很多人都听说过大模型应用开发,但不知道具体是什么或者应该如何学习,今天我就写一个简单个人文档文档助手,分享一些我学习大模型应用开发的心得体会;
一、整体实现思路
加载文档 → 分割文本 → 生成向量 → 存储向量 → 检索相关文本 → 结合大模型回答问题二、环境准备
本地大模型下载(ollama本地大模型如何部署,可以看我之前发过的文章):
# 生成向量嵌入模型
ollama pull nomic-embed-text
# 本地依赖的大模型引擎
ollama pull qwen2.5:7b
需要安装的依赖:
# LangChain 核心组件
pip install langchain
pip install langchain-community
pip install langchain-core
pip install langchain-text-splitters
# 向量数据库与 Ollama 集成
pip install langchain-chroma
pip install langchain-ollama
# 文档加载器依赖
pip install pypdf # PDF 支持
pip install docx2txt # Word 文档支持
# 环境变量管理
pip install python-dotenv三、技术架构
|-------|--------------------------------------|--------------------|
| 组件 | 技术选型 | 说明 |
| 文档加载 | LangChain Loaders | 支持 PDF、TXT、DOCX 格式 |
| 文本分割 | RecursiveCharacterTextSplitter | 智能分割,保留上下文 |
| 向量嵌入 | OllamaEmbeddings (nomic-embed-text) | 本地嵌入模型 |
| 向量存储 | Chroma | 轻量级本地向量数据库 |
| 大语言模型 | ChatOllama | 本地部署的 LLM |
| 链式调用 | LCEL (LangChain Expression Language) | 最新版链式编排 |
四、RAG 原理图
┌─────────────────────────────────────────────────────────────┐
│ 预处理阶段 │
├─────────────────────────────────────────────────────────────┤
│ 文档 → 文本分割 → 向量嵌入 → Chroma 向量库 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ 问答阶段 │
├─────────────────────────────────────────────────────────────┤
│ 用户问题 → 向量检索 → 获取相关文档 → 构建 Prompt → LLM 生成 │
└─────────────────────────────────────────────────────────────┘五、代码详解
5.1 load_documents(file_path: str)
功能:根据文件扩展名加载不同格式的文档
参数:
file_path(str): 文档的绝对或相对路径
返回值:
list[Document]: 文档对象列表,每个对象包含page_content和metadata
支持的文件格式:
|---------|----------------|-------------|
| 扩展名 | 加载器 | 说明 |
| .pdf | PyPDFLoader | PDF 文档,按页分割 |
| .txt | TextLoader | 纯文本文件 |
| .docx | Docx2txtLoader | Word 文档 |
异常处理:
- 不支持的格式抛出
ValueError - 文件读取失败返回空列表
[]
示例:
docs = load_documents("./data/manual.pdf")
# 输出: 加载文档成功: ./data/manual.pdf,共 50 页/段5.2 split_documents(documents: list[Document])
功能:将长文档分割成适合向量化的文本块
参数:
documents(listDocument): 文档对象列表
返回值:
list[Document]: 分割后的文本块列表
分割策略:
RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最大 1000 字符
chunk_overlap=200, # 相邻块重叠 200 字符(保留上下文连贯性)
separators=["\n\n", "\n", "。", "!", "?", ",", "、", " "] # 中文优先分隔符
)设计考量:
chunk_overlap=200:确保上下文不丢失,避免答案被截断- 中文分隔符优先级:段落 → 句子 → 标点 → 词
5.3 init_vector_db(splits)
功能:初始化向量数据库并存储文档向量
参数:
splits(listDocument): 分割后的文本块列表
返回值:
Chroma: Chroma 向量数据库对象
关键配置:
embeddings = OllamaEmbeddings(
model="nomic-embed-text", # 嵌入模型名称
base_url=os.getenv("LOCAL_MODEL_URL") # Ollama 服务地址
)
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化目录
)注意:向量库持久化后,下次启动可直接加载,无需重新向量化。
5.4 build_agent(vectorstore)
功能:构建 RAG 问答链(核心方法)
参数:
vectorstore(Chroma): 已初始化的向量数据库
返回值:
tuple: (rag_chain, get_sources)
-
rag_chain: LCEL 链对象,用于执行问答get_sources: 辅助函数,获取检索来源
LCEL 链式调用详解:
rag_chain = (
RunnablePassthrough.assign(
context=lambda x: "\n\n".join(
[doc.page_content for doc in retriever.invoke(x["question"])]
)
) # 1. 检索相关文档,赋值给 context
| prompt # 2. 填充 Prompt 模板
| llm # 3. 调用大模型生成回答
| output_parser # 4. 解析输出为字符串
)Prompt 模板设计:
你是一个专业的文档问答助手,仅基于以下提供的上下文信息回答用户的问题。
如果上下文没有相关信息,请明确说明"无法从文档中找到相关答案",不要编造内容。
不知道的信息,直接回答不知道。
上下文: {context}
问题: {question}设计要点:
- 明确约束"仅基于上下文回答",防止模型幻觉
- 检索数量
k=2:平衡准确性和响应速度
5.5 qa_interaction(rag_chain, get_sources)
功能:交互式问答界面
参数:
rag_chain: RAG 链对象get_sources: 获取检索来源的函数
交互流程:
1. 显示欢迎信息
2. 循环等待用户输入
├── 输入 "exit" → 退出程序
├── 输入为空 → 提示重新输入
└── 有效问题 → 调用 RAG 链 → 输出答案和来源输出格式:
助手:[模型生成的回答]
[来源] 回答来源(前2条):
来源1:[相关文档片段]...
来源2:[相关文档片段]...六、完整代码
#整体逻辑是:加载文档 → 分割文本 → 生成向量 → 存储向量 → 检索相关文本 → 结合大模型回答问题
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import PyPDFLoader, TextLoader, Docx2txtLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings, ChatOllama
# 核心:最新 LCEL 组件
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 加载环境变量
load_dotenv()
# 1. 加载文档
def load_documents(file_path: str):
"""
加载文档
根据不同文件的后缀加载不同格式的文档
:param file_path: 文档路径
:return: 加载后的文档对象列表
"""
# 获取文件后缀
file_ext=os.path.splitext(file_path)[-1]
try:
if file_ext==".pdf":
loader=PyPDFLoader(file_path)
elif file_ext==".txt":
loader=TextLoader(file_path)
elif file_ext==".docx":
loader=Docx2txtLoader(file_path)
else:
raise ValueError(f"暂时不支持的文件格式: {file_ext}")
# 加载文档并返回
documents=loader.load()
print(f"加载文档成功: {file_path},共{len(documents)} 页/段")
return documents
except Exception as e:
print(f"加载文件失败: {e}")
return []
# 2. 分割文本
def split_documents(documents: list[Document]):
"""
分割文本
将长文本分割成小文本
:param documents: 加载后的文档对象列表
:return: 分割后的文本列表
"""
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个块最大 1000 字符
chunk_overlap=200, # 相邻块重叠 200 字符(保留上下文)
length_function=len, # 字符长度函数(默认)
separators=["\n\n", "\n", "。", "!", "?", ",", "、", " "] # 分隔符优先级:中文分割符
)
# 分割文档
splits = text_splitter.split_documents(documents)
print(f"分割文档成功: 共{len(splits)} 段")
return splits
# 3. 初始化向量库,并存储向量
def init_vector_db(splits):
"""
初始化向量库,并存储向量
:param splits: 分割后的文本列表
:return: Chroma向量库对象
"""
# 初始化 Ollama 本地嵌入模型
embeddings=OllamaEmbeddings(model="nomic-embed-text",base_url=os.getenv("LOCAL_MODEL_URL"))
# 初始化本地 Chroma 向量库并添加文档
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db" # 本地持久化目录(可选,自动创建)
)
print("[OK] 千问嵌入模型已初始化,向量库存储到 ./chroma_db 目录")
return vectorstore
# 4. 构建问答链
def build_agent(vectorstore):
"""
构建问答链
:param vectorstore: Chroma向量库对象
:return: 问答链对象
"""
# 加载模型
llm = ChatOllama(
model=os.getenv("LOCAL_MODEL_NAME"),
base_url=os.getenv("LOCAL_MODEL_URL"),
temperature=0.5
)
# 定义检索器(从向量库检索相关文档,使用 MMR 提高多样性)
retriever = vectorstore.as_retriever(
search_type="mmr", # 使用 MMR 算法,减少重复结果
search_kwargs={"k": 3, "fetch_k": 10} # 返回3个结果,从10个候选中选择
)
# 构建问答链 RAG 链(推荐新方式)
prompt = ChatPromptTemplate.from_template(
"""你是一个专业的文档问答助手。请遵循以下规则:
1. 仅基于提供的上下文信息回答问题
2. 如果上下文没有相关信息,请明确回答"根据文档内容,无法回答该问题"
3. 回答要简洁准确,不要编造内容
上下文:
{context}
问题: {question}
回答:"""
)
# 定义输出解析器
output_parser = StrOutputParser()
# 5. 构建 RAG 链(LCEL 链式调用,核心!)
rag_chain = (
RunnablePassthrough.assign(
context=lambda x: "\n\n---\n\n".join(
[doc.page_content for doc in retriever.invoke(x["question"])])
)
| prompt
| llm
| output_parser
)
# 获取检索来源的辅助函数(用于展示回答来源)
def get_sources(question):
"""检索问题相关的文档来源"""
return retriever.invoke(question)
print("[OK] RAG 问答链构建完成,可开始提问!")
return rag_chain, get_sources
# -------------------------- 6. 交互问答(调用 RAG 链) --------------------------
def qa_interaction(rag_chain, get_sources):
print("\n" + "=" * 50)
print(" RAG 文档问答助手")
print("=" * 50)
print("输入问题进行提问,输入 'exit' 或 'quit' 退出\n")
while True:
try:
question = input("你:").strip() # 去除首尾空格
except (EOFError, KeyboardInterrupt):
print("\n[!] 再见!")
break
# 退出判断
if question.lower() in ("exit", "quit", "q"):
print("[!] 再见!")
break
# 空输入判断
if not question:
print("[!] 请输入有效问题!")
continue
try:
# 调用 RAG 链
answer = rag_chain.invoke({"question": question})
# 获取回答来源
sources = get_sources(question)
# 输出结果
print(f"\n助手:{answer}")
# 去重显示来源
if sources:
print("\n" + "-" * 40)
print("回答来源:")
seen = set()
for i, doc in enumerate(sources):
# 简单去重:取前100字符判断
content_key = doc.page_content[:100]
if content_key not in seen:
seen.add(content_key)
source_info = doc.metadata.get("source", "未知来源")
page_info = doc.metadata.get("page", "")
page_str = f" (第{page_info + 1}页)" if page_info != "" else ""
print(f" [{len(seen)}] {source_info}{page_str}")
print(f" {doc.page_content[:150]}...")
if len(seen) >= 2: # 最多显示2条
break
print("-" * 40)
except Exception as e:
print(f"[错误] 回答生成失败:{e}")
# -------------------------- 主函数 --------------------------
if __name__ == "__main__":
import sys
print("=" * 50)
print(" RAG 文档问答系统")
print("=" * 50)
# 检查是否已有向量库
db_path = "./chroma_db"
use_existing = False
if os.path.exists(db_path):
choice = input("\n检测到已有向量库,是否使用?(y/n): ").strip().lower()
if choice == "y":
use_existing = True
if use_existing:
# 加载已有向量库
embeddings = OllamaEmbeddings(model="nomic-embed-text", base_url=os.getenv("LOCAL_MODEL_URL"))
vector_db = Chroma(
persist_directory=db_path,
embedding_function=embeddings
)
print("[OK] 已加载现有向量库")
else:
# 新建向量库
DOCUMENT_PATH = input("\n请输入文档路径:").strip()
if not DOCUMENT_PATH:
print("[错误] 文档路径不能为空")
sys.exit(1)
docs = load_documents(DOCUMENT_PATH)
if not docs:
sys.exit(1)
splits = split_documents(docs)
vector_db = init_vector_db(splits)
# 构建问答链并开始交互
rag_chain, get_sources = build_agent(vector_db)
qa_interaction(rag_chain, get_sources)七、脚本测试效果
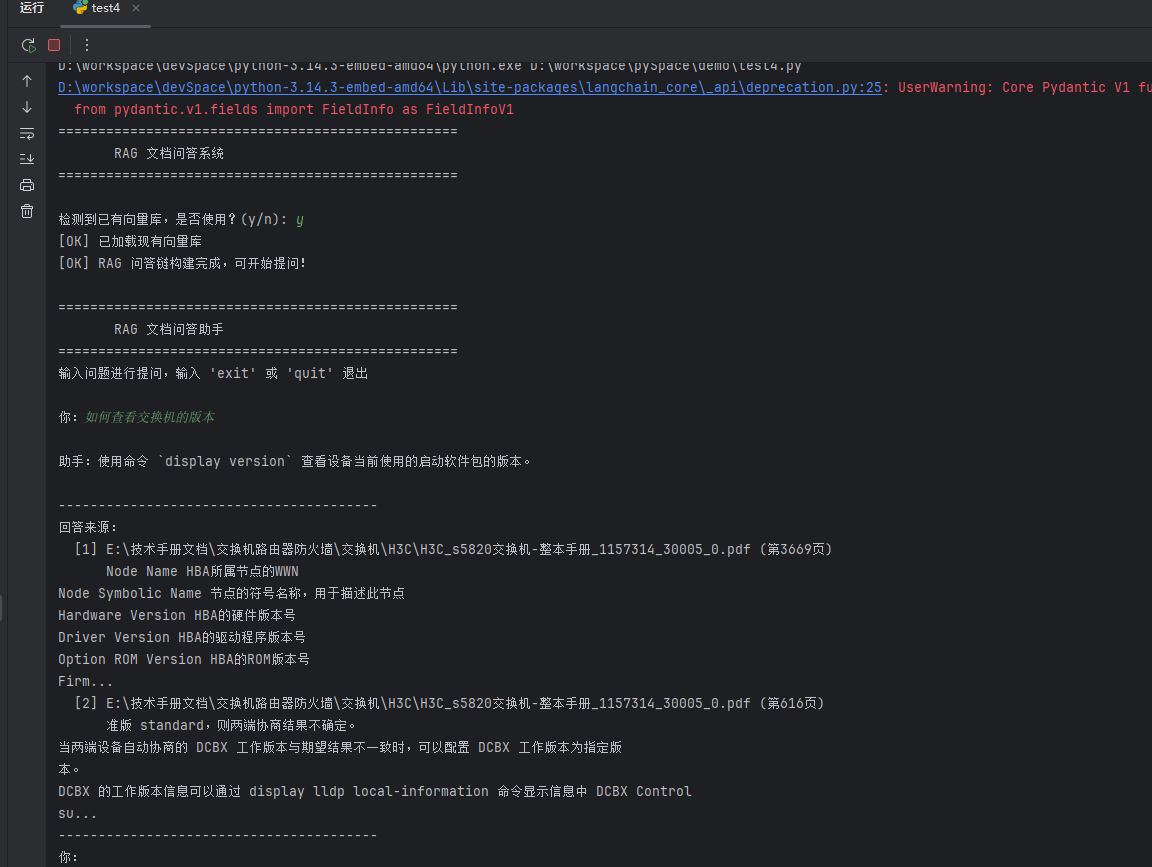
我输入了一个本地的关于交换机的pdf文档,加载到了向量数据库,并保存到了本地;
问题:如何查看交换机的版本
回答效果如下:
总结
通过这一个小小的案例,可以清楚的了解到大模型应用开发的整个流程,数据如何保存,数据如何读取,提示词模板如何设计等,算是一个入门的一个教程,没有写前端页面,有兴趣的也可以写一个前端页面;后续关于大模型应用开发的探索学习我将会持续分享一些心得体会;