文章目录
-
- [1. Collection](#1. Collection)
-
- [1.1 方法接口](#1.1 方法接口)
- [1.2 Collection的遍历方式](#1.2 Collection的遍历方式)
- [1.3 Collection总结](#1.3 Collection总结)
- [2. List](#2. List)
-
- [2.1 接口](#2.1 接口)
- [2.2 List集合遍历方式](#2.2 List集合遍历方式)
- [2.3 总结](#2.3 总结)
- [3. ArrayList](#3. ArrayList)
-
- [3.1 源码](#3.1 源码)
- [3.2 迭代器源码](#3.2 迭代器源码)
- [4. LinkedList](#4. LinkedList)
-
- [4.1 方法接口](#4.1 方法接口)
- [4.2 源码](#4.2 源码)
- [5. Set](#5. Set)
-
- [5.1 方法接口](#5.1 方法接口)
- [5.2 遍历方式](#5.2 遍历方式)
- [5.3 总结](#5.3 总结)
- [6. HashSet](#6. HashSet)
-
- [6.1 哈希值](#6.1 哈希值)
- [6.2 底层原理](#6.2 底层原理)
- [6.3 HashSet三个问题](#6.3 HashSet三个问题)
- [7. LinkedHashSet](#7. LinkedHashSet)
-
- [7.1 底层原理](#7.1 底层原理)
- [7.2 总结](#7.2 总结)
- [8. TreeSet](#8. TreeSet)
-
- [8.1 遍历](#8.1 遍历)
- [8.2 排序规则](#8.2 排序规则)
- [8.3 总结](#8.3 总结)
- [9. 总结:使用场景](#9. 总结:使用场景)
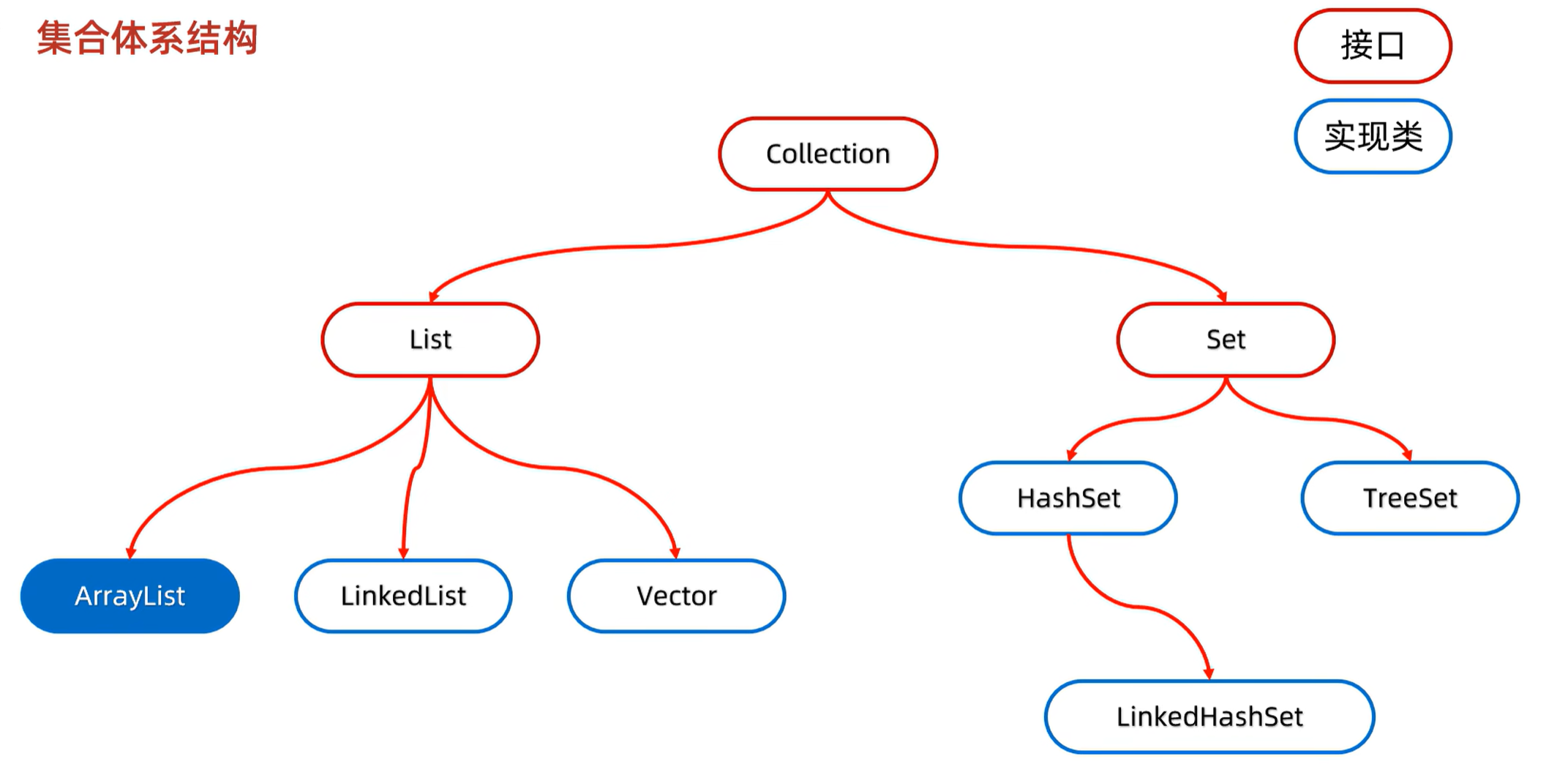
List系列集合:添加的序列是有序(存取顺序一样)、可重复、有索引
Set序列集合:添加的序列是无序(存取顺序可能不一样)、不重复、无索引
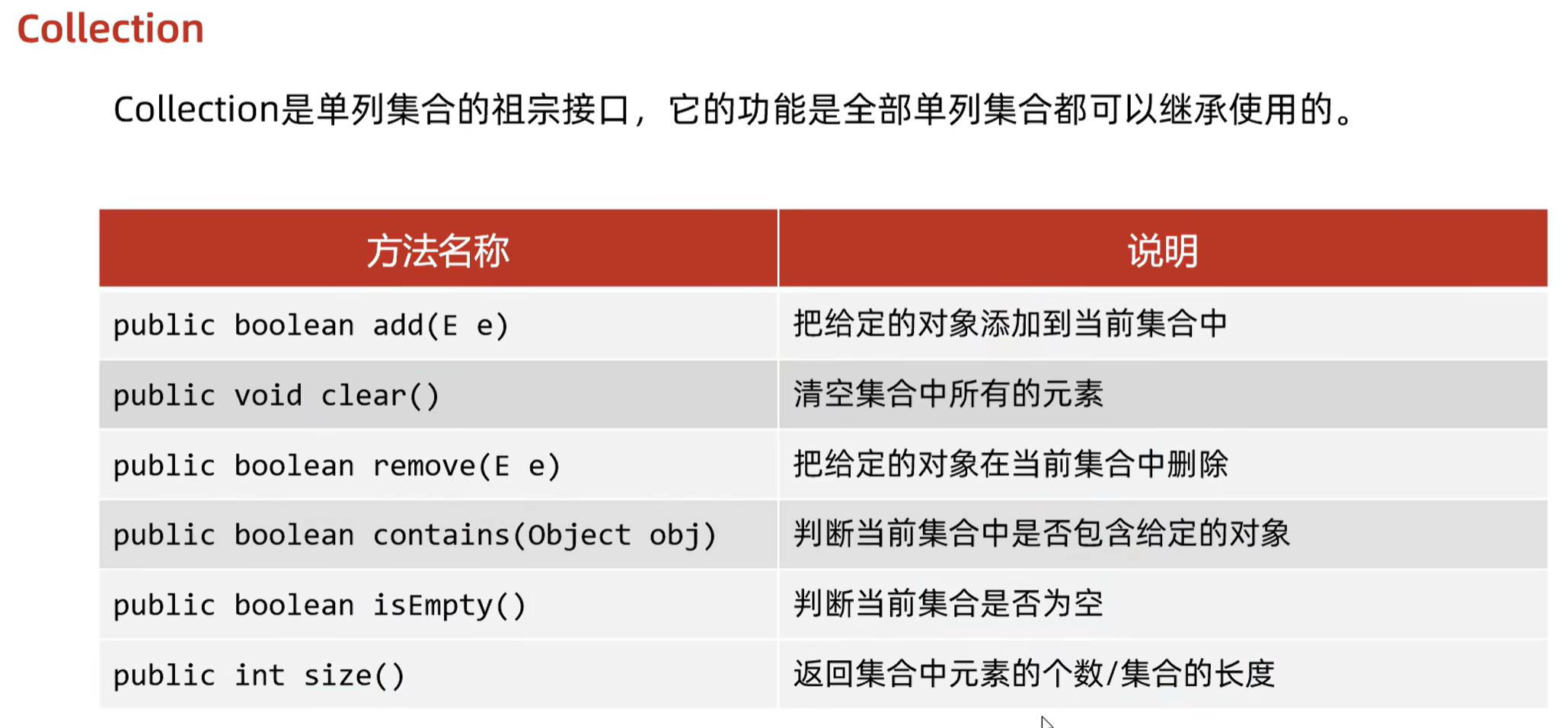
1. Collection
1.1 方法接口
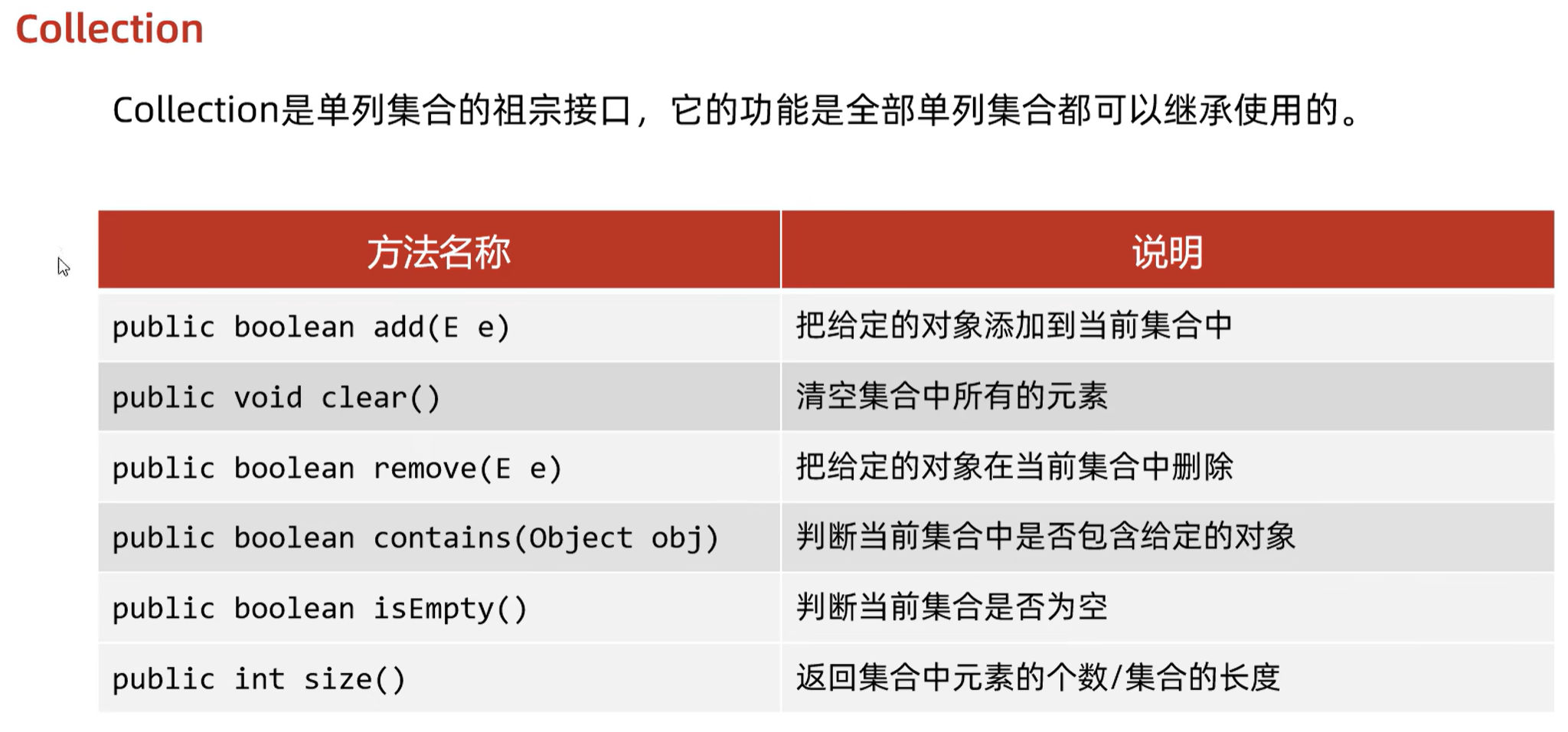
添加元素:
- 细节1,我们向List系列集合中添加元素,那么方法永远返回true,因为List系列集合允许元素重复
- 细节2,我们向Set系列集合中添加元素,如果元素不存在,方法返回true,表示添加成功;
如果元素已经存在,方法返回false,表示添加失败。因为Set系列集合不允许元素重复
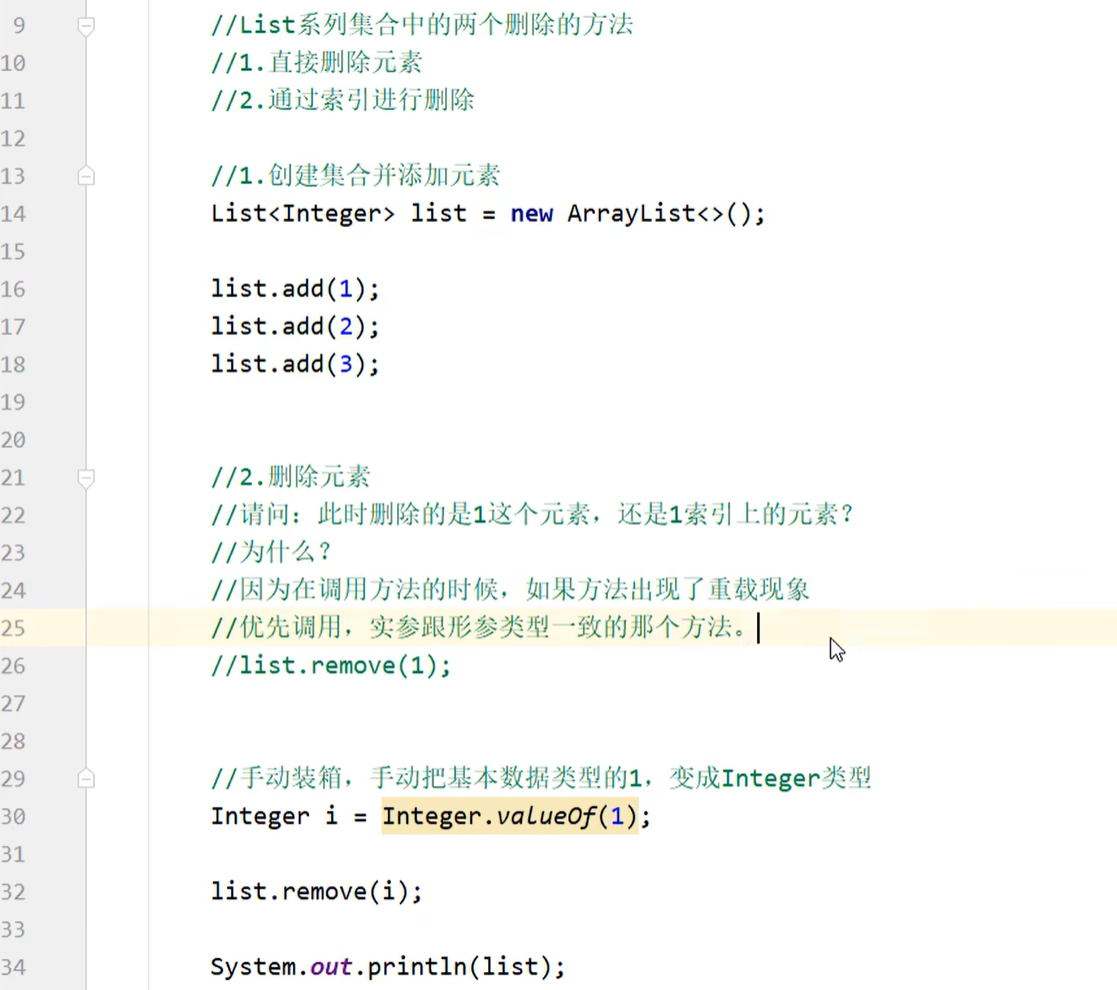
删除:
- 因为Collection中定义的是共性方法,所以此时不能通过索引进行删除。只能通过元素的对象进行删除
- 删除成功返回true,失败返回false
包含:
- 底层是依赖 equals 方法判断是否存在的
- 所以,如果集合中存储的是自定义对象,也想通过contains方法来判断是否包含,那么在javabean中,一定要重写 equals 方法
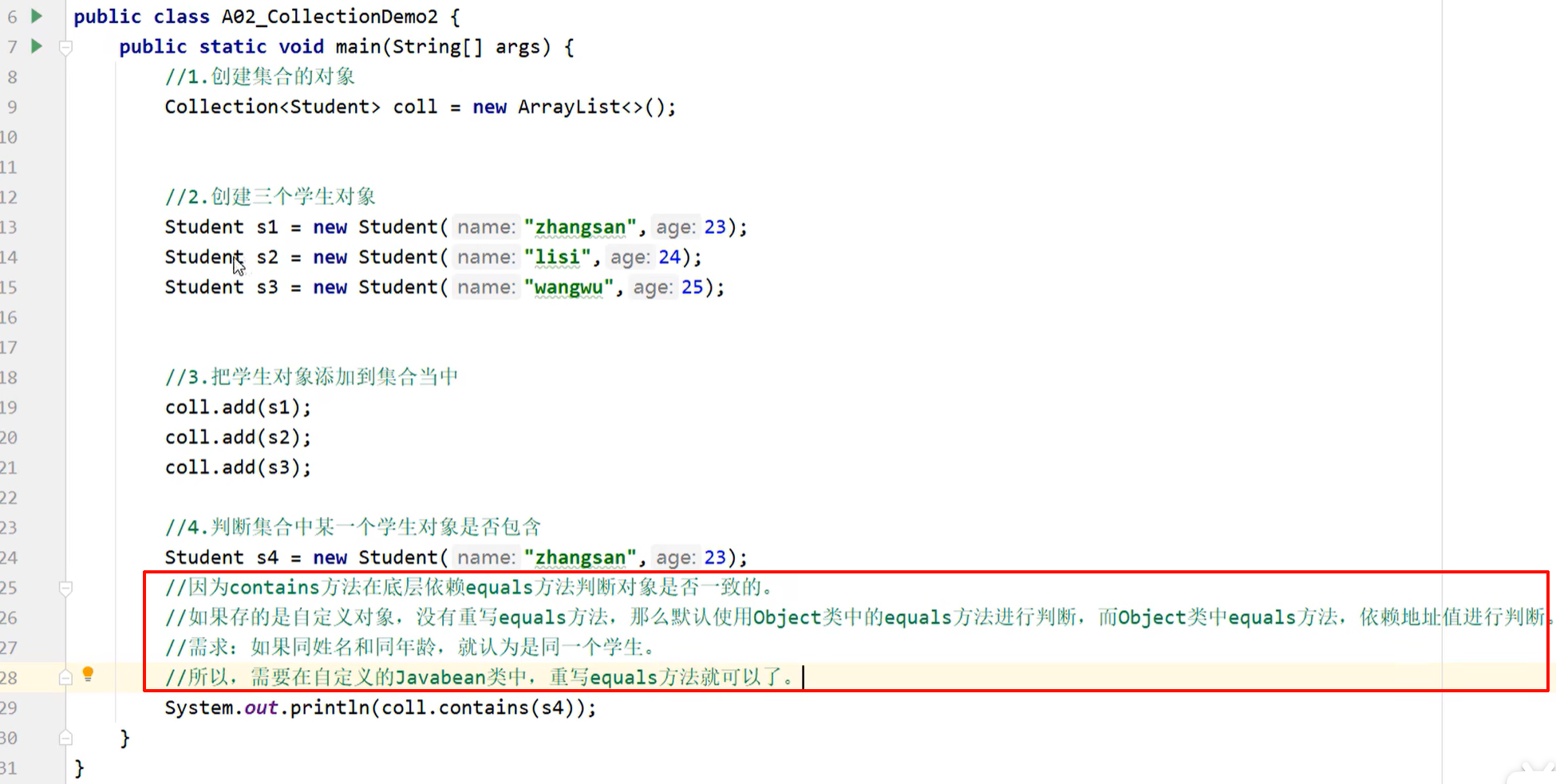
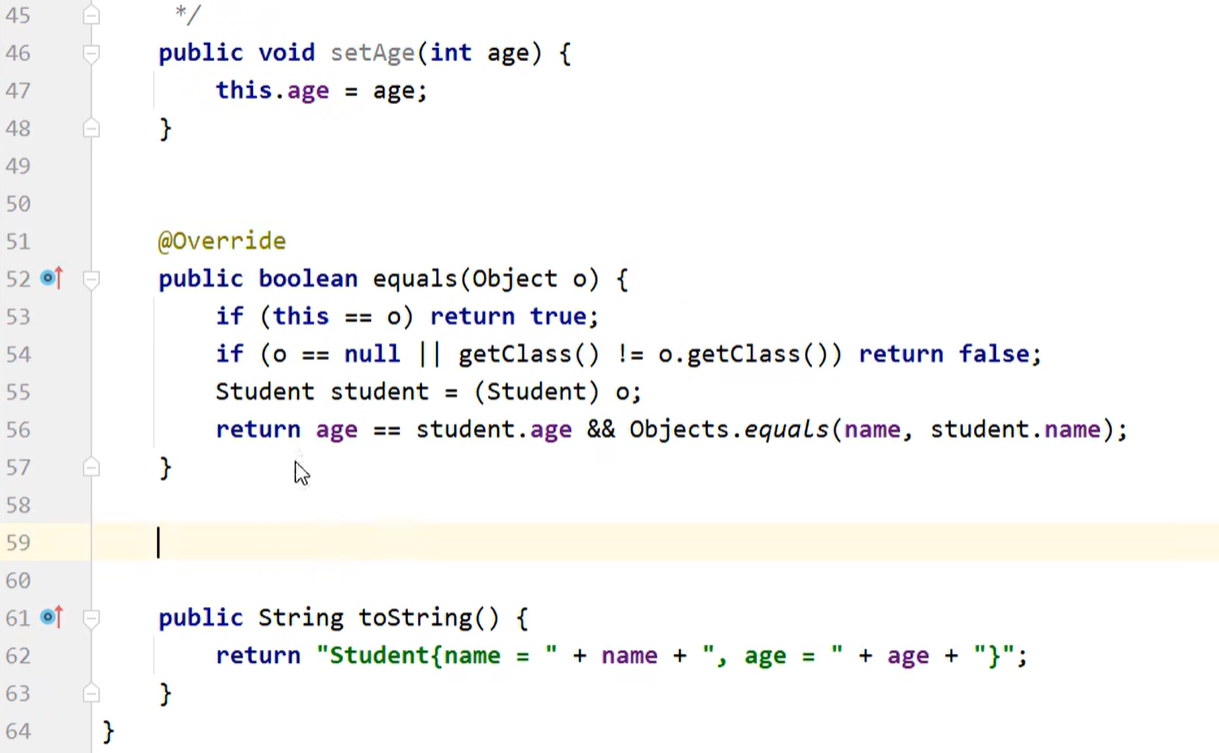
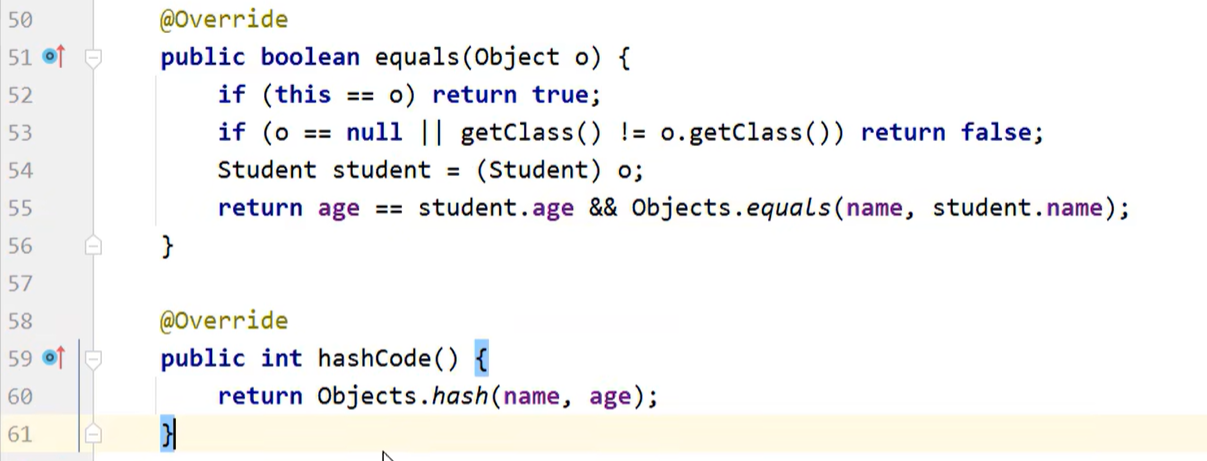
Student 类中重写的 equals 方法:
1.2 Collection的遍历方式
迭代器遍历
迭代器不依赖索引。

使用:



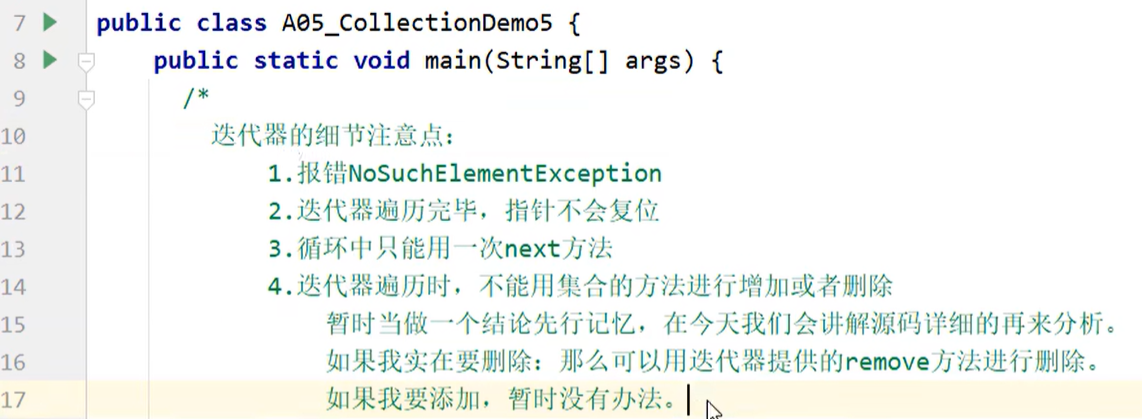
总结:

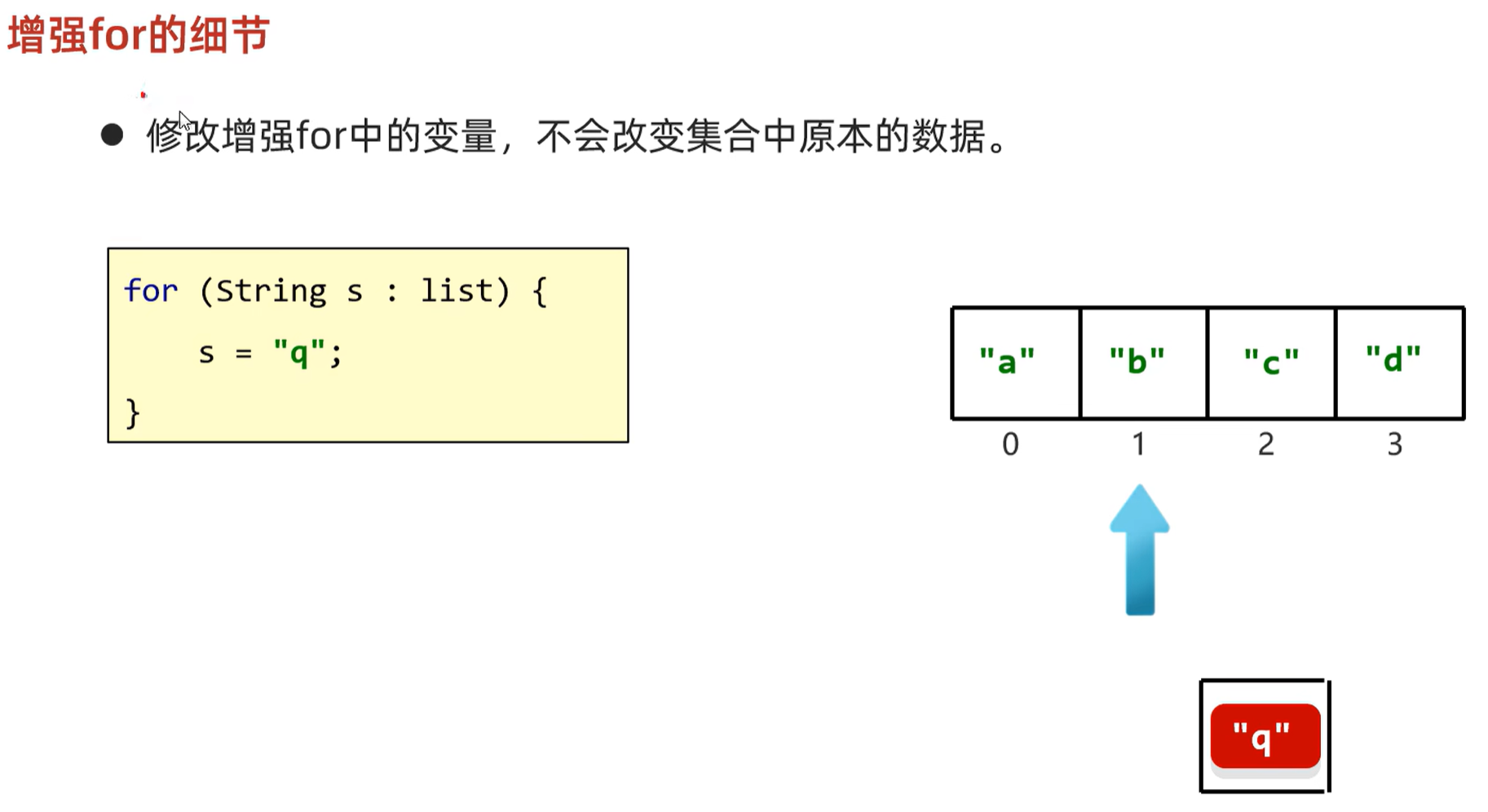
增强for遍历

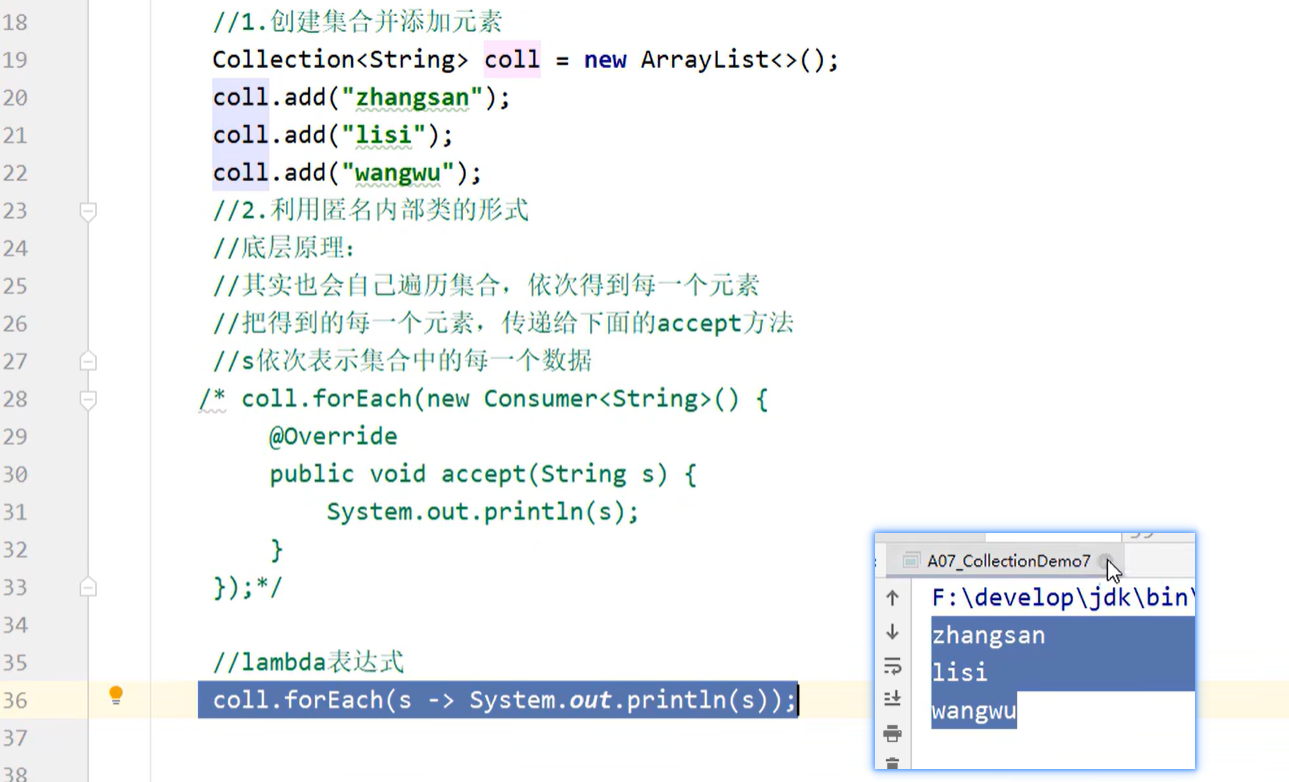
Lambda表达式遍历

先用匿名内部类理解一下:

1.3 Collection总结

2. List
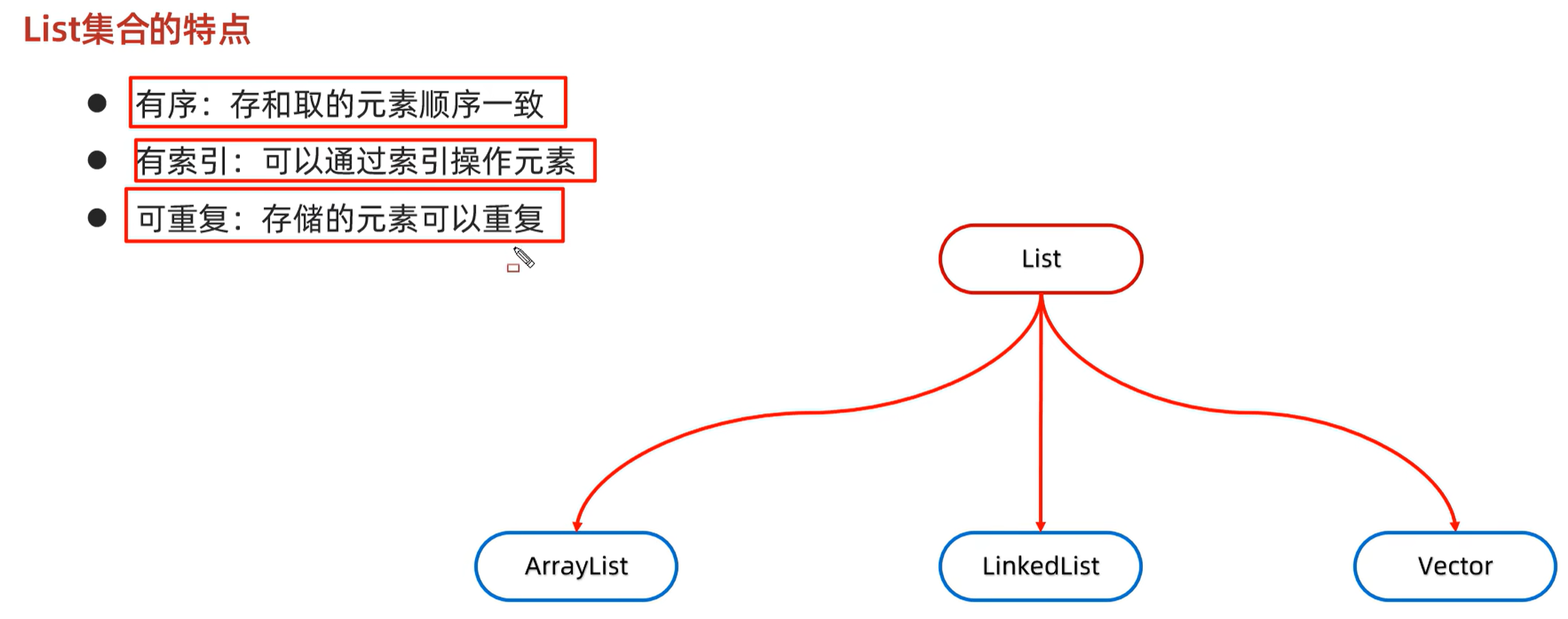
2.1 接口

例子:
2.2 List集合遍历方式
迭代器遍历

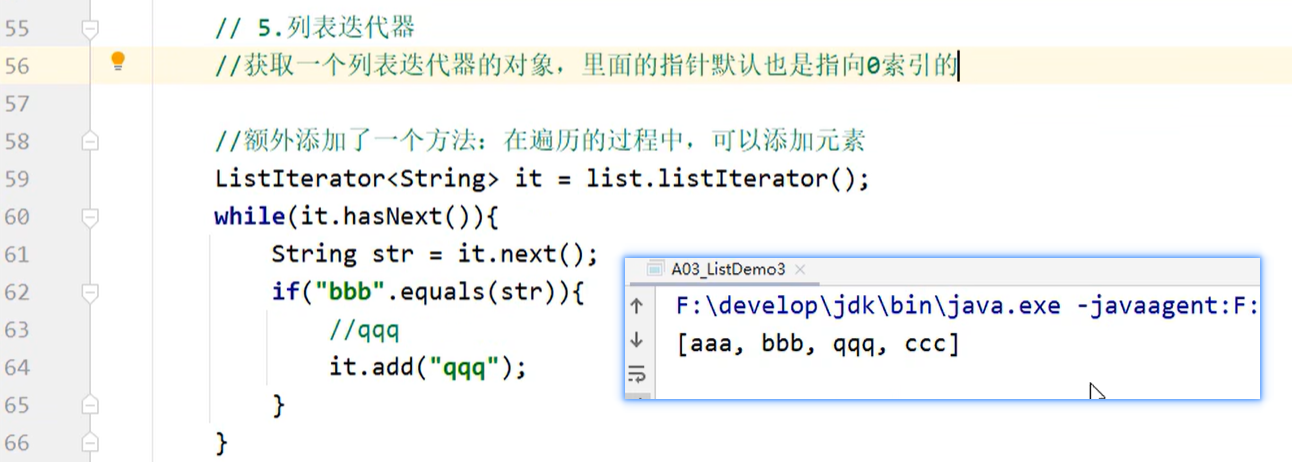
列表迭代器遍历
ListIterator就是在Iterator的基础上添加的prev系列方法,可以实现反向操作,最重要的是添加了add和set方法,可以实现遍历List的时候同时进行添加,修改的操作。

示例一:
java
ArrayList<Character> list = new ArrayList<>();
for (char c = 'A'; c <= 'G'; c++) {
list.add(c);
}
Iterator<Character> it = list.iterator();
while (it.hasNext()) {
char c = it.next(); // next() 返回下一个元素
if (c == 'C') {
it.remove(); // remove() 移除元素
} else {
System.out.print(c + ", ");
}
}示例二:
java
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
for (int i = 1; i <= 3; i++) {
list.add(i);
}
System.out.println(list); // [1, 2, 3]
ListIterator<Integer> li = list.listIterator();
boolean flag = true;
// 如果是正序迭代 或者 有前一个可以迭代的元素
while (flag || li.hasPrevious()) {
int index = 0;
int ele = 0;
if (flag) {
index = li.nextIndex(); // nextIndex() 返回下一个元素的索引
ele = li.next(); // next() 返回下一个元素
} else {
index = li.previousIndex(); // previousIndex 返回上一个元素的索引
ele = li.previous(); // previous() 返回上一个元素
}
if (ele == 1) {
// 如果迭代到的元素是 1 ,则将该元素替换成 0
li.set(0); // set() 用指定元素替换最后返回的元素
} else if (ele == 3) {
li.remove(); // remove() 移除最后返回的元素
}
System.out.println("(" + index + ") = " + ele);
// 判断是否还有下一个可以迭代的元素
if (!li.hasNext()) {
flag = false;
li.add(10); // add() 添加一个元素
}
}
}
java
// 结果
[1, 2, 3]
(0) = 1
(1) = 2
(2) = 3
(2) = 10
(1) = 2
(0) = 0增强for遍历
同上上图
Lambda表达式遍历---forEach()

普通for遍历(因为List集合存在索引)

2.3 总结

3. ArrayList
3.1 源码
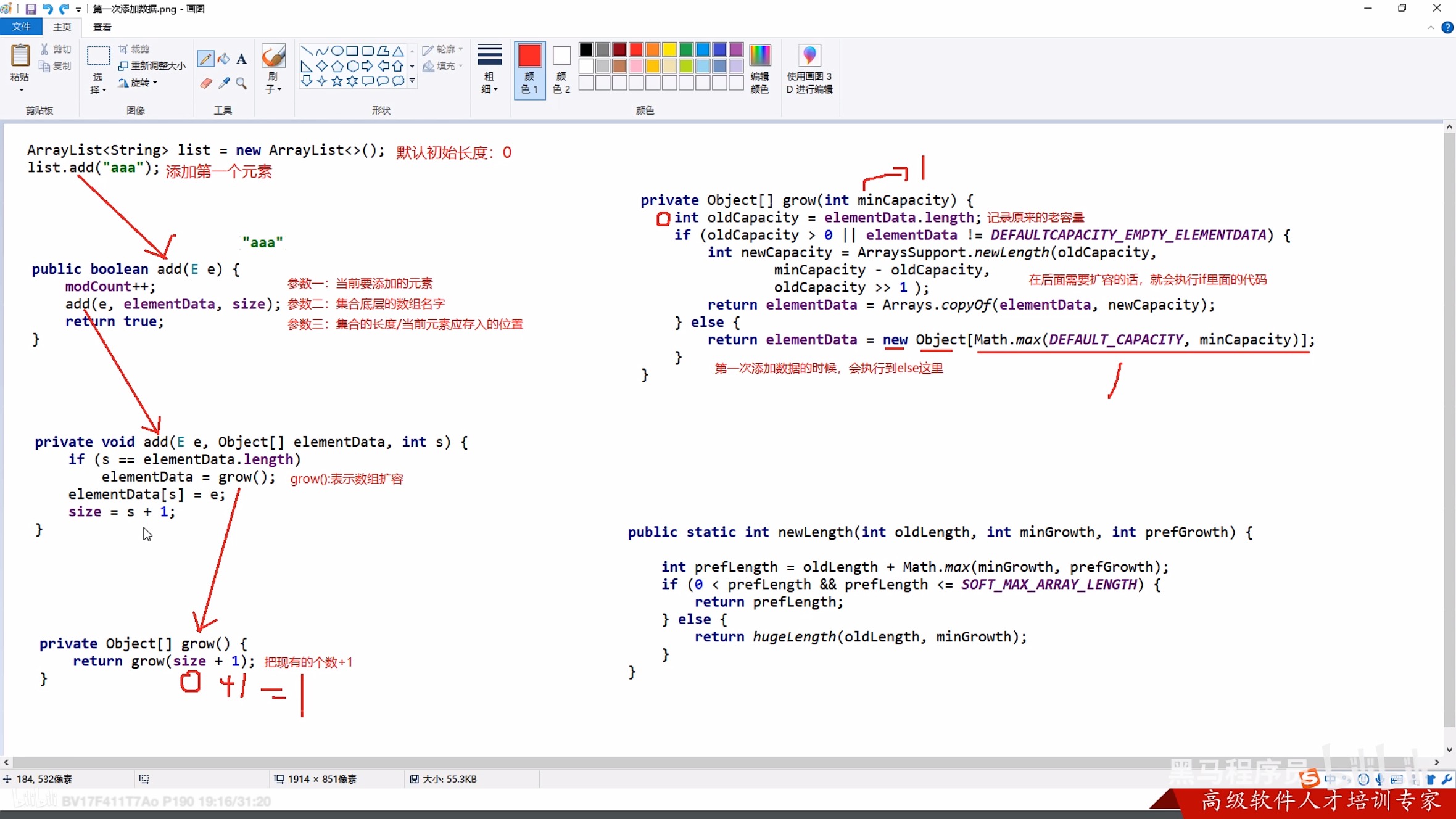
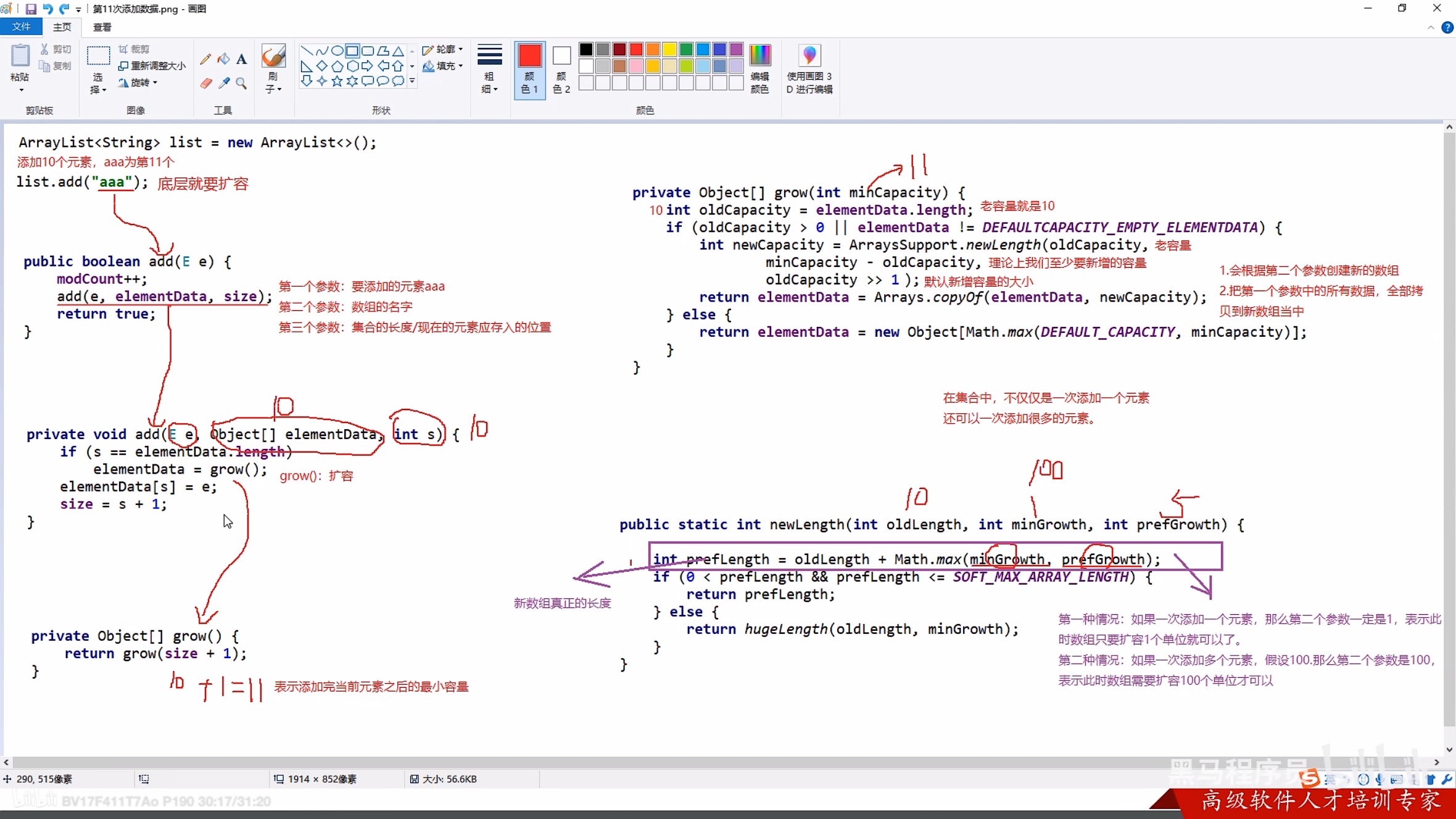
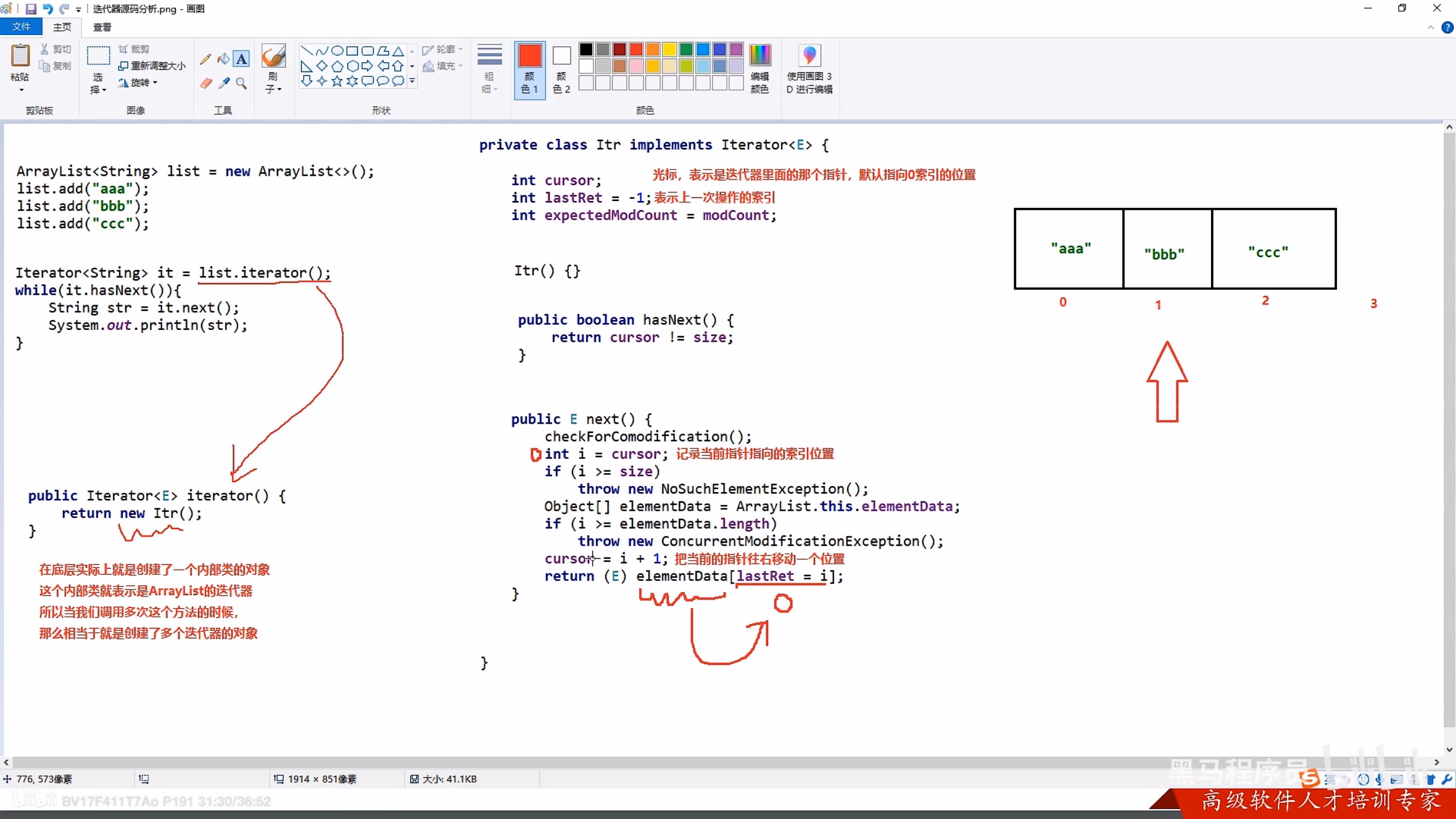
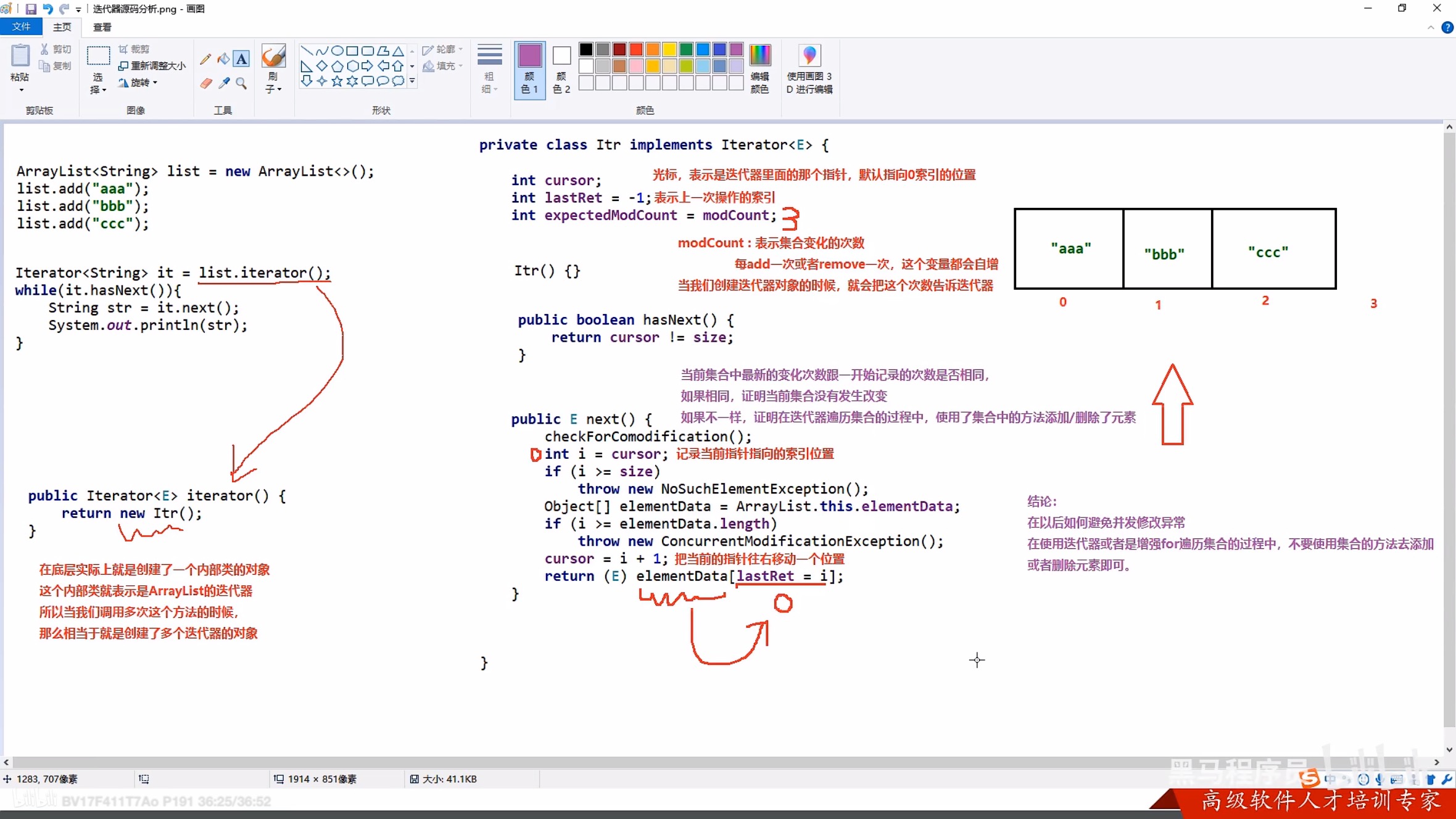
3.2 迭代器源码
4. LinkedList
4.1 方法接口
不怎么用。

4.2 源码
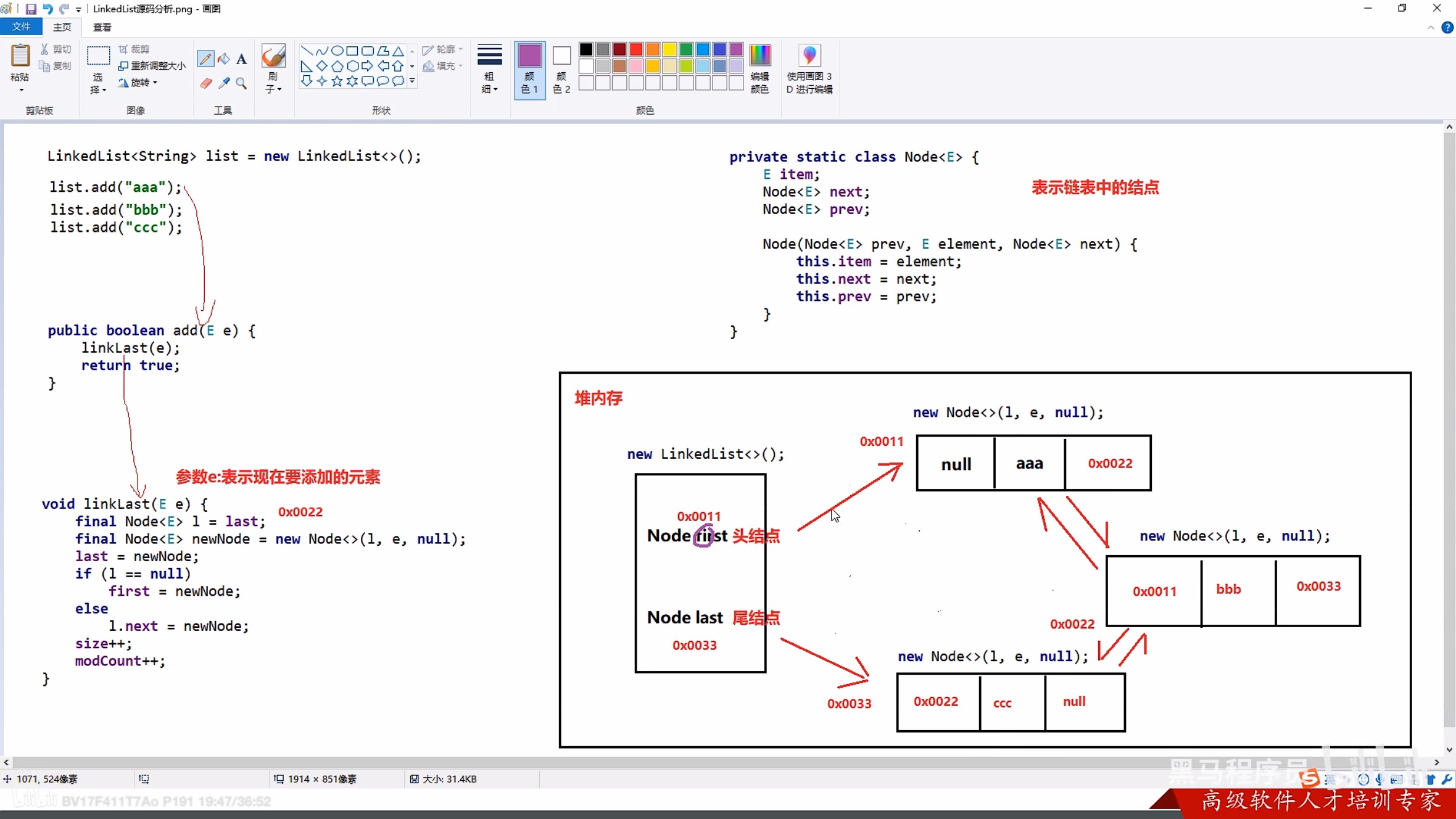
5. Set

5.1 方法接口
仍可以用 Collection 中的:
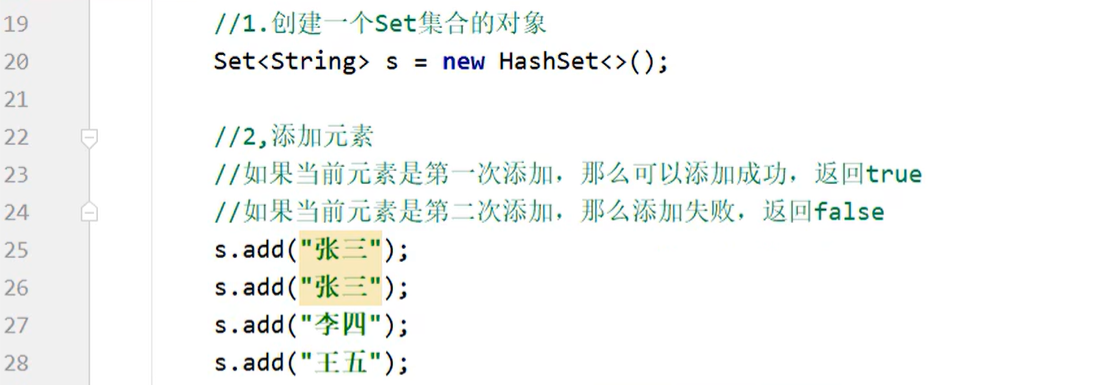

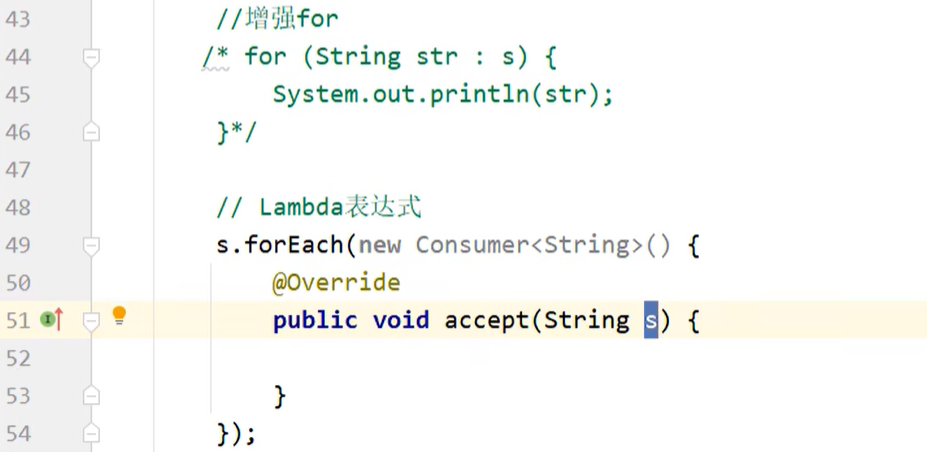
5.2 遍历方式
迭代器遍历

增强for遍历

Lambda表达式遍历

5.3 总结

6. HashSet

6.1 哈希值



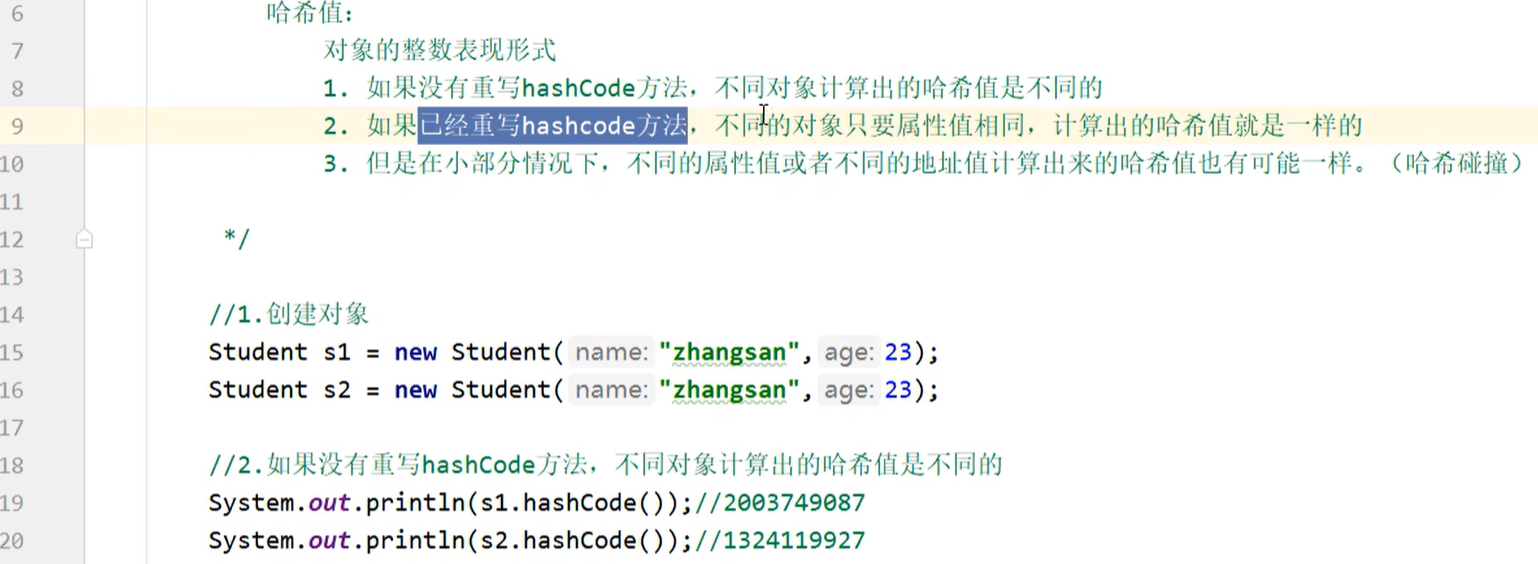
没有重写hashCode()
没有重写 hashCode(),不同对象计算出的哈希值是不同的:
重写hashCode()
重写 hashCode(),不同对象但是相同属性 计算出的哈希值是相同的:

小概率情况下发生哈希碰撞

6.2 底层原理
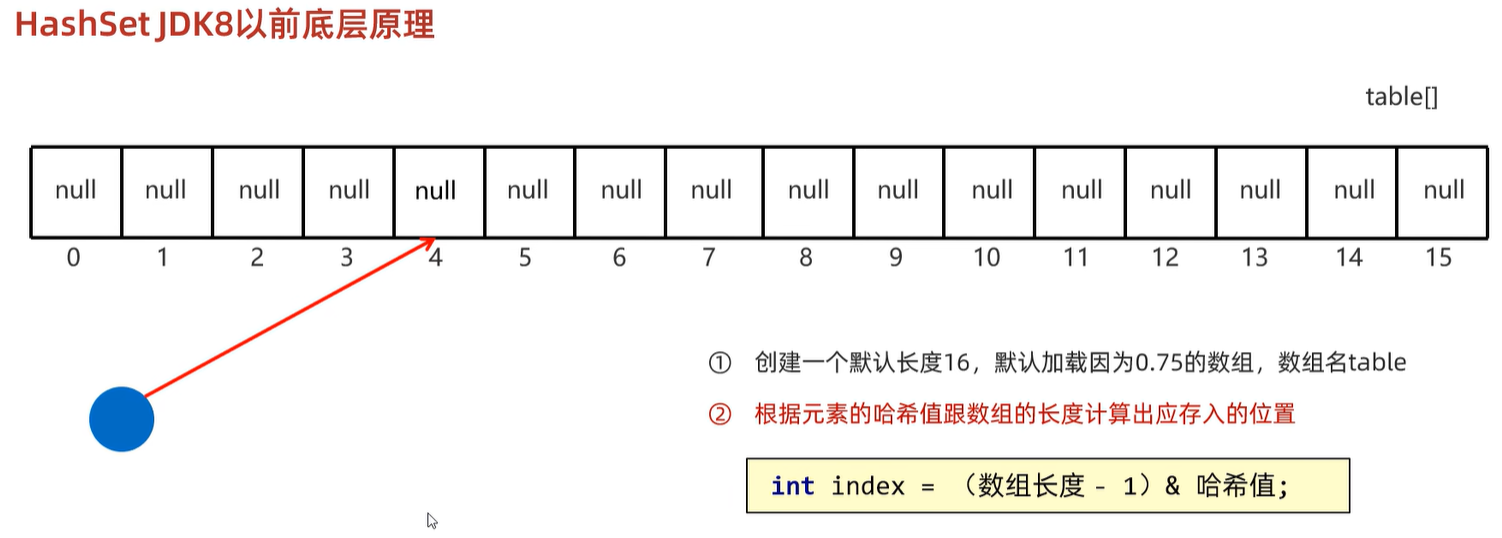
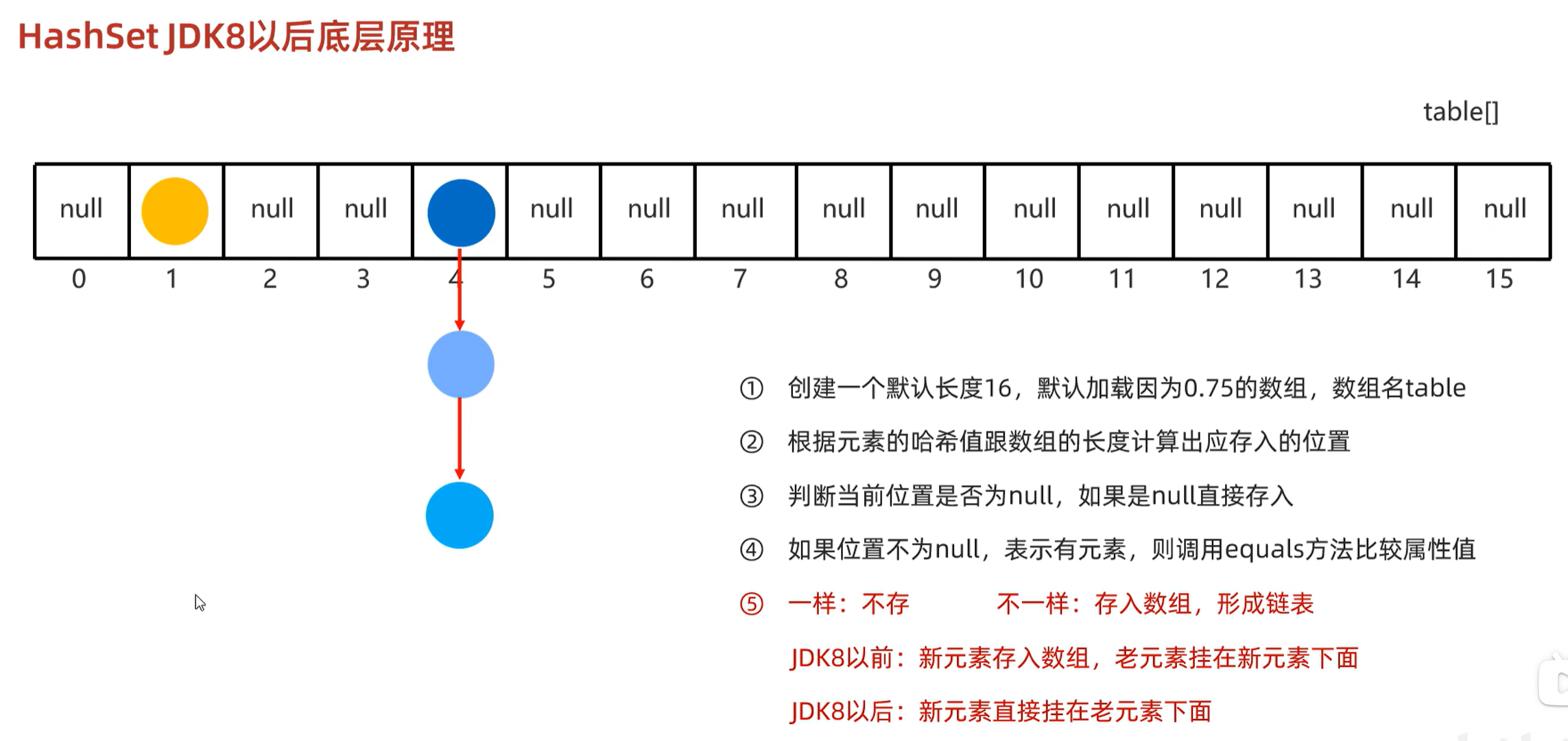
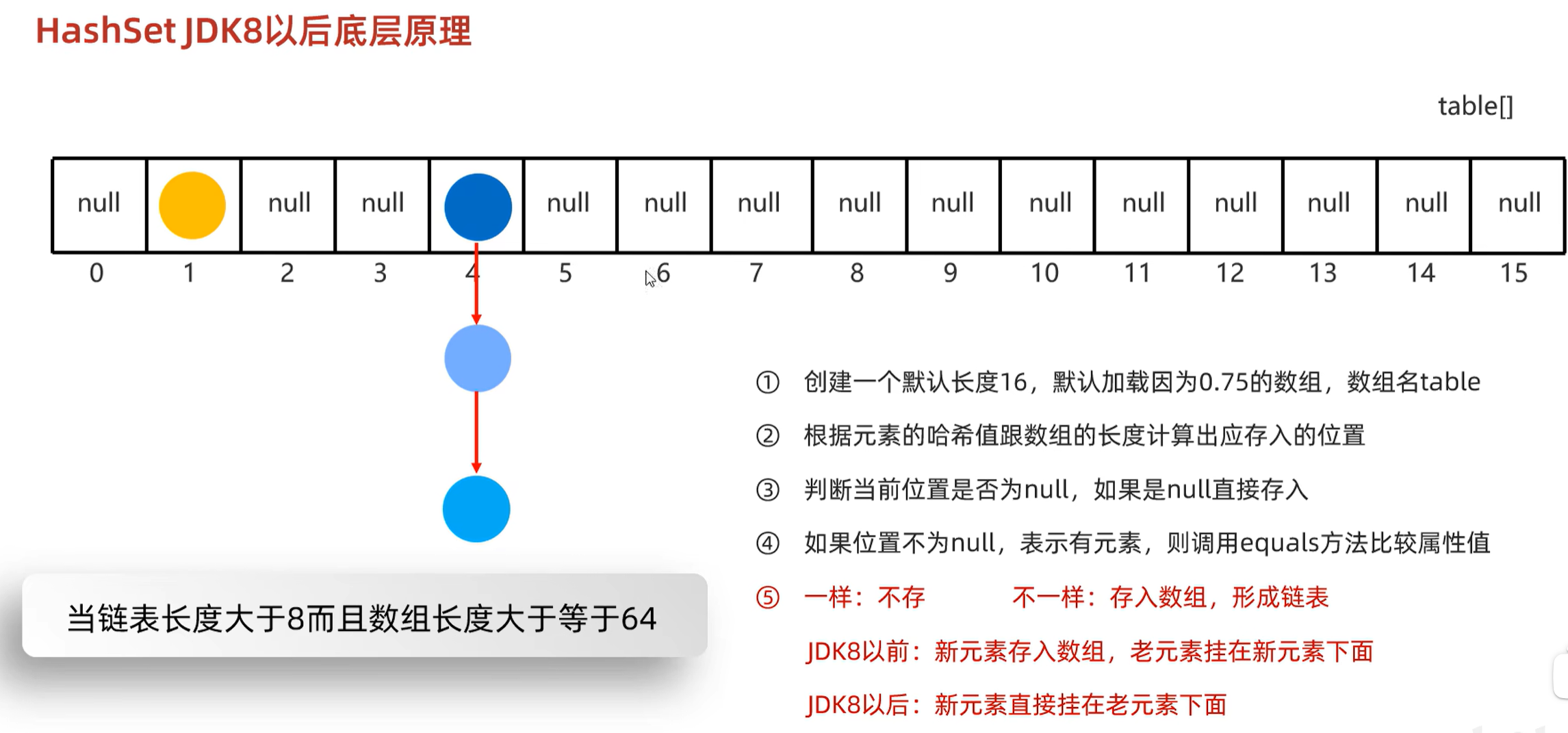
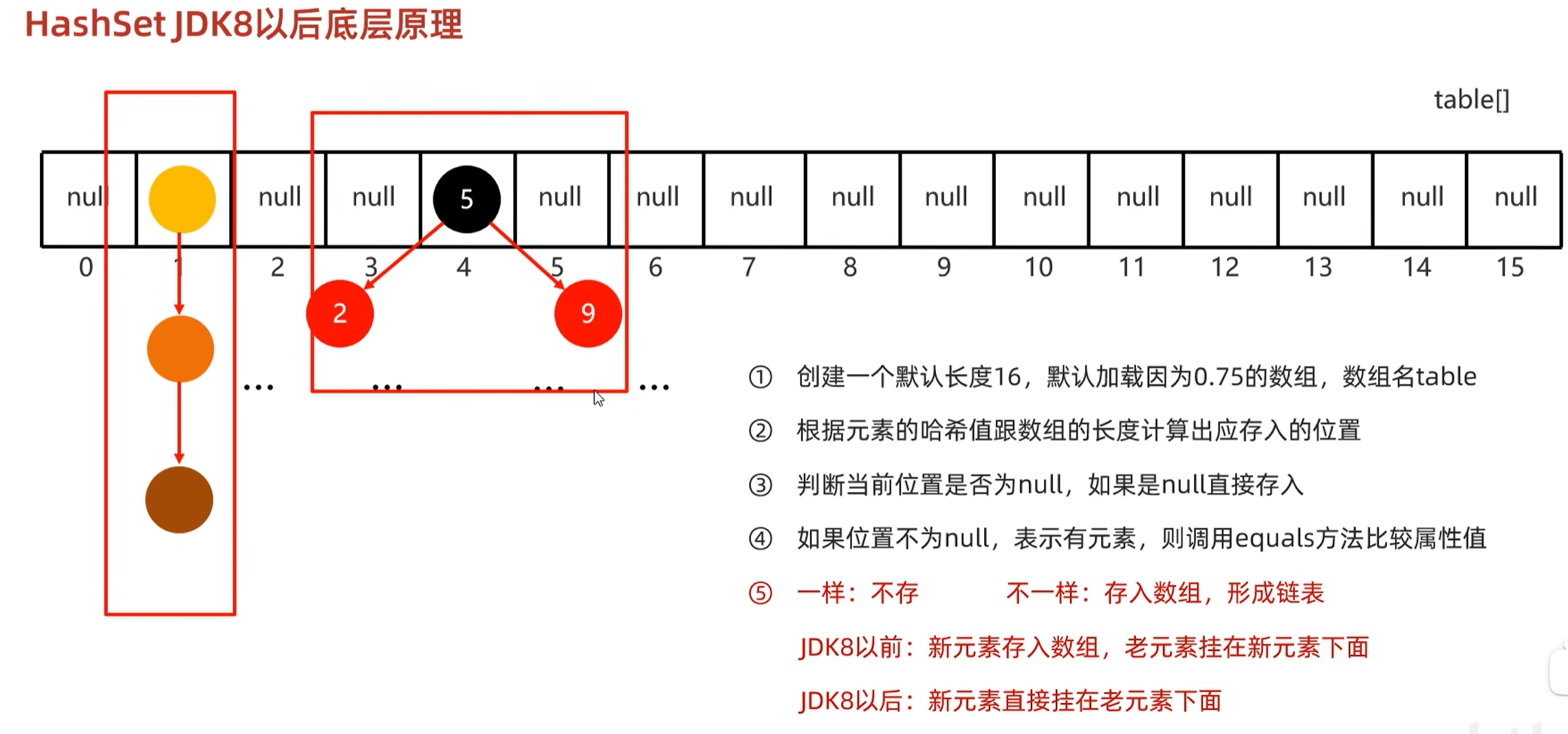

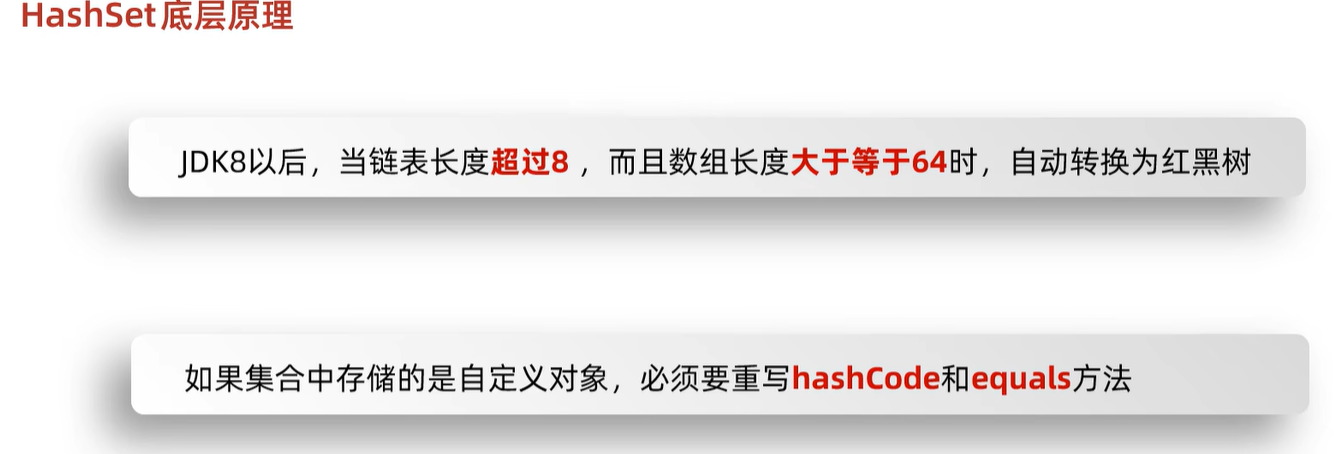
必须符合两个条件才会转换成红黑树:链表长度大于8,并且数组长度大于等于64。
6.3 HashSet三个问题
- 为什么存和取顺序不一样?
HashSet 遍历的时候是从0索引开始的,一条链表一条链表的遍历。如果对应索引是红黑树则会把红黑树遍历
- 为什么没有索引?
他不够纯粹,底层是数组、链表、红黑树三种结构组成的
- 是利用什么机制来保证数据去重的?
hashCode()和equals()两个方法,hashCode()确认存放的位置,equals()判断内部属性值是否相同。如果存放的是自定义类型,一定要重写这两个方法。
7. LinkedHashSet
7.1 底层原理

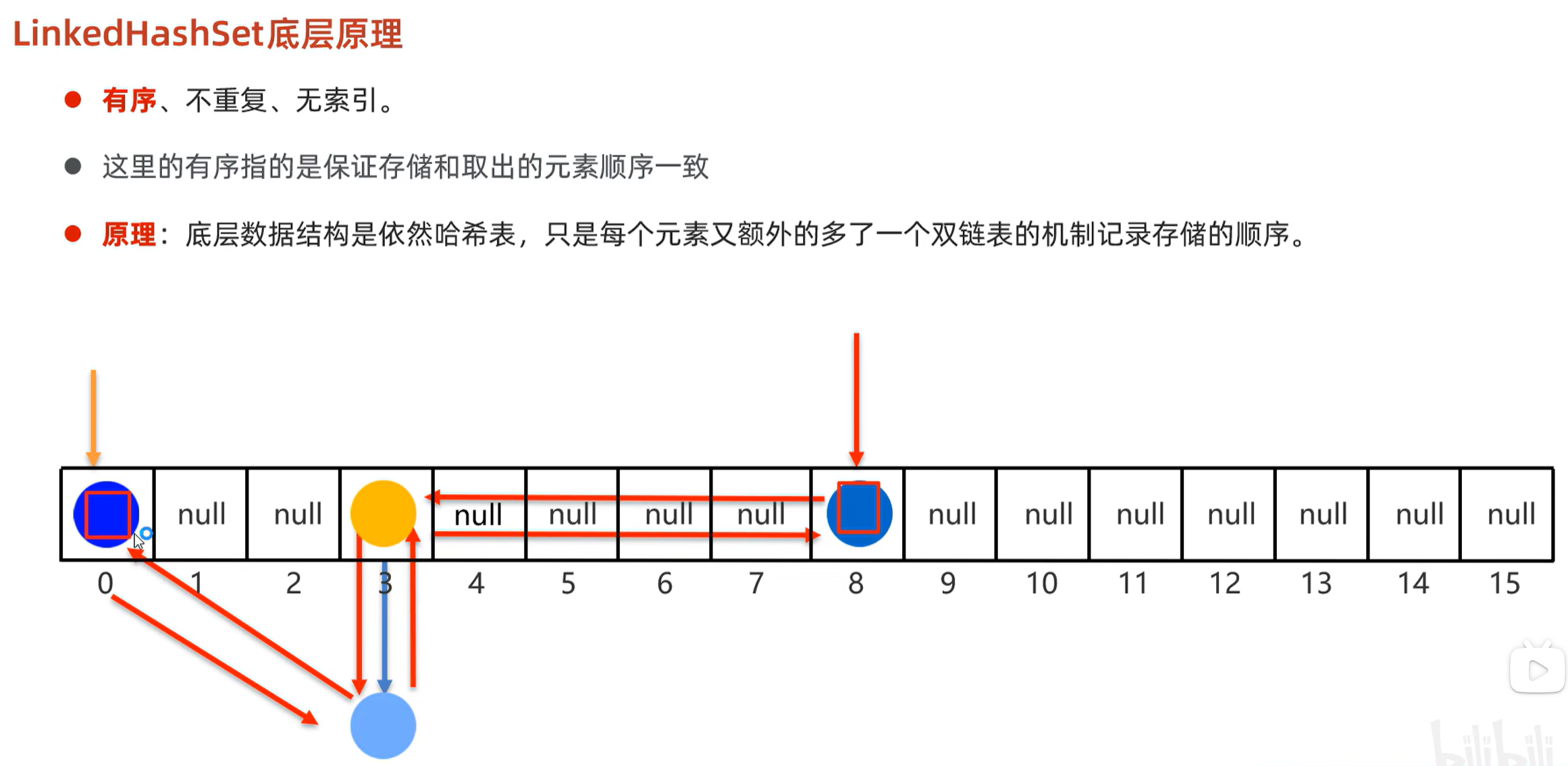
7.2 总结

8. TreeSet

8.1 遍历
迭代器遍历

增强for遍历

Lambda表达式遍历
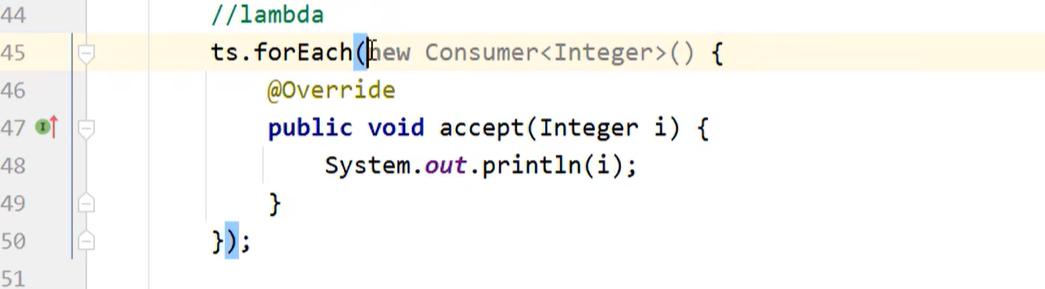
8.2 排序规则


方式一:默认排序规则/自然排序
JavaBean类 实现Comparable接口,重写里面的抽象方法,再指定比较规则。
Student 实现 Comparable 接口,重写里面的抽象方法,再指定比较规则。
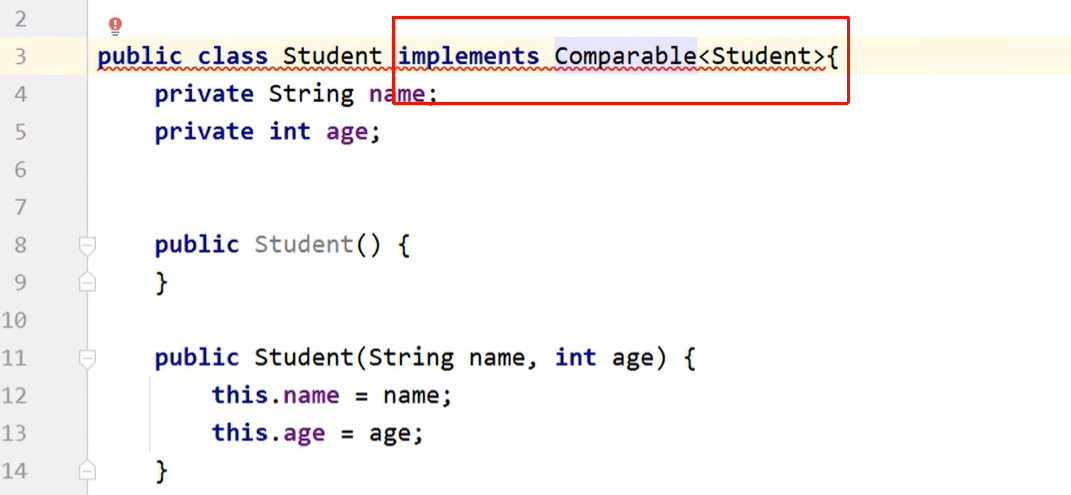

按照年龄升序排列:



方式二:比较器排序
创建 TreeSet 对象的时候,传递比较器 Comparator 制定规则。
使用原则:默认使用第一种,如果第一种不能满足当前需求,就是用第二种。

长度一样则按照原本的 compareTo 方法比较。

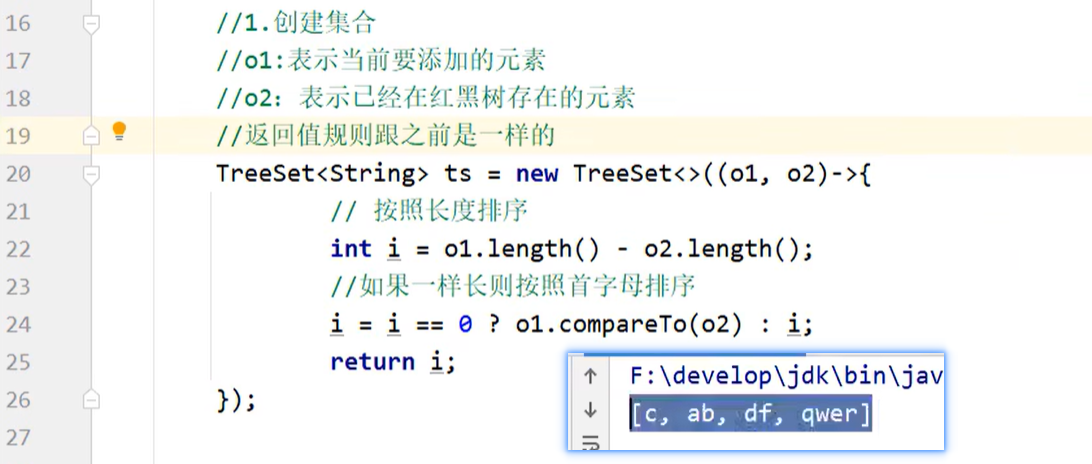
8.3 总结
方式一和方式二都存在,以方式二为准。

9. 总结:使用场景
