原文地址:https://arxiv.org/pdf/2312.03594
代码地址:https://github.com/open-mmlab/PowerPaint
现有的论文要么重点在修复图片(可以理解为背景),要么重点在物体生成(可以理解为前景),然后同时做两种相同的任务是有挑战的。比如在有一堆蛋糕的图片中一个任务是擦除其中某一个蛋糕,另一个任务是根据图片的信息生成一个新的蛋糕。
为了能够同时做上述两种任务,本文基于SD和classifier free guidance提出了Powerpaint算法,可以实现生成、擦除以及根据mask形状生成等功能。下面具体来介绍该方法。
一、基础知识简介
由于本文算法是在Stable Diffusion的基础上提出,所以先简单介绍一下Stable Diffusion。Stable Diffusion由前向(forward)和逆向(reverse)两个阶段构成。
前向流程为加噪流程,公式如下
xt=αtˉx0+(1−αˉt)ϵ,ϵ∼N(0,I)x_t = \sqrt{\bar{\alpha_t}}x_0 + \sqrt(1-\bar\alpha_t)\epsilon, \epsilon \sim \mathcal{N}(0, I)xt=αtˉ x0+( 1−αˉt)ϵ,ϵ∼N(0,I)
其中xtx_txt是生成的噪声图片,t为时间步数,αˉt\bar\alpha_tαˉt控制信噪比的参数。
逆向流程就是去噪,通过神经网络预测的噪声来一步一步还原图片。
一个经典的diffusion model优化目标如下:
L=Ex0,t,ϵt∣∣ϵt−ϵθ(xt,t)∣∣22\mathcal{L}=E_{x_0, t, \epsilon_t}||\epsilon_t - \epsilon_\theta(x_t, t)||_2^2L=Ex0,t,ϵt∣∣ϵt−ϵθ(xt,t)∣∣22
ϵ为噪声,θ为神经网络参数\epsilon为噪声,\theta为神经网络参数ϵ为噪声,θ为神经网络参数
Powerpaint在原始SD网络基础上新增了5个通道的输入,即9通道。所以第一层网络的通道数为从5变成9。新增了5个通道用了做什么,4个通道是masked image经过vae的输出,1个通道是下采样的mask。所以PowerPaint的输入为原图经过vae encoder后再加噪得到的latens(4通道),masked image经过vae后的latents(4通道),以及下采样的mask(1通道)的concate结果,下面记为xt′x'_txt′。所以PowerPaint的优化目标为:
L=Ex0,t,y,ϵt∣∣ϵt−ϵθ(xt′,τθ(y),t)∣∣22\mathcal{L}=E_{x_0, t,y,\epsilon_t}||\epsilon_t - \epsilon_\theta(x't,\tau\theta(y), t)||_2^2L=Ex0,t,y,ϵt∣∣ϵt−ϵθ(xt′,τθ(y),t)∣∣22
τθ(⋅)\tau_\theta(\cdot)τθ(⋅)为clip text encoder,y为text
二、可学习的prompt训练
文章通过定义三类可学习的prompt,用于完成前面提到的可以填补背景、可以生成物体、可以按照形状生成物体的任务,这三个可学习的prompt分别用符号Pctxt、Pobj、PshapeP_{ctxt}、P_{obj}、P_{shape}Pctxt、Pobj、Pshape表示。下面分别介绍。
2.1 Context-aware Image Inpainting
图像修复任务就是根据提供的图片信息自动填充缺失的像素。之前的算法为了达到这个目的,通过随机的mask掉图片中的像素来训练图像复原能力(即输入为原图加噪latents、masked image latent、mask)。本文在这个基础上新增一个可学习的prompt PctxtP_{ctxt}Pctxt,训练修复图片任务时,学习该prompt,优化目标为:
pctxt=argminpEx0,m,t,p,ϵt∣∣ϵt−ϵθ(xt′,τθ(p),t)∣∣22p_{ctxt}=argmin_{p}E_{x_0, m, t,p,\epsilon_t}||\epsilon_t - \epsilon_\theta(x't,\tau\theta(p), t)||_2^2pctxt=argminpEx0,m,t,p,ϵt∣∣ϵt−ϵθ(xt′,τθ(p),t)∣∣22
2.2 Text-guided Object Inpainting
在生成物体这个任务上,同2.1也是新增一个可学习的prompt,称为 PobjP_{obj}Pobj,而且优化目标也同2.1 。不一样的有两点,第一 一般在图像中生成物体会有prompt提示要生成的物体,新增可学习的prompt PobjP_{obj}Pobj作为原始prompt的后缀。第二图片的mask是根据目标检测获取的物体框作为mask。
2.3 Controllable Shape Guided Object Inpainting
根据mask的形状和提示来生成物体。同前面方式一样,文章引入一个可学习的prompt PshapeP_{shape}Pshape。文章尝试如果mask用的是图片物体分割mask容易造成过拟合,使得生成的物体能够和提供的mask匹配,比如不会因为提供一个长方形mask和猫,生成的物体是一个巨大的猫脸和图片内容不匹配。为了得到想要的效果,文章提供的mask为分割结果随机的膨胀后的结果。
与之前不同的是,这里要根据mask来补充里面的物体,为了使得填充的物体合适,训练时引入α\alphaα参数,α\alphaα计算方式为原始物体mask占膨胀后mask的面积比例。将α\alphaα应用到text里面来控制PctxtP_{ctxt}Pctxt和PshapeP_{shape}Pshape在text信息中的占比,具体如下所示
τθ′=(1−α)⋅τ(y,pctxt)+α⋅τ(y,pshape)\tau'\theta=(1-\alpha)\cdot\tau(y, p{ctxt})+\alpha\cdot\tau(y, p_{shape})τθ′=(1−α)⋅τ(y,pctxt)+α⋅τ(y,pshape)
可以看出PobjP_{obj}Pobj单独训练,PctxtP_{ctxt}Pctxt和PshapeP_{shape}Pshape是可能联合训练的
三、模型使用
具体的使用方式有下图几种,包括
- 根据prompt+PobjP_{obj}Pobj生成物体
- 根据PctxtP_{ctxt}Pctxt填补像素
- 根据classifier free guidance,利用PctxtP_{ctxt}Pctxt、PobjP_{obj}Pobj来去除物体
- 利用PshapeP_{shape}Pshape、PctxtP_{ctxt}Pctxt来生成对应的物体
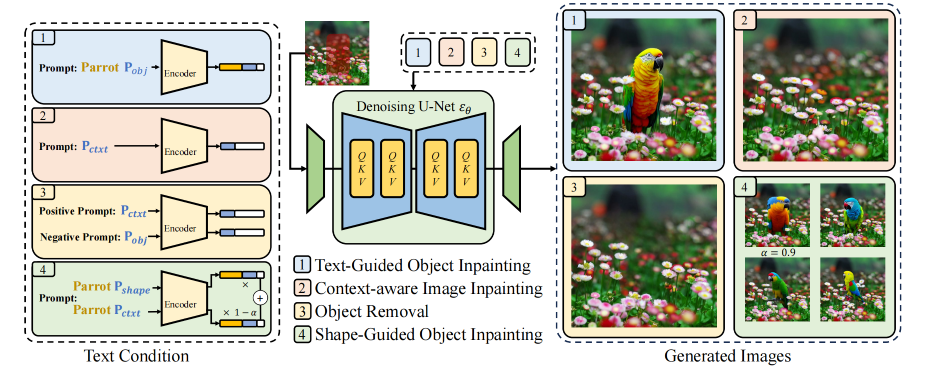
这里重点介绍去除物体。
3.1 Object Removal
采用classifier free guidance的方式,联合利用PctxtP_{ctxt}Pctxt和PobjP_{obj}Pobj来达到去除物体的目的。
classifier free guidance会使得生成的结果更像正样本prompt而更抑制负样本的prompt,所以这里正样本prompt为PctxtP_{ctxt}Pctxt负样本为PobjP_{obj}Pobj。具体去噪的噪声估计形式如下所示:
ϵθ~=ω⋅ϵθ(xt′,τθ(pctxt,t)+(1−ω)⋅ϵθ(xt′,τθ(pobj,t))\widetilde{\epsilon_\theta}=\omega\cdot\epsilon_\theta(x't, \tau\theta(p_{ctxt}, t)+(1-\omega)\cdot\epsilon_\theta(x't, \tau\theta(p_{obj}, t))ϵθ =ω⋅ϵθ(xt′,τθ(pctxt,t)+(1−ω)⋅ϵθ(xt′,τθ(pobj,t))
ω\omegaω为权重参数
到这里算法重点部分介绍完了,具体训练参数可以查看原文,这里不赘述