目录
一、Easi3R
1、概述
motivation:MonST3R,CUT3R,DAS3R等静态场景重建模型向动态场景扩展的工作,一般都需要额外的几何先验,进行训练。
contribution:依赖于DUSt3R模型(MonST3R),提出一种无需训练的4D重建适配方法Easi3R,可以在推理时适配,无需从零预训练或针对动态数据的微调。
Easi3R中发现,DUSt3R的交叉注意力图,天然编码了丰富的相机和物体运动信息,可以分界处纹理缺失,观测不足,相机运动,动态物体的信息。
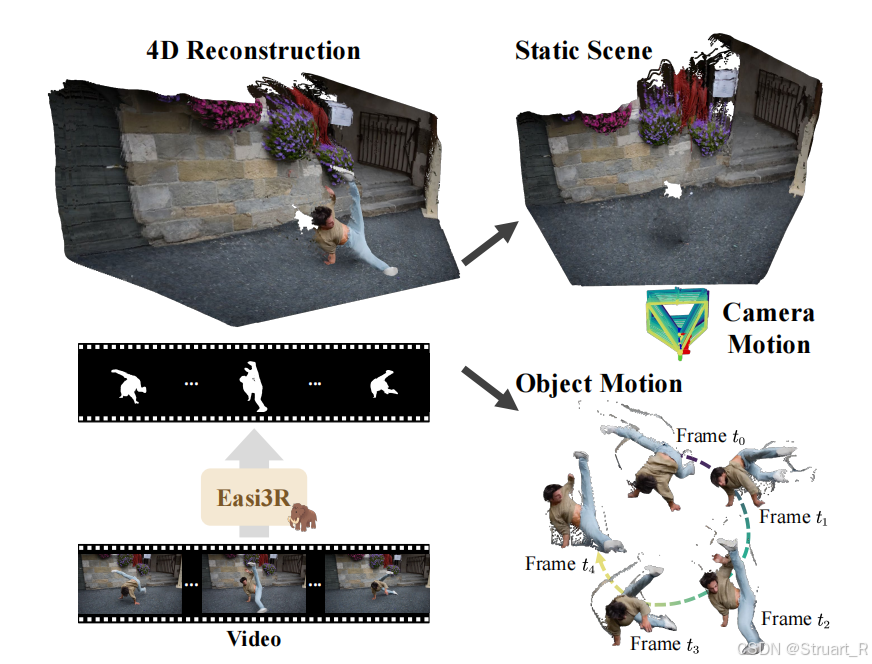
2、架构设计
首先Easi3R不是一个完整的架构,他是在DUSt3R上添加的一个免训练的模块。我们不需要重新训练DUSt3R的Encoder和Decoder。
(1)滑动窗口
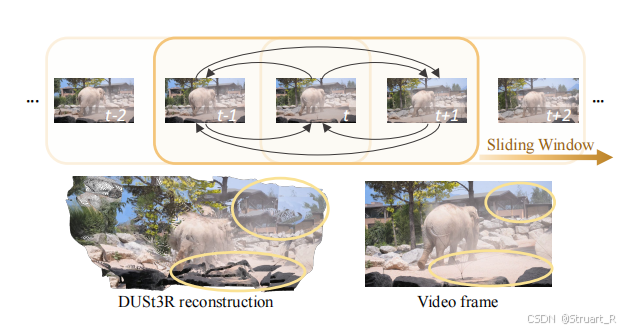
首先DUSt3R是每两帧进行图像对的特征匹配操作得到局部点云,然后再优化一个全局点云。但是这就导致并不能理解第一帧和第三帧之间的特征关系,只能最终通过loss来回归,本质上并没有提取相关的跳帧间特征关系。
Easi3R则提出一个滑动窗口,一般设置为2n-1,我们假设是3,那么每一个帧都对应一个滑动窗口,包含他的前一帧和后一帧,并且考虑所有的图像对关系,比如以第二帧为中心,那么就需要考虑三对。
(2)计算注意力权重
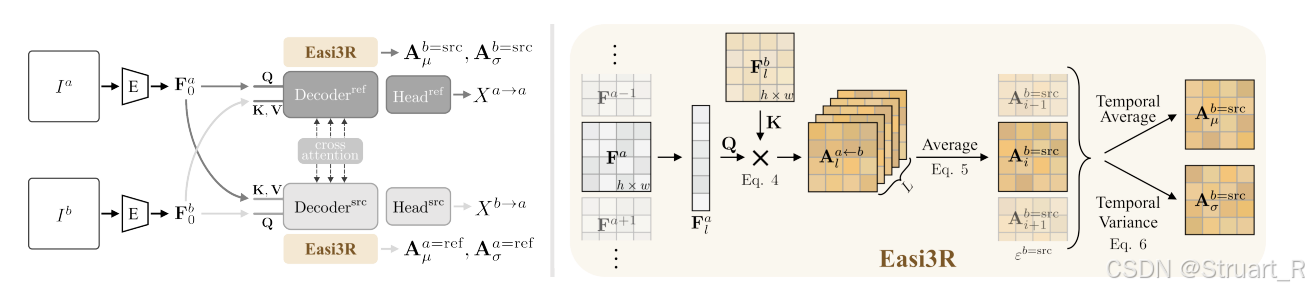
针对每一对图像对,我们都采用DUSt3R进行前向传播,这时一定能输出一组局部点云关系,也就是第一帧的在当前坐标系下的点云,第二帧在第一帧坐标系下的点云。
Easi3R的工作就是建立在两个解码器的每一层特征的基础上
具体来说,对于每个解码器会有L层,那么就有L层的中间特征,而此时把第一帧的l层特征作为查询,第二帧的l层特征作为K,V计算cross-attn,就得到第一帧l层的交叉注意力值,我们把L层的交叉注意力值计算平均值和方差就得到了
。对于第二帧我们则做相反的操作,得到
。
其实这一部分交叉注意力与DUSt3R是一模一样的,Easi3R就是在交叉注意力值进行了解耦。
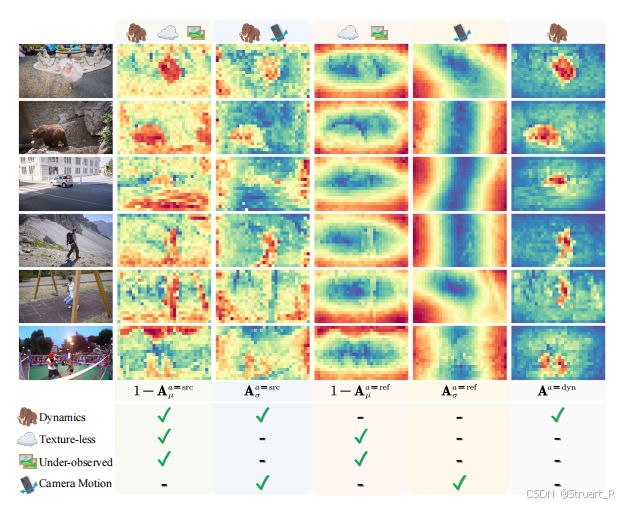
在论文中,深入分析了,
这四个变量都对应着视频里的哪些特征:因为最终特征信息都在第一帧的视角上,只不过融合了第二帧的信息。
:低均值区域。作为"源"时,如果某区域对"参考视图"的贡献一直很低,它可能是动态物体或纹理缺失区。
:高标准差区域。作为"源"时,如果某区域对"参考视图"的贡献随时间波动很大,说明它正在运动(无论是相机运动还是物体自运动)。
:高均值区域。作为"参考"时,某区域能稳定地接收来自各"源视图"的信息,说明它是可靠、纹理丰富的区域 。(过滤掉背景部分)
:低标准差区域。作为"参考"时,某区域接收信息的模式很稳定,说明它是不受运动影响的静态区域 。(过滤掉背景和相机移动部分)
动态物体区域定义为:
(3)取出动态mask部分
虽然现在我们得到了动态注意力部分,如果强行对这一部分权重赋值0,那么最终的点云就不会有动态物体部分,但是这也存在一个问题,没有考虑时间一致性,可能某一帧把人和头发都作为动态物体,而下一帧又没有把头发纳入动态物体,导致最终的静态点云出现伪影。
所以这里先对视频中所有帧的视觉编码tokens都放在一个池子里,计算k-means,把相似的像素分配一个聚类标签,这样从语义角度就稳住了时间一致性。之后计算该聚类的所有像素的动态注意力值的平均值,得到唯一的,代表该聚类动态程度的分数
,并且对每一帧每一个像素的
都用
替换。
最终利用otsu阈值法,计算一个动态权重与静态权重的阈值(前景与背景),即每一帧的动态物体分割区域为:
(4)4D重建
首先我们对动态物体分割区域的注意力权重赋值0,其他区域计算softmax并依赖传统的局部点云到全局点云的估计算法(估计一个scale和变换矩阵),估计全局点云(无动态区域),以及每一帧的相机位姿。这一部分的估计算法,我们只考虑静态区域,不考虑动态区域。
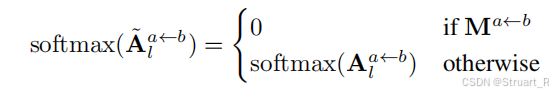
最后我们再利用最初的DUSt3R,此时我们只保留mask区域,那么输出的就是每一帧动态部分的局部点云以及错误姿态,所以我们依赖全局统一的该帧的相机位姿,来校准局部点云,这样得到了全局坐标系下的动态区域的点云信息。
先扣除动态部分,建立静态部分的重建,是防止动态部分影响静态部分重建以及相机姿态估计"
二、VGGT4D
1、概述
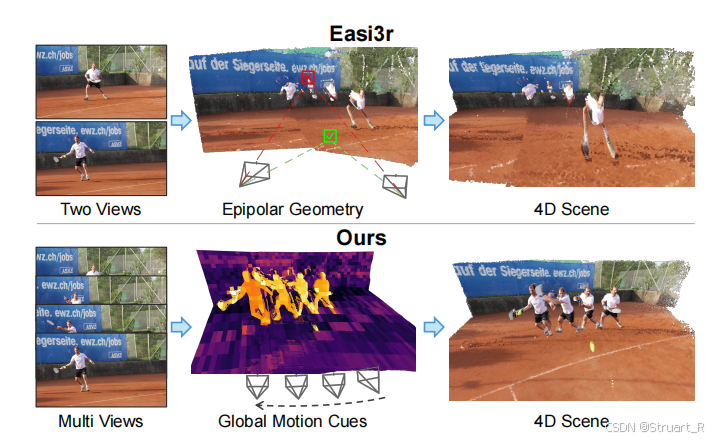
motivation:对比Easi3R工作,它无需训练,通过分析DUSt3R解码器注意力的时空统计来分割动态掩码。然而,Easi3R建立在成对交叉注意力架构 上,这使其只能捕捉局部特征交互,导致时间视野短,生成的掩码在帧间不一致,并且在动态-静态边界处存在错误,进而导致重建点云中的深度漂移和浮动伪影。此外,其核心假设(违反极线几何的token会获得低注意力)并不适用于采用全局注意力聚合多视图信号的VGGT。
contribution:提出了一种无需额外训练的方法,通过挖掘VGGT全局注意力中潜在的动态线索,赋予这个3D基础模型以4D场景理解能力。
VGGT4D的解耦方法是:通过聚合VGGT注意力中的Gram相似性统计量 来提取动态显著性信号,并引入了一种基于投影梯度感知的细化策略,以锐化掩码边界,获得能够稳定4D重建的精确动态掩码。
2、架构设计
这个架构设计是将VGGT的全局注意力配合了Easi3R的动态部分提取技术。
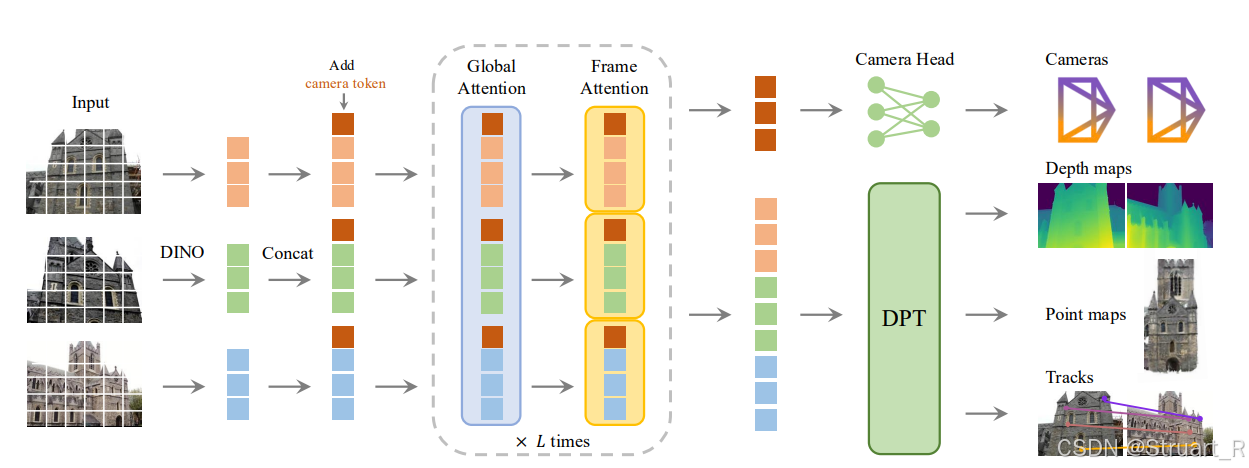
先讲述架构的设计,下图为VGGT结构。
输入一组图片,每一帧都经过DINO,得到编码后的token,并添加可学习的camera tokens,之后把所有的tokens拼接,输入到global attention中,再拆分为每一个帧,输入到Frame attn中,经过L层重复的操作,输出tokens,并经过四个不同的解码头,得到位姿,深度图,点云和track信息。
VGGT4D的操作,则是对Global attention部分的QKV进行了动态特征提取,通过加权得到了动态掩码信息。
(1)滑动窗口
这一部分与Easi3R相同,这里我们设置滑动窗口为-6, -4, -2, 2, 4, 6,提取每一层attn层的QK信息。比如说当前ref_id是10,那么源帧就是4,6,8,12,14,16帧,stride=2,保证大跨度。
(2)动态注意力权重计算
首先VGGT中定义一共24层attn层,也就是交替执行global attn和frame attn一共12次,VGGT4D规定,attn的0-1, 3-8, 17-22层为浅层区,中层区,深层区,要把每一个区看做一个整体,也就是最终会得到三个权重。
先考虑当参考帧为帧,源帧为
,层级为
的情况(比如参考帧为10,源帧为集合中任意一个,比如4),我们需要计算三个值:
- Q向量gram矩阵:
- K向量gram矩阵:
- QK标准注意力矩阵:
然后我们扩展到指定的0-1, 3-8, 17-22层都去计算这三个矩阵,之后对于同一个区的计算平均值,此时对于指定的参考帧为帧,源帧为
情况下,应该只有九个矩阵(浅层、中层、深层各三个)。
接下来扩展到滑动窗口上,对于参考帧为帧情况,应该有6个源帧,一共54个矩阵。对浅层区,我们对6组数据的QK矩阵计算方差,对Kgram矩阵计算均值,得到
对中层区则只计算,深层区计算
最后计算三个权重:

并计算动态注意力权重Dyn:
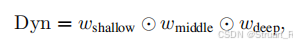
此时对于每一张图片都会相应得到一个动态注意力权重Dyn,然后利用otsu阈值法计算自适应,该帧的动态区域掩码就为
。
(3)掩码优化
这一步与Easi3R也相似,因为缺乏空间一致性,但是他没有用DINOv2得到的语义特征来聚类,而是用基于3D点云的空间位置(几何位置)聚类,所以我们也就是考虑每一个3D点是不是属于动态部分。
首先他计算投影深度与观测深度的差 ,即深度残差。
投影深度:VGGT生成的全局点云(第一次前向传播,存在动态场景偏差)根据第i帧的相机位姿投影得到的z坐标,深度信息d_i
观测深度:VGGT对第i帧直接预测的深度信息D_i(u_i, v_i)
之后计算投影损失 ,并计算它的梯度,作为深度残差进行加权,得到加权梯度
,这种操作放大了那些同时具有大残差和大梯度的点的信号(即高置信度的动态点),而抑制了那些可能梯度大但残差小(或反之)的边界情况,梯度信号能在噪声背景下更清晰地凸显出真正的动态物体。
聚合后深度差:
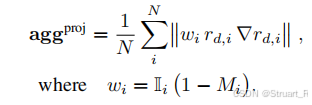
由于在纹理缺失区域(例如平坦的白墙、均匀色的地板),深度图 的梯度
信息量很少(近乎为零)。这使得公式中依赖深度图梯度的
计算变得不可靠或无信息量,导致几何检验失效。
引入光度残差 ,由于颜色(外观)信息在很多情况下与纹理无关。即使是在无纹理区域,动态物体 (如一个穿鲜艳衣服的人)的颜色与静态背景 (如白墙)的颜色通常也存在显著差异。因此,一个动态点投影到静态背景上时,会产生巨大的颜色差异 。
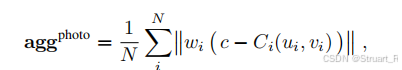
最后把这两者合并作为每一个点对应的动态值,如果超出阈值,那么属于动态部分。
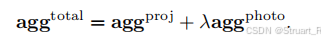
(4)4D重建
我们查询每一个点是否属于动态部分,对于动态点,我们要根据每一帧的位姿,映射到对应的帧上,并构成动态区域掩码,这样可以在第二次VGGT工作中mask掉这部分信息,从而生成没有动态信息的静态场景重建,此时的点云和每一帧的位姿就更干净了。
最后在对动态部分生成单独的点云信息,并且基于当前正确的位姿信息还原,得到4D重建场景。
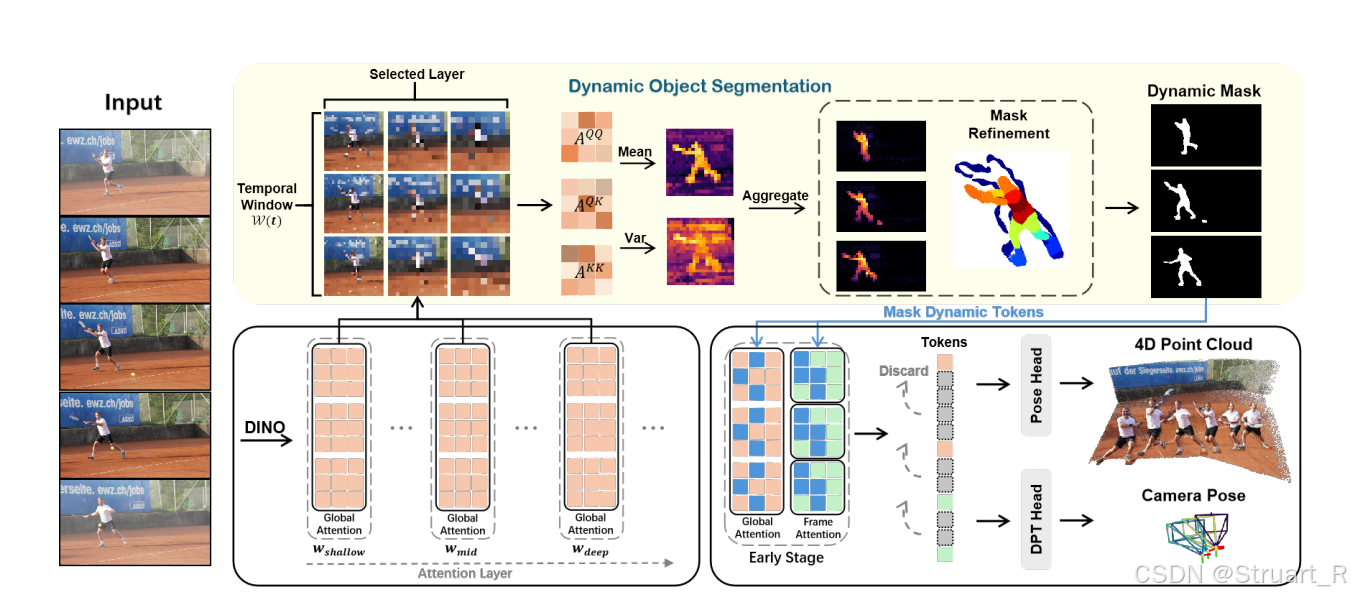
现在有一个重要的问题,动态注意力权重中QQ,QK,KK到底对应着什么?解释可能不太清楚,但更有可能是通过可视化发现的。
(1)K向量:倾向于编码更"本体 "的、与物体自身语义属性强相关 的特征。因此,比较不同帧之间K向量的相似性(KK),能直接反映出"这两个地方是不是同一种东西"(例如,都是"人"这个类别),从而清晰地区分前景物体和背景。这就是为什么用KK的均值来捕捉语义显著性。
(2)V向量:其角色更偏向于"交互与匹配 "。在VGGT的全局注意力框架下,Q需要去"询问"所有帧的所有K。因此,Q的特征可能更早地融合了上下文信息,并对几何对应关系 更敏感。当物体运动时,其Q特征寻找匹配对象的过程会变得不稳定,这体现在QK(标准注意力)的方差上。所以
用
来在已定位的前景中放大运动信号。
(3)中层:经过多次"帧内聚合-全局交互"的交替,Q向量已经充分融合了多视图信息。此时,一个静态点的Q特征应在不同帧间保持高度一致(因为它描述的是同一个3D点),而动态点的Q特征则会出现分裂。因此,QQ的相似性直接、纯粹地衡量了这种"跨帧特征一致性",使其成为检测运动不稳定性()的完美指标。K向量此时可能已更深地融入背景语义中,对运动不那么敏感。
(4)深层:Q向量承载的已经是高度提炼的、用于最终几何推理的表示。其QQ相似性的统计特性(高均值、低方差)自然成为了可靠3D点的空间先验,用于来抑制噪声。
三、4DVGGT
1、概述
motivation:现有的3D几何基础模型(如VGGT、π3)在静态场景的几何估计(如姿态、深度估计)上取得了巨大成功。然而,动态场景的几何估计需要同时建模空间和时间特征,这超出了纯3D模型的能力范围。当前的一些4D方法试图将时间线索嵌入到空间特征中,在统一的潜在空间中进行建模。但由于空间特征(不同视角间的结构一致性)和时间特征(相邻时间步间的运动连续性)存在本质上的异质性,这种统一范式容易导致特征表示不匹配,进而使模型在动态场景中产生不稳定、不可靠的几何知识。因此,需要一种新的"分而治之"的时空表示方法。
contribution:
(1)4DVGGT模型,支持多设置输入、多层次表示和多任务预测的统一框架,为动态场景的建模提供了新范式。最离谱的是,他能直接输出动态分割物体?暂时没有代码
(2)设计了自适应视觉网格,使模型能够处理任意数量视图和任意时间步长的视觉输入,提高了模型的通用性
(3)除了VGGT中引入的可学习的view tokens外,又添加了time tokens,用于建模相邻时间步之间的时间表示。
2、架构
(1)输入
定义了一个自适应视觉网格,以适应双目,甚至多目视频。如果是单目视频,那么数据经过DINO后,添加一致的view token,和随时间变化的time tokens。如果是多目视频,那么数据经过DINO后,会生成依赖当前相机ID的view token,和随时间变化的time tokens。
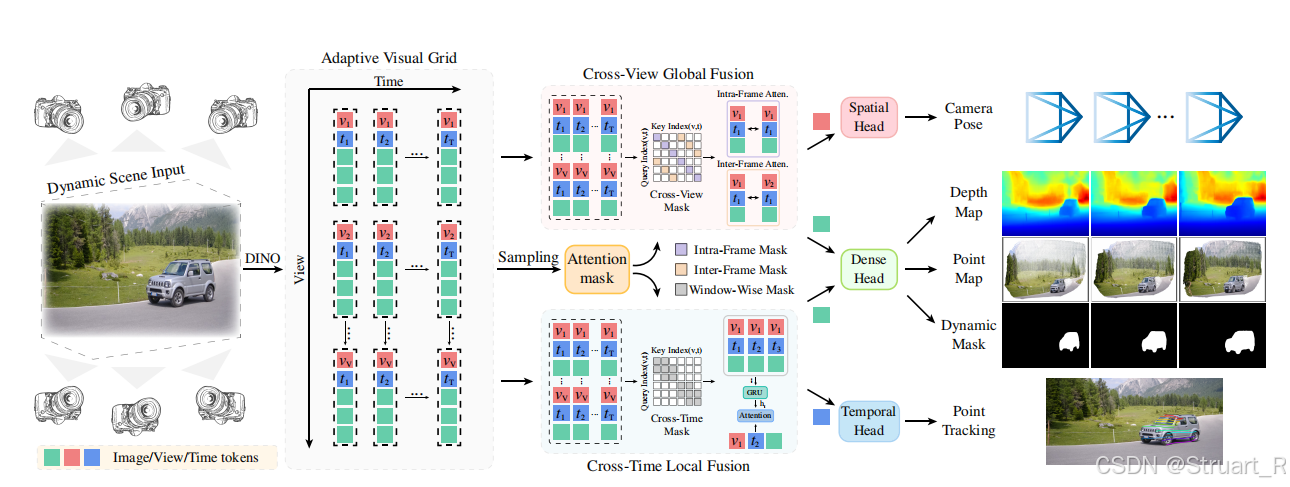
(2)双模块注意力融合
**Cross-View Global Fusion (CVGF) 模块:**包含intra-frame attention(帧内注意力)和inter-frame attention(帧间注意力),层数为16。使用cross-view mask方法
注意力掩码规则 :该模块的注意力掩码规定,**只允许同一时间步内的token之间进行交互。**允许在同一个时间步t上,不同视图(v不同)的token之间可以互相注意力。
帧内注意力:让一个视图内部的token相互关注,以强化该单帧图像自身的特征表示,聚焦于关键区域。
帧间注意力:让不同视图的token之间进行交叉注意力,这是该模块的核心。通过这种跨视图的注意力,模型能够建立不同视角下同一场景点之间的对应关系,从而推理出场景的3D几何结构。
经过重复的注意力机制后输出特征.
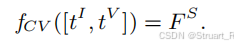
Cross-Time Local Fusion (CTLF) 模块:
注意力机制:只允许同一视图(即同一个view token)内,一个局部时间窗口中的token之间进行交互 。视角token仅用于标识,不参与计算。
窗口大小:默认的滑动窗口大小 S = 5,这意味着在某个时间点 t,模型只关注以其为中心的附近几帧(如前2帧、后2帧)。
架构结合了GPU编码上下文,对于某个特定视图,在一个以时间步 t为中心、大小为 S的滑动窗口内,窗口中的所有token会先顺序输入一个GRU。GRU的循环特性使其能够融合窗口内的历史信息,输出一个蕴含了该短时序上下文的隐藏状态 。
以中心时刻 t的token作为查询,以上一步GRU输出的隐藏状态作为键和值,进行自注意力计算。这样,中心帧的查询就能够基于其邻近帧的融合上下文来更新自己的表示,从而捕获连贯的运动模式。
此窗口沿时间轴滑动,处理完该视图的所有时间步。处理完所有视图的所有时间步后,模块输出最终的时间特征
(3)预测
深度、点云、动态mask预测:
模型首先通过一个DPT模块 ,将这两个特征 和
(的Image tokens)转换成一个密集的、像素对齐的特征图
。这使得后续的预测可以在图像的原生分辨率上进行。
对于不同的模态预测,需要不同的MLP来预测。
camera pose预测:
只需要中提取view tokens部分,用MLP进行预测
track预测:
只需要中提取time tokens部分,用MLP进行预测
(4)损失函数:
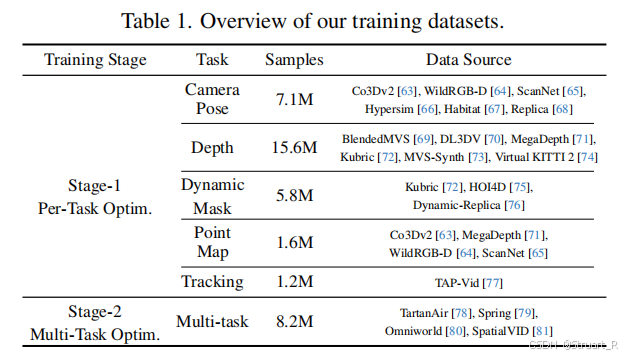
可以利用不同的数据集,可能只有深度,或者只有track也可以训练,损失包含这五个预测头的损失。
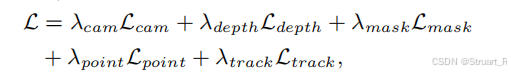
相机损失(huber loss):
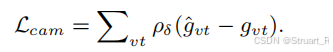
深度损失(L2 loss + L2 gradient loss):
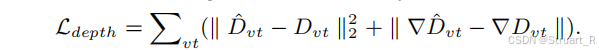
分割损失(二元交叉熵)
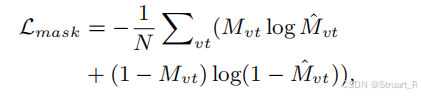
点云损失(L2 loss + L2 gradient loss)
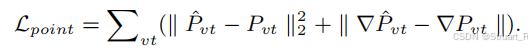
跟踪损失(2D+3D CD loss)
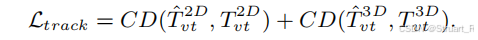
3、数据集
参考文献:
https://arxiv.org/abs/2503.24391