目录
还记得我们整个项目的服务架构吗?
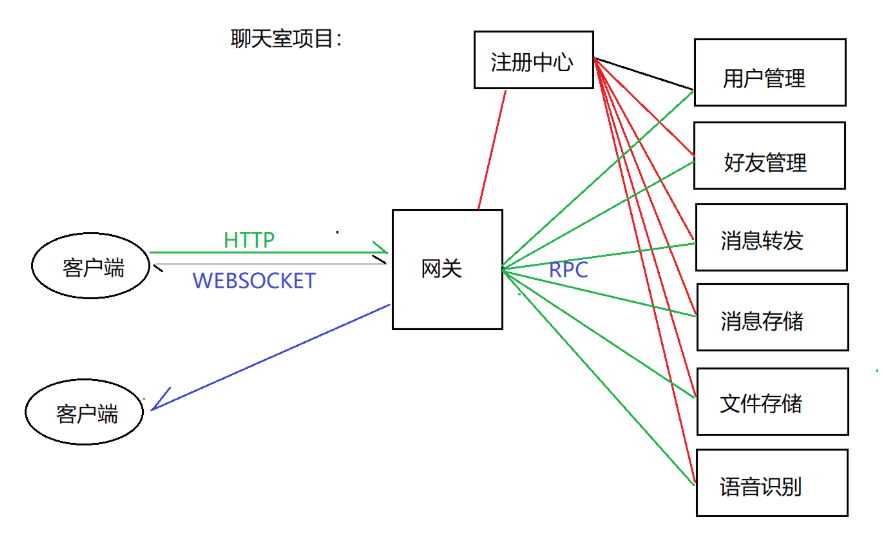
当语音识别子服务启动后,其首要任务是与注册中心(etcd服务器)建立连接并完成服务注册。
这一过程涉及以下几个关键环节:
-
向注册中心注册 :子服务实例将自身提供的RPC服务信息 (包括服务名称、版本、协议、对外访问地址和端口)**通过API写入etcd。**为了确保注册信息的准确性和实时性,通常会设置一个租约(lease)并定期续约,这样一旦服务实例崩溃或网络分区,etcd能够自动将过期实例从注册表中移除。注册完成后,该服务实例便成为服务发现体系中的一个可用节点。
-
健康检查与保活:子服务后台会启动一个心跳任务,周期性地向etcd刷新租约,告知注册中心自己依然存活。同时,etcd可以配置健康检查机制,主动探测服务实例的状态,进一步增强系统的可靠性。
-
网关的服务发现:客户端发送语音识别请求到网关,网关作为统一的入口,需要知道应该将请求转发给哪个具体的服务实例。为此,网关通常会缓存一份服务注册表,或者实时向etcd查询可用的语音识别服务实例列表。当有多个实例时,网关可以根据负载均衡策略(如轮询、一致性哈希、最少连接数等)选择一个目标实例。
-
RPC调用与结果返回 :网关确定目标实例后,会发起RPC调用(基于brpc框架),将客户端的原始请求(包含语音数据)转发给语音识别子服务。子服务接收到请求后,调用百度AI SDK完成语音识别,将识别出的文字文本封装成RPC响应返回给网关。网关再将响应转换为客户端期望的格式(如HTTP JSON或WebSocket消息)返回给客户端。
一.前置准备
1.1..hxx文件的实现
由于我们的用户管理子服务只与这个文件存储子服务存在关联,所以,我们就先搞这个用户管理子服务。
作为我们的用户,我们也需要定义一个结构来表示我们的用户(存在于base.proto文件)
cpp
// 用户信息结构,用于表示一个用户的基本资料
message UserInfo
{
string user_id = 1; // 用户ID,唯一标识一个用户
string nickname = 2; // 用户昵称
string description = 3; // 个人签名/描述
string email = 4; // 绑定邮箱号,可用于登录或联系
bytes avatar = 5; // 头像图片的二进制数据
}那么针对这些数据,我们是需要存储到我们的数据库里面的。
所以,我们借助ODB来搭建出我们的数据库的表的结构。
但是有一个问题
- 由于头像这类数据具有特殊性,它属于非结构化的二进制文件,无法像昵称、用户 ID 那样以文本形式直接存储在数据库字段中并直接获取。
- 通常的做法是将头像以二进制文件的形式单独保存到服务器端的文件系统或对象存储中,而在数据库里只存放文件路径或唯一标识。
所以数据库里面不存放真正的头像数据,只存放这个头像对应的文件ID。其实下面的ES里面也存的是文件ID,而不是真正的头像数据。
user.hxx
cpp
#pragma once
#include <cstddef>
#include <odb/core.hxx>
#include <odb/nullable.hxx>
#include <string>
namespace IMS
{
#pragma db object table("user") // ODB 映射:该类对应数据库中的 "user" 表
class User
{
public:
User() {} // 默认构造函数
// 通过用户名、昵称和密码构造用户对象
User(const std::string &uid, const std::string &nickname, const std::string &password)
: _user_id(uid), _nickname(nickname), _password(password) {}
// 通过邮箱构造用户对象(昵称默认使用 uid,密码未设置)
User(const std::string &uid, const std::string &email)
: _user_id(uid), _nickname(uid), _email(email) {}
// 设置用户 ID(数据库唯一标识,业务上唯一的用户名)
void user_id(const std::string &val) { _user_id = val; }
// 获取用户 ID
std::string user_id() { return _user_id; }
// 获取用户昵称,如果未设置则返回空字符串
std::string nickname()
{
if (_nickname)
return *_nickname;
return std::string();
}
// 设置用户昵称
void nickname(const std::string &val) { _nickname = val; }
// 获取用户描述(签名),如果未设置则返回空字符串
std::string description()
{
if (!_description)
return std::string();
return *_description;
}
// 设置用户描述
void description(const std::string &val) { _description = val; }
// 获取用户密码,如果未设置则返回空字符串
std::string password()
{
if (!_password)
return std::string();
return *_password;
}
// 设置用户密码
void password(const std::string &val) { _password = val; }
// 获取用户邮箱,如果未设置则返回空字符串
std::string email()
{
if (!_email)
return std::string();
return *_email;
}
// 设置用户邮箱
void email(const std::string &val) { _email = val; }
// 获取用户头像文件 ID,如果未设置则返回空字符串
std::string avatar_id()
{
if (!_avatar_id)
return std::string();
return *_avatar_id;
}
// 设置用户头像文件 ID
void avatar_id(const std::string &val) { _avatar_id = val; }
private:
friend class odb::access; // 允许 ODB 访问私有成员,用于持久化操作
#pragma db id auto // ODB 主键映射,auto 表示由数据库自动生成
unsigned long _id; // 内部自增主键,数据库自动分配
#pragma db type("varchar(64)") index unique // 映射为 VARCHAR(64),创建索引且唯一
std::string _user_id; // 用户业务 ID(用户名),唯一标识
#pragma db type("varchar(64)") index unique // 映射为 VARCHAR(64),创建索引且唯一
odb::nullable<std::string> _nickname; // 用户昵称,可空
odb::nullable<std::string> _description; // 用户签名(个人描述),可空
#pragma db type("varchar(64)") // 映射为 VARCHAR(64)
odb::nullable<std::string> _password; // 用户密码,可空
#pragma db type("varchar(64)") index unique // 映射为 VARCHAR(64),创建索引且唯一
odb::nullable<std::string> _email; // 用户邮箱,可空
#pragma db type("varchar(64)") // 映射为 VARCHAR(64)
odb::nullable<std::string> _avatar_id; // 用户头像文件 ID,可空
};
}
// odb -d mysql --std c++11 --generate-query --generate-schema --profile boost/date-time person.hxx
// 以上为 ODB 编译器命令示例,用于生成数据库映射代码和 SQL 建表语句这里我们着重讲解odb::nullable又是啥意思?
std::string 和 odb::nullable<std::string> 的核心区别在于 对数据库 NULL 值的表示能力。
std::string
- 始终表示一个"值",即使为空字符串 "" 也是一个有效值。
- 映射到数据库时,默认对应 NOT NULL 字段(除非手动设置 null 属性)。
- 无法区分"空字符串"和"没有值(NULL)"。
odb::nullable<std::string>
- 可以表示三种状态:有值(非空字符串)、空字符串、NULL。
- 映射到数据库时对应允许 NULL 的字段。
- 提供 null 判断方法:if (_nickname) 或 _nickname.null()。
- 取值时需先检查是否为空,避免访问无效值。
在您的代码中,像 _nickname、_description、_email 等字段之所以使用 nullable,是因为这些信息在用户注册时可能未提供,数据库需要存储 NULL 来表示"未设置",而不是空字符串。
我们完全可以写一个程序程序来测试我们的这个odb代码
test.cpp
cpp
// main.cpp (MySQL 版本)
#include <iostream>
#include <odb/database.hxx>
#include <odb/transaction.hxx>
#include <odb/mysql/database.hxx>
#include "user.hxx" // 包含 IMS::User 类定义
#include "user-odb.hxx" // ODB 生成的持久化代码
int main()
{
using namespace odb::core;
// 1. 创建 MySQL 数据库连接
auto db = std::make_shared<odb::mysql::database>(
"root", // 用户名
"123456", // 密码
"TestDB", // 数据库名
"127.0.0.1", // 主机地址
0, // 端口(0 表示默认 3306)
nullptr, // Unix socket
"utf8" // 字符集
);
// 2. 创建表(如果尚未创建)
{
transaction t(db->begin());
// 根据 User 类的映射手动创建表结构
db->execute(
"CREATE TABLE IF NOT EXISTS user ("
"id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,"
"user_id VARCHAR(64) NOT NULL UNIQUE,"
"nickname VARCHAR(64) UNIQUE,"
"description VARCHAR(64),"
"password VARCHAR(64),"
"email VARCHAR(64) UNIQUE,"
"avatar_id VARCHAR(64)"
") ENGINE=InnoDB DEFAULT CHARSET=utf8"
);
t.commit();
}
// 3. 插入测试数据
{
transaction t(db->begin());
// 使用不同的构造函数创建用户对象
IMS::User u1("zhangsan", "张三", "pass123");
u1.description("I am Zhang San");
u1.email("zhangsan@example.com");
u1.avatar_id("avatar1");
IMS::User u2("lisi", "李四", "pass456");
u2.email("lisi@example.com");
IMS::User u3("wangwu", "王五", "pass789");
u3.description("Nice guy");
u3.email("wangwu@example.com");
u3.avatar_id("avatar2");
IMS::User u4("zhaoliu", "赵六", "pass000");
// 邮箱留空(实际为 nullable,未设置时为空)
IMS::User u5("sunqi", "孙七", "pass111");
u5.email("sunqi@example.com");
IMS::User u6("zhouba", "周八", "pass222");
u6.email("zhouba@example.com");
// 持久化所有用户
db->persist(u1);
db->persist(u2);
db->persist(u3);
db->persist(u4);
db->persist(u5);
db->persist(u6);
t.commit();
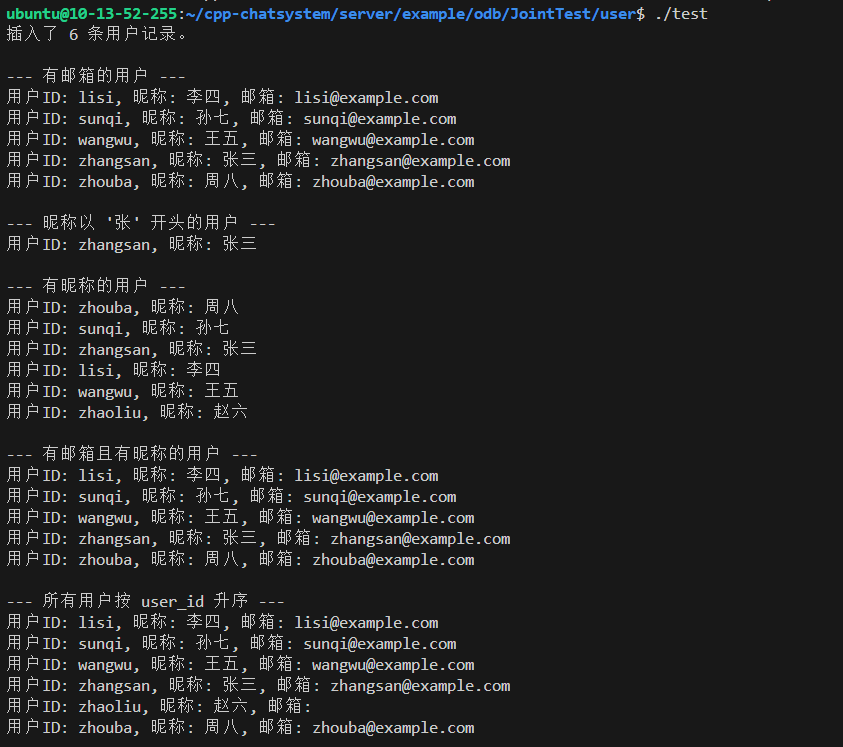
std::cout << "插入了 6 条用户记录。\n\n";
}
// 4. 查询示例
using query = odb::query<IMS::User>;
using result = odb::result<IMS::User>;
// 示例 1:查询所有有邮箱的用户(email IS NOT NULL)
{
transaction t(db->begin());
auto cond = query::email.is_not_null();
result r = db->query<IMS::User>(cond);
std::cout << "--- 有邮箱的用户 ---\n";
for (const auto& user : r) {
std::cout << "用户ID: " << user.user_id()
<< ", 昵称: " << user.nickname()
<< ", 邮箱: " << user.email() << "\n";
}
std::cout << "\n";
t.commit();
}
// 示例 2:查询昵称以 "张" 开头的用户(模糊查询)
{
transaction t(db->begin());
auto cond = query::nickname.like("张%");
result r = db->query<IMS::User>(cond);
std::cout << "--- 昵称以 '张' 开头的用户 ---\n";
for (const auto& user : r) {
std::cout << "用户ID: " << user.user_id()
<< ", 昵称: " << user.nickname() << "\n";
}
std::cout << "\n";
t.commit();
}
// 示例 3:查询昵称不为空的用户(IS NOT NULL)
{
transaction t(db->begin());
auto cond = query::nickname.is_not_null();
result r = db->query<IMS::User>(cond);
std::cout << "--- 有昵称的用户 ---\n";
for (const auto& user : r) {
std::cout << "用户ID: " << user.user_id()
<< ", 昵称: " << user.nickname() << "\n";
}
std::cout << "\n";
t.commit();
}
// 示例 4:组合条件:有邮箱 且 昵称不为空
{
transaction t(db->begin());
auto cond = query::email.is_not_null() && query::nickname.is_not_null();
result r = db->query<IMS::User>(cond);
std::cout << "--- 有邮箱且有昵称的用户 ---\n";
for (const auto& user : r) {
std::cout << "用户ID: " << user.user_id()
<< ", 昵称: " << user.nickname()
<< ", 邮箱: " << user.email() << "\n";
}
std::cout << "\n";
t.commit();
}
// 示例 5:按用户ID升序排序(所有用户)
{
transaction t(db->begin());
auto cond = query::user_id.is_not_null(); // 实际上所有记录都有 user_id
result r = db->query<IMS::User>(cond + "ORDER BY user_id ASC");
std::cout << "--- 所有用户按 user_id 升序 ---\n";
for (const auto& user : r) {
std::cout << "用户ID: " << user.user_id()
<< ", 昵称: " << user.nickname()
<< ", 邮箱: " << user.email() << "\n";
}
std::cout << "\n";
t.commit();
}
return 0;
}
我们去数据库看看
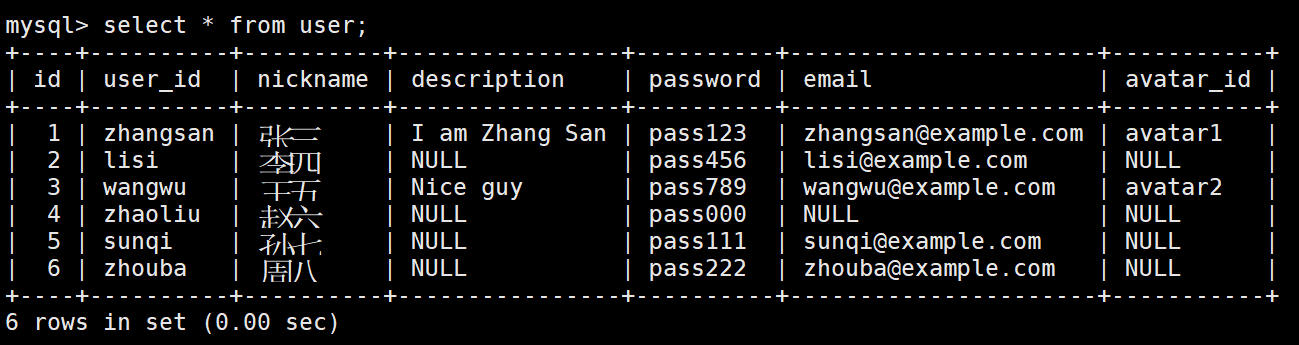
完美符合我们的预期。
1.2.mysql操作类的实现
我们虽然使用odb来实现了我们用户表的定义,但是我们针对这个用户表的增删查改的操作还是比较繁琐的,那么,我们就有必要去对这些操作进行二次封装。
首先,无论是什么表,都是需要先连接到一个数据库里面的,就像上面的例子那样子
cpp
// 1. 创建 MySQL 数据库连接
auto db = std::make_shared<odb::mysql::database>(
"root", // 用户名
"123456", // 密码
"TestDB", // 数据库名
"127.0.0.1", // 主机地址
0, // 端口(0 表示默认 3306)
nullptr, // Unix socket
"utf8" // 字符集
);那么由于我们多个子服务都需要使用到这个数据库连接,那么我们就将这个数据库连接单独进行封装
我们封装到common/mysql.hpp
cpp
#pragma once
#include <string>
#include <memory> // std::auto_ptr
#include <cstdlib> // std::exit
#include <iostream>
#include <odb/database.hxx>
#include <odb/mysql/database.hxx>
#include "logger.hpp"
// 用户注册, 用户登录, 验证码获取, 邮箱注册,邮箱登录, 获取用户信息, 用户信息修改
// 用信息新增, 通过昵称获取用户信息,通过邮箱获取用户信息, 通过用户ID获取用户信息, 通过多个用户ID获取多个用户信息,信息修改
namespace IMS
{
// ODB工厂类,用于创建MySQL数据库连接对象
class ODBFactory
{
public:
// 创建并返回一个共享的ODB MySQL数据库连接对象
// @param user 数据库用户名
// @param pswd 数据库密码
// @param host 数据库主机地址
// @param db 数据库名称
// @param cset 字符集(如utf8)
// @param port 数据库端口号
// @param conn_pool_count 连接池大小
// @return 指向odb::core::database的共享指针,可用于执行数据库操作
static std::shared_ptr<odb::core::database> create(
const std::string &user,
const std::string &pswd,
const std::string &host,
const std::string &db,
const std::string &cset,
int port,
int conn_pool_count) {
// 创建连接池工厂,指定连接池大小
std::unique_ptr<odb::mysql::connection_pool_factory> cpf(
new odb::mysql::connection_pool_factory(conn_pool_count, 0));
// 使用连接池工厂创建MySQL数据库连接对象
auto res = std::make_shared<odb::mysql::database>(user, pswd,
db, host, port, "", cset, 0, std::move(cpf));
return res;
}
};
}有了这个mysql.hpp,我们就能专注于我们的这个user表的增删查改操作了,而不用去考虑数据库连接的问题。
common/mysql_user.hpp
cpp
#pragma once
#include "mysql.hpp"
#include "user-odb.hxx"
#include "user.hxx"
namespace IMS
{
// 用户表操作类,封装对 User 对象的 CRUD 操作
class UserTable
{
public:
using ptr = std::shared_ptr<UserTable>;
// 构造函数,接收数据库连接对象
UserTable(const std::shared_ptr<odb::core::database> &db) : _db(db) {}
......
private:
std::shared_ptr<odb::core::database> _db; // 数据库连接对象
};
}我们继续编写一下
common/mysql_user.hpp
cpp
#pragma once
#include "mysql.hpp"
#include "user-odb.hxx"
#include "user.hxx"
namespace IMS
{
// 用户表操作类,封装对 User 对象的 CRUD 操作
class UserTable
{
public:
using ptr = std::shared_ptr<UserTable>;
// 构造函数,接收数据库连接对象
UserTable(const std::shared_ptr<odb::core::database> &db) : _db(db) {}
// 插入用户记录
// @param user 待插入的用户对象(共享指针)
// @return 成功返回 true,失败返回 false
bool insert(const std::shared_ptr<User> &user)
{
try
{
odb::transaction trans(_db->begin()); // 开始事务
_db->persist(*user); // 持久化对象
trans.commit(); // 提交事务
}
catch (std::exception &e)
{
LOG_ERROR("新增用户失败 {}:{}!", user->nickname(), e.what());
return false;
}
return true;
}
// 更新用户记录
// @param user 待更新的用户对象(共享指针)
// @return 成功返回 true,失败返回 false
bool update(const std::shared_ptr<User> &user)
{
try
{
odb::transaction trans(_db->begin()); // 开始事务
_db->update(*user); // 更新对象
trans.commit(); // 提交事务
}
catch (std::exception &e)
{
LOG_ERROR("更新用户失败 {}:{}!", user->nickname(), e.what());
return false;
}
return true;
}
// 根据昵称查询用户
// @param nickname 用户昵称
// @return 用户对象的共享指针,若未找到则返回空指针
std::shared_ptr<User> select_by_nickname(const std::string &nickname)
{
std::shared_ptr<User> res;
try
{
odb::transaction trans(_db->begin()); // 开始事务
typedef odb::query<User> query; // 查询类型别名
typedef odb::result<User> result; // 结果集类型别名
res.reset(_db->query_one<User>(query::nickname == nickname)); // 执行查询
trans.commit(); // 提交事务
}
catch (std::exception &e)
{
LOG_ERROR("通过昵称查询用户失败 {}:{}!", nickname, e.what());
}
return res;
}
// 根据邮箱查询用户
// @param email 用户邮箱
// @return 用户对象的共享指针,若未找到则返回空指针
std::shared_ptr<User> select_by_email(const std::string &email)
{
std::shared_ptr<User> res;
try
{
odb::transaction trans(_db->begin()); // 开始事务
typedef odb::query<User> query; // 查询类型别名
typedef odb::result<User> result; // 结果集类型别名
res.reset(_db->query_one<User>(query::email == email)); // 执行查询
trans.commit(); // 提交事务
}
catch (std::exception &e)
{
LOG_ERROR("通过邮箱查询用户失败 {}:{}!", email, e.what());
}
return res;
}
// 根据用户ID查询用户
// @param user_id 用户唯一标识
// @return 用户对象的共享指针,若未找到则返回空指针
std::shared_ptr<User> select_by_id(const std::string &user_id)
{
std::shared_ptr<User> res;
try
{
odb::transaction trans(_db->begin()); // 开始事务
typedef odb::query<User> query; // 查询类型别名
typedef odb::result<User> result; // 结果集类型别名
res.reset(_db->query_one<User>(query::user_id == user_id)); // 执行查询
trans.commit(); // 提交事务
}
catch (std::exception &e)
{
LOG_ERROR("通过用户ID查询用户失败 {}:{}!", user_id, e.what());
}
return res;
}
// 根据用户ID列表批量查询用户
// @param id_list 用户ID的列表
// @return 用户对象的向量,按查询顺序返回
std::vector<User> select_multi_users(const std::vector<std::string> &id_list)
{
// select * from user where id in ('id1', 'id2', ...)
if (id_list.empty())
{
return std::vector<User>(); // 空列表直接返回空结果
}
std::vector<User> res;
try
{
odb::transaction trans(_db->begin()); // 开始事务
typedef odb::query<User> query; // 查询类型别名
typedef odb::result<User> result; // 结果集类型别名
// 动态构造 IN 条件字符串
std::stringstream ss;
ss << "user_id in (";
for (const auto &id : id_list)
{
ss << "'" << id << "',";
}
std::string condition = ss.str();
condition.pop_back(); // 移除最后一个逗号
condition += ")";
// 执行原始查询
result r(_db->query<User>(condition));
// 将结果转换为 vector
for (result::iterator i(r.begin()); i != r.end(); ++i)
{
res.push_back(*i);
}
trans.commit(); // 提交事务
}
catch (std::exception &e)
{
LOG_ERROR("通过用户ID批量查询用户失败:{}!", e.what());
}
return res;
}
private:
std::shared_ptr<odb::core::database> _db; // 数据库连接对象
};
}UserTable 类封装了对 User 数据库表的基本 CRUD 操作,提供了以下功能:
插入:insert() -- 向数据库插入一条用户记录。
更新:update() -- 更新已存在的用户记录。
单条查询:
- select_by_nickname() -- 根据用户昵称查询单个用户。
- select_by_email() -- 根据邮箱查询单个用户。
- select_by_id() -- 根据用户业务 ID(用户名)查询单个用户。
批量查询:select_multi_users() -- 根据多个用户 ID 批量查询用户列表(使用 IN 子句)。
所有数据库操作均在事务中执行,并捕获异常并记录日志。该类通过封装 ODB 的持久化接口,简化了上层业务对 User 表的访问。
1.3.ES客户端搭建
由于我们在用户管理的过程中,需要进行根据用户名来搜索
我们的ES客户端封装的是核心其实是查询操作。
Elasticsearch 基于 Lucene 构建,专为全文检索、模糊匹配、复杂条件组合、聚合分析而设计。它的倒排索引结构可以毫秒级响应关键词搜索,支持多字段匹配、权重调整、高亮显示等。
ESUser::search() 方法实现了在 user_id.keyword、email.keyword、nickname 三个字段中进行多字段匹配,并支持排除指定用户列表。
这种查询如果用 MySQL 实现:
- 可能需要写多个 LIKE '%keyword%' 条件,在大数据量下性能极差。
- 排除列表的 NOT IN 可能更慢,且无法使用索引优化。
首先我们肯定需要一个工厂类来快速搭建我们的ES客户端句柄
cpp
// ESClientFactory类:用于创建elasticlient::Client对象的工厂类
class ESClientFactory
{
public:
// 静态方法:根据主机列表创建并返回elasticlient::Client的共享指针
// 参数:
// host_list - Elasticsearch节点地址列表(例如:{"http://localhost:9200"})
static std::shared_ptr<elasticlient::Client> create(const std::vector<std::string> host_list)
{
// 使用主机列表构造Client对象并封装为共享指针返回
return std::make_shared<elasticlient::Client>(host_list);
}
};我们的ESUser类就是基于这个客户端句柄来进行操作的
cpp
// ESUser类:管理Elasticsearch中用户索引的增删改查操作
class ESUser
{
public:
// 类型别名:指向ESUser的共享指针
using ptr = std::shared_ptr<ESUser>;
// 构造函数:接收elasticlient::Client共享指针,用于后续操作
// 参数:
// client - Elasticsearch客户端共享指针
ESUser(const std::shared_ptr<elasticlient::Client> &client) : _es_client(client) {}
......
private:
std::shared_ptr<elasticlient::Client> _es_client;
};有了客户端,我们就需要提供下面这3步核心操作
- 创建索引
- 向索引内容添加一条新数据
- 在索引内部查询数据
1.3.1.创建索引
注意这个ESIndex这个接口其实是我们的common/icsearch.hpp里面的,如果你有点忘记了,我这里直接给你看common/icsearch.hpp源代码
cpp
// 类 ESIndex:用于定义和创建 Elasticsearch 索引的映射(mapping)和设置(settings)
class ESIndex
{
public:
// 构造函数:初始化索引名称、文档类型,并设置默认的 IK 分词器配置
// 参数 client:指向 elasticlient::Client 的共享指针,用于发送 HTTP 请求
// 参数 name:索引名称
// 参数 type:文档类型,默认为 "_doc"(Elasticsearch 7.x 后推荐)
ESIndex(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client)
{
// 构建索引设置(settings)部分,配置 IK 分词器
Json::Value analysis; // analysis 对象
Json::Value analyzer; // analyzer 对象
Json::Value ik; // ik 分词器对象
Json::Value tokenizer; // tokenizer 对象
// 设置分词器为 ik_max_word(IK 分词器的最大粒度分词模式)
tokenizer["tokenizer"] = "ik_max_word";
// 将 tokenizer 赋值给 ik 对象下的 "ik" 字段
ik["ik"] = tokenizer;
// 将 ik 对象赋值给 analyzer 对象下的 "analyzer" 字段
analyzer["analyzer"] = ik;
// 将 analyzer 对象赋值给 analysis 对象下的 "analysis" 字段
analysis["analysis"] = analyzer;
// 将 analysis 对象放入 _index 的 "settings" 字段中
_index["settings"] = analysis;
}
// 成员函数 append:向索引的 properties 中添加一个字段定义(链式调用)
// 参数 key:字段名称
// 参数 type:字段类型,默认为 "text"
// 参数 analyzer:分词器名称,默认为 "ik_max_word"
// 参数 enabled:是否启用该字段(若为 false,则该字段不会被索引和存储)
// 返回值:返回当前对象的引用,支持链式调用
ESIndex& append(const std::string &key,
const std::string &type = "text",
const std::string &analyzer = "ik_max_word",
bool enabled = true)
{
Json::Value fields;
fields["type"] = type; // 设置字段类型
fields["analyzer"] = analyzer; // 设置分词器(仅对 text 类型有效)
if (enabled == false)
{
// 如果 enabled 为 false,则添加 "enabled": false 字段,表示该字段不参与索引和存储
fields["enabled"] = enabled;
}
// 将该字段定义添加到 _properties 对象中,键为字段名
_properties[key] = fields;
// 返回当前对象引用,以便链式调用
return *this;
}
// 成员函数 create:根据已添加的字段定义,创建索引(实际发送请求到 Elasticsearch)
// 参数 index_id:可选的索引文档 ID,但这里可能用于某些特殊场景,默认为 "default_index_id"
// 注意:在 elasticlient 的 index 方法中,如果指定了 ID,会创建或更新一个文档,而不是创建索引本身。
// 但是如果索引不存在,那么就会自动触发索引的自动创建(同时设置 mapping),
bool create(const std::string &index_id = "default_index_id")
{
// 构建 mappings 部分
Json::Value mappings;
mappings["dynamic"] = true; // 允许动态添加字段(未在 mapping 中定义的字段也会被索引)
mappings["properties"] = _properties; // 将字段定义赋值给 properties
_index["mappings"] = mappings; // 将 mappings 对象放入 _index 的 "mappings" 字段
// 将整个 _index 对象序列化为字符串
std::string body;
bool ret = Serialize(_index, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body); // 输出序列化后的请求体,便于调试
// 发起索引创建请求(实际上调用的是 index 方法,可能期望创建索引并插入一个文档)
try
{
// 调用 client->index 方法,传入索引名称、类型、文档 ID 和请求体
// 注意:这实际上是在创建或更新一个文档,而不是纯粹的创建索引。
// 如果索引不存在,Elasticsearch 会自动创建索引并使用请求体中的 mapping 作为索引的 mapping。
auto rsp = _client->index(_name, _type, index_id, body);
// 检查响应状态码是否为 2xx(成功)
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("创建ES索引 {} 失败,响应状态码异常: {}", _name, rsp.status_code);
return false;
}
}
catch(std::exception &e)
{
// 捕获异常并记录错误
LOG_ERROR("创建ES索引 {} 失败: {}", _name, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型(通常为 "_doc")
Json::Value _properties; // 存储字段定义的 JSON 对象(mapping 的 properties 部分)
Json::Value _index; // 完整的索引定义(包含 settings 和 mappings)
std::shared_ptr<elasticlient::Client> _client; // 共享的 elasticlient 客户端指针
};回忆过我们的icsearch.hpp之后,我们就来创建我们的索引吧
cpp
// 创建用户索引(如果不存在)
// 返回值:成功返回true,失败返回false
bool createIndex()
{
// 构建索引结构:定义字段及其类型、分词器、是否存储等属性
bool ret = ESIndex(_es_client, "user") // 指定索引名称为"user"
.append("user_id", "keyword", "standard", true) // 用户ID,keyword类型,标准分词,存储
.append("nickname") // 昵称,默认text类型,standard分词,不存储
.append("email", "keyword", "standard", true) // 邮箱,keyword类型,标准分词,存储
.append("description", "text", "standard", false) // 描述,text类型,标准分词,不存储
.append("avatar_id", "keyword", "standard", false) // 头像ID,keyword类型,标准分词,不存储
.create(); // 执行创建索引操作
if (ret == false)
{
LOG_INFO("用户信息索引创建失败!"); // 记录失败日志
return false;
}
LOG_INFO("用户信息索引创建成功!"); // 记录成功日志
return true;
}
我知道大家这样子看其实是有一点小困难的。
那么我们就将它转换成JSON格式来看看
cpp
{
// ----- 索引设置部分 -----
"settings": {
"analysis": {
"analyzer": {
"ik": { // 定义名为 "ik" 的自定义分析器
"tokenizer": "ik_max_word" // 使用 IK 分词器的最大粒度分词模式
}
}
}
},
// ----- 映射部分 -----
"mappings": {
"dynamic": true, // 允许动态添加字段(ESIndex 默认设置)
"properties": {
// 用户 ID 字段:keyword 类型,用于精确匹配,存储原始值,使用 standard 分析器
"user_id": {
"type": "keyword", // 精确匹配字段
"store": true, // 存储该字段的原始值
"analyzer": "standard" // 指定分析器(代码中显式传入 "standard")
},
// 昵称字段:text 类型,用于全文搜索,不存储,使用 standard 分析器
"nickname": {
"type": "text", // 全文搜索字段, Eindex::append里面的默认参数会使用 "text"
"store": true, // 单独存储
"analyzer": "ik_max_word" // 代码中未显式传入,但 Eindex::append里面的默认参数会使用 "ik_max_word"
},
// 邮箱字段:keyword 类型,精确匹配,存储,使用 standard 分析器
"email": {
"type": "keyword",
"store": true,
"analyzer": "standard"
},
// 描述字段:text 类型,全文搜索,不存储,使用 standard 分析器
"description": {
"type": "text",
"store": false,
"analyzer": "standard"
},
// 头像 ID 字段:keyword 类型,精确匹配,不存储,使用 standard 分析器
"avatar_id": {
"type": "keyword",
"store": false,
"analyzer": "standard"
}
}
}
}这个创建索引还算是明白吧。
如果不明白,请回去:【即时通讯系统】环境搭建4------Elasticsearch(ES)-CSDN博客
1.3.2.往索引里面添加数据
这个还是借助了icsearch.hpp的ESInsert来实现
cpp
// 类 ESInsert:用于向 Elasticsearch 索引中插入或更新文档
class ESInsert
{
public:
// 构造函数:初始化索引名称、文档类型和客户端指针
ESInsert(std::shared_ptr<elasticlient::Client> &client,
const std::string &name, //索引名称
const std::string &type = "_doc"):
_name(name),
_type(type),
_client(client){}
// 模板成员函数 append:向待插入的文档中添加字段(链式调用)
// 参数 key:字段名
// 参数 val:字段值,可以是任意类型(Json::Value 支持的类型)
// 返回值:返回当前对象的引用,支持链式调用
template<typename T>
ESInsert &append(const std::string &key, const T &val){
_item[key] = val; // 将键值对存入 _item 对象
return *this;
}
// 成员函数 insert:将构建的文档插入到 Elasticsearch 中
// 参数 id:可选,文档的 ID。如果为空字符串,Elasticsearch 会自动生成 ID。
// 返回值:成功返回 true,失败返回 false
bool insert(const std::string id = "")
{
// 将 _item 序列化为 JSON 字符串
std::string body;
bool ret = Serialize(_item, body);
if (ret == false)
{
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body); // 输出请求体,便于调试
// 发起索引文档请求
try
{
// 调用 client->index 方法,传入索引名、类型、文档 ID 和请求体
auto rsp = _client->index(_name, _type, id, body);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("新增数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return false;
}
}
catch(std::exception &e)
{
LOG_ERROR("新增数据 {} 失败: {}", body, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
Json::Value _item; // 存储待插入文档的 JSON 对象
std::shared_ptr<elasticlient::Client> _client; // 共享的客户端指针
};现在我们就能比较轻松的写出下面这个代码了
cpp
// 向用户索引中插入或更新一条用户数据
// 参数:
// uid - 用户ID(作为文档ID)
// email - 邮箱
// nickname - 昵称
// description - 描述
// avatar_id - 头像ID
// 返回值:成功返回true,失败返回false
bool appendData(const std::string &uid,
const std::string &email,
const std::string &nickname,
const std::string &description,
const std::string &avatar_id)
{
// 构建插入数据
bool ret = ESInsert(_es_client, "user") // 指定索引"user"
.append("user_id", uid) // 添加字段user_id
.append("nickname", nickname) // 添加字段nickname
.append("email", email) // 添加字段email
.append("description", description) // 添加字段description
.append("avatar_id", avatar_id) // 添加字段avatar_id
.insert(uid); // 执行插入,以uid作为文档ID
if (ret == false)
{
LOG_ERROR("用户数据插入/更新失败!"); // 记录错误日志
return false;
}
LOG_INFO("用户数据新增/更新成功!"); // 记录成功日志
return true;
}这个也没什么好说的,就是存储的添加而已。
1.3.3.查询数据
这个还是借助了icsearch.hpp的ESSearch类来进行实现
这里我就不列出来了,你们自己去代码网站里面找
cpp
// 根据关键词搜索用户,并排除指定的用户ID列表
// 参数:
// key - 搜索关键词(将在email、user_id、nickname字段中匹配)
// uid_list - 需要排除的用户ID列表(不返回这些用户)
// 返回值:User对象的vector,包含搜索结果
std::vector<User> search(const std::string &key, const std::vector<std::string> &uid_list)
{
std::vector<User> res; // 存储结果
// 构建搜索查询:should条件(任意匹配) + must_not排除
Json::Value json_user = ESSearch(_es_client, "user") // 指定索引"user"
.append_should_match("email.keyword", key) // email.keyword字段匹配关键词
.append_should_match("user_id.keyword", key) // user_id.keyword字段匹配关键词
.append_should_match("nickname", key) // nickname字段(text类型)匹配关键词
.append_must_not_terms("user_id.keyword", uid_list) // 排除指定user_id列表
.search(); // 执行搜索,返回JSON格式结果
if (json_user.isArray() == false)
{ // 检查结果是否为数组
LOG_ERROR("用户搜索结果为空,或者结果不是数组类型");
return res; // 返回空vector
}
int sz = json_user.size(); // 获取结果数量
LOG_DEBUG("检索结果条目数量:{}", sz);
// 遍历搜索结果,将JSON转换为User对象
for (int i = 0; i < sz; i++)
{
User user; // 创建User对象
// 从JSON中提取_source下的字段值并设置到User对象
user.user_id(json_user[i]["_source"]["user_id"].asString());
user.nickname(json_user[i]["_source"]["nickname"].asString());
user.description(json_user[i]["_source"]["description"].asString());
user.email(json_user[i]["_source"]["email"].asString());
user.avatar_id(json_user[i]["_source"]["avatar_id"].asString());
res.push_back(user); // 添加到结果vector
}
return res;
}Elasticsearch 的 bool 查询包含四种逻辑子句,它们可以灵活组合,实现复杂的搜索逻辑:
- should: 子句中的条件至少满足一个 (逻辑 OR),**满足的条件越多,文档的相关度评分越高。**如果 bool 查询中没有 must 或 filter,则至少需要满足一个 should 条件(除非通过 minimum_should_match 参数另行控制)。
- must_not: 子句中的条件必须都不满足 (逻辑 NOT),用于排除文档。它也是过滤行为,不参与评分,同样可以利用缓存。
在构建 上面这2种 子句时,可以根据字段类型和查询意图选择不同的查询类型,其中最常用的是 term 和 match:
- term 查询 :用于精确匹配某个字段的确切值。它不会对查询词进行分析(即不分词),直接在倒排索引中查找与给定值完全相等的词条。适用于 keyword 类型、数值、日期等需要精确匹配的字段。
- 例如:{ "term": { "user_id": "USER4b862aaa..." } } 会精确匹配 user_id 字段为指定字符串的文档。
- match 查询 :用于全文搜索,会对查询文本进行分析**(分词)**,然后去匹配字段中的词条。它适用于 text 类型字段,会按照字段的分析器(如 IK 分词器)对查询字符串进行分词,再在倒排索引中查找这些词条。
- 例如:{ "match": { "nickname": "张三" } } 如果 nickname 是 text 类型,查询词 "张三" 会被分词为 "张" 和 "三",然后匹配包含这两个词的文档。
上面那段代码对应的查询语句如下:注意
下面这个张三是我们传递进去的key,这个"user1", "user2"是我们传递进去的uid_list
cpp
{
"query": {
"bool": {
// should 子句:匹配任意一个即可(类似 OR)
"should": [
{
"match": {
"email.keyword": "张三" // 在 email.keyword 字段精确匹配(keyword 类型)
}
},
{
"match": {
"user_id.keyword": "张三" // 在 user_id.keyword 字段精确匹配
}
},
{
"match": {
"nickname": "张三" // 在 nickname 字段全文搜索(text 类型,会分词)
}
}
],
// must_not 子句:必须不满足的条件(类似 NOT IN)
"must_not": [
{
"terms": {
"user_id.keyword": ["user1", "user2"] // 排除指定的用户 ID 列表
}
}
]
}
}
}bool 是复合查询,可以将多个条件组合在一起。它包含以下子句(这里用了 should 和 must_not):
一.should(应匹配)
含义:只要满足其中任意一个条件,文档就算匹配(类似于 SQL 中的 OR)。
作用:让搜索结果包含与关键词相关的用户。
这里 should 中有三个条件(数组):
1.match 查询 on email.keyword
- match 是全文搜索查询,会对查询词进行分析。
- 但 email.keyword 字段是 keyword 类型(精确值),所以这里的 match 实际上会当作精确匹配处理,等价于 term 查询。
- 目的:如果用户的邮箱字段完全等于关键词,就匹配。
2.match 查询 on user_id.keyword
- 同上,user_id.keyword 也是 keyword 类型,精确匹配用户的业务 ID(用户名)。
- 目的:如果用户 ID 完全等于关键词,就匹配。
3.match 查询 on nickname
- nickname 是 text 类型,会被 IK 分词器分词。
- 这里 match 会将关键词"张三"进行分词(如"张"、"三"、"张三"),然后去匹配昵称字段的分词结果。
- 目的:如果昵称中包含关键词的分词片段,就匹配(支持模糊搜索)。
综合:只要用户满足上述三个条件中的任意一个,就会被纳入候选结果。
二.must_not(必须不匹配)
-
含义:文档必须不满足该子句中的所有条件(类似于 SQL 中的 NOT IN)。
-
作用:排除某些用户。
-
terms 查询用于精确匹配多个值(类似于 SQL 的 IN,这里是 NOT IN 的逻辑)。
-
含义:用户 ID 不能是 "user1" 或 "user2"。如果用户 ID 在这两个值中,就会被排除。
1.4.Redis客户端搭建
Redis 数据管理主要包含以下三个核心功能:
-
会话信息管理
以会话 ID 为键、用户 ID 为值,维护登录会话的映射关系。
-
用户登录时,系统分配一个唯一的会话 ID,并将其与用户 ID 一并存入 Redis,完成会话创建。
-
用户在后续操作中携带该会话 ID,服务端通过此 ID 在 Redis 中快速查找对应的用户 ID,用于身份认证和鉴权。
-
支持会话的新增、删除、获取等基本操作,确保会话生命周期可被有效管理。
-
-
登录状态管理
以用户 ID 为键,值置为空(仅用于存在性判断),记录用户的在线状态。
-
用户登录成功后,将其用户 ID 写入 Redis,标记为在线。
-
当用户长连接断开(如 WebSocket 关闭)或主动登出时,删除对应键,标记为离线。
-
若用户尝试重复登录,系统会检查该用户 ID 是否已存在,若存在则判定为重复登录,可根据业务策略拒绝新登录或强制踢出旧会话。
-
提供登录状态的新增、删除、存在性判断等操作,便于实时监控用户在线情况。
-
-
验证码管理
以验证码标识(通常为手机号或邮箱)为键,验证码字符串为值,并设置有效期。
-
用户请求获取短信或邮箱验证码时,系统生成随机验证码及其标识,将键值对存入 Redis 并设定有效期(如 5 分钟),保证验证码具有时效性。
-
在邮箱注册、登录、修改绑定邮箱等需要身份验证的环节,用户提交验证码后,系统根据标识从 Redis 中获取验证码进行比对,验证成功则立即删除该记录,防止验证码被重复使用。
-
支持验证码的新增、删除、获取等操作,满足安全验证需求。
-
以上三类数据均利用 Redis 的高性能、键值存储及自动过期特性,为系统提供高效的会话、状态及验证码管理能力。
首先,我们在实现上面3个功能的时候,都是需要创建Redis客户端,那么我们干脆就使用一个工厂类来创建这个Redis客户端指针
cpp
// RedisClientFactory类:用于创建Redis客户端连接的工厂类
class RedisClientFactory
{
public:
// 静态方法:创建并返回一个指向sw::redis::Redis对象的共享指针
// 参数:
// host - Redis服务器的主机名或IP地址
// port - Redis服务器的端口号
// db - 要使用的数据库索引(默认0)
// keep_alive - 是否保持长连接
static std::shared_ptr<sw::redis::Redis> create(
const std::string &host,
int port,
int db,
bool keep_alive)
{
// 设置Redis连接选项
sw::redis::ConnectionOptions opts;
opts.host = host; // 主机
opts.port = port; // 端口
opts.db = db; // 数据库编号
opts.keep_alive = keep_alive; // 是否保持连接活跃
// 创建Redis对象并封装为共享指针返回
auto res = std::make_shared<sw::redis::Redis>(opts);
return res;
}
};那么3个服务内部的成员变量都是这个Redis客户端指针,这些服务都是基于这个客户端指针来完成的
1.4.1.会话信息管理
**用户登录成功后,服务端会为其分配一个全局唯一的会话 ID。**这个会话 ID 与用户 ID 是一一对应的关系,作为用户在本次登录会话中的身份凭证。
会话 ID 通常在验证用户身份、确认未在其他地方重复登录后生成,一般采用 UUID 或类似的唯一字符串。服务端会将会话 ID 与用户 ID 的映射关系存入 Redis,同时标记该用户为"已登录"状态。随后,服务端将这个会话 ID 返回给客户端,客户端需要在后续请求中携带该 ID 以证明自己的登录状态。
**当客户端发起需要身份认证的请求时,服务端根据请求中携带的会话 ID,从 Redis 中查找对应的用户 ID,从而识别出具体是哪个用户,并确认其登录状态是否仍然有效。**这种方式实现了无状态的鉴权机制,服务端无需在本地存储登录信息,每次请求都通过 Redis 查询完成身份识别,既保证了水平扩展能力,也让客户端无需重复输入密码即可保持登录状态。
当用户主动退出登录,或因超时导致会话失效时,服务端会将该会话 ID 与用户 ID 的映射关系从 Redis 中删除 ,**同时清除用户的登录标记。**此后该会话 ID 即失效,无法再用于身份认证,从而确保会话的安全性和状态的准确控制。
cpp
// Session类:管理用户会话,使用Redis存储会话ID与用户ID的映射
class Session
{
public:
// 类型别名:指向Session的共享指针
using ptr = std::shared_ptr<Session>;
// 构造函数:接收一个Redis客户端共享指针,用于后续操作
// 参数:
// redis_client - 共享的Redis客户端对象
Session(const std::shared_ptr<sw::redis::Redis> &redis_client):
_redis_client(redis_client){}
// 添加或更新会话:将会话ID(ssid)与用户ID(uid)关联存储到Redis
// 参数:
// ssid - 会话ID(用作键)
// uid - 用户ID(用作值)
void append(const std::string &ssid, const std::string &uid) {
_redis_client->set(ssid, uid); // 执行Redis SET命令
}
// 删除指定的会话记录
// 参数:
// ssid - 要删除的会话ID
void remove(const std::string &ssid) {
_redis_client->del(ssid); // 执行Redis DEL命令
}
// 根据会话ID获取对应的用户ID
// 参数:
// ssid - 会话ID
// 返回值:
// sw::redis::OptionalString,如果键存在则包含用户ID,否则为空
sw::redis::OptionalString uid(const std::string &ssid) {
return _redis_client->get(ssid); // 执行Redis GET命令
}
private:
// 私有成员:Redis客户端共享指针,所有操作通过它进行
std::shared_ptr<sw::redis::Redis> _redis_client;
};这里管理的键值对就是<会话ID,用户ID>
1.4.2.登陆状态管理
这个类通过 Redis 来管理用户的在线状态,核心逻辑非常简单:用键的存在与否表示在线或离线。
- 标记在线:当用户登录成功时,调用 append 方法,在 Redis 中设置一个键,键名就是用户 ID,值为空字符串。此时键存在,即代表该用户在线。
- 标记离线:当用户退出登录或会话过期时,调用 remove 方法,将对应的键从 Redis 中删除。键被删除后,就代表用户离线。
- 检查状态:通过 exists 方法,调用 Redis 的 get 命令检查该键是否存在。如果 get 能取到值(哪怕是个空值),说明键存在,用户在线;如果返回空,说明键已被删除或从未设置,用户离线。
这种方式利用了 Redis 作为高速缓存,实现了一种轻量级的在线状态追踪,只需一次键值查询即可完成判断,非常适合高并发场景。
cpp
// Status类:管理用户在线状态,通过存在性检查判断用户是否在线
class Status
{
public:
// 类型别名:指向Status的共享指针
using ptr = std::shared_ptr<Status>;
// 构造函数:接收一个Redis客户端共享指针
// 参数:
// redis_client - 共享的Redis客户端对象
Status(const std::shared_ptr<sw::redis::Redis> &redis_client):
_redis_client(redis_client){}
// 标记用户为在线:在Redis中设置一个键(uid),值为空字符串
// 参数:
// uid - 用户ID,作为键
void append(const std::string &uid) {
_redis_client->set(uid, ""); // 存储空值,仅用于存在性检查
}
// 标记用户为离线:删除对应的键
// 参数:
// uid - 用户ID
void remove(const std::string &uid) {
_redis_client->del(uid);
}
// 检查用户是否在线:通过GET命令判断键是否存在
// 参数:
// uid - 用户ID
// 返回值:
// true 表示键存在(在线),false 表示不存在(离线)
bool exists(const std::string &uid) {
auto res = _redis_client->get(uid); // 尝试获取值
if (res) return true; // 如果有值,则用户在线
return false; // 否则离线
}
private:
// 私有成员:Redis客户端共享指针
std::shared_ptr<sw::redis::Redis> _redis_client;
};1.4.3.验证码管理
验证码在生成的时候,我们也会去生成一个独一无二的验证码ID。
我们将<验证码ID,验证码>存入Redis,这样子客户端判断验证码是否有效的时候就可以去Redis服务器中查询。
但是我们的验证码是有时效的,所以我们需要给<验证码ID,验证码>加上一个TTL租约,默认设置为5分钟,如果想要修改,可以通过第3个参数来设定
cpp
// Codes类:管理验证码,支持设置过期时间
class Codes
{
public:
// 类型别名:指向Codes的共享指针
using ptr = std::shared_ptr<Codes>;
// 构造函数:接收一个Redis客户端共享指针
// 参数:
// redis_client - 共享的Redis客户端对象
Codes(const std::shared_ptr<sw::redis::Redis> &redis_client):
_redis_client(redis_client){}
// 添加或更新验证码:将验证码code与标识cid关联存储,并设置过期时间
// 参数:
// cid - 验证码的标识,用作键
// code - 验证码内容,用作值
// t - 过期时间,默认为300000毫秒(5分钟)
void append(const std::string &cid, const std::string &code,
const std::chrono::milliseconds &t = std::chrono::milliseconds(300000))
{
// 执行Redis SET命令,并指定过期时间(毫秒)
_redis_client->set(cid, code, t);
}
// 删除指定的验证码记录
// 参数:
// cid - 验证码标识
void remove(const std::string &cid) {
_redis_client->del(cid);
}
// 根据标识获取对应的验证码内容
// 参数:
// cid - 验证码标识
// 返回值:
// sw::redis::OptionalString,如果键存在则包含验证码,否则为空
sw::redis::OptionalString code(const std::string &cid) {
return _redis_client->get(cid);
}
private:
// 私有成员:Redis客户端共享指针
std::shared_ptr<sw::redis::Redis> _redis_client;
};我们这里特别需要注意,对于验证码,我们是设置了5分钟的租约的,也就是说,我们的验证码是在5分钟内有效!!!