今天我准备学习泰坦尼克号生存预测小项目。我问腾讯元宝要代码来学习,不过,它给我的代码,每一个都运行失败,给了我4篇代码,4篇全是运行失败,timeout,应该是泰坦尼克号数据集下载不了吧。算了,看看能不能我自己去网上找一份泰坦尼克号数据集,或者自己手搓一份泰坦尼克号的数据集吧。
虽然代码下载泰坦尼克号数据集是没成功过,但是,腾讯元宝给了我一个网址,我打开之后,看到是泰坦尼克号数据集:
https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv

我把这个网页里的数据,全选复制粘贴(ctrl+a,ctrl+c,ctrl+v)到一个新建的excel文档里,然后点excel文档上方的"数据","分列","分割符号","逗号",完成。之后保存一下表格,就可以了。文件名的话叫做titanic.xlsx。
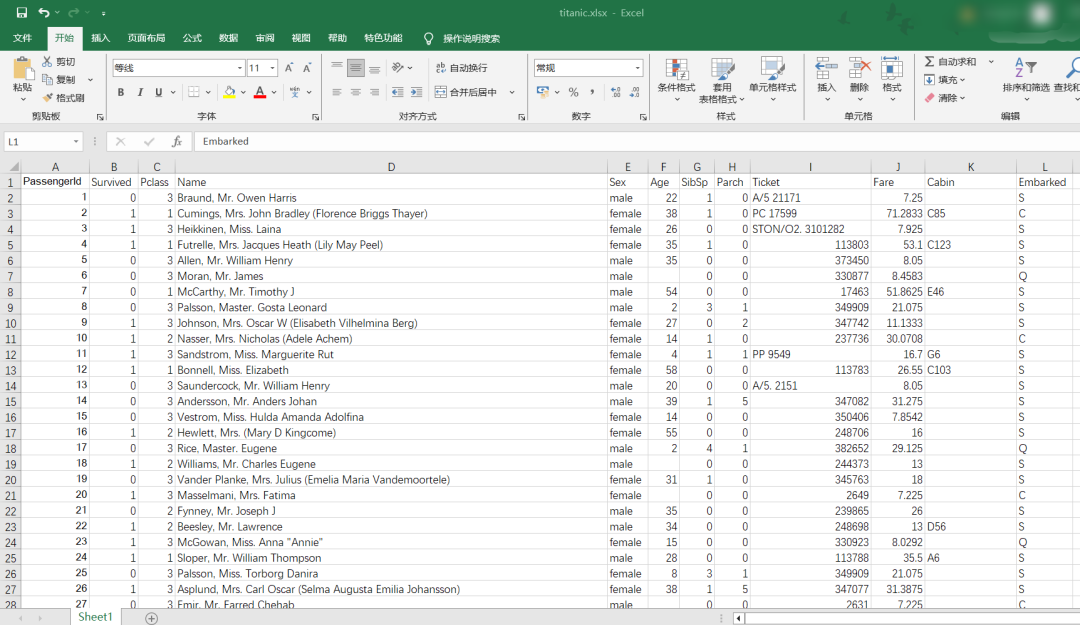
我问了一下腾讯元宝,泰坦尼克号数据集的标头,分别是什么意思呢?
腾讯元宝给我的解释是

我把这个titanic.xlsx文件上传给腾讯元宝,让它给我一份用这个做数据集的泰坦尼克号生存预测的代码。
# 泰坦尼克号生存预测 - 无警告优化版import pandas as pdimport numpy as npimport warnings # 导入警告模块
# 1. 【关键】忽略警告信息,让控制台变干净warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_report
print("🚢 泰坦尼克号生存预测项目启动!")
# ========== 2. 加载数据 ==========# 请确保你的文件名是 titanic.xlsxtry: df = pd.read_excel('titanic.xlsx') print(f"✅ 数据加载成功!样本数: {len(df)}")except FileNotFoundError: print("❌ 找不到文件 titanic.xlsx,请确保文件和代码在同一目录下!") exit()
# ========== 3. 缺失值处理 ==========print(f"\n🔍 正在处理缺失值...")# 根据你的数据情况:# Age(年龄): 填中位数 (最稳健)df['Age'].fillna(df['Age'].median(), inplace=True)
# Embarked(登船港口): 填众数 (出现最多的那个)df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True)
# Cabin(船舱号): 缺失太多,我们标记为 'Unknown'df['Cabin'].fillna('Unknown', inplace=True)
# Fare(票价): 如果测试集里有缺失,也填中位数 (防御性编程)if df['Fare'].isnull().sum() > 0: df['Fare'].fillna(df['Fare'].median(), inplace=True)
print("✅ 缺失值处理完成。")
# ========== 4. 特征工程 (提取关键信息) ==========# 从姓名中提取头衔 (Mr, Miss, Mrs等),这通常很有用df['Title'] = df['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)# 把罕见的头衔归为一类df['Title'] = df['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')df['Title'] = df['Title'].replace('Mlle', 'Miss')df['Title'] = df['Title'].replace('Ms', 'Miss')df['Title'] = df['Title'].replace('Mme', 'Mrs')
# 家庭大小df['FamilySize'] = df['SibSp'] + df['Parch'] + 1# 是否独自一人df['IsAlone'] = 0df.loc[df['FamilySize'] == 1, 'IsAlone'] = 1
# ========== 5. 数据编码 (把文字变成数字) ==========# 性别df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})# 登船港口df['Embarked'] = df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})# 头衔title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}df['Title'] = df['Title'].map(title_mapping)df['Title'].fillna(0, inplace=True) # 填充未匹配到的
# 船舱等级 (原本就是数字,不用动)# Pclass 保持不变
# ========== 6. 选择最终用于训练的特征 ==========features = ['Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'FamilySize', 'IsAlone', 'Title']target = 'Survived'
X = df[features]y = df[target]
# ========== 7. 划分数据集 & 标准化 ==========X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化 (让模型跑得更快更好)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
# ========== 8. 训练模型 ==========print("\n🏋️ 正在训练模型...")model = LogisticRegression(max_iter=1000)model.fit(X_train_scaled, y_train)
# ========== 9. 评估模型 ==========predictions = model.predict(X_test_scaled)accuracy = accuracy_score(y_test, predictions)print(f"\n🎉 模型训练完成!测试集准确率: {accuracy:.2%}")
print("\n📊 详细分类报告:")print(classification_report(y_test, predictions))
# ========== 10. 看看哪些特征最重要 ==========print("\n📈 特征重要性分析 (系数越大越重要):")coef_df = pd.DataFrame({'Feature': features, 'Coefficient': model.coef_[0]})coef_df = coef_df.sort_values(by='Coefficient', ascending=False)print(coef_df)运行结果

这个泰坦尼克号数据集,一共是891名乘客的数据。我看了一下数据集,空值还是挺多的。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

针对空值,腾讯元宝给的解决方法是,age列的空值用中位数填充,embarked列的空值用众数填充,fare列的空值用中位数填充,cabin列的空值用unknown填充。
计算数据集里,每一列的空值数量,其实可以使用pandas包里的isnull().sum()来计算的。
计算数据集里的空值数量的代码
import pandas as pd
#1、加载数据集df = pd.read_excel('titanic.xlsx',sheet_name = 'Sheet1')print(f"数据集形状:{df.shape}")
#2、统计各列空值数量missing_counts = df.isnull().sum() #计算每列空值数量print("有空值的列的列名和空值的数量:")print(missing_counts[missing_counts > 0].sort_values(ascending = False)) #只输出有空值的列运行结果

看来数据集有空值的列,只有3列而已,腾讯元宝写给我的代码里,还多加了一列Fare列的空值处理,看来这一列的空值处理可以删掉了。
PassengerId 乘客ID,无空值
Survived 是否幸存,这是泰坦尼克号生存预测小项目的目标变量。0表示乘客死亡,1表示乘客幸存,无空值。
Pclass 船舱等级,1表示头等舱,2表示二等舱,3表示三等舱,无空值。
Name 乘客姓名,无空值。
Sex 乘客性别,无空值。
Age 乘客年龄,无空值。
SibSp 乘客同行的兄弟姐妹/配偶数量,无空值。
Parch 乘客同行的父母/子女数量,无空值。
Ticket 船票号码,无空值。
Fare 船票票价,无空值。
Cabin 乘客居住的船舱号,空值很多。
Embarked 乘客登船的港口,C表示瑟堡,Q表示昆士敦,S表示南安普敦,空值也比较多。
我除了南安普顿略微听过这个名字,另外两个港口名字我是真没听说过。我出于好奇心,去百度了一下,泰坦尼克号当年停船过的港口。
南安普敦在英国南部,是泰坦尼克号上船的始发港口,至今依旧是英国通往欧洲船只的重要港口。
瑟堡在法国西北部,曾经是欧洲的大西洋航线上的重要港口,也是诺曼底地区的最重要的港口,曾经很繁荣,在二战时期被德军轰炸,后来就衰落了。
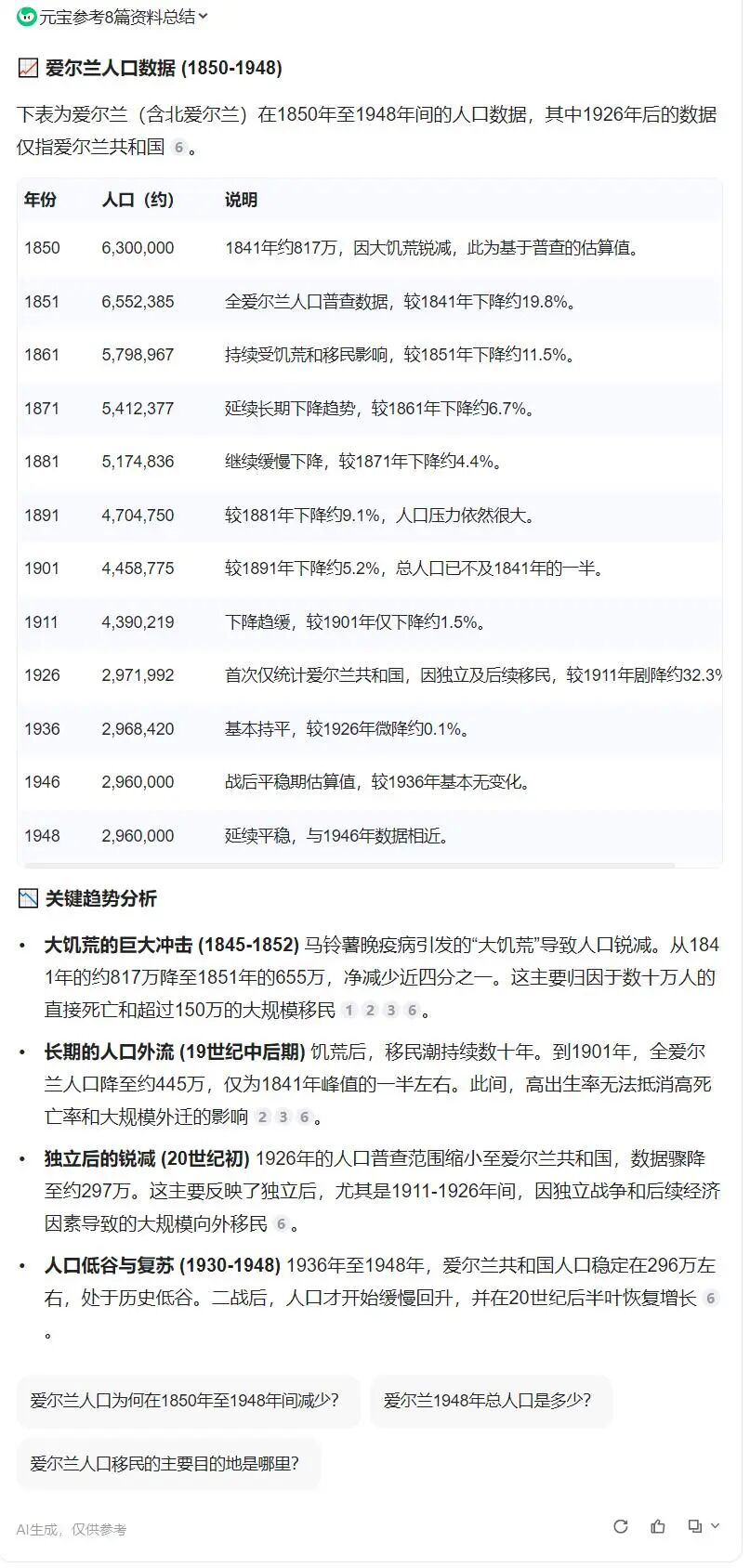
Queenstown我本来查到的是新西兰的皇后镇,但,这泰坦尼克号是去了新西兰吗?新西兰不是在大洋洲吗?撞的是南极的冰山?好像不对。然后,我查泰坦尼克号当年停船过的港口的时候,发现Queenstown其实是爱尔兰的昆士敦,位于爱尔兰南部,这里后来改了个名字,叫做科夫。曾经爱尔兰因为饥荒和贫困,从1848年至1950年,将近100年的时间里,有250万的爱尔兰人从这里上船,移民英国,移民北美,去当劳工。现在这个科夫城,2022年人口才只有1.4万人。
题外话,250万人口对于我们中国来说,就是一个县级市的人口规模。爱尔兰2026年的人口约为 535万至555万,250万人,差不多是它这个国家现在的人口规模的一半的人口呢。不过,这半个国家的人口,是在将近100年里流失的,时间线有点长。
我记得我之前读马克思的《资本论》的时候,看到过讲爱尔兰人因为种植的土豆减产,导致本就不富裕的生活雪上加霜,他们为了避免被饿死,大量离开家乡,前往英国,进工厂打工。然后工资低,工厂的工作环境糟糕,他们在工厂附近的住处,又居住条件恶劣。超长时间超负荷的工作、食物差、空气污染、水污染,导致他们很容易生病死掉,活不久,死的时候往往还很年轻。很惨的一群人。
我去查了一下爱尔兰在1848-1950年的人口变化
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

回归正题,我去网上查了一下泰坦尼克号的航行路线图,我看到了一个知乎网友Stacy的图。
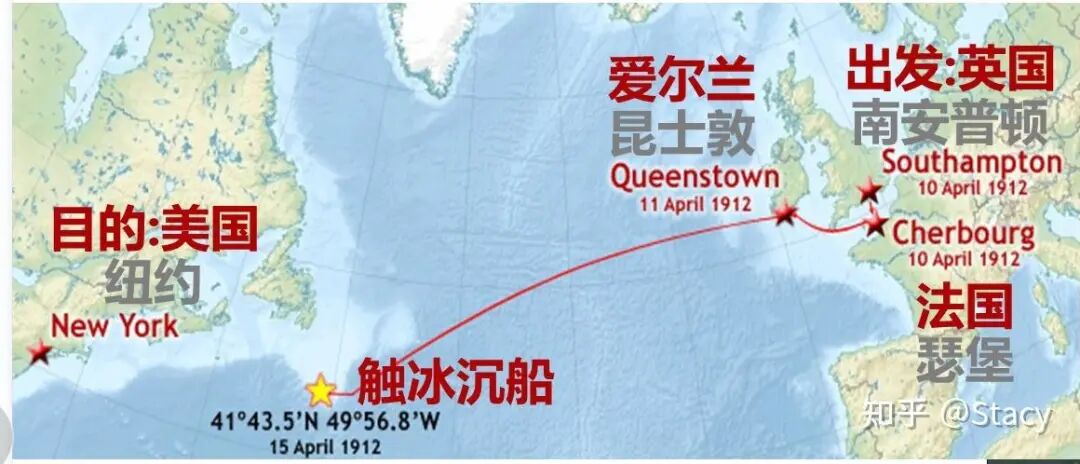
我当时看到这个图的时候,我觉得很吃惊。因为,我心目中,海上漂浮的大冰山是北极和南极这种长年冰天雪地的地方,才会有的东西。这个图上,沉船的地方,已经和美国纽约差不多的纬度了!已经是温带或是亚热带了呀!冰山居然可以出现在温带或是亚热带地区的海上!我以前一直以为,泰坦尼克号是在穿越北冰洋的时候,不幸撞冰山的。好颠覆我的认知。
泰坦尼克号航行路线:
1912年4月10日,12点从英国南安普顿出发;
19点船停法国瑟堡上客;
21点离开法国瑟堡,驶往爱尔兰昆士敦(现科克);
1912年4月11日,12点半在昆士敦停泊,上客及载邮件;
14点离开昆士敦驶向纽约(航行目的地);
1912年4月14日,23点40在西经50度14分,北纬41度16分与冰山相撞
1912年4月15日,2点20全船沉没。
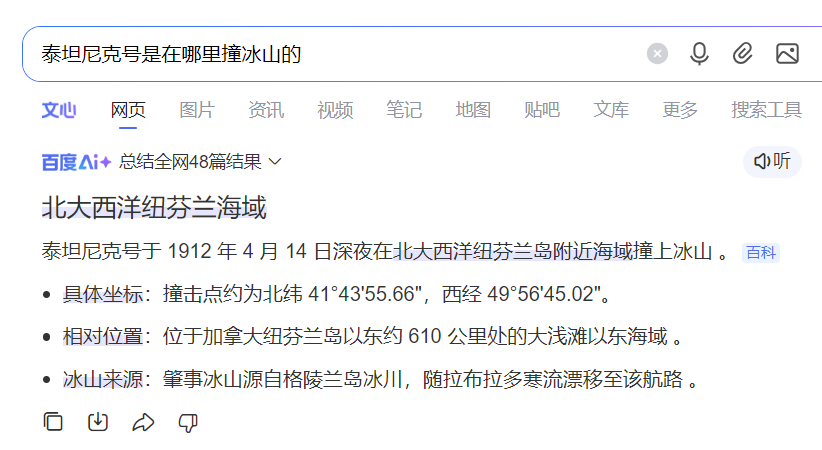
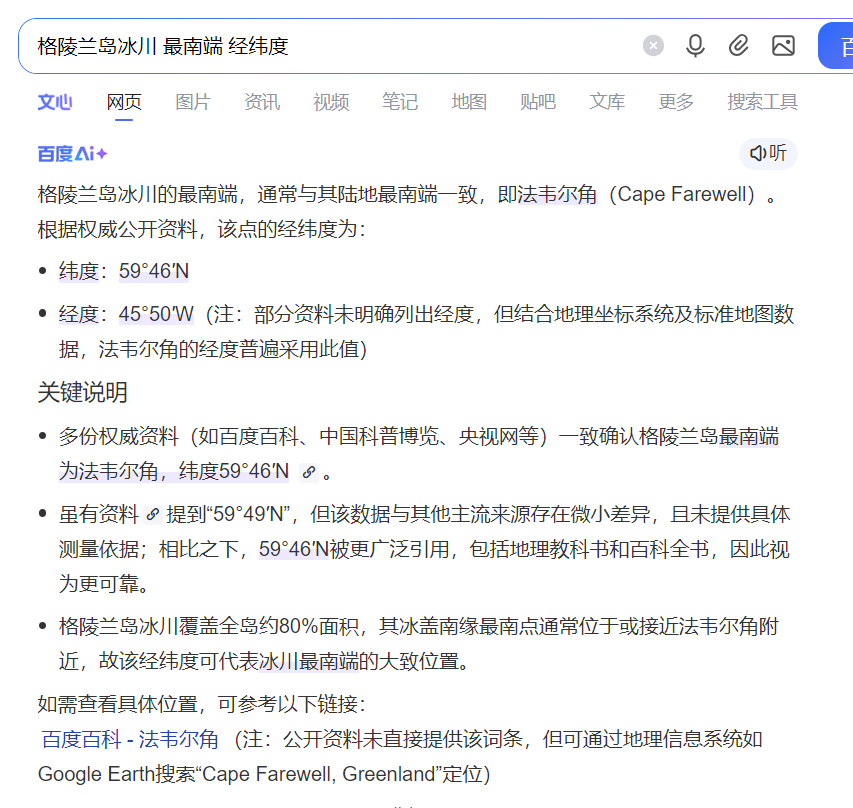
我在网上查到,使用geopy包,可以做到用两个地点的经纬度,计算两个地方之间的距离。
先在cmd命令行里,输入pip install geopy,安装geopy包。
然后,写元宝教我的代码,哎呀,它给我的代码依旧很花里胡哨。我只保留了其中一点点必须的代码。
from geopy.distance import geodesic
#直接使用十进制坐标#格陵兰岛冰川最南端:59°46′N, 45°50′Wiceberg_start = (59.766667,-45.833333) #纬度,经度
#泰坦尼克号沉船地点:41°43'55.66"N, 49°56'45.02"Wtitanic_wreck = (41.732128,-49.945839) #纬度,经度
#计算距离distance_km = geodesic(iceberg_start,titanic_wreck).km
print("冰山从格陵兰岛冰川漂到泰坦尼克号沉船地点的距离为:")print(f"{distance_km:.2f}公里")运行结果

我的天啊!这个冰山居然可以漂2000多公里远,还没有完全化成水,还是一座大冰山,大到能撞沉远洋航行的大轮船。
我去百度了一下,2000公里的球面距离,相当于我们国内从哪里到哪里的距离。然后,查到从北京到深圳的球面距离,是1943公里。这个冰山漂的距离,比从北京到深圳的距离还长。怎么会这样?然后,我又去百度了一下,泰坦尼克号撞上的冰山。

好家伙,沉船的地点附近海域,每年平均会漂浮450座冰山......好吓人啊。而且,这冰山,能在海上漂个半年,都还能一直是冰山,只不过是从超大型冰山,变成小冰山,但还是一座大到能撞沉大轮船的冰山。
我以前一直以为,泰坦尼克号是纯粹的运气不好,晚上太黑,看不见冰山,加上船体偷工减料导致被冰山撞上就完蛋,要是当时瞭望的船员提早看见那座冰山就好了,就能没事的。
现在,我感觉,本来就不经撞的脆皮大轮船泰坦尼克号,像是进入了漂着好多冰山的海上"地雷区",冰山那么多,危险是一定有的,这座冰山没遇上,可当地当时的冰山多得是,下座,再下座,再下下下下下座冰山呢,总有冰山会被偶遇到,只不过它撞上去了,爆了大雷,船沉了,死了好多人。实际上,本就脆皮还视力不好的它,就是在劫难逃。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

回到泰坦尼克号生存预测的代码
还是先从头文件开始看吧
1、import pandas as pd
导入pandas包,这是一个用于数据分析和操作的包。
正文中用到pd的部分一共2处。
第1处是在"加载数据"里,调用read_excel()函数,加载titanic.xlsx文件,作为本代码的数据集。
df = pd.read_excel('titanic.xlsx')第2处是在"看看哪些特征最重要"里,调用DataFrame()函数,创建DataFrame。
coef_df = pd.DataFrame({'Feature': features, 'Coefficient': model.coef_[0]})2、import numpy as np
导入numpy包,这个包主要用于矩阵计算的。
正文中使用到np的部分一共有0处,哎呀,真的可以删掉的。
3、from sklearn.model_selection import train_test_split
从scikit-learn包里,引入train_test_split函数,该函数的作用是把数据集分割成训练集和测试集。
正文中用到train_test_split函数的部分只有1处,在"划分数据集 & 标准化"里。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)4、from sklearn.preprocessing import StandardScaler
从sklearn.preprocessing包里引入StandardScaler函数,作用是对数据集里的各个特征进行缩放。把每一个特征,都缩放到,位于均值为0,标准差为1的分布范围里。
正文中用到StandardScaler函数的部分只有1处,在"划分数据集 & 标准化"里。
# 标准化 (让模型跑得更快更好)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)5、from sklearn.linear_model import LogisticRegression
从scikit-learn包里,引入LogisticRegression函数,这个函数的作用是创建逻辑回归模型,这个模型在流行病学中应用较多。
正文中用到LogisticRegression函数的部分只有1处,在"训练模型"和后续的"评估模型"里。
# ========== 8. 训练模型 ==========``print("\n🏋️ 正在训练模型...")``model = LogisticRegression(max_iter=1000)``model.fit(X_train_scaled, y_train)``# ========== 9. 评估模型 ==========``predictions = model.predict(X_test_scaled)
6、from sklearn.metrics import accuracy_score, classification_report
从scikit-learn 包里,引入用于分类模型评估的核心工具accuracy_score和classification_report:
accuracy_score:计算分类准确率(Accuracy),即预测正确的样本占总样本的比例。
classification_report:生成详细的分类评估报告,包含精确率(Precision)、召回率(Recall)、F1 分数(F1-score)和支持数(Support)等指标。
正文中用到accuracy_score和classification_report两个函数的部分只有1处,在"评估模型"里。
# ========== 9. 评估模型 ==========predictions = model.predict(X_test_scaled)accuracy = accuracy_score(y_test, predictions)print(f"\n🎉 模型训练完成!测试集准确率: {accuracy:.2%}")
print("\n📊 详细分类报告:")print(classification_report(y_test, predictions))7、warnings.filterwarnings('ignore')
在代码运行的时候,忽略警告信息,让控制台变干净。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

看代码的正文的结构。
1、加载数据 2、缺失值处理 3、特征工程 (提取关键信息) 4、划数据编码 (把文字变成数字) 5、选择最终用于训练的特征 6、划分数据集 & 标准化 7、训练模型 8、评估模型 9、看看哪些特征最重要
1、加载数据
前面头文件引入的包,里面有一句
import pandas as pd这一步,用到的核心代码
df = pd.read_excel('titanic.xlsx')把泰坦尼克号数据集文件titanic.xlsx的数据导入,用代码进行读取。
2、缺失值处理
使用pandas包里的fillna()函数,对空值进行填充。
这一步,用到的核心代码
# Age(年龄): 填中位数 (最稳健)df['Age'].fillna(df['Age'].median(), inplace=True)
# Embarked(登船港口): 填众数 (出现最多的那个)df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True)
# Cabin(船舱号): 缺失太多,我们标记为 'Unknown'df['Cabin'].fillna('Unknown', inplace=True)本数据集,有空值的列一共3个,为Age、Embarked、Cabin。Age的缺失值填入中位数,使用median()函数。Embarked的缺失值填入众数,使用mode()函数。Cabin的缺失值填入"Unknown"。
3、特征工程 (提取关键信息)
这一步,用到的核心代码
# 从姓名中提取头衔 (Mr, Miss, Mrs等),这通常很有用df['Title'] = df['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)# 把罕见的头衔归为一类df['Title'] = df['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don','Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')df['Title'] = df['Title'].replace('Mlle', 'Miss')df['Title'] = df['Title'].replace('Ms', 'Miss')df['Title'] = df['Title'].replace('Mme', 'Mrs')
# 家庭大小df['FamilySize'] = df['SibSp'] + df['Parch'] + 1# 是否独自一人df['IsAlone'] = 0df.loc[df['FamilySize'] == 1, 'IsAlone'] = 14、划数据编码 (把文字变成数字)
这一步,用到的核心代码
性别
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})# 登船港口df['Embarked'] = df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})# 头衔title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}df['Title'] = df['Title'].map(title_mapping)df['Title'].fillna(0, inplace=True) # 填充未匹配到的
# 船舱等级 (原本就是数字,不用动)# Pclass 保持不变我其实没看明白,特征工程和数据编码,这两部分,为什么要这样写?这样写的作用是什么?于是,我把我的疑问,拿去问了问腾讯元宝。
元宝给的回答是这样的。大概意思是,把这些文本类型的数据,重新划分或是修改成数字类型的数据,一是因为计算机在进行模型训练的时候,只能处理数字类型的数据,二是为了把一些可以合并的特征给合并了,提高信息密度
好吧,这样的操作,我又涨知识了。我在看到这个数据集的时候,我当时还在想,这里面有些列的数据,都是文本,这怎么训练模型呢?元宝这么一解释,我终于搞明白了,解决办法是,把文本转化一下,变成数字,再给模型训练使用。
5、选择最终用于训练的特征
这一步,用到的核心代码
features = ['Pclass', 'Sex', 'Age', 'Fare', 'Embarked', 'FamilySize', 'IsAlone', 'Title']target = 'Survived'
X = df[features]y = df[target]经过前面的特征工程和数据编码两步,对数据集里的特征列的数据进行转化/拆分/合并之后,这一步是在确定训练模型使用的特征矩阵和目标变量。
训练模型使用的特征矩阵,一共是8个特征:Pclass(船舱等级)、Sex(乘客性别)、Age(乘客年龄)、Fare(船票票价)、Embarked(登船港口)、FamilySize(携带家庭成员总数)、IsAlone(独自一人)、Title(头衔)。
训练模型使用的目标变量是Survived(乘客是否幸存)。
6、划分数据集 & 标准化
前面头文件引入的包,里面有2句
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler这一步,用到的核心代码
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 标准化 (让模型跑得更快更好)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)划分数据集,分割成80%的训练集和20%的测试集。对特征矩阵X的训练集和测试集进行标准化处理。
7、训练模型
前面头文件引入的包,里面有一句
from sklearn.linear_model import LogisticRegression这一步,用到的核心代码
l = LogisticRegression(max_iter=1000)``model.fit(X_train_scaled, y_train)
创建了一个逻辑回归模型用于训练,max_iter=1000的意思是,迭代次数上限设置为1000次。
我去查了一下,为什么使用逻辑回归?
逻辑回归模型的优势:
可解释性强:可以清楚看到每个特征的影响(正相关/负相关)
计算效率高:训练速度快,适合初学者项目
输出概率:不仅能预测类别,还能输出生存概率
避免过拟合:自带L2正则化,对噪声有一定鲁棒性
额,好吧,我好像还是不明白逻辑回归好在哪里。可能是,我对常见的机器学习使用的模型,都了解不多导致的,算了,以后接触它们更多之后,再琢磨吧。
8、评估模型
前面头文件引入的包,里面有一句
from sklearn.metrics import accuracy_score, classification_report这一步,用到的核心代码
predictions = model.predict(X_test_scaled)accuracy = accuracy_score(y_test, predictions)print(f"\n🎉 模型训练完成!测试集准确率: {accuracy:.2%}")
print("\n📊 详细分类报告:")print(classification_report(y_test, predictions))模型训练完成之后,这一步就是看模型的分类准确率,然后生成详细的分类评估报告。
9、看看哪些特征最重要
这一步,用到的核心代码
print("\n📈 特征重要性分析 (系数越大越重要):")coef_df = pd.DataFrame({'Feature': features, 'Coefficient': model.coef_[0]})coef_df = coef_df.sort_values(by='Coefficient', ascending=False)print(coef_df)整个泰坦尼克号生存预测小项目,做完之后,就是为了看看,这些特征里,哪些特征是对乘客的生存和死亡,起到的影响比较大嘛。
现在,重新看一下这个代码的运行结果
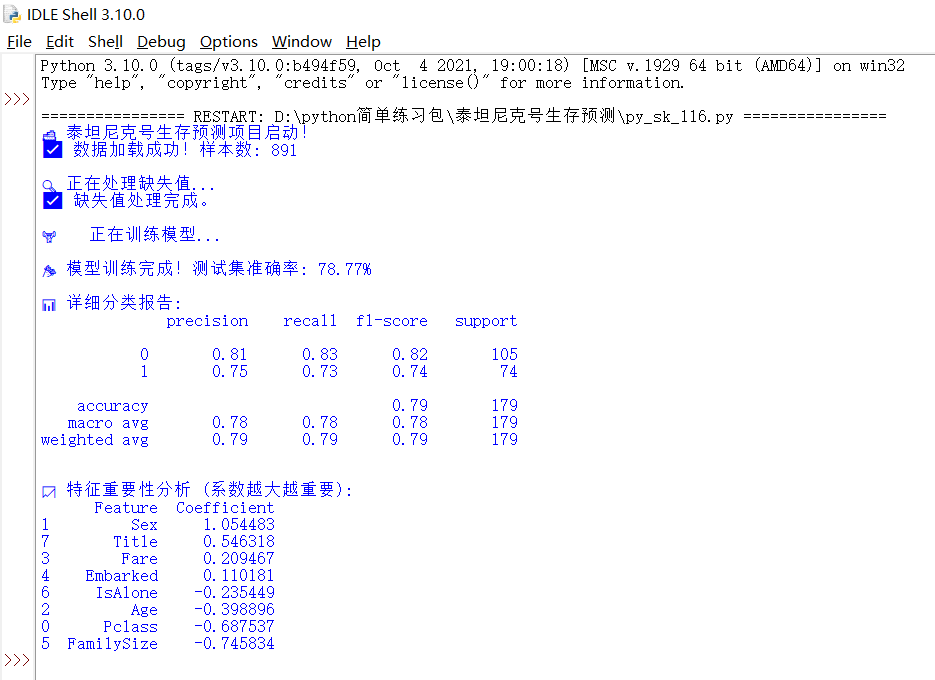
这8个特征里面,对Survived(乘客是否幸存),正影响的特征从高到低为:Sex(乘客性别)、Title(头衔)、Fare(船票票价)、Embarked(登船港口)。负影响的特征从高到低为:IsAlone(独自一人)、Age(乘客年龄)、Pclass(船舱等级)、FamilySize(携带家庭成员总数)
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

结合起来看,船上的乘客里,性别女>头衔高>船票票价贵>登船港口昆士敦,有利于幸存。而船上的乘客容易死亡的因素,独自一人<乘客年龄大<船舱等级三等舱<携带家庭成员总数多。
看来,最容易死掉的倒霉乘客,可能是,性别男、头衔低、船票票价低、登船港口南安普敦、携带家庭成员数量多、住在三等舱、乘客本人年龄大。
不过,我觉得,最幸运的乘客,不必列出来幸存条件了。把这张船的船票退掉,没上这艘船的乘客,才是最幸运的乘客。