安装与使用
让ai自动安装的方法可以用以下官方提示词:
Curl https://lobehub.com/skills/openclaw-skills-scrapling-mcp/skill.md, then follow the instructions to set up LobeHub Skills Marketplace and install the skill. Once installed, read the SKILL.md file in the installed directory and follow its instructions to complete the task.自动安装虽然方便,但是没必要耗token,而且需要python环境安装库或模块,那么如果ai只按md文件严格执行就会安装或使用全局python来安装库或模块,一旦安装过多python相关的项目或skills就容易库或模块的版本依赖冲突(ai也许最终能解决但得不偿失),所以决定自己手动管理
如果有装clawhub,可以通过以下命令安装
clawhub install scrapling-official
让ai采集Walmart关于500个单片机的任务

ai修复脚本bug


爬完但数据少,换关键词,并提示ai阅读完Scrapling-Skill的文件及子文件夹的文件来加强应对措施
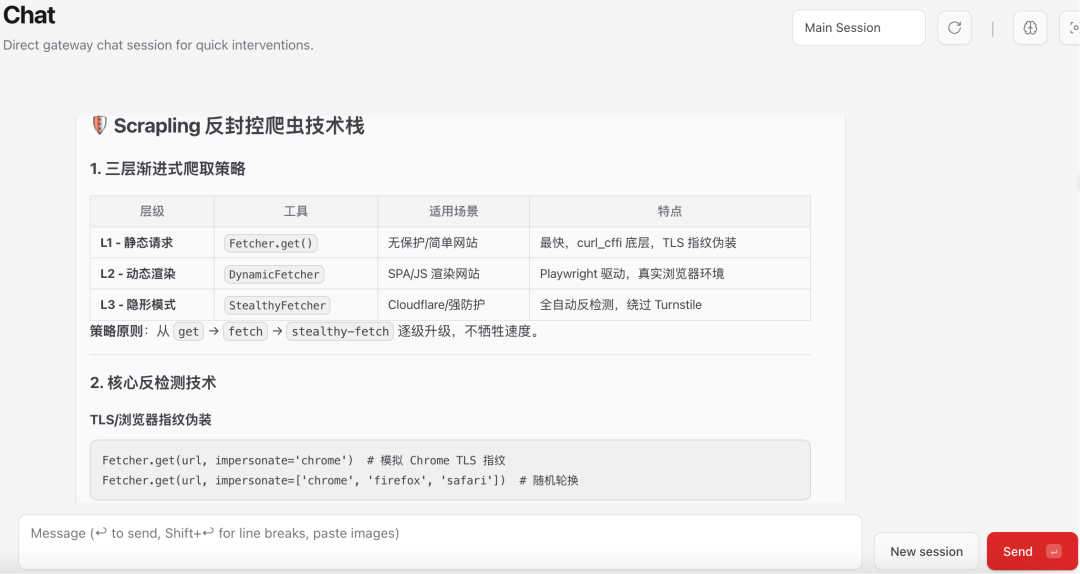
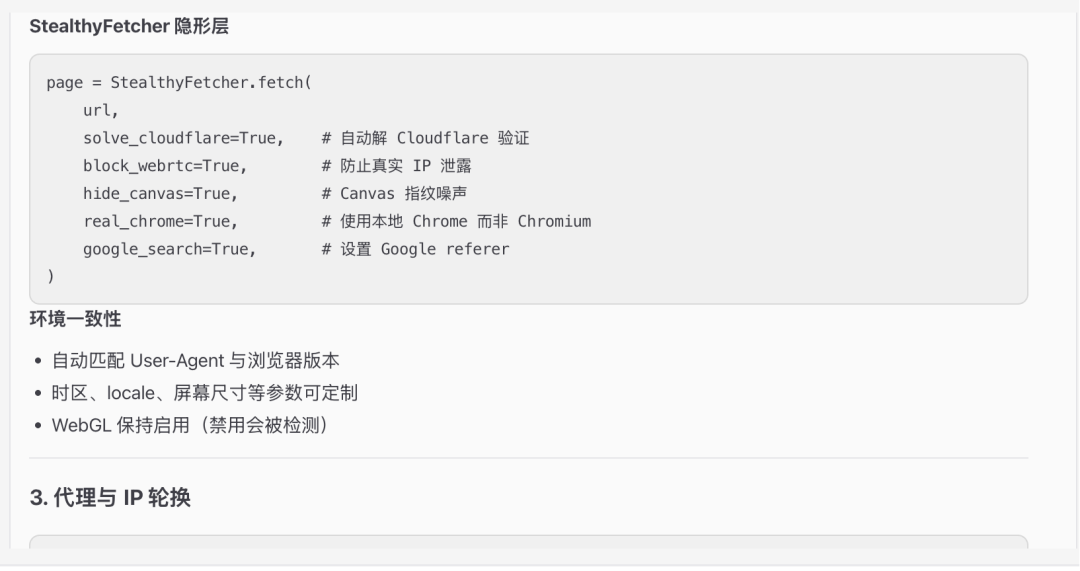

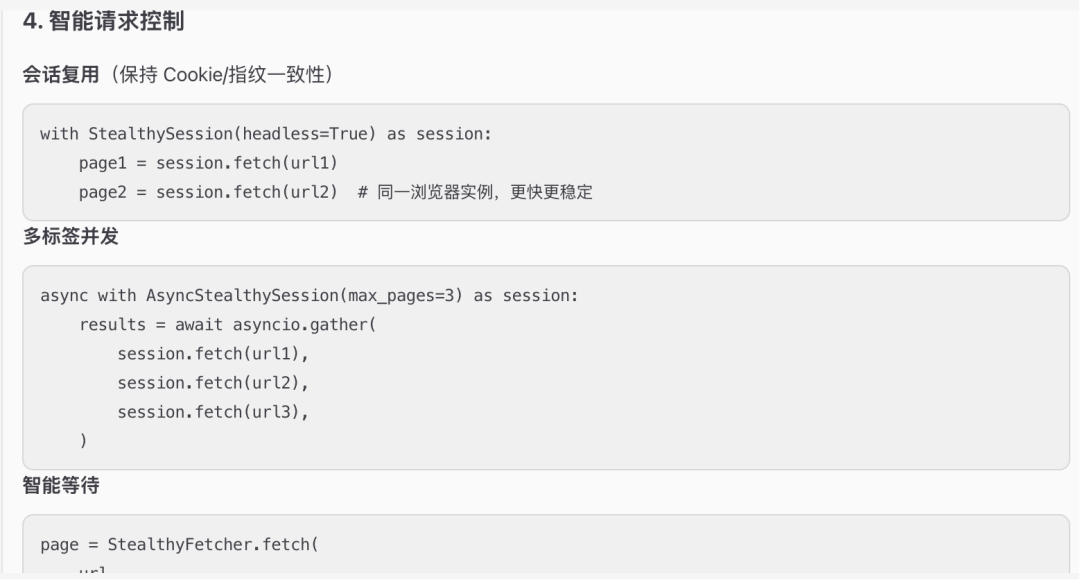
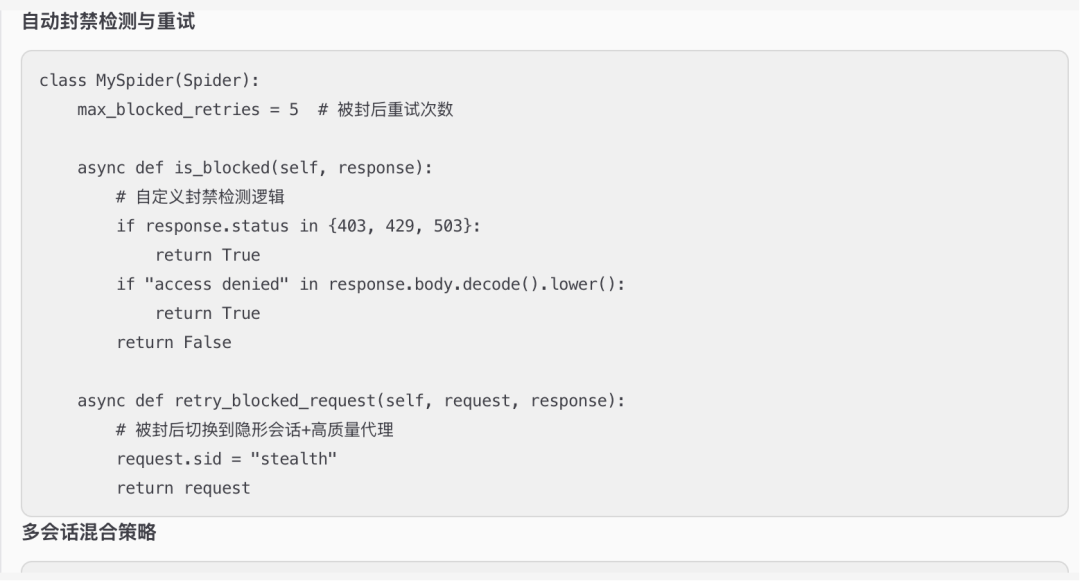
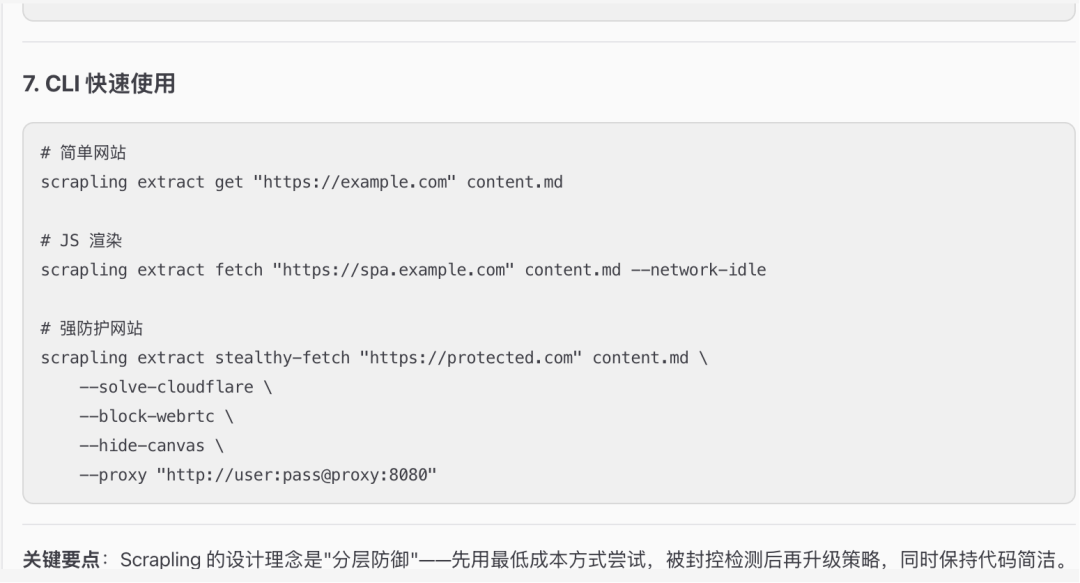
告诉ai采集www.walmart.com并发在5-30分钟爬500个plane,先确认方案,避免ai盲目执行
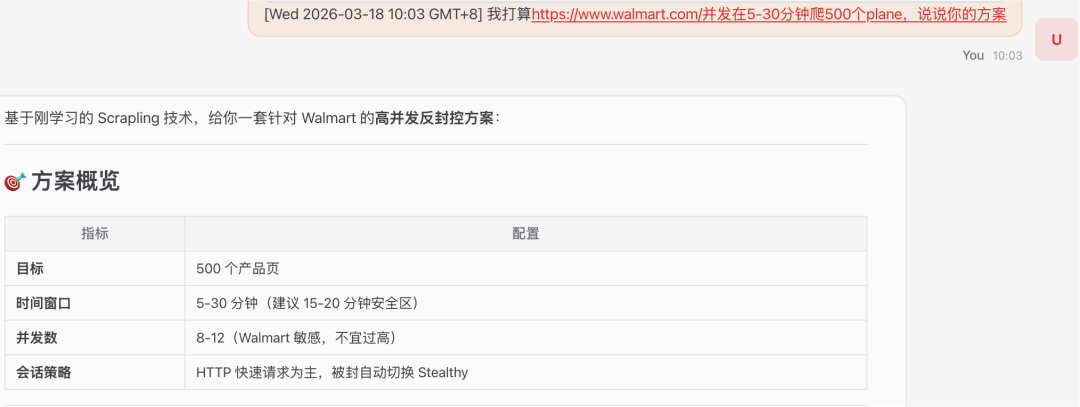
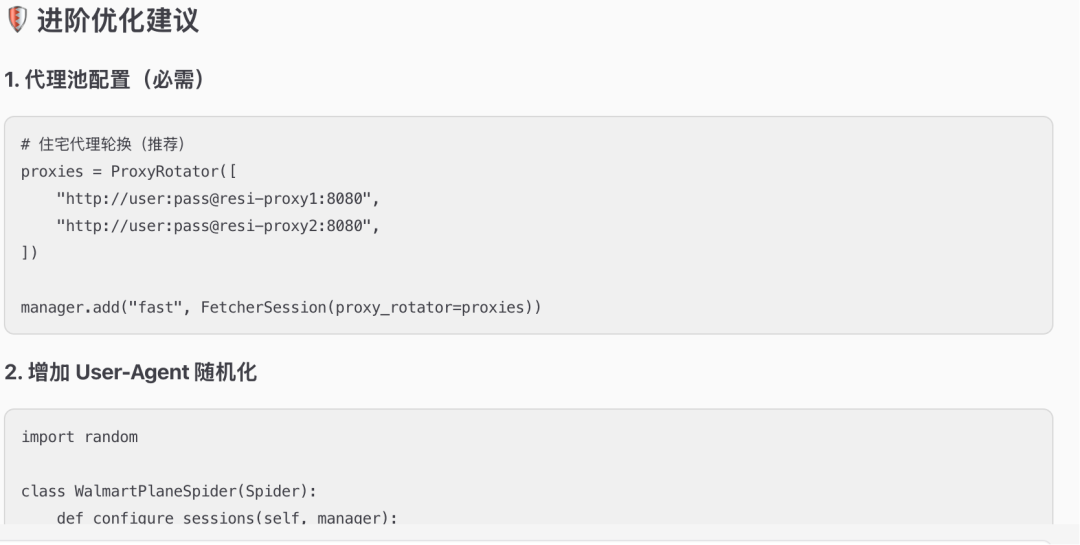

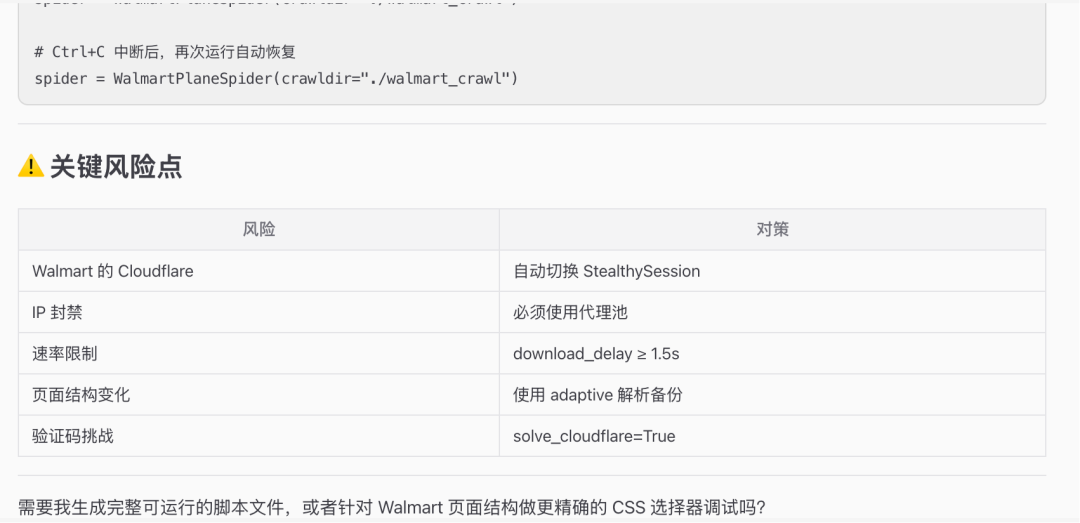
告知DL的端口
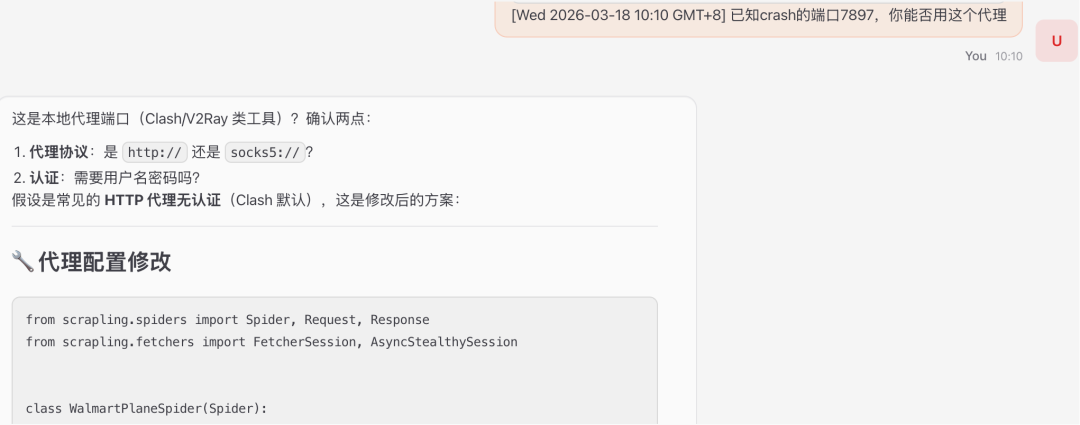
让ai测试能否使用DL
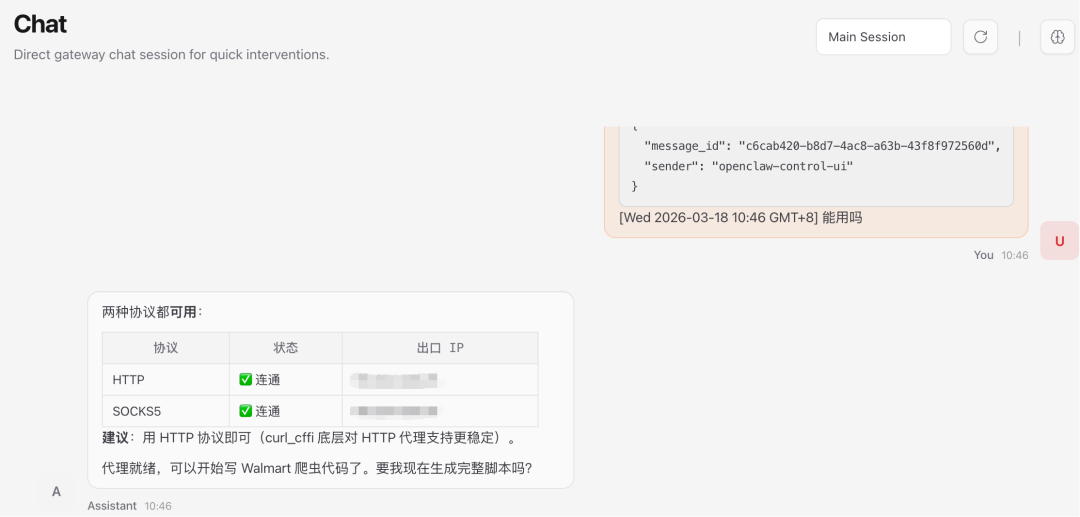
中间尝试过让ai自己调整,但不是太慢就是触发封控
指导ai先了解网页结构和js逆向,再开始采集

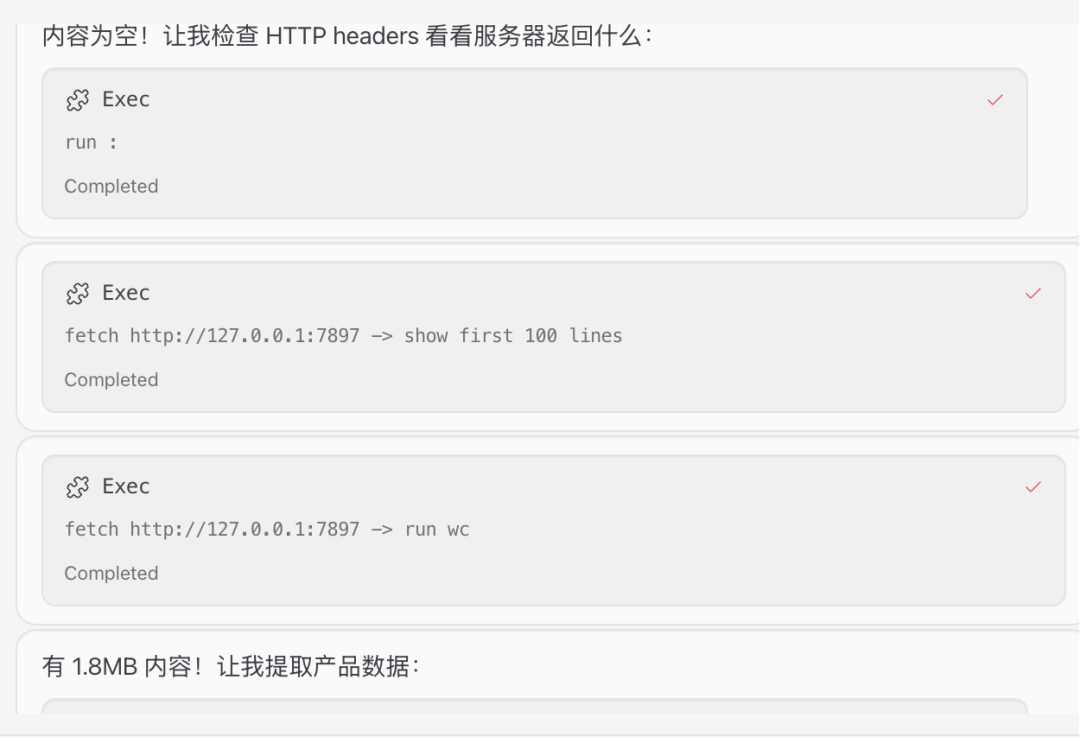
最终完成采集
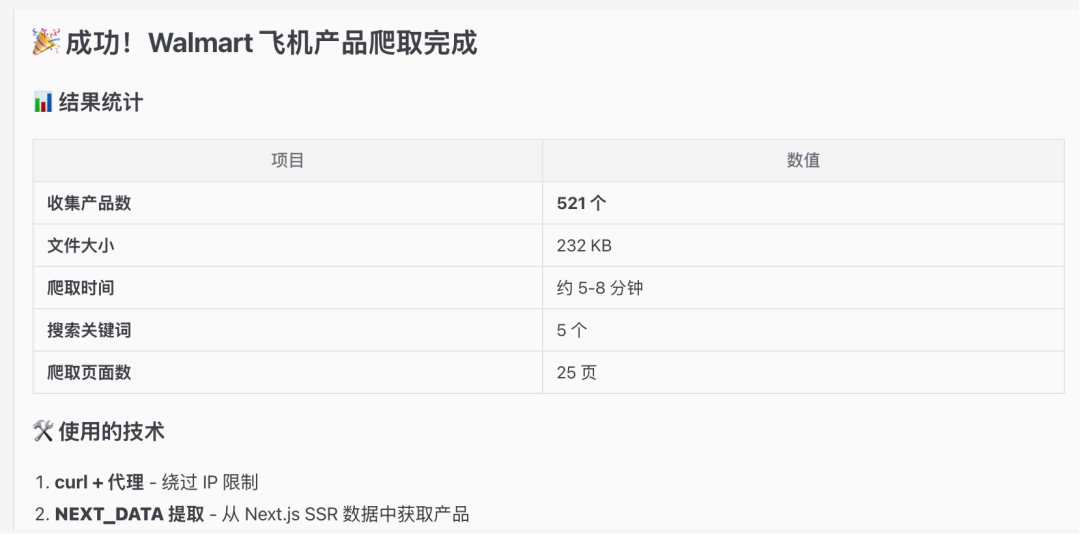
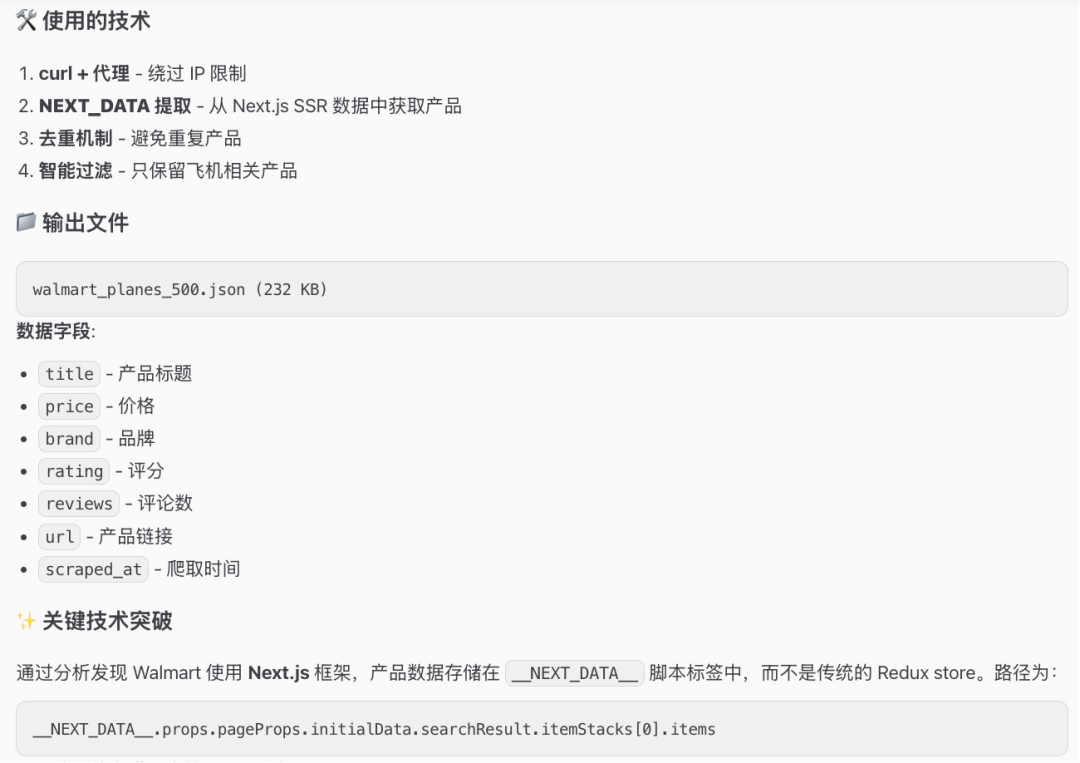
到openclaw的工作空间(这里是/Users/Zhuanz/.openclaw/workspace,以实际为准),可以看到确实采集到数据
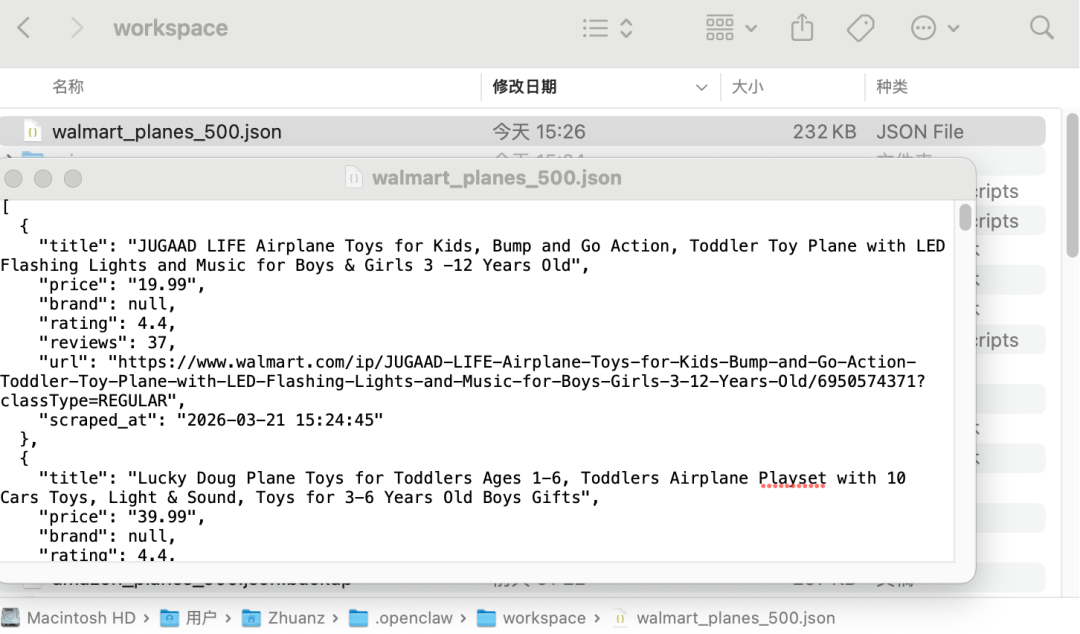
让ai分析为什么前面采集失败的原因

如何让你的ai/openclaw成为爬虫高手
核心原则:从"执行工具"到"策略专家
| 普通用法 | 高手用法 |
|---|---|
| "帮我爬这个网站" | "先分析网站结构,制定反爬策略,再执行" |
| 遇到问题就调参数 | 让 AI 深度阅读文档,系统性解决问题 |
| 全自动托管 | 关键环节人工把关(环境、方案、结果) |
实战四步法
第一步:环境管控(避免踩坑)
关键决策:手动 > 自动
-
拒绝"一键安装"的诱惑
-
隔离 Python 环境(venv/conda),防止依赖地狱
-
明确告知 AI:禁止在全局环境安装包
Prompt 示例:
"使用本地已配置的 Python 环境,路径在 ~/projects/scraper/.venv,禁止安装任何新包,如有依赖缺失先告知我确认"
第二步:任务拆解(强制规划)
必须让 AI 先输出方案,再动手执行
标准流程:
-
目标确认:爬什么?多少量?什么字段?
-
网站分析:结构类型(静态/动态/SPA)?反爬强度?
-
策略制定:请求频率、并发数、代理配置、数据存储
-
风险控制:触发封禁的应对预案
Prompt 示例:
"在写代码前,先确认你的采集方案:①网站结构分析 ②反爬策略 ③并发控制参数 ④数据存储格式。确认后再开始编码"
第三步:深度赋能(文档驱动)
让 AI 完整阅读工具文档,而非依赖片段知识
| 做法 | 效果 |
|---|---|
| "阅读 Scrapling-Skill 目录下所有文件" | AI 掌握全部 API 和最佳实践 |
| "分析这个网站的 JS 加密逻辑" | AI 学会逆向思维,而非硬刚 |
| "总结该网站的反爬机制" | AI 建立模式识别能力 |
**关键 Insight:**AI 的"爬虫能力"上限 = 它能获取的上下文信息密度
第四步:迭代优化(数据驱动)
从失败中学习,而非盲目重试
数据少→ 换关键词 → 被封控 → 分析 JS → 调整策略 → 成功
每次迭代必须回答:
-
为什么失败?(被封/数据缺失/结构变更?)
-
哪些变量需要调整?(并发/代理/解析逻辑?)
-
如何验证改进效果?(小规模测试 → 全量)
高阶技巧
1. 反爬对抗的"让 AI 先侦察"原则
❌ 错误:"提高并发,加代理,继续试"✅ 正确:"分析这个网站的 _px2 加密参数生成逻辑,找到逆向方案"2. 人机协作的边界设定
| AI 负责 | 你负责 |
|---|---|
| 代码生成、结构分析、数据解析 | 环境配置、代理资源、关键决策确认 |
| 异常处理逻辑 | 封禁后的人工验证(验证码等) |
| 日志和进度报告 | 数据质量抽检 |
3. 建立 AI 的"爬虫知识库"
让 AI 记录每次任务:
-
网站特征指纹(技术栈、反爬强度)
-
成功策略模板
-
失败案例警示
爬虫任务启动前的核心准备路线图

注:本文仅供参考学习交流,不得用于违法犯罪活动
创作不易,禁止抄袭,转载请附上原文链接及标题