一、一致性

事务的作用:状态的安全切换
- 事务的本质就是把数据库从一个合法的一致性状态,安全地切换到另一个合法的一致性状态 :
- 事务开始前:数据库是状态 A(合法)
- 事务执行中:可能暂时出现中间状态(比如钱已扣、未到账),但这些中间状态对其他事务不可见
- 事务提交后:数据库变成状态 B(依然合法)
- 如果事务失败回滚:数据库会回到状态 A,不会停在中间的不一致状态
一致性的规则不是数据库天生自带的,而是由你的业务逻辑定义的:
- 数据库只提供技术手段(比如原子性、隔离性、持久性)来保证规则不被破坏
- 真正的 "什么是一致",比如 "转账必须金额相等""库存不能为负",是由业务代码和约束来定义的
二、数据并发的场景有三种
2.1 读 - 读(Read-Read)
- 场景:多个事务同时读取同一份数据,比如多个用户同时查询商品库存。
- 特点 :读操作不会修改数据,彼此之间没有冲突,不会破坏数据一致性。
- 结论 :不存在安全问题,不需要任何并发控制,可以直接并行执行,效率最高。
2.2 读 - 写(Read-Write)
- 场景:一个事务在读取数据,另一个事务在修改同一份数据,比如用户 A 查看余额,同时用户 B 在转账扣款。
- 风险 :会破坏事务的隔离性,引发三类经典问题:
- 脏读:读到了其他事务未提交的修改(如果对方回滚,数据就无效了)。
- 不可重复读:同一事务内,两次读取同一份数据,结果却不一样(因为中间被其他事务修改并提交了)。
- 幻读:同一事务内,两次范围查询得到的行数不一样(因为中间有其他事务插入 / 删除了符合条件的记录)。
- 处理 :需要通过事务隔离级别 (如读已提交、可重复读)或锁机制来控制。
2.3 写 - 写(Write-Write)
- 场景:多个事务同时修改同一份数据,比如两个用户同时下单扣减同一件商品的库存。
- 风险 :会导致更新丢失 (Lost Update),分为两类:
- 第一类更新丢失 :一个事务回滚时,覆盖了另一个事务已提交的修改。
- 第二类更新丢失 :两个事务同时读取同一份数据,各自修改后提交,后提交的事务会覆盖先提交的结果,导致先提交的修改丢失。
- 处理 :需要通过悲观锁 (如行锁、表锁)或乐观锁(如版本号、时间戳)来保证写操作的互斥。
三、读写
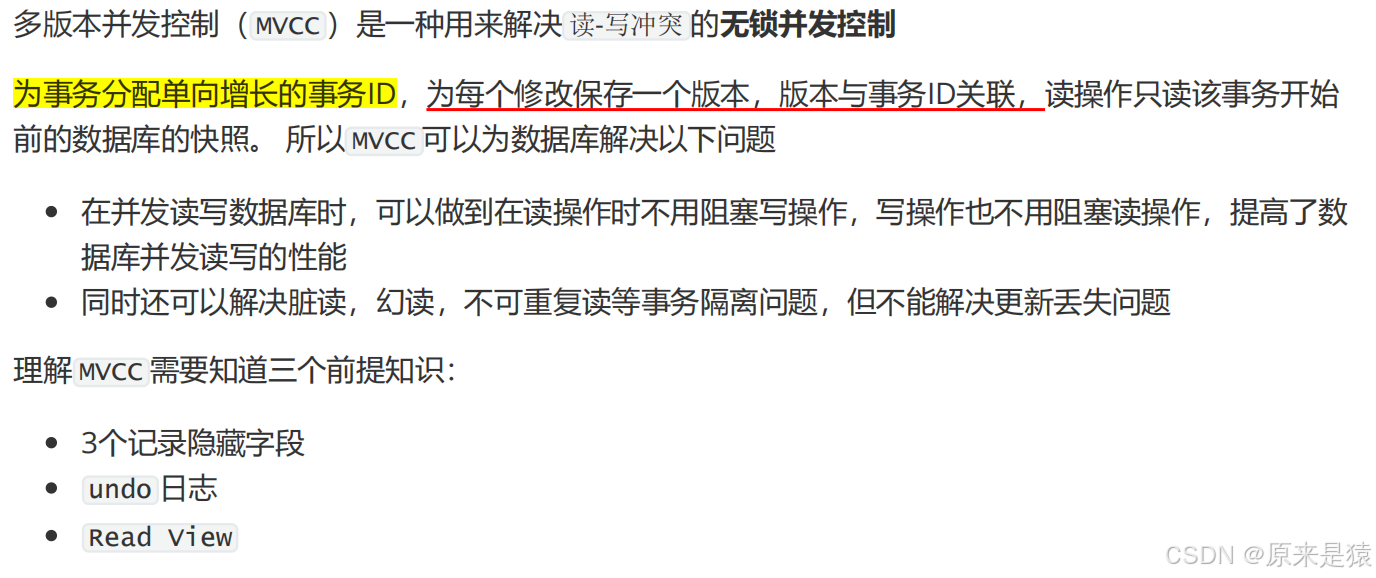

3.1 3个记录隐藏列字段
1. DB_TRX_ID(事务 ID)
- 大小:6 字节
- 作用 :记录最后一次创建 / 修改这条记录的事务 ID
- 通俗理解 :**每条数据都有一个 "最后操作人" 标记,这个 "操作人" 就是事务 ID。**比如你用事务 A 修改了这条数据,那这条数据的
DB_TRX_ID就会被更新为事务 A 的 ID。 - 核心用途:配合 MVCC,判断当前事务能否看见这条数据版本。
2. DB_ROLL_PTR(回滚指针)
- 大小:7 字节
- 作用 :指向这条记录的上一个历史版本,历史版本数据存在
undo log(回滚日志)里 - 通俗理解 :可以把它想象成一条 "时光机" 指针,指向这条数据修改前的样子。比如你把数据从
100改成200,新记录的DB_ROLL_PTR就会指向undo log里保存的100版本,方便回滚或其他事务读取旧版本。 - 核心用途:实现 MVCC 多版本,支持事务回滚和一致性读。
对指针的理解不要理解得太肤浅了 , 数组下标,特定内存空间的地址都可以看成指针
3. DB_ROW_ID(隐藏主键)
- 大小:6 字节
- 作用 :当数据表没有显式定义主键时,InnoDB 会自动生成这个自增 ID 作为聚簇索引
- 通俗理解 :如果你没给表设主键,InnoDB 会 "偷偷" 给每条数据加一个自增序号,用它来组织聚簇索引**(因为 InnoDB 必须有聚簇索引)**。如果你已经设了主键,这个字段就不会生成,直接用主键当聚簇索引。
- 核心用途:保证聚簇索引存在,优化数据存储和查询。
4. 补充:删除 flag(删除标记)
数据页是内存级别的
- 作用:记录是否被逻辑删除,更新 / 删除操作不会立刻物理删除数据,只是修改这个标记
- 通俗理解 :InnoDB 的删除是 "软删除",比如你执行
DELETE,它不会立刻把数据从磁盘抹掉,只是把删除 flag 设为 "已删除",之后在后台慢慢清理。这样做是为了配合 MVCC,让其他事务还能读到旧版本,同时保证事务安全。 - 核心用途:实现 MVCC 的一致性读,避免物理删除导致历史版本丢失。
假设测试表结构是:

3.2 undo日志
- MySQL 将来是以服务进程的方式,在内存中运行。我们之前所讲的所有机制:索引,事务,隔离性,日志等,都是在内存中完成的,即在 MySQL 内部的相关缓冲区 中,保存相关数据,完成各种判断操作。然后在合适的时候,将相关数据刷新到磁盘当中的。
- 所以,我们这里理解undo log,简单理解成,就是****MySQL 中的一段内存缓冲区,用来保存日志数据的就行。 一般事务提交之后 , 这个缓冲区会被释放 (提交后的事务,rollback 没有用了)。
MySQL 的运行方式:内存优先
- MySQL 是一个服务进程,运行在内存里。
- 索引、事务、隔离性、日志(包括 undo log)这些核心机制,都先在内存缓冲区里完成:
- 读写数据、判断事务可见性、记录回滚信息...... 都在内存中高效执行。
- 不会每次操作都直接写磁盘,因为磁盘 I/O 太慢,会严重拖慢性能。
- 等时机合适(比如事务提交、内存满了、后台定时任务),再把内存里的数据批量刷新到磁盘持久化。
undo log 的简单理解
- 你可以把
undo log直接理解为:MySQL 内存里的一段专用缓冲区。 - 它的作用是:保存数据修改前的旧版本,用来:
- 事务失败时回滚(把数据恢复到修改前的样子)。
- 实现 MVCC(多版本并发控制),让其他事务能读到历史版本的数据,保证隔离性和一致性读。
- 本质上,
undo log就是 MySQL 在内存里为了 "反悔" 和 "读旧数据" 而准备的一份 "备份日志"。
3.3 模拟MVCC
现在有一个事务10(仅仅为了好区分),对student表中记录进行修改(update):将name(张三)改成name(李四)。
- 事务10 , 因为要修改 , 先要对记录加锁
- 修改前 , 先将需要改的 行记录 拷贝到 undo log 中 , 所以 , undo log 中就有了一行副本数据**(原理就是 : 写时拷贝)**
- 所以现在Mysql 中有两行同样的记录 。 现在 修改原始记录中 的 name , 改成 '李四' 。并且修改原始记录的隐藏字段 DB_TRX_ID 为当前事务 10 的ID, 默认从10开始 , 之后递增 。而原纪录的回滚指针 DB_ROLL_PTR列 , 里面写入 undo log 中副本数据 的地址, 从而指向副本记录 , 即表示我的上一个版本就是它 。
- 事务10 提交 , 释放锁 。

现在又有一个事务11,对student表中记录进行修改(update):将age(28)改成age(38)。
这个时候我们修改的数据是当前的数据!!! 历史的 , 在undo log 里面的数据 不可改 ,因为它是稳定的 , 历史的 , 陈旧的
- 事务 11 , 因为也要修改 , 所以要先给该记录加行锁
- 修改前,现将改行记录拷贝到****undo log中,所以,undo log **中就又有了一行副本数据。**此时,新的 副本,我们采用头插方式,插入undo log
- 先修改原始记录中的age,改成 38。并且修改原始记录的隐藏字段****DB_TRX_ID 为当前 事务11 的ID 。而原始记录的回滚指针DB_ROLL_PTR 列,里面写入undo log 中副本数据的地址,从而指向副 本记录,既表示我的上一个版本就是它。
- 事务11提交,释放锁。

这样,我们就有了一个基于链表记录的 历史版本链 。所谓的回滚,无非就是用历史数据,覆盖当前数据。
上面的一个一个版本,我们可以称之为一个一个的快照。
3.3.1 不同操作对版本链的影响
-
UPDATE/DELETE :都会生成历史版本,形成版本链
- DELETE 不是物理删除,只是打删除标记,同样会进入版本链。
- 这两种操作会生成历史版本 ,通过
DB_ROLL_PTR指针串联成版本链。
-
INSERT :没有历史版本,只在
undo log里留一条记录用于回滚,事务提交后可清理。
虽然没有历史本版 ,但是 一般为了回滚操作,insert的数据也是要被放入undo log **中,**如果当前事务commit了,那么这个undo log 的历史insert记录就可以被清空了。回滚 -> 还会记录这个insert 相对的语句 delete , 就相当于你insert 数据 , 你想回滚 , 就会执行这个对应的delete 语句。
总结一下 : update 个 delete 可以形成版本链 , insert 暂时不考虑 , INSERT 只用于回滚,不参与版本链。
- SELECT:不修改数据,不生成新版本,但会决定读哪个版本。
首先 , select 不会对数据做任何修改 ,所以 , 为select 维护版本 , 并没有意义 。
SELECT 不修改数据,所以不会产生新版本,但它需要决定读最新版 还是历史版:
① 当前读(Current Read):读取最新的记录 , 增删改 , 都叫当前读。
- 定义:读取最新提交的版本,会加锁(共享锁 / 排他锁)。
- 场景:
- 增删改操作本身就是当前读
- select 也有可能当前读 ----> 带锁的查询**:
SELECT ... LOCK IN SHARE MODE(共享锁)、SELECT ... FOR UPDATE**- 特点:保证读到最新数据,但会阻塞其他写操作,性能较低。
② 快照读(Snapshot Read):读历史版本
- 定义:读取历史版本 ,不加锁 ,可以和写操作并行执行。
- 场景:普通
SELECT语句(在READ COMMITTED/REPEATABLE READ隔离级别下)。- 意义:这就是 MVCC 的核心价值------ 不加锁实现并发读写,大幅提升数据库性能。
- 之前读写并发的原因 , 写是当前读数据 , 读是历史数据 , 所以不会出现访问同一个位置的情况 , 就不需要加锁,不会相互夯住 ,不会影响 , 就可以并发进行操作 。
- 事务A把数据修改之后 , 事务B读取的数据依旧是老数据 , 是因为有隔离性的存在 ,隔离性本质是在版本上做隔离
- ,在多个事务同时删改查的时候,都是当前读,是要加锁的。那同时有select过来,如果也要**读 取最新版(**当前读),那么也就需要加锁,这就是串行化。
3.3.2 总结:
UPDATE/DELETE生成版本链,INSERT只用于回滚。SELECT分当前读(加锁读最新)和快照读(无锁读历史)。- MVCC 通过快照读实现无锁并发 ,而隔离级别决定了读哪个版本。
为什么快照读能提升效率?
- 如果所有读都用当前读:读写会互相加锁,变成串行执行,性能差。
- 如果用快照读:读操作去读历史版本,完全不受写操作加锁的影响,读写可以并行,效率更高。
谁决定了 SELECT 是当前读还是快照读?
隔离级别决定了 SELECT 的读取模式:
- 不同隔离级别会控制:事务能看到哪些历史版本、什么时候生成快照(Read View)。
- 比如 MySQL 默认的
REPEATABLE READ隔离级别:- 事务第一次执行普通
SELECT时生成一个快照(Read View)。 - 之后整个事务期间,所有
SELECT都复用这个快照,保证 "可重复读"。
- 事务第一次执行普通
- 而
READ COMMITTED隔离级别:- 每次
SELECT都会生成新的快照,只能看到其他事务已提交的修改。
- 每次
为什么要有隔离级别呢?
因为事务是原子的 , 无论如何 , 事务都有先后。 但是经过上面的操作我们发现,事务从begin->CURD->commit,是有一个阶段的。也就是事务有执行前,执 行中,执行后的阶段。但,不管怎么启动多个事务,总是有先有后的。那么多个事务在执行中,CURD****操作是会交织在一起的。那么,为了保证事务的"有先有后",是不是应该让不同 的事务看到它该看到的内容,这就是所谓的隔离性与隔离级别要解决的问题。
3.4 Read View
- read View , 是一个对象 , 值初始化之后 , 不变
- read View 事务是可见性的一个类 , 不是事务创建出来 , 就会有read View , 而是当前这个事务(已经存在) , 首次进行快照读的时候 , mysql 形成Read View!!!

对比规则(简化版):
-
如果
DB_TRX_ID< 最小活跃事务 ID → 这个修改事务已经提交了,可见。 -
如果
DB_TRX_ID> 最大事务 ID → 这个修改是在当前事务之后才开始的,不可见。 -
如果
DB_TRX_ID在活跃事务列表里 → 这个事务还没提交,不可见 ;不在列表里 → 已经提交,可见。class ReadView {
// 省略...
private:
/** 高水位,大于等于这个ID的事务均不可见*/
trx_id_t m_low_limit_id
我们在实际读取数据版本链的时候,是能读取到每一个版本对应的事务ID的,即:当前记录的
DB_TRX_ID 。
那么,我们现在手里面有的东西就有,当前快照读的 ReadView 和 版本链中的某一个记录的
DB_TRX_ID 。
所以现在的问题就是,当前快照读,应不应该读到当前版本记录。一张图,解决所有问题!
/** 低水位:小于这个ID的事务均可见 /
trx_id_t m_up_limit_id;
/* 创建该 Read View 的事务ID*/
trx_id_t m_creator_trx_id;
/** 创建视图时的活跃事务id列表*/
ids_t m_ids;
/** 配合purge,标识该视图不需要小于m_low_limit_no的UNDO LOG,- 如果其他视图也不需要,则可以删除小于m_low_limit_no的UNDO LOG*/
trx_id_t m_low_limit_no;
/** 标记视图是否被关闭*/
bool m_closed;
// 省略...
};
m_ids; //一张列表,用来维护Read View生成时刻,系统正活跃的事务ID
up_limit_id; //记录m_ids列表中事务ID最小的ID(没有写错)
low_limit_id; //ReadView生成时刻系统尚未分配的下一个事务ID,也就是目前已出现过的事务ID的
最大值+1(也没有写错)
creator_trx_id //创建该ReadView的事务ID - 如果其他视图也不需要,则可以删除小于m_low_limit_no的UNDO LOG*/
- 我们在实际读取数据版本链的时候,是能读取到每一个版本对应的事务ID的,即:当前记录的 DB_TRX_ID 。
- 那么,我们现在手里面有的东西就有,当前快照读的 ReadView 和 版本链中的某一个记录的 DB_TRX_ID 。
- 所以现在的问题就是,当前快照读,应不应该读到当前版本记录。
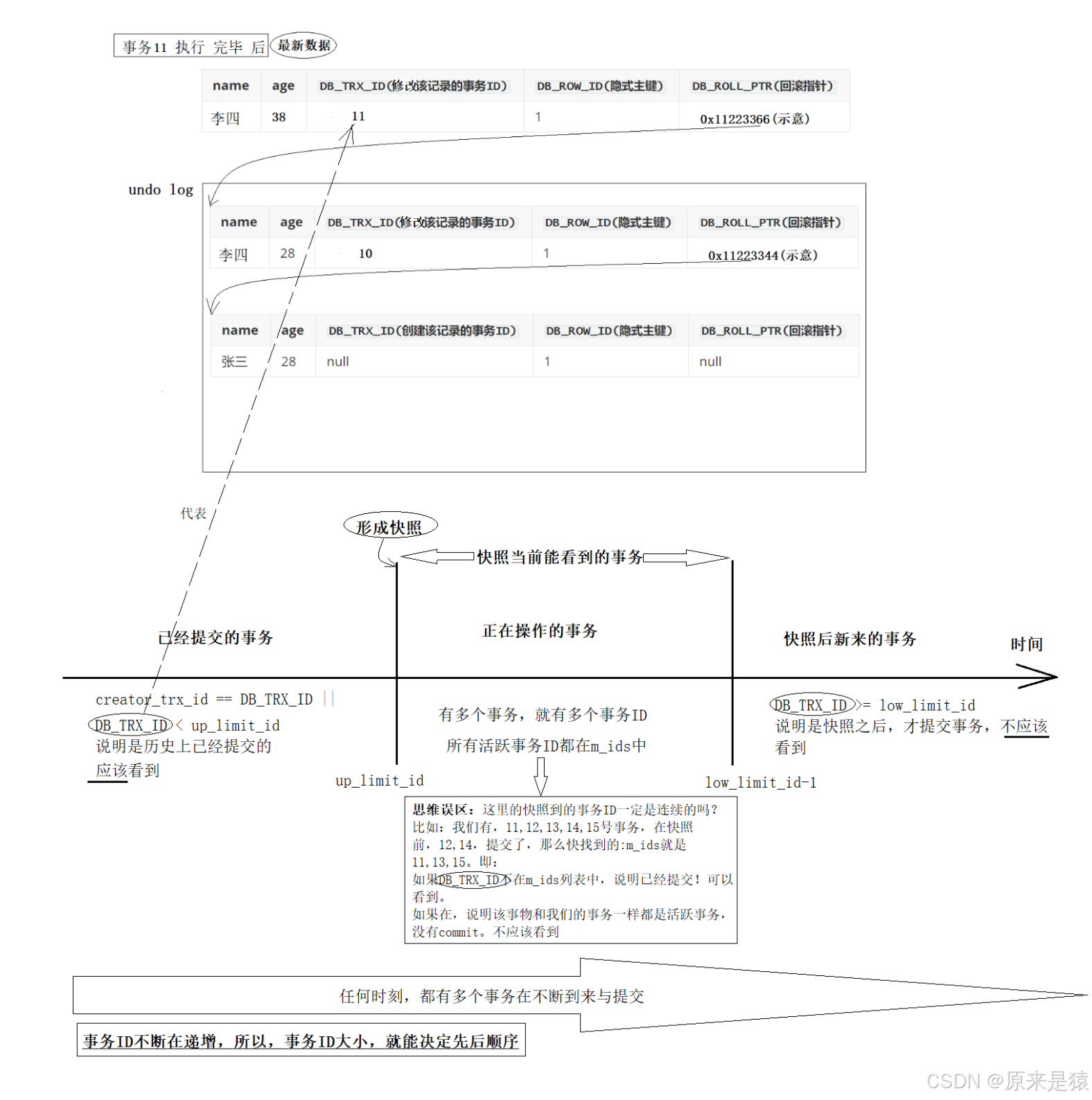
Read View 是事务在快照读那一刻对系统事务状态拍的 "照片",把时间线分成三段:
- 已经提交的事务 :
DB_TRX_ID < up_limit_id(这些事务的修改对当前事务可见)- 正在操作的事务(活跃事务) :所有未提交的事务 ID 都存在
m_ids列表里(这些事务的修改对当前事务不可见)- 快照后新来的事务 :
DB_TRX_ID >= low_limit_id(这些事务是快照之后才开始的,修改对当前事务不可见)关键定义:
up_limit_id:当前系统中最小的活跃事务 IDlow_limit_id:当前系统中最大的事务 ID + 1(代表快照之后新事务的起点)m_ids:当前所有活跃(未提交)事务 ID 的集合
对应策略:

如果查到不应该看到当前版本,接下来就是遍历下一个版本,直到符合条件,即可以看到。上面的
readview 是当你进行select的时候,会自动形成。
3.5 整体流程

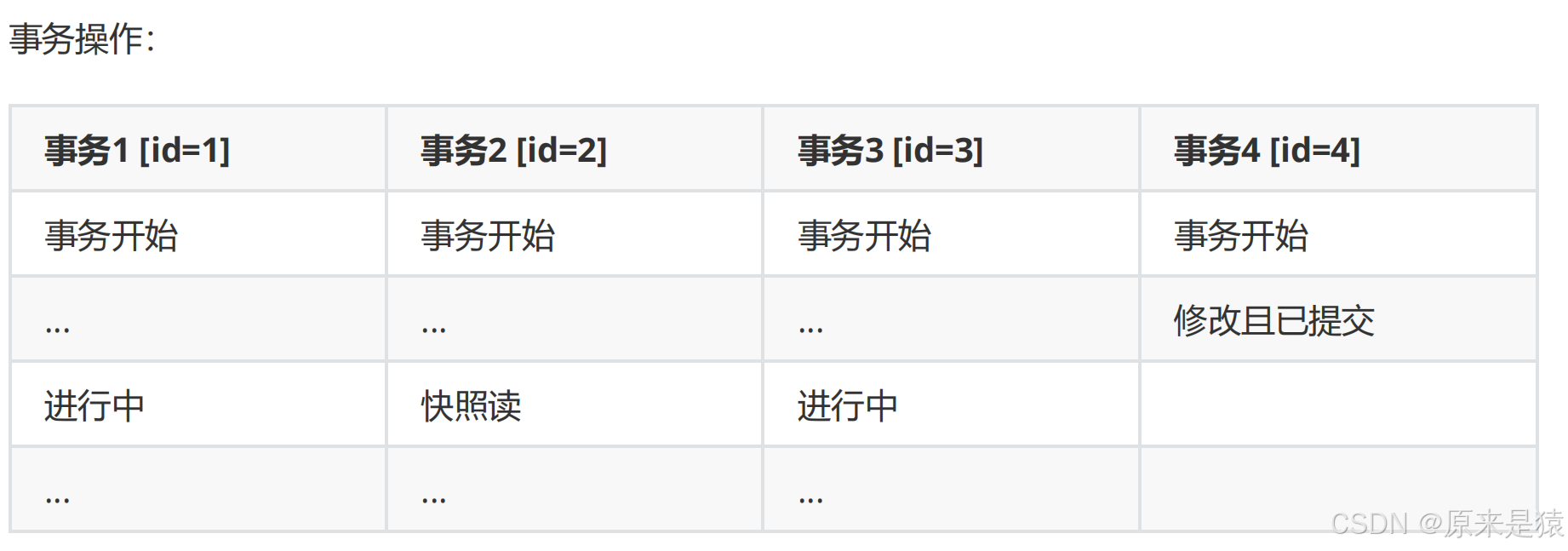
- 事务4:修改name(张三) 变成name(李四)
- 当 事务2 对某行数据执行了****快照读 ,数据库为该行数据生成一个 Read View 读视图


- 只有事务4修改过该行记录,并在事务2执行快照读前,就提交了事务。

- 我们的事务2在快照读该行记录的时候,就会拿该行记录的 DB_TRX_ID 去up_limit_id,low_limit_id和活跃事务ID列表(trx_list) 进行比较,判断当前事务2能看到该记
录的版本。


四、RR与RC的本质区别
4.1 当前读和快照读在RR级别下的区别
下面的代码经过测试,是完全没有问题的。
select * from user lock in share mode ,以加共享锁方式进行读取,对应的就是当前读。
测试表:
--设置RR模式下测试
mysql> set global transaction isolation level REPEATABLE READ;
Query OK, 0 rows affected (0.00 sec)
--重启终端
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
--依旧用之前的表
create table if not exists user(
id int primary key,
age int not null,
name varchar(50) not null default ''
)ENGINE=InnoDB DEFAULT CHARSET=UTF8;
--插入一条记录,用来测试
mysql> insert into user (id, age, name) values (1, 15,'黄蓉');
Query OK, 1 row affected (0.00 sec)
测试用例1-表1:
测试用例2-表2:
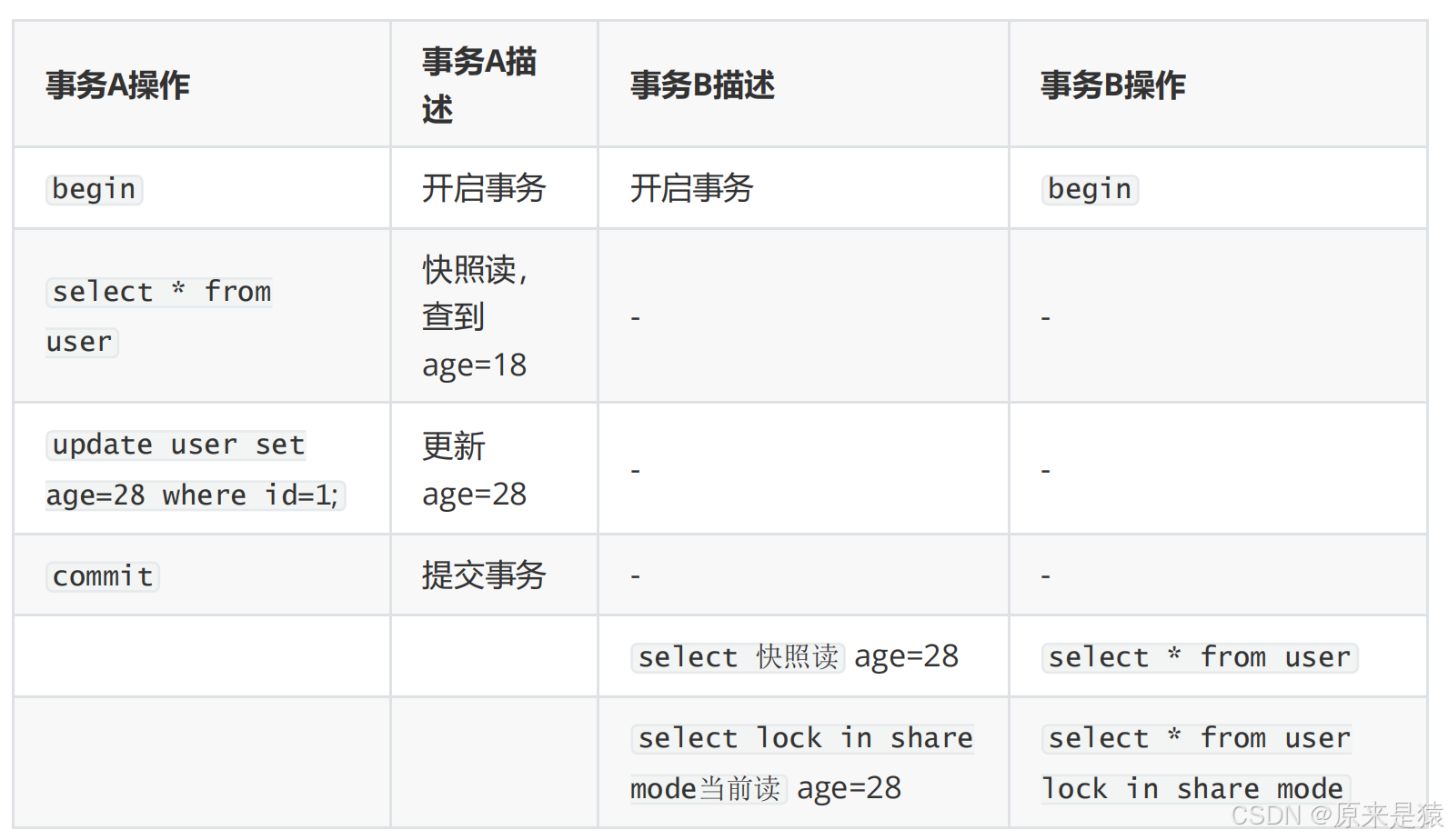
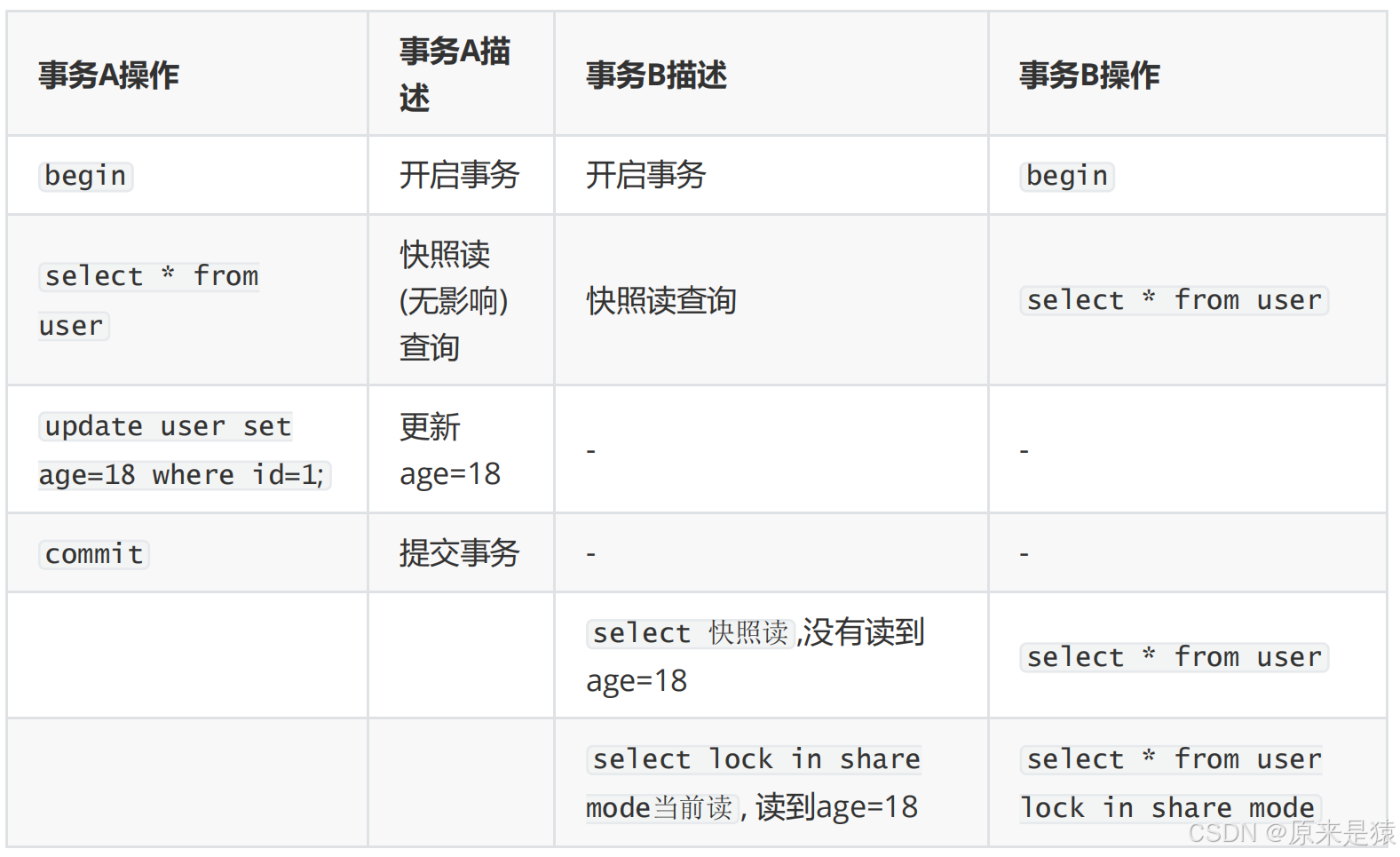
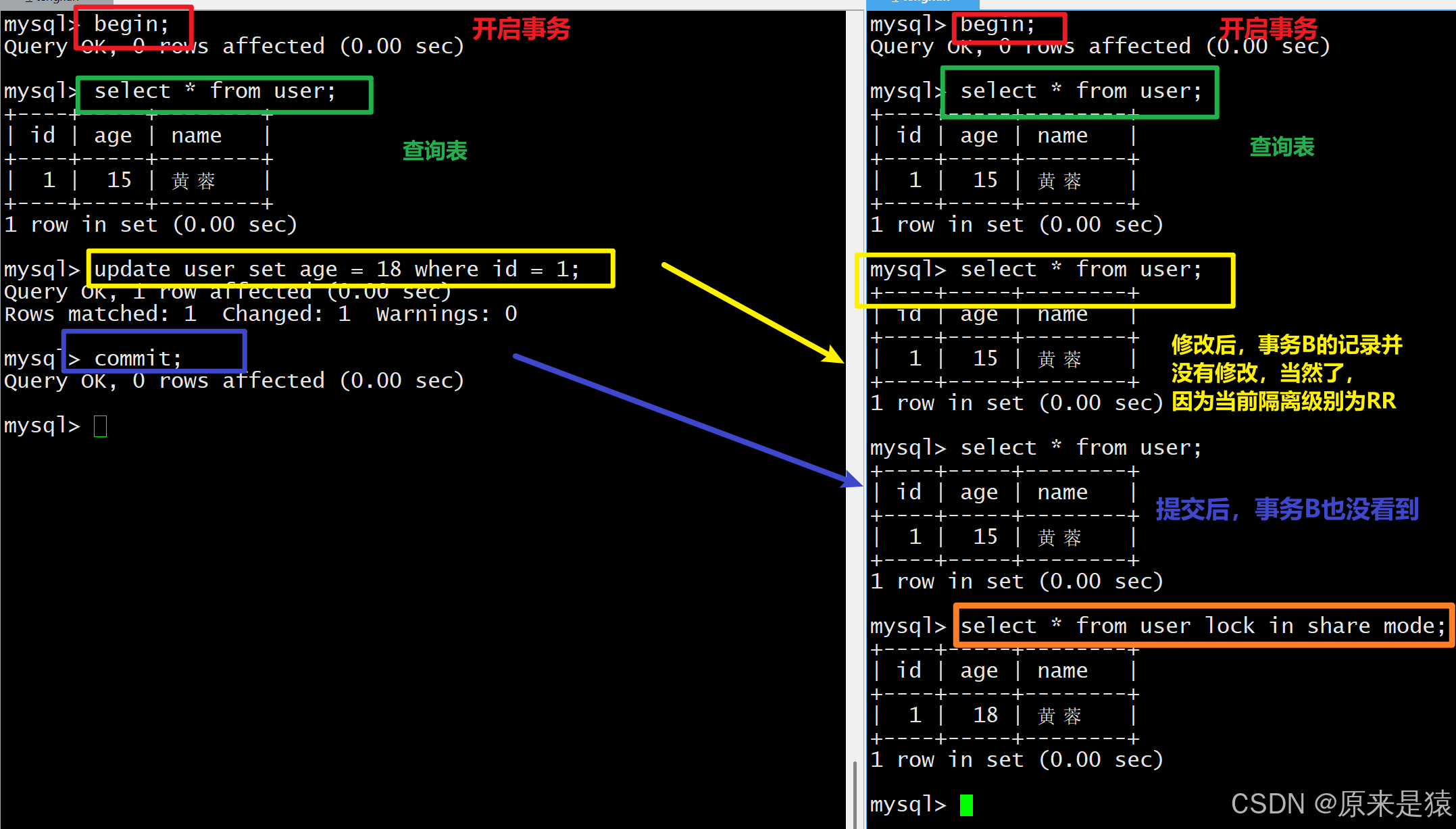
- 用例1与用例2:唯一区别仅仅是 表1 的事务B在事务A修改age前 快照读 过一次age数据
- 而 表2 的事务B在事务A修改age前没有进行过快照读。
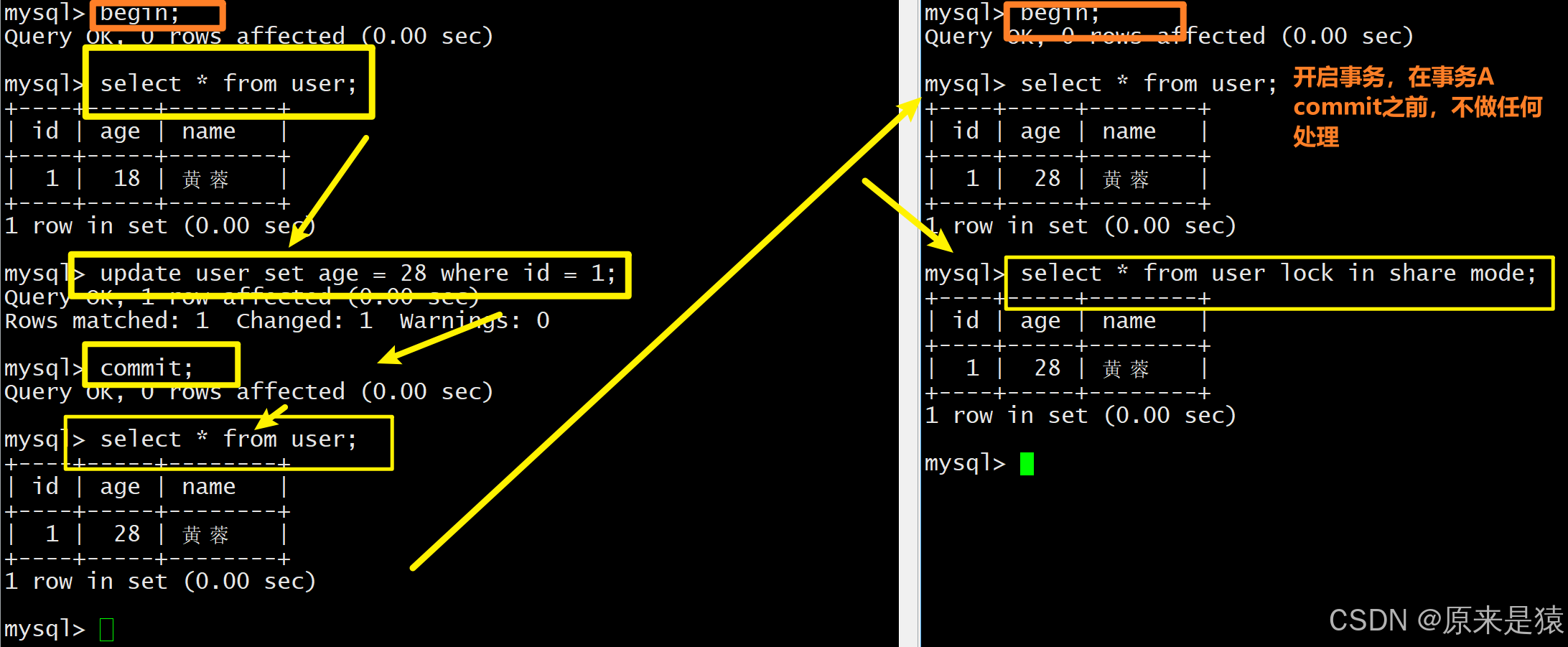
我们看事务 B 的行为:
- 事务 B 先开启 ,但还没执行任何
SELECT。 - 事务 A 执行了更新并提交 :把
age从 18 改成 28。 - 事务 B 第一次执行快照读(
select * from user) :- 此时才生成 Read View,这个 Read View 已经能看到事务 A 提交的修改,所以读到
age=28。 - 之后事务 B 再执行任何快照读,都会复用这个 Read View,结果永远是
age=28。
- 此时才生成 Read View,这个 Read View 已经能看到事务 A 提交的修改,所以读到
- 如果事务 B 在事务 A 更新前就执行了第一次快照读 :
- 生成的 Read View 里看不到事务 A 的修改,之后就算事务 A 提交了,事务 B 后续快照读依然会读到
age=18,这就是 "可重复读" 的效果。
- 生成的 Read View 里看不到事务 A 的修改,之后就算事务 A 提交了,事务 B 后续快照读依然会读到
!!! read view 形成的时机不同 , 会影响事务的可见性!!!
1. 为什么 "首次快照读" 这么关键?
在
REPEATABLE READ隔离级别下:
- 事务第一次执行普通
SELECT(快照读)时,会生成一个 Read View(读视图),也就是对当前系统事务状态拍了一张 "快照"。- 这个 Read View 会被整个事务复用,直到事务提交。
- 后续所有快照读,都会基于这张 "快照" 去判断可见性,不会再感知到其他事务新提交的修改。
4.2 RR与RC的本质区别
RR:一次生成,全程复用
RC:每次快照读,都重新生成
- 正是Read View生成时机的不同,从而造成RC,RR级别下快照读的结果的不同
- 在RR级别下的某个事务的对某条记录的第一次快照读会创建一个快照及Read View , 将当前系统活跃的其他事务记录起来此后在调用快照读的时候,还是使用的是同一个****Read View **,**所以只要当前事务在其他事务提交更新之前使用过快照读,那么之后的快照读使用的都是同一个Read View,所以对之后的修改不可见;
- **即RR级别下,**快照读生成Read View时,Read View会记录此时所有其他活动事务的快照,这些事 务的修改对于当前事务都是不可见的。而早于Read View创建的事务所做的修改均是可见
- 而在RC级别下的 ,事务中,每次快照读都会新生成一个快照和Read View, 这就是我们在RC级别下的事务中可以看到别的事务提交的更新的原因
- 总之在RC隔离级别下,是每个快照读都会生成并获取最新的Read View;而在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View。
- 正是RC每次快照读,都会形成Read View,所以,RC才会有不可重复读问题。
五、读-读
不讨论
六、写-写
现阶段,直接理解成都是当前读,当前不做深究