Hive排序与分桶技术综述
❒ ORDER BY
ORDER BY 用于对 SQL 查询的最终输出结果进行全局排序。它通过一个 Reducer 任务完成排序,确保全局有序性。然而,当输入数据规模较大时,单一的 Reducer 任务可能导致计算时间较长。默认情况下,ORDER BY 按照递增顺序(ascending)进行排序。例如,以下 SQL 语句使用 ORDER BY 对 cust_id 进行排序:select distinct cust_id,id_no,part_date from ads_api_cda_basic_info_parquet_pt order by cust_id。
❒ SORT BY
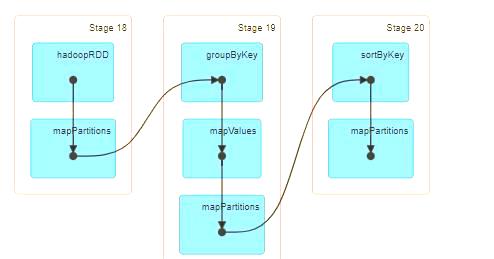
SORT BY 并非直接对 SQL 的最终输出结果进行排序,而是在数据进入 Reducer 之前,对 Map 端的输出数据 按照指定字段进行预排序。值得注意的是,SORT BY 不会改变 Reducer 的数量。它主要确保每个 Reducer 内部的数据维持一定的顺序,但并不保证 SQL 查询结果的全局有序性。以下是一个使用 SORT BY 的示例 SQL 语句:select distinct cust_id, id_no, part_date from ads_api_cda_basic_info_parquet_pt SORT BY cust_id。
❒ DISTRIBUTE BY
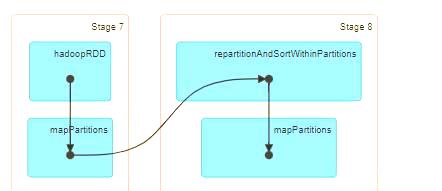
DISTRIBUTE BY 是一种分发规则,它决定了将 MAP 端的输出记录分配给哪个 reducer 进行进一步处理。这种分配不会改变 reducer 的数量。在默认情况下,采用 hash 取模算法将具有相同 Distribute By 字段的 MAP 端输出数据分发给同一个 reducer。然而,需要注意的是,Distribute By 并不保证每个 reducer 内部的所有记录都保持顺序。以下是一个使用 DISTRIBUTE BY 的示例 SQL 语句:select distinct cust_id, id_no, part_date from ads_api_cda_basic_info_parquet_pt distribute by cust_id。
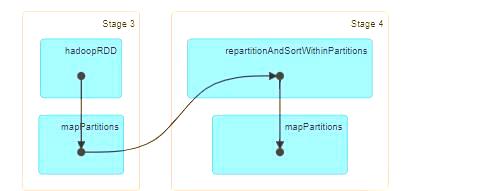
DISTRIBUTE BY 与 SORT BY 的联合应用,可确保每个 REDUCER 内部处理的所有记录 都维持原有顺序。值得注意的是,Distribute By 的分区字段与 SORT BY 的排序字段可以互不相同。例如,以下 SQL 语句展示了这种配合使用的方式:select distinct cust_id, id_no, part_date from ads_api_cda_basic_info_parquet_pt distribute by cust_id sort by id_no。通过恰当选择 DISTRIBUTE BY 字段,并辅以 SORT BY,可以有效地解决一系列问题,包括 Map 输出文件大小的不均、Reduce 输出文件大小的不均、小文件的过多以及文件过大等。
❒ CLUSTER BY
CLUSTER BY 的作用相当于同时使用 DISTRIBUTE BY 和 SORT BY;在 CLUSTER BY 中,底层的 Distribute By 分区字段与 SORT BY 排序字段是相同的;CLUSTER BY 不会改变 REDUCER 的数量;示例 SQL 语句:select distinct cust_id, id_no, part_date from ads_api_cda_basic_info_parquet_pt cluster by cust_id;
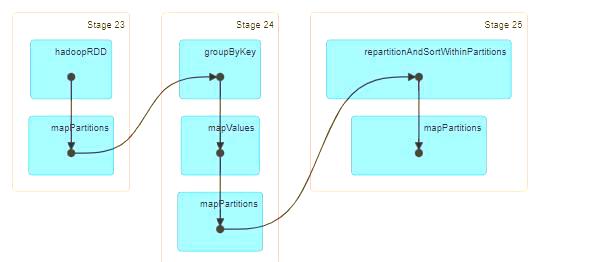
CLUSTER BY 在 Spark Web UI 中的体现
使用 CLUSTER BY 时,在 Spark Web UI 中可以观察到其底层的工作机制。Distribute By 分区字段与 SORT BY 排序字段在 CLUSTER BY 中是统一的,这确保了数据在分区的同时也进行了排序,从而优化了查询性能。值得注意的是,CLUSTER BY 不会改变 REDUCER 的数量,这也是其高效性的一个体现。
❒ BUCKET 桶表
在 HIVE中,桶表(BUCKET) 是一种特殊的数据表,它具有多个优势,包括高效取样、支持mapside join等。当声明桶表时,用户需要指定分桶字段和桶的数量,例如"CLUSTERED BY(user_id) INTO 31 BUCKETS"。在底层执行写入操作时,桶表会自动添加CLUSTER BY子语句,确保数据按照指定的分桶字段进行分布。此外,桶表的写入操作会涉及reducer,且reducer的数量会自动设置为声明的桶数。
通过合理选择分桶字段和数量,桶表能有效控制底层小文件的数量,从而减轻数据倾斜和小文件问题。而且,使用桶表来处理这些问题时,所有的更改都在 DDL 层面进行,无需修改 DML 语句添加CLUSTER/DISTRIBUTE BY子语句。由于DDL通常是系统上线或后续优化调整时的一次性操作,这进一步增加了系统的灵活性和运维的便捷性。