

1.拿到题目后想到该题目的字符串有周期性,可以以Z的左上角字符开始,到下一个左上角字符结束(不包含该字符),具体如下图所示:
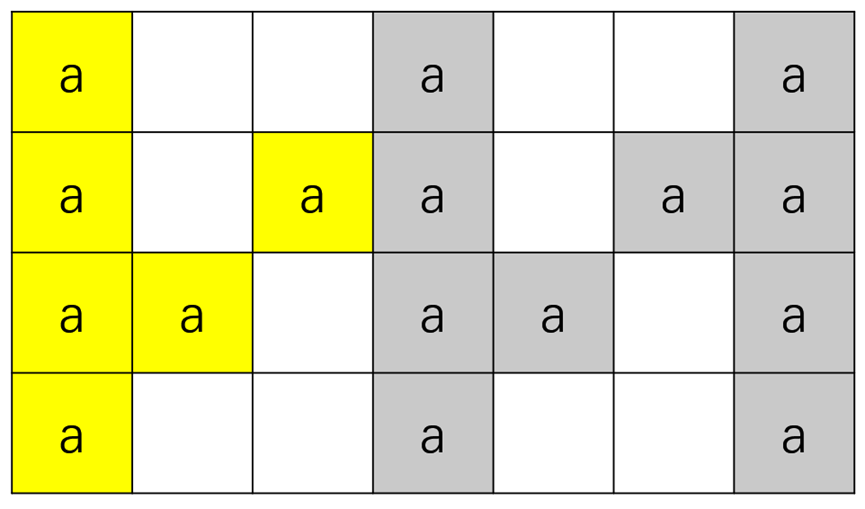
黄色标注的部分即为一个周期单元mem,根据规律可得出mem的值为行数 * 2 - 2。
2.每一行的字符下标也有规律,可以发现每一行都一定包含该行的第一个字符,如果不是第一行或者最后一行,还会包含scur + mem - 2 \* row,cur为当前指针位置,row为正被扫描的该行号。根据以上思想,可以初步写出如下代码:
cpp
1. char* convert(char* s, int numRows) {
2. int len = strlen(s);
3. char res[len];
4. int mem = numRows * 2 - 2;
5. int cnt = 0;
6.
7. for (int i = 0; i < numRows; i++){
8. int cur = i;
9. while (cur < len){
10. res[cnt++] = s[cur];
11. if (mem == 0){
12. break;
13. }
14. if (i > 0 && i < numRows - 1 && cur + mem - 2 * i < len){
15. res[cnt++] = s[cur + mem - 2 * i];
16. }
17. cur += mem;
18. }
19. }
20.
21. return res;
22. }3.但是写的代码报错了,检查后发现有如下两点原因:
①我将结果数组定义为局部变量了,储存在栈上的局部变量会在函数结束后被回收并销毁,这样会导致每次传出去的指针指向的内存全部为NULL。正确做法应该是使用malloc,将结果数组储存在堆上。
②没有正确处理行数为1的情况。我现在的代码虽然加了if (mem == 0)的判断,会跳出while循环,但那样会导致处于同一行的剩余字符全都被跳过了。正确做法是在运行for循环之前就进行行数判断,如果行数为1或者行数大于等于字符串长度(字符全都在第一列上)时直接返回s。
4.修正了以上为题后,写出的完整代码如下:
cpp
1. char* convert(char* s, int numRows) {
2. int len = strlen(s); // 字符串长度
3. char* res = (char*)malloc(sizeof(char) * (len + 1)); // 结果字符串(堆内存)
4. int mem = numRows * 2 - 2; // 一个周期的长度(Z字形一个来回)
5. int cnt = 0; // 结果数组下标
6.
7. // 边界条件:1行 或 字符串很短,直接返回原串
8. if (numRows == 1 || len <= numRows){
9. return s;
10. }
11.
12. // 按行遍历:第 0 行 → 第 1 行 → ... → 第 numRows-1 行
13. for (int i = 0; i < numRows; i++){
14. int cur = i; // 第 i 行的起始位置就是 i
15.
16. // 沿着周期往下走
17. while (cur < len){
18. res[cnt++] = s[cur]; // 把当前字符放入结果
19.
20. // 【核心】中间行需要多取一个斜着的字符
21. if (i > 0 && i < numRows - 1 && cur + mem - 2 * i < len){
22. res[cnt++] = s[cur + mem - 2 * i];
23. }
24.
25. cur += mem; // 跳到下一个周期
26. }
27. }
28.
29. res[cnt] = '\0'; // 字符串必须结尾加结束符
30. return res;
31. }需要注意的是,给字符串进行malloc时需要给末尾的'\0'也留出空间,所以需要(char*)malloc(sizeof(char) * (len + 1))。该算法的时间复杂度为O(n),空间复杂度也为O(n)。
5.但目前的代码不是最快的,以下是力扣最快的完整代码:
cpp
1. char* convert(char* s, int numRows) {
2. // ===================== 边界条件 =====================
3. // 如果只有1行 或 行数 >= 字符串长度,不需要变换,直接返回原串
4. if (numRows == 1 || numRows >= strlen(s)) {
5. return s;
6. }
7.
8. int len = strlen(s); // 字符串长度
9. char* result = (char*)malloc((len + 1) * sizeof(char)); // 堆内存分配(必须!)
10. if (result == NULL) { // 安全判断:内存分配失败
11. return NULL;
12. }
13.
14. int index = 0; // 结果数组的写入下标
15. int cycleLen = 2 * numRows - 2; // 【核心】一个 Z 字形周期的长度
16.
17. // ===================== 按行遍历:逐行取出字符 =====================
18. for (int i = 0; i < numRows; i++) {
19. // j 是周期起点,每次跳一个周期
20. for (int j = 0; j + i < len; j += cycleLen) {
21.
22. // 1. 先取「竖列」上的字符
23. result[index++] = s[j + i];
24.
25. // 2. 中间行需要额外取「斜向上」的字符
26. // 第一行 & 最后一行 没有斜向字符
27. if (i != 0 && i != numRows - 1) {
28. int midIndex = j + cycleLen - i; // 斜向字符的下标
29. if (midIndex < len) { // 不越界才取
30. result[index++] = s[midIndex];
31. }
32. }
33. }
34. }
35.
36. result[index] = '\0'; // C 字符串必须加结束符
37. return result;
38. }咨询了ai后得知,虽然算法思路一样,但该代码在以下几个方面比我做得好:
①提前了行数和边界判断的代码,放到了malloc前面。malloc是一个相对耗时的操作系统底层调用。而该代码把判断放在最前面,遇到不需要变换的情况,直接O(1)极速返回,且不消耗任何额外内存。
②对于cur的推导公式,我的为:cur + mem - 2 * i,而该代码为:j + cycleLen -- i,其中j是周期起点,相当于cur = j + i。在经过代数替换后会发现我的公式和该代码的一样,但是我的代码比它多算了一次乘法,导致慢了一些。
③该代码将循环中的if判断条件拆成了如下:
cpp
1. if (i != 0 && i != numRows - 1) {
2. int midIndex = j + cycleLen - i;
3. if (midIndex < len) {
4. result[index++] = s[midIndex];
5. }
6. }这样做可以把不依赖内层循环的 if 条件剥离出来,方便编译器做分支预测,节省时间。