
文章目录
文章目录
- [01 基础信息](#01 基础信息)
- [02 背景](#02 背景)
- [03 方法](#03 方法)
- [04 结果](#04 结果)
- [05 思考](#05 思考)
- [06 新掌握的表达](#06 新掌握的表达)
01 基础信息
- 标题:A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction
- 作者:Jo Schlemper, Jose Caballero, Joseph V. Hajnal, Anthony N. Price, and Daniel Rueckert
- 期刊:IEEE TMI 2018
- 关键词:深度学习,卷积神经网络,动态磁共振成像,压缩感知,图像重建
- 总结:本文提出了一种级联 CNN 框架,通过在神经网络中嵌入数据一致性层(Data Consistency Layer),实现了从高度欠采样(高达 11 倍)的 k-space 数据中快速重建动态心脏 MR 图像 。它将传统的迭代优化过程"展开(Unrolling)"为一个端到端的深层网络。
02 背景
逆问题建模:
MRI 重建本质上是求解 y = F u x + e y = F_u x + e y=Fux+e 的欠定方程 。
数据一致性 (DC) 的本质:
作者指出,如果我们已经知道某些 k-space 的采样值,CNN 就不应该随意修改它们 。
数学表达式 :
s r e c ( j ) = { s c n n ( j ) if j ∉ Ω s c n n ( j ) + λ s 0 ( j ) 1 + λ if j ∈ Ω s_{rec}(j) = \begin{cases} s_{cnn}(j) & \text{if } j \notin \Omega \\ \frac{s_{cnn}(j) + \lambda s_0(j)}{1 + \lambda} & \text{if } j \in \Omega \end{cases} srec(j)={scnn(j)1+λscnn(j)+λs0(j)if j∈/Ωif j∈Ω
注:当 λ → ∞ \lambda \to \infty λ→∞ 时,采样点直接用原始测量值替换,非采样点用 CNN 预测值 。
重新整理的一些背景知识:
什么是压缩感知?
传统的香农采样定理要求采样频率必须大于信号最高频率的两倍,但 MRI 扫描如果按此标准执行,时间会非常漫长 。压缩感知允许我们以远低于 Nyquist 标准的速率进行采样(即欠采样),并依然能够完美恢复图像 。
需要满足的前提条件:
(1)稀疏性(Sparsity):图像在某个变换域(如小波变换 Wavelet 或有限差分域 TV)中,大部分像素值接近于零,只有少数非零值 。
(2)非相干性(Incoherence):采样模式(通常是随机欠采样)产生的伪影在变换域中表现为不相关的噪声,而不是结构性的干扰 。
(3)非线性重建:通过迭代算法寻找一个既符合已采集数据,又在变换域最稀疏的解 。
什么是并行成像?
利用线圈空间灵敏度的差异(Coil Sensitivity Maps)来提供额外的空间编码信息 。这使得我们可以跳过一些 k k k 空间扫描线,通过解方程组的方式找回丢失的数据 。(利用数据中明显的冗余性,将因采样不足而产生的初始欠定问题转化为易于解决的确定性或过定性问题。)
并行成像与压缩感知的区别:并行成像(Parallel Imaging, PI)利用的是硬件先验(线圈的空间灵敏度),而压缩感知(Compressed Sensing, CS)利用的是数学先验(图像的稀疏性)。
什么是欠定方程?
在磁共振成像(MRI)中,我们希望获取完整的图像数据 x x x。然而,为了加快扫描速度,我们只采集了少量的 k k k 空间数据 y y y 。
数学定义:当我们采集的数据量 M M M 远小于待重建的像素点数量 N N N 时(即 M ≪ N M \ll N M≪N),方程 y = F u x + e y = F_u x + e y=Fux+e 就是一个欠定方程 。
后果:这种方程有无数种可能的解 。如果直接进行傅里叶逆变换,图像会出现严重的混叠伪影(Aliasing Artifacts),看起来像是很多层图像重叠在一起 。
什么是基于字典学习的MR图像重建?
在传统压缩感知中,我们使用预定义的正交基(如小波基 Ψ \Psi Ψ)。而在 DLMRI 中,我们认为图像块 R i x R_i x Rix 可以由一个过完备字典(Over-complete Dictionary) D D D 中的极少数原子线性组合而成 。
其核心优化目标函数如下:
min x , D , γ i ∑ i ( ∥ R i x − D γ i ∥ 2 2 + ν ∥ γ i ∥ 0 ) + λ ∥ y − F u x ∥ 2 2 \min_{x, D, \gamma_i} \sum_{i} \left( \| R_i x - D\gamma_i \|_2^2 + \nu \| \gamma_i \|_0 \right) + \lambda \| y - F_u x \|_2^2 x,D,γimini∑(∥Rix−Dγi∥22+ν∥γi∥0)+λ∥y−Fux∥22
R i x R_i x Rix:从待重建图像 x x x 中提取的第 i i i 个图像块 。
D D D:待学习的字典,列向量为"原子" 。
γ i \gamma_i γi:对应图像块在字典下的稀疏系数, ∥ c i t e s t a r t γ i ∥ 0 \| cite_start\gamma_i \|_0 ∥citestartγi∥0 约束了非零原子的数量(即稀疏性) 。
λ ∥ y − F u x ∥ 2 2 \lambda \| y - F_u x \|_2^2 λ∥y−Fux∥22:数据一致性项(Data Fidelity),确保重建结果与采集到的 k 空间信号吻合 。
03 方法
这篇文章最精华的设计在于它的层级结构:
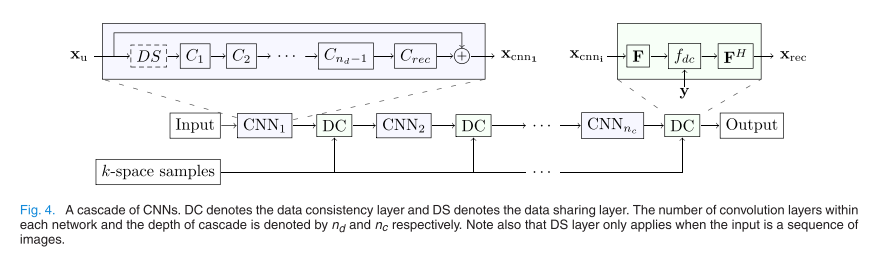
- 级联模块 ( n c n_c nc 迭代) :它不是一个单一的大网络,而是由多个子网络( C N N 1 , C N N 2 , . . . CNN_1, CNN_2, ... CNN1,CNN2,...)串联而成,每个子网络后面都跟着一个 DC 层 。这种结构模仿了传统压缩感知中的"去噪-投影"迭代过程 。
- 数据共享层 (Data Sharing, DS) :针对动态(Dynamic) MRI,利用相邻帧在时间轴上的相关性。如果相邻帧变动不大,可以用它们的 k-space 采样来填补当前帧的空缺 。
04 结果
- 2D vs 级联深度 :
论文对比了 D11-C1(11层纯卷积)和 D5-C2(2个级联,每个级联5层卷积) 。实验证明,增加级联次数和 DC 层(D5-C2)比单纯增加卷积层(D11-C1)效果更好且更不易过拟合 。 - 重建速度:
2D 图像重建仅需 23 毫秒,动态序列重建在 10 秒 以内,完全满足实时成像需求 。 - 鲁棒性:
作者专门讨论了噪声处理。通过将 λ \lambda λ 设置为可学习的参数(CNN-AD),网络在面对高噪声数据时表现出了极强的鲁棒性 。
05 思考
为什么深度学习的方法也需要采用迭代的方式?
- 强制满足物理一致性(Data Consistency)
直接用一个纯 CNN 网络代替,本质上是在做图像到图像的"像素映射"。可能使得图像生成伪造的信息。采用迭代展开的方法,在每次迭代中,DC层,都要强制要求网络预测值与实际采集到的原始信号进行对比。 - 将先验知识与优化理论相结合
传统算法如压缩感知(CS)或字典学习(DLMRI),已经证明了"去噪---投影---去噪"这种循环迭代是求解逆问题的科学路径 。这样的思路,使得网络更具可解释性。同时,这种结构允许我们用相对较小的参数量实现极深的有效深度 。
可以学习的点?
物理先验的重要性、小样本的策略(数据增强的方式)
06 新掌握的表达
二维图像帧独立重建:each 2-D image frame is reconstructed independently
联合时间帧重建: reconstructing the frames of the sequences jointly