Ubuntu datasophon1.2.1 二开之八:验证实时数据入湖
- 背景
- 第一步:环境准备
- 第二步:往Kafka生产测试数据
-
- [创建Kafka Topic](#创建Kafka Topic)
- [第三步:在ClickHouse中创建目标表(在安装clickhouse机器上操作)](#第三步:在ClickHouse中创建目标表(在安装clickhouse机器上操作))
- [第四步:启动Flink SQL作业](#第四步:启动Flink SQL作业)
-
- 1.创建hdfs目录
- [2.修改flink 配置(/opt/datasophon/flink/conf/flink-conf.yaml ),连接yarn](#2.修改flink 配置(/opt/datasophon/flink/conf/flink-conf.yaml ),连接yarn)
- [3.进flink sql client执行](#3.进flink sql client执行)
- 第五步:验证数据
- 遇到的坑
-
- [坑1:Jar 包冲突 - NoSuchMethodError](#坑1:Jar 包冲突 - NoSuchMethodError)
- [坑2:YARN HA 配置 - ResourceManager 端口不通](#坑2:YARN HA 配置 - ResourceManager 端口不通)
- [坑3:HDFS 权限 - Checkpoint 写入失败](#坑3:HDFS 权限 - Checkpoint 写入失败)
- [坑4:TaskManager Slot 不足](#坑4:TaskManager Slot 不足)
- [坑5:Paimon 聚合表 changelog-producer 配置](#坑5:Paimon 聚合表 changelog-producer 配置)
- [坑6:max 聚合函数不支持 retraction](#坑6:max 聚合函数不支持 retraction)
- [坑7:DataNode/NodeManager PID 目录权限](#坑7:DataNode/NodeManager PID 目录权限)
- [坑8:YARN 用户与 HDFS 用户权限分离](#坑8:YARN 用户与 HDFS 用户权限分离)
- 最后
背景
按客户要求,该装的组件都安装了。下来帮客户验证,实时数据入湖技术路线。
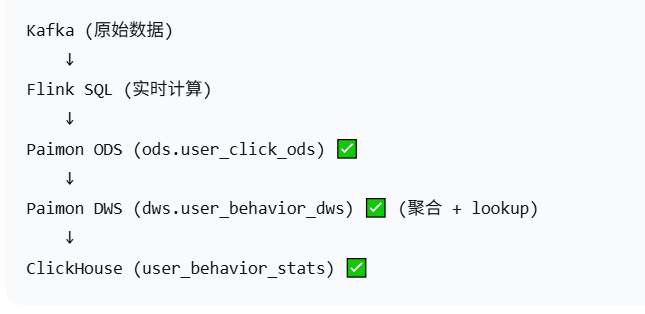
根据客户要求,走技术栈:Kafka -> Flink -> Paimon -> HDFS -> ClickHouse
除了Kafka没安装之外,其他组件都安装了。在datasophon控制台安装一下即可。选
择ddp3,ddp4两台机
验证大概流程如下:
第一步:环境准备
由于flink 是连通各个组件的枢纽,所以它必须有连通各组件的jar,准备这些jar是最耗费时间和精力,是成功失败的关键。下面列出原始flink 子目录lib和opt目录和能跑通flink 子目录lib和opt目录差异
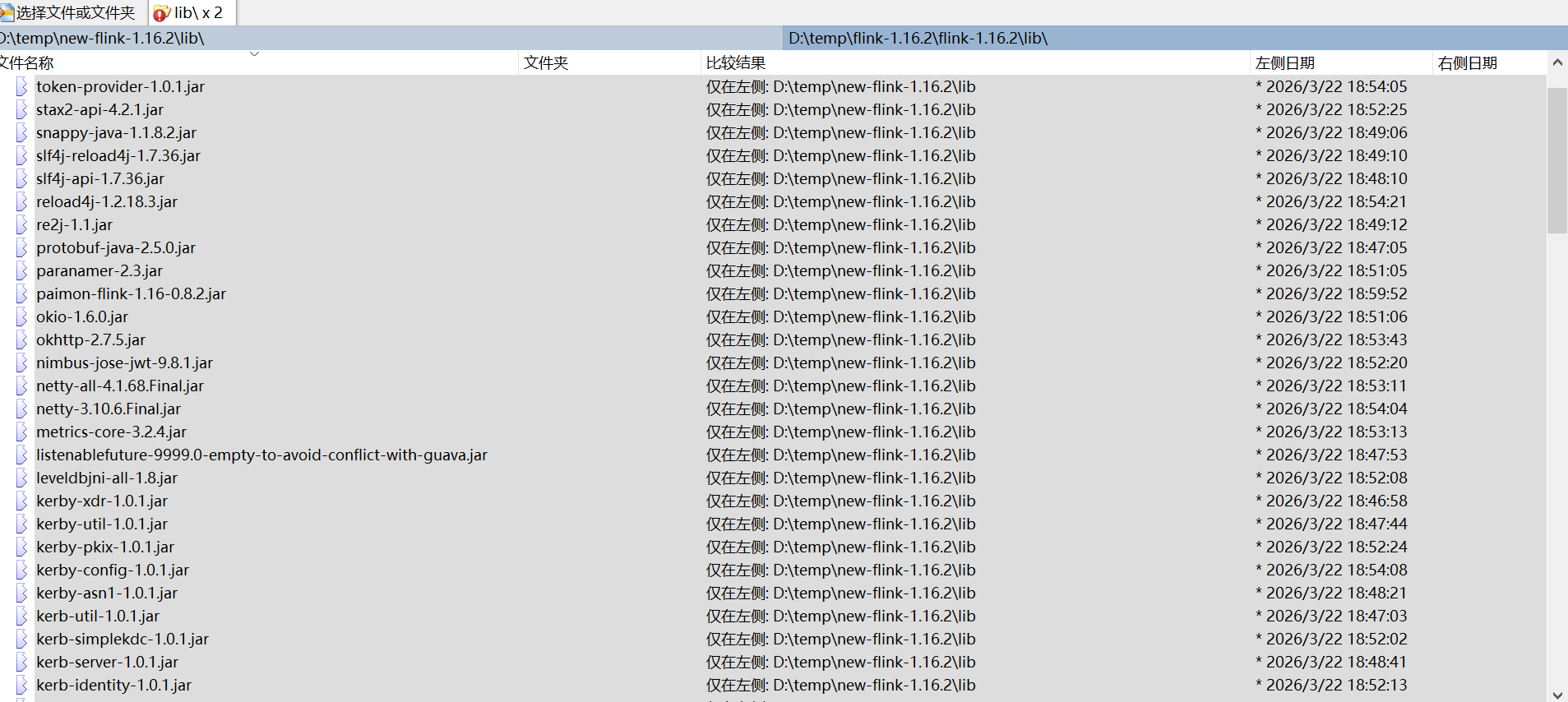
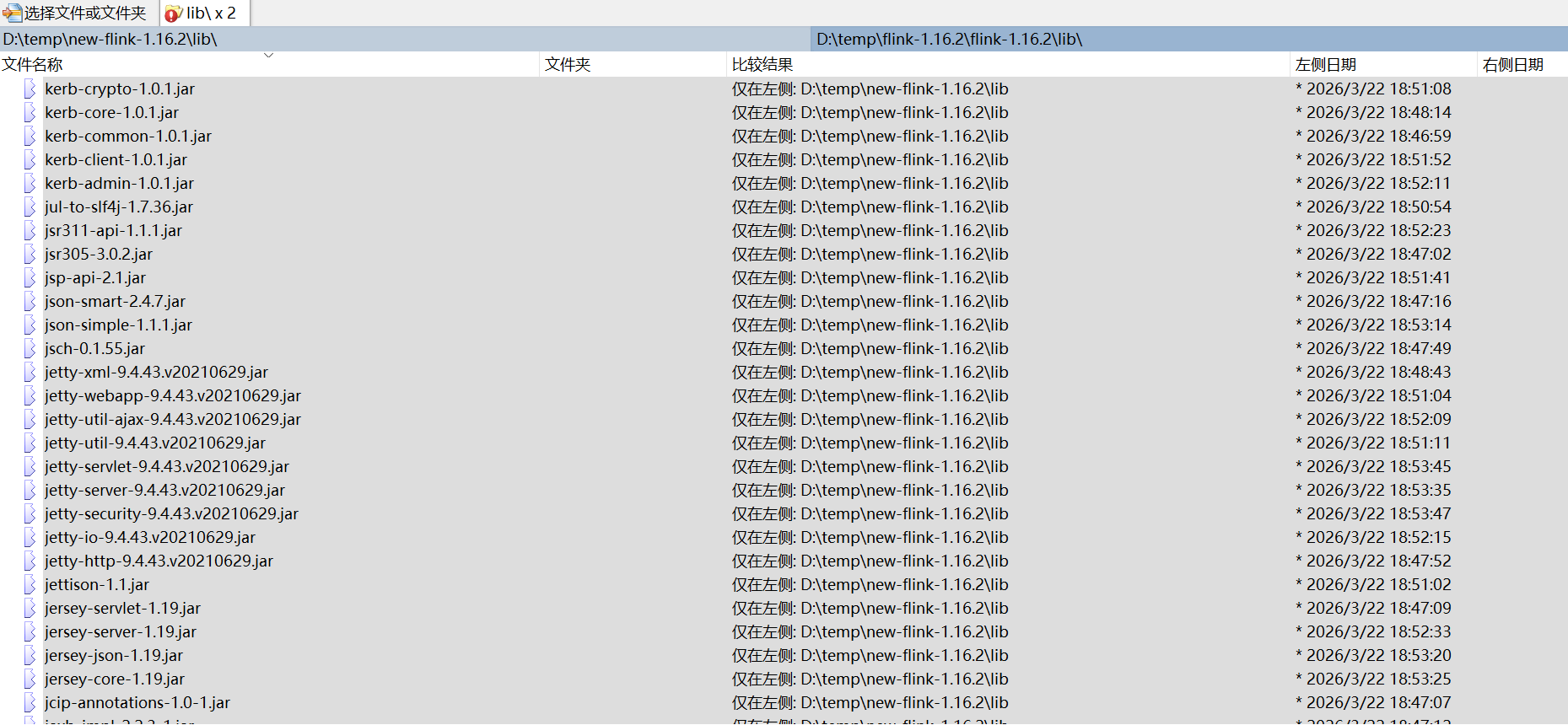
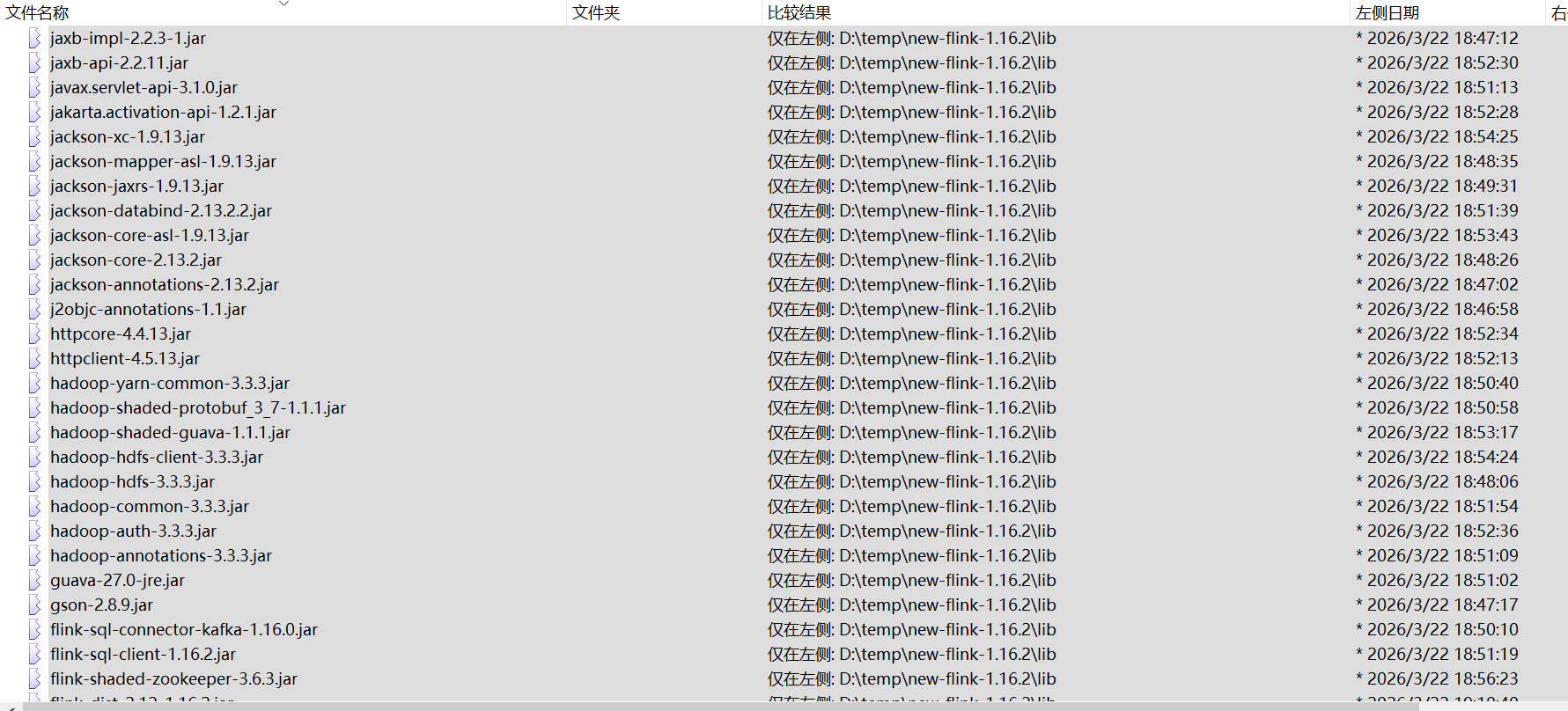
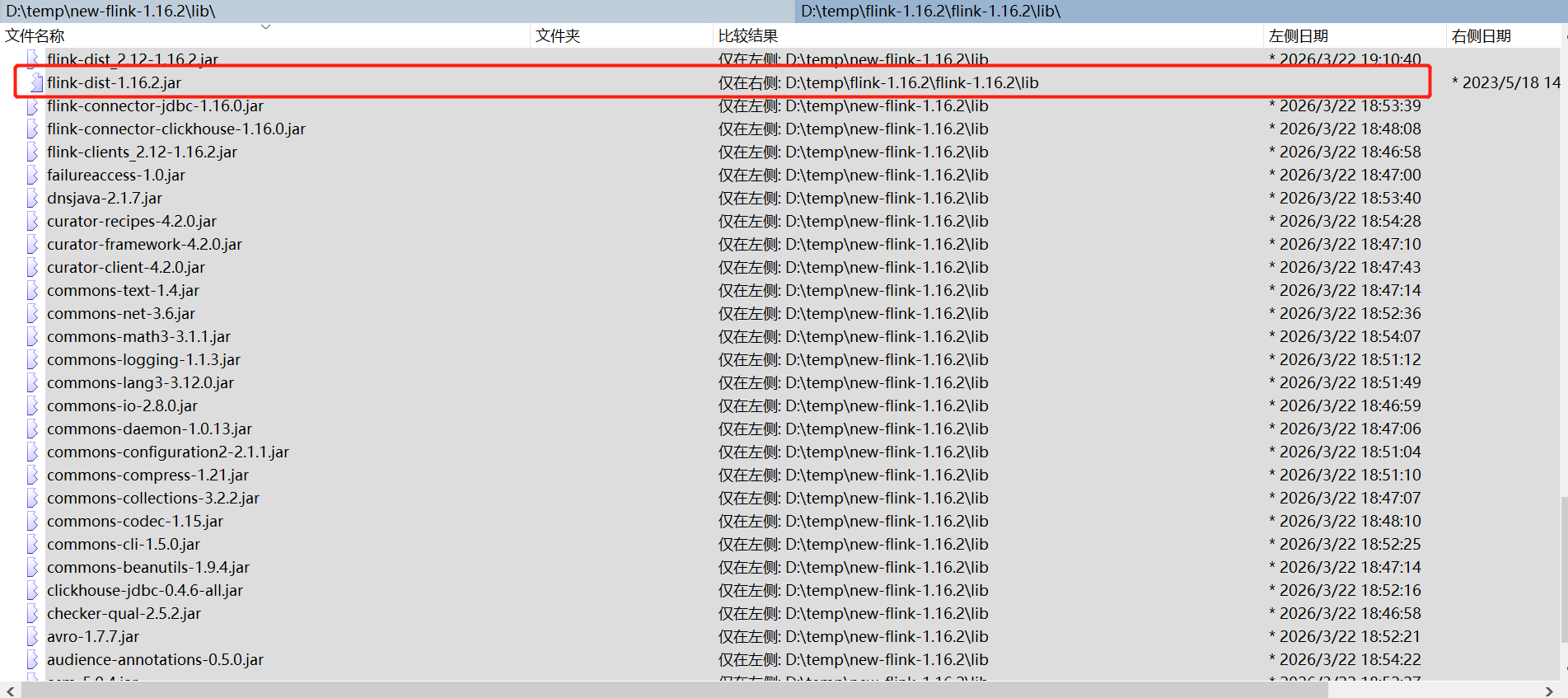

有这么多Jar需要补充,画红框的jar需要删除,否则会报方法没找到,具体见后面坑说明
第二步:往Kafka生产测试数据
创建Kafka Topic
javascript
# 在Kafka服务器上执行
kafka-topics.sh --create \
--bootstrap-server ddp4:9092,ddp3:9092 \
--replication-factor 1 \
--partitions 3 \
--topic user_click_log产生数据
javascript
# 用命令行发送几条测试数据
echo '{"user_id":"user_2","item_id":"item_31","behavior":"click1","ts":1700000000000,"event_time":"2024-01-01T00:00:00"}' | kafka-console-producer.sh --broker-list ddp4:9092,ddp3:9092 --topic user_click_log查看kafka未读消息
javascript
bin/kafka-consumer-groups.sh --bootstrap-server ddp3:9092,ddp4:9092 --describe --group flink-paimon-ck-demo第三步:在ClickHouse中创建目标表(在安装clickhouse机器上操作)
javascript
# cd /opt/datasophon/clickhouse
# ./clickhouse.sh status
# ./clickhouse.sh start #启动ck
# cd bin
# ./clickhouse client --host 127.0.0.1 --port 9000 --user default #登录进ck
-- 创建结果表
CREATE TABLE IF NOT EXISTS default.user_behavior_stats (
dt Date,
behavior String,
pv UInt64,
uv UInt64,
last_item String,
update_time DateTime
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(dt)
ORDER BY (dt, behavior);
-- 查看表结构
DESC default.user_behavior_stats;第四步:启动Flink SQL作业
1.创建hdfs目录
javascript
hdfs dfs -mkdir -p /user/root/paimon_warehouse
hdfs dfs -chmod 777 /user/root/paimon_warehouse2.修改flink 配置(/opt/datasophon/flink/conf/flink-conf.yaml ),连接yarn
javascript
#指定JAVA_HOME
env.java.home: /usr/local/jdk1.8.0_333
# JobManager 内存
jobmanager.memory.process.size: 1024m
# TaskManager 内存
taskmanager.memory.process.size: 1024m
taskmanager.numberOfTaskSlots: 2
# 并行度
parallelism.default: 2
# 执行目标
execution.target: yarn-per-job
# 类加载器配置(关键!)
#classloader.resolve-order: parent-first
#classloader.parent-first-patterns.additional: org.apache.flink.yarn;org.apache.flink.client;org.apache.flink.runtime;org.apache.flink.streaming;org.apache.flink.
api
# 让 Flink 的用户代码类加载器优先加载类,而不是父类加载器(Hadoop 类加载器)
classloader.resolve-order: child-first
# 明确将冲突的包加入 child-first 的加载列表中(可选,但推荐)
classloader.parent-first-patterns.additional: org.apache.flink.yarn;org.apache.flink.client;org.apache.flink.runtime;org.apache.flink.streaming;org.apache.flink.api;org.apache.hadoop;org.apache.commons.math3
# YARN 配置
yarn.application.queue: root.default
yarn.resourcemanager.address: ddp1:8032
yarn.resourcemanager.scheduler.address: ddp1:8030
# 高可用配置(如果需要)
high-availability: zookeeper
high-availability.zookeeper.quorum: ddp1:2181,ddp2:2181,ddp3:2181
high-availability.storageDir: hdfs://nameservice1/flink/ha
# 检查点目录 - 使用 nameservice
state.checkpoints.dir: hdfs://nameservice1/flink/checkpoints
execution.checkpointing.interval: 60s
execution.checkpointing.timeout: 10min
execution.checkpointing.mode: EXACTLY_ONCE
# 保存点目录 - 使用 nameservice
state.savepoints.dir: hdfs://nameservice1/flink/savepoints
# HDFS HA Configuration
fs.hdfs.hadoopconf: /opt/datasophon/hdfs/etc/hadoop
flink.hadoop.dfs.nameservices: nameservice1
flink.hadoop.dfs.ha.namenodes.nameservice1: nn1,nn2
flink.hadoop.dfs.namenode.rpc-address.nameservice1.nn1: ddp1:8020
flink.hadoop.dfs.namenode.rpc-address.nameservice1.nn2: ddp2:8020
flink.hadoop.dfs.client.failover.proxy.provider.nameservice1: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider 3.进flink sql client执行
javascript
# 使用 application 模式直接提交 SQL 任务
# 将 /opt/datasophon 的所有权递归改为 hdfs(或给其他用户写权限)
sudo chown -R hdfs:hdfs /opt/datasophon/flink-1.16.2/log
sudo chown -R hdfs:hdfs /opt/datasophon/flink-1.16.2/
sudo -u hdfs -s
cd /opt/datasophon/flink/bin
env HADOOP_HOME=/opt/datasophon/hdfs HADOOP_CONF_DIR=/opt/datasophon/hdfs/etc/hadoop HADOOP_CLASSPATH=$(/opt/datasophon/hdfs/bin/hadoop classpath) /opt/datasophon/flink-1.16.2/bin/sql-client.sh embedded -t yarn-application -Djobmanager.memory.process.size=1024m -Dtaskmanager.memory.process.size=1024m -Dtaskmanager.numberOfTaskSlots=4 -Dyarn.application.queue=root.default -Dyarn.resourcemanager.address=ddp1:8032 -Dclassloader.resolve-order=parent-first -Dflink.trace.classloading=true
# -Dstate.checkpoints.dir=hdfs:///tmp/flink-checkpoints # #-Dstate.savepoints.dir=hdfs:///tmp/flink-savepoints
然后
Flink SQL>
-- =====================================================
-- 1. 创建Kafka源表(连接Kafka 2.4.1)
-- =====================================================
DROP TEMPORARY TABLE IF EXISTS kafka_source;
CREATE TEMPORARY TABLE kafka_source (
user_id STRING,
item_id STRING,
behavior STRING,
ts BIGINT,
event_time STRING,
row_time AS
COALESCE(
-- 尝试从 event_time 解析
CASE
WHEN event_time IS NOT NULL AND event_time <> ''
THEN TO_TIMESTAMP(event_time)
ELSE NULL
END,
-- 尝试从 ts 解析
CASE
WHEN ts IS NOT NULL AND ts > 0
THEN TO_TIMESTAMP_LTZ(ts, 3)
ELSE NULL
END,
-- 最后兜底用当前时间
CURRENT_TIMESTAMP
)
-- 暂时去掉 WATERMARK,先让数据能写入
) WITH (
'connector' = 'kafka',
'topic' = 'user_click_log',
'properties.bootstrap.servers' = 'ddp4:9092,ddp3:9092',
'properties.group.id' = 'flink-paimon-ck-demo',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
-- 设置 NOT NULL 约束处理策略
SET 'table.exec.sink.not-null-enforcer' = 'DROP';
-- =====================================================
-- 2. 创建Paimon Catalog(数据存储在HDFS)
-- =====================================================
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://nameservice1/paimon_warehouse', -- 改成 nameservice1
'fs.default-scheme' = 'hdfs',
'hadoop-conf-dir' = '/opt/datasophon/hdfs/etc/hadoop' -- 加上这个
);
USE CATALOG paimon_catalog;
-- 创建数据库
CREATE DATABASE IF NOT EXISTS ods;
CREATE DATABASE IF NOT EXISTS dws;
-- =====================================================
-- 3. 创建Paimon ODS表(原始数据存储)
-- =====================================================
CREATE TABLE IF NOT EXISTS ods.user_click_ods (
user_id STRING,
item_id STRING,
behavior STRING,
ts BIGINT,
event_time STRING,
row_time TIMESTAMP(3),
dt STRING,
PRIMARY KEY (dt, user_id, row_time) NOT ENFORCED -- dt 加入主键
) PARTITIONED BY (dt)
WITH (
'bucket' = '4',
'file.format' = 'parquet',
'snapshot.time-retained' = '24 h'
);
-- =====================================================
-- 4. 创建Paimon DWS表(聚合中间层)
-- =====================================================
DROP TABLE IF EXISTS dws.user_behavior_dws;
-- 重建表,添加 ignore-retract
CREATE TABLE IF NOT EXISTS dws.user_behavior_dws (
dt STRING,
behavior STRING,
pv BIGINT,
uv BIGINT,
last_item STRING,
update_time TIMESTAMP(3),
PRIMARY KEY (dt, behavior) NOT ENFORCED
) WITH (
'bucket' = '2',
'merge-engine' = 'aggregation',
'changelog-producer' = 'lookup',
'fields.pv.aggregate-function' = 'sum',
'fields.pv.ignore-retract' = 'false', -- sum 支持 retract
'fields.uv.aggregate-function' = 'max',
'fields.uv.ignore-retract' = 'true', -- 关键:忽略撤回
'fields.last_item.aggregate-function' = 'last_non_null_value',
'fields.last_item.ignore-retract' = 'true', -- 忽略撤回
'fields.update_time.aggregate-function' = 'last_value',
'fields.update_time.ignore-retract' = 'true' -- 忽略撤回
);
-- =====================================================
-- 5. 创建ClickHouse结果表(通过JDBC连接)
-- =====================================================
CREATE TEMPORARY TABLE clickhouse_sink (
dt STRING,
behavior STRING,
pv BIGINT,
uv BIGINT,
last_item STRING,
update_time TIMESTAMP(3),
PRIMARY KEY (dt, behavior) NOT ENFORCED -- 主键必须
) WITH (
'connector' = 'clickhouse',
'url' = 'clickhouse://ddp3:8123',
'database-name' = 'default',
'table-name' = 'user_behavior_stats',
'username' = 'default',
'password' = '',
'sink.batch-size' = '100',
'sink.flush-interval' = '3000',
'sink.update-strategy' = 'update' -- 关键参数:告诉连接器要处理更新
);
-- =====================================================
-- 6. 启动数据流转
-- =====================================================
BEGIN STATEMENT SET;
INSERT INTO ods.user_click_ods
SELECT
user_id,
item_id,
behavior,
ts,
event_time,
row_time,
DATE_FORMAT(row_time, 'yyyy-MM-dd') AS dt
FROM `default_catalog`.`default_database`.kafka_source;
INSERT INTO dws.user_behavior_dws
SELECT
dt,
behavior,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv,
LAST_VALUE(item_id) AS last_item,
CURRENT_TIMESTAMP AS update_time
FROM ods.user_click_ods
GROUP BY dt, behavior;
INSERT INTO clickhouse_sink
SELECT
dt,
behavior,
pv,
uv,
last_item,
update_time
FROM dws.user_behavior_dws;
END;第五步:验证数据
javascript
cd /opt/datasophon/clickhouse
./clickhouse.sh status
./clickhouse.sh start #启动ck
cd bin
./clickhouse client --host 127.0.0.1 --port 9000 --user default #登录进ck
select * from user_behavior_stats;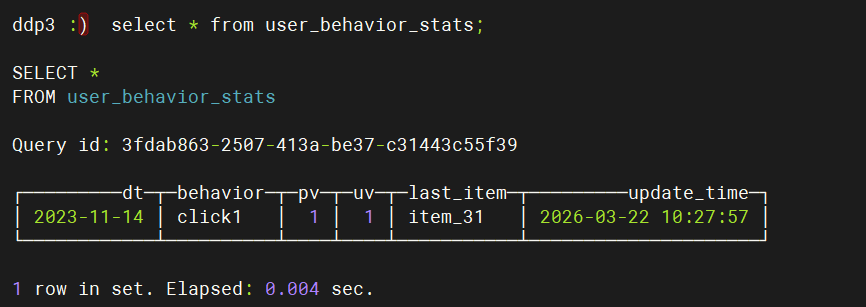
遇到的坑
坑1:Jar 包冲突 - NoSuchMethodError
现象:java.lang.NoSuchMethodError: org.apache.commons.math3.stat.descriptive.rank.Percentile.withNaNStrategy
排查:本地编译的 flink-dist_2.12-1.16.2.jar 与环境的 flink-dist-1.16.2.jar 冲突
解决:移除本地编译版本,使用官方发行版;排除 hadoop-common 中的 math3 依赖
坑2:YARN HA 配置 - ResourceManager 端口不通
现象:yarn application -list 卡住,telnet 8031/8032 失败
排查:ddp1 上 RM 只监听了 8033(Admin 端口),缺少 8031/8032
解决:在 yarn-env.sh 中添加 -Dyarn.resourcemanager.ha.id=rm1/rm2,重启 RM
坑3:HDFS 权限 - Checkpoint 写入失败
现象:Permission denied: user=root123, access=WRITE, inode="/user"
解决:使用 /tmp 目录作为 checkpoint 路径,或创建 /user/root123 目录并授权
坑4:TaskManager Slot 不足
现象:TaskExecutor has no more allocated slots for job
解决:增加 taskmanager.numberOfTaskSlots=4
坑5:Paimon 聚合表 changelog-producer 配置
现象:Pre-aggregate streaming reading is not supported
解决:changelog-producer 改为 lookup 或 full-compaction
坑6:max 聚合函数不支持 retraction
现象:Aggregate function 'max' does not support retraction
解决:添加 fields.uv.ignore-retract='true'
坑7:DataNode/NodeManager PID 目录权限
现象:ERROR: Unable to write in /opt/.../pid. Aborting.
解决:PID 目录权限设为 hdfs:hadoop 775,确保 hdfs 和 yarn 都能写入
坑8:YARN 用户与 HDFS 用户权限分离
现象:datanode can only be executed by hdfs / nodemanager can only be executed by yarn
解决:DataNode 用 hdfs 用户启动,NodeManager 用 yarn 用户启动,通过 hadoop 组共享 PID 目录写权限
最后
统一用户权限管理的重要性
分布式环境排查思路:先看日志,再看端口,最后看权限
生产环境建议:checkpoint 目录独立、资源隔离、监控告警
系统不是安装完就能用,需要各方面调整,也不简单。如需沟通:lita2lz