhost linux]# ./a.out
Before: pid is 43676
After:pid is 43676, fork return 43677
After:pid is 43677, fork return 0这里看到了三行输出,一行 before,两行 after。进程 43676 先打印 before 消息,然后它又打印 after。
另一个 after 消息是 43677 打印的。注意到进程 43677 没有打印 before,为什么呢?如下图所示
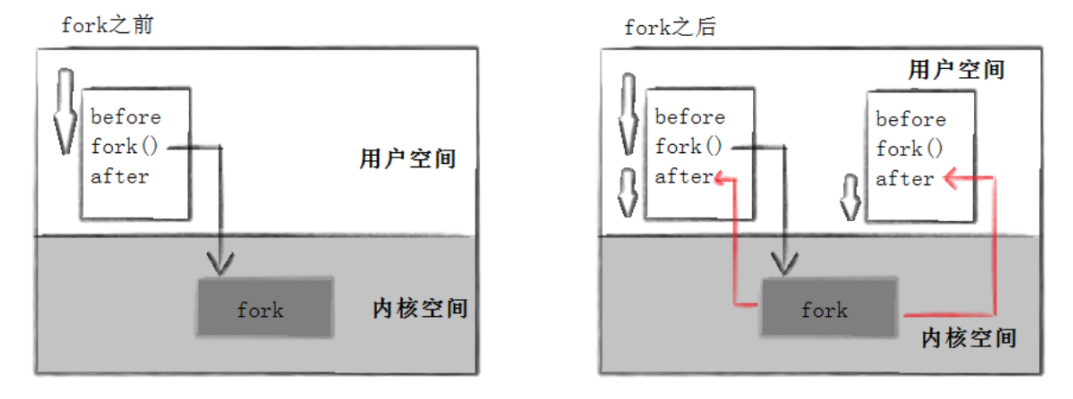
所以,fork 之前父进程独立执行,fork 之后,父子两个执行流分别执行。注意,fork 之后,谁先执行完全由调度器决定。
(2)fork函数的返回值
子进程返回0
父进程返回的是子进程的pid
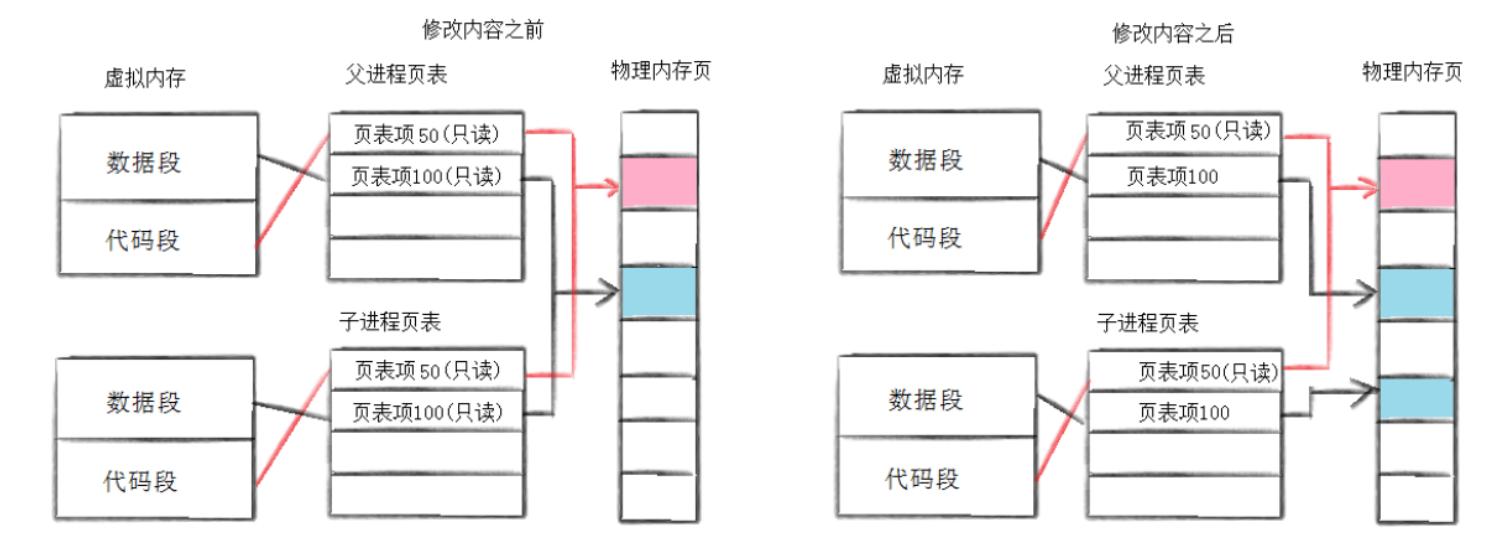
(3)写时拷贝
通常,父子代码共享,父子在不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图:
qu
因为有写时拷贝技术的存在,所以父子进程得以彻底分离!完成了进程独立性的技术保证!
写时拷贝,是一种延时申请技术,可以提高整机内存的使用效率。
(4)fork的常用用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。
例如,父进程等待客户端请求,生成子进程来处理请求。
一个进程要执行一个不同的程序。
例如子进程从fork返回后,调用exec函数。
(5)fork调用失败的原因
系统中有太多的进程
实际用户的进程数超过了限制
2 写时拷贝
(1) 写时拷贝的原理--->部分
当我们的权限是只读,如果这个时候写入数据,就会转化失败。操作系统会介入,识别到子进程要访问共享数据,操作系统会触发写时拷贝,修改页表·。父子进程就可以正常访问各自数据
系统fork 之后,是通过修改页表权限,来触发报错,让 操作系统 介入,完成写时拷贝的!

(2)为什么要有写时拷贝
区分问题:写入!= 覆盖写入,修改也是写入!count = 10; count++;
因为有写时拷贝技术的存在,所以父子进程得以彻底分离!完成了进程独立性的技术保证!
写时拷贝,是一种延时申请技术,可以提高整机内存的使用率。
写时拷贝可以满足各种不同的写入场景
3 关于进程创建的实际应用场景
使用fork+写时拷贝技术,进行安全备份!!!
二 进程终止
进程终止本质就是系统中少了一个进程
1 进程终止的几种情况
代码运行完毕,结果正确
代码运行完毕,结果不正确
代码异常终止
前两种是正常情况,最后一种是异常情况
(1)怎么知道代码跑完了,结果正不正确?
我们先来引入一个概念:
cs
int main()
{
//.....
return 0;
}这里的return 值,有什么含义吗?
这里的return值,表示的是退出码,通常0表示成功
退出码是给谁的?为什么要有它?
1 退出码是给父进程bash或者自定义父进程的2 退出码是为了让父进程知道子进程任务完成的怎么样,因为0标识成功,非0标识失败
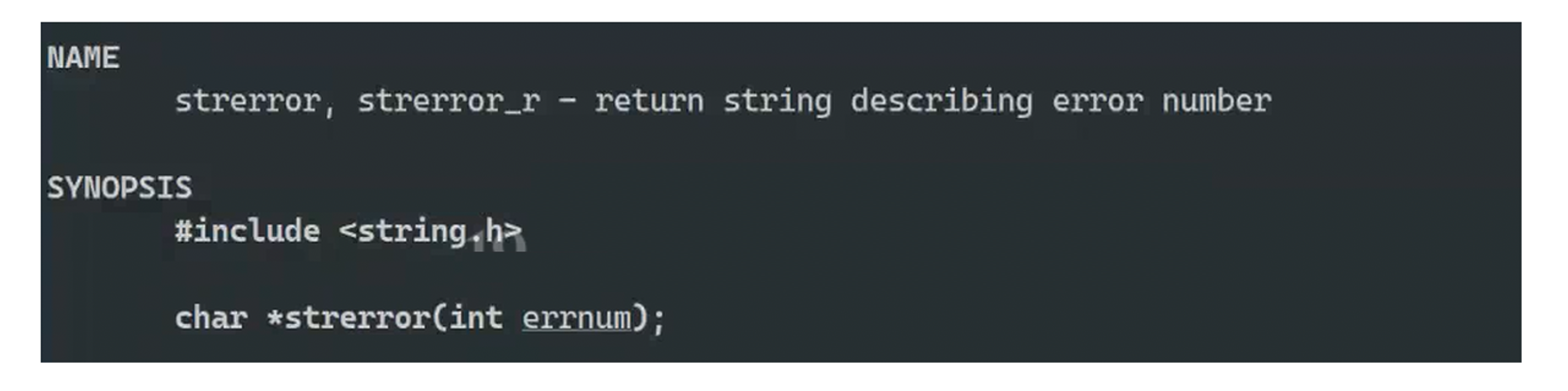
父进程要知道是什么原因失败的,1,2,3,4,5分别表示不同的失败原因。所以我们需要有一种机制,把0,1,2....转化成对应的描述,我们就可以用到strerror
strerror:把错误码转化成字符串
(2)代码没跑完,异常了,怎么去衡量异常?
直接输出一个结论:收到了信号,导致进程异常了
kill - l:1-31是普通信号,但是没有0号信号
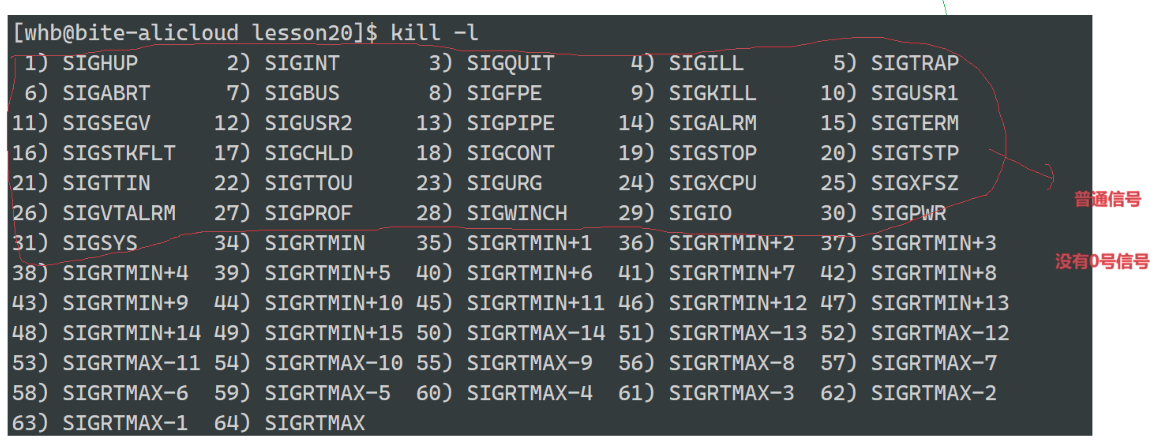
(3)结论
衡量一个进程运行结果是否 "可信",可以用两个数字来表示:
exit code(退出码)
signal number(信号编号)
这两个数字在 Linux/Unix 系统中,通常可以通过 waitpid() 等系统调用获取,对应变量如:
bash
long exit_state;
int exit_code, exit_signal;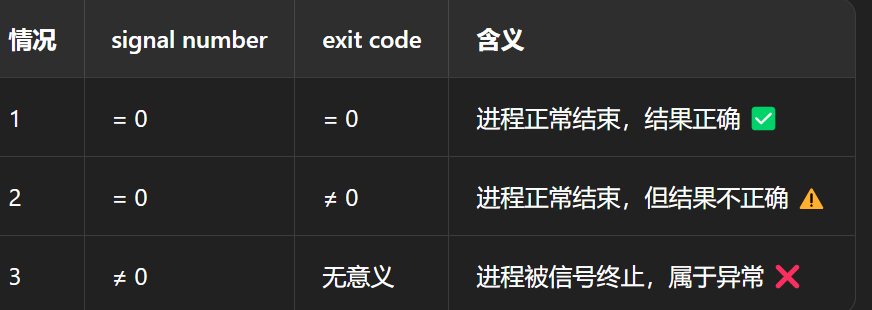
重要细节:
如果一个进程异常退出(被信号终止),那么它的退出码( exit code) 是无意义的,只有 signal number 才有参考价值。
进程退出的时候,会把自己的退出信息维护起来,僵尸状态。这俩个数字(exit code 和 signal number)会被维护在僵尸进程的PCB内部
2 进程常见的退出方法
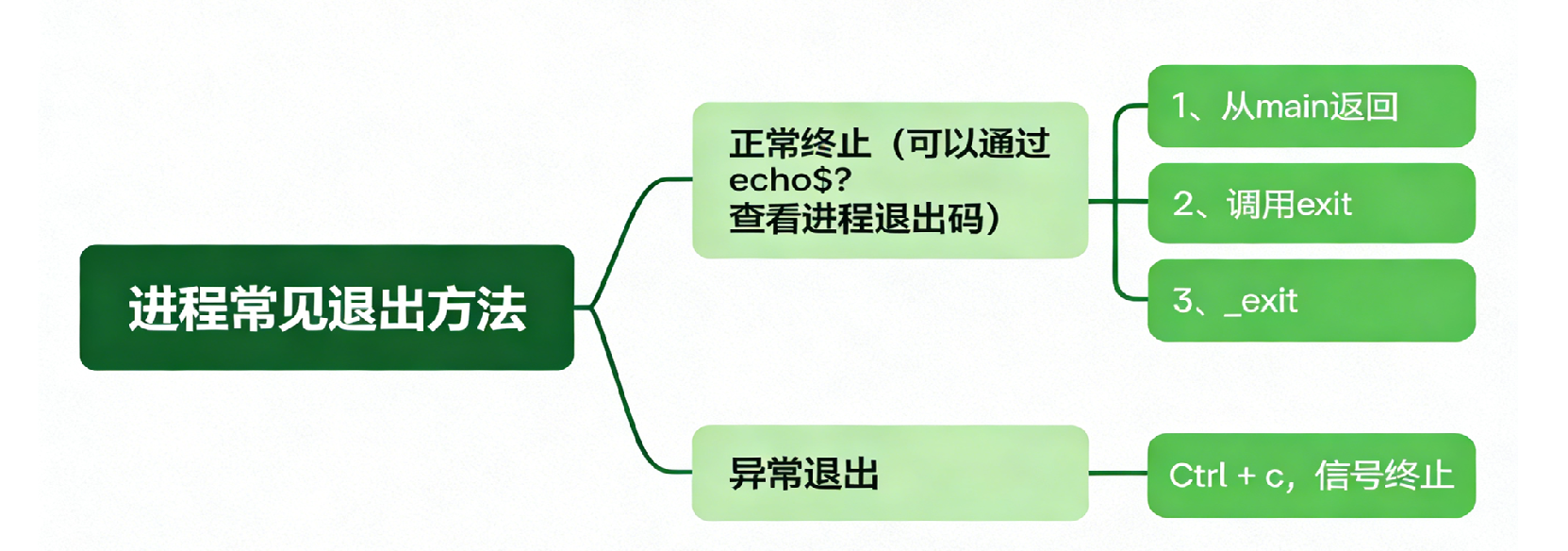
(1)echo $? 命令
在 Linux/Unix 系统中,每个命令或程序执行结束后,都会返回一个退出码 (0-255 之间的整数):
0:表示程序 / 命令执行成功
非 0:表示执行失败(不同的非 0 值对应不同的错误类型)
$? 是系统内置的环境变量,专门存储上一个执行的命令 / 程序的退出码
我们来看一下echo $?的使用场景:
bash
# 执行一个不存在的命令(故意制造失败)
ls non_exist_file
# 查看退出码
echo $?
# 输出:2 (表示文件不存在,不同错误对应不同非0值)(2)退出码
退出码是 Unix/Linux 系统中程序 / 命令执行完毕后返回给操作系统的一个整数(范围 0-255),本质是程序向调用者(如 Shell、其他程序)传递「执行结果」的标准化方式

退出码只有正确和·错误两种表示:
0 = 执行成功 (无任何错误);
1-255 = 执行失败(不同数值代表不同类型的错误,是行业通用约定,而非强制规则)
• 退出码0 表示命令执行无误,这是完成命令的理想状态。
• 退出码1 我们也可以将其解释为"不被允许的操作"。例如在没有sudo权限的情况下使用yum;再例如除以0等操作也会返回错误码1,对应的命令为let a=1/0。
• 130 (SIGINT或^C)和143 (SIGTERM)等终止信号是非常典型的,它们属于128+n信号,其中n代表终止码。
• 可以使用strerror函数来获取退出码对应的描述。
所以我们可以通过退出码判断程序是否正确退出,也可以在shell脚本中根据退出码进行逻辑判断
main函数返回值称为进程退出码
(3)_exit函数
bash
#include <unistd.h>
void _exit(int status);
参数:status 定义了进程的终⽌状态,⽗进程通过wait来获取该值说明:虽然status是int,但是仅有低8位可以被父进程所⽤。所以_exit(-1)时,在终端执⾏$?发现
返回值是255。
(4)exit函数
bash
#include <unistd.h>
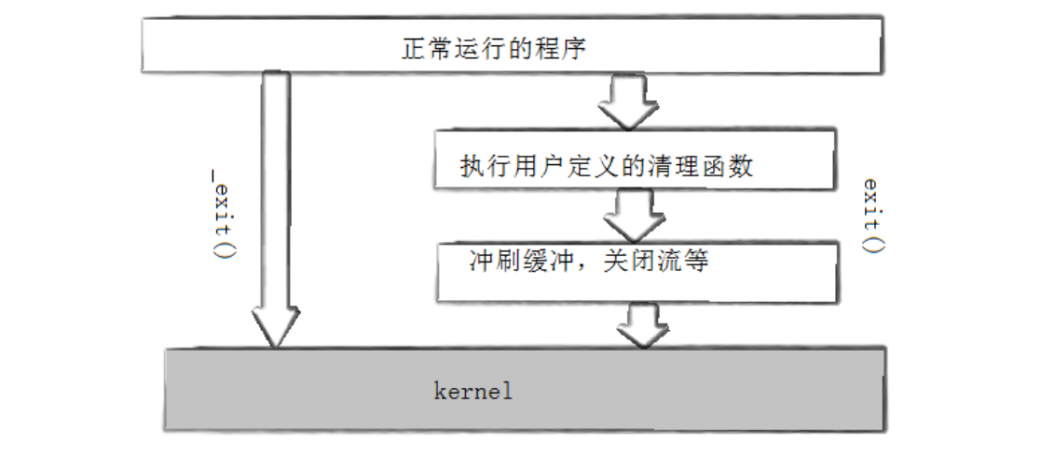
void exit(int status);exit最后也会调用_exit(底层是_exit()封装的),但在调用_exit之前,还做了其他工作:
- 执行用户通过atexit或on_exit定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入。
- 调用_exit。
实例:
bash
int main()
{
printf("hello");
exit(0);
}
运⾏结果:
[root@localhost linux]# ./a.out
hello[root@localhost linux]#
int main()
{
printf("hello");
_exit(0);
}
运⾏结果:
[root@localhost linux]# ./a.out
[root@localhost linux]# (5)exit和return有什么区别
return只有在main函数中才表示进程结束,exit在任意地方都表示进程结束
exit和_exit的头文件不同,且_exit是系统调用,但是exit是库函数
exit和_exit最大的区别:在进程结束的时候,一般会主动冲刷缓冲区,但是_exit不会冲刷缓冲区,它直接杀死进程
我们在这里埋一个种子:这个缓冲区应该由谁提供?---->一定不是操作系统提供的
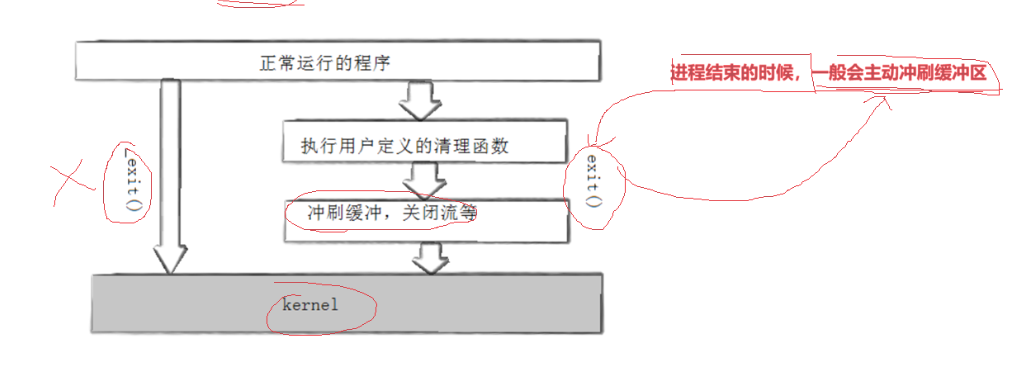
最佳实践用exit
库函数和系统调用是上下级的关系,其实exit在底层就调用了_eixt
所以进程属于操作系统内被管理对象,杀掉进程,就是释放进程内PCB和数据,但是不可能用户自己释放,要系统调用释放
(6)总结
