探索世界模型从阅读一篇综述开始!
论文:Understanding World or Predicting Future? A Comprehensive Survey of World Models
论文与代码汇总:https://github.com/tsinghua-fib-lab/World-Model
综述系列篇:
【SAM综述】医学图像分割的分割一切模型:当前应用和未来方向
0、摘要
由于 GPT-4 等多模态大语言模型 以及 Sora 等视频生成模型 的进步,世界模型这一概念在通用人工智能 研究中备受关注。(什么样的模型才能被叫做世界模型呢)
**本文对世界模型相关文献进行了全面综述。通常,世界模型被视为理解当前世界状态或预测其未来动态的工具。**本文提出了一种系统性的分类方法,强调世界模型的两个主要功能:
(1)构建内部表征以理解世界运行机制;
(2)预测未来状态以模拟并指导决策;
首先,本文回顾了这两类模型的当前进展;其次,探讨了世界模型在生成式游戏、自动驾驶、机器人以及社会模拟等关键领域的应用,重点分析各领域如何利用上述两类功能。最后,本文总结了主要挑战,并展望了未来潜在的研究方向。
1、引言
科学界长期致力于发展一个能够复制世界基本动力学 的统一模型,以追求通用人工智能(AGI)。2024年,多模态大语言模型以及 Sora 等视频生成模型的出现,进一步引发了围绕这类世界模型的讨论。尽管这些模型展现出捕捉部分世界知识的涌现能力------例如 Sora 生成的视频似乎完美遵循物理定律------但关于它们是否真正称得上全面的世界模型,仍存在疑问(哲学思考:什么是真正的智能?)。因此,在人工智能时代迈向新突破的当下,对世界模型研究的最新进展、应用及未来方向进行系统性的综述,既及时又必要。(是的,很及时)
世界模型的定义 仍处于持续争论之中,主要分为两种视角:**理解世界与预测未来。**如 图 2 所示,Ha 与 Schmidhuber 的早期工作侧重于对外部世界进行抽象,以深入理解其潜在机制。而 LeCun 则认为,世界模型不仅应能感知和建模真实世界,还应具备构想未来可能状态以指导决策的能力。Sora 等视频生成模型专注于模拟世界的未来演化,因此更接近于世界模型的预测功能。这就提出了一个问题:世界模型应该优先理解现在,还是预测未来? 本文从上述两种视角出发,对相关文献进行全面综述,重点介绍关键方法及其面临的挑战。
世界模型的潜在应用涵盖多个领域,不同领域对理解能力 与预测能力 的需求各异。以自动驾驶为例,世界模型需要实时感知道路状况并准确预测其演变,尤其关注即时环境感知与复杂趋势的预测(感知与预测)。对于机器人而言,世界模型在导航、目标检测与任务规划等任务中至关重要,既需要精确理解外部动态,也需要具备生成可交互的具身环境的能力(视觉、演算、控制)。在虚拟社会系统模拟领域,世界模型则需捕捉和预测更为抽象的行为动态,例如社会互动与人类决策过程。因此,对这些能力进展的全面梳理,以及对未来研究方向与趋势的探讨,既及时又必要。(是的,很必要)
现有关于世界模型的综述大致可分为两类。第一类主要聚焦于世界模型在特定领域的应用 ,如视频处理与生成、自动驾驶、基于智能体的应用等;第二类则关注从能够处理多模态数据的多模态模型到世界模型的技术演进 。然而,这些文献往往缺乏对"什么是世界模型"以及不同实际应用对世界模型有何要求这两个问题的系统考察(所以什么是世界模型呢)。本文旨在对世界模型进行正式的定义与分类,回顾近期的技术进展,并探讨其广泛的应用。
本文的主要贡献可概括如下:
(1)提出了一种新的世界模型分类体系,围绕两大核心功能展开:构建隐式表征以理解外部世界的运行机制,以及预测外部世界的未来状态。第一类聚焦于学习并内化世界知识以支持后续决策的模型开发,第二类则强调从视觉感知出发,增强对物理世界的预测与模拟能力。
(2)基于该分类体系,梳理了生成式游戏、自动驾驶、机器人及社会模拟等关键应用领域对世界模型不同侧重点的利用方式。
(3)指出了世界模型在未来研究中可适应更广泛实际应用的方向与趋势。
本文其余部分的结构如下:第 2 节介绍世界模型的背景并阐述本文提出的分类体系;第 3 节和第 4 节分别详细阐述两类世界模型的当前研究进展;第 5 节介绍世界模型在三个关键研究领域的应用;第 6 节概述世界模型面临的开放问题与未来方向。
2、背景与分类
2.1、 历史与当前发展
本节探讨文献中世界模型概念的演变,并将构建世界模型的工作分为两个不同的分支:内部表征与未来预测。
(1)深度学习前时代
在人工智能领域,构建世界内部模型的概念由来已久(梦想由来已久),可追溯至 20 世纪 60 年代 Marvin Minsky 提出的框架表示 等奠基性工作,该框架旨在系统性地捕捉关于世界的结构化知识。在强化学习背景下,世界模型作为基于模型的方法的基本组成部分出现,其中智能体 对其环境动态构建显式的表征。该领域的早期工作主要聚焦于学习状态转移模型 ,即在给定当前状态和动作的情况下预测下一个状态,从而使智能体能够在执行前进行规划并模拟可能的动作序列。这些环境模型通常采用表格方法或简单的参数化函数来表示,为随着深度学习的到来而出现的更复杂的世界建模方法奠定了基础。
Figure 1 | 深度学习时代世界模型的发展路线图:
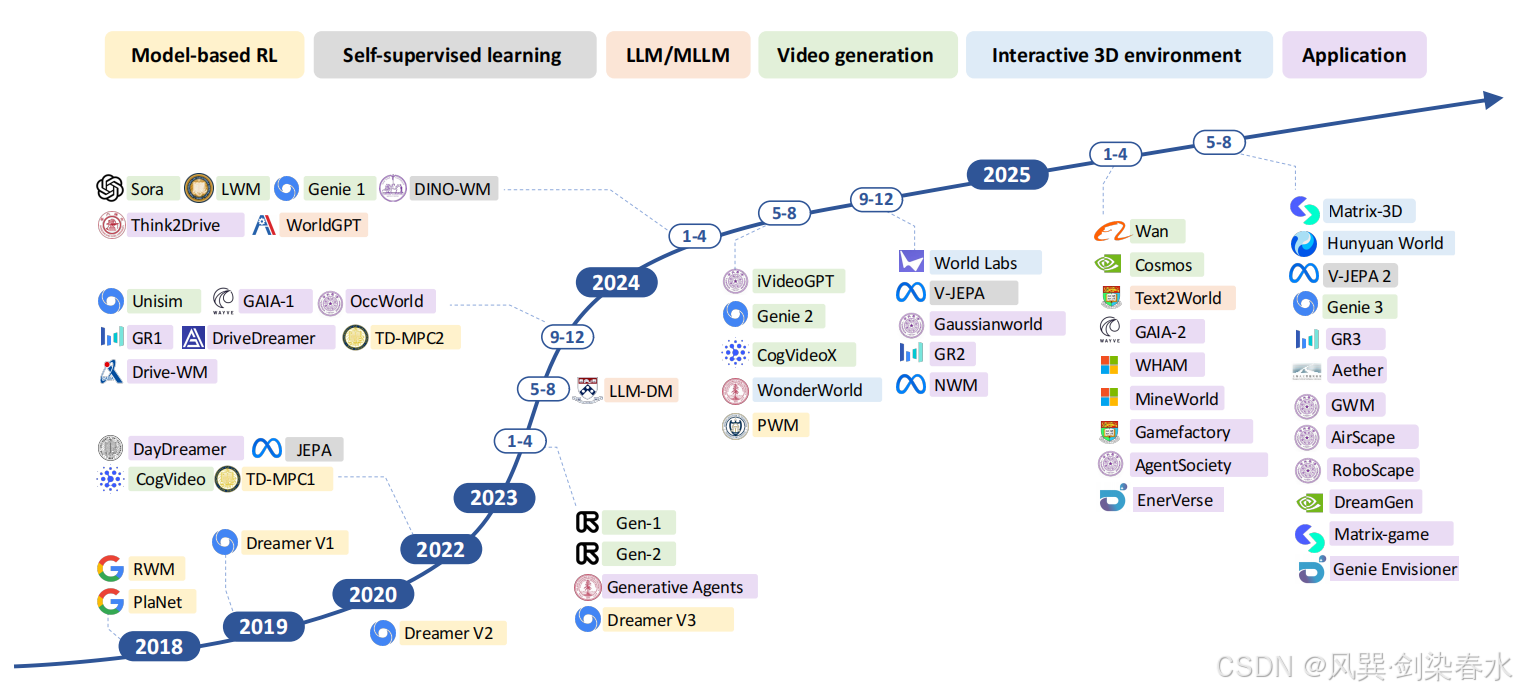
(2)基于模型的强化学习
Ha 等人在 2018 年通过提出一种基于循环神经网络的隐式模型 用于学习潜在表征,显著复兴并推广了"世界模型"这一术语。这一研究方向与"心智模型"的心理学理论相一致,该理论认为人类通过将外部世界抽象为简化的元素和关系来感知世界(人类学习潜在表示)------这一潜在的哲学原理在框架表示与世界模型中均有所体现。该原理表明,从认知角度来看,人类对世界的理解通常涉及构建能够捕捉本质模式而无需详尽细节的抽象表征 。在此概念框架基础上,作者引入了一个受人类认知系统启发的智能体模块,如 图 2 所示。在该循环世界模型中,智能体从真实环境接收反馈,这些反馈随后被转化为一系列输入以训练模型。该模型擅长模拟在外部环境中执行特定动作后可能出现的结果。本质上,它创建了对潜在未来世界演化的心智模拟,并基于对这些预测结果的评估做出决策。这一方法紧密模仿了基于模型的强化学习方法,两种策略均涉及模型生成外部世界的内部表征,以辅助完成各种决策任务中的导航与求解。在此概念基础之上,后续研究进一步发展了世界模型架构,包括 Google DeepMind 的 Dreamer 系列,该系列展示了学习到的世界表征在日益复杂领域中的可扩展性与有效性。
(3)自监督学习
在2022年关于自主机器智能发展的前瞻性文章中,Yann LeCun 提出了联合嵌入预测架构(JEPA) ,这是一个模仿人脑结构的框架。如 图 2 所示,JEPA 包含一个处理感官数据的感知模块 (即编码器),以及一个评估该信息的认知模块 (即预测器),后者有效地体现了世界模型。该模型使得大脑能够评估行为并确定最适合实际应用的响应。JEPA 的一个关键创新在于其自监督学习范式 ,使系统能够在无需依赖大量标注数据的情况下学习丰富的世界表征。**JEPA 并非在像素空间中预测原始感官输入,而是学习在潜在嵌入空间中预测抽象表征,从而使学习过程更加高效和稳健。**这种方法使模型能够捕捉数据中的语义关系和因果结构,同时避免了像素级预测所带来的计算负担和潜在问题,例如聚焦于不相关的细节或噪声(隐空间潜在表示)。
LeCun 的框架尤其引人入胜之处在于它融合了"快"与"慢"思考的双系统 概念。系统 1 涉及直观的、本能式的反应: 即无需显式调用世界模型即可做出的快速决策,例如本能地躲避迎面走来的人。相比之下,系统 2 则采用深思熟虑的、经过计算的推理,利用已学习的世界模型来考虑未来的状态 。它超越了即时的感官输入,通过自监督表征模拟潜在的未来场景,例如预测房间内接下来十分钟可能发生的事件并据此调整行为。这种前瞻能力要求构建一个能够基于环境预期动态与演化 来有效指导决策的世界模型。在该框架中,世界模型通过对潜变量的自监督学习来理解和表征外部世界至关重要,这种学习方式在过滤冗余信息的同时捕捉关键信息。这种方法能够形成一种高效且极简的世界表征,从而促进对未来场景的最优决策与规划。基于这些原理,最近的实现如 V-JEPA 和 V-JEPA2 已经证明了基于视频的自监督学习的实践可行性,展示了 JEPA 架构如何从未标注的视频数据中学习丰富的时空表征,以服务于下游的视觉任务。
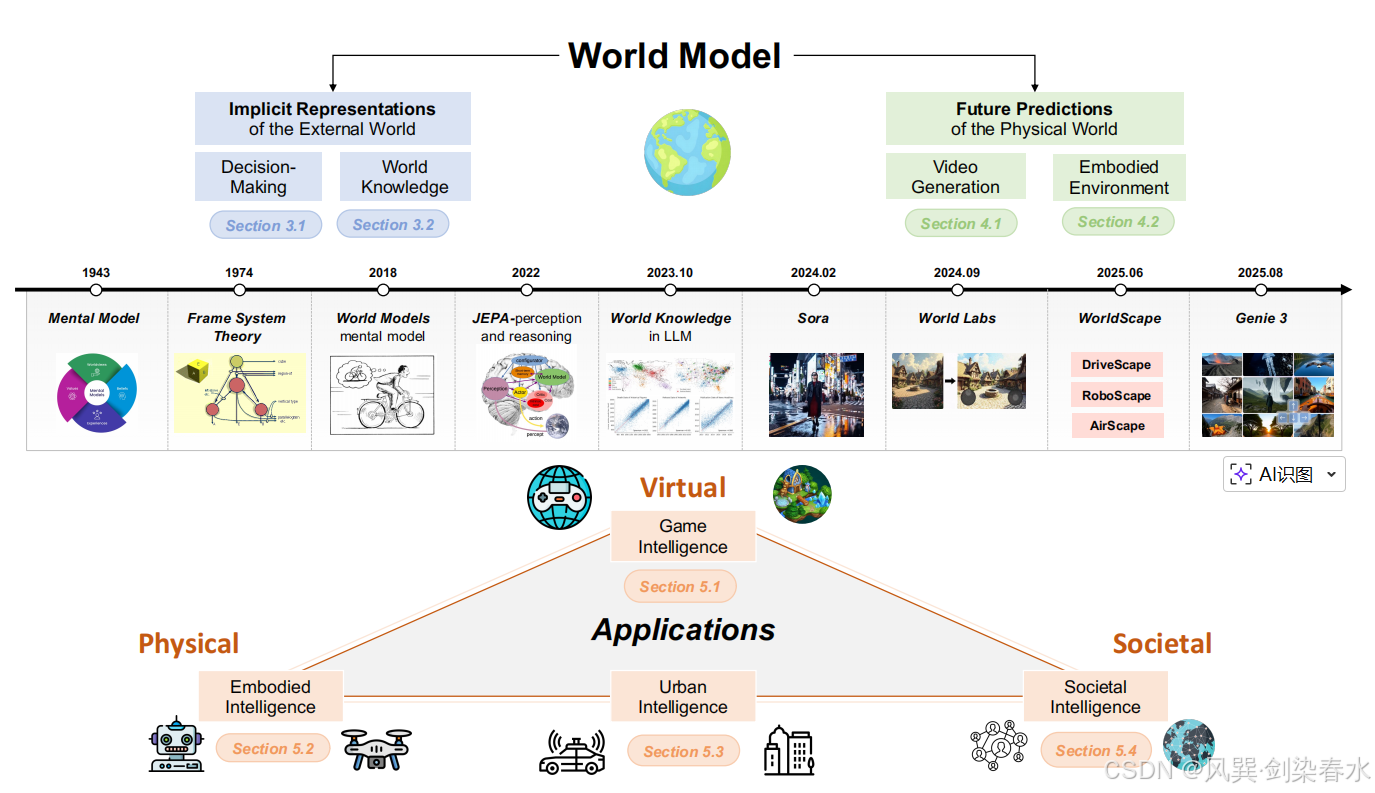
**Figure 2 | 本综述的整体框架:**本文系统界定世界模型的核心目标:认知外部世界动态规律、预测未来场景 ,并梳理关键概念定义与相关应用的发展脉络;
(4)大语言模型
"我语言的界限即是我世界的界限 。"------路德维希·维特根斯坦。(文字信息包罗万象)这一深刻见解在大语言模型的背景下尤为贴切,因为大语言模型通过文本数据学习世界运行的基本原理,这些原理可用于构建全面的世界模型。近期研究表明,在庞大语料库上训练的大语言模型能够自然地习得潜在的世界知识,包括空间与时间理解能力 ,从而能够对真实世界场景做出复杂的预测。这种能力已被用于基于模型的任务规划,其中预训练的语言模型作为构建世界模型的基础,能够对复杂的序列化任务进行推理。多模态能力的整合进一步增强了世界建模的潜力。多模态大语言模型能够处理并整合来自视觉、文本及其他感官模态的信息,创建更丰富、更全面的世界表征。理解这些模型如何处理、表征和利用世界知识,对于开发能够弥合语言知识与真实世界理解之间鸿沟的更有效的世界模型仍然至关重要。
(5)视频生成
视频生成已成为当代人工智能研究中世界建模的主要方法。与早期的隐式世界表征不同,这些模型能够显式地生成视觉序列,展示出对时间动态、空间一致性和物理定律的理解 。(统计经验还是真正理解呢)借助扩散模型与 Transformer 架构等先进生成技术,近年来的视频生成模型------包括 Sora、Keling 和 Gen-2 ------以文本指令或真实世界视觉数据为输入,生成高质量的视频序列。这些模型展现了卓越的世界建模能力,例如在 3D 视频模拟中保持一致性、生成物理上合理的结果以及模拟复杂的数字环境。这些方法的复杂性表明,它们建模的是真实世界的基本动态 ,而不仅仅是生成视觉上吸引人的内容。**这代表了向能够主动模拟和预测环境随时间演化的世界模型的根本性转变。**近期的发展进一步推动了这一范式,Cosmos 在物理定律遵循方面取得了突破性表现,而 Genie 3 则实现了可控世界模拟的实时交互能力。
(6)交互式 3D 环境
交互式 3D 场景生成是世界建模中的另一个重要范式,其核心在于创建沉浸式的 3D 世界,使用户能够在虚拟环境中进行空间探索和交互 。(虚拟现实么)代表性工作如 Wonderworld,展示了从单张 2D 图像生成可交互 3D 场景的能力,体现了从极简输入创建可探索虚拟世界的潜力。该方法强调空间一致性、几何理解以及对用户导航与交互的实时响应。近期进展显著扩展了这些能力:Matrix-3D 通过全景 3D 重建实现了大范围、可全方位探索的 3D 世界生成;HunyuanWorld 1.0 则通过语义分层的 3D 网格表示实现了沉浸式 360° 体验,并可与现有计算机图形管线无缝兼容。
(7)应用
自 2023 年以来,世界模型已迅速扩展到多个应用领域。在自动驾驶领域 ,GAIA-1 和 Drive-WM 等奠基性工作建立了复杂交通场景中车辆交互与环境动态的建模方法。机器人领域 同样取得了长足进步,以 2023 年的 DayDreamer 为代表,并延续至 2025 年在机器人操作任务方面的最新发展。导航应用 方面,机器人路径规划已扩展到六自由度空中智能体。游戏领域 是一个极具前景的方向,以世界与人类动作模型(WHAM)为代表的里程碑式工作展示了世界模型如何创建动态、响应式的虚拟环境。在更大尺度上,基于智能体的社会模拟 利用世界模型来理解复杂的社会动态与人类交互,为真实世界的社会现象提供计算层面的洞察。(计算世界)
2.2、多领域视角下世界模型概念的演变
人工智能中的世界模型概念有着深厚的心理学根源,远超出当代机器学习的范畴。理解这些基础性的关联,有助于揭示现代 AI 世界模型如何实现那些在多个学科中被研究数十年的基本认知原则。
"心智模型 "这一心理学概念最早由苏格兰心理学家 Kenneth Craik 在其开创性著作《解释的本质》(1943)中明确提出。他提出,"心智会构建现实的小尺度模型",以预测和理解外部事件 。Craik 的核心见解是:人类认知的根本运作方式在于创建能够捕捉外部世界基本结构与动态的内部表征,从而实现预测性推理与适应性行为。(捕获信息,预测推理)
这一基础性概念随后由英国心理学家 Philip Nicholas Johnson-Laird 在 20 世纪 80 年代通过其"心智模型理论"加以系统发展和形式化。在其具有影响力的著作《心智模型:迈向语言、推理与意识的认知科学》(1983)中,Johnson-Laird 论证了人类推理是通过心智模型的构建与操作来实现的------这些内部表征保留了其所表征情境的结构关系。根据该理论,当人类进行演绎推理、归纳推断或反事实思考时,会通过构建并检验不同可能世界的心智模型,来对不同的情境进行心智模拟。(计划周末去爬山,心里会想象"如果下雨就取消,如果晴天就出发"。这种"如果...就..."的推演,就是通过构建不同的"可能世界"模型来模拟结果。)
Johnson-Laird 的框架确立了若干关键原则,这些原则与当代 AI 世界模型直接对应:**心智模型是对潜在无限领域的有限表征;它们捕捉结构关系而非表面细节;它们能够对替代性情境进行预测性模拟。**这些原则已成为理解人类与人工智能体如何高效地表征复杂环境并对其进行推理的基础。
心智模型 = 大脑里的"小沙盘": 它不是真实世界,而是抓住关键规律(比如"冷热传递"),忽略无关细节(比如杯子的颜色)。
用模型来推理: 比如做逻辑题"所有 A 是 B,所有 B 是 C,那么 A 和 C 什么关系?"------大脑会构造一个包含 A、B、C 三者包含关系的图像(模型),然后看出 A 一定是 C。
能模拟"反事实": 即使事情没发生,你也可以想象"如果我昨天没带伞,会不会淋湿?"这种思考依赖于你内心对"下雨+没伞→淋湿"这一因果关系的模型。
2.3、分类体系
无论是侧重于学习外部世界的内部表征,还是模拟其运行原理,这些概念都汇聚成一个共识:**世界模型的根本目的在于理解世界动态,并以确定性(或在一定保障下)计算下一个状态,从而使模型能够外推更长时程的演化,并支持下游的决策与规划。**基于此视角,本文对世界模型的最新进展进行全面审视,并按照如 图 2 所示的以下几个维度进行分析。
(1)外部世界的隐式表征(第 3 节)
该研究方向通过构建环境变化模型,以实现更明智的决策,其最终目标是预测未来状态的演化。 它将外部现实转化为以潜变量表征这些元素的模型,从而促进隐式的理解。此外,随着大语言模型的出现,以往集中于传统决策任务的工作,因其对世界知识具有细致描述的能力而得到了显著增强。本文进一步关注将世界知识融入现有模型的相关研究。(将世界压缩为潜变量或语义表征,用于决策)
(2)外部世界的未来预测(第 4 节)
本文首先探讨以视觉视频数据为主、模拟外部世界 的生成模型。这些工作的重点在于生成视频的真实性,使其能够反映物理世界的未来状态。随着近期研究重心转向构建真正可交互的物理世界,本文进一步考察从视觉表征到空间表征、从视频到具身化的转变 。这包括对生成镜像外部世界的具身环境相关研究的全面覆盖。(预测未来:随时间帧推演,对未来物理世界进行演化,内在地理解物体运动、遮挡关系、光影变化、重力等物理规律,以及事件发生的时序因果)
(3)世界模型的应用(第 5 节)
世界模型已在多个领域展现出广泛的应用前景,涵盖游戏智能、具身智能体、城市系统与社会建模。这些领域------分别以生成式游戏、机器人、自动驾驶及社会模拟为代表------展示了世界模型如何在虚拟与物理环境中架起感知、推理与想象之间的桥梁 。本文将探讨世界模型在这些领域的融合如何推动理论认知与实践创新,并强调其在塑造智能系统方面的变革潜力。(从"生成未来视频"向"生成可交互的具身环境"演进)
3、外部世界的隐式表征
本章探讨世界模型如何通过将环境表征为潜变量,从而实现更明智的决策。第 3.1 节聚焦于基于模型的强化学习中的世界模型,第 3.2 节则探讨将世界知识融入大语言模型等先进 AI 模型的方法,以提升其在真实世界任务中的表现。
3.1、决策过程中的世界模型
在决策任务中,理解环境是为生成优化策略奠定基础的主要任务 。因此,决策过程中的世界模型应包含对环境的全面理解。它使我们能够在不影响真实环境的情况下进行假设性动作,从而降低试错成本。在文献中,关于如何学习与利用世界模型的研究最初出现在基于模型的强化学习领域 。此外,近期大语言模型 和多模态大语言模型 的进展也为世界模型的构建提供了全面的基础架构。由于语言是一种更通用的表征形式,基于语言的世界模型可以适应更广泛的任务。在决策任务中利用世界模型的两种方案如 图 3 所示。
Figure 3 | 两种利用世界模型进行决策的方案:
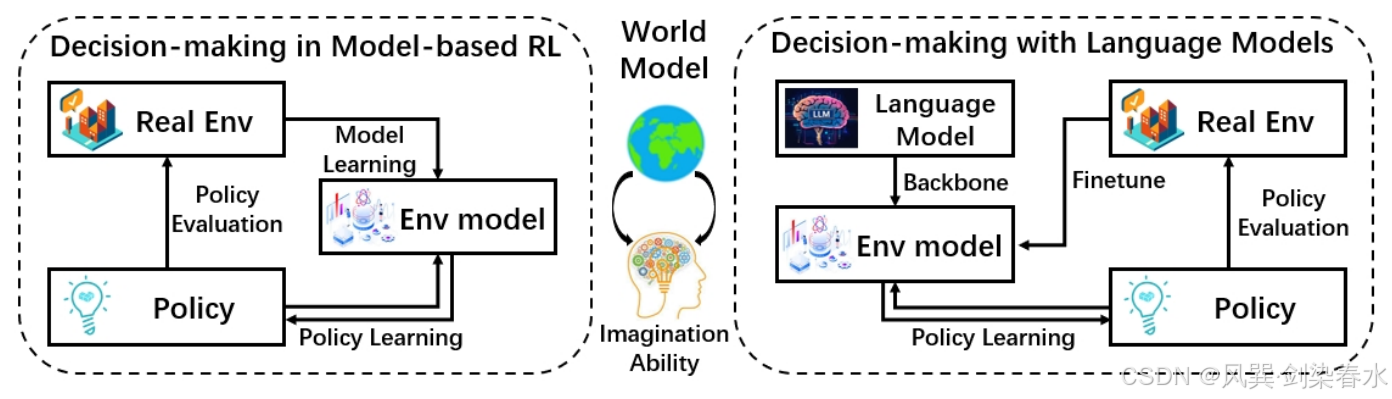
3.1.1、基于模型强化学习中的世界模型
在决策任务中,世界模型这一概念通常指代基于模型强化学习(MBRL)中的环境模型。决策问题一般被建模为马尔可夫决策过程(MDP),可用五元组 ( S , A , M , R , γ ) (S,A,M,R,γ) (S,A,M,R,γ) 表示,其中 S S S、 A A A、 γ γ γ 分别对应状态空间、动作空间与折扣因子。此处的世界模型包含状态转移动力学 M M M 与奖励函数 R R R。由于多数场景下奖励函数是预先定义好的,因此 MBRL 的核心任务是学习并利用状态转移动力学,以此支撑后续策略优化。
(1)世界模型学习
想要学习精准的世界模型,最直观的方法是在单步状态转移上采用均方预测误差进行优化:
min θ E s ′ ∼ M ∗ ( ⋅ ∣ s , a ) ∥ s ′ − M θ ( s , a ) ∥ 2 2 , (1) \min_{\theta} \mathbb{E}_{s' \sim M^*(\cdot|s,a)} \left \\left\\\| s' - M_\\theta(s,a) \\right\\\|_2\^2 \\right, \tag{1} θminEs′∼M∗(⋅∣s,a)∥s′−Mθ(s,a)∥22,(1)其中 M ∗ M^∗ M∗ 为采集轨迹数据所使用的真实环境转移动力学, M θ M_θ Mθ 为待学习的参数化转移模型。
除直接使用确定性转移模型外,Chua 等人进一步采用概率转移模型 对随机不确定性进行建模,优化目标为最小化两个转移模型之间的 KL 散度:
min θ E s ′ ∼ M ∗ ( ⋅ ∣ s , a ) log ( M ∗ ( s ′ ∣ s , a ) M θ ( s ′ ∣ s , a ) ) . (2) \min_{\theta} \mathbb{E}_{s' \sim M^*(\cdot|s,a)} \left \\log\\left( \\frac{M\^\*(s'\|s,a)}{M_\\theta(s'\|s,a)} \\right) \\right. \tag{2} θminEs′∼M∗(⋅∣s,a)log(Mθ(s′∣s,a)M∗(s′∣s,a)).(2)在上述两种框架下,世界模型学习任务都可以转化为监督学习任务,学习标签来自智能体与真实环境交互得到的轨迹数据,也被称作仿真数据。(状态转移模型 M ( s ′ ∣ s , a ) M(s'|s,a) M(s′∣s,a) 描述了在状态 s s s 执行动作 a a a 后转移到下一状态 s ′ s' s′ 的概率)
对于高维环境而言,表示学习是基于模型强化学习(MBRL)中世界模型高效训练的核心前提。Ha 与 Schmidhuber 的早期研究通过自编码器 - 隐状态流水线完成图像重建;而 Hafner 等人将视觉编码器与隐动力学结合,解决基于像素的控制任务。其迭代版本 DreamerV3 引入鲁棒归一化与平衡优化策略,无需人类数据与领域专属调参,即可完成超过 150 项任务(包括《我的世界》钻石收集任务)。Samsami 等人提出的回忆成像等面向记忆的扩展方法,进一步提升了模型的长时序推理能力。
另一大研究趋势是基于 Transformer 架构、通过下一词元预测实现统一模型学习 ,该思路由 Janner 等人提出,并由 Schubert 等人进一步拓展。此外,Georgiev 等人训练了大型离线多任务世界模型,其平滑的隐动力学特性,让智能体仅依靠一阶梯度就能高效完成单任务策略学习,无需在线规划即可实现优异的可扩展性与性能表现。
Jonathan Richens 等人的近期研究进一步佐证了世界模型的必要性:**任何能够在多步目标导向任务中泛化的智能体,都必然学习了环境的预测模型,而世界模型会从智能体策略中自然涌现。**这一结论与当前研究趋势高度契合:将预测建模融入强化学习,以此应对更复杂、更面向目标的智能决策任务。
一个智能体(无论是人还是AI)如果能够完成"需要一连串动作才能达到目标"的复杂任务(比如"先去超市买菜,再去邮局寄包裹,最后回家"),那么它脑子里一定有一个对环境的"预测模型"------也就是知道"如果我做这个动作,世界会变成什么样"。这个预测模型不是额外加装的,而是从它学会完成任务的策略中自然产生的。
(2)基于世界模型的策略生成
在世界模型完成理想优化后,生成对应策略最直接的方法是模型预测控制(MPC)(有点像模型推理)。依托已有模型,MPC 通过如下方式规划最优动作序列:
max a t : t + τ E s t ′ + 1 ∼ p ( s t ′ + 1 ∣ s t ′ , a t ′ ) ∑ t ′ = t t + τ r ( s t ′ , a t ′ ) , (3) \max_{a_{t:t+\tau}} \mathbb{E}{s{t'+1} \sim p(s_{t'+1}|s_{t'},a_{t'})} \left \\sum_{t'=t}\^{t+\\tau} r(s_{t'}, a_{t'}) \\right, \tag{3} at:t+τmaxEst′+1∼p(st′+1∣st′,at′)t′=t∑t+τr(st′,at′),(3) 其中 τ τ τ 代表规划时域长度。Nagabandi 等人采用简单蒙特卡洛方法 对动作序列进行采样。Chua 等人则摒弃均匀动作采样方式,提出一种结合轨迹采样的新型概率算法。后续大量研究也通过优化世界模型的使用方式 (训练好了,如何用好),进一步提升了优化效率。
Hansen 等人提出了改进型基于模型强化学习算法 TD-MPC2,该算法在习得隐式世界模型的隐空间内完成轨迹优化,在各类连续控制任务中均表现优异;同时支持训练参数量达数亿的大规模跨领域智能体,具备极强的可扩展性。
另一种主流的世界模型策略生成方法是蒙特卡洛树搜索(MCTS) 。该方法维护一棵搜索树,树中每个节点对应由预设价值函数评估的状态,智能体以此选择能抵达更高价值状态的动作(有点像对抗搜索博弈)。AlphaGo 与 AlphaGo Zero 是离散动作空间中 MCTS 的经典落地应用。Moerland 等人将 MCTS 拓展至连续动作空间决策问题;Oh 等人构建价值预测网络,在习得模型中依托价值与奖励预测结果,通过 MCTS 完成动作搜索。
3.1.2、基于语言骨干网络的世界模型
大语言模型(LLM) 与多模态大语言模型(MLLM) 的快速发展,推动了大量相关应用领域的进步。以语言作为通用表征骨干,基于语言的世界模型在诸多决策任务中展现出巨大应用潜力。
(1)基于大语言模型世界模型的直接动作生成
**大语言模型能够依托构建好的世界模型,在决策任务中直接输出动作。**例如在导航场景中,Yang 等人将预训练文生视频模型迁移至机器人控制专属任务,以文本指令作为大语言模型输出,完成机器人操作标注(语言作为指令控制)。Zhou 等人通过分解视频生成流程,学习组合式世界模型,让模型对未知任务具备强大的少样本迁移能力。
除训练、微调专用语言世界模型外,大语言模型与多模态大语言模型也可直接部署,用于理解决策任务中的环境世界。Long 等人提出多专家协作方案 ,处理视觉语言导航任务:搭建标准化讨论流程,由 8 个大语言模型专家协同输出最终运动决策;依托专家间的讨论与未来状态想象,构建抽象世界模型,支撑后续动作生成。Zhao 等人结合大语言模型与开放词汇检测技术,梳理导航任务里多模态信号与关键信息的关联,提出全向图结构 ,将局部空间结构建模为导航任务世界模型。与此同时,Yang 等人借助大语言模型想象助手,基于环境感知结果推理全局语义图作为世界模型,并搭配反思规划器直接生成智能体动作。
近期相关研究持续优化这一范式,针对性解决网页导航等特殊场景难题。Chae 等人提出世界模型增强(WMA)智能体 ,通过面向转移过程的新型观测抽象预测动作结果,优化网页导航效果,解决机票不可退款这类不可逆动作带来的复杂问题。与之类似,Qiao 等人构建参数化世界知识模型(WKM),为智能体同时提供先验全局知识与动态局部知识,有效缓解盲目试错、幻觉动作等常见问题。
(2)大语言模型世界模型的模块化应用
尽管直接将大语言模型输出作为动作在落地部署上简单便捷,但该方案的决策质量高度依赖大语言模型自身的推理能力。尽管本年度大语言模型的推理潜力已得到充分验证,但通过将基于大语言模型的世界模型作为模块,搭配外部基于模型的验证器或高效规划算法,仍能进一步提升其推理性能。
Guan 等人通过提示 GPT-4 生成并迭代优化 PDDL 领域描述,提取显式世界模型 ;再将这类模型与成熟规划器结合,在极少人工干预的情况下实现优异规划效果。Xiang 等人将具身智能体部署在 VirtualHome 模拟器这一世界模型当中,向大语言模型注入具身先验知识;为更好地规划、完成特定目标,他们设计了目标条件规划方案,利用蒙特卡洛树搜索求解具身任务的真实目标。
Lin 等人提出 Dynalang 智能体,该智能体学习多模态世界模型,预测未来文本与图像表征,并通过模型模拟推演学习动作策略;其策略学习阶段,仅依托此前生成的多模态表征,使用演员 - 评论家算法完成训练。Liu 等人进一步将大语言模型推理建模为贝叶斯自适应马尔可夫决策过程(MDP)中的学习与规划任务:大语言模型等效为世界模型,在马尔可夫决策过程的演员 - 评论家更新中以上下文学习方式运行。其所提 RAFA 框架,在 ALFWorld 等多个复杂推理任务与环境中,性能得到显著提升。
该模块化方案也已成功落地网页导航 等垂直领域。Gu 等人提出 WebDreamer 基于模型规划框架,以专用大语言模型作为世界模型模拟动作执行效果,在网页任务上性能比肩树搜索方法,同时效率大幅提升。Tang 等人则提出 WorldCoder 基于模型智能体,通过编写、修改 Python 代码构建并迭代优化自身世界模型,相比现有方法具备更优的样本效率与计算效率。
直接动作: LLM 既当世界模型又当决策者,一步输出动作;
模块化: LLM 只负责模拟世界动态,决策交给外部专门的规划/学习模块,相当于把"想象"和"决策"分开,更精确但需要更多计算;
例:直接动作是"问路随手一指";模块化是"先给你张地图(LLM生成),再给你个导航算法(规划器)自己算路线"。
3.2、模型习得的世界知识
大语言模型在海量网络文本与书籍数据上完成预训练后,积累了大量真实世界常识与日常生活相关知识。**这类内嵌知识被认为是模型具备优异泛化能力、能高效完成真实世界任务的核心关键。**例如,研究者利用大语言模型的常识知识,完成任务规划、机器人控制与图像理解任务。此外,Li 等人发现:大语言模型用于表征概念全集的高维向量中,内嵌着类脑结构的世界知识 ;Li 等人同时证明,语言模型的表征会与视觉模型表征逐渐趋于同构。 (传说中的文脉相通啊)
依托这类丰富的人类日常生活先验知识,大语言模型已成功落地各类真实场景。例如,借助先验知识为人类日常行为提供语义信息,大语言模型在本地生活服务等领域展现出优异效果。
与通用常识、泛化知识不同,本文从世界模型视角,聚焦大语言模型内部蕴含的世界知识。如 图 4 所示,按照对象与空间范围,大语言模型中的世界知识可分为三类:(1)全局物理世界知识;(2)局部物理世界知识;(3)人类社会世界知识。 相关近期研究总结详见 表 1 。
Figure 4 | 用于构建世界模型的大型语言模型中的世界知识:
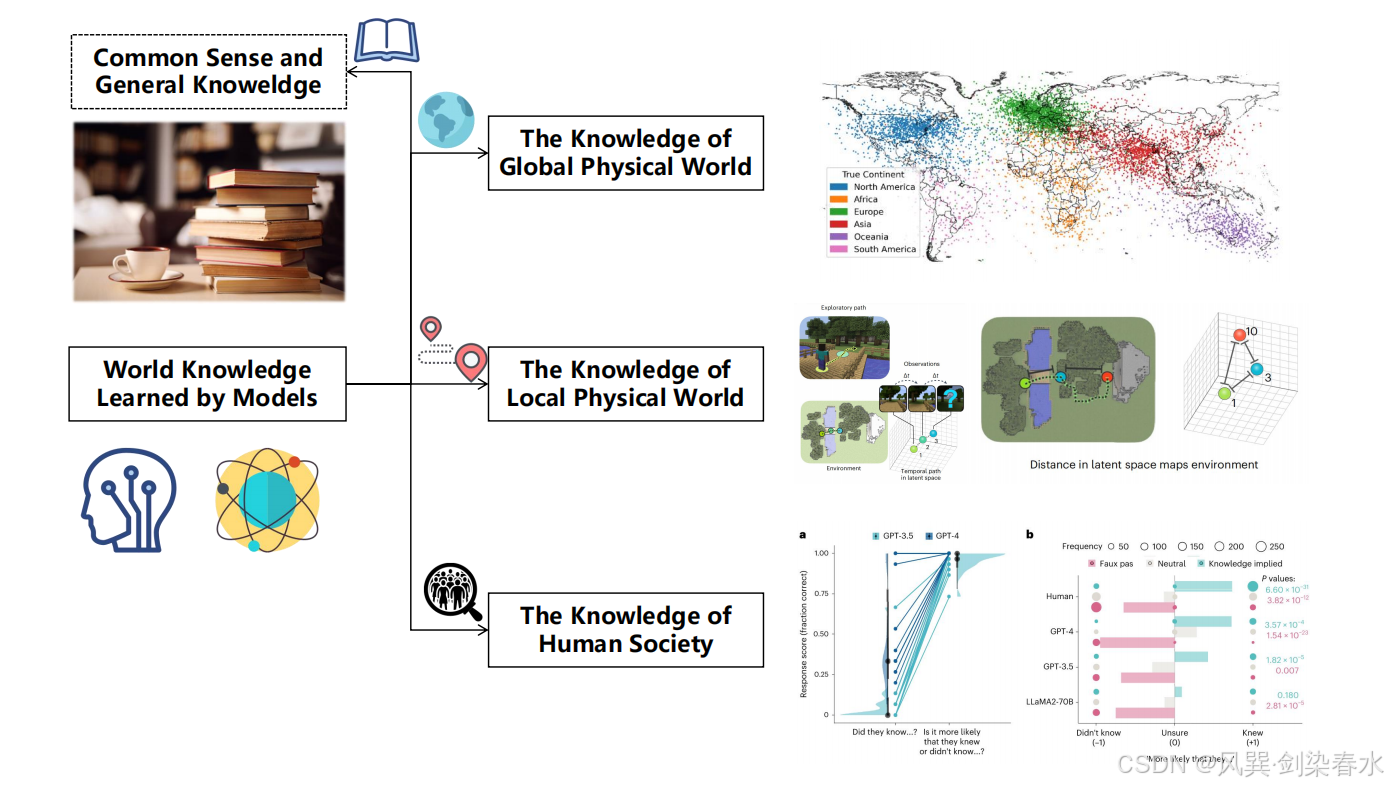
Table 1 | 模型学习的世界知识领域近期研究进展概览:
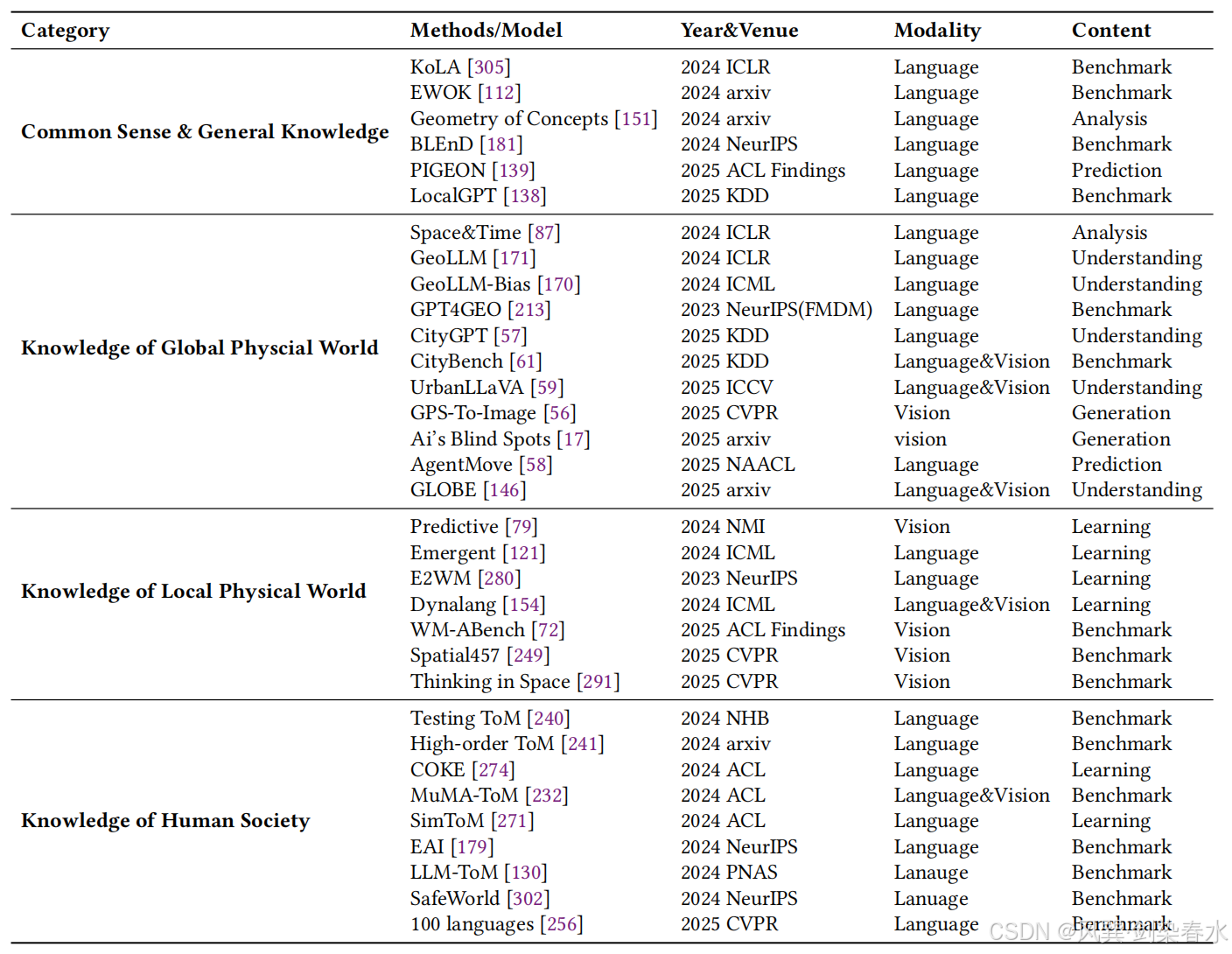
3.2.1、全局物理世界知识
本节首先介绍聚焦于分析、理解全局物理世界知识 的相关研究。Gurnee 等人首次提供证据表明,大语言模型确实习得真实世界的空间与时间知识 ,而非仅仅捕捉表层统计规律(居然能证明不是统计规律!)。他们在 LLaMA2 中识别出独特的 "空间神经元" 与 "时间神经元",这说明模型跨多个尺度学习了空间与时间的线性表征。与以往聚焦嵌入空间的研究不同,Manvi 等人设计了基于文本地址的高效提示词,用于提取地理空间的真实世界常识,并成功提升模型在各类下游地理空间预测任务中的性能。
尽管大语言模型确实获取了部分隐式真实世界知识,但这类知识的质量仍存争议。例如,Feng 等人发现,大语言模型中内嵌的城市知识通常粗糙且不准确。为解决这一问题,他们提出了一套高效框架,以改善模型对特定城市知识的习得能力。
依托大语言模型中内嵌的全局地理空间知识,研究者正利用此类先验世界知识,解决以往方法面临的泛化挑战。典型应用包括:用于全局移动性预测的 AgentMove、用于生成具备地理感知性与风格可控性图像的 GPS-to-Image,以及用于基于知识的图像地理定位的 GLOBE。
从长远来看,尽管大语言模型已展现出对部分真实世界知识的捕获能力,但仍需进一步投入以增强此类知识,从而支撑更广泛、更可靠的真实世界应用。(同志仍需努力啊)
3.2.2、局部物理世界知识
与全局物理世界知识不同,局部物理世界是人类日常生活及绝大多数现实任务的核心环境载体。因此,理解并建模局部物理世界 ,是构建完整世界模型的关键课题。
本文首先介绍认知地图(cognitive map) 概念:**它指人类为导航与理解所处环境而形成的心理表征,包含空间关系与地标信息等。**该概念最初用于解释人类学习过程,但研究者发现大语言模型中同样存在类似结构(有点子抽象了这个),并利用这一发现提升人工模型在物理世界学习与理解中的效率与性能。
**认知地图的通俗理解:**你第一次去一个大型商场,逛了一圈后,虽然记不住每个店铺的精确坐标,但你脑子里会形成"厕所在这头,电梯在那头,我停车的位置大概在西南角"这样一张关系图。这张图包含地标(厕所、电梯)和空间关系(远近、左右、前后)。下次你要从电梯走到厕所,你不需要看路牌,凭这张"心地图"就能知道怎么走。
近期研究积极探索,引导模型在各类环境中通过类认知地图过程学习抽象知识。例如,Cornet 等人在简化版《我的世界》环境中证明,视觉预测编码能让智能体仅从像素层面构建空间认知地图 。训练完成后,该隐式地图可编码与任意目标的度量距离,实现对未来观测的准确推演。
Lin 等人研究如何通过世界模型学习流程(具体为预测环境的后续帧)教会模型理解游戏环境。借此方式,模型能在动态环境中生成更优动作。此外,Jin 等人发现,语言模型可通过预测下一词元,学习程序语义的涌现表征。近期研究将上述工作拓展至更贴近现实的场景,结果显示:即便是针对简单的局部环境,基于大语言模型的方法在构建精准模型方面,仍存在显著能力差距。
3.2.3、人类社会世界知识
除物理世界外,理解人类社会是世界模型另一核心关键维度 。David Premack 与 Guy Woodruff 提出心智理论 (Theory of Mind),该理论后续被用于解释个体如何推断周围他人的心理状态。
大量近期研究深入探索了大语言模型如何习得、展现这类社会世界建模能力。Sap 等人围绕各类心智理论任务评估大语言模型性能,判断模型类人行为是否源自其对社会规则与隐性知识的真正理解。
Strachan 等人对比人类与大语言模型在多项心智理论能力上的表现,包括错误信念理解、反讽识别等能力。研究结果既验证了 GPT-4 在这类任务中的潜力,也指出了模型存在明显短板,尤其在社交失礼行为识别任务上表现受限。
**心智理论 = 站在别人角度想问题,猜他信什么、要什么、感觉什么。**它是社交智能的基础,也是世界模型中理解"人类社会"的关键部分。
比如:你和朋友吃饭,他看了一眼菜单又看了看钱包,你心里马上想:"他可能嫌贵了。"------这就是心智理论在起作用:你推断出他的心理状态(担心价格)。再比如,你看到小孩在找玩具,你知道他"以为"玩具在床底下(即使实际不在),这就是理解对方的错误信念。
除推断个体心理状态外,研究者也在探索大语言模型如何建模人类社会更深层、更广泛的底层规则 。例如,Mozikov 等人研究了情绪因素如何影响大语言模型的道德判断与决策行为(骂大模型一顿,它会回答的更准确么),强调需要稳健机制 来保障模型稳定一致的伦理准则。另有相关研究探索了模型适配全球化复杂社会环境的能力:Yin 等人评估大语言模型在全球多元场景下,生成兼具实用性、文化敏感性与合法合规性回复的能力;Vayani 针对上百种不同文化背景的语言开展大模型大规模评测,凸显语言多样性在构建全球化社会世界模型 中的重要意义(都干到全球去了(○´・д・)ノ)。
上述研究印证了大语言模型在社会世界建模方面的巨大潜力,同时也暴露了模型在处理复杂社交场景时存在显著短板。为弥补这些缺陷、增强大语言模型面向真实复杂场景应用的心智理论能力,研究者提出了多项创新方案:Wu 等人提出 COKE 框架,通过构建知识图谱 ,依托认知链让大语言模型显式运用心智理论;Alex 等人设计 SimToM 两阶段提示框架,有效提升大语言模型在各类心智理论任务上的表现。
4、物理世界的未来预测
4.1、面向视频生成的世界模型
将视频生成能力融入世界模型,标志着环境建模领域实现重大跨越式发展。传统世界模型主要聚焦于离散、静态未来状态的预测。而世界模型通过生成视频式仿真序列,捕捉连续时空动态变化,得以适配更复杂、动态变化的环境。视频生成技术的这一突破,将世界模型的能力推向了全新高度。
4.1.1、迈向视频世界模型
视频世界模型 是一套计算框架,它依托视觉上下文里的历史观测信息与潜在动作,模拟、预测世界未来状态。该概念继承了通用世界模型的核心思想:捕捉环境动态演化规律,让智能体预判世界随时间的变化趋势 。而视频世界模型的核心目标,是生成能够表征环境状态时序演变的连续视觉帧序列。
Sora 是一款大规模视频生成模型,可基于多模态各类输入,生成最长 1 分钟、时序连贯、高画质视频序列(顶流登场)。它依托神经网络架构,生成视觉连贯的仿真画面,画面规律往往贴合光线反射、物体融化等真实世界物理原理。这些能力让 Sora 具备世界模拟器潜力,可根据初始条件与参数预测世界未来状态。
然而尽管视频生成效果出色,Sora 在完整理解、模拟外部世界方面仍存在显著局限。 其核心短板是因果推理能力不足,只能被动生成时序画面,无法主动预判动作会如何改变事件发展。除此之外,Sora 难以稳定复刻正确物理规律,无法精准模拟受力物体运动、流体动力学、光线交互等复杂物理过程。
自 Sora 高质量视频生成取得成功后,近两年涌现出多款大规模视频生成基础模型,例如 OpenSora、CogVideoX、Wan。这类模型通过更高效变分自编码器(VAE)预训练、海量视频数据集深度预训练,具备极强视觉生成能力,是世界模型的核心基础组件。
Cosmos 进一步推动领域发展,推出专用物理世界仿真视频生成底座模型 :通过海量真实物理视频预训练,同时探索扩散模型与自回归架构 ,在物理规律贴合度、世界规律理解能力上实现全新突破。与此同时,Genie 2 与 Genie 3 聚焦游戏场景视频生成;其中 Genie 2 专门设计自回归扩散架构,支持跟随外部动作指令生成交互式视频。
除专项模型外,行业在长时序视频生成、交互式视频生成、物理规律贴合度等核心技术难题上持续突破。研究者的研究重心,正从无约束基础视频生成,转向复刻真实决策空间、服务智能决策的交互式仿真任务 。除此之外,世界模型概念也跳出纯视觉想象场景,拓展至自然环境、游戏、自动驾驶、机器人等各类专属场景仿真落地。(从好玩到好用)
4.1.2、视频世界模型的核心能力
尽管学界对于 Sora 这类模型能否算作成熟完备的世界模型仍存在争议(按照理解物理过程来看,可能不是真正意义上的世界模型),但毋庸置疑,视频世界模型在环境仿真与未来预测领域具备巨大潜力。这类模型通过生成真实、动态的视频序列,为理解复杂环境、与复杂环境交互提供了强大方案。为达到这一高阶能力,本节梳理了视频世界模型区别于传统视频生成模型、必须具备的核心关键能力。(什么样的才能成为视频世界模型)
(1)长时序预测能力
一个可靠的视频世界模型,必须能够**遵循环境长期动态规律,完成跨长时间跨度的未来预测。**该能力可以让模型模拟场景演化全过程,保障生成视频序列完全贴合真实世界的时序变化逻辑。
尽管 Sora 已经可以生成 1 分钟时长、时序连贯性极高的高质量视频,但它依旧无法模拟真实环境中复杂的长期动态变化规律。近期大量研究都在拓展视频生成时长,以此捕捉更长距离时序依赖,提升长序列时序一致性。
(2)多模态融合能力
除文本引导视频生成外,视频世界模型正不断融合图像、动作等更多模态信息,以此提升仿真真实度与交互可控性。多模态融合能够构建更丰富的仿真场景,更好地还原真实世界环境复杂度,同时提升生成场景的精准度与多样性。
(3)交互可控能力
交互性与可控性,是视频世界模型另一项核心关键能力。理想的世界模型不仅能生成逼真环境仿真,更支持与环境进行实时交互。这类交互能力可以模拟不同动作带来的后续结果与环境反馈,适配各类动态决策场景落地应用。当前相关研究重点优化仿真过程可控性,支持用户自主引导、探索各类场景演化。
(4)跨泛化场景适配能力
目前视频世界模型正逐步适配各类专属场景仿真,包括自然环境、自动驾驶、游戏交互等领域。模型能力早已超越基础视频生成,能够复刻真实世界动态规律,支撑海量多样化下游应用落地。
**Table 2 | 各类视频生成相关近期模型综述:**汇总了长时序视频生成、多模态学习、交互式视频生成、时序一致性建模、多样化环境建模方向的相关模型研究;
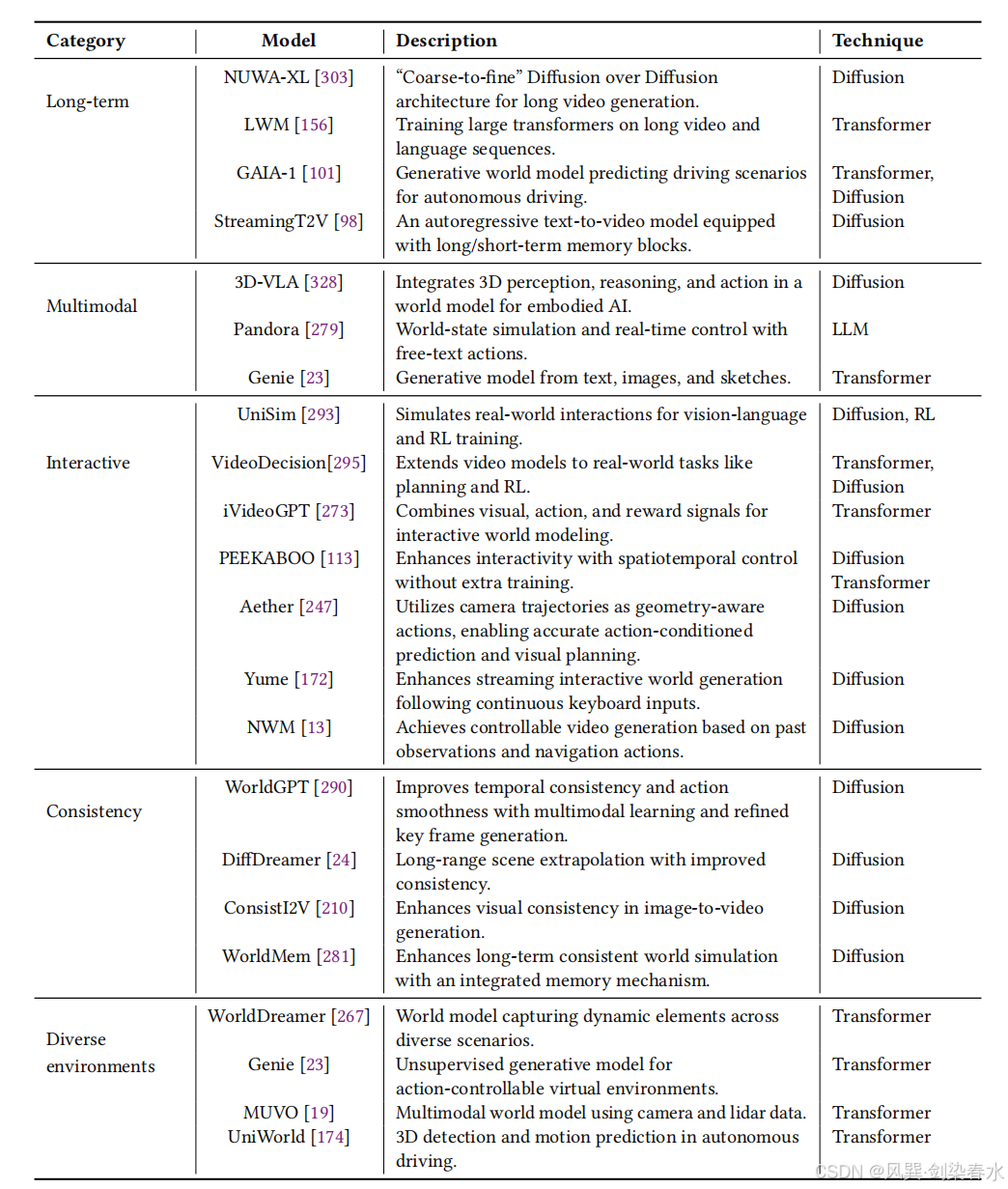
4.2、作为具身交互环境的世界模型
面向具身环境的世界模型研发,对于模拟、预测智能体与外部世界交互适配规律 至关重要。早期生成模型仅聚焦世界视觉层面仿真,依靠视频数据捕捉环境动态变化规律。
近年来研究重心转向构建全交互式具身仿真环境。这类模型不只还原世界视觉特征,更建模贴合真实世界规律的空间关系与物理交互规则。通过融合空间表征、从视频仿真升级为沉浸式具身环境,世界模型如今能为智能体开发提供完整平台,支撑智能体与复杂真实环境交互。
具身智能:一种将人工智能系统嵌入物理实体,使其能够通过与物理环境的动态交互,来感知、学习、推理和行动的智能范式
传统 AI: 像一个被关在硬盘里的"大脑",只能处理你给它的文字、图片、数据。它能看到"杯子"这个词,但不知道杯子怎么拿、多重、滑不滑------因为它没有身体去体验。
具身智能: 给 AI 装上一个"身体"(比如机器人、无人机、虚拟角色),让它能够感知环境、做出动作、并从动作的结果中学习。它不只是"想",而是"做"------比如伸手去抓杯子、绕开障碍物走路、按按钮开门。
**具身智能核心三要素:**有身体 (实体或虚拟仿真身体);能感知 (摄像头、触觉、陀螺仪等);能交互(动作、移动、操作物体);
如 图 5 所示,具身环境类世界模型可分为三类:室内环境、室外环境、动态演化环境 ,相关研究汇总见 表 3 。总体而言,当前大多数研究工作主要致力于开发静态的、现有的室内与室外具身化环境。当下新兴研究趋势,是依托生成模型构建第一视角动态视频仿真环境,以此预测动态变化的未来世界 。这类环境可以为具身智能体训练提供灵活、高真实度反馈,让智能体适配持续变化的复杂场景,大幅提升自身泛化能力。
**Figure 5 | 交互式具身环境世界模型分类,涵盖室内环境、室外环境与动态环境三类:**外部世界建模的研究方向,正从构建静态既有环境,逐步转向对动态演化的未来环境进行预测建模;
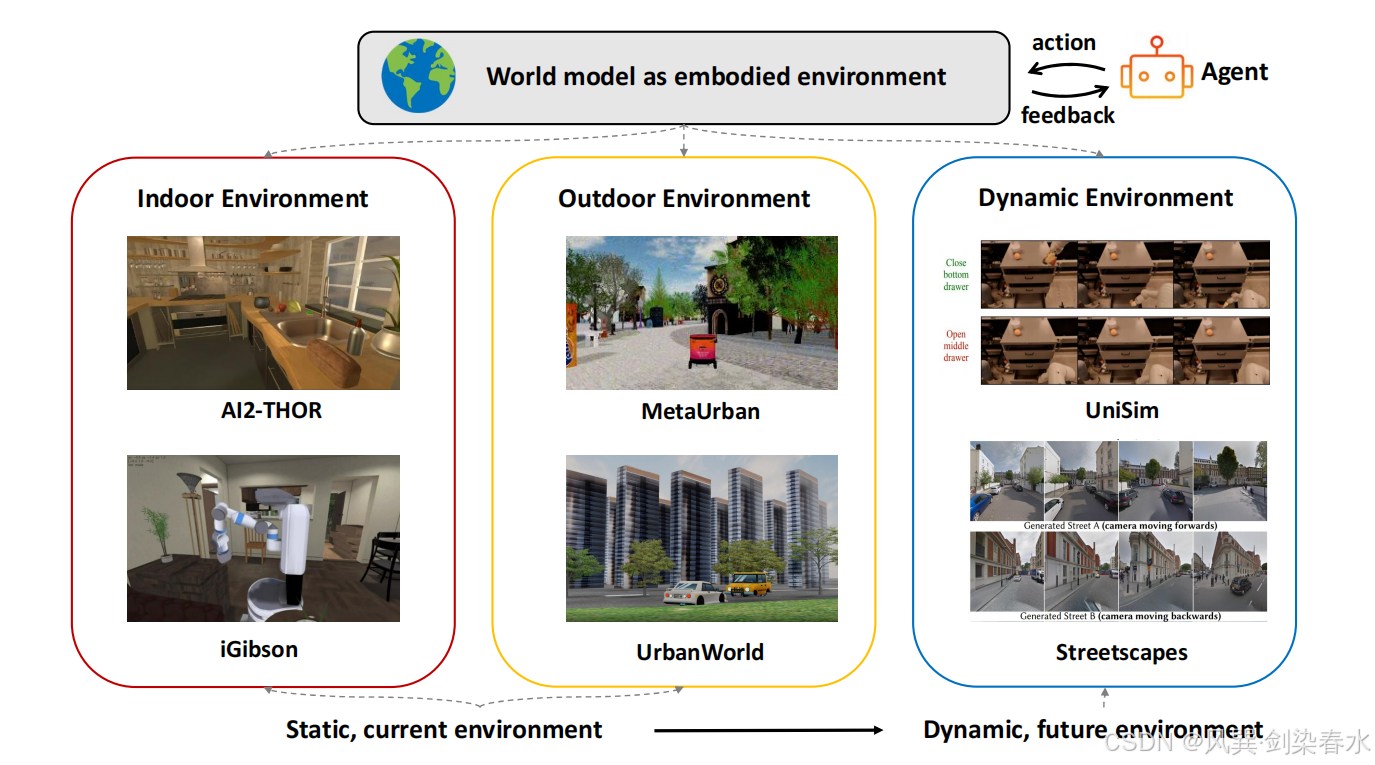
**Table 3 | 现有具身环境世界模型相关研究对比,涵盖室内、室外、动态三类环境相关工作:**在「模态」一列中:V 代表视觉、L 代表激光雷达、T 代表文本、A 代表音频;在「场景数量」一列中:- 代表无公开上报数据;任意 代表该方法支持生成不限数量的场景;
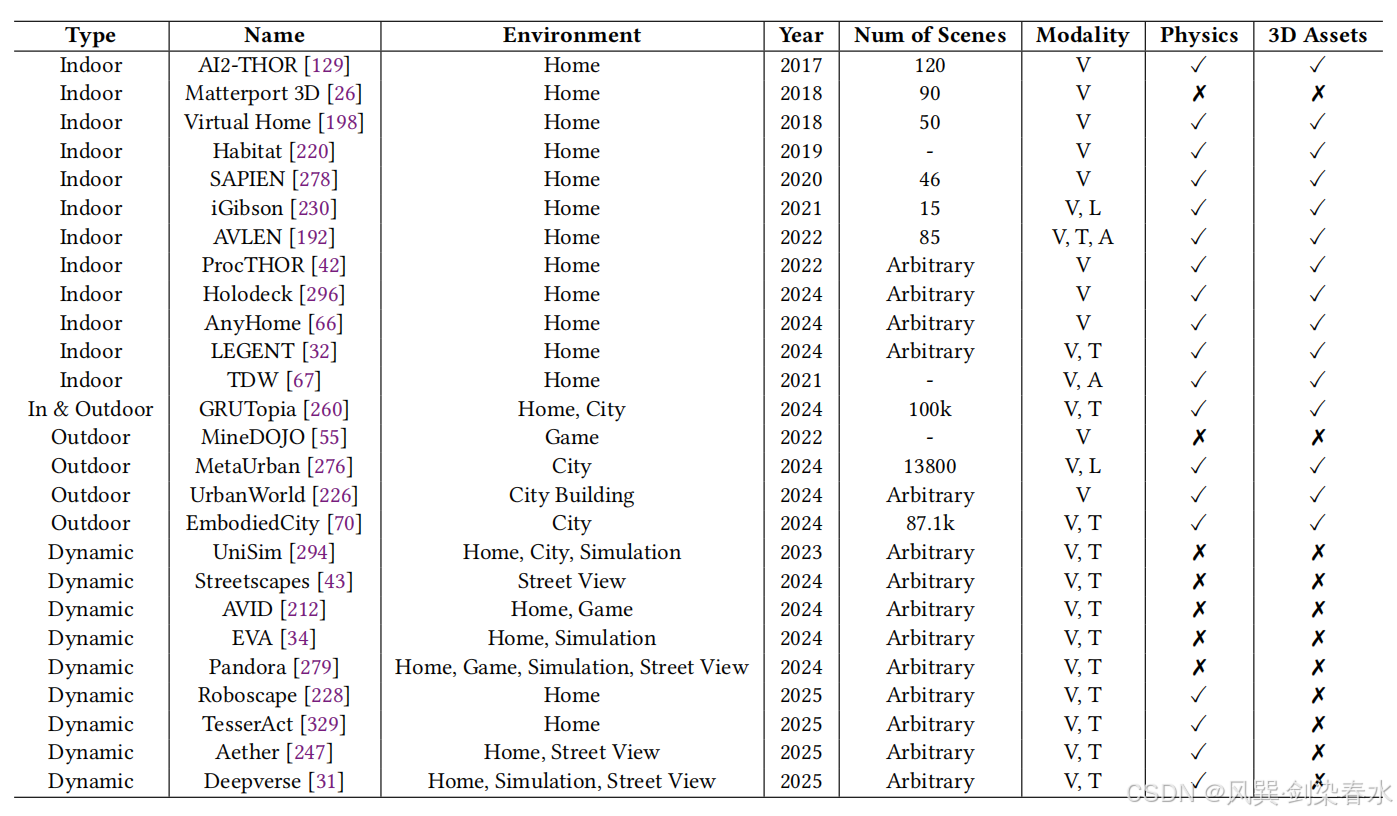
4.2.1、 室内环境
室内环境具备可控、结构化的场景特性,能够支撑智能体完成物体操控、自主导航、与人实时交互等精细化专项任务(在室内进行相关任务)。AI2-THOR、Matterport 3D 等早期室内环境构建工作,仅提供单一视觉信息。这类平台搭建照片级逼真室内场景,供智能体开展视觉导航,复现居家生活交互任务;同时验证了视觉强化学习算法的有效性,助力智能体依靠环境线索优化决策策略。通过模拟烹饪、清洁等真实生活任务,这类平台可评估智能体在不同空间、不同物体间的行为泛化能力。
后续相关研究持续拓展环境数据模态维度 :iGibson 新增激光雷达观测信号反馈,有效提升智能体环境感知精度;AVLEN 进一步补充音频信号,让智能体可在居家场景下完成物体操作、路径规划等复杂任务。该方向核心难点,是让智能体在受限空间内,理解并响应视觉、语言、听觉多模态输入。
GRUtopia 等环境额外引入社交交互维度,要求智能体在场景中同时与实体物品、非玩家角色(NPC)交互,学习空间位序排布、多智能体任务协作等社交动态规律,对高阶交互建模技术提出更高要求。社交交互模块的融入,让智能体能够在类人社交行为与任务执行效果之间实现平衡。
近年来随着大语言模型技术发展,多项研究搭建了灵活的环境生成流水线,支持通过自然语言指令自定义生成各类室内场景。(可交互、动态演化的环境)
4.2.2、室外环境
与室内环境相比,室外环境尺度更大、场景多变,因此构建室外世界模型面临更大挑战。部分现有研究聚焦城市室外场景 ,例如 MetaUrban 平台,支持智能体在大规模城市环境中开展导航任务,需要应对交通动态变化、建筑结构多样、多实体社交交互等复杂挑战。这类任务通常依赖上下文感知导航算法,让智能体根据环境布局与实时状态调整运动轨迹与行为策略。但 MetaUrban 的场景,是从现有素材库检索、拼接 3D 资源构建而成。
近期 UrbanWorld 借助先进生成技术,大幅拓展了室外场景覆盖范围,利用三维生成模型搭建可自定义的复杂城市空间,支撑更多样化的城市任务场景。从静态素材拼接环境转向生成式动态环境,让智能体能够适配陌生街道布局、新型物体与建筑结构等多样化任务。
除真实开放世界生成相关工作外,MineDOJO 等虚拟开放世界平台进一步提升任务难度,程序化生成沙盒式开放场景 。该类平台借鉴《我的世界》开放式玩法,驱动智能体完成资源采集、场景建造、生存探索等任务,要求智能体具备持续环境探索与自适应学习能力(智能体也是玩上游戏了)。在这类环境中,智能体需要主动探索未知信息、动态调整自身行为以完成指定任务;相关训练可以帮助智能体习得跨场景、跨地形的通用知识,实现在各类复杂室外环境下高效稳定运行。
4.2.3、动态环境
动态环境依托生成模型搭建灵活、实时的仿真体系,相较于传统静态仿真器实现了关键性技术演进。这类环境无需人工手动调整配置,可动态生成海量多样化场景,让智能体获得丰富的第一视角交互体验,进而提升智能体在复杂、不可预测真实场景下的自适应能力与泛化性能。
UniSim 是该方向代表性工作,它可根据空间运动、文本指令、相机参数等输入条件,动态生成机器人操作视频序列 。该系统融合三维仿真、真实机器人动作、互联网多模态数据,构建高保真多样化环境,支撑智能体开展物体操控、自主导航等任务训练。该方案核心优势是场景高度灵活,不受固定物理静态环境约束。
Pandora 将 UniSim 的机器人动作动态生成能力,拓展至室内外全场景人机协同动作仿真领域。后续研究 AVID 在 UniSim 基础上,以动作信息为约束条件,结合预训练扩散模型噪声预测模块,生成动作驱动的动态环境视觉时序画面。
在 UniSim 视频扩散框架之上,EVA 额外引入视觉 - 语言模型,优化具身视频时序预测效果,提升画面时序一致性 。面向开放世界动态场景,Streetscapes 采用自回归视频扩散模型,仿真天气变化、车流变动等复杂城市动态导航环境。这类环境时序逻辑连贯、城市场景灵活多变,贴合真实世界环境不确定性特征。
动态环境领域核心发展趋势,是采用生成式世界模型搭建可扩展、自适应仿真平台。该方案大幅降低环境搭建人工成本,助力智能体快速在海量多样场景中完成训练;同时第一视角训练模式高度贴合人类真实决策逻辑,有效增强智能体复杂动态场景适配能力,推动面向复杂动态场景的具身智能体技术发展。
综合上述研究进展可知,面向具身环境的世界模型,在真实世界环境时序演化仿真领域已取得显著突破。当前相关研究仍以室内静态环境构建为主,同时正大力向大规模室外场景、动态仿真环境方向拓展 。构建动作驱动、第一视角未来世界预测的动态环境,是极具潜力的发展方向,能够有效提升智能体应对未知场景的自适应能力。与此同时,动态具身世界建模的最新研究,均高度重视物理约束规律 的融合:
Aether 以相机运动轨迹 作为动作约束,生成驱动式 RGB-D 视频,强化模型几何特征认知学习能力;TesserAct 进一步引入法线图 作为视频生成物理约束条件;Roboscape 在视频生成过程中融合深度图与关键点动态变化规律 ,学习并生成更贴合真实物理规律的物体运动与空间结构;Deepverse 则将历史时序帧的几何预测信息 ,融入当前动作约束下的环境预测结果。上述各类方法共同提升了动态世界仿真的真实度与物理规律贴合度,最终为具身智能体搭建高可靠、高保真的仿真训练环境。(还是要与传统相结合)
5、应用领域
5.1、游戏智能
游戏环境是世界模型研究的理想试验平台:**它场景可控、逻辑复杂,要求模型深度理解物理规律、因果逻辑与交互动态变化。**与真实世界应用不同(真实场景真值往往模糊、难以获取),游戏具备清晰完备的规则体系、明确的动作 - 结果对应关系,能够精准量化评估世界模型各项能力。(有明确的任务与奖励机制)
更为重要的是,世界模型技术正以前所未有的方式,彻底革新游戏开发流程与玩家游玩体验。传统游戏开发依赖人工编写规则、预设场景素材、脚本化交互逻辑,既限制了创作想象空间,又需要投入海量开发资源。世界模型带来范式革新,催生生成式游戏系统 :这类系统可自主生成全新游戏内容、动态适配玩家行为逻辑,实现传统编程方案无法达成的涌现式游玩体验(游戏策划解放了?)。
当前相关研究,已明确世界模型在游戏领域应用的三大核心能力维度:
(1)交互性
对用户输入做出合理响应,是游戏世界模型的核心基础要求。GameNGen 搭建全神经网络游戏引擎,可实现复杂环境实时交互,以 20 帧每秒的帧率运行,同时保障长时长对局内游戏逻辑稳定连贯。与之类似,GameGen-X 设计专属模块,接入游戏多模态控制信号,在视频生成领域首次统一角色交互逻辑与场景内容调控能力。Matrix-Game 进一步升级相关技术,训练参数量超 170 亿的大模型,依托精细化键鼠动作标注,实现对角色行为、相机视角运动的精准可控。
(2)时序一致性
在长时序画面中保持游戏状态逻辑统一,是生成式模型面临的重大难题。当前研究同时解决两类一致性问题:数值一致性 (保障分数变动、量化数值等游戏机制逻辑准确)、空间一致性 (避免场景跳转出现违和断层)。
MineWorld 采用视觉 - 动作自回归 Transformer 架构,同步学习游戏状态深度表征、动作 - 状态关联规律,解决时序一致性问题。模型并行解码算法,可在实时生成画面的同时,保障超长游戏流程的时序逻辑连贯。
WHAM(世界与人类动作模型)进一步优化该能力,可生成多样且逻辑统一的游戏时序画面,同时留存用户自定义修改内容 ------ 该能力被认为是支撑游戏创意开发的关键技术。
(3)跨多样环境泛化能力
适配各类游戏场景与环境的泛化能力 ,是该领域难度最高的核心技术维度。GameFactory 借助场景通用动作控制方案,利用预训练视频扩散模型的开放域生成先验知识,突破固定风格与场景限制,从零创造全新游戏。
近期相关研究进一步构建「生成式无限游戏」,彻底突破传统有限、硬编码游戏系统的局限。该方案采用专用蒸馏大语言模型动态生成游戏玩法规则 ,搭配动态区域图像提示适配器保障画面时序统一,让游戏玩法规则可依托底层生成模型自然涌现。
虚拟环境中探索驱动的技术路线,也为泛化能力研究开辟了全新方向:探索智能体完全依靠世界模型生成多样化训练数据,无需额外奖励信号,即可快速适配全新未知环境。
5.2、具身智能
**具身智能的核心目标,是研发能够感知、理解复杂物理世界,并与之高效交互的智能体。**该领域核心难题,是让机器人具备环境动态推理能力,以此支撑稳定、实时的自主决策。
世界模型已成为颠覆性技术范式,精准匹配上述需求,赋予机器人环境感知、未来预测、精准执行的核心能力。相关技术进步,一方面得益于神经网络架构与学习算法的迭代升级,让机器人能够构建隐式表征,精准捕捉外部世界关键特征;另一方面预测模型可推演未来环境状态,跳出静态抽象局限,实现前瞻性、自适应行为决策。
两类能力相互结合,让机器人直接从真实世界交互数据中学习成为可能。表 4 汇总了机器人领域 世界模型构建的核心学习任务,并按照前文三大技术维度完成分类(典型案例如 图 S1 所示)。
Table 4 | 构建机器人世界模型所涉及的核心学习任务:
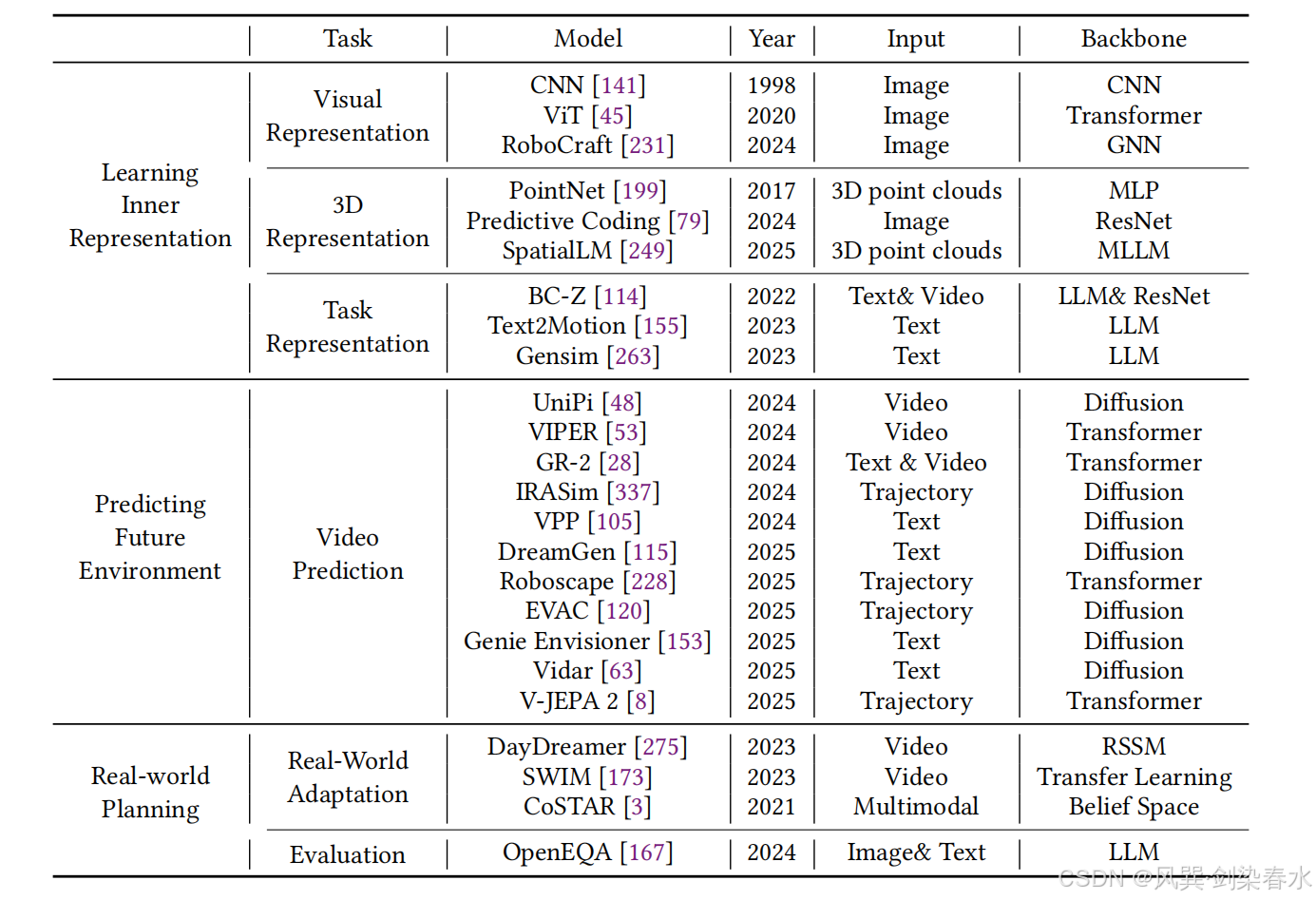
Figure S1 | 机器人世界模型的开发:
5.2.1、隐式表征学习
传统机器人任务(如物体抓取)大多在高度结构化环境中开展,环境关键要素均经过显式建模,机器人无需自主学习、迭代更新对世界的认知规律。但当机器人部署至陌生环境,尤其是关键特征、动态规律 未被预先建模的场景时,原本可顺利完成的任务极易失效,机器人无法对未知环境特征完成泛化适配(泛化问题?)。因此,让机器人学习环境隐式表征,是迈向通用智能的关键第一步。
为帮助机器人认知世界物体,卷积神经网络(CNN)、视觉 Transformer(ViT)等视觉模型,将实体视觉特征整合为统一表征,支撑机器人完成关键任务物体识别。RoboCraft 将视觉观测转换为粒子特征,通过图神经网络捕捉底层系统空间结构(将视觉观测信息(如图像中的物体、表面、关键点等)离散化为一组有限的、带有物理属性的"粒子"表示,每个粒子都携带位置、速度、材质等特征信息。)。
同时相关研究拓展物理三维空间感知能力 :PointNet 采用非对称函数编码无序三维点云,提取环境空间特征。最新研究将局部探索路径采集的观测信息,聚合为隐空间内全局物理空间表征,助力机器人精准追踪、趋近目标物体。SpatialLM 进一步升级技术方案,将原始三维点云处理为带语义标签的结构化三维场景表征,大幅提升机器人、自动驾驶复杂任务空间推理能力。
伴随大语言模型语义理解能力发展,全新机器人意图感知范式诞生:**先用文本描述任务需求,再通过大模型获取对应文本语义表征。**BC-Z 以语言表征作为任务统一表征,提升机器人多任务泛化性能;Text2Motion 借助大语言模型,将自然语言指令拆解为任务级、动作级双层规划,处理复杂时序物体操作任务。
5.2.2、环境未来状态预测
世界模型是机器人领域研究的前沿核心技术,主要在三大应用方向 实现技术突破:合成数据生成、通过想象未来状态引导动作、用于策略评估的环境仿真。
首先,具身世界模型可生成高质量机器人动作视频 ,扩充真实采集数据集,进而优化下游机器人策略模型训练效果。例如 DreamGen 搭建四阶段技术流水线,生成神经运动轨迹,产出基于视频世界模型的机器人合成数据;该方案显著提升视觉 - 语言 - 动作(VLA)模型 在高接触交互任务中的作业成功率与泛化能力。
Roboscape 在视频生成过程中融入物理规律约束,让合成数据具备更合理的运动逻辑 、更高空间精度,将其加入 VLA 模型训练后,效果提升十分显著。EVAC 通过多层级动作约束机制、光线映射编码技术,生成动态多视角画面,扩充包含各类失败轨迹的多样化训练数据,提升模型泛化性能;同时扩充人工采集轨迹数据,兼具数据生成引擎与模型效果评估工具双重作用。
其次,具身世界模型通过预测未来场景观测结果 ,引导机器人完成动作决策生成。该领域近期核心突破,是利用生成式视频模型(尤其是基于扩散架构、Transformer 架构的模型),直接从视觉数据中隐式学习环境动态规律 。
例如 UniPi 将动作预测任务建模为视频生成问题,以当前环境状态约束扩散模型,可视化推演未来场景变化。与之类似,VIPER 采用预训练自回归 Transformer,依托专家演示视频习得的丰富特征,指导机器人动作输出。GR-2 依托海量互联网视频数据构建稳健先验知识,再针对机器人专项任务微调,精准预测画面内容与动作轨迹。VPP 基于文本指令微调视频生成模型,结合视觉表征约束的逆动力学模型,推导机器人执行动作。Genie Envisioner 依托预训练具身视频生成基础模型,搭配轻量化并行流匹配动作模型,将语言约束下的视觉隐特征,转换为低延迟精细化运动指令。Vidar 搭建两阶段机器人动作预测框架,融合大规模扩散视频预训练与新型掩码逆动力学模型。V-JEPA 2 则在隐空间建模世界状态跳转规律 ,通过模型预测控制(MPC) 完成动作规划:对候选动作轨迹进行大量采样,依靠能量优化筛选最优执行方案。
第三,具身世界模型可作为环境仿真器,用于机器人策略效果评估。IRASim、Roboscape 均以初始画面为起点,完成轨迹到视频的生成任务;二者在世界模型仿真环境、真实物理环境下的策略评估结果高度相关,证明所学世界模型可以精准还原真实世界状态跳转规律。GE-Sim 同样实现该能力,搭建策略与世界模型的闭环交互系统,无需人工手动建模环境,即可完成高扩展性、高灵活性的策略仿真验证。
综上,这类以视觉为核心的生成式世界建模技术,为机器人前瞻性控制与环境仿真奠定了坚实基础,大幅提升机器人未来状态推理能力,优化长周期任务执行效果。
5.2.3、从仿真环境到真实世界迁移
深度强化学习 在机器人领域展现出卓越性能,可支撑机器人完成稳定运动行走、高精度物体操作、鞋带捆绑等高难度复杂自主任务。但该方法极低的样本利用率,严重限制了实际落地效果。例如在真实环境中训练机器人还原魔方,需要耗费等效数万年的仿真训练时长。
因此绝大多数机器人训练均在仿真环境 内完成,并依托分布式训练方案提升迭代效率。但仿真环境与真实物理场景存在固有差异,仿真环境训练完成的策略,直接迁移到实体机器人上极易失效,在陌生复杂场景中问题尤为突出。
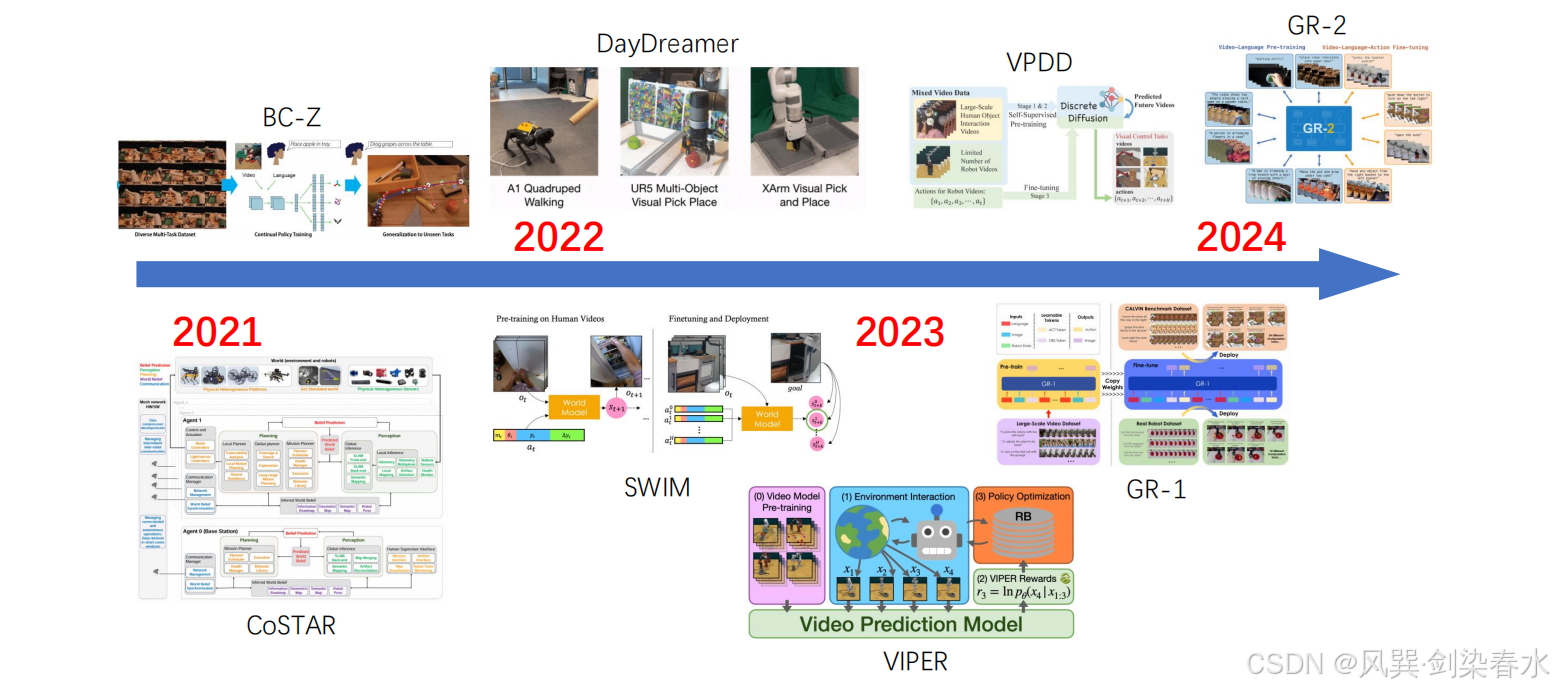
该领域近期核心突破发现:**世界模型通过学习真实世界通用动力学表征,可以有效弥合仿真 - 现实域间差距。**例如 NeBula 构建结构化信念空间,让机器人在多样机身形态、非结构化环境中快速推理、自适应适配任务。DayDreamer 进一步验证通用世界模型能力,让机器人仅用数小时即可在真实环境中自主学习运动控制,大幅降低对海量仿真训练的依赖。除此之外,SWIM 结合人类视频监督学习与少量真实环境微调,仅依靠不到 30 分钟的真实交互数据,就实现机器人任务泛化。
上述研究均证明:世界模型构建面向真实物理世界的稳健内部表征,大幅缩小仿真与现实之间的性能鸿沟,助力机器人实现快速环境适配与跨场景泛化。
5.3、城市智能
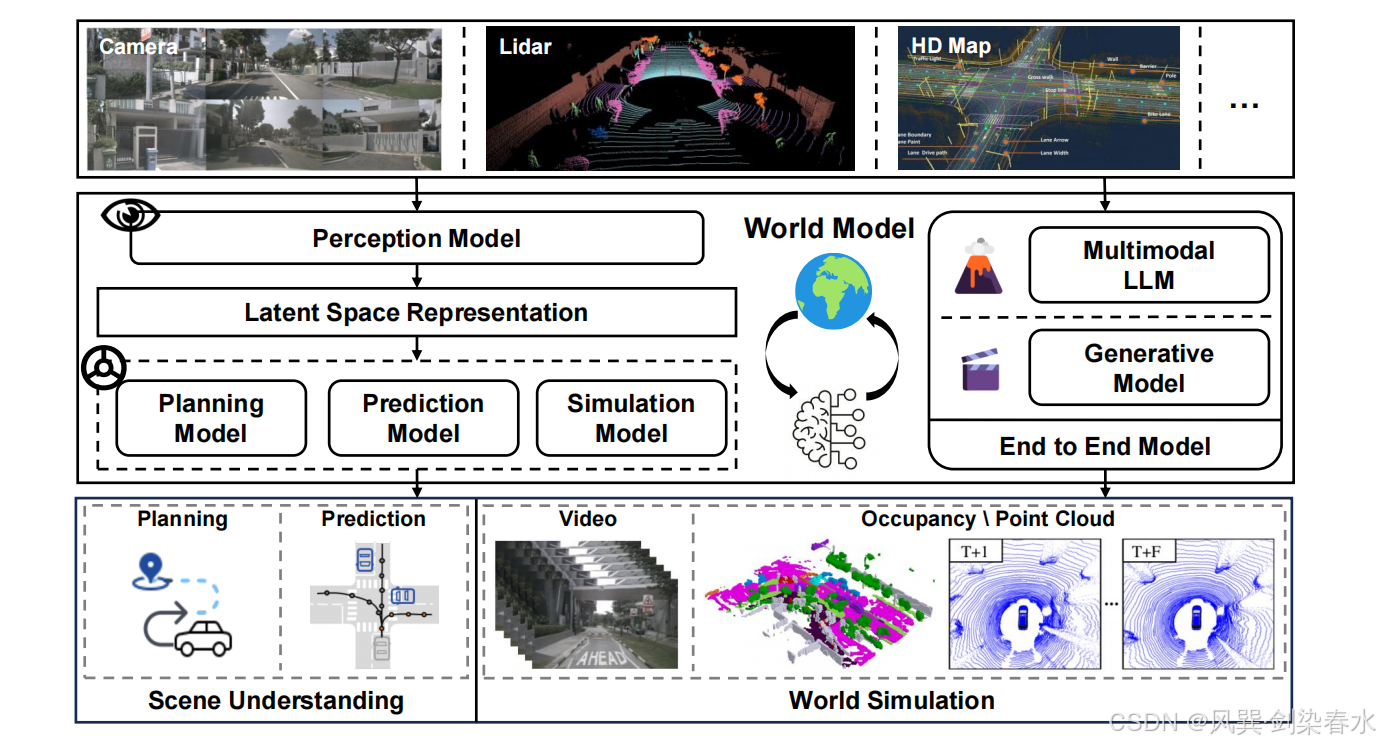
5.3.1、自动驾驶
近年来,随着视觉生成模型、多模态大语言模型技术飞速发展,世界模型在自动驾驶领域受到越来越广泛的关注。现代自动驾驶完整技术流程,通常分为感知、预测、规划、控制四大核心模块。其中感知与预测环节,对应驾驶场景理解任务,本质是学习车辆外部环境的隐式表征 。与此同时,相关综述研究指出,端到端世界仿真器 正在快速兴起:这类模型依托图像、点云、轨迹、文本等多模态输入,学习仿真高还原度真实驾驶场景,推演环境未来状态,支撑下游路径规划、行为决策等任务。
上述两大技术方向,与本文前文对世界模型的分类体系高度契合;下文将详细阐述世界模型在自动驾驶场景下的具体应用与技术发展成果。
(1)隐式表征学习
自动驾驶车辆通常依靠摄像头、毫米波雷达、激光雷达感知真实路况,通过图像、视频、点云数据采集环境信息。传统早期决策范式中,模型直接输入感知数据,输出车辆运动规划结果(缺少对未来状态的想象与模拟)。与之不同,人类驾驶员驾驶车辆时,会先观测、预判其他交通参与者当前与未来状态,再制定自身驾驶策略。因此,**依托感知数据学习世界隐式表征、预测周边环境未来状态,是提升自动驾驶决策可靠性的核心环节。**本文将该过程定义为自动驾驶车辆在隐空间内构建世界模型。
如 图 6 左半部分所示,在多模态大模型、端到端自动驾驶技术兴起之前,自动驾驶感知、预测任务分属独立模块,各模块使用专属数据集、针对单一任务单独训练。感知模块 处理图像、点云等多源数据,完成目标检测、路网分割等任务,将真实路况映射至抽象几何空间;预测模块 则在该几何空间内,推演周边环境未来状态,包括各类交通参与者的运动轨迹与行为变化。(分工明确,各司其职)
Figure 6 | 世界模型在自动驾驶中的应用:
感知数据处理技术与深度学习迭代深度绑定,相关演进历程如 表 5 所示。2017 年问世的 PointNet,是首个采用深度学习算法处理三维点云数据 的模型。随着卷积神经网络技术发展,YOLOP、MultiNet 等基于图像的感知方案快速成熟,在驾驶场景理解各类任务中取得优异效果。
近年来 Transformer 架构在自然语言处理领域大放异彩,也同步被应用于图像场景理解任务。BEVFormer 依靠注意力机制融合多视角相机图像,构建鸟瞰视角抽象几何空间,在目标检测等多项任务中达到行业顶尖性能。除此之外,Transfusion 通过交叉注意力机制融合激光雷达与相机数据,进一步提升感知精度。(注意力机制我的神)在感知结果基础上,循环神经网络(RNN)、卷积神经网络(CNN)、Transformer 等模型被广泛用于编码历史场景信息,预测交通参与者未来行为轨迹。
随着多模态大语言模型快速兴起与普及,大量研究尝试将这类模型通用场景理解能力落地自动驾驶领域。TOKEN 将完整交通场景拆解为物体层级语义知识,借助大模型推理能力,解决长尾场景轨迹预测与路径规划难题;OmniDrive 搭建大语言模型驱动智能体,依托视觉问答技术,覆盖场景描述、反事实逻辑推理、行车决策等多类自动驾驶任务。(从"感知与预测"跃升为"理解、推理与可解释决策")
Table 5 | 现有场景理解与世界模拟研究的比较:
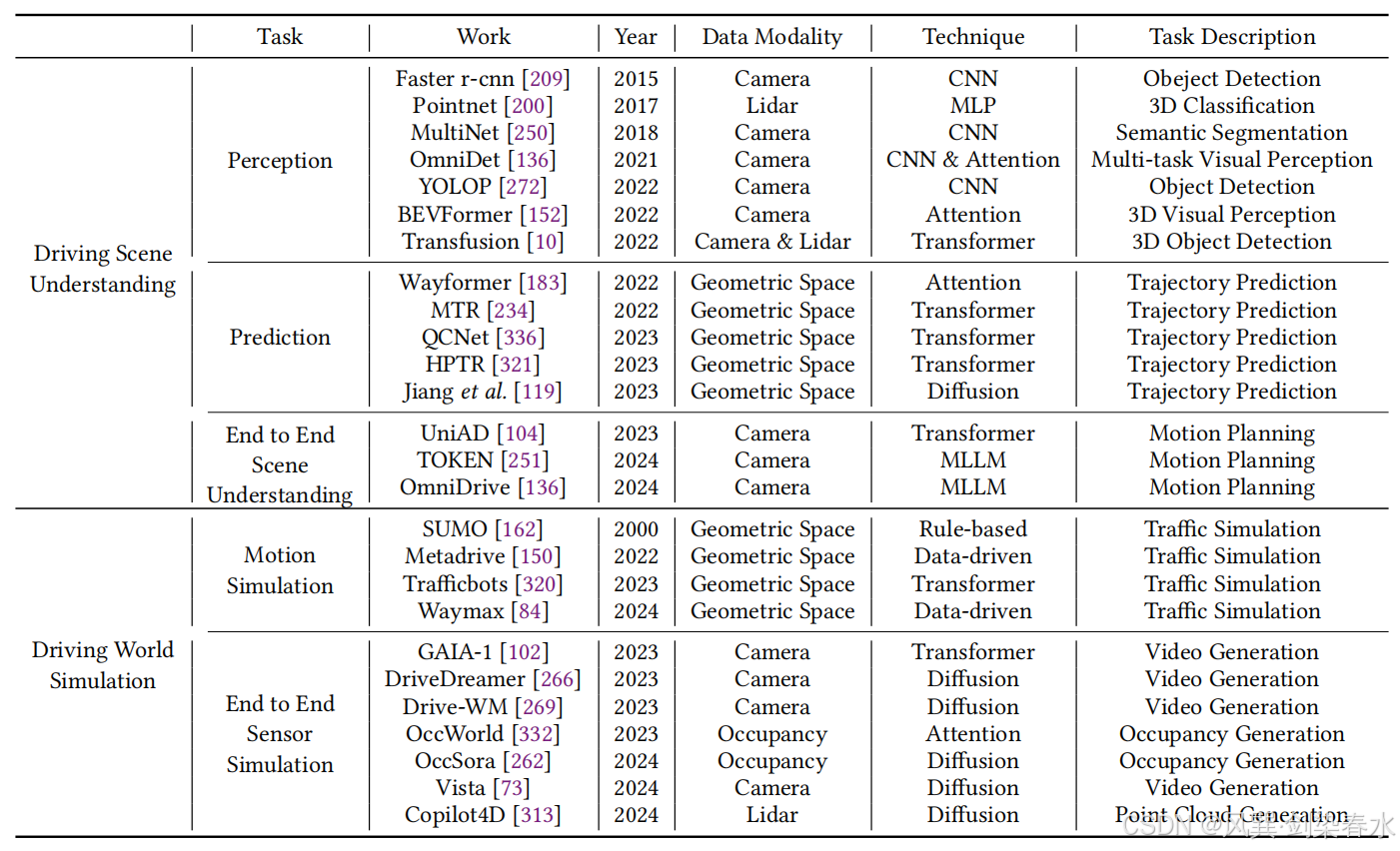
(2)世界仿真器
如 表 5 所示,在多模态大模型、视觉生成模型兴起之前,交通场景仿真大多在几何空间 内完成。这类仿真依赖的场景数据,一般由自动驾驶车辆感知模块采集、或是人工搭建而成;模型以几何轨迹形式推演场景未来状态,还需要额外建模与渲染,才能输出适配车辆感知的可用结果。多模块级联架构 极易造成信息损失,同时抬高仿真复杂度,大幅提升场景调控难度;此外高保真场景渲染需要消耗海量算力,严重限制虚拟交通场景的生成效率。(传统几何仿真又慢又复杂)
基于扩散视频生成模型构建世界模型,有效解决了上述痛点。该类模型在大规模交通场景数据集上训练,可直接生成高度贴合真实路况的相机感知数据。同时扩散模型原生可控性,搭配 CLIP 等图文对齐技术,让使用者可以便捷调控场景生成逻辑 。(视频生成模型可以直接"脑补"出逼真的未来路况视频)
GAIA-1、DriveDreamer 系列是首批采用该方案构建自动驾驶世界模型的代表性工作。在此基础上,Drive-WM 新增规划任务闭环控制能力,Vista 则重点优化画面分辨率、延长时序预测时长。
除视频空间未来状态预测方案外,大量研究探索了多类型车辆感知数据建模路径:OccWorld、OccSora 通过预测三维占据网格,推演世界未来状态;Copilot4D 依托雷达点云时序变化构建世界模型。相较于视频数据,这类特征可以更精准还原交通场景空间几何特性。
5.3.2、自主物流
本节介绍世界模型在城市场景自主物流领域的落地应用,主要覆盖两大方向:微型移动物流车辆、低空飞行器 。两类场景均从环境理解、未来预测两个维度梳理代表性研究,详细内容如 表 6 所示。
Table 6 | 世界模型在自主物流与城市分析中的应用:
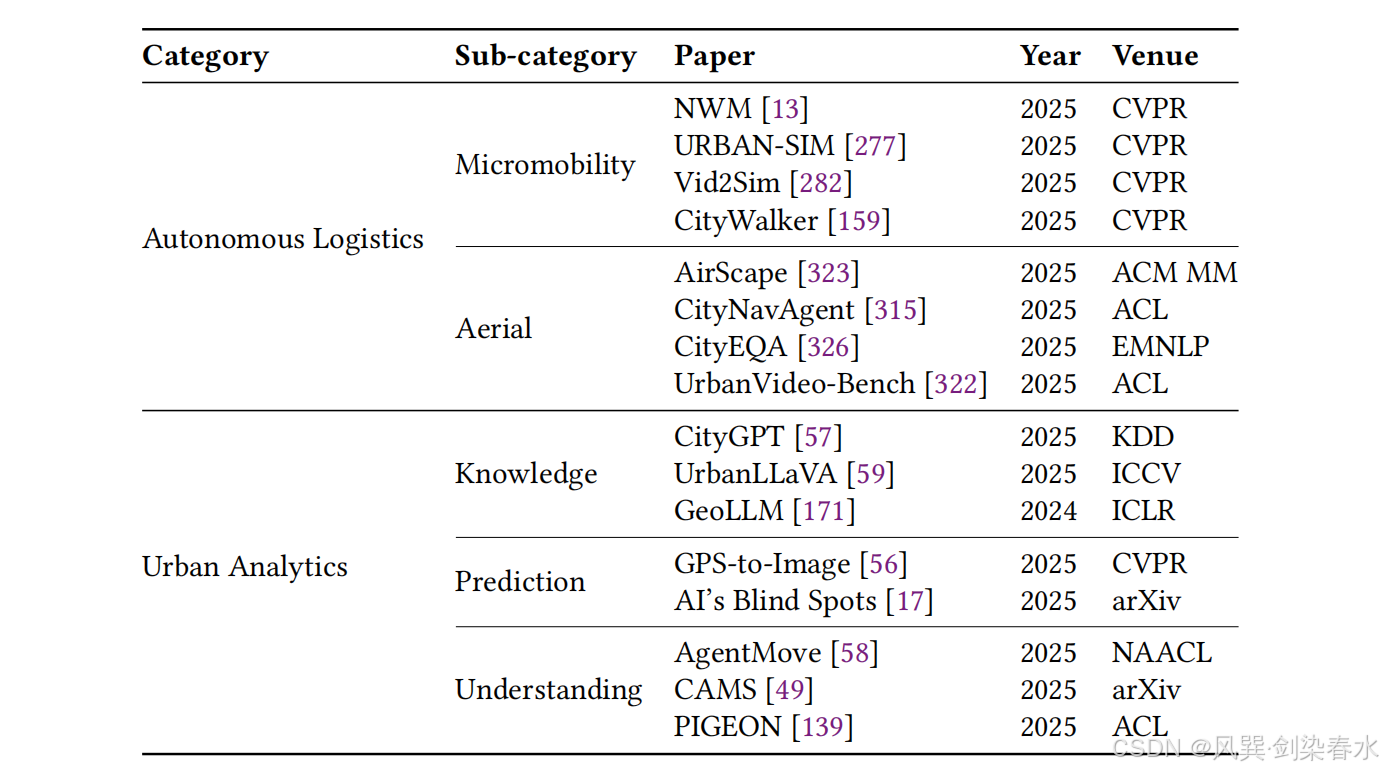
微型移动物流车辆 ,是自动驾驶技术向具身智能场景的延伸,需要应对更复杂周边环境与人机交互场景,核心任务为自主导航 :通过感知理解周边世界,实现更安全、高效的移动与交互行为。
环境理解层面: Vid2Sim、CityWalker 依托海量互联网公开视频数据,学习多样化环境特征与动态交互场景规律,以此训练机器人导航策略,保障模型强大泛化能力与行为可控性。
未来预测层面: 行业存在两类主流技术范式。第一种是搭建高保真物理仿真环境,生成丰富多样场景 ;机器人在虚拟环境中完成大规模训练后,再迁移部署至真实世界。第二种是基于视频生成模型,构建可交互、可控制的世界模型;模型根据机器人动作、行驶轨迹,预判后续可能遇到的未来场景,提升机器人跨场景通用导航能力。
针对低空飞行器 场景,当前绝大多数研究聚焦环境理解相关应用,重点覆盖场景感知、自主导航 方向;而环境未来预测相关技术仍处于初步探索阶段。
环境理解领域的经典范式,是从图像、视频数据中解析当前城市场景与核心要素,为后续导航等下游任务提供完备支撑。对多样复杂城市场景的深度理解,依赖充足的城市环境先验知识,尤其是大语言模型所蕴含的海量世界常识与通用语义知识。
场景生成领域中,AirScape 是首个面向低空飞行器的专用世界模型。该模型可根据飞行器飞行行为,预测未来场景变化,同时严格保障物理规律一致性、时空逻辑连贯性,为后续低空飞行器高效训练、复杂任务落地,提供全新技术路径与仿真环境。
5.3.3、城市时空分析
本节介绍世界模型在城市智能分析领域的相关应用。基于 3.2 节所述结论 ------ **大语言模型已习得完备的世界地理常识知识,**下文将从环境理解、未来预测两个维度梳理相关研究,汇总内容详见 表 6 。
环境理解层面: 一方面面向城市环境本身,UrbanLLaVA 等多模态大语言模型,依托模型内嵌海量世界常识,完成城市场景识别、全域场景理解等高泛化任务 61。另一方面面向环境内人类行为,AgentMove、CAMS 借助模型内置城市空间地理知识 57,建模人群出行移动规律;同时 PIGEON 依托大语言模型通用常识,解析居民日常需求与对应行为模式,实现低频小众场景下精准行为理解与预测。
未来预测层面: GPS-to-Image 尝试通过 GPS 定位信号,约束生成图像的场景风格与内容特征,验证了模型学习地理位置与城市风貌关联规律的可行性。但相关研究 17 同时指出,现有图像生成模型,在精准区分不同地域文化风貌、场景特色特征方面,仍存在较大优化空间。
总体而言,世界模型在城市时空分析领域的落地应用仍较为有限(方向来了),具备广阔的未来发展与拓展潜力。
5.4、社会智能
社会智能是指一个社会感知环境、推演未来、协同行动以实现共同目标的集体能力,源于个体、机构与环境之间的相互作用。在计算环境中实现社会智能的有效途径是构建社会仿真体 ,即由各类智能体组成的虚拟社会计算系统,这些智能体能够表现出贴近真实人类的复杂行为。传统社会仿真系统通常采用两种方式构建:
(1)专家定义规则: 将领域知识编码为明确的行为规范;
(2)强化学习: 智能体在仿真环境中通过试错优化策略;
这些方法在特定场景下虽有效,但往往导致仿真动态过程过于简化,或可解释性不足。大语言模型的出现为构建更丰富、更可信的社会仿真体提供了变革性基础,既能够复现程式化的社会事实 ,也能生成可信的社会行为预测结果。
在本综述中,从两个互补的视角探讨世界模型在社会智能框架中的应用:
(1)社会仿真体作为显式世界模型: 它是现实社会的镜像,为社会智能的涌现提供结构化环境;
(2)智能体在仿真体中构建隐式世界模型: 智能体通过交互学习形成外部环境的内部表征,以此指导自身决策与社会行为;
这两个视角 ------反映现实社会与理解外部世界,构成了下文小节的核心框架。相关代表性研究汇总如 表 7 所示。
**Table 7 | 从两个视角审视 LLM 驱动的社会模拟模型的代表性工作:**反映现实社会与理解外部世界;
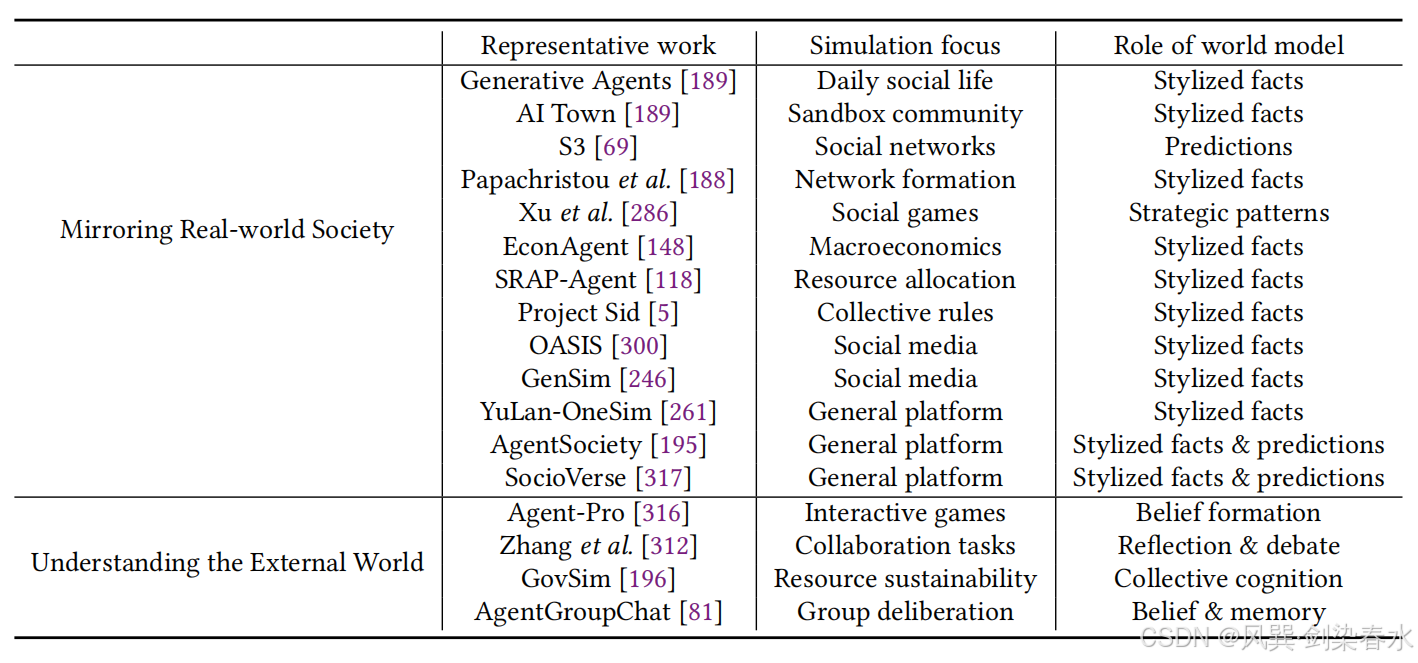
5.4.1、构建反映现实社会的社会仿真体
随着大语言模型智能体技术快速发展,构建高逼真度社会仿真系统的可行性大幅提升。AI Town 是该领域代表性工作:这是一个沙盒环境,其中的生成式智能体可表现出高度可信的个体行为,并在群体层面涌现出与真实社区高度相似的社会动态特征。这类系统验证了社会仿真体 作为显式世界模型的核心价值 ------ 它为观测与研究社会智能(包括集体感知、集体推理与协同行动)提供了可控实验环境。
在社交网络场景中,S3 验证了 LLM 智能体能够复现真实信息传播规律,捕捉公共事件发展的动态特征。Papachristou 等人的研究进一步指出,智能体群体可自发形成网络结构,完美复刻人类社会的自组织特性。这类工作证明了社会仿真体能够以数字化形式,还原社会智能的自适应与信息交互特性。
除社交网络外,LLM 智能体还展现出对战略交互中高阶推理行为 的建模能力。Xu 等人的研究表明,在狼人杀这类社交推理游戏中,智能体可表现出欺骗、对抗等复杂策略行为,反映了社会智能中的认知与竞争维度(人机狼人杀)。
在经济学与资源分配领域,基于 LLM 的智能体实现了从微观个体推理到宏观结果的自下而上建模:EconAgent 复现了个体决策行为所涌现的宏观经济趋势 ;SRAP-Agent 用于评估资源分配政策 效果;Project Sid 则探索了群体对税收规则的集体响应模式 。这些案例展示了社会智能如何在经济系统中以聚合模式呈现(实现经济决策,又要失业了)。
5.4.2、社会仿真体中智能体对外部世界的理解
除了在宏观层面复刻现实社会特征外,社会仿真体也为研究智能体如何形成环境内部表征提供了实验场景。大语言模型智能体通过交互积累经验、将经验存储为记忆,并将其转化为隐式世界模型。这些模型构成了社会智能的认知基础,使智能体不仅能够回顾过往交互,还能在决策过程中对其他智能体与外部环境进行推理。
多项研究展示了隐性世界模型在实际应用中的形成机制:Agent-Pro 将交互历史转化为结构化信念,以此指导后续决策与策略更新。这些信念反映了智能体对其他个体的理解,与 3.2 节中讨论的心智理论能力直接相关。Zhang 等人的研究进一步拓展了这一方向,引入社会心理学中的反思与辩论机制,提升多智能体任务中的协作效率。
在群体层面:GovSim 研究了由 LLM 智能体组成的社会中,可持续合作行为 能否自发涌现。在该框架中,智能体通过对话收集公共资源与同伴行为策略信息,形成对外部环境的高阶认知(好科幻啊)。这些认知本质上是支撑群体级社会智能的世界模型隐式表征。Interactive Group Chat 探索了智能体在遗产纠纷、法庭辩论等场景中的类人审议过程。智能体依托记忆与推理,生成与真实人类高度相似的交互策略与社会动态。
5.5、世界模型的功能
世界模型的核心设计目标,是接收外部指令或动作,建模环境的动态状态转移过程 。其功能可划分为两大核心角色:云端环境模拟器与端侧智能体大脑。
云端世界模型,通常以视频生成系统 的形式呈现,依托文本或动作轨迹生成大规模高质量视频数据。这些生成数据可作为数据引擎,扩充真实世界数据,用于训练策略模型(如 VLA、VLN 模型)。同时,云端世界模型可作为强化学习的虚拟环境 ,与智能体交互以支持虚拟场景下的进化学习。这一能力大幅降低了真实世界交互的成本与风险,在自动驾驶等领域尤为关键。此外,云端世界模型还可作为策略评估器,通过与策略模型交互输出观测序列,实现对策略模型性能的评估。
端侧世界模型,作为端侧智能体大脑时,通常无需直接生成底层视觉画面,而是在隐空间内压缩世界状态信息 。例如 V-JEPA 2 在隐空间中训练世界模型,通过模型预测控制(MPC)实现设备端的动作规划。
此外也可采用两阶段方案:世界模型先处理视觉观测信息,再将其转换为可执行动作指令。
云端: 生成可视化的视频环境,用于训练与评估。
端侧: 压缩世界状态到隐空间,用于实时决策与执行。
6、开放问题与未来方向
近期超写实生成式 AI 的快速发展,尤其是以 Sora 为代表的多模态大模型,使世界模型的研究受到了广泛关注。尽管相关技术正处于快速创新阶段,但仍有许多关键的开放性问题亟待解决。(又一个 AI 热点呀)
6.1、物理规则与反事实仿真
世界模型的核心目标之一,是**捕捉环境的因果结构,尤其是其底层物理规则,从而能够推理出数据分布之外的反事实场景。**这种能力对于处理罕见但关键的任务场景(如自动驾驶中的极端案例)、缩小仿真与现实之间的差距至关重要。
近期的研究进展也引出了一个关键问题:大规模、纯数据驱动的生成模型,能否仅从原始视觉数据中习得这些物理规则? 尽管基于 Transformer 和扩散模型的视频生成器(如 Sora)能够生成极具真实感的序列,但研究发现它们仍持续存在物理规律违背问题,例如重力、流体或热动力学表现不准确。
显式嵌入物理规则 的混合方法正成为富有前景的解决方案:Genesis 展示了这一方向:它将快速照片级渲染与重构的通用物理核心相结合,实现了基于第一性原理仿真的语言条件数据生成。PhysGen 在图像到视频层面采用了类似的思路:将刚体模拟器与扩散优化器结合,能够从单张图像生成可控且物理上合理的运动。软约束混合方法通过学习时先验来强制执行物理规则。物理信息扩散(physics-informed diffusion)引入了基于偏微分方程(PDE)的残差损失函数,在保留生成灵活性的同时,对违背控制方程的行为进行惩罚。这类 "硬规则 + 软约束" 的设计在不牺牲真实感的前提下,提升了模型的可控性与可解释性。
相关诊断性研究也印证了这类混合方法的必要性:Kang 等人的研究表明,随着扩散视频模型规模扩大,其在分布内数据上的保真度可达到完美水平,但在分布外数据或组合性测试中则表现失效,这说明模型是基于 "案例" 而非基于规则进行泛化。Motamed 等人基于 Physics-IQ 基准测试得出了相似结论:当前视频生成模型虽能实现逼真的视觉效果,但在需要理解光学、流体动力学或磁学规律的任务中表现普遍不佳。
与此同时,基于第一性原理的基准测试已开始将 "物理保真度" 量化为可评估维度:T2VPhysBench 评估模型对核心物理定律(包括牛顿力学与守恒定律)的遵循情况,并记录了主流文本到视频系统中存在的系统性违背问题;VBench-2.0 则明确将物理规律与常识作为视频生成任务的标准评估维度。
"第一性原理" 指的是最基本的物理定律和自然规则,例如牛顿力学(惯性、作用力与反作用力)、能量守恒、动量守恒、光学折射、流体动力学等,而不是依赖数据中的统计规律或案例匹配。
综上,现有证据表明,仅靠数据驱动的模型扩展,不足以让模型习得鲁棒的物理规律 。整合显式模拟器,或以其他方式引入物理先验,仍是构建可泛化至未知反事实场景、同时具备可解释性与透明度的世界模型的重要研究方向(大力奇迹不符合物理规律啊)。
6.2、丰富世界模型的社会维度
仅模拟物理环境要素,尚不足以构建先进的世界模型 ------ 在许多关键场景中,人类行为与社会交互同样发挥着决定性作用。例如,在构建城市场景世界模型时,居民的行为模式尤为关键。
现有研究表明,大语言模型具备的类人常识推理能力,为通过生成式智能体模拟真实人类行为提供了独特契机。然而,设计能够模拟真实、全面的人类行为与社会交互的自主智能体,仍是一个悬而未决的难题。
近期研究指出,人类行为模式与认知过程的相关理论,可为智能体工作流的设计提供指导,进而提升大语言模型对人类行为的模拟能力,这是未来研究的重要方向。
此外,对生成人类行为真实性的评估,目前仍高度依赖人工主观判断,难以扩展至大规模世界模型的评估场景。因此,开发可靠、可扩展的评估方案 ,将是丰富世界模型社会维度的另一重要研究方向(设计标准)。
6.3、基准测试
对世界模型进行基准测试既必要又充满挑战。由于学界追求的目标各异 (学习内部表征 vs. 预测未来世界)、技术路线多样 (如大语言模型智能体、视频扩散模型),且应用场景广泛 (自动驾驶、机器人、社会仿真),目前尚未形成统一的标准任务或评估指标(各个目标有各个目标的指标)。尽管如此,近期多项研究表明,精心设计的测试平台能够揭示当前模型无法成为可靠世界模拟器的关键短板,相关基准汇总如 表 8 所示。
Table 8 | 用于评估世界模型的代表性基准:
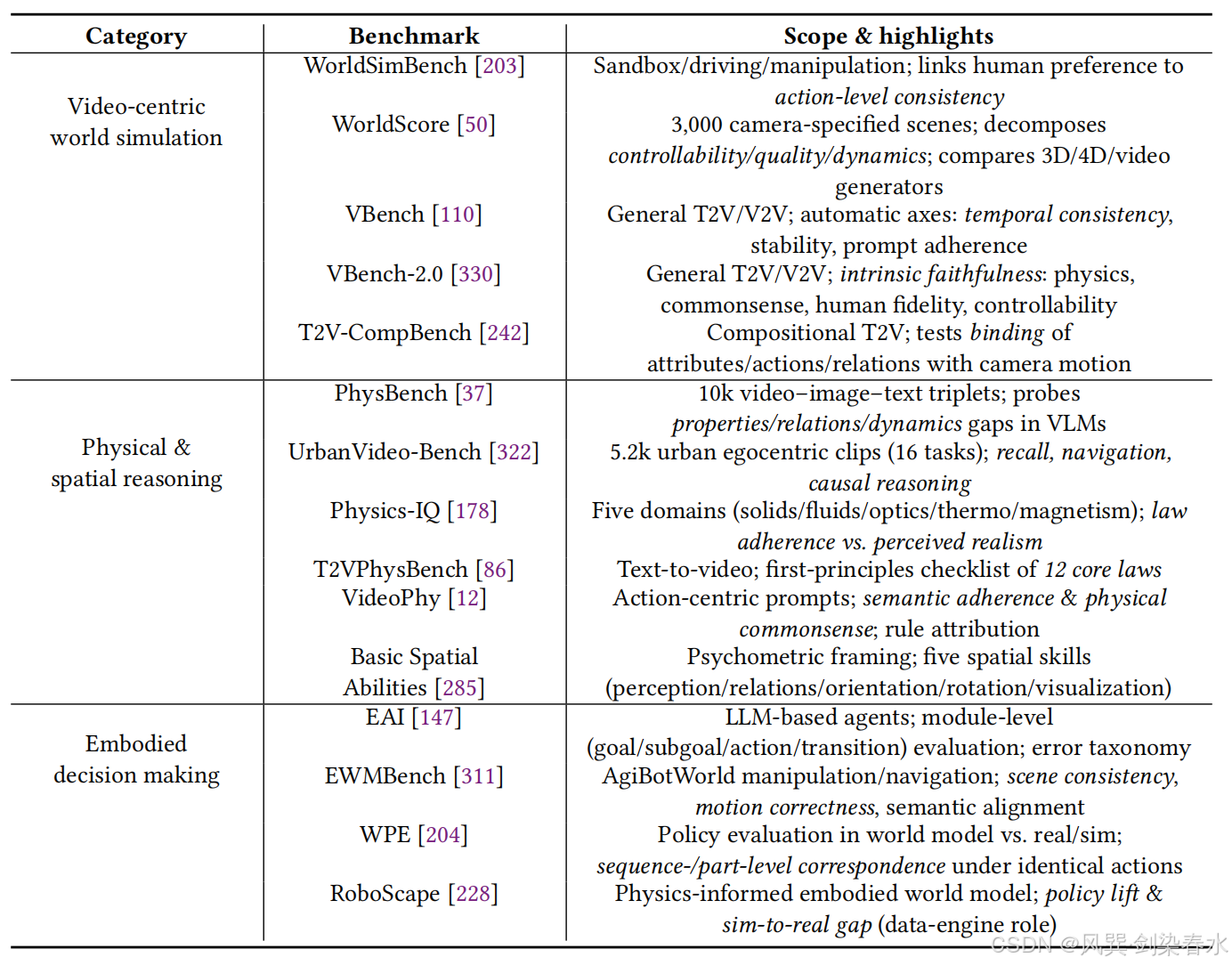
(1)以视频为中心的世界仿真
WorldSimBench 将感知质量与可控性联系起来,通过结合人类偏好与沙盒、驾驶、操控场景下的动作一致性进行评估;
WorldScore 在此基础上补充了相机指定协议,将性能分解为可控性、视觉质量和动态特性三大维度,在超过 3000 个场景中实现了 3D/4D 生成器与视频生成器之间的直接对比;
VBench 实现了对时间一致性、主体 / 背景稳定性、提示词遵循度等指标的自动评估;
VBench-2.0 则进一步将物理规则、常识、人类行为保真度、可控性等 "内在真实性" 指标独立出来,区分了 "看起来真实" 与 "行为像真实世界" 的不同要求;
T2V-CompBench 则通过基于多模态大语言模型(MLLM)、目标检测与跟踪的指标,测试属性、动作、关系和镜头运动之间的绑定关系,完成组合性压力测试。
(2)物理与空间推理能力
除了视觉外观之外,世界模型还必须遵循物理定律 ,并具备空间推理能力 。
PhysBench(含 1 万组视频 - 图像 - 文本三元组)揭示了当前多模态大语言模型(VLMs)在物体属性、关系和动态理解上存在系统性缺陷;
UrbanVideo-Bench(含 5200 个无人机视频片段、16 类任务)则诊断了模型在长时自我中心流数据中的记忆召回、导航与因果推理能力不足。
以物理定律为核心 的测试套件进一步细化了这一问题:
Physics-IQ 从固体 / 流体力学、光学、热力学、磁学五大领域进行评估,发现模型对物理规律的理解与视觉真实感之间基本脱钩(有待进一步探索);
T2VPhysBench 为文本到视频系统提供了包含 12 条核心定律的第一性原理检查清单。
在生成能力方面,VideoPhy 量化了模型在以动作中心的提示词下的语义一致性和物理常识遵循度,并将错误归因于具体规则(如支撑、惯性、连续性)。另一项基于心理测量学的研究则锚定了五大基础空间能力 ------ 感知、关系、方向、心理旋转、可视化,揭示了 13 个多模态大语言模型在几何 / 旋转任务上的薄弱环节,并提供了可校准的任务用于追踪模型进展。
(3)具身决策能力
当世界模型嵌入控制回路时,整体成功率往往掩盖了过程性错误(哈哈哈,过程错了结果没问题)。
Embodied Agent Interface (EAI) 标准化了基于大语言模型的四大模块(目标理解、子目标分解、动作序列规划、状态转移建模),并提供了细粒度的错误分类 (如幻觉、 示能性(这个东西能用来做什么)、规划错误);
EWMBench 使用 AgiBot World 数据,从场景一致性、运动正确性(符合物理 / 任务的轨迹)和语义对齐三个维度测试具身世界模型,明确地将视频合理性与动作的前置条件和示能性关联起来;
以角色为中心的视角将模型作为环境进行评估:WPE 比较了在相同动作序列下,模型生成视频与真实视频 / 模拟器的推演结果(从某个初始状态出发,按照给定的动作序列或策略逐步执行,得到的一整条时间序列数据,通常包括每个时间步的状态、动作、奖励等),报告序列级和部分级的对应关系;
而 RoboScape 这类基于物理的世界模型,则通过测量在模型生成数据上训练时的策略提升和仿真到现实的差距,评估了模型作为数据引擎的作用。
尽管取得了这些进展,世界模型的基准测试仍是一项开放挑战 。未来的工作应聚焦于构建更多样、更真实的基准,以严格测试模型的泛化能力。此外,标准化评估协议 对于提升跨环境下的可比性和鲁棒性评估至关重要(我要制定这江湖的规则!)。
6.4、具身智能视角下的仿真与现实鸿沟弥合
世界模型一直被视为实现具身智能的关键一步。它可作为功能强大的仿真器,构建环境的全面要素并建模其间的真实关系。这类环境能支持具身智能体通过与仿真环境的交互进行学习,从而降低对监督数据的依赖。
为实现这一目标,提升生成式 AI 模型的多模态、多任务与三维能力,已成为开发面向具身智能体的通用世界模型的重要研究课题。此外,缩小仿真与现实之间的差距 一直是具身环境仿真器的长期研究难题,因此将训练好的具身智能从仿真环境迁移到物理世界至关重要。收集更多细粒度的感官数据 也是实现这一目标的关键步骤,这可通过具身智能体的交互界面来实现。因此,一个极具前景的未来研究方向是构建自强化循环 ,以充分利用生成式世界模型与具身智能体之间的协同效应(生成式世界模型与具身智能体之间形成的一个相互促进、持续进化的正向反馈回路)。
世界模型 → 具身智能体: 世界模型作为仿真器,生成丰富、逼真的虚拟环境。具身智能体在其中进行大量试错学习,快速积累经验,提升决策和行动能力,而无需依赖昂贵的真实世界数据。
具身智能体 →世界模型: 智能体在真实世界交互中收集到细粒度、多模态的感官数据(如触觉、力觉、高精视觉),这些数据反馈给世界模型,用于校准和优化模型参数,缩小仿真与现实的差距。改进后的世界模型能生成更贴近真实物理规律的场景。
6.5、仿真效率
对众多应用场景而言,保障世界模型的高仿真效率至关重要。例如,帧率是训练复杂无人机操控 AI 的关键指标。目前大多数大型生成式 AI 所采用的 Transformer 架构,因其自回归特性(每次仅能生成一个 token),对高速仿真构成了巨大挑战(为什么不使用 mamba 架构呢)。
为加速大型生成式模型的推理,学界已提出多种策略:
(1)模型层面: 融合大小生成式模型、对大模型进行蒸馏;
(2)系统层面: 构建可对大语言模型请求进行优化调度的仿真平台;
传统物理仿真器在处理大规模复杂系统时,也面临计算成本高昂的问题。已有研究表明,图神经网络等深度学习模型可用于高效近似物理系统。因此,探索小型深度学习模型与大型生成式 AI 模型之间的协同效应 ,是一个重要研究方向。此外,为实现显著的速度提升,还需要从底层硬件、编程平台到 AI 模型的全栈优化。
6.6、伦理与安全考量
(1)数据隐私
当前利用大型生成式 AI 构建世界模型的趋势,引发了严重的隐私风险担忧 ,这主要源于其庞大且往往不透明的训练数据。大量研究聚焦于评估大语言模型等生成式 AI 推断隐私信息的风险,这在视频生成模型的场景中尤为敏感。为符合 GDPR 等隐私法规,提高生成式 AI 全生命周期的透明度至关重要,这有助于公众了解这些 AI 模型如何收集、存储和使用数据(模型有风险)。
(2)不安全场景的模拟
生成式 AI 极强的智能能力,使得保障其安全访问成为首要任务。此前针对大语言模型的研究发现,通过对抗性提示词可诱导其生成不安全内容。世界模型被不当使用的风险可能更大:恶意用户可能利用此类技术模拟有害场景,降低策划非法和不道德活动的成本。因此,保障世界模型的安全使用是未来的重要研究方向(用户有问题)。
(3)问责机制
生成超逼真文本、图像和视频的能力,引发了传播错误信息和虚假信息等严重社会问题。例如,深度伪造技术的出现导致了大规模滥用,对社会、经济和政治系统造成了广泛的负面影响。因此,检测 AI 生成内容已成为应对这些风险的关键研究问题。然而,随着生成式 AI 的进步,这一挑战正变得愈发严峻;当能够生成连贯、多维度输出的世界模型出现后,情况将更为棘手。水印等技术有助于提升世界模型使用的可追溯性与问责性。我们需要更多的研究关注,以及法律层面的解决方案,来完善世界模型使用的问责机制(以假乱真的图像生成,有图有真相的魔法失灵了)。
7、总结
理解世界与预测未来 ,一直是开发人工生成智能的科学家们的长期目标,这凸显了构建跨领域世界模型的重要意义。本文首次对世界模型进行了全面综述,系统探讨了其两大核心功能:对外部世界的隐式表征与未来预测。
本文对这两大核心功能的现有研究进行了详尽总结,重点关注了:
(1)用于决策的世界模型
(2)模型习得的世界知识
(3)作为视频生成器的世界模型
(4)作为具身环境的世界模型
此外,本文回顾了世界模型在关键应用领域的进展,包括生成式游戏、机器人技术、自动驾驶与社会仿真体。最后,针对这一快速发展领域中尚未解决的挑战,本文指出了开放问题并提出了富有前景的研究方向,以期推动这一新兴领域的进一步探索。
完结撒花(●'◡'●)