前面我们已经完成了三种Cache的设计。本期我们就来调整一下内存池相关的设计问题
相关代码在我的个人gitee:高并发内存池: 个人学习的项目------高并发内存池
目录
对于大于256KB的内存申请释放
前面我们已经讲解对于小于256KB的内存池而言,它会通过我们前面设计的三重Cache申请资源。但是实际中并不总是申请小于256KB的内存。那么对于大于256KB的内存我们怎么处理呢?
前面我们以8KB为一页,那么我们就来分类讨论一下,设申请size
32页<size<=256页的时候,可以 去找PageCache申请
size>256页的时候,就要去系统堆申请
Common.h
cpp
#pragma once
#include"MemoryAllocator.h"
#include <iostream>
#include <vector>
#include<algorithm>
#include <cstdlib>
#include<stdexcept>
#include<cassert>
#include<thread>
#include<mutex>
#include<memory>
#include <stddef.h> // 跨平台定义 size_t,必须包含
#ifdef _WIN32
// Windows 平台:VirtualAlloc 需要 windows.h
// 同时定义 NOMINMAX 避免与 std::min 冲突(若后续使用)
#ifndef NOMINMAX
#define NOMINMAX
#endif
#include <windows.h>
#else
// Linux 平台:mmap、sysconf 需要以下头文件
#include <sys/mman.h> // mmap, MAP_FAILED, PROT_READ, PROT_WRITE, MAP_PRIVATE, MAP_ANONYMOUS
#include <unistd.h> // sysconf, _SC_PAGESIZE
#endif
using std::cout;
using std::endl;
using std::vector;
//内存池可申请的最大的内存------256KB
static const int MAX_SIZE = 256 * 1024;
static const int NFRESSLISTS = 208;
static const size_t NPAGES = 129;
static const size_t PAGE_SHIFT = 13;
// 跨平台类型定义:PageID_
// 适用:Windows (32/64位) + Linux (32/64位)
// 1. 64 位 Windows 系统
#if defined(_WIN64)
typedef unsigned long long PageID;
// 2. 32 位 Windows 系统
#elif defined(_WIN32)
typedef size_t PageID;
// 3. Linux 系统(自动适配 32/64 位)
#elif defined(__linux__)
typedef size_t PageID;
// 4. 不支持的平台(报错提示)
#else
#error "当前仅支持 Windows 和 Linux 系统!"
#endif
//给一个对象取前4/8字节
static inline void*& NextObject(void* object)
{
return *(void**)object;
}
//管理好切分的小对象的链表
class FreeList
{
private:
void* freelist_=nullptr;
size_t maxSize_=1;
size_t size_ = 0;
public:
void Push(void* object)
{
//头插
/*if (object == nullptr)
{
throw "申请的对象内存为空";
}*/
assert(object);
NextObject(object) = freelist_;
freelist_ = object;
++size_;
}
void PushRange(void*start,void* end,size_t n)
{
(void)end; // 标记未使用参数,消除警告
NextObject(start) = freelist_;
freelist_ = start;
size_ += n;
}
void* Pop()
{
//头删
/*if (freelist_ == nullptr)
{
throw "内存链表为空";
}*/
assert(freelist_);
void* object = freelist_;
freelist_ = NextObject(object);
--size_;
return object;
}
void PopRange(void*& start, void*& end, size_t n)
{
assert(n>=size_);
start = freelist_;
end = start;
for (size_t i = 0; i < n - 1; ++i)
{
end = NextObject(end);
}
freelist_ = NextObject(end);
NextObject(end) = nullptr;
size_ -= n;
}
//判断是否为空
bool Empty()
{
return freelist_ == nullptr;
}
size_t& MaxSize()
{
return maxSize_;
}
size_t size()
{
return size_;
}
};
//对齐映射规则
//以8字节对齐最合适------因为64系统下一个指针是8个字节,导致无法储存指针进而挂接在链表上
class Alignment
{
// 整体控制在最多10%左右的内碎片浪费
// [1,128] 8byte对齐 freelist[0,16)
// [128+1,1024] 16byte对齐 freelist[16,72)
// [1024+1,8*1024] 128byte对齐 freelist[72,128)
// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)
// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
private:
//方式二:位运算
//static防止多次定义 constexpr编译期计算 inline建议编译器编译期内联
static constexpr inline size_t _RoundUP(size_t size, size_t Align)
{
return (size + Align - 1) & ~(Align - 1);
//比如size=5,则二进制为00000101,Align为8,则Align - 1为00000111
// size + Align - 1为00001100,即12
//~为按位取反, ~(Align - 1)为11111000
//&为按位与,当对应位数均为1时方为1
//00001100&11111000=>
//00001100
//11111000
//=>00001000,为8
}
public:
//频繁调用的小函数常见写法
static constexpr inline size_t RoundUP(size_t size)
{
if (size <= 128)//128B
{
return _RoundUP(size, 8);
}
else if (size < 1024)//1KB
{
return _RoundUP(size, 16);
}
else if (size <= 8 * 1024)//8KB
{
return _RoundUP(size, 128);
}
else if (size <= 64 * 1024)//64KB
{
return _RoundUP(size, 1024);
}
else if (size <= 256 * 1024)//256KB
{
return _RoundUP(size, 8 * 1024);
}
//添加了额外的处理
else
{
return _RoundUP(size, 1 << PAGE_SHIFT);
}
}
//计算映射到哪个桶内的自由链表
//这里除法计算的都是2的幂数,现代主流编译器(MSVC、GCC、Clang会将其转化为位运算)
static constexpr inline size_t Index(size_t size)
{
size_t aligned = RoundUP(size); // 先对齐,可能抛出异常
if (aligned <= 128) // 8字节对齐区间 [8, 128]
{
// 桶索引:8→0, 16→1, ..., 128→15
return aligned / 8 - 1;
}
else if (aligned <= 1024) // 16字节对齐区间 [144, 1024]
{
// 起始144对应桶16,步长16
return (aligned - 144) / 16 + 16;
}
else if (aligned <= 8 * 1024) // 128字节对齐区间 [1152, 8192]
{
// 起始1152对应桶72,步长128
return (aligned - 1152) / 128 + 72;
}
else if (aligned <= 64 * 1024) // 1024字节对齐区间 [9216, 65536]
{
// 起始9216对应桶128,步长1024
return (aligned - 9216) / 1024 + 128;
}
else if (aligned <= 256 * 1024) // 8*1024字节对齐区间 [73728, 262144]
{
// 起始73728对应桶184,步长8192
return (aligned - 73728) / (8 * 1024) + 184;
}
else // 理论上不会到达这里,因为 RoundUP 已经对过大 size 抛异常
{
throw std::runtime_error("申请内存过大");
}
}
// 一次thread cache从中心缓存获取多少个
static size_t NumMoveSize(size_t size)
{
assert(size >0);
// [2, 512], 一次批量移动多少个对象的(慢启动)上限值
// 小对象一次批量上限高
// 小对象一次批量上限低
int num = MAX_SIZE / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
// 计算一次向系统获取几个页
// 单个对象 8byte
// ...
// 单个对象 256KB
static size_t NumMovePage(size_t size)
{
size_t num = NumMoveSize(size);
size_t npage = num * size;
npage >>= PAGE_SHIFT;
if (npage == 0)
npage = 1;
return npage;
}
};
//Span用来管理多个连续页的大块内存跨度调度结构
//CentralCache和PageCache都需要调用
struct Span
{
PageID PageNum=0; //页数
size_t n_=0; //多个大块内存的起始页的页号
//双向链表
Span* prev_=nullptr;
Span* next_=nullptr;
void* freeList_=nullptr;//切出来小内存的自由链表
size_t IsUseCount_=0; //被切出去的内存,分配给ThreadCache计数
bool IsUse = false; //是否被使用
size_t ObjectSize=0; //对象数量
bool isLargeMemory = false; // 标记是否为大内存块(>256KB)
void* systemMemoryPtr = nullptr; // 系统分配的内存指针(仅用于大内存块)
};
//带头双向循环链表
class SpanList
{
private:
std::unique_ptr<Span> head_; // 头节点由 unique_ptr 独占管理
//多线程访问同一个桶会形成竞争导致变慢,访问各自的桶即使是加锁也不会变慢
public:
std::mutex mtx_;
SpanList()
: head_(std::make_unique<Span>())
{
head_->prev_ = head_.get();
head_->next_ = head_.get();
}
Span* Begin()
{
return head_->next_;
}
Span* End()
{
return head_->prev_;
}
void PushFront(Span* span)
{
Insert(Begin(), span);
}
Span* PopFront()
{
Span* target = head_->next_;
Erase(target);
return target;
}
bool Empty()
{
return head_->next_ == head_.get();
}
// 插入:将 newSpan 插入到 pos 之前(pos 不能为 nullptr)
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
// 连接前后节点
Span* prev = pos->prev_;
prev->next_ = newSpan;
newSpan->prev_ = prev;
newSpan->next_ = pos;
pos->prev_ = newSpan;
// newSpan 的所有权已转移给链表(由链表负责析构时释放)
}
// 删除:从链表中移除 pos 指向的节点(不能是头节点)
void Erase(Span* pos)
{
assert(pos);
// 确保不删除头节点
if (pos == head_.get())
{
return; // 头节点由 unique_ptr 管理,不能删除
}
// 从链表中摘除
pos->prev_->next_ = pos->next_;
pos->next_->prev_ = pos->prev_;
// 重置指针,避免悬空指针
pos->prev_ = nullptr;
pos->next_ = nullptr;
}
// 析构函数:释放所有非头节点
~SpanList()
{
Span* cur = head_->next_;
while (cur != head_.get())
{
Span* next = cur->next_;
delete cur; // 释放每个普通节点
cur = next;
}
// head_ 由 unique_ptr 自动释放,无需手动处理
}
};MemoryAlloc.h
cpp
// File: MemoryAllocator.h
#pragma once
#include <cstddef>
#include <stdexcept>
#include <new>
#ifdef _WIN32
#include <windows.h>
#else
#include <sys/mman.h>
#include <unistd.h>
#endif
// 默认页大小 4KB
static const size_t PAGE_SIZE = 4096; // 1<<12
// 按页申请内存(kpage:页数)
inline static void* SystemAlloc(size_t kpage)
{
size_t size = kpage * PAGE_SIZE;
#ifdef _WIN32
void* ptr = VirtualAlloc(nullptr, size, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
void* ptr = mmap(nullptr, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (ptr == MAP_FAILED)
ptr = nullptr;
#endif
if (!ptr)
throw std::bad_alloc();
return ptr;
}
inline static void SystemFree(void* ptr)
{
if (!ptr) return;
#ifdef _WIN32
if (!VirtualFree(ptr, 0, MEM_RELEASE)) {
throw std::runtime_error("VirtualFree failed");
}
#else
// 在Linux下,我们需要知道内存大小才能正确释放
// 这里使用一个简化的实现:假设ptr是通过mmap分配的
// 更健壮的实现需要记录分配的大小信息
if (munmap(ptr, 0) == -1) {
throw std::runtime_error("munmap failed");
}
#endif
}ThreadCache.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS
#include "ThreadCache.h"
#include"CentralCache.h"
// 跨平台min函数包装器,避免Windows.h的宏冲突
namespace PlatformUtils
{
template<typename T>
inline const T& Min(const T& a, const T& b)
{
return (a < b) ? a : b;
}
}
// 定义 thread_local 变量(每个线程独立)
thread_local ThreadCache* pTLSThreadCache = nullptr;
//申请资源
void* ThreadCache::Allocator(size_t size)
{
assert(size <= MAX_SIZE);
size_t AlignSize = Alignment::RoundUP(size);
size_t index = Alignment::Index(size);
if (!freelist_[index].Empty())
return freelist_[index].Pop();
else
return FetchFromCentralCache(index, AlignSize);
}
//释放资源
void ThreadCache::Deallocator(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAX_SIZE);
size_t index = Alignment::Index(size);
freelist_[index].Push(ptr);
//链表长度大于一次批量申请的内存
if (freelist_[index].size() >= freelist_[index].MaxSize())
{
ListTooLong(freelist_[index], size);
}
}
//从CentralCache申请资源
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
//满开始反馈调节算法
// 1、最开始不会一次向central cache一次批量要太多,因为要太多了可能用不完
// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限
// 3、size越大,一次要的BatchNum越小
// 4、size越小,一次要得BatchNum越大
size_t BatchNum = PlatformUtils::Min(freelist_[index].MaxSize(), Alignment::NumMoveSize(size));
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::Instance()->FetchRangeObj(start, end, BatchNum, size);
assert(actualNum > 0);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
freelist_[index].PushRange(NextObject(start), end, actualNum-1);
return start;
}
if (BatchNum == freelist_[index].MaxSize())
{
freelist_[index].MaxSize() += 1;
}
return nullptr;
}
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
list.PopRange(start, end, list.MaxSize());
CentralCache::Instance()->ReleaseListToSpans(start, size);
}释放对象优化
Common.h
cpp
//Span用来管理多个连续页的大块内存跨度调度结构
//CentralCache和PageCache都需要调用
struct Span
{
PageID PageNum=0; //页数
size_t n_=0; //多个大块内存的起始页的页号
//双向链表
Span* prev_=nullptr;
Span* next_=nullptr;
void* freeList_=nullptr;//切出来小内存的自由链表
size_t IsUseCount_=0; //被切出去的内存,分配给ThreadCache计数
bool IsUse = false; //是否被使用
size_t ObjectSize=0; //对象数量
bool isLargeMemory = false; // 标记是否为大内存块(>256KB)
void* systemMemoryPtr = nullptr; // 系统分配的内存指针(仅用于大内存块)
};PageCache.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS
#include"PageCache.h"
#include <iostream>
PageCache PageCache::sInstan_;
Span* PageCache::MapObjectToSpan(void* object)
{
PageID id = ((PageID)object >> PAGE_SHIFT);
std::unique_lock<std::mutex> lock(pagemtx_);
auto ret = IdSpanMap_.find(id);
if (ret != IdSpanMap_.end())
{
return ret->second;
}
else
{
assert(false);
return nullptr;
}
}
Span* PageCache::GetSpan(size_t K)
{
assert(K > 0 && K < NPAGES);
//大于128页的直接向堆申请内存,不进行切分
if (K > NPAGES-1)
{
void* ptr = SystemAlloc(K);
Span* span = new Span;
span->PageNum = (PageID)ptr >> PAGE_SHIFT;
span->n_ = K;
IdSpanMap_[span->PageNum] = span;
IdSpanMap_[span->PageNum + K - 1] = span;
return span;
}
if (!spanlist_[K].Empty())
{
return spanlist_[K].PopFront();
}
// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分
for (size_t i = K + 1; i < NPAGES; ++i)
{
if (!spanlist_[i].Empty())
{
Span* nSpan = spanlist_[i].PopFront();
Span* kSpan = new Span;
// 在nSpan的头部切一个k页下来
// k页span返回
// nSpan再挂到对应映射的位置
kSpan->PageNum = nSpan->PageNum;
kSpan->n_ = K;
nSpan->PageNum += K;
nSpan->n_ -= K;
spanlist_[nSpan->n_].PushFront(nSpan);
//存储span页号与span的映射,方便回收时合并查找
IdSpanMap_[nSpan->PageNum] = nSpan;
// 1000 5
IdSpanMap_[nSpan->PageNum + nSpan->n_ - 1] = nSpan;
//建立ID与span映射,方便CentralCache回收时查找对应的span
for (PageID i = 0; i < kSpan->n_; ++i)
{
IdSpanMap_[kSpan->PageNum + i] = kSpan;
}
return kSpan;
}
}
// 走到这个位置就说明后面没有大页的span了
// 这时就去找堆要一个128页的span
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->PageNum = (PageID)ptr >> PAGE_SHIFT;
bigSpan->n_ = NPAGES - 1;
spanlist_[bigSpan->n_].PushFront(bigSpan);
return GetSpan(K);
}
void PageCache::ReleaseSpanToPageCache(Span* span)
{
// 大于128 page的直接还给堆
if (span->n_ > NPAGES-1)
{
void* ptr = (void*)(span->PageNum << PAGE_SHIFT);
SystemFree(ptr);
delete span;
return;
}
// 如果是大内存块,直接返回,不进行合并操作
if (span->isLargeMemory) {
return;
}
// 对span前后的页,尝试进行合并,缓解内存碎片问题
//向前合并
while (1)
{
PageID prevId = span->PageNum - 1;
auto ret = IdSpanMap_.find(prevId);
// 前面的页号没有,不合并了
if (ret == IdSpanMap_.end())
{
break;
}
// 前面相邻页的span在使用,不合并了
Span* prevSpan = ret->second;
if (prevSpan->IsUse == true)
{
break;
}
// 合并出超过128页的span没办法管理,不合并了
if (prevSpan->n_ + span->n_ > NPAGES - 1)
{
break;
}
span->PageNum = prevSpan->PageNum;
span->n_ += prevSpan->n_;
spanlist_[prevSpan->n_].Erase(prevSpan);
delete prevSpan;
}
// 向后合并
while (1)
{
PageID nextId = span->PageNum + span->n_;
auto ret = IdSpanMap_.find(nextId);
if (ret == IdSpanMap_.end())
{
break;
}
Span* nextSpan = ret->second;
if (nextSpan->IsUse == true)
{
break;
}
if (nextSpan->n_ + span->n_ > NPAGES - 1)
{
break;
}
span->n_ = nextSpan->n_;
spanlist_[nextSpan->n_].Erase(nextSpan);
delete nextSpan;
}
spanlist_[span->n_].PushFront(span);
span->IsUse = false;
IdSpanMap_[span->PageNum] = span;
IdSpanMap_[span->PageNum + span->n_ - 1] = span;
}
// 注册大内存块
Span* PageCache::RegisterLargeSpan(void* ptr, size_t kpage)
{
if (!ptr) {
throw std::invalid_argument("Invalid pointer for large memory registration");
}
// 检查是否已经注册
if (largeMemoryMap_.find(ptr) != largeMemoryMap_.end()) {
throw std::runtime_error("Large memory block already registered");
}
// 创建新的Span来管理这个大内存块
Span* span = new Span();
span->PageNum = reinterpret_cast<PageID>(ptr) >> PAGE_SHIFT;
span->n_ = kpage;
span->isLargeMemory = true;
span->systemMemoryPtr = ptr;
span->IsUse = true;
// 注册到映射表
largeMemoryMap_[ptr] = span;
// 注册到页映射表(用于MapObjectToSpan查找)
for (PageID i = 0; i < span->n_; ++i) {
IdSpanMap_[span->PageNum + i] = span;
}
return span;
}
// 注销大内存块
void PageCache::UnregisterLargeSpan(Span* span)
{
if (!span || !span->isLargeMemory) {
throw std::invalid_argument("Invalid span for large memory unregistration");
}
// 从大内存映射表中移除
auto it = largeMemoryMap_.find(span->systemMemoryPtr);
if (it != largeMemoryMap_.end()) {
largeMemoryMap_.erase(it);
}
// 从页映射表中移除
for (PageID i = 0; i < span->n_; ++i) {
IdSpanMap_.erase(span->PageNum + i);
}
// 删除Span对象
delete span;
}
// 检查是否为大内存块
bool PageCache::IsLargeMemory(void* ptr) const
{
return largeMemoryMap_.find(ptr) != largeMemoryMap_.end();
}ConcurrentAlloc.h
cpp
#pragma once
#include"Common.h"
#include"ThreadCache.h"
#include"TLSManager.h"
#include"PageCache.h"
// 并发申请内存
static void* ConcurrrentAlloc(size_t size)
{
if (size == 0) return nullptr;
if (size > MAX_SIZE)
{
// 大内存分配:直接使用系统分配器
try
{
size_t alignsize = Alignment::RoundUP(size);
size_t kpage = (alignsize + PAGE_SIZE - 1) >> PAGE_SHIFT;
// 使用系统分配器分配大内存
void* ptr = SystemAlloc(kpage);
if (!ptr)
{
throw std::bad_alloc();
}
// 记录大内存块信息到PageCache
PageCache::Instance()->pagemtx_.lock();
PageCache::Instance()->RegisterLargeSpan(ptr, kpage);
PageCache::Instance()->pagemtx_.unlock();
return ptr;
}
catch (const std::exception& e)
{
std::cerr << "Large memory allocation failed: " << e.what() << std::endl;
throw;
}
}
else
{
// 小内存分配:通过TLSManager获取当前线程的ThreadCache实例
// RAII模式自动管理生命周期,线程结束时自动清理
try
{
return TLSManager::GetInstance().Allocator(size);
}
catch (const std::exception& e)
{
std::cerr << "Small memory allocation failed: " << e.what() << std::endl;
throw;
}
}
}
// 并发释放内存
static void ConcurrrentDealloc(void* ptr)
{
if (!ptr) return;
Span*span=PageCache::Instance()->MapObjectToSpan(ptr);
size_t size=span->ObjectSize;
Span* span = PageCache::Instance()->MapObjectToSpan(ptr);
if (size > MAX_SIZE)
{
// 大内存释放
try {
PageCache::Instance()->pagemtx_.lock();
if (!span)
{
PageCache::Instance()->pagemtx_.unlock();
throw std::runtime_error("Invalid pointer for large memory deallocation");
}
PageCache::Instance()->ReleaseSpanToPageCache(span);
// 从PageCache中注销大内存块
PageCache::Instance()->UnregisterLargeSpan(span);
PageCache::Instance()->pagemtx_.unlock();
// 使用系统分配器释放内存
SystemFree(ptr);
}
catch (const std::exception& e)
{
std::cerr << "Large memory deallocation failed: " << e.what() << std::endl;
throw;
}
}
else
{
// 小内存释放:通过TLSManager获取当前线程的ThreadCache实例
try
{
TLSManager::GetInstance().Deallocator(ptr, size);
}
catch (const std::exception& e)
{
std::cerr << "Small memory deallocation failed: " << e.what() << std::endl;
throw;
}
}
}配备内存池申请变量
这里我们就要与之前的内存池相连了,首先在PageCache.h中添加声明:
cpp
#pragma once
#include"Common.h"
#include "ConcurrentMemoryPool.h"
#include<unordered_map>
class PageCache
{
private:
SpanList spanlist_[NFRESSLISTS];
std::unordered_map<PageID, Span*>IdSpanMap_;
static PageCache sInstan_;
ConcurrentMemoryPool<Span> spanPool_;//添加声明
PageCache() = default;
PageCache(const PageCache&) = delete;
public:
static PageCache* Instance()
{
return &sInstan_;
}
// 获取从对象到span的映射
Span* MapObjectToSpan(void* obj);
// 释放空闲span回到Pagecache,并合并相邻的span
void ReleaseSpanToPageCache(Span* span);
std::mutex pagemtx_;
//获取K页的span
Span* GetSpan(size_t K);
};PageCache.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS
#include "PageCache.h"
PageCache PageCache::sInstan_;
// 获取一个K页的span
Span* PageCache::GetSpan(size_t k)
{
assert(k > 0);
// 大于128 page的直接向堆申请
if (k > NPAGES - 1)
{
void* ptr = SystemAlloc(k);
//Span* span = new Span;
Span* span = spanPool_.New();
span->PageNum = (PageID)ptr >> PAGE_SHIFT;
span->n_ = k;
IdSpanMap_[span->PageNum] = span;
return span;
}
// 先检查第k个桶里面有没有span
if (!spanlist_[k].Empty())
{
Span* kSpan = spanlist_[k].PopFront();
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (size_t i = 0; i < kSpan->n_; ++i)
{
IdSpanMap_[kSpan->PageNum + i] = kSpan;
}
return kSpan;
}
// 检查一下后面的桶里面有没有span,如果有可以把他它进行切分
for (size_t i = k + 1; i < NPAGES; ++i)
{
if (!spanlist_[i].Empty())
{
Span* nSpan = spanlist_[i].PopFront();
//Span* kSpan = new Span;
Span* kSpan = spanPool_.New();
// 在nSpan的头部切一个k页下来
// k页span返回
// nSpan再挂到对应映射的位置
kSpan->PageNum = nSpan->PageNum;
kSpan->n_ = k;
nSpan->PageNum += k;
nSpan->n_ -= k;
spanlist_[nSpan->n_].PushFront(nSpan);
// 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时
// 进行的合并查找
IdSpanMap_[nSpan->PageNum] = nSpan;
IdSpanMap_[nSpan->PageNum + nSpan->n_ - 1] = nSpan;
// 建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (PageID i = 0; i < kSpan->n_; ++i)
{
IdSpanMap_[kSpan->PageNum + i] = kSpan;
}
return kSpan;
}
}
// 走到这个位置就说明后面没有大页的span了
// 这时就去找堆要一个128页的span
//Span* bigSpan = new Span;
Span* bigSpan = spanPool_.New();
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->PageNum = (PageID)ptr >> PAGE_SHIFT;
bigSpan->n_ = NPAGES - 1;
spanlist_[bigSpan->n_].PushFront(bigSpan);
return GetSpan(k);
}
Span* PageCache::MapObjectToSpan(void* obj)
{
PageID id = ((PageID)obj >> PAGE_SHIFT);
std::unique_lock<std::mutex> lock(pagemtx_);
auto ret = IdSpanMap_.find(id);
if (ret != IdSpanMap_.end())
{
return ret->second;
}
else
{
assert(false);
return nullptr;
}
}
void PageCache::ReleaseSpanToPageCache(Span* span)
{
// 大于128 page的直接还给堆
if (span->n_ > NPAGES - 1)
{
void* ptr = (void*)(span->PageNum << PAGE_SHIFT);
SystemFree(ptr);
//delete span;
spanPool_.Delete(span);
return;
}
// 对span前后的页,尝试进行合并,缓解内存碎片问题
while (1)
{
PageID prevId = span->PageNum - 1;
auto ret = IdSpanMap_.find(prevId);
// 前面的页号没有,不合并了
if (ret == IdSpanMap_.end())
{
break;
}
// 前面相邻页的span在使用,不合并了
Span* prevSpan = ret->second;
if (prevSpan->IsUse == true)
{
break;
}
// 合并出超过128页的span没办法管理,不合并了
if (prevSpan->n_ + span->n_ > NPAGES - 1)
{
break;
}
span->PageNum = prevSpan->PageNum;
span->n_ += prevSpan->n_;
spanlist_[prevSpan->n_].Erase(prevSpan);
//delete prevSpan;
spanPool_.Delete(prevSpan);
}
// 向后合并
while (1)
{
PageID nextId = span->PageNum + span->n_;
auto ret = IdSpanMap_.find(nextId);
if (ret == IdSpanMap_.end())
{
break;
}
Span* nextSpan = ret->second;
if (nextSpan->IsUse == true)
{
break;
}
if (nextSpan->n_ + span->n_ > NPAGES - 1)
{
break;
}
span->n_ += nextSpan->n_;
spanlist_[nextSpan->n_].Erase(nextSpan);
//delete nextSpan;
spanPool_.Delete(nextSpan);
}
spanlist_[span->n_].PushFront(span);
span->IsUse = false;
IdSpanMap_[span->PageNum + span->n_ - 1] = span;
IdSpanMap_[span->PageNum] = span;
}多线程下与malloc的性能测试对比
多线程下与malloc的性能对比
cpp
#define _CRT_SECURE_NO_WARNINGS
//多线程下与malloc的性能测试
#include"ConcurrentAlloc.h"
#include<thread>
#include<vector>
#include<atomic>
#include<ctime>
#include<cstdio>
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]()
{
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(malloc(16));
//v.push_back(malloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
free(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0;
std::atomic<size_t> free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&]() {
std::vector<void*> v;
v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t begin1 = clock();
for (size_t i = 0; i < ntimes; i++)
{
v.push_back(ConcurrentAlloc(16));
//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < ntimes; i++)
{
ConcurrentFree(v[i]);
}
size_t end2 = clock();
v.clear();
malloc_costtime += (end1 - begin1);
free_costtime += (end2 - begin2);
}
});
}
for (auto& t : vthread)
{
t.join();
}
printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, malloc_costtime.load());
printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",
nworks, rounds, ntimes, free_costtime.load());
printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",
nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
int main()
{
size_t n = 1000;
cout << "==========================================================" << endl;
BenchmarkConcurrentMalloc(n, 10, 10);
cout << endl << endl;
BenchmarkMalloc(n, 10, 10);
cout << "==========================================================" << endl;
return 0;
}运行结果如下,显然我们的性能问题异常严重,但是这个性能分析和优化我们下期更新
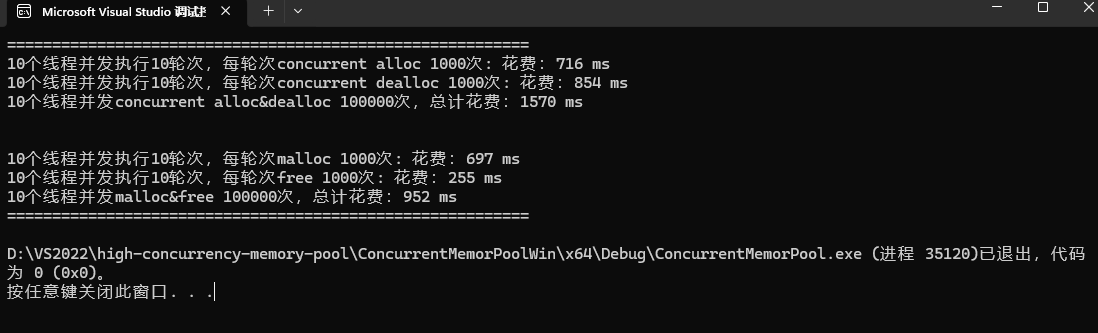
本期内容就到这里了。后续我们还会针对内存池进行进一步的性能优化
封面图自取:
