目录
[1. 【模板】一维前缀和](#1. 【模板】一维前缀和)
[2. 【模板】二维前缀和](#2. 【模板】二维前缀和)
[例题2:和为 K 的子数组](#例题2:和为 K 的子数组)
一、什么是前缀和?
关于前缀和的算法,简单来说,它的核心思想就是预处理 。在进行了预处理之后,我们就可以在暴力枚举的过程中快速 得到查询的结果,这里的快速比起只是直接暴力枚举的算法的优化是极大了,而具体的优化方法一般都是使用以空间换时间的方法。
以空间换时间 :通常是通过开辟新的数组来实现预处理操作。
那么前缀和的算法通过预处理的优化后,查询的过程到底有多快呢?我们可以通过以下的模板例题来实际体验一下。
二、典型模板例题
关于前缀和,我们可以分为:一维前缀和和二维前缀和。
1. 【模板】一维前缀和
题目链接:【模板】前缀和_牛客题霸_牛客网
如图所示:
题目的意思就是让我们输入一个数组,然后进行m次询问,每次询问都会输入 l 和 r 即一个区间: l , r ,要求求出在原数组中这段区间中的所有元素和。
题目解答思路:
当我们第一次看到这个题,我们首先会想到直接暴力枚举的做法:每次输入 l 和 r 的时候都遍历一下这段区间的元素进行相加。但是这种方法是会超时的(因为这样做的最大时间复杂度就是O(m*n)了,由于m和n的最大值都是10的5次方,所以一定会超时)。
因此我们就可以使用前缀和这种方法:通过预处理来优化。前缀和的方法就是专门用来解决这种邱某一区间和的问题的。具体做法如下所示:
步骤1:预处理出一个前缀和数组dp。
通过预处理建立一个前缀和数组 dp,这里的dp数组的规模是和原数组一模一样的。
在dp数组中,每一个元素 dp i 表示的是原数组中区间 1, i 的所有元素的和 。
求出dp数组的推到公式是:dp i = dp i - 1 + arr i ; ,即通过这个公式,我们遍历一遍原数组arr就可以得到dp数组了(时间复杂度是O(n))。
步骤2:使用这个前缀和数组 dp。
有了这个dp数组,那么当我们求原数组区间 l, r 的和的时候就可以直接通过dp数组来得到了,具体做法如下:
如果我们要求原数组区间 l, r 的和,则我们就可以直接通过 dp r - dp l - 1 来直接得到结果,如图所示:
在这张图中,我们可以发现,如果我们要求原数组区间 l, r 的元素之和,则就可以看作是原数组区间 1, r 的元素之和减去区间 1, l - 1 的元素之和,即 dp r - dp l - 1 。
所以,当我们查询区间 l, r 的元素之和时,通过 dp r - dp l - 1 就可以直接得到结果了。查询一次,通过这个关系,时间复杂度O(1)就可以解决一次询问了,m次询问就是O(m)的时间复杂度了。
注意:我们上述使用的所有数组的下标都是从1 开始的,这样是为了方面处理边界情况,如果我们的下标是从0开始的话,那么当我们求原数组中下标区间为 0, 2 的时候,我们就会执行dp2-dp-1了,出现数组越界。所以我们在初始化数组的时候一般都是以下标从1开始设置的。
所以我们的代码实现(C++实现)如下所示:
cpp
#include <iostream>
#include <vector>
using namespace std;
int main()
{
// 1.输入数据
int n, m; // 元素数量 查询次数
cin >> n >> m;
vector<int> arr(n + 1);
for(int i = 1; i <= n; i++)
{
cin >> arr[i];
}
// 2.预处理出一个前缀和数组
vector<long long> dp(n + 1);
for(int i = 1; i <= n; i++)
{
dp[i] = dp[i - 1] + arr[i];
}
// 3.使用前缀和数组进行m次查询
int l = 0, r = 0;
while (m--)
{
cin >> l >> r;
cout << dp[r] - dp[l - 1] << endl;
}
return 0;
}综上,通过前缀和算法的时间复杂度就是O(n+m),相比与暴力枚举的O(n*m),效率确实是大大提高了。
2. 【模板】二维前缀和
题目链接:【模板】二维前缀和_牛客题霸_牛客网
如图所示: 简单来说,这个题目的意思就是让我们输入一个二维数组,然后进行q次查询,每次查询都会输入两个坐标(x1,y1)和(x2,y2),我们需要输出在原二维数组中以(x1,y1)为左上角,以(x2,y2)为右下角的一个矩阵中的所有元素之和。
简单来说,这个题目的意思就是让我们输入一个二维数组,然后进行q次查询,每次查询都会输入两个坐标(x1,y1)和(x2,y2),我们需要输出在原二维数组中以(x1,y1)为左上角,以(x2,y2)为右下角的一个矩阵中的所有元素之和。
题目解答思路:
解法1:我们直接使用暴力枚举的做法,每次都通过两层for循环求出对应矩阵的元素之和来获得结果,和上面的一维数组一样,这种方法也是会超时的,这里的最大时间复杂度是O(n*m*q)。
解法2:使用前缀和的方法来解决。
步骤1:预处理出一个前缀和数组dp。
数组dp的规模和原数组arr的规模也是一样的(数组下标都是从1开始设置的)。
在dp数组中,每一个元素 dp i j 表示的是原数组中以坐标 ( 1, 1 ) 为左上角,以 ( i, j ) 为左下角的矩阵中所有元素之和 。那么我们该如何求出这个dp数组呢?如图所示:
那么如果我们要求元素 dp i j ,那就是A,B,C,D这4个区域的所有元素之和,而A又可以看做是以(1,1)为左上角,以(i,j)为右下角的矩阵中所有元素之和,通过dp表示就是 dp i - 1 j - 1 ;同理A+B的矩阵就是dp i - 1 j ;A+C的矩阵就是dp i j - 1 ;D就是arr i j 。所以可以得到如下递推公式:
通过这个公式,我们遍历一遍原二维数组arr就可以得到dp数组(时间复杂度是O(n*m))。
步骤2:使用这个二维的前缀和数组(矩阵) dp。
有了dp这个矩阵,我们想要算以(x1,y1)为左上角,以(x2,y2)为右下角的一个矩阵中的所有元素之和就可以这样算:通过(x1,y1)和(x2,y2)我们可以将原数组arr划分为4部分,如图所示:
此时我们要求的就是D部分的矩阵中所有元素之和。而A+B+C+D就表示以(1,1)为左上角,以(x2, y2)为右下角的矩阵中所有元素之和,即dpx2y2;同理,A+B表示dpx1-1y2;A+C表示dpx2y1-1;A表示dpx1-1y1-1。所以D就可以表示为如下图所示的递推公式:
所以当我们知道了左上角和右下角的坐标之后,就可以使用前缀和数组dp来通过上图所示的公式直接求出对应的结果了。q次询问,则时间复杂度就是O(q)。
所以我们的代码实现(C++实现)如下所示:
cpp
#include <iostream>
#include <vector>
using namespace std;
int main()
{
// 1.输入数据
int n, m, q; // n行m列,q次查询
cin >> n >> m >> q;
vector<vector<int>> arr(n + 1, vector<int>(m + 1));
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= m; j++)
{
cin >> arr[i][j];
}
}
// 2.预处理出前缀和数组(long long存储防止溢出)
vector<vector<long long>> dp(n + 1, vector<long long>(m + 1));
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= m; j++)
{
// 二维前缀和矩阵递推公式
dp[i][j] = dp[i - 1][j] + dp[i][j - 1] + arr[i][j] - dp[i - 1][j - 1];
}
}
// 3.使用前缀和数组
int x1, y1, x2, y2;
while (q--)
{
cin >> x1 >> y1 >> x2 >> y2;
long long ret = dp[x2][y2] - dp[x1 -1][y2] - dp[x2][y1 -1] + dp[x1 - 1][y1 - 1];
cout << ret << endl;
}
return 0;
}综上,二维前缀和的时间复杂度就是O(n*m+q)。
简单总结一下:
上述两种关于一维和二维的前缀和算法解析,我们可以明显感受到前缀和算法相比于最直接暴力枚举的时间效率的提升。
同时我们也可以认识到:一般前缀和算法的本质就是以空间换时间的做法:开辟了一个与原数组相同规模的数组来进行预处理操作,然后再使用这个前缀和数组来获取结果。
而使用前缀和算法的关键就是找到预处理的方法(递推公式)和获取结果的方法(递推公式)。
三、前缀和的经典例题
接下来,我们讲解几个比较经典的使用了前缀和思想解决的问题。
例题1:寻找数组的中心下标
题目链接:724. 寻找数组的中心下标 - 力扣(LeetCode)
题目描述如图所示: 这道题的意思就是在给定的数组中找到一个能够使左右两边元素之和相同的一个元素下标,比如有a0,a1,a2,a3,......,an,如果有一个下标 t ,能够使 a0,...,a(t-1) 中元素之和与 a(t+1),...,an 中元素之和相同,我们就需要找到这个t,注意这道题的数组下标都是从0开始的,并且如果能够满足这种情况的下标有多个,最终答案取的是最左边的一个。
这道题的意思就是在给定的数组中找到一个能够使左右两边元素之和相同的一个元素下标,比如有a0,a1,a2,a3,......,an,如果有一个下标 t ,能够使 a0,...,a(t-1) 中元素之和与 a(t+1),...,an 中元素之和相同,我们就需要找到这个t,注意这道题的数组下标都是从0开始的,并且如果能够满足这种情况的下标有多个,最终答案取的是最左边的一个。
解决方法:
当然,我们可以直接使用暴力解法,即从左向右遍历每一个下标,每次都求出该下标之前的元素和与之后的元素和,进行判断是否相同。时间复杂度是O(n^2),虽然这道题可以通过,但我们使用前缀和的思想来解决更优。
使用前缀和的思想来解决,这里我们有两种方法:
- 方法1:使用两个数组:一个前缀和数组 f 和一个后缀和数组 g 。
- 方法2:只使用一个前缀和数组 dp 。
方法1:使用两个数组:一个前缀和数组 f 和一个后缀和数组 g 。
在前缀和数组 f 中,f i 表示的是原数组中 0, i - 1 区间中的所有元素之和;而在后缀和数组 g 中,g i 表示的是原数组中 i + 1, n - 1 区间中的所有元素之和。然后我们通过比较 f i 和 g i 就可以表示 i 之前的区间和 i 之后的区间中的元素和是否相同了。如图所示:
第一步,进行预处理,我们可以通过递推公式 f i = f i - 1 + nums i + 1 求出 f 数组,但是注意边界情况 i=0 时,f0 表示的是0必须的左边的元素之和(不包含nums0),即f0需要处理为0;同理我们也可以通过递推公式 g i = g i + 1 + nums i + 1 来求出g数组。也要助理边界情况 i = n-1的时候,gn -1表示的也是最后一个元素的右边元素之和,即 g n - 1 也需要处理成0。
第二步,使用这两个数组。通过比较 f i 和 g i 是否相等就可以得到最有的下标,并且从左向右遍历,第一次找到的下标就是最左边的下标。

代码实现如下所示:
cpp
class Solution {
public:
int pivotIndex(vector<int>& nums)
{
//1.预处理数组f和g
int n = nums.size();
vector<int> f(n),g(n);
f[0] = g[n - 1] = 0; // 处理越界情况
for(int i = 1; i < n; i++)
{
f[i] = f[i - 1] + nums[i - 1]; // f[i]表示[0,i-1]区间元素的和(前缀和)
}
for(int i = n - 2; i >= 0; i--)
{
g[i] = g[i + 1] + nums[i + 1]; // g[i]表示[i+1,n-1]区间元素的和(后缀和)
}
// 2.使用f和g
for(int i = 0; i < n; i++)
{
if(f[i] == g[i])
{
return i;
}
}
return -1;
}
};方法2:只使用一个前缀和数组 dp 。
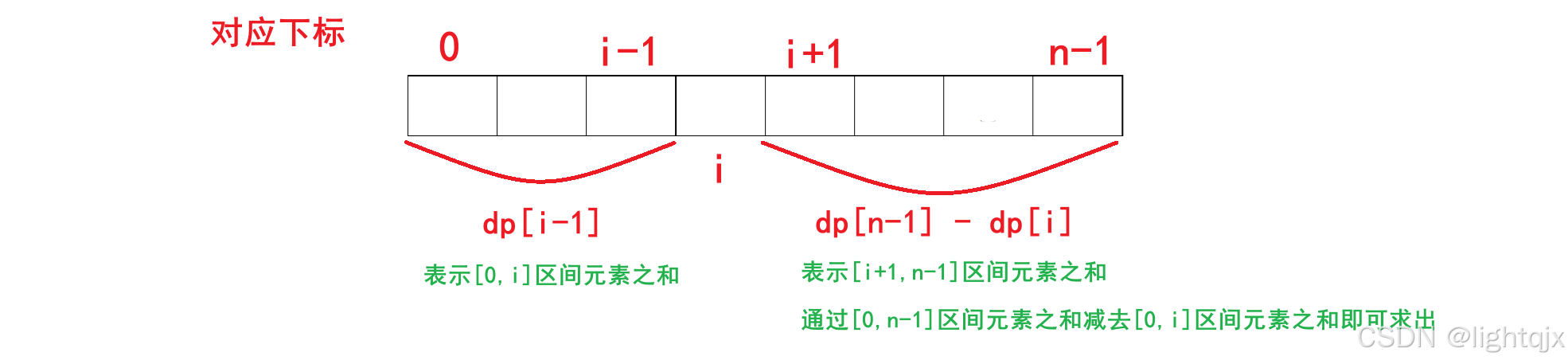
dp i 表示的就是原数组中 0, i 区间中所有元素之和。我们要判断前后元素之和是否线条,通过dp数组就可以计算出对应的结果了,如图所示:
第一步,预处理出前缀和数组dp。通过递推公式 dp i = dp i - 1 + nums i 即可求出,同时需要注意边界情况 i = 0 时,递推公式会越界,所以需要单独处理 dp 0 为 0。
第二步,使用这个前缀和数组dp。前区间表示为dp i - 1 ,后区间表示为 dp n - 1 - dp i ,然后判断这两个值是否其他即可。但是需要注意边界情况,当 i = 0 时,需要左区间需要单独处理为0,当 i = n -1 时,后区间需要单独处理为0。
所以对应的代码实现如下所示:
cpp
class Solution {
public:
int pivotIndex(vector<int>& nums)
{
//1.预处理前缀和数组
int n = nums.size();
vector<int> dp(n + 1);
for(int i = 0; i < n; i++)
{
if(i == 0)
dp[i] = nums[i];
else
dp[i] = dp[i - 1] + nums[i]; //dp[i]表示[0,i]区间元素之和
}
// 2.使用前缀和数组
int left = 0, right = 0;
for(int i = 0; i < n; i++)
{
// 处理越界情况
if(i == 0)
left = 0, right = dp[n - 1] - dp[i];
else if(i == n - 1)
left = dp[i - 1], right = 0;
else
left = dp[i - 1], right = dp[n - 1] - dp[i];
// 比较dp数组[0,i-1]和[i+1, n-1]区间的值
if(left == right)
return i;
}
return -1;
}
};例题2:和为 K 的子数组
题目链接:560. 和为 K 的子数组 - 力扣(LeetCode)
题目描述如图所示: 这个题目的意思就是让我们在一个数组中找一个和为k的连续非空序列。
这个题目的意思就是让我们在一个数组中找一个和为k的连续非空序列。
解决方法:
解法1:直接暴力求解:遍历这个数组,每次遍历都以当前位置向后遍历统计和为k的子数组(即每次考虑以 i 为开头的子数组)。最大时间复杂度是O(n^2)。
解法2:利用前缀和的思想来解决。除此之外这道题我们还需要使用到哈希表的知识。这道题可以算是比较复杂的了。
接下来我们来看看解决这道题的思想:
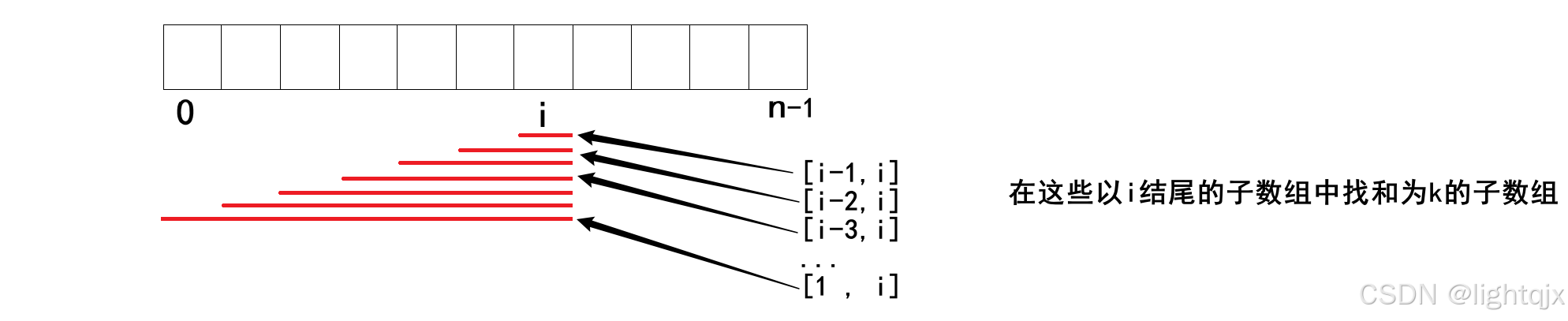
通过暴力解法,我们知道这道题,我们通过考虑以 i 为开头的子数组是解决不出来的。那么我们就考虑一下以 i 为结尾的子数组 ,即在从前向后遍历的过程中,每次都向前找和为k的子数组,如图所示:
但是,如果这样那么这和暴力解法的时间复杂度没有什么区别,所以这种方法还是不行,此时我们可以通过前缀和 将原题目转化一下,假设这里id前缀和数组为dp,dp i 表示 0, i 区间中的元素和,那么转化办法如图所示:
所以,整个问题就变成了遍历一遍原数组,每一次都在 0, i - 1 区间中去找一个前缀和为 dp i - k 的子数组,并统计个数。
那么接下来,我们就需要来看看如何快速的找到 0, i - 1 区间中去找一个前缀和为 dp i - k 的子数组的个数?对于这个问题我们可以使用哈希表来解决,使用 unordered_map<int,int> hash,其中存储的是 <前缀和,出现次数>,这样就可以快速知道在 0, i - 1 区间中前缀和为 dp i - k 的子数组的个数。
所以,我们整个题的解决思路就出来了:我们可以通过遍历一次就求出这个结果,而每遍历到一个位置,我们就可以直接通过哈希表直接得到前缀和为k对应子数组的个数,并统计。
到此,我们对这个题目就有了大体的解决方法了,但是要实现这个思路,我们还需要处理一下事项:
- 我们不用真的创建一个前缀和数组,可以使用一个变量sum来标记前一个位置的前缀和即可,因为我们前缀和的公式就是:dp i = dp i - 1 + nums i ,这里的dp i - 1 表示的就是前一个位置的前缀和。
- 前缀和加入哈希表的实机:我们需要保证:在计算 i 位置的前缀和之前,哈希表中只能保存了 0, i - 1 区间中的所有前缀和,因为如果直接保存了这个数组中前缀和为k的子数组个数,则在统计时会将 i 位置之后和为k的子数组也统计到,从而出错。
- 当 i 位置的前缀和就是 k 的时候,此时 sum - k 就是0,而寻找的区间 0, i - 1 就是 0 , -1 ,统计不到数组,但是由于此时的这个前缀和就是k,所以我们实际的个数其实是 1 ,因此需要将bash0设置为1。
具体的代码实现如下所示:
cpp
class Solution {
public:
int subarraySum(vector<int>& nums, int k)
{
int n = nums.size();
unordered_map<int,int> hash; // <前缀和,出现次数>
hash[0] = 1;
int sum = 0, ret = 0;
for(int i = 0; i < n; i++)
{
sum += nums[i]; // sum表示[1,i]区间的前缀和
// 求[1,i-1]中有多少个sum-k
if(hash.count(sum - k)) ret += hash[sum - k]; // 如果哈希表中存在sum-k,则说明存在和是k的子数组,需要统计
hash[sum]++; // 将前缀和加入哈希表
}
return ret;
}
};例题3:矩阵区域和
题目链接:1314. 矩阵区域和 - 力扣(LeetCode)
题目描述如图所示: 这道题的意思就是说,给定我们一个二维数组mat,和一个k值,让我们返回一个新的二维数组ans,要求ans的每一个元素ans i j 都是mat i j 周围k圈围成的元素之和。如图所示:
这道题的意思就是说,给定我们一个二维数组mat,和一个k值,让我们返回一个新的二维数组ans,要求ans的每一个元素ans i j 都是mat i j 周围k圈围成的元素之和。如图所示: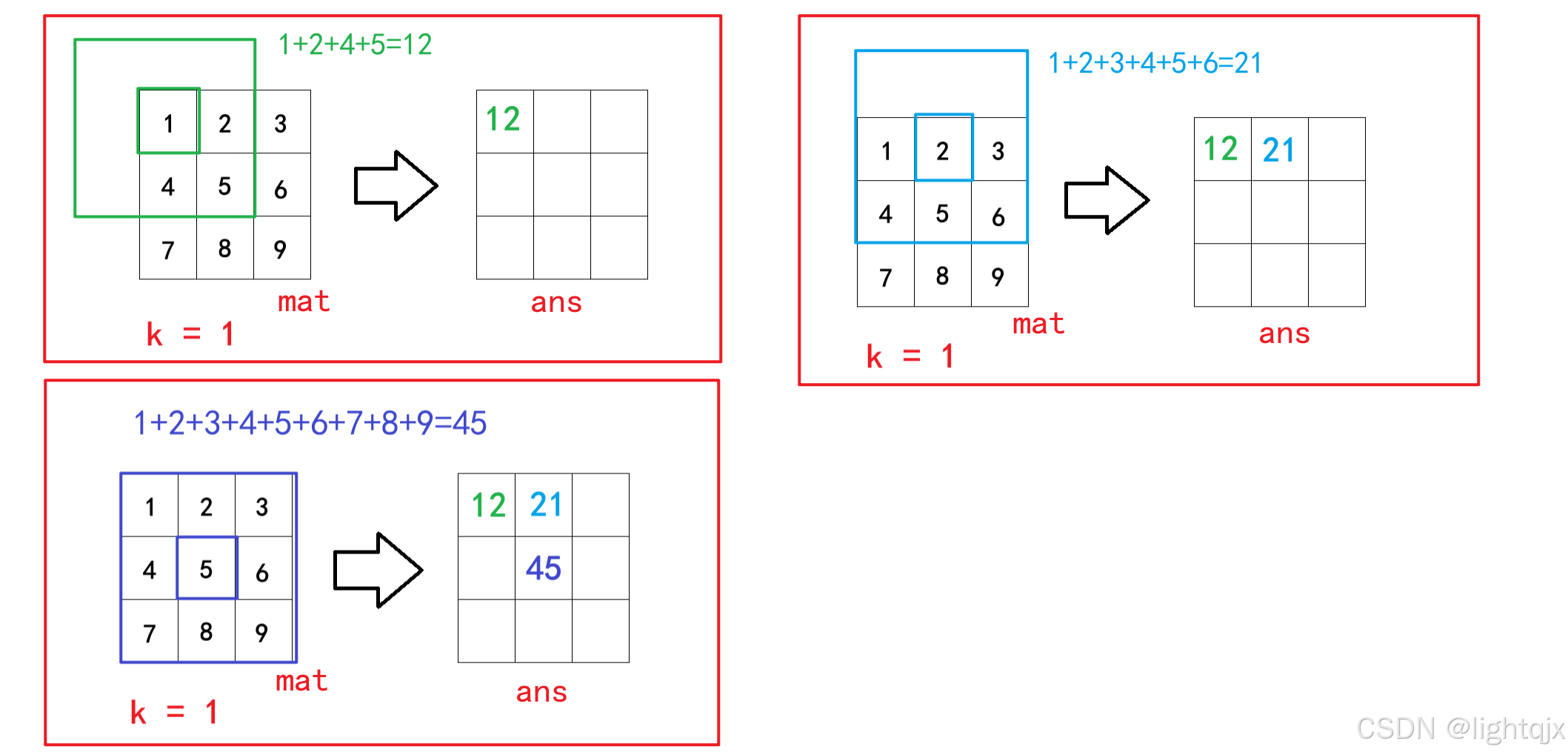 很明显,这道题就是二维前缀和的解决方法:
很明显,这道题就是二维前缀和的解决方法:
我们需要先找到需要相加的小矩阵的左上角坐标,和右下角坐标。然后套用二维前缀和的公式进行求解。
那么我们要如何求出对应下标呢?这很简单,如图所示:
这样可以找到左上角坐标,和右下角坐标。除此之外,关于下标我们还需要考虑一下细节:
- 在这个题目中,不论是mat还是ans,它们的下标都是从0开始的,而我们前缀和数组dp的下标一般都是从1开始的,因为如果从0开始,我们的dp前缀和数组需要考虑很多边界情况,所以我们的dp数组都是以1下标开始的。那么在使用前缀和数组和原数组进行一个映射关系:dp中的(x,y)在mat中就是(x-1,y-1)。
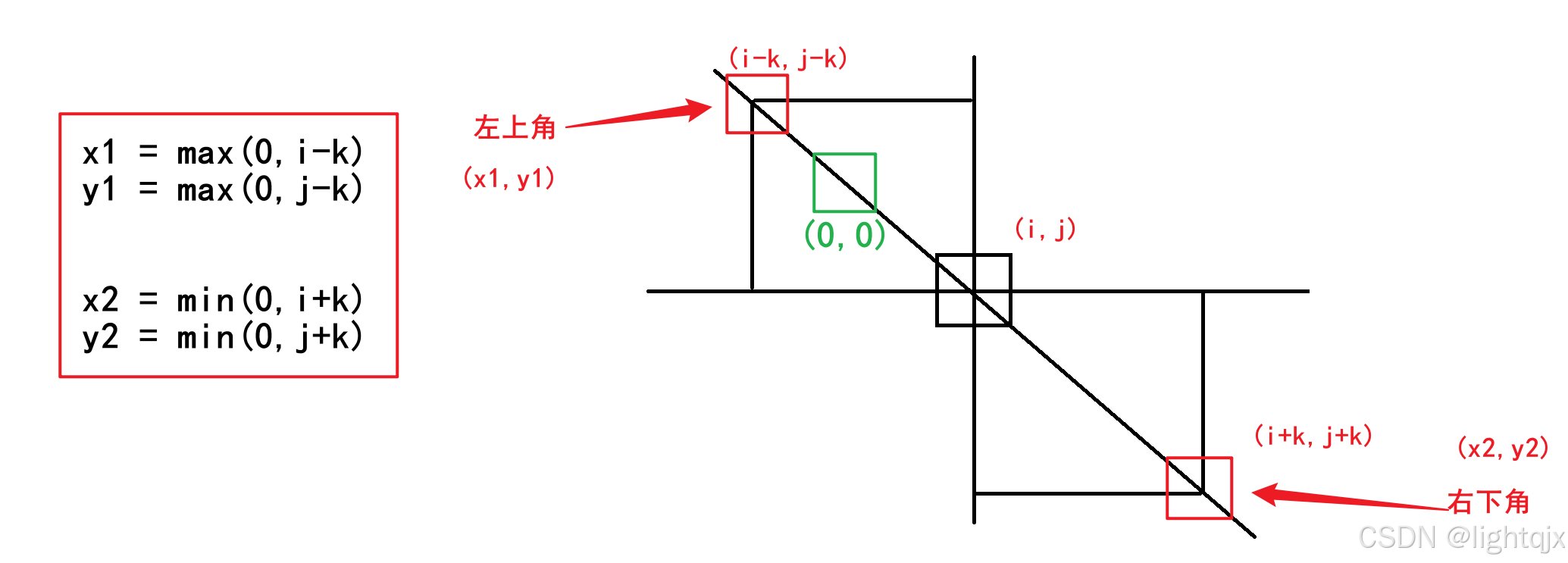
- 如果(i+k,j+k)或(i-k,j-k)越界,则我们需要考虑边界情况,那么对于左上角,我们取0和(i+k,j+k)的最大值即可,对于右下角,我们取m-1和(i+k,j+k)的最小值即可。
所以,我们的解题思路如下:
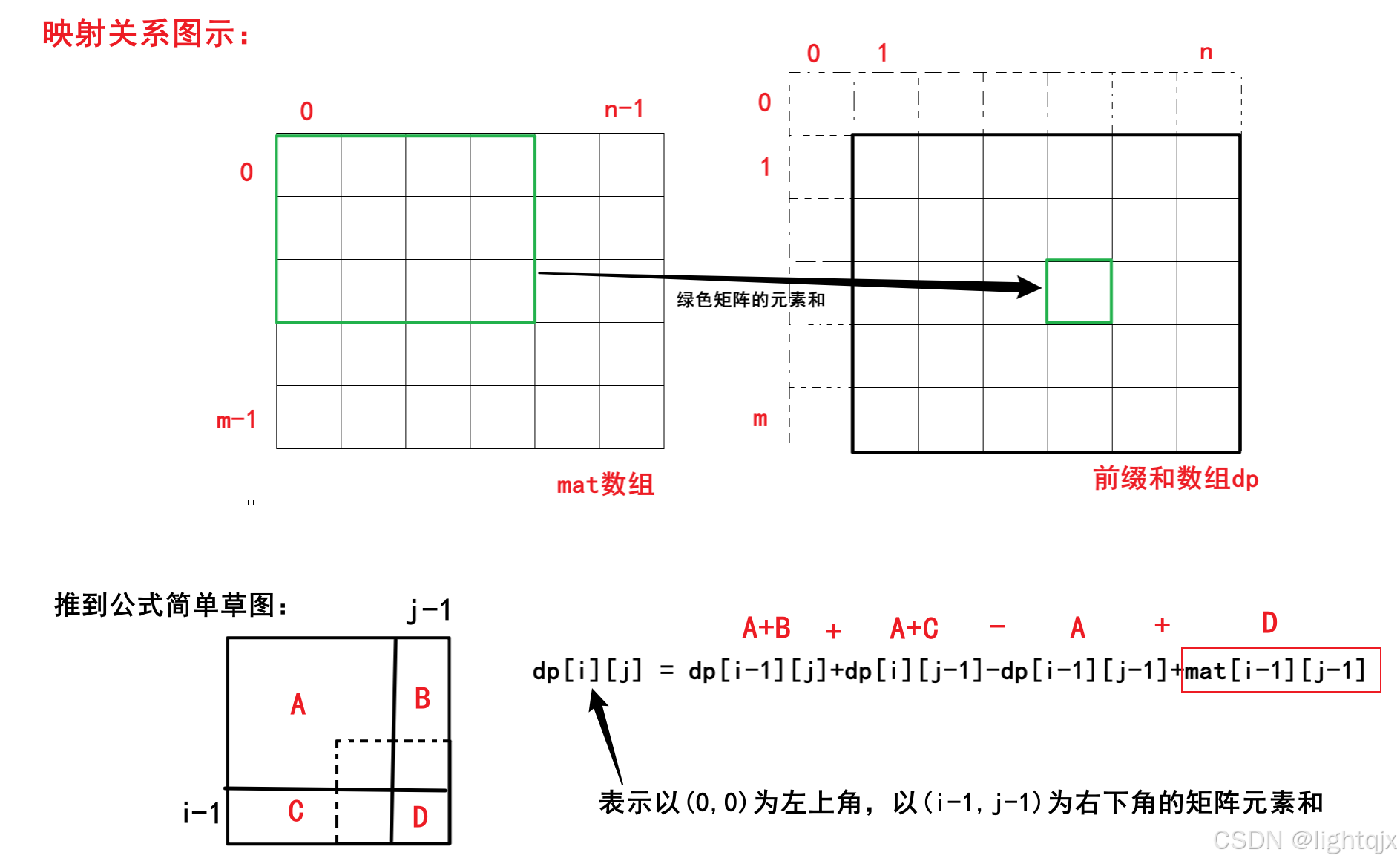
第一步,预处理一个前缀和数组dp,考虑到题目中的数组下标都是从0开始的,而前缀和数组下标是从1开始的,所以 dp i j 表示的是原数组中以坐标 ( 0, 0 ) 为左上角,以 ( i - 1, j - 1 ) 为左下角的矩阵中所有元素之和。 推到公式如下:
第二步,使用dp数组求出以(x1,y1)为左上角,以(x2,y2)为右下角的一个矩阵中的所有元素之和,为了防止(i+k, j+k)或(i-k, j-k)越界,这里的x1, y1, x2, y2还是表示如下:
除此之外,为了保证下标从1开始的dp数组和下标从0开始的返回结果数组ans之前的映射关系,我们需要让这里的x1, y1, x2, y2都加一个1。所以x1, y1, x2, y2最终表示如下:
- x1 = max(0, i - k) + 1
- y1 = max(0, j - k) + 1
- x2 = min(0, i + k) + 1
- y2 = min(0, j + k) + 1
具体解释如下所示:

所以代码实现:
cpp
class Solution {
public:
vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k)
{
int m = mat.size(), n = mat[0].size();
// 1.预处理一个前缀和数组dp
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
for(int i = 1; i <= m; i++)
{
for(int j = 1; j <=n; j++)
{
dp[i][j] = dp[i - 1][j] + dp[i][j - 1] - dp[i - 1][j - 1] + mat[i - 1][j - 1];
}
}
// 2.使用dp数组
vector<vector<int>> ans(m, vector<int>(n));
for(int i = 0; i < m; i++)
{
for(int j = 0; j < n; j++)
{
int x1 = max(0, i - k) + 1, y1 = max(0, j - k) + 1;
int x2 = min(m - 1, i + k) + 1, y2 = min(n - 1, j + k) + 1;
ans[i][j] = dp[x2][y2] - dp[x1-1][y2] - dp[x2][y1-1] + dp[x1-1][y1-1];
}
}
return ans;
}
};感谢各位观看!希望能多多支持!