1 预训练
1.1 预训练是什么
通过一个已经训练好的模型A,去完成一个小数据量的任务B(使用了模型A的浅层参数),前提是模型A与模型B相似
1.2 预训练怎么用
fairseq、transformers库
1.3 总结
一个任务A和一个任务B极其相似,任务A已经训练好了一个模型A,使用模型A的浅层参数去训练任务B,得到模型B:
1.微调(常用,浅层参数会跟着模型B训练改变)
2.冻结(浅层参数不变)
2 统计语言模型
2.1 语言模型
语言(人说的话)+ 模型(完成某个任务)
1.P("判断这个词的词性"),P("判断这个词的磁性")
2."判断这个词的____"
2.2 统计语言模型
用统计的方法解决上述问题
解决第一个问题:"判断这个词的词性" = "判断""这个""词""的""词性"
用
条件概率链式法则(概率论)实现
通过这个法则,我们可以求每一次词出现的概率,连乘就是这句话出现的概率
解决第二个问题:P(word_next | "判断" "这个" "词" "的") 求概率最大时那个词是什么
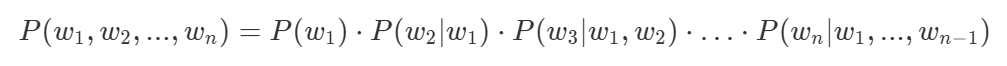
2.3 n元语言模型

3 神经网络语言模型NNLM
神经网络+语言模型:用神经网络的方式完成某个与语言相关的任务(1.判断一句话的概率,2.一句话缺词填空)
独热编码:通过0和1编码的方式让计算机认识单词(缺点:向量维度大、有大量冗余信息、无法通过余弦相似度判断两个词之间的关联性)
对于任何一个独热编码都可以通过Q矩阵得到一个新的词向量
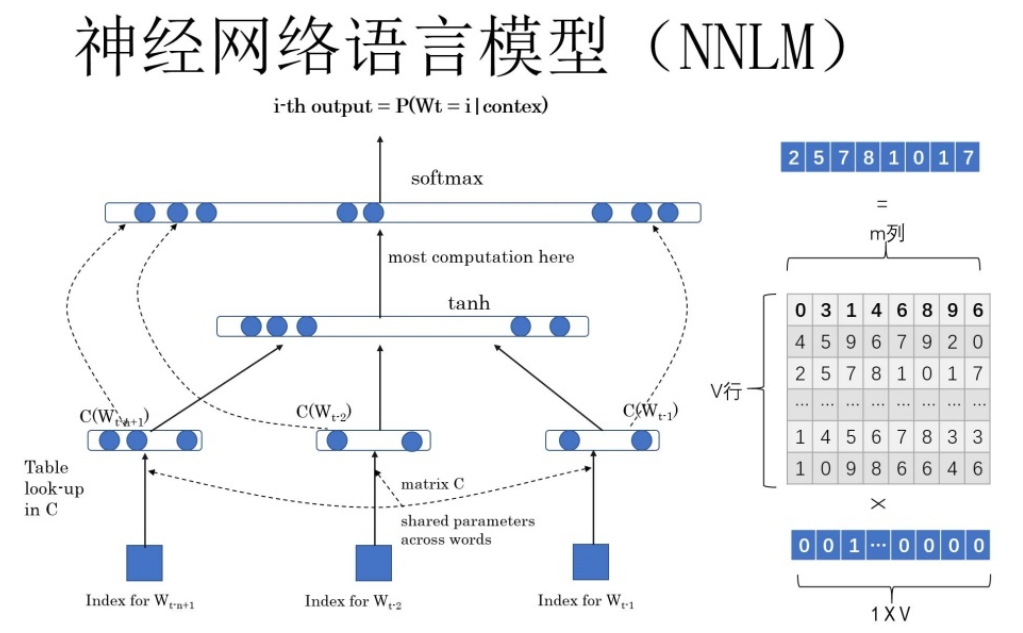
词向量::神经网络语言模型的副产品Q矩阵(词向量),用一个向量表示一个词
有了Q矩阵可以随意选择词向量维度,通过Q矩阵得到的词向量可以求词与词之前相似关系
4 Word2Vec
Word2Vec 与 NNLM 区别:NNLM重点是为了预测下一个词
Word2Vec重点是训练数据集为了得到词向量
4.1 CBOW
通过上下文预测中间词,一个老师(中间词词向量)告诉多个学生(上下文词向量)如何优化
4.2 Skip-gram
通过中间词预测上下文,多个老师(上下文词向量)告诉一个学生(中间词词向量)如何优化
4.3 词向量缺点
词向量缺点是无法表示多意(例如:🍎和苹果手机)
5 预训练语言模型
词向量的矩阵Q是不是预训练模型?
答:是的
预训练语言模型:中文 -> 独热编码 -> 提前训练好的embedding矩阵得到词向量 -> 执行接下来的任务微调:随着任务,改变embedding Q矩阵
冻结:embedding矩阵不变
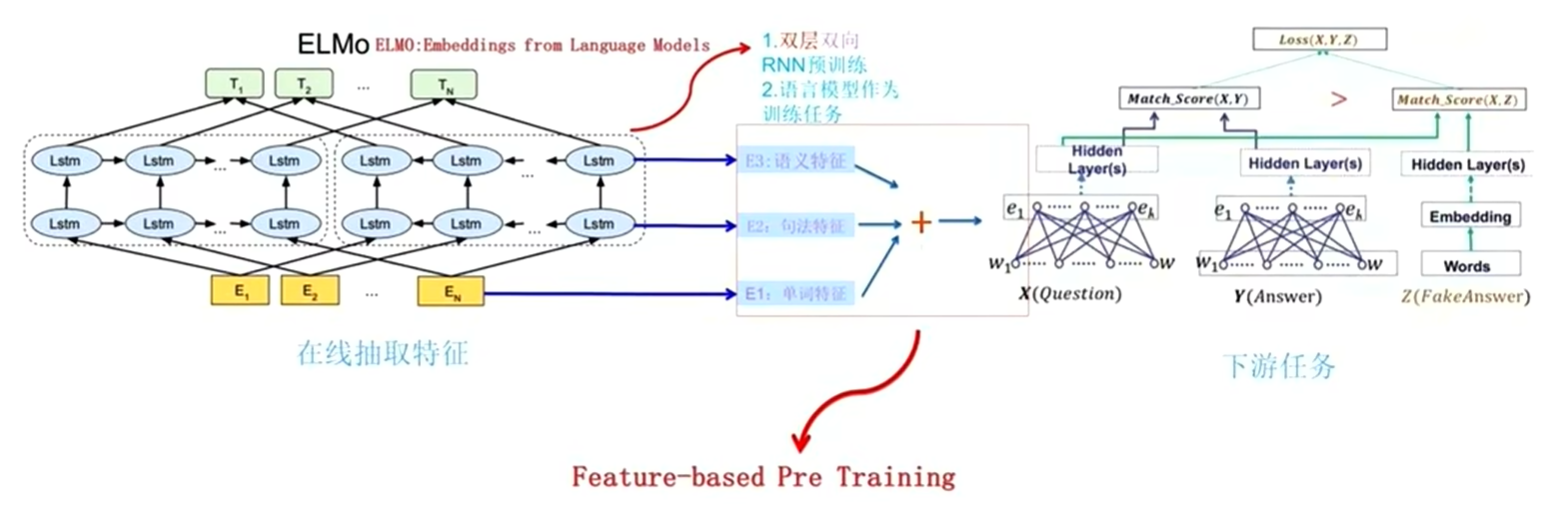
6 ELMo模型
ELMo模型是通过
预训练的方式专门用于生成词向量,并且解决了一词多意的问题
CBOW:上下文词向量取平均值后接一个全连接的线性层(词向量并没有携带上下文,无法知道序列信息)
ELMo:获取上下文后,将三层信息叠加(T = 原词向量E1 + 正序循环输出词向量 + 反序循环输出词向量)ELMo每次根据上下文语义信息动态生成,
不会直接存储,但可以提取使用
ELMo训练过程(1)预训练阶段(得到预训练ELMo模型):
大量文本 → 训练LSTM网络 → 得到训练好的模型参数
↓
保存的是模型参数
(2)使用阶段(每次都要计算):新句子 → 输入ELMo模型 → 现场计算 → 得到T₁, T₂, T₃...
↓
用于下游任务
7 注意力机制
7.1 为什么需要注意力机制
首先让我们先思考一下为什么需要注意力机制?那一定是因为之前的模型在处理序列问题时有一定的局限性
RNN、CNN局限性

RNN、LSTM:
1.需要依次序列计算,
对于远距离的相互依赖的特征,需要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小2.串行计算,无法并行
注意力机制的必要性

1. 解决长距离依赖问题
传统方法(如RNN)处理长句子时:"我昨天在公园遇到的那个穿红色衣服的女孩......"读到"女孩"时,已经忘了前面的"我"
自注意力机制:"女孩"可以直接看到句子开头的"我",无论多远,都能直接建立联系
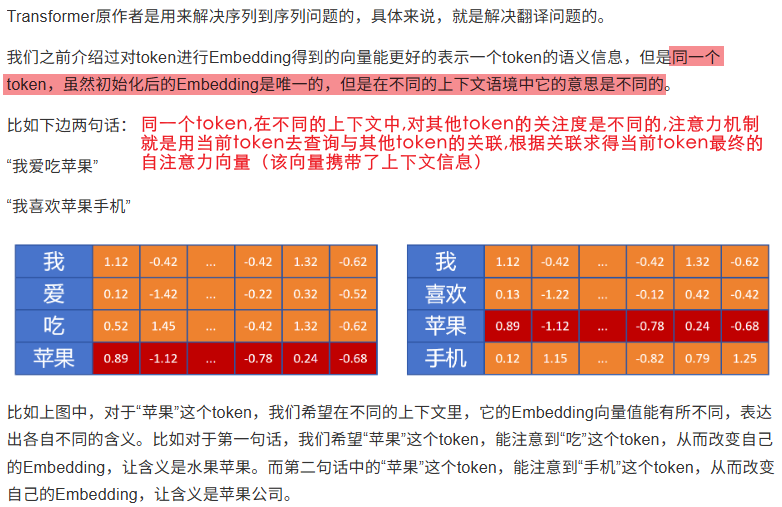
2. 理解词义依赖关系同一个词在不同上下文意思不同:
"苹果很好吃" vs "苹果股价上涨"
自注意力让"苹果"看到后面的词("好吃"或"股价"),从而确定自己的意思
3. 并行计算,速度快传统RNN要一个一个词处理(像流水线)
自注意力可以同时处理所有词(每个词都可以了解全局)
7.2 Transformer里的注意力机制
7.3 自注意力机制
注意力机制的核心,由3个重要的值决定:
一个是Q,代表查询变量。一个是K,代表应答变量。一个是V,代表值。Q和K之间计算注意力系数,决定最终取用值的多少。
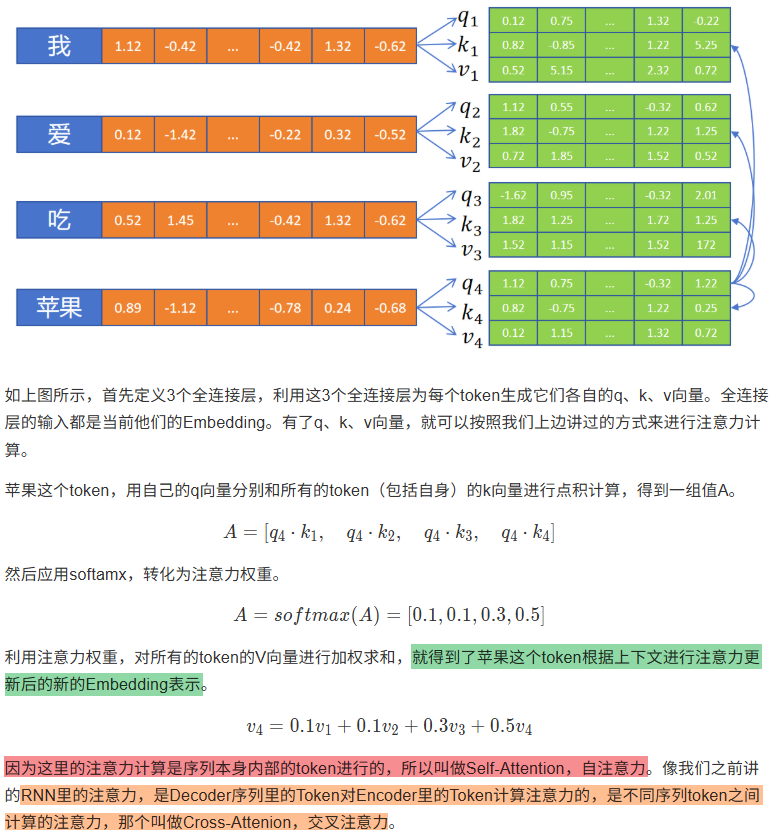
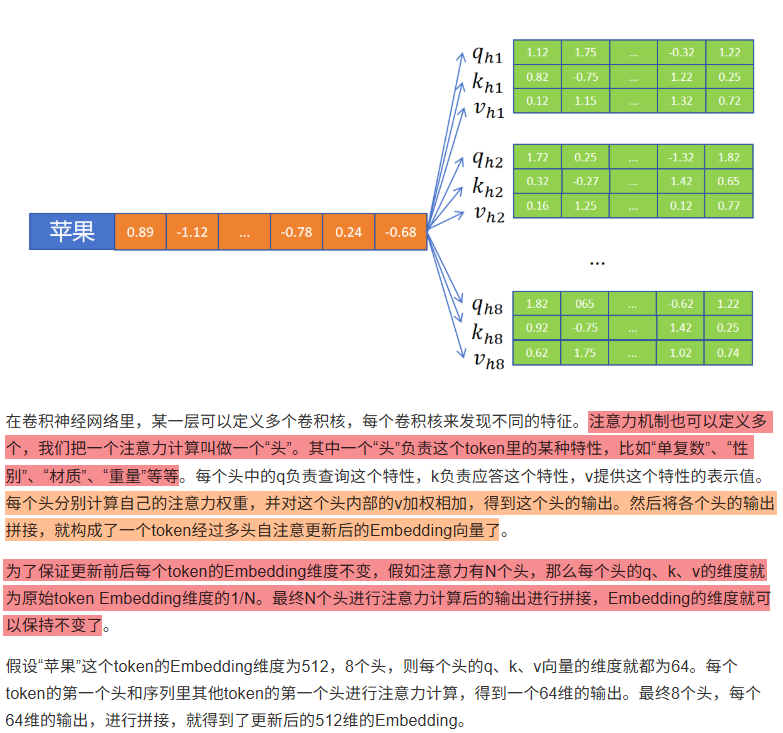
7.4 多头自注意力机制
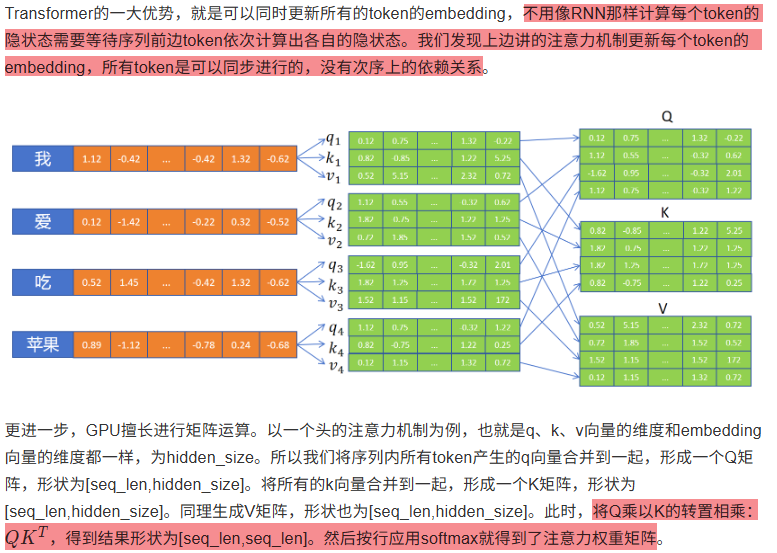
7.5 矩阵运算加速


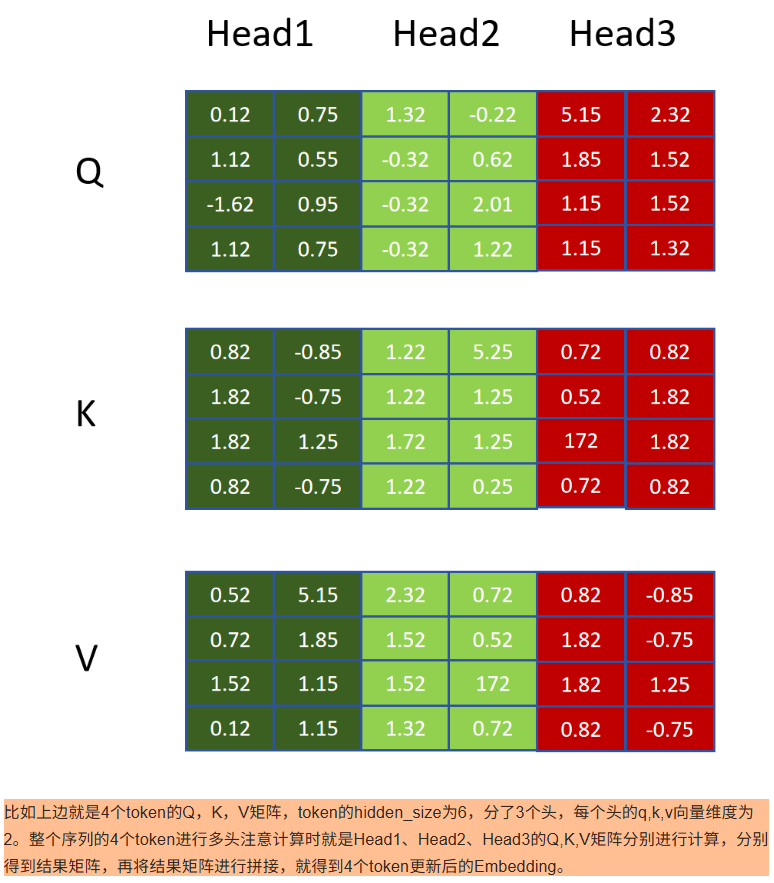
一个完整的注意力机制计算后还会通过一个
全连接层来整理token的embedding(全连接层作用:引入非线性变换,整合信息,特征增强与提炼)。这个全连接层不会改变token embedding的维度
具体例子说明句子:"The cat sat on the mat."
⭐ 经过注意力后:"cat"的embedding包含了"sat"、"on"、"mat"的信息,但还只是简单的加权混合
⭐ 经过FFN后:模型理解"cat sat on mat"表示"猫在垫子上坐着" 而不仅仅是"cat+sat+on+mat"的叠加,形成了更高层次的语义理解
再举个栗子🌰:8个64像素图片拼接在一起的像素 ≠ 1个256像素图片像素
7.6 掩码自注意力机制
掩码自注意力机制就是在求得注意力权重矩阵(还没利用softmax对注意力权重计算前)后,对当前token后面的token的注意力权重进行掩码,不给模型看到后面的信息
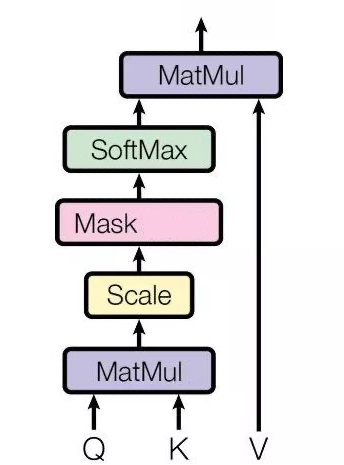
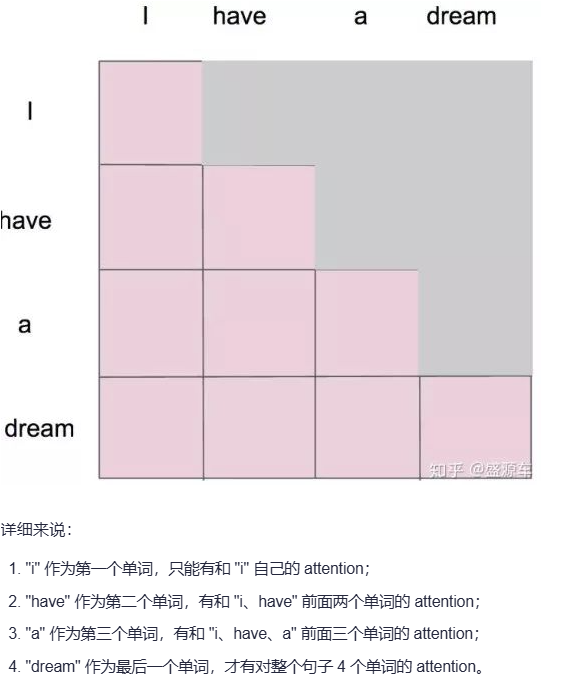

用有掩码的自注意力(因果掩码)
任务类型 :🌱写文章、续写故事
🌱机器翻译(生成目标语言)
🌱代码生成
🌱对话回复生成
模型示例 :🌱GPT系列:只能看到左边的词
🌱Transformer解码器:生成时用掩码
不用掩码的自注意力
任务类型 :🌱文本分类(情感分析、主题分类)
🌱命名实体识别(NER)
🌱句子相似度计算
🌱问答(理解问题)
模型示例 :🌱BERT:可以看到整个句子
🌱Transformer编码器:分析时用无掩码
8 位置编码

"我爱你"、"你爱我"自注意力矩阵权重相同,但表达的意思完全不同,所以需要为token添加位置编码
8.1 绝对位置编码
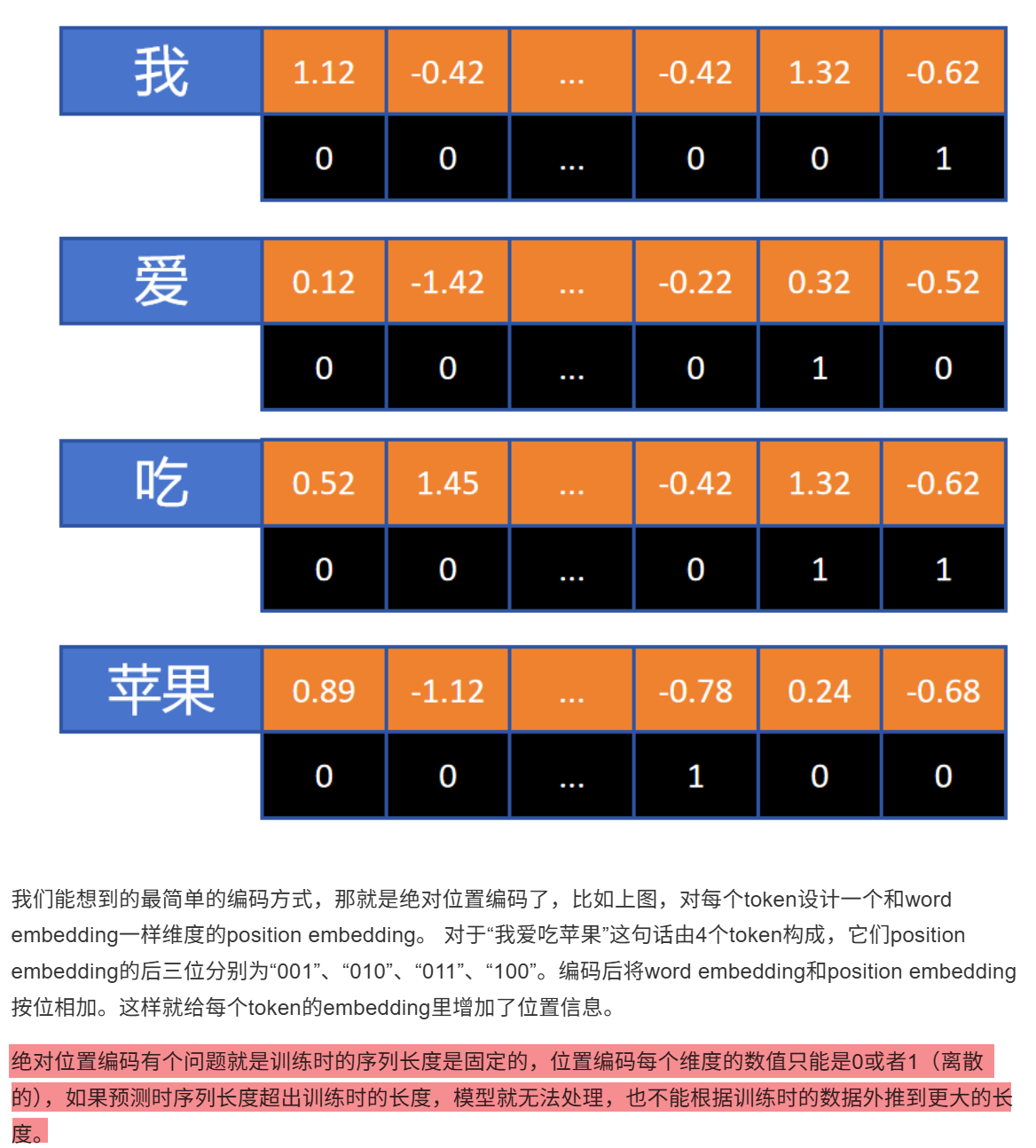
🌱 且这种编码方式蕴含信息量太少,在计算自注意力时也无法通过点积等方式反应词与词之间在空间上的复杂关系
🌱 所以需要将位置编码变成一个高维向量,该向量中蕴含丰富的空间位置关系,例如:让模型感受不同位置的差异(数据量很大,同一个词不同位置导致token 向量不同,模型会学习到其中的位置差异),甚至让模型捕捉某两个词之间的位置关系(正余弦加减法公式 => 旋转角度)
8.2 Sin Cos函数位置编码
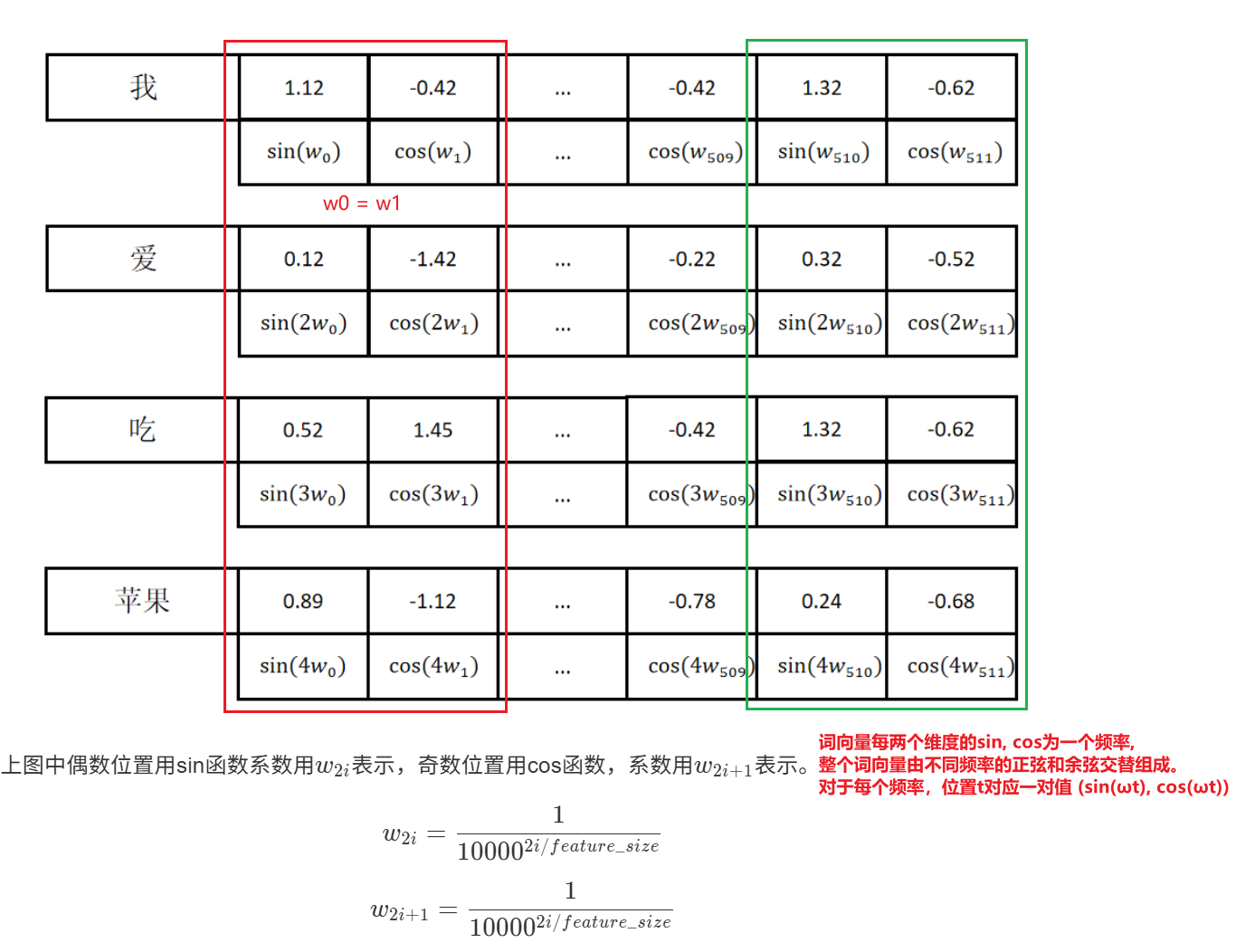

在 transformer 使用的 sin、cos 位置编码中,如果只看两个位置向量之间的点积(也就是注意力机制中衡量两个词相关性的分数),这个分数
只取决于它们之间的相对距离(比如相隔几个词),而和它们各自的绝对位置(比如是第 1 个词还是第 100 个词)无关
位置编码每两个维度为一个频率,浅层频率变化快,深层频率变化慢。通过sinwx、coswx可以在二维坐标系中确定一个唯一位置,其与x轴夹角为wx,而词与词之间的相对位置则可以表示为以当前位置绕原点旋转一个固定角度,可以用一个简单的旋转公式算出来新坐标的位置(所以即使预测时序列长度超出训练长度,模型也会自己学习后面的规律)

不同频率正余弦组合确定编码唯一性
javascript
# 假设只有两个频率
位置t: [sin(ω₁t), cos(ω₁t), sin(ω₂t), cos(ω₂t)]
# 要找到t'使得编码相同,需要:
sin(ω₁t) = sin(ω₁t') 且 cos(ω₁t) = cos(ω₁t') # 时钟1相同
sin(ω₂t) = sin(ω₂t') 且 cos(ω₂t) = cos(ω₂t') # 时钟2相同
# 这意味着:
ω₁t ≡ ω₁t' (mod 2π) # t' = t + 2πk₁/ω₁
ω₂t ≡ ω₂t' (mod 2π) # t' = t + 2πk₂/ω₂
2πk₁/ω₁ = 2πk₂/ω₂
⇒ k₁/ω₁ = k₂/ω₂
⇒ k₁ω₂ = k₂ω₁
由于ω₁和ω₂不可公度(频率比是无理数),
只有当k₁=k₂=0时成立,即t'=t。
多个频率时:几乎不可能有两个不同位置有完全相同编码!总结
"sin+cos组合创建二维旋转系统,每个位置唯一"意思是:
🌼 二维系统:每个频率对应一个二维平面上的单位圆
🌼 旋转:位置增加 → 在圆上旋转一定角度
🌼 唯一性:多个不同频率的圆组合,确保每个位置有唯一编码
🌼 相对性:
两个位置的关系只取决于旋转角度差(相对位置)
9 Layer Norm(层归一化)
9.1 对比Batch Norm(批量归一化)

🌱 1.不同batch之间的差异:
句子长度可能很长(如512个词)
GPU内存有限 → Batch Size只能很小(如4)
批次1:包含4个长句子
批次2:包含4个短句子
批次3:包含4个中等句子
每个批次的统计量(均值、方差)差异巨大! 导致训练不稳定!
🌱 2.不同句子之间的差异:为了让所有句子一样长,短的句子后面用< pad >填充:
句子1:"I love NLP" → "I", "love", "NLP", "", ""
句子2:"Hello" → "Hello", "", "", "", ""
出现大量的< pad >均值会变低
如果使用Batch Norm就可能会导致一个token的embedding在不同句子、不同batch中归一化后的结果是不同的,显然这会导致训练模型不是很稳定
9.2 Layer Norm实现

✔️ 每个词向量独立计算自己的均值和方差!
❌ "king"和"apple"用同一个均值和方差,可能不公平,因为它们的原始分布本就不同
Layer Norm作用 :🌱 稳定训练:防止梯度爆炸/消失
🌱 加速收敛:数据分布更稳定
🌱 正则化效果:轻微的正则化作用
🌱 允许大学习率:训练更快
🌼归一化作用:使数据分布更稳定,防止embedding有的维度过大,有的维度过小,并且不改变维度之间的相对大小🌼
每一维度γ和β的作用(提取更针对性的信息):给模型选择权,可以接受标准化,也可以根据任务调整各维度的状态,例如:对于情感分析的模型可以放大情感维度,缩小词频维度
🌰 例如:原始图像:可能有曝光问题、颜色偏差
标准化:调整亮度、对比度到标准范围
γ调整:根据任务增强某些颜色,增强有用信息
10 Transformer
输入输出不等长 => 编码器(只处理输入,得到一个编码结果)、解码器结构(处理编码结果得到输出)
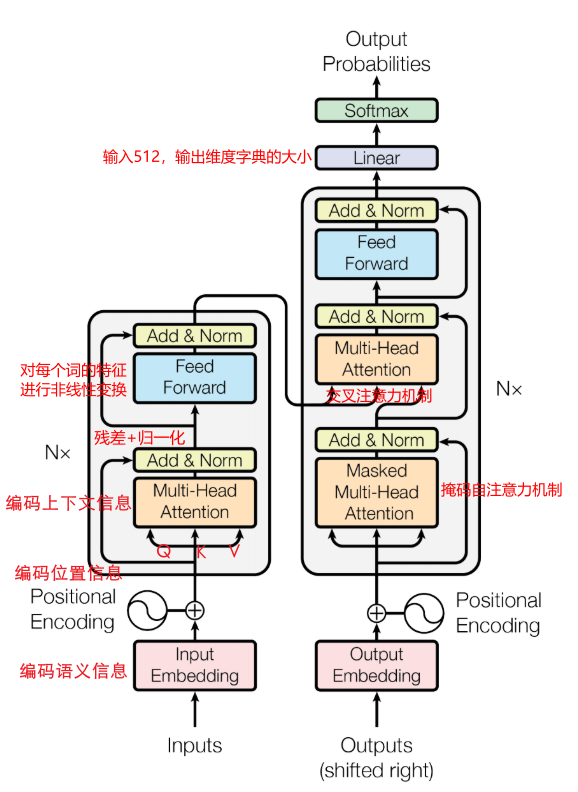
下面均用英文句子翻译成中文句子举例
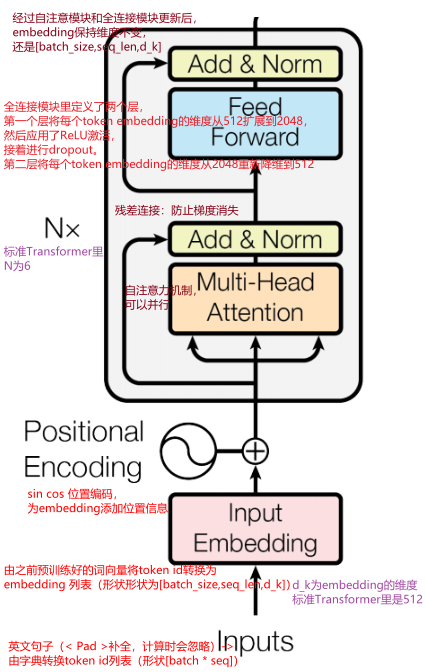
10.1 Encoder
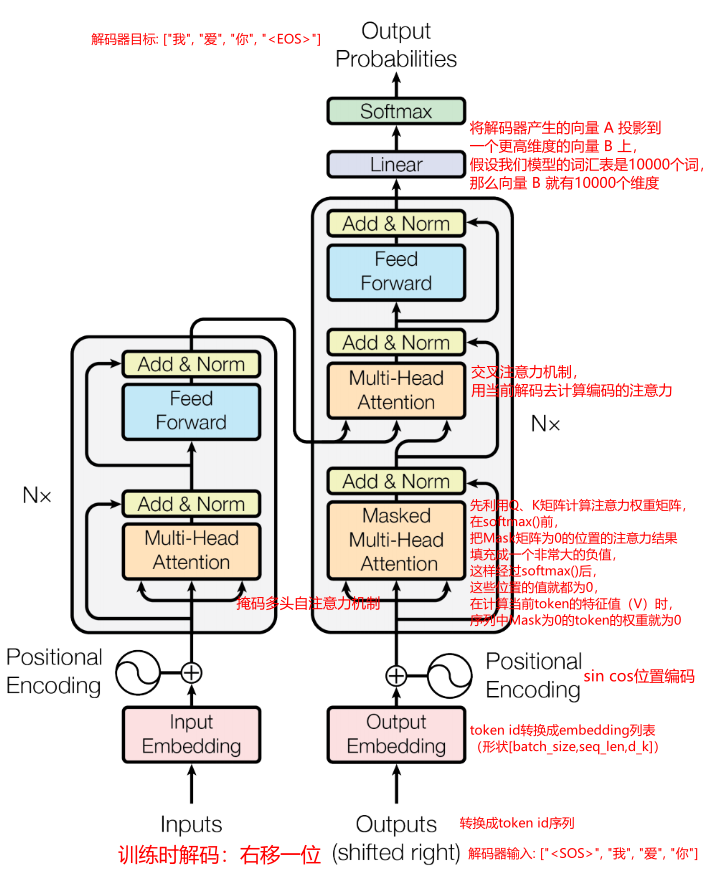
10.2 Decoder
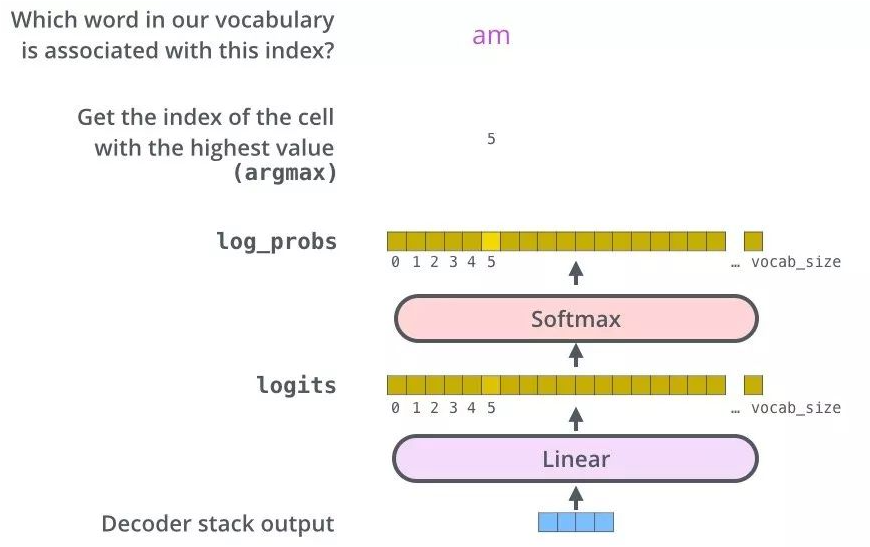
解码器在循环外输出翻译结果的过程:
10.3 编码解码完整过程
编码器过程(上一层编码器输出是下一层编码器输入)
python
# 输入:英文句子 "I love you"
# 第1层编码器:
# 输入:[I_emb, love_emb, you_emb] + 位置编码
# 学习:I是主语,love是动词,you是宾语
# 输出:基础语法特征
# 第2层编码器:
# 输入:第1层输出
# 学习:"I"和"love"是主谓关系,"love"和"you"是动宾关系
# 输出:句法关系特征
# 第3层编码器:
# 输入:第2层输出
# 学习:整个句子的语义结构
# 输出:语义特征
# 第4-6层编码器:
# 不断深化和抽象特征
# 最终输出:英文句子的高级语义表示解码器输出(上一层解码器输出是下一层解码器输入)
交叉注意力向量都使用编码器第6层输出向量求取
python
# 训练时(Teacher Forcing):
# 输入:中文序列 "<SOS> 我 爱 你"
# 第1层解码器:
# 自注意力输入:<SOS>_emb, 我_emb, 爱_emb, 你_emb + 位置编码
# 交叉注意力输入:学习当前解码输入向量对编码器第6层输出的注意力向量
# 学习:<SOS>→我,我→爱的关系,并与英文对齐
# 输出:初步对齐表示
# 第2层解码器:
# 自注意力输入:第1层解码器输出
# 交叉注意力输入:编码器第6层输出
# 学习:更深入的对齐关系
# 输出:更准确的对齐表示
# 第3-6层解码器:
# 不断优化对齐和表示
# 最终输出:准备生成下一个词的概率分布10.4 编码器中的并行化
Transformer的Decoder部分通过引入
"teacher force"和"masked self attention"实现并行化。在训练阶段,Decoder的输入不依赖于前一时刻的输出,而是依赖于正确的目标样本。这种策略称为"teacher force",它可以避免因中间预测错误而影响后续预测,从而加快训练速度
此外,Decoder还使用了"masked self attention",即在计算当前时刻的输出时,只考虑当前及之前的输入,而不考虑之后的输入。这种机制通过添加一个mask,使得Decoder在训练时可以并行计算所有的输出
需要注意的是,Decoder的并行化仅在训练阶段有效。在测试阶段,由于没有正确的目标样本,Decoder的输入仍然依赖于前一时刻的输出,因此无法并行计算
10.5 残差连接
🌼 1.解决梯度消失问题(最重要!)
🌱 没有残差连接:深层网络梯度消失输入 → Layer1 → Layer2 → ... → Layer12 → 输出
反向传播时,梯度要穿过12层,容易消失
🌱 有残差连接:梯度可以"跳过"某些层 输入 → (输入 + Layer1) → (输入 + Layer2) → ...梯度可以通过残差路径直接传播!
🌼 2.保持信息完整性
🌱 没有残差连接:信息在深层可能丢失原始信息 → 变换1 → 变换2 → ... → 变换12
经过12次变换后,原始信息可能完全丢失
🌱有残差连接:原始信息始终保留原始信息 → (原始信息 + 变换1) → (原始信息 + 变换2) → ...
即使经过很多层,原始信息仍然存在!
11 Transformer代码实现
11.1 多头注意力机制
python
import torch
import torch.nn as nn
import numpy as np
class MultiHeadAttention(nn.Module):
def __init__(self, d_k, d_v, sum_heads, d_model, p=0):
super().__init__()
# 单头k和q维度
self.d_k = d_k
# 单头v维度
self.d_v = d_v
# embedding维度
self.d_model = d_model
# 注意头数量
self.sum_heads = sum_heads
self.dropout = nn.Dropout(p)
# 生成多头Q、K、V矩阵
# Q矩阵投影变换,d_model维映射到d_k*sum_heads
self.W_Q = nn.Linear(d_model, d_k * sum_heads)
self.W_K = nn.Linear(d_model, d_k * sum_heads)
self.W_V = nn.Linear(d_model, d_v * sum_heads)
# 输出投影变换,拼接后的V矩阵维度映射回embedding维度
self.W_out = nn.Linear(d_v * sum_heads, d_model)
# 归一化,标准差计算公式sqrt(2.0 / (输入维度 + 输出维度))
nn.init.normal(self.W_Q.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal(self.W_K.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_k)))
nn.init.normal(self.W_V.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
nn.init.normal(self.W_out.weight, mean=0, std=np.sqrt(2.0 / (d_model + d_v)))
def forward(self, Q, K, V, attn_mask):
# batch大小
batch = Q.size(0)
# q和k序列长度
q_len, k_len = Q.size(1), K.size(1)
# [batch, q_len, d_model] => [batch, q_len, sum_heads * d_k] => [batch, q_len, sum_heads, d_k] => [batch, sum_heads, q_len, d_k]
Q = self.W_Q(Q).view(batch, -1, self.sum_heads, self.d_k).transpose(1, 2)
K = self.W_K(K).view(batch, -1, self.sum_heads, self.d_k).transpose(1, 2)
V = self.W_V(V).view(batch, -1, self.sum_heads, self.d_v).transpose(1, 2)
if attn_mask is not None:
assert attn_mask.size() == (batch, q_len, k_len)
# [batch, q_len, k_len] => [batch, 1, q_len, k_len] => [batch, self.sum_heads, q_len, k_len]
attn_mask = attn_mask.unsqueeze(1).repeat(1, self.sum_heads, 1, 1)
# 转换成布尔型, 0赋值False, 1赋值True
attn_mask = attn_mask.bool()
# 计算注意力权重
# [batch, sum_heads, q_len, d_k] @ [batch, sum_heads, d_k, k_len] => [batch, sum_heads, q_len, k_len]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_k)
if attn_mask is not None:
scores.masked_fill(attn_mask, -1e4)
# 应用softmax
attns = torch.softmax(scores, dim=-1)
attns = self.dropout(attns)
# K和V是同源,K和V的token序列长度应该相同 => k_len = v_len
# [batch, sum_heads, q_len, k_len] @ [batch, sum_heads, k_len, d_v] => [batch, sum_heads, q_len, d_v]
output = torch.matmul(attns, V)
# [batch, sum_heads, q_len, d_v] => [batch, q_len, sum_heads, d_v] => [batch, q_len, sum_heads * d_v]
output = output.transpose(1, 2).contiguous().reshape(batch, -1, self.sum_heads * self.d_v)
# [batch, q_len, sum_heads * d_v] => [batch, q_len, d_model]
output = self.W_out(output)
return output11.2 前馈神经网络
python
# 两个MLP
class PoswiseFFN(nn.Module):
def __init__(self, d_model, d_ff, p=0.):
super().__init__()
# 词向量维度,Transformer中为512
self.d_model = d_model
# 中间层维度,Transformer中为2048
self.d_ff = d_ff
# d_model:输入通道数, d_ff:输出通道数(filter), 卷积核大小,步长,padding
self.conv1 = nn.Conv1d(d_model, d_ff, 1, 1, 0)
self.conv2 = nn.Conv1d(d_ff, d_model, 1, 1, 0)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=p)
def forward(self, X):
# [N, seq_len, d_model](Conv1d要求:通道数在维度1) -> [N, d_model, seq_len] -> [N, d_ff, seq_len]
out = self.conv1(X.transpose(1, 2)) # (N, d_model, seq_len) -> (N, d_ff, seq_len)
out = self.relu(out)
out = self.conv2(out).transpose(1, 2) # (N, d_ff, seq_len) -> (N, d_model, seq_len)
out = self.dropout(out)
return out12 GPT
12.1 GPT1(内容生成)

12.1.1 模型架构
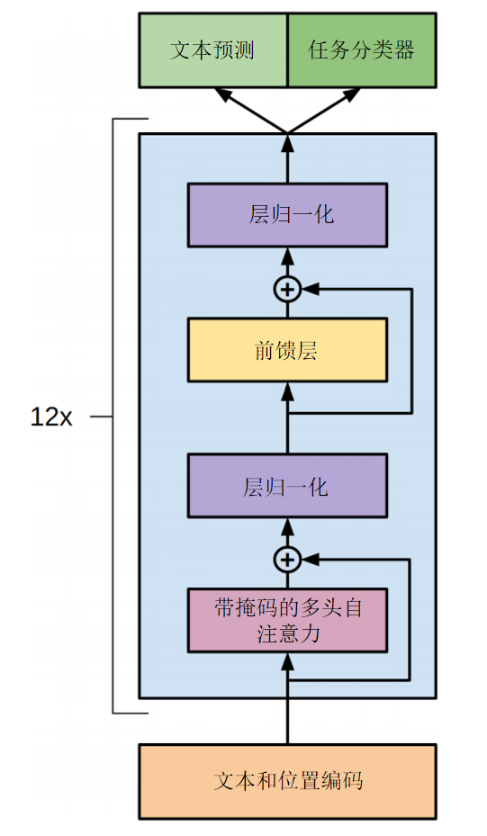

12.1.2 下游任务适配方式
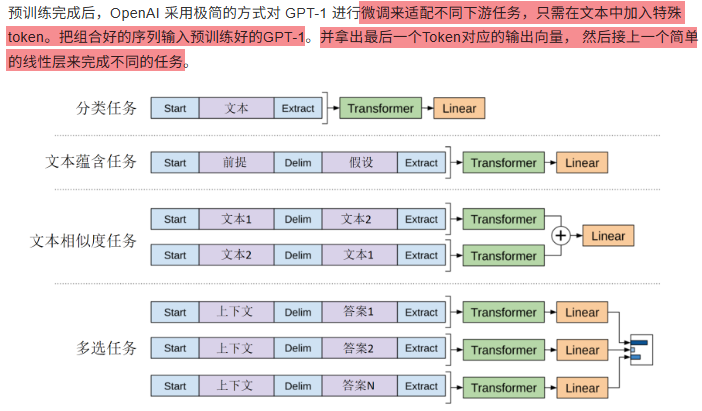

12.1.3 多任务联合训练

12.1.4 训练数据与设置
GPT-1 的预训练使用了 BooksCorpus 数据集:
包含约 7000 本未出版图书;
总词量约为 8 亿;
上下文窗口长度:512 个 token;
批处理大小:32
12.1.5 效果
GPT1通过预训练+微调 的范式,用通用的模型架构,通过对不同任务设计不同的输入的方式下,不对模型结构进行大幅修改,在12个NLP任务中,有9个刷新了当时的最好成绩,显示出其强大的通用性和迁移能力。
GPT-1的发布,标志着以无监督预训练为核心的大模型路线正式确立。它证明了即使使用最基础的"预测下一个词"的目标,也能学到强大的语言表示能力,并且易于迁移到多种NLP 任务中。这为后续如 GPT-2、GPT-3 和 GPT-4 等更强大的语言模型奠定了坚实的基础
12.2 BERT(特征提取)
GPT-1的成功让人们看到了在NLP领域"预训练+微调"模式的可行性,GPT-1是Decoder-Only的架构。BERT(Bidirectional Encoder Representations from Transformers)的作者认为GPT-1的注意力是单向的,也就是每个token只能关注它前面token的信息。但是对于NLP任务,双向注意力可以看到序列里所有token的信息,这样对于上下文理解会更加全面,应该会取得更好的效果
12.2.1 BERT模型架构
BERT是一个Encoder-Only的架构。它采用了Transformer里的Encoder部分的架构
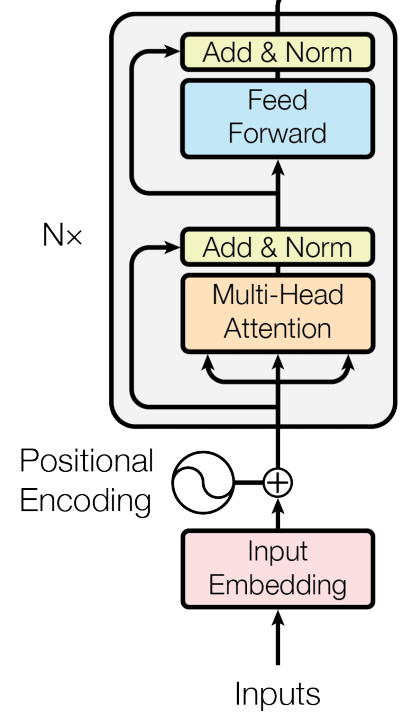

12.2.2 输入与输出
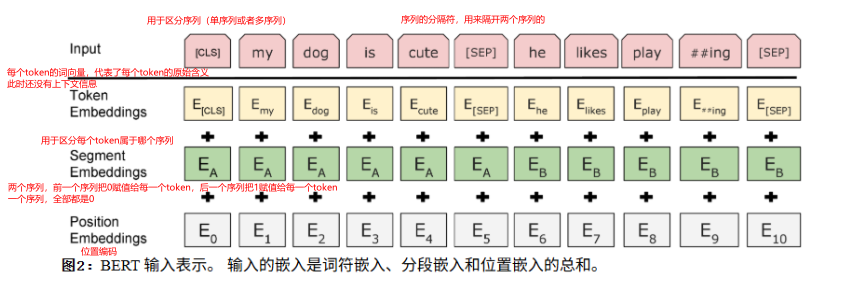
BERT可以解决NLP领域的两类问题,一类是序列级别的问题,一类是token级别的问题(类似NER)
序列级别的问题也分为两类,一类是单个序列的,比如对一句话进行正面和负面情绪的判别🌱 输入:CLS 这 部 电 影 太 好 看 了 SEP,判断情感为正面还是负面
🌱 其他例子
- 文本分类(新闻属于体育/政治/娱乐)
- 垃圾邮件检测
- 语言检测
一类是两个序列的,比如判断两句话的蕴含关系🌱 序列A:猫在追老鼠; 序列B:动物在运动。理解两个句子的关系,判断逻辑关系
🌱 其他例子
- 文本相似度(两句话意思是否相同)
- 问答(问题+文本 → 答案)
- 复述检测
token级别的问题输入:张 三 去 北 京 旅 游
输出:B-PER I-PER O B-LOC I-LOC O O
🌱 需要BERT:
(1)理解每个词在上下文中的含义
(2)为每个词单独打标签
🌱 其他例子
- 词性标注(名词/动词/形容词)
- 语义角色标注
- 中文分词
12.2.3 预训练BERT
因为BERT预设是可以同时解决序列级别问题和token级别的问题。所以预训练时就必须设计能提取token上下文信息和序列信息的任务
Token级别任务:遮蔽语言模型(MLM)
遮蔽语言模型(Masked Language Model,掩码语言模型),是
随机将输入token中的一些进行mask,替换为[MASK] token。然后在BERT输出时,根据[MASK]token的输出向量加一个分类头,预测出原始被遮蔽的token id。这个任务就是填空题,锻炼模型根据上下文信息猜出空缺token的能力。这样训练模型就让模型能更高的提取token级别的上下文信息。但是为了防止模型只是在输入MASK这个token时才刻意提取它的上下文信息(看到MASK认真,看到正常词偷懒),实际BERT在训练时,
先随机选择15%的token做最终的token id预测。在这15%的token里,80%的概率用[MASK] token替换原来的token,10%的概率随机替换为其他token,10%的概率保持原有token不变。经过这样的数据设计,BERT模型就可以很好的提取没个token的上下文信息了
python
# 步骤1:准备训练数据
原始句子 = "我爱北京天安门"
# 步骤2:分词
tokens = ["我", "爱", "北", "京", "天", "安", "门"]
# BERT实际用WordPiece分词,这里简化
# 步骤3:随机选择15%的token
假设随机数决定选择:位置1("爱")和位置5("安")
# 总共7个token,15%≈1个,但BERT实际可能选更多
# 步骤4:对每个选中的token决定处理方式
# 对"爱"(位置1):
随机数 = 0.75 → 属于80% → 替换为[MASK]
输入变为:我 [MASK] 北 京 天 安 门
# 对"安"(位置5):
随机数 = 0.05 → 属于10% → 替换为随机词
随机词 = "大"
输入变为:我 [MASK] 北 京 天 大 门
# 最终输入:
["我", "[MASK]", "北", "京", "天", "大", "门"]
# 步骤5:BERT的任务
位置1:预测原始词是"爱"
位置5:预测原始词是"安"(不是"大"!)
# 步骤6:计算损失
loss1 = -log(P("爱" | 上下文))
loss2 = -log(P("安" | 上下文))
总损失 = loss1 + loss2序列级别任务:下一句预测(NSP)
下一句预测(Next Sentence Prediction)的任务是
判断句子B是否是句子A的下文。如果是的话输出'IsNext',否则输出'NotNext'。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的
12.2.4 微调BERT
BERT的微调很简单,只需要
按照问题类型组织输入token即可。比如是两个序列,就在序列之间加[SEP] token,并且设置合适的Segment Embedding
另外根据不同的任务,利用不同位置token的输出,加上分类头来进行下游任务。序列级别的就提取[CLS] token的输出,token级别的就提取每个token的输出
BERT进行微调时,只有分类头是全新的随机初始化的,其他参数,包括Encoder和Embedding都是预训练好的,进行全参数量的微调
12.3 GPT2
GPT-2 的设计初衷是为了解决 GPT-1 与 BERT 虽然引入了预训练机制,但在处理具体下游任务时仍需进行微调的局限
12.3.1 GPT2的目标

12.3.2 架构改进

12.3.3 总结
GPT-2的意义是模型训练时只需要一个任务,那就是预测下一个词,就
可以训练出一个可以解决各种问题,具备通用能力的模型。这个模型不需要在不同任务上进行微调,就能得到一个还不错的成绩。在GPT-2之前,具体任务类型需要被设计进网络结构,(比如添加分类头,设置分类数量),但是GPT-2是把任务类型通过prompt这种自然语言的方式传入到模型。模型也不是输出任务可能结果的概率值,而是以自然语言方式给出答案。这种统一是一个巨大的进步
12.4 GPT-3
传统模型(如 BERT 和 GPT-1)在处理特定任务时,通常需要大量标注数据进行微调。而 GPT-3 探索的是另一种方式:
能否仅通过"提示"(prompt)和少量示例,就完成复杂任务,而无需调整模型参数
GPT-3 (足够大的模型足够多的数据让AI学会了"如何学习")沿用了 GPT-2 的结构,并将模型规模推向了新高度,最大版本拥有 1750 亿个参数,在 3000 亿个 token的文本数据上进行了训练


12.5 GPT4(多模态)


参考
RethinkFun
水论文的程序猿-水导
读懂BERT,看这一篇就够了
三万字最全解析!从零实现Transformer(小白必会版😃)