导读
实时语音识别(ASR)正在从云端走向终端。会议转录、直播字幕、语音助手等场景对延迟的要求越来越苛刻------用户期望话音未落,文字已经出现在屏幕上。然而,现有的高精度 ASR 模型大多是离线架构,需要等待一段完整语音输入后才能处理,无法满足实时交互的需求。而已有的流式方案往往在精度上做出较大让步。
Mistral AI 发布的 Voxtral Mini 4B Realtime试图在这两者之间找到平衡:一个原生流式设计的 4.4B 参数 ASR 模型,在 480ms 延迟下实现了接近离线模型的转录精度,覆盖 13 种语言,权重以 Apache 2.0 协议开源。更值得关注的是,社区项目 voxtral-mini-realtime-rs 已将其 Q4 量化至 2.5GB,通过 WebGPU 在浏览器标签页中完成端侧实时转录。本文将从实时流式 ASR 的需求出发,拆解 Voxtral Realtime 的架构设计、性能表现、部署方案,并讨论其在端侧 ASR 领域的定位。
项目信息
- 模型: Voxtral Mini 4B Realtime
- 团队: Mistral AI
- 时间: 2026 年 2 月 4 日
- 论文链接: arxiv.org/abs/2602.11...
- 模型权重: huggingface.co/mistralai/V...
- 协议: Apache 2.0
一、为什么需要原生流式 ASR?
传统高精度 ASR 模型(如 Whisper)采用双向注意力机制(bidirectional attention),编码器需要"看到"整段音频后才能生成特征表示。这意味着模型必须等待一个完整的音频片段(Whisper 固定为 30 秒)输入完毕后才开始处理。对于离线转录(录音文件、播客后期处理)这没有问题,但对于实时场景------会议同声字幕、语音助手、直播弹幕------这种等待是不可接受的。
一种常见的折中方案是分块处理(chunking):把音频切成短片段,逐段送入离线模型。但这种做法引入了两个问题:一是片段边界处容易产生识别错误(因为模型看不到跨片段的上下文);二是每个片段仍需等待一定长度的音频积累,延迟依然受限于块大小。
Voxtral Realtime 走了另一条路:从训练阶段就按流式设计。它的编码器使用因果注意力(causal attention),只关注当前和过去的音频帧,不依赖未来信息;文本解码与音频输入之间有明确的时间对齐关系------每个文本 token 对应 80ms 的音频。这种"原生流式"设计避免了分块方案的边界割裂问题,同时支持配置不同的延迟(从 80ms 到 2400ms),在精度和延迟之间灵活取舍。
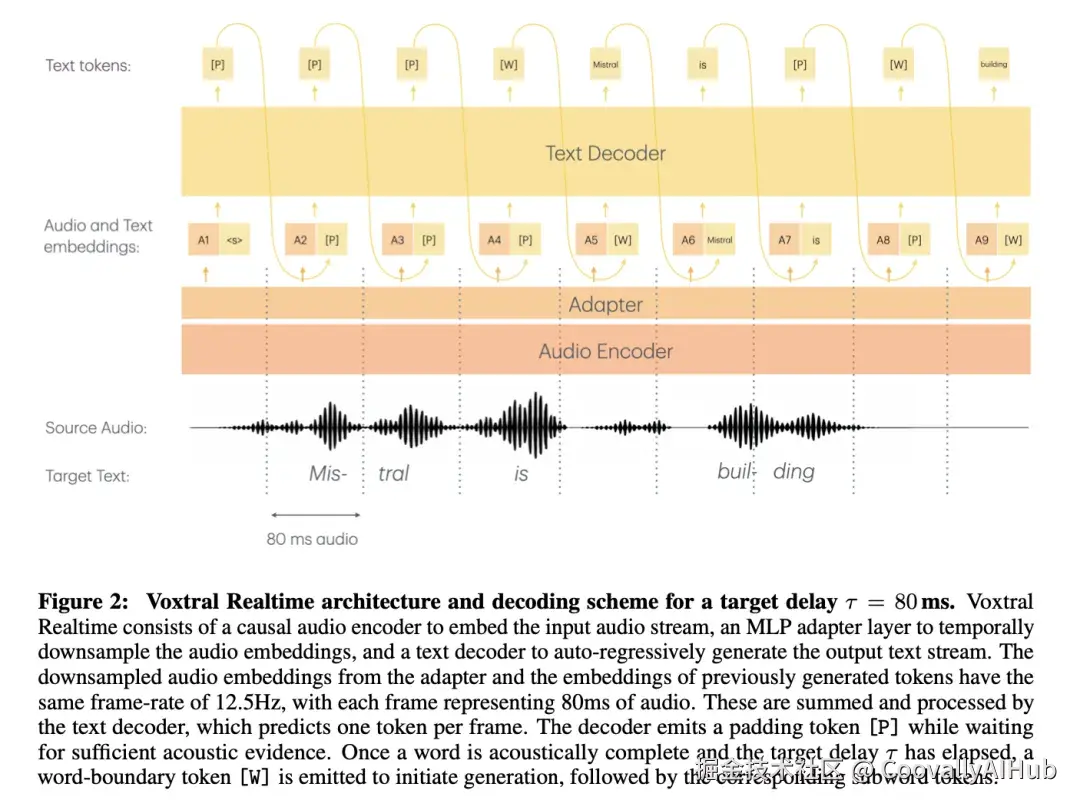
二、架构设计:因果编码器 + 延迟流建模
Voxtral Realtime 由三个核心组件构成:
图片来源于原论文
因果音频编码器(Causal Audio Encoder)
- 规模 :32 层,1280 维,约 970M 参数
- 输入处理 :将原始波形转为 128 bin 的 log-Mel 频谱图(hop size 160),经过 2 倍时间降采样后,每 20ms 输出一个嵌入向量(50Hz 帧率)
- 关键设计 :使用因果自注意力 ,每一帧只关注当前及过去的输入,配合 750 帧滑窗注意力(约 15 秒窗口),支持理论上无限长的流式输入
- 与 Whisper 编码器的核心差异:Whisper 用双向注意力 + LayerNorm + GELU;Voxtral 用因果注意力 + RMSNorm + SwiGLU
适配层(Adapter)
- 单层 MLP,将编码器输出做 4 倍时间压缩 ,最终帧率降至 12.5Hz(每帧 80ms)
- 约 25M 参数
语言解码器(Language Decoder)
- 规模 :26 层,3072 维,约 3.4B 参数,使用分组查询注意力(8 个 KV 头)
- 初始化自 Ministral 3B基座模型
- 采用 8192 token 滑窗注意力,同样支持长时流式推理
延迟流建模(Delayed Streams Modeling)
模型的核心创新在于流同步设计 :在每个解码步骤中,解码器接收的输入是当前时刻音频嵌入与最近生成的文本 token 嵌入的逐元素求和。音频流和文本流之间保持固定的时间偏移(即"延迟"),模型在训练时从 80ms 到 2400ms 均匀采样不同延迟值。
为了让单一模型 适配不同延迟,Voxtral 提出了 Ada RMS-Norm:通过正弦嵌入将延迟值编码为 32 维向量,经 MLP 投影后以加法形式注入前馈层的归一化空间。这样只增加约 5M 参数,就实现了在不同延迟设置下灵活切换,无需为每个延迟单独训练模型。
总参数量 :约 4.4B(970M + 25M + 3.4B + 5M)。
训练策略
训练分两个阶段:
- 编码器预热(前 5% 训练步):冻结解码器,仅训练编码器和适配层,学习率 4×10⁻⁴,让编码器先学习音频表示
- 端到端联合训练(后 95%):全部参数一起优化,学习率 6×10⁻⁵
训练使用 z-loss 惩罚项防止 logit 幅度发散,保持 softmax 归一化器接近零。
三、性能数据:480ms 延迟下逼近离线模型
多语言基准 FLEURS(WER%)
以下为 Voxtral Realtime 在 480ms 延迟下与其他模型的对比(数据来自论文 Table 7):
| 语言 | Whisper(离线) | GPT-4o mini Transcribe(实时 API) | Voxtral Mini V2(离线) | Voxtral Realtime(480ms) |
|---|---|---|---|---|
| 英语 (en) | 4.00 | 3.65 | 3.32 | 4.90 |
| 西班牙语 (es) | 2.81 | 3.41 | 2.63 | 3.31 |
| 法语 (fr) | 5.55 | 5.84 | 4.32 | 6.42 |
| 德语 (de) | 5.46 | 4.07 | 3.54 | 6.19 |
| 意大利语 (it) | 2.71 | 2.82 | 2.17 | 3.27 |
| 葡萄牙语 (pt) | 3.90 | 5.04 | 3.56 | 5.03 |
| 荷兰语 (nl) | 5.87 | 6.00 | 4.78 | 7.07 |
| 俄语 (ru) | 5.13 | 5.30 | 4.75 | 6.02 |
| 阿拉伯语 (ar) | 15.44 | 13.99 | 13.54 | 22.53 |
| 印地语 (hi) | 28.87 | 8.39 | 10.33 | 12.88 |
| 日语 (ja) | 4.97 | 9.89 | 4.14 | 9.59 |
| 韩语 (ko) | 14.30 | 19.46 | 12.29 | 15.74 |
| 中文 (zh) | 7.94 | 15.43 | 7.30 | 10.45 |
| 宏平均 | 8.23 | 7.95 | 5.90 | 8.72 |
在 480ms 延迟下,Voxtral Realtime 的 13 语言宏平均 WER 为 8.72%,与离线 Whisper(8.23%)差距不到 0.5 个百分点。当延迟放宽至 960ms 时,WER 降至 7.70%,已经优于 Whisper。
英语短音频基准(WER%)
以下为 10 个英语短音频数据集的宏平均对比(数据来自论文 Table 5):
| 模型 | 延迟 | 宏平均 WER |
|---|---|---|
| Whisper(离线) | --- | 8.39 |
| GPT-4o mini Transcribe(实时 API) | --- | 7.93 |
| Voxtral Mini Transcribe V2(离线) | --- | 7.27 |
| Scribe v2 Realtime(实时 API) | --- | 7.33 |
| Nemotron Streaming | 560ms | 9.59 |
| Nemotron Streaming | 1120ms | 9.41 |
| Voxtral Realtime | 480ms | 8.47 |
| Voxtral Realtime | 960ms | 7.94 |
| Voxtral Realtime | 2400ms | 7.72 |
Voxtral Realtime 在 480ms 延迟下英语短音频 WER 为 8.47%,与离线 Whisper(8.39%)几乎持平。论文中 GPT-4o mini Transcribe 和 Scribe v2 Realtime 均被归类为"实时 API"模型(非离线),同类流式模型 Nemotron Streaming 在 560ms 延迟下 WER 为 9.59%,差距明显。
英语长音频基准(WER%)
长音频场景下 Voxtral Realtime 表现更好(数据来自论文 Table 6):
| 模型 | 延迟 | 宏平均 WER |
|---|---|---|
| Whisper(离线) | --- | 7.97 |
| GPT-4o mini Transcribe(实时 API) | --- | 7.97 |
| Voxtral Mini Transcribe V2(离线) | --- | 7.11 |
| Scribe v2 Realtime(实时 API) | --- | 7.43 |
| Voxtral Realtime | 480ms | 7.73 |
| Voxtral Realtime | 960ms | 7.13 |
在 480ms 延迟下,Voxtral Realtime 的长音频 WER 7.73% 已经优于Whisper(离线)和 GPT-4o mini Transcribe(实时 API)的 7.97%。
延迟-精度权衡
模型支持从 80ms 到 2400ms 的延迟配置,用户可根据场景灵活选择:
| 延迟 | 英语短音频 WER | FLEURS 宏平均 WER | 适用场景 |
|---|---|---|---|
| 240ms | 9.95 | 10.80 | 极低延迟语音交互 |
| 480ms | 8.47 | 8.72 | 实时字幕 / 语音助手(推荐) |
| 960ms | 7.94 | 7.70 | 会议转录 |
| 2400ms | 7.72 | 6.73 | 高精度字幕生成 |
注:"适用场景"列为编者建议,非论文原文。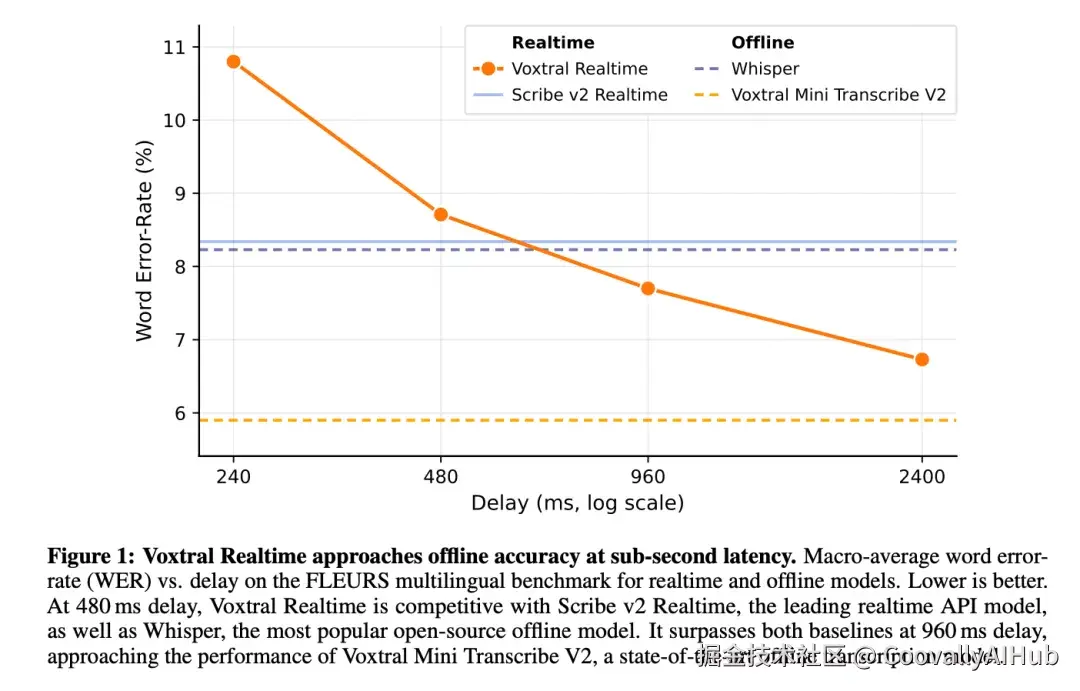 图片来源于原论文
图片来源于原论文
四、部署方案:从 GPU 服务器到浏览器标签页
服务器端部署(vLLM,推荐)
Voxtral Realtime 已集成到 vLLM推理框架,支持生产级流式服务:
makefile
# 安装
uv pip install -U vllm
uv pip install soxr librosa soundfile
uv pip install --upgrade transformers
# 启动服务
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve mistralai/Voxtral-Mini-4B-Realtime-2602 \
--compilation_config '{"cudagraph_mode": "PIECEWISE"}'vLLM 为该模型做了专门优化:定制的 paged-attention 后端处理编码器(50Hz)与解码器(12.5Hz)的异构 KV 缓存;支持可恢复请求(resumable requests),每 80ms 增量音频更新时保留 KV 状态;通过 WebSocket 双向端点实现边接收音频、边输出文本。
GPU 显存要求:BF16 推理需 16GB 以上 VRAM。
Transformers 推理
Transformers v5.2.0+ 已原生支持:
ini
from transformers import VoxtralRealtimeForConditionalGeneration, AutoProcessor
from mistral_common.tokens.tokenizers.audio import Audio
repo_id = "mistralai/Voxtral-Mini-4B-Realtime-2602"
processor = AutoProcessor.from_pretrained(repo_id)
model = VoxtralRealtimeForConditionalGeneration.from_pretrained(
repo_id, device_map="auto"
)
audio = Audio.from_file("audio_file.mp3", strict=False)
audio.resample(processor.feature_extractor.sampling_rate)
inputs = processor(audio.audio_array, return_tensors="pt")
inputs = inputs.to(model.device, dtype=model.dtype)
outputs = model.generate(**inputs)
decoded_outputs = processor.batch_decode(outputs, skip_special_tokens=True)
print(decoded_outputs[0])推荐配置 :temperature 设为 0.0;1 小时音频需设置 --max-model-len >= 45000(计算公式:音频秒数 / 0.08)。
浏览器端部署(WebGPU)
社区开发者基于 Burn ML 框架(Rust)实现了 Voxtral Realtime 的纯 Rust 推理引擎(voxtral-mini-realtime-rs),并通过 WASM + WebGPU 将其部署在浏览器中:
- 模型体积 :Q4_0 量化后约 2.5GB(原始 F32 约 16GB)
- 量化方案:4-bit 量化,block size 32,每 block 18 字节
- 浏览器适配:GGUF 文件切分为 512MB 分片,绕过浏览器 ArrayBuffer 大小限制;使用自定义 WGSL shader 实现融合反量化与矩阵乘法
- 运行要求:支持 WebGPU 的浏览器(Chrome 113+ 或 Edge),足够 RAM 容纳 2.5GB 模型
- 在线 Demo:HuggingFace Spaces 上可直接体验(mistralai/Voxtral-Realtime-WebGPU)
其他社区实现
| 实现 | 语言 | 说明 |
|---|---|---|
| voxtral.c | C | Salvatore Sanfilippo(antirez)开发,纯 C 实现,零外部依赖 |
| voxtral-mini-realtime-rs | Rust | 基于 Burn 框架,支持本地 + 浏览器 |
| MLX (voxmlx / mlx-audio) | Python | Apple MLX 框架适配(社区有两个独立实现) |
| ExecuTorch | --- | 端侧部署方案(官方列出,标注为未测试) |
支持的 13 种语言
英语、中文、西班牙语、法语、德语、阿拉伯语、印地语、日语、韩语、俄语、意大利语、荷兰语、葡萄牙语。
五、总结与思考
Voxtral Realtime 在端侧实时 ASR 领域提供了一个值得关注的选项,其核心特点可以从三个维度理解:
与离线模型的关系:Voxtral Realtime 不是要替代 Whisper 或 GPT-4o Transcribe 等离线模型,而是填补"需要实时输出"的场景空白。在 480ms 延迟下,它的精度与离线 Whisper 的差距控制在 1% WER 以内(长音频场景甚至更优),这是此前流式模型难以达到的水平。
与 Moonshine 等轻量端侧模型的定位差异:Moonshine(27M-61M 参数)面向极端资源受限的设备,仅支持英语,模型极小但精度有限。Voxtral Realtime(4.4B 参数)体量大得多,覆盖 13 种语言,适合有一定算力条件的端侧场景(如带独立 GPU 的笔记本、WebGPU 浏览器环境)。两者面向不同的硬件层级。
实际部署考量:
- BF16 全精度推理需要 16GB 以上显存,适合服务器端
- Q4 量化后 2.5GB 可在浏览器中运行,但需要 WebGPU 支持和足够内存,移动端浏览器的 WebGPU 支持仍在普及中,实际运行效果受设备 GPU 性能限制
- 推荐延迟 480ms 是精度与响应速度的平衡点;对精度要求更高的场景可选 960ms 或 2400ms
- Apache 2.0 协议允许商业使用,数据不出本地,适合隐私敏感场景
适用场景:私有会议转录、直播实时字幕、语音助手的前端识别模块、需要多语言支持的跨国协作工具。